
Jak wyodrębnić dane z PDF w .NET
Jak wyodrębnić dane z pliku PDF w środowisku .NET
IronPDF ułatwia wyodrębnianie tekstu, tabel, pól formularzy i załączników z dokumentów PDF w środowisku .NET za pomocą zaledwie kilku wierszy kodu, co idealnie nadaje się do automatyzacji przetwarzania faktur, tworzenia baz wiedzy lub generowania raportów bez skomplikowanego parsowania.
Dokumenty PDF są wszechobecne w biznesie; Współczesne przykłady obejmują faktury, raporty, umowy i instrukcje obsługi. Jednak programowe pozyskanie z nich istotnych informacji może być trudne. Pliki PDF skupiają się na wyglądzie, a nie na sposobie uzyskiwania dostępu do danych.
Dla programistów .NET IronPDF for .NET to potężna biblioteka .NET do obsługi plików PDF, która ułatwia wyciąganie danych z plików PDF. Możesz pobierać tekst, tabele, pola formularzy, obrazy i załączniki bezpośrednio z dokumentów PDF. Niezależnie od tego, czy automatyzujesz przetwarzanie faktur, tworzysz bazę wiedzy, czy generujesz raporty, ta biblioteka pozwala zaoszczędzić mnóstwo czasu.
W niniejszym przewodniku przedstawiono praktyczne przykłady pobierania treści tekstowych, danych tabelarycznych i wartości pól formularzy wraz z objaśnieniami po każdym fragmencie kodu, aby można było dostosować je do własnych projektów.
Jak rozpocząć pracę z IronPDF?
Dlaczego instalacja przebiega tak szybko?
Instalacja IronPDF zajmuje kilka sekund za pomocą menedżera pakietów NuGet. Otwórz konsolę menedżera pakietów i uruchom:
Install-Package IronPdf
Dla programistów Windows instalacja jest prosta. Jeśli wdrażasz oprogramowanie na systemie Linux lub macOS, IronPDF obsługuje również te platformy. Możesz nawet uruchamiać IronPDF w kontenerach Docker lub wdrażać go w Azure i AWS.
Jaki jest najprostszy sposób na wyodrębnienie tekstu?
Po zainstalowaniu można od razu rozpocząć przetwarzanie dokumentów PDF. Oto minimalny przykład w .NET, który pokazuje prostotę API IronPDF:
using IronPdf;
// Load any PDF document
var pdf = PdfDocument.FromFile("document.pdf");
// Extract all text with one line
string allText = pdf.ExtractAllText();
Console.WriteLine(allText);using IronPdf;
// Load any PDF document
var pdf = PdfDocument.FromFile("document.pdf");
// Extract all text with one line
string allText = pdf.ExtractAllText();
Console.WriteLine(allText);Imports IronPdf
' Load any PDF document
Dim pdf = PdfDocument.FromFile("document.pdf")
' Extract all text with one line
Dim allText As String = pdf.ExtractAllText()
Console.WriteLine(allText)Ten kod ładuje plik PDF i wyodrębnia z niego cały tekst. IronPDF automatycznie obsługuje złożone struktury plików PDF, dane formularzy i kodowania, które zazwyczaj powodują problemy w innych bibliotekach. Dane wyodrębnione z dokumentów PDF można zapisać w pliku tekstowym lub poddać dalszej obróbce w celu analizy.
Praktyczna wskazówka: Wyodrębniony tekst można zapisać w pliku .txt do późniejszego przetworzenia lub przeanalizować w celu wypełnienia baz danych, arkuszy Excel lub baz wiedzy. Ta metoda sprawdza się dobrze w przypadku raportów, umów lub dowolnych plików PDF, w których potrzebujesz po prostu szybko uzyskać surowy tekst. W przypadku bardziej zaawansowanych scenariuszy ekstrakcji zapoznaj się z obszernym przewodnikiem po parsowaniu.
Jak wyodrębnić dane z określonych stron pliku PDF?
