
PDF vs PDFA (Geliştiriciler İçin Nasıl Çalışır)
.NET'te PDF'ten Veri Çıkarma Nasıl Yapılır
IronPDF, yalnızca birkaç satır kodla .NET'teki PDF belgelerinden metin, tablo, form alanları ve ekleri çıkarmayı kolaylaştırır, bu da fatura işlemlerini otomatikleştirme, bilgi tabanları oluşturma veya karmaşık ayrıştırma olmadan raporlar oluşturmak için idealdir.
PDF belgeleri iş dünyasında her yerdedir; modern örnekler arasında faturalar, raporlar, sözleşmeler ve kılavuzlar bulunur. Ancak hayati bilgileri programlı olarak onlardan almak zor olabilir. PDF'ler, şeylerin nasıl göründüğüne odaklanır, verilerin nasıl erişileceğine değil.
.NET geliştiricileri için IronPDF, PDF dosyalarından veri çıkarmayı kolaylaştıran güçlü bir .NET PDF kütüphanesidir. PDF belgelerinden doğrudan metin, tablo, form alanları, görseller ve ekler çekebilirsiniz. İster fatura süreçlerini otomatikleştiriyor, ister bir bilgi tabanı oluşturuyor veya raporlar üretiyor olun, bu kütüphane çok fazla zaman kazandırır.
Bu kılavuz, kod parçacıklarının her biri sonrasında açıklamalarla birlikte metinsel içerik, tablo verileri ve form alanı değerlerini çıkarmanın pratik örneklerini sağlayacak, böylece bunları kendi projelerinize uyarlayabilirsiniz.
IronPDF ile Çalışmaya Nasıl Başlarım?
Neden Yükleme Bu Kadar Hızlı?
IronPDF, NuGet Paket Yöneticisi aracılığıyla saniyeler içinde yüklenir. Paket Yöneticisi Konsolu'nu açın ve şunu çalıştırın:
Install-Package IronPdf
Windows geliştiricileri için kurulum basittir. Eğer Linux veya macOS platformlarına dağıtım yapıyorsanız, IronPDF bu platformları da destekler. IronPDF'i Docker konteynerlerinde çalıştırabilir veya Azure ve AWS platformlarına dağıtabilirsiniz.
Metin Çıkarmanın En Basit Yolu Nedir?
Yüklendikten sonra, PDF belgelerini işlemeye hemen başlayabilirsiniz. IronPDF'ün API'sinin en basit bir .NET örneği burada gösterilmektedir:
using IronPdf;
// Load any PDF document
var pdf = PdfDocument.FromFile("document.pdf");
// Extract all text with one line
string allText = pdf.ExtractAllText();
Console.WriteLine(allText);using IronPdf;
// Load any PDF document
var pdf = PdfDocument.FromFile("document.pdf");
// Extract all text with one line
string allText = pdf.ExtractAllText();
Console.WriteLine(allText);Imports IronPdf
' Load any PDF document
Dim pdf = PdfDocument.FromFile("document.pdf")
' Extract all text with one line
Dim allText As String = pdf.ExtractAllText()
Console.WriteLine(allText)Bu kod, bir PDF'yi yükler ve her metin parçasını çıkarır. IronPDF, tipik olarak diğer kütüphanelerde sorunlara neden olan karmaşık PDF yapıları, form verisi ve kodlamaları otomatik olarak yönetir. PDF belgelerinden çıkarılan veriler bir metin dosyasına kaydedilebilir veya analiz için daha fazla işleme tabi tutulabilir.
Pratik ipucu: Çıkarılan metni işlem için daha sonra kullanılmak üzere bir .txt dosyasına kaydedebilir veya veritabanlarını, Excel tablolarını veya bilgi tabanlarını doldurmak için ayrıştırabilirsiniz. Bu yöntem, raporlar, sözleşmeler veya sadece ham metne hızlıca ihtiyacınız olduğu herhangi bir PDF için iyi çalışır. Daha karmaşık çıkarma senaryoları için kapsamlı ayrıştırma rehberine göz atın.
