
Jak czytać pliki PDF w Selenium WebDriver C# bez zwykłej złożoności
Dokumenty PDF stanowią wyjątkowe wyzwanie w automatycznym testowaniu: chociaż Selenium WebDriver doskonale radzi sobie z interakcją z elementami stron internetowych, nie potrafi odczytać treści zawartej w pliku PDF, ponieważ plik ten jest renderowany jako strumień binarny, a nie jako elementy DOM. W tym artykule pokazano, jak rozwiązać ten problem w języku C#, łącząc Selenium z IronPDF, gotową do użycia w środowisku produkcyjnym biblioteką PDF dla platformy .NET, która pozwala wyodrębniać, weryfikować i przetwarzać zawartość plików PDF za pomocą zaledwie kilku wierszy kodu — bez konieczności stosowania skomplikowanego zarządzania zależnościami w stylu Javy.
Dlaczego Selenium ma trudności z obsługą treści PDF?
Gdy plik PDF otwiera się w przeglądarce, Selenium może przejść do strony i wchodzić w interakcję z elementami sterującymi przeglądarki, ale nie może wyszukiwać tekstu ani danych wewnątrz dokumentu. Pliki PDF są renderowane jako obiekty osadzone lub wtyczki, a nie jako elementy HTML, które protokół WebDriver może przeglądać. Przeglądarka plików PDF wyświetla dokument wizualnie, ale nie ma dostępnego DOM, który Selenium mogłoby sprawdzić — każde zapytanie XPath lub selektor CSS nie zwraca żadnych wyników.
Tradycyjne rozwiązania wymagają pobrania pliku na dysk, wywołania oddzielnej biblioteki parsującej i ręcznego połączenia wszystkich elementów. Ten wieloetapowy proces zwiększa złożoność, powoduje powstanie niestabilnego kodu testowego i komplikuje procesy CI/CD, w których trudno jest kontrolować ścieżki plików i uprawnienia. IronPDF eliminuje wszystkie te etapy, umożliwiając załadowanie pliku PDF z adresu URL lub lokalnej ścieżki i wyodrębnienie jego tekstu za pomocą jednego wywołania — bezpośrednio w istniejącym projekcie testowym .NET, bez żadnych plików pośrednich ani konfiguracji.
W praktyce oznacza to, że kod testowy staje się krótszy, łatwiejszy do odczytania i znacznie mniej podatny na awarie w przypadku zmiany środowiska testowego. Aby uzyskać szerszy obraz możliwości IronPDF wykraczających poza wyodrębnianie tekstu, odwiedź centrum dokumentacji IronPDF.

Jak zainstalować IronPDF do testowania Selenium?
Zainstalowanie wymaganych pakietów zajmuje mniej niż minutę. Otwórz konsolę menedżera pakietów w Visual Studio i uruchom:
Install-Package IronPdf
dotnet add package IronPdfInstall-Package IronPdf
dotnet add package IronPdfBędziesz również potrzebować pakietów Selenium, jeśli nie ma ich jeszcze w Twoim projekcie:
Install-Package Selenium.WebDriver
Install-Package Selenium.WebDriver.ChromeDriverInstall-Package Selenium.WebDriver
Install-Package Selenium.WebDriver.ChromeDriver
Po zainstalowaniu pakietów dodaj następujące dyrektywy using na początku pliku testowego:
using IronPdf;
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
using System.IO;using IronPdf;
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
using System.IO;Imports IronPdf
Imports OpenQA.Selenium
Imports OpenQA.Selenium.Chrome
Imports System.IOIronPDF jest przeznaczony dla platformy .NET 10 i działa wieloplatformowo w systemach Windows, Linux i macOS, dzięki czemu ten sam kod testowy działa w każdym środowisku — w tym w kontenerach Docker i agentach CI w chmurze.
!{--01001100010010010100001001010010010000010101001001011001010111110100011101000101010101000101111101010011010101000100000101010010010101000100010101000100010111110101011101001001010100010010000101111101010000010100100100111101000100010101010100001101010100010111110101010001010010010010010100000101001100010111110100001001001100010011110100001101001011--}
Jak otworzyć plik PDF bezpośrednio z adresu URL?
