
Cómo crear un generador de PDF .NET Core
Los documentos PDF presentan un desafío único en las pruebas automatizadas: si bien Selenium WebDriver destaca por su interacción con elementos web, no puede leer el contenido dentro de un PDF porque el archivo se renderiza como un flujo binario en lugar de elementos DOM. Este artículo muestra cómo resolver este problema en C# combinando Selenium con IronPDF , una biblioteca PDF .NET lista para producción que permite extraer, validar y procesar contenido PDF con solo unas pocas líneas de código, sin necesidad de una compleja gestión de dependencias al estilo Java.
¿Por qué Selenium tiene problemas con el contenido PDF?
Cuando se abre un PDF en un navegador, Selenium puede navegar a la página e interactuar con los controles del navegador, pero no puede consultar el texto o los datos dentro del documento. Los archivos PDF se representan como objetos incrustados o complementos, no como elementos HTML que el protocolo WebDriver pueda atravesar. El visor de PDF del navegador muestra el documento visualmente, pero no hay un DOM accesible para que Selenium lo inspeccione: cada consulta XPath o selector CSS no devuelve nada.
Las soluciones alternativas tradicionales requieren descargar el archivo al disco, invocar una biblioteca de análisis independiente y conectar todo manualmente. Ese proceso de varios pasos agrega complejidad, crea un código de prueba frágil y complica los procesos de CI/CD donde las rutas de archivos y los permisos son difíciles de controlar. IronPDF elimina todos esos pasos al permitirle cargar un PDF desde una URL o una ruta local y extraer su texto en una sola llamada, directamente dentro de su proyecto de prueba .NET existente, sin archivos ni configuraciones intermedias.
El resultado práctico es que el código de prueba se vuelve más corto, más fácil de leer y mucho menos propenso a fallar cuando cambia el entorno de prueba. Para obtener una visión más amplia de todo lo que IronPDF puede hacer más allá de la extracción de texto, visita el centro de documentación de IronPDF .

¿Cómo instalar IronPDF para realizar pruebas de Selenium?
Obtener los paquetes necesarios en su lugar lleva menos de un minuto. Abra la consola del gestor de paquetes en Visual Studio y ejecute:
Install-Package IronPdf
También necesitarás los paquetes de Selenium si aún no están en tu proyecto:
Install-Package Selenium.WebDriver
Install-Package Selenium.WebDriver.ChromeDriverInstall-Package Selenium.WebDriver
Install-Package Selenium.WebDriver.ChromeDriver
Una vez instalados los paquetes, agregue estas directivas using en la parte superior de su archivo de prueba:
using IronPdf;
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
using System.IO;using IronPdf;
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
using System.IO;Imports IronPdf
Imports OpenQA.Selenium
Imports OpenQA.Selenium.Chrome
Imports System.IOIronPDF apunta a .NET 10 y funciona en múltiples plataformas: Windows, Linux y macOS, por lo que el mismo código de prueba se ejecuta en todos los entornos, incluidos los contenedores Docker y los agentes de CI en la nube.
¿Cómo leer un PDF directamente desde una URL?
Al leer contenido PDF desde una URL se omite por completo el paso de descarga. Selenium localiza el enlace, IronPDF carga el documento y usted tiene el texto completo disponible para afirmaciones en solo unas pocas líneas.