Belirli PDF Sayfalarından Veri Nasıl Çıkarılır?
Her Şeyi Çıkarmak Yerine Neden Belirli Sayfaları Hedefliyorsunuz?
Gerçek dünya uygulamaları genellikle kesin veri çıkarımı gerektirir. IronPDF, belirli sayfalardan değerli bilgileri hedeflemek için birden fazla yöntem sunar. Bu örnek için, aşağıdaki PDF'yi kullanacağız:
using IronPdf;
// Load PDF from a memory stream if needed
byte[] pdfBytes = File.ReadAllBytes("report.pdf");
var pdfFromStream = PdfDocument.FromBytes(pdfBytes);
// Or load from a URL
var pdfFromUrl = PdfDocument.FromUrl("___PROTECTED_URL_32___");using IronPdf;
// Load PDF from a memory stream if needed
byte[] pdfBytes = File.ReadAllBytes("report.pdf");
var pdfFromStream = PdfDocument.FromBytes(pdfBytes);
// Or load from a URL
var pdfFromUrl = PdfDocument.FromUrl("___PROTECTED_URL_32___");Imports IronPdf
' Load PDF from a memory stream if needed
Dim pdfBytes As Byte() = File.ReadAllBytes("report.pdf")
Dim pdfFromStream As PdfDocument = PdfDocument.FromBytes(pdfBytes)
' Or load from a URL
Dim pdfFromUrl As PdfDocument = PdfDocument.FromUrl("___PROTECTED_URL_32___")Çıkarılan Metindeki Öne Çıkan Bilgileri Nasıl Ararım?
Aşağıdaki kod, belirli sayfalardan veri çıkarır ve sonuçları konsola döndürür. Bu teknik, çok sayfalı PDF'ler ile çalışırken veya işlem için PDF'leri bölmek gerektiğinde özellikle yararlıdır:
using IronPdf;
using System;
using System.Text.RegularExpressions;
// Load any PDF document
var pdf = PdfDocument.FromFile("AnnualReport2024.pdf");
// Extract from selected pages
int[] pagesToExtract = { 0, 2, 4 }; // Pages 1, 3, and 5
foreach (var pageIndex in pagesToExtract)
{
string pageText = pdf.ExtractTextFromPage(pageIndex);
// Split on 2 or more spaces (tables often flatten into space-separated values)
var tokens = Regex.Split(pageText, @"\s{2,}");
foreach (string token in tokens)
{
// Match totals, invoice headers, and invoice rows
if (token.Contains("Invoice") || token.Contains("Total") || token.StartsWith("INV-"))
{
Console.WriteLine($"Important: {token.Trim()}");
}
}
}using IronPdf;
using System;
using System.Text.RegularExpressions;
// Load any PDF document
var pdf = PdfDocument.FromFile("AnnualReport2024.pdf");
// Extract from selected pages
int[] pagesToExtract = { 0, 2, 4 }; // Pages 1, 3, and 5
foreach (var pageIndex in pagesToExtract)
{
string pageText = pdf.ExtractTextFromPage(pageIndex);
// Split on 2 or more spaces (tables often flatten into space-separated values)
var tokens = Regex.Split(pageText, @"\s{2,}");
foreach (string token in tokens)
{
// Match totals, invoice headers, and invoice rows
if (token.Contains("Invoice") || token.Contains("Total") || token.StartsWith("INV-"))
{
Console.WriteLine($"Important: {token.Trim()}");
}
}
}Imports IronPdf
Imports System
Imports System.Text.RegularExpressions
' Load any PDF document
Dim pdf = PdfDocument.FromFile("AnnualReport2024.pdf")
' Extract from selected pages
Dim pagesToExtract As Integer() = {0, 2, 4} ' Pages 1, 3, and 5
For Each pageIndex In pagesToExtract
Dim pageText As String = pdf.ExtractTextFromPage(pageIndex)
' Split on 2 or more spaces (tables often flatten into space-separated values)
Dim tokens = Regex.Split(pageText, "\s{2,}")
For Each token As String In tokens
' Match totals, invoice headers, and invoice rows
If token.Contains("Invoice") OrElse token.Contains("Total") OrElse token.StartsWith("INV-") Then
Console.WriteLine($"Important: {token.Trim()}")
End If
Next
NextBu örnek, PDF belgelerinden metin çıkarmayı, önemli bilgileri aramayı ve depolama için hazırlamayı gösterir. ExtractTextFromPage() yöntemi, belgenin okuma sırasını korur, bu da belge analizi ve içerik indeksleme görevleri için mükemmeldir. Gelişmiş metin manipülasyonu için, PDF'ler içinde metin arama ve değiştirme yapabilirsiniz.