Odczytywanie treści pliku PDF z adresu URL całkowicie pomija etap pobierania. Selenium lokalizuje link, IronPDF ładuje dokument, a Ty masz pełny tekst dostępny do weryfikacji w zaledwie kilku linijkach kodu.
// Initialize Chrome driver
var driver = new ChromeDriver();
// Navigate to a webpage containing a PDF link
driver.Navigate().GoToUrl("https://ironpdf.com/");
// Find and capture the PDF URL
IWebElement pdfLink = driver.FindElement(By.CssSelector("a[href$='.pdf']"));
string pdfUrl = pdfLink.GetAttribute("href");
// Load the PDF directly from the URL -- no download needed
var pdf = PdfDocument.FromUrl(new Uri(pdfUrl));
string extractedText = pdf.ExtractAllText();
// Assert expected content
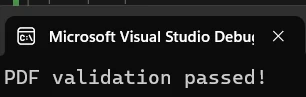
if (extractedText.Contains("IronPDF"))
{
Console.WriteLine("PDF validation passed!");
}
driver.Quit();// Initialize Chrome driver
var driver = new ChromeDriver();
// Navigate to a webpage containing a PDF link
driver.Navigate().GoToUrl("https://ironpdf.com/");
// Find and capture the PDF URL
IWebElement pdfLink = driver.FindElement(By.CssSelector("a[href$='.pdf']"));
string pdfUrl = pdfLink.GetAttribute("href");
// Load the PDF directly from the URL -- no download needed
var pdf = PdfDocument.FromUrl(new Uri(pdfUrl));
string extractedText = pdf.ExtractAllText();
// Assert expected content
if (extractedText.Contains("IronPDF"))
{
Console.WriteLine("PDF validation passed!");
}
driver.Quit();Imports OpenQA.Selenium
Imports OpenQA.Selenium.Chrome
Imports IronPdf
' Initialize Chrome driver
Dim driver As IWebDriver = New ChromeDriver()
' Navigate to a webpage containing a PDF link
driver.Navigate().GoToUrl("https://ironpdf.com/")
' Find and capture the PDF URL
Dim pdfLink As IWebElement = driver.FindElement(By.CssSelector("a[href$='.pdf']"))
Dim pdfUrl As String = pdfLink.GetAttribute("href")
' Load the PDF directly from the URL -- no download needed
Dim pdf As PdfDocument = PdfDocument.FromUrl(New Uri(pdfUrl))
Dim extractedText As String = pdf.ExtractAllText()
' Assert expected content
If extractedText.Contains("IronPDF") Then
Console.WriteLine("PDF validation passed!")
End If
driver.Quit()PdfDocument.FromUrl() pobiera i analizuje dokument w pamięci. Wywołanie ExtractAllText() zwraca cały tekst ze wszystkich stron jako pojedynczy ciąg znaków, gotowy do wykorzystania w sprawdzianach. W przypadku dokumentów chronionych hasłem należy przekazać dane uwierzytelniające jako dodatkowy parametr, aby chronione pliki pozostały dostępne podczas testowania. Aby dowiedzieć się więcej o opcjach wyodrębniania tekstu, zapoznaj się z przewodnikiem IronPDF dotyczącym wyodrębniania tekstu.
Wynik
Jak automatycznie pobrać i przetworzyć plik PDF?