// Initialize Chrome driver
var driver = new ChromeDriver();
// Navigate to a webpage containing a PDF link
driver.Navigate().GoToUrl("https://ironpdf.com/");
// Find and capture the PDF URL
IWebElement pdfLink = driver.FindElement(By.CssSelector("a[href$='.pdf']"));
string pdfUrl = pdfLink.GetAttribute("href");
// Load the PDF directly from the URL -- no download needed
var pdf = PdfDocument.FromUrl(new Uri(pdfUrl));
string extractedText = pdf.ExtractAllText();
// Assert expected content
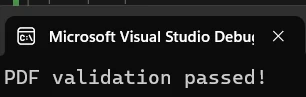
if (extractedText.Contains("IronPDF"))
{
Console.WriteLine("PDF validation passed!");
}
driver.Quit();// Initialize Chrome driver
var driver = new ChromeDriver();
// Navigate to a webpage containing a PDF link
driver.Navigate().GoToUrl("https://ironpdf.com/");
// Find and capture the PDF URL
IWebElement pdfLink = driver.FindElement(By.CssSelector("a[href$='.pdf']"));
string pdfUrl = pdfLink.GetAttribute("href");
// Load the PDF directly from the URL -- no download needed
var pdf = PdfDocument.FromUrl(new Uri(pdfUrl));
string extractedText = pdf.ExtractAllText();
// Assert expected content
if (extractedText.Contains("IronPDF"))
{
Console.WriteLine("PDF validation passed!");
}
driver.Quit();Imports OpenQA.Selenium
Imports OpenQA.Selenium.Chrome
Imports IronPdf
' Initialize Chrome driver
Dim driver As IWebDriver = New ChromeDriver()
' Navigate to a webpage containing a PDF link
driver.Navigate().GoToUrl("https://ironpdf.com/")
' Find and capture the PDF URL
Dim pdfLink As IWebElement = driver.FindElement(By.CssSelector("a[href$='.pdf']"))
Dim pdfUrl As String = pdfLink.GetAttribute("href")
' Load the PDF directly from the URL -- no download needed
Dim pdf As PdfDocument = PdfDocument.FromUrl(New Uri(pdfUrl))
Dim extractedText As String = pdf.ExtractAllText()
' Assert expected content
If extractedText.Contains("IronPDF") Then
Console.WriteLine("PDF validation passed!")
End If
driver.Quit()PdfDocument.FromUrl() recupera y analiza el documento en memoria. La llamada ExtractAllText() devuelve todo el texto de cada página como una sola cadena, lista para tus comprobaciones. Para los documentos protegidos con contraseña, pase las credenciales como un parámetro adicional para que los archivos protegidos permanezcan accesibles durante las pruebas. Para obtener más información sobre las opciones de extracción de texto, consulte la guía de extracción de texto de IronPDF .
Resultado
¿Cómo descargar y procesar un PDF automáticamente?
Cuando se genera un PDF después de la autenticación o mediante un flujo de trabajo dinámico, descargarlo primero puede ser la única opción. Configure Chrome para descargar automáticamente archivos PDF a un directorio conocido y luego entregue la ruta del archivo a IronPDF:
// Configure Chrome to auto-download PDFs
var chromeOptions = new ChromeOptions();
chromeOptions.AddUserProfilePreference("download.default_directory", @"C:\PDFTests");
chromeOptions.AddUserProfilePreference("plugins.always_open_pdf_externally", true);
var driver = new ChromeDriver(chromeOptions);
string appUrl = "https://example.com/reports";
// Trigger the download
driver.Navigate().GoToUrl(appUrl);
driver.FindElement(By.Id("downloadReport")).Click();
// Wait for the download -- replace Thread.Sleep with a file-system watcher in production tests
System.Threading.Thread.Sleep(3000);
// Read the downloaded PDF
string pdfPath = @"C:\PDFTests\report.pdf";
var pdf = PdfDocument.FromFile(pdfPath);
string content = pdf.ExtractAllText();
// Validate specific data
bool hasExpectedData = content.Contains("Quarterly Revenue: $1.2M");
Console.WriteLine($"Revenue data found: {hasExpectedData}");
// Extract text from a specific page (zero-indexed)
string page2Content = pdf.ExtractTextFromPage(1);
// Clean up
File.Delete(pdfPath);
driver.Quit();// Configure Chrome to auto-download PDFs
var chromeOptions = new ChromeOptions();
chromeOptions.AddUserProfilePreference("download.default_directory", @"C:\PDFTests");
chromeOptions.AddUserProfilePreference("plugins.always_open_pdf_externally", true);
var driver = new ChromeDriver(chromeOptions);
string appUrl = "https://example.com/reports";
// Trigger the download
driver.Navigate().GoToUrl(appUrl);
driver.FindElement(By.Id("downloadReport")).Click();
// Wait for the download -- replace Thread.Sleep with a file-system watcher in production tests
System.Threading.Thread.Sleep(3000);
// Read the downloaded PDF
string pdfPath = @"C:\PDFTests\report.pdf";