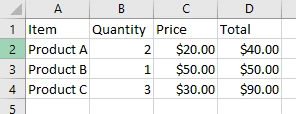
PDF Belgelerinden Tablo Verileri Nasıl Çıkarılır?
Tablo Çıkarma Neden Düz Metinden Farklıdır?
PDF dosyalarındaki tabloların yerel bir yapısı yoktur; sadece tablo gibi görünmesi için konumlandırılmış metinsel içerik. IronPDF, tablosal verileri düzeni koruyarak çıkarır, böylece Excel veya metin dosyalarına işleyebilirsiniz. PDF'lerdeki görüntüleri içeren daha karmaşık senaryolar için, PDF'lere görüntüler eklemeniz veya bunları ayrıca çıkarmanız gerekebilir.
Çıkarılan Tabloları CSV Formatına Nasıl Dönüştürürüm?
using IronPdf;
using System.Text;
using System.Text.RegularExpressions;
using System.IO;
var pdf = PdfDocument.FromFile("example.pdf");
string rawText = pdf.ExtractAllText();
// Split into lines for processing
string[] lines = rawText.Split('\n');
var csvBuilder = new StringBuilder();
foreach (string line in lines)
{
if (string.IsNullOrWhiteSpace(line) || line.Contains("Page"))
continue;
string[] rawCells = Regex.Split(line.Trim(), @"\s+");
string[] cells;
// If the line starts with "Product", combine first two tokens as product name
if (rawCells[0].StartsWith("Product") && rawCells.Length >= 5)
{
cells = new string[rawCells.Length - 1];
cells[0] = rawCells[0] + " " + rawCells[1]; // Combine Product + letter
Array.Copy(rawCells, 2, cells, 1, rawCells.Length - 2);
}
else
{
cells = rawCells;
}
// Keep header or table rows
bool isTableOrHeader = cells.Length >= 2
&& (cells[0].StartsWith("Item") || cells[0].StartsWith("Product")
|| Regex.IsMatch(cells[0], @"^INV-\d+"));
if (isTableOrHeader)
{
Console.WriteLine($"Row: {string.Join("|", cells)}");
string csvRow = string.Join(",", cells).Trim();
csvBuilder.AppendLine(csvRow);
}
}
// Save as CSV for Excel import
File.WriteAllText("extracted_table.csv", csvBuilder.ToString());
Console.WriteLine("Table data exported to CSV");using IronPdf;
using System.Text;
using System.Text.RegularExpressions;
using System.IO;
var pdf = PdfDocument.FromFile("example.pdf");
string rawText = pdf.ExtractAllText();
// Split into lines for processing
string[] lines = rawText.Split('\n');
var csvBuilder = new StringBuilder();
foreach (string line in lines)
{
if (string.IsNullOrWhiteSpace(line) || line.Contains("Page"))
continue;
string[] rawCells = Regex.Split(line.Trim(), @"\s+");
string[] cells;
// If the line starts with "Product", combine first two tokens as product name
if (rawCells[0].StartsWith("Product") && rawCells.Length >= 5)
{
cells = new string[rawCells.Length - 1];
cells[0] = rawCells[0] + " " + rawCells[1]; // Combine Product + letter
Array.Copy(rawCells, 2, cells, 1, rawCells.Length - 2);
}
else
{
cells = rawCells;
}