Gdy plik PDF jest generowany po uwierzytelnieniu lub w ramach dynamicznego przepływu pracy, jedyną opcją może być jego pobranie. Skonfiguruj przeglądarkę Chrome tak, aby automatycznie pobierała pliki PDF do określonego katalogu, a następnie przekaż ścieżkę do pliku do IronPDF:
// Configure Chrome to auto-download PDFs
var chromeOptions = new ChromeOptions();
chromeOptions.AddUserProfilePreference("download.default_directory", @"C:\PDFTests");
chromeOptions.AddUserProfilePreference("plugins.always_open_pdf_externally", true);
var driver = new ChromeDriver(chromeOptions);
string appUrl = "https://example.com/reports";
// Trigger the download
driver.Navigate().GoToUrl(appUrl);
driver.FindElement(By.Id("downloadReport")).Click();
// Wait for the download -- replace Thread.Sleep with a file-system watcher in production tests
System.Threading.Thread.Sleep(3000);
// Read the downloaded PDF
string pdfPath = @"C:\PDFTests\report.pdf";
var pdf = PdfDocument.FromFile(pdfPath);
string content = pdf.ExtractAllText();
// Validate specific data
bool hasExpectedData = content.Contains("Quarterly Revenue: $1.2M");
Console.WriteLine($"Revenue data found: {hasExpectedData}");
// Extract text from a specific page (zero-indexed)
string page2Content = pdf.ExtractTextFromPage(1);
// Clean up
File.Delete(pdfPath);
driver.Quit();// Configure Chrome to auto-download PDFs
var chromeOptions = new ChromeOptions();
chromeOptions.AddUserProfilePreference("download.default_directory", @"C:\PDFTests");
chromeOptions.AddUserProfilePreference("plugins.always_open_pdf_externally", true);
var driver = new ChromeDriver(chromeOptions);
string appUrl = "https://example.com/reports";
// Trigger the download
driver.Navigate().GoToUrl(appUrl);
driver.FindElement(By.Id("downloadReport")).Click();
// Wait for the download -- replace Thread.Sleep with a file-system watcher in production tests
System.Threading.Thread.Sleep(3000);
// Read the downloaded PDF
string pdfPath = @"C:\PDFTests\report.pdf";
var pdf = PdfDocument.FromFile(pdfPath);
string content = pdf.ExtractAllText();
// Validate specific data
bool hasExpectedData = content.Contains("Quarterly Revenue: $1.2M");
Console.WriteLine($"Revenue data found: {hasExpectedData}");
// Extract text from a specific page (zero-indexed)
string page2Content = pdf.ExtractTextFromPage(1);
// Clean up
File.Delete(pdfPath);
driver.Quit();Imports OpenQA.Selenium
Imports OpenQA.Selenium.Chrome
Imports System.IO
Imports System.Threading
' Configure Chrome to auto-download PDFs
Dim chromeOptions As New ChromeOptions()
chromeOptions.AddUserProfilePreference("download.default_directory", "C:\PDFTests")
chromeOptions.AddUserProfilePreference("plugins.always_open_pdf_externally", True)
Dim driver As New ChromeDriver(chromeOptions)
Dim appUrl As String = "https://example.com/reports"
' Trigger the download
driver.Navigate().GoToUrl(appUrl)
driver.FindElement(By.Id("downloadReport")).Click()
' Wait for the download -- replace Thread.Sleep with a file-system watcher in production tests
Thread.Sleep(3000)
' Read the downloaded PDF
Dim pdfPath As String = "C:\PDFTests\report.pdf"
Dim pdf = PdfDocument.FromFile(pdfPath)
Dim content As String = pdf.ExtractAllText()
' Validate specific data
Dim hasExpectedData As Boolean = content.Contains("Quarterly Revenue: $1.2M")
Console.WriteLine($"Revenue data found: {hasExpectedData}")
' Extract text from a specific page (zero-indexed)
Dim page2Content As String = pdf.ExtractTextFromPage(1)
' Clean up
File.Delete(pdfPath)
driver.Quit()Preferencja plugins.always_open_pdf_externally omija wbudowaną przeglądarkę plików PDF w przeglądarce Chrome, dzięki czemu plik trafia na dysk zamiast otwierać się w przeglądarce. ExtractTextFromPage() zapewnia precyzję na poziomie strony, gdy różne dane walidacyjne pojawiają się na różnych stronach wielostronicowego raportu. Aby efektywnie pracować z dużymi dokumentami, zapoznaj się z poradami dotyczącymi wydajności IronPDF.
Jak weryfikować zawartość plików PDF w testach automatycznych?
