.NET PDF Creation (Developer Tutorial Using IronPDF)
.NETでPDFからデータを抽出する方法
IronPDF を使用すると、わずか数行のコードで.NETの PDF ドキュメントからテキスト、表、フォーム フィールド、添付ファイルを簡単に抽出できるため、請求書処理の自動化、ナレッジ ベースの構築、複雑な解析を行わずにレポートを生成するのに最適です。
PDFドキュメントはビジネスのどこにでもあります。 現代の例としては、請求書、レポート、契約書、マニュアルが含まれます。 しかし、それらからプログラム的に重要な情報を取得することは難しい場合があります。 PDFはデータのアクセス方法ではなく、見た目に焦点を当てています。
.NET開発者にとって、IronPDFは、PDFファイルからデータを簡単に抽出することができる強力な .NET PDFライブラリです。 PDF ドキュメントからテキスト、表、フォーム フィールド、画像、添付ファイルを直接取得できます。 請求書処理の自動化、ナレッジベースの構築、レポートの生成など、このライブラリを使用すると多くの時間を節約できます。
このガイドでは、テキストコンテンツの抽出、表データの抽出、フォームフィールドの値の抽出に関する実用的な例を説明し、各コードスニペットの後に説明を加えて、独自のプロジェクトに適応可能にします。
IronPDFを使い始めるにはどうすればいいですか?
なぜインストールがこんなに速いのですか?
NuGetパッケージ マネージャーを使用すると、 IronPDF のインストールは数秒で完了します。 パッケージマネージャーコンソールを開いて、以下を実行します:
Install-Package IronPdf
Windows開発者にとって、インストールは簡単です。 LinuxまたはmacOSにデプロイする場合、 IronPDF はそれらのプラットフォームもサポートします。 IronPDF をDocker コンテナーで実行したり、 AzureやAWSにデプロイしたりすることもできます。
テキストを抽出する最も簡単な方法は何ですか?
インストールすると、すぐに PDF ドキュメントの処理を開始できます。 IronPDFのAPIのシンプルさを示す最小限の .NET例です。
using IronPdf;
// Load any PDF document
var pdf = PdfDocument.FromFile("document.pdf");
// Extract all text with one line
string allText = pdf.ExtractAllText();
Console.WriteLine(allText);using IronPdf;
// Load any PDF document
var pdf = PdfDocument.FromFile("document.pdf");
// Extract all text with one line
string allText = pdf.ExtractAllText();
Console.WriteLine(allText);Imports IronPdf
' Load any PDF document
Dim pdf = PdfDocument.FromFile("document.pdf")
' Extract all text with one line
Dim allText As String = pdf.ExtractAllText()
Console.WriteLine(allText)このコードは PDF を読み込み、すべてのテキストを抽出します。 IronPDFは、他のライブラリで一般的に問題を引き起こす複雑なPDF構造、フォームデータ、およびエンコーディングを自動的に処理します。 PDF ドキュメントから抽出されたデータは、テキスト ファイルに保存したり、さらに処理して分析したりすることができます。
実用的なヒント: 抽出したテキストを.txtファイルに保存して後で処理することができ、データベース、Excelシート、または知識ベースを作成するために解析できます。 この方法は、レポート、契約書、または未処理のテキストがすぐに必要なPDFに適しています。 より高度な抽出シナリオについては、包括的な解析ガイドをご覧ください。
特定の PDF ページからデータを抽出するにはどうすればよいですか?
すべてを抽出するのではなく、特定のページをターゲットにするのはなぜですか?
実世界のアプリケーションでは、正確なデータ抽出が必要です。 IronPDF は、特定のページから貴重な情報をターゲットにする複数の方法を提供します。 この例では、次のPDFを使用します。
using IronPdf;
// Load PDF from a memory stream if needed
byte[] pdfBytes = File.ReadAllBytes("report.pdf");
var pdfFromStream = PdfDocument.FromBytes(pdfBytes);
// Or load from a URL
var pdfFromUrl = PdfDocument.FromUrl("___PROTECTED_URL_32___");using IronPdf;
// Load PDF from a memory stream if needed
byte[] pdfBytes = File.ReadAllBytes("report.pdf");
var pdfFromStream = PdfDocument.FromBytes(pdfBytes);
// Or load from a URL
var pdfFromUrl = PdfDocument.FromUrl("___PROTECTED_URL_32___");Imports IronPdf
' Load PDF from a memory stream if needed
Dim pdfBytes As Byte() = File.ReadAllBytes("report.pdf")
Dim pdfFromStream As PdfDocument = PdfDocument.FromBytes(pdfBytes)
' Or load from a URL
Dim pdfFromUrl As PdfDocument = PdfDocument.FromUrl("___PROTECTED_URL_32___")抽出されたテキスト内の重要な情報を検索するにはどうすればよいですか?