Dlaczego warto skupić się na konkretnych stronach zamiast pobierać wszystko?
Praktyczne zastosowania często wymagają precyzyjnego pozyskiwania danych. IronPDF oferuje wiele metod pozyskiwania cennych informacji z określonych stron. W tym przykładzie wykorzystamy następujący plik PDF:
using IronPdf;
// Load PDF from a memory stream if needed
byte[] pdfBytes = File.ReadAllBytes("report.pdf");
var pdfFromStream = PdfDocument.FromBytes(pdfBytes);
// Or load from a URL
var pdfFromUrl = PdfDocument.FromUrl("___PROTECTED_URL_32___");using IronPdf;
// Load PDF from a memory stream if needed
byte[] pdfBytes = File.ReadAllBytes("report.pdf");
var pdfFromStream = PdfDocument.FromBytes(pdfBytes);
// Or load from a URL
var pdfFromUrl = PdfDocument.FromUrl("___PROTECTED_URL_32___");Imports IronPdf
' Load PDF from a memory stream if needed
Dim pdfBytes As Byte() = File.ReadAllBytes("report.pdf")
Dim pdfFromStream As PdfDocument = PdfDocument.FromBytes(pdfBytes)
' Or load from a URL
Dim pdfFromUrl As PdfDocument = PdfDocument.FromUrl("___PROTECTED_URL_32___")Jak wyszukiwać kluczowe informacje w wyodrębnionym tekście?
Poniższy kod pobiera dane z określonych stron i zwraca wyniki do konsoli. Technika ta jest szczególnie przydatna podczas pracy z wielostronicowymi plikami PDF lub gdy konieczne jest podzielenie plików PDF w celu przetworzenia:
using IronPdf;
using System;
using System.Text.RegularExpressions;
// Load any PDF document
var pdf = PdfDocument.FromFile("AnnualReport2024.pdf");
// Extract from selected pages
int[] pagesToExtract = { 0, 2, 4 }; // Pages 1, 3, and 5
foreach (var pageIndex in pagesToExtract)
{
string pageText = pdf.ExtractTextFromPage(pageIndex);
// Split on 2 or more spaces (tables often flatten into space-separated values)
var tokens = Regex.Split(pageText, @"\s{2,}");
foreach (string token in tokens)
{
// Match totals, invoice headers, and invoice rows
if (token.Contains("Invoice") || token.Contains("Total") || token.StartsWith("INV-"))
{
Console.WriteLine($"Important: {token.Trim()}");
}
}
}using IronPdf;
using System;
using System.Text.RegularExpressions;
// Load any PDF document
var pdf = PdfDocument.FromFile("AnnualReport2024.pdf");
// Extract from selected pages
int[] pagesToExtract = { 0, 2, 4 }; // Pages 1, 3, and 5
foreach (var pageIndex in pagesToExtract)
{
string pageText = pdf.ExtractTextFromPage(pageIndex);
// Split on 2 or more spaces (tables often flatten into space-separated values)
var tokens = Regex.Split(pageText, @"\s{2,}");
foreach (string token in tokens)
{
// Match totals, invoice headers, and invoice rows
if (token.Contains("Invoice") || token.Contains("Total") || token.StartsWith("INV-"))
{
Console.WriteLine($"Important: {token.Trim()}");
}
}
}Imports IronPdf
Imports System
Imports System.Text.RegularExpressions
' Load any PDF document
Dim pdf = PdfDocument.FromFile("AnnualReport2024.pdf")
' Extract from selected pages
Dim pagesToExtract As Integer() = {0, 2, 4} ' Pages 1, 3, and 5
For Each pageIndex In pagesToExtract
Dim pageText As String = pdf.ExtractTextFromPage(pageIndex)
' Split on 2 or more spaces (tables often flatten into space-separated values)
Dim tokens = Regex.Split(pageText, "\s{2,}")
For Each token As String In tokens
' Match totals, invoice headers, and invoice rows
If token.Contains("Invoice") OrElse token.Contains("Total") OrElse token.StartsWith("INV-") Then
Console.WriteLine($"Important: {token.Trim()}")
End If
Next
NextTen przykład pokazuje, jak wyodrębnić tekst z dokumentów PDF, wyszukać kluczowe informacje i przygotować je do przechowywania. Metoda ExtractTextFromPage() zachowuje kolejność czytania dokumentu, dzięki czemu idealnie nadaje się do analizy dokumentów i indeksowania treści. W przypadku zaawansowanej edycji tekstu można nawet wyszukiwać i zamieniać tekst w plikach PDF.