Sprawdzanie, czy dokument zawiera właściwe terminy, jest najczęstszym scenariuszem testowym. Poniższa metoda pomocnicza przyjmuje ścieżkę do pliku oraz tablicę wymaganych terminów, a następnie zwraca false w momencie, gdy brakuje jakiegokolwiek oczekiwanego terminu:
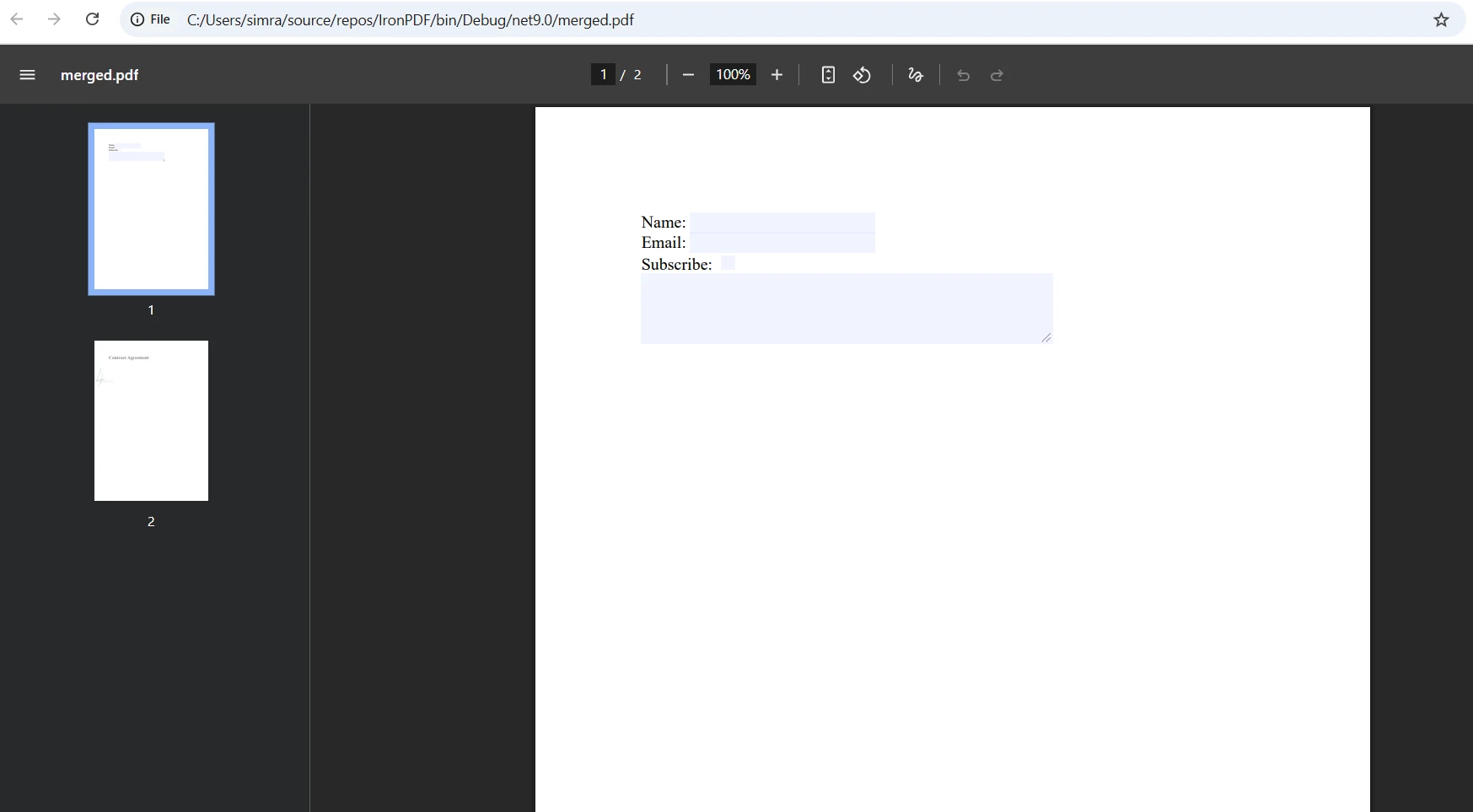
bool ValidatePdfContent(string pdfPath, string[] expectedTerms)
{
var pdf = PdfDocument.FromFile(pdfPath);
string fullText = pdf.ExtractAllText();
// Verify each required term
foreach (string term in expectedTerms)
{
if (!fullText.Contains(term, StringComparison.OrdinalIgnoreCase))
{
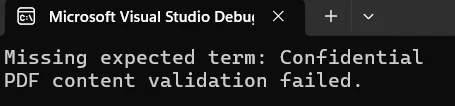
Console.WriteLine($"Missing expected term: {term}");
return false;
}
}
// Validate first-page structure
if (pdf.PageCount > 0)
{
string firstPageText = pdf.ExtractTextFromPage(0);
if (!firstPageText.Contains("Invoice #") && !firstPageText.Contains("Date:"))
{
Console.WriteLine("Header validation failed");
return false;
}
}
return true;
}bool ValidatePdfContent(string pdfPath, string[] expectedTerms)
{
var pdf = PdfDocument.FromFile(pdfPath);
string fullText = pdf.ExtractAllText();
// Verify each required term
foreach (string term in expectedTerms)
{
if (!fullText.Contains(term, StringComparison.OrdinalIgnoreCase))
{
Console.WriteLine($"Missing expected term: {term}");
return false;
}
}
// Validate first-page structure
if (pdf.PageCount > 0)
{
string firstPageText = pdf.ExtractTextFromPage(0);
if (!firstPageText.Contains("Invoice #") && !firstPageText.Contains("Date:"))
{
Console.WriteLine("Header validation failed");
return false;
}
}
return true;
}Imports System
Function ValidatePdfContent(pdfPath As String, expectedTerms As String()) As Boolean
Dim pdf = PdfDocument.FromFile(pdfPath)
Dim fullText As String = pdf.ExtractAllText()
' Verify each required term
For Each term As String In expectedTerms
If Not fullText.Contains(term, StringComparison.OrdinalIgnoreCase) Then
Console.WriteLine($"Missing expected term: {term}")
Return False
End If
Next
' Validate first-page structure
If pdf.PageCount > 0 Then
Dim firstPageText As String = pdf.ExtractTextFromPage(0)
If Not firstPageText.Contains("Invoice #") AndAlso Not firstPageText.Contains("Date:") Then