// Keep header or table rows
bool isTableOrHeader = cells.Length >= 2
&& (cells[0].StartsWith("Item") || cells[0].StartsWith("Product")
|| Regex.IsMatch(cells[0], @"^INV-\d+"));
if (isTableOrHeader)
{
Console.WriteLine($"Row: {string.Join("|", cells)}");
string csvRow = string.Join(",", cells).Trim();
csvBuilder.AppendLine(csvRow);
}
}
// Save as CSV for Excel import
File.WriteAllText("extracted_table.csv", csvBuilder.ToString());
Console.WriteLine("Table data exported to CSV");Imports IronPdf
Imports System.Text
Imports System.Text.RegularExpressions
Imports System.IO
Dim pdf = PdfDocument.FromFile("example.pdf")
Dim rawText As String = pdf.ExtractAllText()
' Split into lines for processing
Dim lines() As String = rawText.Split(ControlChars.Lf)
Dim csvBuilder As New StringBuilder()
For Each line As String In lines
If String.IsNullOrWhiteSpace(line) OrElse line.Contains("Page") Then
Continue For
End If
Dim rawCells() As String = Regex.Split(line.Trim(), "\s+")
Dim cells() As String
' If the line starts with "Product", combine first two tokens as product name
If rawCells(0).StartsWith("Product") AndAlso rawCells.Length >= 5 Then
cells = New String(rawCells.Length - 2) {}
cells(0) = rawCells(0) & " " & rawCells(1) ' Combine Product + letter
Array.Copy(rawCells, 2, cells, 1, rawCells.Length - 2)
Else
cells = rawCells
End If
' Keep header or table rows
Dim isTableOrHeader As Boolean = cells.Length >= 2 AndAlso (cells(0).StartsWith("Item") OrElse cells(0).StartsWith("Product") OrElse Regex.IsMatch(cells(0), "^INV-\d+"))
If isTableOrHeader Then
Console.WriteLine($"Row: {String.Join("|", cells)}")
Dim csvRow As String = String.Join(",", cells).Trim()
csvBuilder.AppendLine(csvRow)
End If
Next
' Save as CSV for Excel import
File.WriteAllText("extracted_table.csv", csvBuilder.ToString())
Console.WriteLine("Table data exported to CSV")Karmaşık Tabloları Çıkarmada Yaygın Sorunlar Nelerdir?
PDF'lerdeki tablolar genellikle bir grid gibi görünmeleri için konumlandırılmış metindir. Bu kontrol, bir satırın tablo satırına mı yoksa başlığa mı ait olduğunu belirlemeye yardımcı olur. Başlıkları, altbilgileri ve ilgisiz metni filtreleyerek, temiz tablosal verileri bir PDF'den çıkartabilir, CSV veya Excel için hazır hale getirebilirsiniz.
Bu iş akışı, PDF formları, finansal belgeler ve raporlar için çalışır. Çıkarılan verileri daha sonra xlsx dosyalarına dönüştürebilir veya bir zip dosyasına birleştirebilirsiniz. Birleştirilmiş hücrelere sahip karmaşık tablolar için, sütun pozisyonlarına dayalı olarak ayrıştırma mantığını ayarlamanız gerekebilir. Taranmış PDF'ler ile çalışırken, öncelikle metin tanıma için IronOCR kullanmayı düşünün.