Jak wyodrębnić dane z tabel w dokumentach PDF?
Czym różni się ekstrakcja tabel od zwykłego tekstu?
Tabele w plikach PDF nie mają natywnej struktury; są to po prostu treści tekstowe rozmieszczone tak, aby wyglądały jak tabele. IronPDF wyodrębnia dane tabelaryczne, zachowując układ, dzięki czemu można je przetworzyć do plików Excel lub tekstowych. W przypadku bardziej złożonych scenariuszy obejmujących obrazy w plikach PDF może być konieczne wyodrębnienie obrazów osobno.
Jak przekonwertować wyodrębnione tabele do formatu CSV?
using IronPdf;
using System.Text;
using System.Text.RegularExpressions;
using System.IO;
var pdf = PdfDocument.FromFile("example.pdf");
string rawText = pdf.ExtractAllText();
// Split into lines for processing
string[] lines = rawText.Split('\n');
var csvBuilder = new StringBuilder();
foreach (string line in lines)
{
if (string.IsNullOrWhiteSpace(line) || line.Contains("Page"))
continue;
string[] rawCells = Regex.Split(line.Trim(), @"\s+");
string[] cells;
// If the line starts with "Product", combine first two tokens as product name
if (rawCells[0].StartsWith("Product") && rawCells.Length >= 5)
{
cells = new string[rawCells.Length - 1];
cells[0] = rawCells[0] + " " + rawCells[1]; // Combine Product + letter
Array.Copy(rawCells, 2, cells, 1, rawCells.Length - 2);
}
else
{
cells = rawCells;
}
// Keep header or table rows
bool isTableOrHeader = cells.Length >= 2
&& (cells[0].StartsWith("Item") || cells[0].StartsWith("Product")
|| Regex.IsMatch(cells[0], @"^INV-\d+"));
if (isTableOrHeader)
{
Console.WriteLine($"Row: {string.Join("|", cells)}");
string csvRow = string.Join(",", cells).Trim();
csvBuilder.AppendLine(csvRow);
}
}
// Save as CSV for Excel import
File.WriteAllText("extracted_table.csv", csvBuilder.ToString());
Console.WriteLine("Table data exported to CSV");using IronPdf;
using System.Text;
using System.Text.RegularExpressions;
using System.IO;
var pdf = PdfDocument.FromFile("example.pdf");
string rawText = pdf.ExtractAllText();
// Split into lines for processing
string[] lines = rawText.Split('\n');
var csvBuilder = new StringBuilder();
foreach (string line in lines)
{
if (string.IsNullOrWhiteSpace(line) || line.Contains("Page"))
continue;
string[] rawCells = Regex.Split(line.Trim(), @"\s+");
string[] cells;
// If the line starts with "Product", combine first two tokens as product name
if (rawCells[0].StartsWith("Product") && rawCells.Length >= 5)
{
cells = new string[rawCells.Length - 1];
cells[0] = rawCells[0] + " " + rawCells[1]; // Combine Product + letter
Array.Copy(rawCells, 2, cells, 1, rawCells.Length - 2);
}
else
{
cells = rawCells;
}
// Keep header or table rows