Console.WriteLine("Header validation failed")
Return False
End If
End If
Return True
End FunctionStringComparison.OrdinalIgnoreCase zapobiega nieprawidłowemu działaniu testów spowodowanemu różnicami w wielkości liter w generowanych dokumentach. IronPDF zachowuje układ tekstu i formatowanie podczas ekstrakcji, dzięki czemu walidacja pozycyjna — taka jak potwierdzenie, że pola nagłówka pojawiają się na pierwszej stronie — działa niezawodnie w różnych generatorach PDF.
W przypadku bardziej zaawansowanych scenariuszy, takich jak wyodrębnianie tabel z plików PDF, pobieranie osadzonych obrazów lub odczytywanie interaktywnych pól formularzy, IronPDF udostępnia dedykowane interfejsy API dla każdego zadania. Możesz również połączyć wyodrębnianie tekstu z procesami łączenia lub dzielenia plików PDF, gdy Twoja Suite testów wymaga złożenia lub rozłożenia dokumentów przed walidacją.
Dane wejściowe
Wynik
Jakie są najlepsze praktyki dotyczące testowania plików PDF za pomocą Selenium?
Zastosowanie kilku wzorców od samego początku pozwoli na łatwą konserwację Suite testów PDF w miarę rozwoju projektu.
Zastosuj wyraźne oczekiwania zamiast stałych opóźnień. Zastąp Thread.Sleep() obserwatorem systemu plików lub pętlą odpytywania, która sprawdza istnienie pliku. Dokumentacja Selenium dotycząca oczekiwania jawnego obejmuje strategie oczekiwania po stronie przeglądarki, a ta sama zasada ma zastosowanie do pobierania plików. Stałe opóźnienia są niestabilne na wolnych maszynach CI.
Scentralizuj operacje na plikach PDF w klasie bazowej. Utwórz wspólną klasę pomocniczą lub bazową klasę testową, która udostępnia metody takie jak LoadPdfFromUrl, DownloadPdf i ValidateTerms. Poszczególne testy skupiają się wówczas na asercjach, a nie na szczegółach technicznych plików PDF. Odzwierciedla to schemat, który sama firma IronPDF stosuje przy konwersji HTML do PDF i innych podstawowych operacjach.
Po każdym teście należy wyczyścić pobrane pliki. Należy wywołać File.Delete() w bloku finally lub metodzie teardown, aby tymczasowe pliki PDF nie gromadziły się na dysku. Jest to szczególnie ważne w przypadku równoległych przebiegów testów, w których wiele plików może trafić do tego samego katalogu jednocześnie.