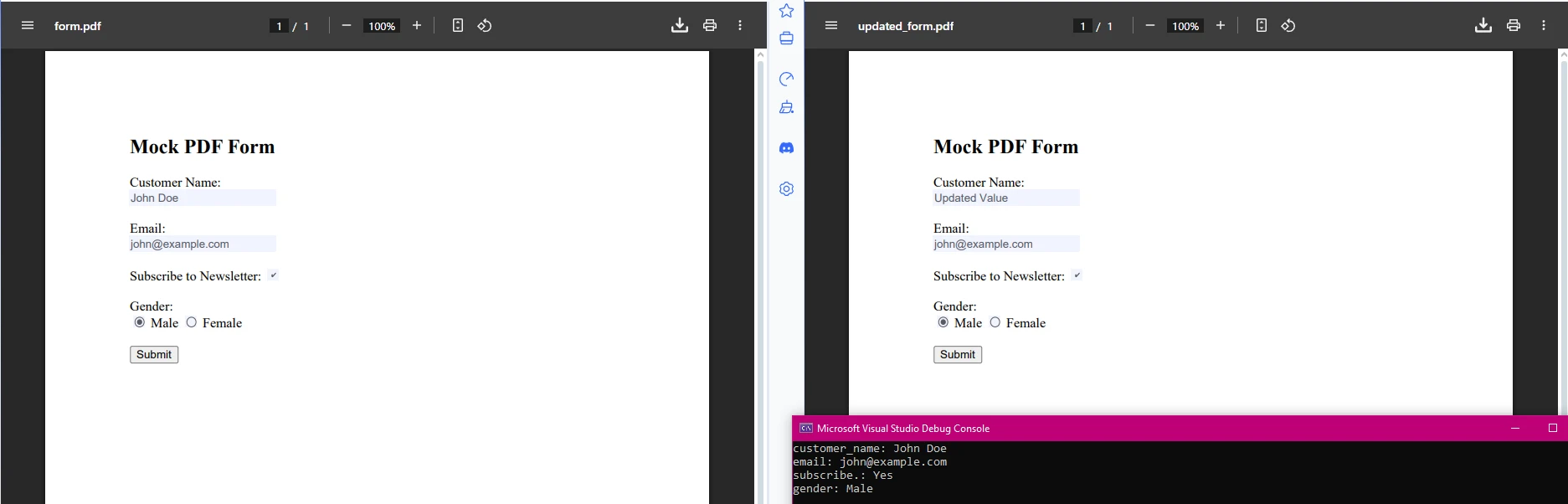
PDF'lerden Form Alanı Verileri Nasıl Çıkarılır?
Neden Form Alanlarını Programlı Olarak Çıkarmalı ve Değiştirmelisiniz?
IronPDF ayrıca form alanı verilerini çıkarma ve değiştirme özelliği sağlar. Bu, özellikle otomatik işlemesi gereken doldurulabilir PDF formları ile uğraşırken yararlıdır:
using IronPdf;
using System.Drawing;
using System.Linq;
var pdf = PdfDocument.FromFile("form_document.pdf");
// Extract form field data
var form = pdf.Form;
foreach (var field in form) // Removed '.Fields' as 'FormFieldCollection' is enumerable
{
Console.WriteLine($"{field.Name}: {field.Value}");
// Update form values if needed
if (field.Name == "customer_name")
{
field.Value = "Updated Value";
}
}
// Save modified form
pdf.SaveAs("updated_form.pdf");using IronPdf;
using System.Drawing;
using System.Linq;
var pdf = PdfDocument.FromFile("form_document.pdf");
// Extract form field data
var form = pdf.Form;
foreach (var field in form) // Removed '.Fields' as 'FormFieldCollection' is enumerable
{
Console.WriteLine($"{field.Name}: {field.Value}");
// Update form values if needed
if (field.Name == "customer_name")
{
field.Value = "Updated Value";
}
}
// Save modified form
pdf.SaveAs("updated_form.pdf");Imports IronPdf
Imports System.Drawing
Imports System.Linq
Dim pdf = PdfDocument.FromFile("form_document.pdf")
' Extract form field data
Dim form = pdf.Form
For Each field In form ' Removed '.Fields' as 'FormFieldCollection' is enumerable
Console.WriteLine($"{field.Name}: {field.Value}")
' Update form values if needed
If field.Name = "customer_name" Then
field.Value = "Updated Value"
End If
Next
' Save modified form
pdf.SaveAs("updated_form.pdf")Daha gelişmiş form işleme için, belirli alan türleriyle de çalışabilirsiniz:
// Work with different form field types
foreach (var field in pdf.Form)
{
switch (field)
{
case TextFormField textField:
Console.WriteLine($"Text field '{field.Name}': {textField.Value}");
break;
case CheckBoxFormField checkBox:
Console.WriteLine($"Checkbox '{field.Name}': {checkBox.Value}");
checkBox.Value = true; // Check the box
break;
case ComboBoxFormField comboBox:
Console.WriteLine($"ComboBox '{field.Name}': {comboBox.Value}");
// Set to first available option
if (comboBox.Choices.Any())
comboBox.Value = comboBox.Choices.First();
break;
}
}// Work with different form field types
foreach (var field in pdf.Form)
{
switch (field)
{
case TextFormField textField:
Console.WriteLine($"Text field '{field.Name}': {textField.Value}");
break;
case CheckBoxFormField checkBox:
Console.WriteLine($"Checkbox '{field.Name}': {checkBox.Value}");
checkBox.Value = true; // Check the box
break;
case ComboBoxFormField comboBox:
Console.WriteLine($"ComboBox '{field.Name}': {comboBox.Value}");
// Set to first available option
if (comboBox.Choices.Any())
comboBox.Value = comboBox.Choices.First();
break;
}
}' Work with different form field types
For Each field In pdf.Form
Select Case field
Case textField As TextFormField
Console.WriteLine($"Text field '{field.Name}': {textField.Value}")
Case checkBox As CheckBoxFormField
Console.WriteLine($"Checkbox '{field.Name}': {checkBox.Value}")
checkBox.Value = True ' Check the box
Case comboBox As ComboBoxFormField
Console.WriteLine($"ComboBox '{field.Name}': {comboBox.Value}")
' Set to first available option
If comboBox.Choices.Any() Then
comboBox.Value = comboBox.Choices.First()
End If
End Select
NextForm Alanı Çıkarmayı Ne Zaman Kullanmalıyım?
Bu parçacık, PDF'lerden form alanı değerlerini çıkarır ve programlı olarak güncellenmelerine olanak tanır. Bu, PDF formlarını işlemeyi ve analiz veya rapor oluşturma için özel bilgi parçalarını çıkarmayı kolaylaştırır. Bu, müşteri girişini otomatize etme, anket işleme veya veri doğrulama gibi iş akışlarını otomatize etmeye yararlıdır.
Yaygın kullanım alanları şunlardır:
- Dijital imzaları otomatikleştirme
- Şifre korumalı PDF'leri işleme
- PDF/A uyumluluğu için veri çıkarma
- Özel iş akışları oluşturma
Sonraki Adımlarım Neler?
IronPDF, .NET'te PDF veri çıkarımını pratik ve verimli bir hale getirir. Çeşitli PDF belgelerinden, genellikle ek OCR işleme gerektiren taranmış PDF'ler de dahil olmak üzere metin, tablo, form alanları, görseller ve ekler çıkarabilirsiniz.
Hedefiniz ister bir bilgi tabanı oluşturmak, ister raporlama iş akışlarını otomatikleştirmek veya finansal PDF'lerden veri çıkarmak olsun, bu kütüphane işi manuel kopyalama veya hataya açık ayrıştırma olmadan gerektiren araçları sağlar. Basit, hızlı ve Visual Studio projelerine doğrudan entegre olur. Deneyin; muhtemelen çok zaman kazandıracak ve PDF'lerle çalışmanın getirdiği alışılmış baş ağrılarından kaçınacaksınız.
Daha ileri senaryolar için keşfedin:
- PDF'leri görüntülere dönüştürme
- Meta verilerle çalışma
- PDF sıkıştırma
- Yazı tiplerini yönetme
- Erişilebilir PDF'ler oluşturma
Uygulamalarınızda PDF veri çıkarımını uygulamaya hazır mısınız? IronPDF size göre bir .NET kütüphanesi gibi mi görünüyor? Ücretsiz denemenizi başlatın ticari kullanım için. Kapsamlı kılavuzlar ve API referansları için belgelerimizi ziyaret edin.