bool isTableOrHeader = cells.Length >= 2
&& (cells[0].StartsWith("Item") || cells[0].StartsWith("Product")
|| Regex.IsMatch(cells[0], @"^INV-\d+"));
if (isTableOrHeader)
{
Console.WriteLine($"Row: {string.Join("|", cells)}");
string csvRow = string.Join(",", cells).Trim();
csvBuilder.AppendLine(csvRow);
}
}
// Save as CSV for Excel import
File.WriteAllText("extracted_table.csv", csvBuilder.ToString());
Console.WriteLine("Table data exported to CSV");Imports IronPdf
Imports System.Text
Imports System.Text.RegularExpressions
Imports System.IO
Dim pdf = PdfDocument.FromFile("example.pdf")
Dim rawText As String = pdf.ExtractAllText()
' Split into lines for processing
Dim lines() As String = rawText.Split(ControlChars.Lf)
Dim csvBuilder As New StringBuilder()
For Each line As String In lines
If String.IsNullOrWhiteSpace(line) OrElse line.Contains("Page") Then
Continue For
End If
Dim rawCells() As String = Regex.Split(line.Trim(), "\s+")
Dim cells() As String
' If the line starts with "Product", combine first two tokens as product name
If rawCells(0).StartsWith("Product") AndAlso rawCells.Length >= 5 Then
cells = New String(rawCells.Length - 2) {}
cells(0) = rawCells(0) & " " & rawCells(1) ' Combine Product + letter
Array.Copy(rawCells, 2, cells, 1, rawCells.Length - 2)
Else
cells = rawCells
End If
' Keep header or table rows
Dim isTableOrHeader As Boolean = cells.Length >= 2 AndAlso (cells(0).StartsWith("Item") OrElse cells(0).StartsWith("Product") OrElse Regex.IsMatch(cells(0), "^INV-\d+"))
If isTableOrHeader Then
Console.WriteLine($"Row: {String.Join("|", cells)}")
Dim csvRow As String = String.Join(",", cells).Trim()
csvBuilder.AppendLine(csvRow)
End If
Next
' Save as CSV for Excel import
File.WriteAllText("extracted_table.csv", csvBuilder.ToString())
Console.WriteLine("Table data exported to CSV")Jakie są typowe problemy związane z wyodrębnianiem złożonych tabel?
Tabele w plikach PDF to zazwyczaj po prostu tekst ułożony tak, aby wyglądał jak siatka. Ta kontrola pomaga ustalić, czy dana linia należy do wiersza tabeli, czy do nagłówka. Odfiltrowując nagłówki, stopki i niepowiązany tekst, można wyodrębnić z pliku PDF czyste dane tabelaryczne, gotowe do użycia w formacie CSV lub Excel.
Ten proces sprawdza się w przypadku formularzy PDF, dokumentów finansowych i raportów. Wyodrębnione dane można później przekonwertować na pliki xlsx lub połączyć w plik ZIP. W przypadku złożonych tabel ze scalonymi komórkami może być konieczne dostosowanie logiki parsowania w oparciu o pozycje kolumn. W przypadku pracy ze skanowanymi plikami PDF warto najpierw rozważyć użycie IronOCR do rozpoznawania tekstu.