Przeprowadzaj testy na różnych platformach bez wprowadzania zmian. IronPDF działa w systemach Windows, Linux i macOS bez kompilacji warunkowej. Ten sam zestaw testowy, który działa lokalnie, będzie działał poprawnie na agentach CI opartych na systemie Linux. Konfigurację specyficzną dla Docker można znaleźć w przewodniku wdrażania na wielu platformach.
Nie umieszczaj haseł w systemie kontroli wersji. Podczas pracy z chronionymi plikami PDF odczytuj dane uwierzytelniające ze zmiennych środowiskowych lub menedżera sekretów, zamiast kodować je na stałe. Przeładowanie PdfDocument.FromFile(path, password) w IronPDF akceptuje hasło w momencie ładowania, dzięki czemu miejsce wywołania pozostaje czyste. Strona licencyjna IronPDF obejmuje licencje zespołowe i Enterprise przeznaczone do wdrożeń produkcyjnych.
Ogranicz wyodrębnianie tekstu do potrzebnej strony. ExtractAllText() jest wygodne w przypadku małych dokumentów, ale w przypadku dużych, wielostronicowych plików PDF rozważ wywołanie ExtractTextFromPage() tylko dla stron zawierających dane, które weryfikujesz. Zmniejsza to zużycie pamięci i przyspiesza wykonywanie testów. Pełne sygnatury metod można znaleźć w Dokumentacji API dotyczącej ekstrakcji tekstu.

Jak IronPDF wypada na tle innych bibliotek PDF dla .NET?
| Funkcja | IronPDF | iTextSharp | PdfPig |
|---|---|---|---|
| Wczytaj plik PDF z adresu URL | Tak — pojedyncze wywołanie metody | Wymagane ręczne pobranie pliku HTTP | Wymagane ręczne pobranie pliku HTTP |
| Wyodrębnij cały tekst | Tak -- `ExtractAllText()` | Tak — wieloetapowe | Tak — wieloetapowe |
| Pobieranie na poziomie strony | Tak -- `ExtractTextFromPage(n)` | Tak | Tak |
| Pliki PDF chronione hasłem | Tak — przeciążenie parametrów | Tak | Ograniczone |
| Obsługa .NET 10 | Tak | Częściowe | Tak |
| Generowanie plików PDF z HTML | Tak | Ograniczone | Nie |
| Wieloplatformowe (Linux, macOS) | Tak | Tak | Tak |
| Rodzaj licencji | Wersja komercyjna z bezpłatną wersją próbną | AGPL / Komercyjne | MIT |
Bezpośrednie ładowanie adresów URL oraz ekstrakcja tekstu za pomocą jednej metody sprawiają, że IronPDF ma wyraźną przewagę w kontekście automatyzacji testów, gdzie liczy się szybkość rozwoju. Dla zespołów, które muszą również generować pliki PDF z HTML lub modyfikować istniejące dokumenty w ramach tego samego przepływu pracy, posiadanie jednej biblioteki obsługującej oba zadania znacznie upraszcza drzewo zależności. Alternatywne rozwiązania open source, takie jak PdfPig, są odpowiednie do prostych zadań związanych z ekstrakcją danych, ale wymagają więcej konfiguracji w celu obsługi ładowania adresów URL i nie oferują wbudowanej funkcji generowania plików PDF.
Jak rozpocząć korzystanie z bezpłatnej wersji próbnej?
IronPDF oferuje w pełni funkcjonalną bezpłatną wersję próbną, dzięki czemu można przetestować bibliotekę w swoim środowisku testowym przed zakupem licencji. W okresie próbnym żadne ograniczenia związane z znakami wodnymi nie mają wpływu na procesy wyodrębniania tekstu ani walidacji.
Aby rozpocząć:
- Zainstaluj pakiet NuGet:
dotnet add package IronPdf - Dodaj
using IronPdf;do pliku testowego. - Wywołaj
PdfDocument.FromUrl()lubPdfDocument.FromFile()i rozpocznij wyodrębnianie tekstu.