次のコードは、特定のページからデータを抽出し、結果をコンソールに返します。 この手法は、複数ページの PDFを扱う場合や、処理のためにPDF を分割する必要がある場合に特に便利です。
using IronPdf;
using System;
using System.Text.RegularExpressions;
// Load any PDF document
var pdf = PdfDocument.FromFile("AnnualReport2024.pdf");
// Extract from selected pages
int[] pagesToExtract = { 0, 2, 4 }; // Pages 1, 3, and 5
foreach (var pageIndex in pagesToExtract)
{
string pageText = pdf.ExtractTextFromPage(pageIndex);
// Split on 2 or more spaces (tables often flatten into space-separated values)
var tokens = Regex.Split(pageText, @"\s{2,}");
foreach (string token in tokens)
{
// Match totals, invoice headers, and invoice rows
if (token.Contains("Invoice") || token.Contains("Total") || token.StartsWith("INV-"))
{
Console.WriteLine($"Important: {token.Trim()}");
}
}
}using IronPdf;
using System;
using System.Text.RegularExpressions;
// Load any PDF document
var pdf = PdfDocument.FromFile("AnnualReport2024.pdf");
// Extract from selected pages
int[] pagesToExtract = { 0, 2, 4 }; // Pages 1, 3, and 5
foreach (var pageIndex in pagesToExtract)
{
string pageText = pdf.ExtractTextFromPage(pageIndex);
// Split on 2 or more spaces (tables often flatten into space-separated values)
var tokens = Regex.Split(pageText, @"\s{2,}");
foreach (string token in tokens)
{
// Match totals, invoice headers, and invoice rows
if (token.Contains("Invoice") || token.Contains("Total") || token.StartsWith("INV-"))
{
Console.WriteLine($"Important: {token.Trim()}");
}
}
}Imports IronPdf
Imports System
Imports System.Text.RegularExpressions
' Load any PDF document
Dim pdf = PdfDocument.FromFile("AnnualReport2024.pdf")
' Extract from selected pages
Dim pagesToExtract As Integer() = {0, 2, 4} ' Pages 1, 3, and 5
For Each pageIndex In pagesToExtract
Dim pageText As String = pdf.ExtractTextFromPage(pageIndex)
' Split on 2 or more spaces (tables often flatten into space-separated values)
Dim tokens = Regex.Split(pageText, "\s{2,}")
For Each token As String In tokens
' Match totals, invoice headers, and invoice rows
If token.Contains("Invoice") OrElse token.Contains("Total") OrElse token.StartsWith("INV-") Then
Console.WriteLine($"Important: {token.Trim()}")
End If
Next
Nextこの例では、PDF ドキュメントからテキストを抽出し、重要な情報を検索し、保存用に準備する方法を示します。 ExtractTextFromPage() メソッドはドキュメントの読み取り順序を維持し、ドキュメント分析やコンテンツインデックス作成のタスクに最適です。 高度なテキスト操作では、PDF 内のテキストの検索や置換も可能です。
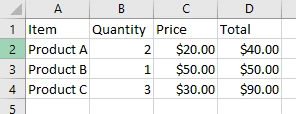
PDF ドキュメントから表データを抽出するにはどうすればよいですか?
表の抽出は通常のテキストとなぜ異なるのでしょうか?