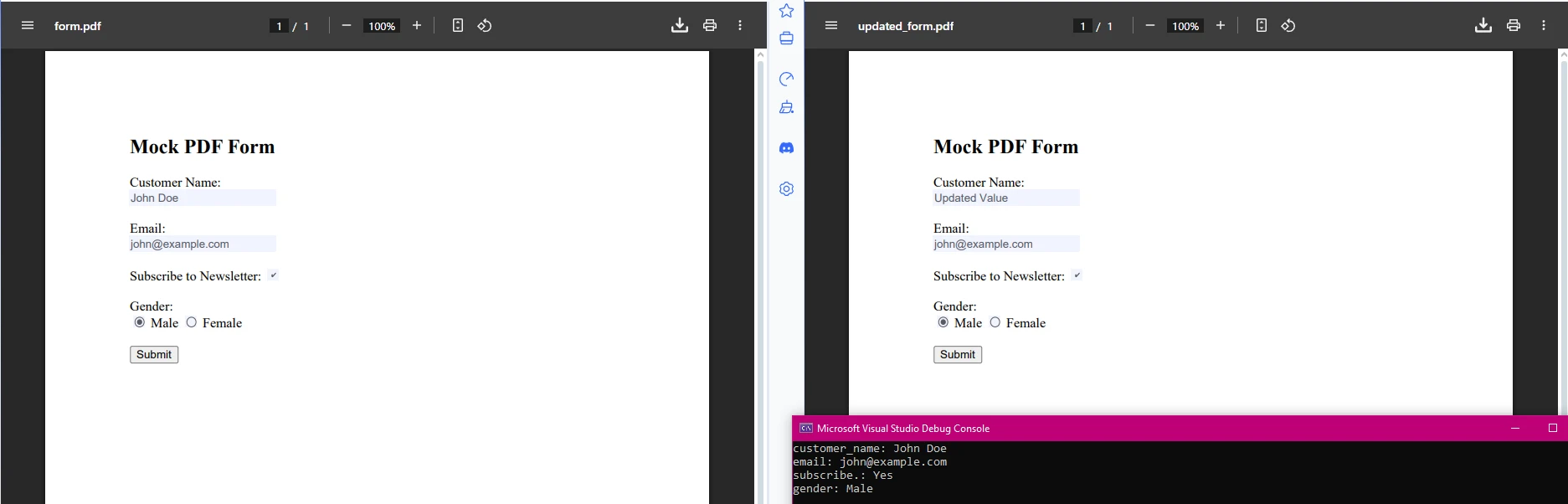
Jak wyodrębnić dane z pól formularzy z plików PDF?
Dlaczego warto programowo wyodrębniać i modyfikować pola formularzy?
IronPDF umożliwia również wyodrębnianie i modyfikowanie danych z pól formularzy. Jest to szczególnie przydatne w przypadku formularzy PDF z możliwością wypełniania, które wymagają automatycznego przetwarzania:
using IronPdf;
using System.Drawing;
using System.Linq;
var pdf = PdfDocument.FromFile("form_document.pdf");
// Extract form field data
var form = pdf.Form;
foreach (var field in form) // Removed '.Fields' as 'FormFieldCollection' is enumerable
{
Console.WriteLine($"{field.Name}: {field.Value}");
// Update form values if needed
if (field.Name == "customer_name")
{
field.Value = "Updated Value";
}
}
// Save modified form
pdf.SaveAs("updated_form.pdf");using IronPdf;
using System.Drawing;
using System.Linq;
var pdf = PdfDocument.FromFile("form_document.pdf");
// Extract form field data
var form = pdf.Form;
foreach (var field in form) // Removed '.Fields' as 'FormFieldCollection' is enumerable
{
Console.WriteLine($"{field.Name}: {field.Value}");
// Update form values if needed
if (field.Name == "customer_name")
{
field.Value = "Updated Value";
}
}
// Save modified form
pdf.SaveAs("updated_form.pdf");Imports IronPdf
Imports System.Drawing
Imports System.Linq
Dim pdf = PdfDocument.FromFile("form_document.pdf")
' Extract form field data
Dim form = pdf.Form
For Each field In form ' Removed '.Fields' as 'FormFieldCollection' is enumerable
Console.WriteLine($"{field.Name}: {field.Value}")
' Update form values if needed
If field.Name = "customer_name" Then
field.Value = "Updated Value"
End If
Next
' Save modified form
pdf.SaveAs("updated_form.pdf")W celu bardziej zaawansowanej obsługi formularzy można również pracować z konkretnymi typami pól:
// Work with different form field types
foreach (var field in pdf.Form)
{
switch (field)
{
case TextFormField textField:
Console.WriteLine($"Text field '{field.Name}': {textField.Value}");
break;
case CheckBoxFormField checkBox:
Console.WriteLine($"Checkbox '{field.Name}': {checkBox.Value}");
checkBox.Value = true; // Check the box
break;
case ComboBoxFormField comboBox:
Console.WriteLine($"ComboBox '{field.Name}': {comboBox.Value}");
// Set to first available option
if (comboBox.Choices.Any())
comboBox.Value = comboBox.Choices.First();
break;
}
}// Work with different form field types
foreach (var field in pdf.Form)
{
switch (field)
{
case TextFormField textField:
Console.WriteLine($"Text field '{field.Name}': {textField.Value}");
break;
case CheckBoxFormField checkBox:
Console.WriteLine($"Checkbox '{field.Name}': {checkBox.Value}");
checkBox.Value = true; // Check the box