Odwiedź stronę bezpłatnej wersji próbnej IronPDF, aby pobrać klucz próbny. W przypadku zespołów lub wdrożeń Enterprise zapoznaj się z opcjami licencyjnymi IronPDF, aby znaleźć plan dostosowany do Twoich potrzeb.
Dodatkowe zasoby, które przyspieszą konfigurację:
- Przewodnik szybkiego startu IronPDF .NET
- Pełna dokumentacja API dla PdfDocument
- Strona IronPDF w NuGet
- Wsparcie społeczności i przykłady
Często Zadawane Pytania
Dlaczego Selenium WebDriver nie może bezpośrednio odczytywać plików PDF?
Selenium WebDriver jest zaprojektowany do interakcji z elementami sieciowymi, które są częścią DOM. Pliki PDF są jednak renderowane jako strumienie binarne, a nie elementy DOM, co uniemożliwia Selenium bezpośrednią interakcję z ich zawartością.
W jaki sposób IronPDF pomaga w odczytywaniu plików PDF w Selenium WebDriver?
IronPDF płynnie integruje się z Selenium WebDriver, umożliwiając wyodrębnianie tekstu i sprawdzanie poprawności danych PDF bez konieczności stosowania skomplikowanych konfiguracji lub wielu bibliotek. Znacznie upraszcza to proces i zwiększa wydajność testowania.
Jakie są zalety korzystania z IronPDF w połączeniu z Selenium do testowania plików PDF?
Wykorzystanie IronPDF wraz z Selenium pozwala na usprawnione przetwarzanie plików PDF, umożliwiając programistom wyodrębnianie i weryfikację tekstu z plików PDF przy użyciu minimalnej ilości kodu. Zmniejsza to potrzebę stosowania dodatkowej konfiguracji lub zewnętrznych bibliotek, dzięki czemu proces ten staje się szybszy i bardziej wydajny.
Czy do testowania plików PDF w języku C# konieczne jest użycie dodatkowych bibliotek wraz z IronPDF?
Nie, IronPDF zapewnia kompleksowe rozwiązanie, które obsługuje wyodrębnianie i walidację plików PDF, eliminując potrzebę stosowania wielu bibliotek lub skomplikowanych konfiguracji w projektach C#.
Czy IronPDF obsługuje pliki PDF generowane przez nowoczesne aplikacje internetowe?
Tak, IronPDF jest szczególnie skuteczny w przypadku nowych dokumentów PDF generowanych przez nowoczesne aplikacje internetowe, umożliwiając wydajne wyodrębnianie tekstu i weryfikację danych.
Co sprawia, że IronPDF jest potężnym narzędziem do automatyzacji PDF w Selenium?
Potężne możliwości IronPDF pozwalają na integrację z Selenium WebDriver, zapewniając wydajny sposób zarządzania plikami PDF. Upraszcza to proces odczytu i walidacji treści PDF bezpośrednio w ramach testów automatycznych.
Jak IronPDF wypada na tle rozwiązań Java, takich jak Apache PDFBox?
W przeciwieństwie do rozwiązań Java, które mogą wymagać wielu instrukcji importu i bibliotek, IronPDF oferuje uproszczone podejście, które integruje się bezpośrednio z projektami C#, upraszczając proces testowania plików PDF w Selenium.
Czy IronPDF jest kompatybilny z Selenium WebDriver w C#?
Tak, IronPDF został zaprojektowany tak, aby płynnie współpracować z Selenium WebDriver w języku C#, zapewniając solidne rozwiązanie do odczytu i walidacji plików PDF w testach automatycznych.
Jakie wyzwania związane z automatycznym testowaniem plików PDF pomaga rozwiązać IronPDF?
IronPDF rozwiązuje problem dostępu do treści plików PDF i ich weryfikacji w testach automatycznych, eliminując potrzebę korzystania z wielu bibliotek i skomplikowanych konfiguracji oraz zapewniając proste rozwiązanie zgodne z Selenium WebDriver.
W jaki sposób IronPDF może poprawić wydajność zautomatyzowanych procesów testowania?
Dzięki integracji z Selenium WebDriver, IronPDF upraszcza proces wyodrębniania tekstu i walidacji danych PDF, zmniejszając złożoność i czas wymagany do zautomatyzowanych procesów testowania.