PDFファイル内の表はネイティブな構造を持っていません。 それらは単に表のように見えるように配置されたテキストコンテンツです。 IronPDFはレイアウトを維持しながら表データを抽出し、Excelまたはテキストファイルに加工できます。 PDF 内の画像が関係するより複雑なシナリオでは、画像を個別に抽出する必要がある場合があります。
抽出したテーブルを CSV 形式に変換するにはどうすればよいですか?
using IronPdf;
using System.Text;
using System.Text.RegularExpressions;
using System.IO;
var pdf = PdfDocument.FromFile("example.pdf");
string rawText = pdf.ExtractAllText();
// Split into lines for processing
string[] lines = rawText.Split('\n');
var csvBuilder = new StringBuilder();
foreach (string line in lines)
{
if (string.IsNullOrWhiteSpace(line) || line.Contains("Page"))
continue;
string[] rawCells = Regex.Split(line.Trim(), @"\s+");
string[] cells;
// If the line starts with "Product", combine first two tokens as product name
if (rawCells[0].StartsWith("Product") && rawCells.Length >= 5)
{
cells = new string[rawCells.Length - 1];
cells[0] = rawCells[0] + " " + rawCells[1]; // Combine Product + letter
Array.Copy(rawCells, 2, cells, 1, rawCells.Length - 2);
}
else
{
cells = rawCells;
}
// Keep header or table rows
bool isTableOrHeader = cells.Length >= 2
&& (cells[0].StartsWith("Item") || cells[0].StartsWith("Product")
|| Regex.IsMatch(cells[0], @"^INV-\d+"));
if (isTableOrHeader)
{
Console.WriteLine($"Row: {string.Join("|", cells)}");
string csvRow = string.Join(",", cells).Trim();
csvBuilder.AppendLine(csvRow);
}
}
// Save as CSV for Excel import
File.WriteAllText("extracted_table.csv", csvBuilder.ToString());
Console.WriteLine("Table data exported to CSV");using IronPdf;
using System.Text;
using System.Text.RegularExpressions;
using System.IO;
var pdf = PdfDocument.FromFile("example.pdf");
string rawText = pdf.ExtractAllText();
// Split into lines for processing
string[] lines = rawText.Split('\n');
var csvBuilder = new StringBuilder();
foreach (string line in lines)
{
if (string.IsNullOrWhiteSpace(line) || line.Contains("Page"))
continue;
string[] rawCells = Regex.Split(line.Trim(), @"\s+");
string[] cells;
// If the line starts with "Product", combine first two tokens as product name
if (rawCells[0].StartsWith("Product") && rawCells.Length >= 5)
{
cells = new string[rawCells.Length - 1];
cells[0] = rawCells[0] + " " + rawCells[1]; // Combine Product + letter
Array.Copy(rawCells, 2, cells, 1, rawCells.Length - 2);
}
else
{
cells = rawCells;
}
// Keep header or table rows
bool isTableOrHeader = cells.Length >= 2
&& (cells[0].StartsWith("Item") || cells[0].StartsWith("Product")
|| Regex.IsMatch(cells[0], @"^INV-\d+"));
if (isTableOrHeader)
{
Console.WriteLine($"Row: {string.Join("|", cells)}");
string csvRow = string.Join(",", cells).Trim();
csvBuilder.AppendLine(csvRow);
}
}
// Save as CSV for Excel import
File.WriteAllText("extracted_table.csv", csvBuilder.ToString());
Console.WriteLine("Table data exported to CSV");Imports IronPdf
Imports System.Text
Imports System.Text.RegularExpressions
Imports System.IO
Dim pdf = PdfDocument.FromFile("example.pdf")
Dim rawText As String = pdf.ExtractAllText()
' Split into lines for processing
Dim lines() As String = rawText.Split(ControlChars.Lf)
Dim csvBuilder As New StringBuilder()
For Each line As String In lines
If String.IsNullOrWhiteSpace(line) OrElse line.Contains("Page") Then
Continue For
End If
Dim rawCells() As String = Regex.Split(line.Trim(), "\s+")
Dim cells() As String
' If the line starts with "Product", combine first two tokens as product name
If rawCells(0).StartsWith("Product") AndAlso rawCells.Length >= 5 Then
cells = New String(rawCells.Length - 2) {}
cells(0) = rawCells(0) & " " & rawCells(1) ' Combine Product + letter
Array.Copy(rawCells, 2, cells, 1, rawCells.Length - 2)
Else
cells = rawCells
End If
' Keep header or table rows
Dim isTableOrHeader As Boolean = cells.Length >= 2 AndAlso (cells(0).StartsWith("Item") OrElse cells(0).StartsWith("Product") OrElse Regex.IsMatch(cells(0), "^INV-\d+"))
If isTableOrHeader Then
Console.WriteLine($"Row: {String.Join("|", cells)}")
Dim csvRow As String = String.Join(",", cells).Trim()
csvBuilder.AppendLine(csvRow)
End If
Next
' Save as CSV for Excel import
File.WriteAllText("extracted_table.csv", csvBuilder.ToString())
Console.WriteLine("Table data exported to CSV")複雑なテーブルを抽出するときによくある問題は何ですか?