Sıkça Sorulan Sorular
.NET kullanarak PDF belgelerinden metin çıkartmanın en iyi yolu nedir?
IronPDF'yi kullanarak .NET uygulamalarında PDF belgelerinden metin çıkartabilirsiniz. İhtiyacınız olan içeriğe erişebilmenizi sağlayarak metin verilerini verimli bir şekilde almak için yöntemler sunar.
IronPDF, veri çıkartma için taranmış PDF'leri işleyebilir mi?
Evet, IronPDF, taranmış PDF'lerden veri çıkartmak için OCR (Optik Karakter Tanıma) desteği sunar, bu da görsel tabanlı belgelerde bile metne erişimi mümkün kılar.
C# kullanarak PDF'den tabloları nasıl çıkarırım?
IronPDF, C# içinde PDF belgelerinden tabloları çözümleyip çıkartacak özellikler sağlar. Belirli yöntemleri kullanarak tablo verilerini doğru bir şekilde tanımlayıp alabilirsiniz.
IronPDF'yi PDF veri çıkartma için kullanmanın avantajları nelerdir?
IronPDF, metin alımı, tablo çözümleme ve taranmış belgeler için OCR dahil olmak üzere PDF veri çıkartma için kapsamlı bir çözüm sunar. .NET uygulamalarıyla sorunsuz bir şekilde entegre olarak, PDF verilerini yönetmenin güvenilir ve verimli bir yolunu sağlar.
IronPDF kullanarak bir PDF'den resim çıkartmak mümkün mü?
Evet, IronPDF, PDF'lerden resim çıkartmanıza olanak tanır. Bu özellik, PDF belgelerine gömülü olan resimlere erişmeniz ve bunları manipüle etmeniz gerektiğinde kullanışlıdır.
IronPDF, veri çıkartma sırasında karmaşık PDF düzenlerini nasıl yönetir?
IronPDF, veri çıkartma sırasında karmaşık PDF düzenlerini yönetmek için, belgelerin karmaşık formatlama ve yapısıyla başa çıkabilmenizi sağlayan sağlam araçlar sunarak tasarlanmıştır.
.NET uygulamasında PDF veri çıkartmayı otomatikleştirebilir miyim?
Kesinlikle. IronPDF, PDF veri çıkartmayı otomatikleştirmenin mümkün olduğu .NET uygulamalarına entegre edilebilir, bu da düzenli ve tutarlı veri alımını gerektiren işlemleri düzene sokar.
IronPDF ile PDF veri çıkartma için hangi programlama dilleri kullanılabilir?
IronPDF, .NET framework içindeki C# ile öncelikli olarak kullanılmaktadır, geliştiricilere PDF'lerden verileri programatik olarak çıkartmak için geniş destek ve işlevsellik sunar.
IronPDF, PDF belgelerinden meta verileri çıkartmayı destekliyor mu?
Evet, IronPDF, PDF belgelerinden yazar, oluşturma tarihi ve diğer belge özellikleri gibi bilgileri erişmenize olanak tanıyan meta verileri çıkartabilir.
IronPDF ile PDF veri çıkartma öğrenimi için hangi örnek kodlar mevcut?
Geliştirici kılavuzu, IronPDF kullanarak .NET uygulamalarınızda PDF veri çıkartmayı ustalaşmanıza yardımcı olacak çalışan kod örnekleri ile birlikte kapsamlı C# öğreticileri sağlar.
IronPDF, yeni .NET 10 sürümü ile tam uyumlu mu ve bu, veri çıkartma için ne gibi avantajlar sağlıyor?
Evet — IronPDF, tüm performans, API ve çalışma zamanı geliştirmelerini desteklenerek, bellek yığın tahsisini azaltmak, dizi arayüz yerelleştirmesini devredışı bırakmak ve gelişmiş dil özellikleri gibi faydalar içerir. Bu geliştirmeler, C# uygulamalarında daha hızlı, daha verimli PDF veri çıkartma iş akışlarına yol açar.