break;
case ComboBoxFormField comboBox:
Console.WriteLine($"ComboBox '{field.Name}': {comboBox.Value}");
// Set to first available option
if (comboBox.Choices.Any())
comboBox.Value = comboBox.Choices.First();
break;
}
}' Work with different form field types
For Each field In pdf.Form
Select Case field
Case textField As TextFormField
Console.WriteLine($"Text field '{field.Name}': {textField.Value}")
Case checkBox As CheckBoxFormField
Console.WriteLine($"Checkbox '{field.Name}': {checkBox.Value}")
checkBox.Value = True ' Check the box
Case comboBox As ComboBoxFormField
Console.WriteLine($"ComboBox '{field.Name}': {comboBox.Value}")
' Set to first available option
If comboBox.Choices.Any() Then
comboBox.Value = comboBox.Choices.First()
End If
End Select
NextKiedy należy stosować ekstrakcję pól formularzy?
Ten fragment kodu pobiera wartości pól formularzy z plików PDF i pozwala na ich aktualizację programowo. Ułatwia to przetwarzanie formularzy PDF i wyodrębnianie określonych informacji do analizy lub generowania raportów. Jest to przydatne do automatyzacji procesów, takich jak wdrażanie klientów, przetwarzanie ankiet lub walidacja danych.
Typowe przypadki uzycia obejmuja:
- Automatyzacja podpisów cyfrowych
- Przetwarzanie plików PDF chronionych hasłem
- Pobieranie danych w celu zapewnienia zgodności z formatem PDF/A
- Tworzenie niestandardowych przepływów pracy
Jakie są moje kolejne kroki?
IronPDF sprawia, że ekstrakcja danych z plików PDF w środowisku .NET jest praktyczna i wydajna. Możesz wyodrębniać tekst, tabele, pola formularzy, obrazy i załączniki z różnych dokumentów PDF, w tym ze skanowanych plików PDF, które zazwyczaj wymagają dodatkowej obróbki OCR.
Niezależnie od tego, czy Twoim celem jest stworzenie bazy wiedzy, automatyzacja procesów raportowania, czy też wyodrębnianie danych z plików PDF dotyczących finansów, ta biblioteka zapewnia narzędzia pozwalające to zrobić bez ręcznego kopiowania lub podatnego na błędy parsowania. Jest proste, szybkie i integruje się bezpośrednio z projektami Visual Studio. Spróbuj; Prawdopodobnie zaoszczędzisz sporo czasu i unikniesz typowych problemów związanych z pracą z plikami PDF.
W przypadku bardziej zaawansowanych scenariuszy zapoznaj się z:
- Konwersja plików PDF na obrazy
- Praca z metadanymi
- Kompresja plików PDF
- Zarządzanie czcionkami
- Tworzenie plików PDF dostosowanych do potrzeb osób niepełnosprawnych
Chcesz wdrożyć funkcję wyodrębniania danych z plików PDF w swoich aplikacjach? Czy IronPDF brzmi jak biblioteka .NET dla Ciebie? Rozpocznij bezpłatny okres próbny do użytku komercyjnego. Zapraszamy do zapoznania się z naszą dokumentacją, w której znajdują się obszerne przewodniki i Dokumentacja API.