PDF内の表は、通常、グリッドのように見えるように配置されたテキストに過ぎません。 この確認は、行が表の行またはヘッダーに属しているかどうかを判断するのに役立ちます。 ヘッダー、フッター、関連のないテキストを除外することで、PDF からクリーンな表形式のデータを抽出し、CSV または Excel に出力できるようになります。
このワークフローは、PDF フォーム、財務文書、レポートに有効です。 抽出したデータは、後でxlsxファイルに変換したり、zipファイルに結合したりできます。結合されたセルを含む複雑な表の場合は、列の位置に基づいて解析ロジックを調整する必要があるかもしれません。 スキャンした PDFを操作する場合は、まずテキスト認識にIronOCRを使用することを検討してください。
PDF からフォーム フィールド データを抽出するにはどうすればよいですか?
フォーム フィールドをプログラムで抽出および変更する理由
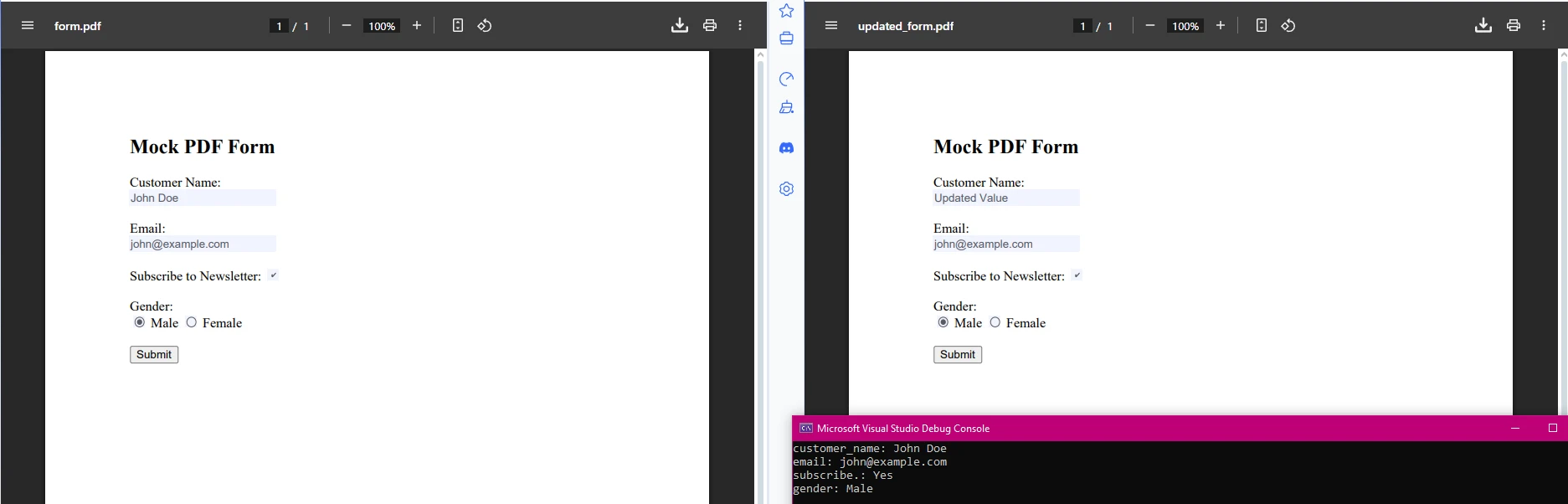
IronPDF、フォーム フィールドのデータの抽出と変更も可能になります。 これは、自動処理が必要な入力可能な PDF フォームを扱う場合に特に便利です。
using IronPdf;
using System.Drawing;
using System.Linq;
var pdf = PdfDocument.FromFile("form_document.pdf");
// Extract form field data
var form = pdf.Form;
foreach (var field in form) // Removed '.Fields' as 'FormFieldCollection' is enumerable
{
Console.WriteLine($"{field.Name}: {field.Value}");
// Update form values if needed
if (field.Name == "customer_name")
{
field.Value = "Updated Value";
}
}
// Save modified form
pdf.SaveAs("updated_form.pdf");using IronPdf;
using System.Drawing;
using System.Linq;
var pdf = PdfDocument.FromFile("form_document.pdf");
// Extract form field data
var form = pdf.Form;
foreach (var field in form) // Removed '.Fields' as 'FormFieldCollection' is enumerable
{
Console.WriteLine($"{field.Name}: {field.Value}");
// Update form values if needed
if (field.Name == "customer_name")
{
field.Value = "Updated Value";
}
}
// Save modified form
pdf.SaveAs("updated_form.pdf");Imports IronPdf
Imports System.Drawing
Imports System.Linq
Dim pdf = PdfDocument.FromFile("form_document.pdf")
' Extract form field data
Dim form = pdf.Form
For Each field In form ' Removed '.Fields' as 'FormFieldCollection' is enumerable
Console.WriteLine($"{field.Name}: {field.Value}")
' Update form values if needed
If field.Name = "customer_name" Then
field.Value = "Updated Value"
End If
Next
' Save modified form
pdf.SaveAs("updated_form.pdf")より高度なフォーム処理のために、特定のフィールド タイプを操作することもできます。
// Work with different form field types
foreach (var field in pdf.Form)
{
switch (field)
{
case TextFormField textField:
Console.WriteLine($"Text field '{field.Name}': {textField.Value}");
break;
case CheckBoxFormField checkBox:
Console.WriteLine($"Checkbox '{field.Name}': {checkBox.Value}");
checkBox.Value = true; // Check the box
break;
case ComboBoxFormField comboBox:
Console.WriteLine($"ComboBox '{field.Name}': {comboBox.Value}");
// Set to first available option
if (comboBox.Choices.Any())
comboBox.Value = comboBox.Choices.First();
break;
}
}// Work with different form field types
foreach (var field in pdf.Form)
{
switch (field)
{
case TextFormField textField:
Console.WriteLine($"Text field '{field.Name}': {textField.Value}");
break;
case CheckBoxFormField checkBox:
Console.WriteLine($"Checkbox '{field.Name}': {checkBox.Value}");
checkBox.Value = true; // Check the box
break;
case ComboBoxFormField comboBox:
Console.WriteLine($"ComboBox '{field.Name}': {comboBox.Value}");
// Set to first available option
if (comboBox.Choices.Any())
comboBox.Value = comboBox.Choices.First();
break;
}
}' Work with different form field types
For Each field In pdf.Form
Select Case field
Case textField As TextFormField
Console.WriteLine($"Text field '{field.Name}': {textField.Value}")
Case checkBox As CheckBoxFormField
Console.WriteLine($"Checkbox '{field.Name}': {checkBox.Value}")
checkBox.Value = True ' Check the box
Case comboBox As ComboBoxFormField
Console.WriteLine($"ComboBox '{field.Name}': {comboBox.Value}")
' Set to first available option
If comboBox.Choices.Any() Then
comboBox.Value = comboBox.Choices.First()
End If
End Select
Nextフォーム フィールド抽出はいつ使用すればよいですか?
このスニペットは、PDFからフォームフィールドの値を抽出し、それをプログラムで更新できるようにします。 これにより、PDF フォームを処理し、分析やレポート生成のために特定の情報を抽出することが容易になります。 これは、顧客オンボーディング、アンケート処理、データ検証などのワークフローの自動化に役立ちます。
一般的な使用例には次のようなものがあります:
- デジタル署名の自動化
- パスワードで保護されたPDFの処理
- PDF/A準拠のためのデータの抽出
- カスタムワークフローの構築
次のステップは何ですか?