Często Zadawane Pytania
Jaki jest najlepszy sposób na wyodrębnianie tekstu z dokumentów PDF przy użyciu .NET?
Korzystając z IronPDF, można łatwo wyodrębniać tekst z dokumentów PDF w aplikacjach .NET. Zapewnia on metody wydajnego pobierania danych tekstowych, gwarantując dostęp do potrzebnych treści.
Czy IronPDF obsługuje zeskanowane pliki PDF w celu ekstrakcji danych?
Tak, IronPDF obsługuje OCR (optyczne rozpoznawanie znaków) w celu przetwarzania i wyodrębniania danych ze skanowanych plików PDF, umożliwiając dostęp do tekstu nawet w dokumentach opartych na obrazach.
Jak wyodrębnić tabele z pliku PDF przy użyciu języka C#?
IronPDF oferuje funkcje analizowania i wyodrębniania tabel z dokumentów PDF w języku C#. Można używać określonych metod do dokładnej identyfikacji i pobierania danych z tabel.
Jakie są zalety korzystania z IronPDF do wyodrębniania danych z plików PDF?
IronPDF oferuje kompleksowe rozwiązanie do ekstrakcji danych z plików PDF, w tym pobieranie tekstu, analizę tabel oraz OCR dla zeskanowanych dokumentów. Integruje się ono płynnie z aplikacjami .NET, zapewniając niezawodny i wydajny sposób obsługi danych PDF.
Czy za pomocą IronPDF można wyodrębnić obrazy z pliku PDF?
Tak, IronPDF umożliwia wyodrębnianie obrazów z plików PDF. Ta funkcja jest przydatna, jeśli potrzebujesz uzyskać dostęp do obrazów osadzonych w dokumentach PDF i manipulować nimi.
W jaki sposób IronPDF radzi sobie ze złożonymi układami plików PDF podczas ekstrakcji danych?
IronPDF został zaprojektowany do zarządzania złożonymi układami plików PDF, oferując solidne narzędzia do nawigacji i wyodrębniania danych, co pozwala na obsługę dokumentów o skomplikowanym formatowaniu i strukturze.
Czy mogę zautomatyzować wyodrębnianie danych z plików PDF w aplikacji .NET?
Oczywiście. IronPDF można zintegrować z aplikacjami .NET w celu automatyzacji ekstrakcji danych z plików PDF, usprawniając procesy wymagające regularnego i spójnego pobierania danych.
Jakich języków programowania mogę używać z IronPDF do wyodrębniania danych z plików PDF?
IronPDF jest używany głównie z językiem C# w .NET Framework, oferując szerokie wsparcie i funkcjonalność dla programistów, którzy chcą programowo wyodrębniać dane z plików PDF.
Czy IronPDF obsługuje wyodrębnianie metadanych z dokumentów PDF?
Tak, IronPDF może wyodrębniać metadane z dokumentów PDF, umożliwiając dostęp do informacji takich jak autor, data utworzenia i inne właściwości dokumentu.
Jakie przykładowe kody są dostępne do nauki ekstrakcji danych z plików PDF za pomocą IronPDF?
Przewodnik dla programistów zawiera kompletne samouczki dotyczące języka C# wraz z działającymi przykładami kodu, które pomogą Ci opanować ekstrakcję danych z plików PDF przy użyciu IronPDF w aplikacjach .NET.
Czy IronPDF jest w pełni kompatybilny z nową wersją .NET 10 i jakie korzyści przynosi to w zakresie ekstrakcji danych?
Tak — IronPDF jest w pełni kompatybilny z .NET 10 i obsługuje wszystkie ulepszenia dotyczące wydajności, API i środowiska uruchomieniowego, takie jak zmniejszone alokacje sterty, dewirtualizacja interfejsu tablic oraz ulepszone funkcje językowe. Ulepszenia te prowadzą do szybszych i bardziej wydajnych procesów ekstrakcji danych PDF w aplikacjach C#.