IronPDFは、.NETでのPDFデータ抽出を実用的かつ効率的にします。 通常は追加の OCR 処理を必要とするスキャンされた PDF を含む、さまざまな PDF ドキュメントからテキスト、表、フォーム フィールド、画像、添付ファイルを抽出できます。
知識ベースの構築、レポートワークフローの自動化、または財務PDFからのデータ抽出を目指す場合でも、このライブラリがあれば手作業のコピーやエラーのある解析を避けて目標を達成できます。 シンプルで高速であり、Visual Studio プロジェクトに直接統合されます。 ぜひお試しください。 おそらく多くの時間を節約でき、PDF を扱う際によくある面倒な作業を回避できるでしょう。
より高度なシナリオについては、以下を参照してください。
PDFデータ抽出をアプリケーションに実装する準備はできていますか? IronPDFは、あなたにとって.NETライブラリでしょうか? 無料トライアルを開始して商業利用してください。 包括的なガイドとAPI リファレンスについては、ドキュメントをご覧ください。
よくある質問
.NETを使用してPDFドキュメントからテキストを抽出する最適な方法は何ですか?
IronPDFを使用することで、.NETアプリケーションでPDFドキュメントからテキストを簡単に抽出できます。必要な内容にアクセスできるようにテキストデータを効率的に取得する方法を提供しています。
IronPDFはスキャンされたPDFのデータ抽出を処理できますか?
はい、IronPDFはスキャンされたPDFを処理し、OCR(光学文字認識)を使用してデータを抽出することができます。これにより、画像ベースのドキュメント内のテキストにもアクセス可能です。
C#を使用してPDFからテーブルを抽出する方法は?
IronPDFは、C#でPDFドキュメントからテーブルを解析し抽出する機能を提供しています。特定のメソッドを使用して、テーブルデータを正確に識別し取得することができます。
PDFデータ抽出にIronPDFを使用する利点は何ですか?
IronPDFは、テキストの取得、テーブル解析、スキャンされたドキュメントのOCRを含むPDFデータ抽出の包括的なソリューションを提供します。これは.NETアプリケーションとシームレスに統合され、PDFデータを処理する際に信頼性のある効率的な方法を提供します。
IronPDFを使用してPDFから画像を抽出することは可能ですか?
はい、IronPDFを使用すればPDFから画像を抽出することができます。この機能は、PDFドキュメント内に埋め込まれた画像にアクセスし操作する必要がある場合に便利です。
データ抽出中にIronPDFは複雑なPDFレイアウトをどのように処理しますか?
IronPDFは、複雑なPDFレイアウトをナビゲートしてデータを抽出するための強力なツールを提供し、複雑なフォーマットと構造を持つドキュメントを処理できるように設計されています。
.NETアプリケーションでPDFデータ抽出を自動化できますか?
もちろんです。IronPDFは.NETアプリケーションに統合してPDFデータ抽出を自動化でき、定期的で一貫したデータ取得が求められるプロセスを効率化します。
PDFデータ抽出にIronPDFを使用する際のプログラミング言語は何ですか?
IronPDFは主に.NETフレームワークでのC#と共に使用されており、プログラムでPDFからデータを抽出しようとする開発者に広範なサポートと機能を提供しています。
IronPDFはPDFドキュメントのメタデータ抽出をサポートしていますか?
はい、IronPDFはPDFドキュメントのメタデータを抽出することができ、著者、作成日、その他の文書プロパティにアクセスすることが可能です。
IronPDFを使用したPDFデータ抽出学習のためのサンプルコードは何ですか?
開発者ガイドには、PDFデータ抽出をIronPDFを用いて.NETアプリケーションで習得するために役立つ動作するコード例を含む完全なC#チュートリアルが提供されています。
IronPDF は新しい .NET 10 リリースと完全に互換性がありますか? また、データ抽出にどのような利点がありますか?
はい。IronPDFは.NET 10と完全に互換性があり、ヒープ割り当ての削減、配列インターフェースの仮想化解除、言語機能の強化など、パフォーマンス、API、ランタイムの改善をすべてサポートしています。これらの改善により、C#アプリケーションにおけるPDFデータ抽出ワークフローの高速化と効率化が実現します。