var pdf = PdfDocument.FromFile(pdfPath);
string content = pdf.ExtractAllText();
// Validate specific data
bool hasExpectedData = content.Contains("Quarterly Revenue: $1.2M");
Console.WriteLine($"Revenue data found: {hasExpectedData}");
// Extract text from a specific page (zero-indexed)
string page2Content = pdf.ExtractTextFromPage(1);
// Clean up
File.Delete(pdfPath);
driver.Quit();Imports OpenQA.Selenium
Imports OpenQA.Selenium.Chrome
Imports System.IO
Imports System.Threading
' Configure Chrome to auto-download PDFs
Dim chromeOptions As New ChromeOptions()
chromeOptions.AddUserProfilePreference("download.default_directory", "C:\PDFTests")
chromeOptions.AddUserProfilePreference("plugins.always_open_pdf_externally", True)
Dim driver As New ChromeDriver(chromeOptions)
Dim appUrl As String = "https://example.com/reports"
' Trigger the download
driver.Navigate().GoToUrl(appUrl)
driver.FindElement(By.Id("downloadReport")).Click()
' Wait for the download -- replace Thread.Sleep with a file-system watcher in production tests
Thread.Sleep(3000)
' Read the downloaded PDF
Dim pdfPath As String = "C:\PDFTests\report.pdf"
Dim pdf = PdfDocument.FromFile(pdfPath)
Dim content As String = pdf.ExtractAllText()
' Validate specific data
Dim hasExpectedData As Boolean = content.Contains("Quarterly Revenue: $1.2M")
Console.WriteLine($"Revenue data found: {hasExpectedData}")
' Extract text from a specific page (zero-indexed)
Dim page2Content As String = pdf.ExtractTextFromPage(1)
' Clean up
File.Delete(pdfPath)
driver.Quit()La preferencia plugins.always_open_pdf_externally omite el visor de PDF integrado de Chrome, de modo que el archivo se guarda en el disco en lugar de abrirse en el navegador. ExtractTextFromPage() le ofrece precisión a nivel de página cuando aparecen datos de validación diferentes en distintas páginas de un informe de varias páginas. Para trabajar con documentos grandes de manera eficiente, revise los consejos de rendimiento de IronPDF .
¿Cómo validar el contenido PDF en pruebas automatizadas?
Comprobar que un documento contiene los términos correctos es el escenario de prueba más común. El siguiente método auxiliar acepta una ruta de archivo y una matriz de términos requeridos, y devuelve false en el momento en que falte cualquier término esperado:
bool ValidatePdfContent(string pdfPath, string[] expectedTerms)
{
var pdf = PdfDocument.FromFile(pdfPath);
string fullText = pdf.ExtractAllText();
// Verify each required term
foreach (string term in expectedTerms)
{
if (!fullText.Contains(term, StringComparison.OrdinalIgnoreCase))
{
Console.WriteLine($"Missing expected term: {term}");
return false;
}
}
// Validate first-page structure
if (pdf.PageCount > 0)
{
string firstPageText = pdf.ExtractTextFromPage(0);
if (!firstPageText.Contains("Invoice #") && !firstPageText.Contains("Date:"))
{
Console.WriteLine("Header validation failed");
return false;
}
}
return true;
}bool ValidatePdfContent(string pdfPath, string[] expectedTerms)
{
var pdf = PdfDocument.FromFile(pdfPath);
string fullText = pdf.ExtractAllText();
// Verify each required term
foreach (string term in expectedTerms)
{
if (!fullText.Contains(term, StringComparison.OrdinalIgnoreCase))
{
Console.WriteLine($"Missing expected term: {term}");
return false;
}
}
// Validate first-page structure
if (pdf.PageCount > 0)
{
string firstPageText = pdf.ExtractTextFromPage(0);
if (!firstPageText.Contains("Invoice #") && !firstPageText.Contains("Date:"))
{
Console.WriteLine("Header validation failed");
return false;
}
}
return true;
}Imports System
Function ValidatePdfContent(pdfPath As String, expectedTerms As String()) As Boolean
Dim pdf = PdfDocument.FromFile(pdfPath)
Dim fullText As String = pdf.ExtractAllText()
' Verify each required term
For Each term As String In expectedTerms
If Not fullText.Contains(term, StringComparison.OrdinalIgnoreCase) Then
Console.WriteLine($"Missing expected term: {term}")
Return False
End If
Next
' Validate first-page structure
If pdf.PageCount > 0 Then
Dim firstPageText As String = pdf.ExtractTextFromPage(0)
If Not firstPageText.Contains("Invoice #") AndAlso Not firstPageText.Contains("Date:") Then
Console.WriteLine("Header validation failed")
Return False
End If
End If
Return True
End FunctionStringComparison.OrdinalIgnoreCase evita que las pruebas fallen debido a diferencias en el uso de mayúsculas en los documentos generados. IronPDF conserva el diseño y el formato del texto durante la extracción, por lo que la validación posicional (como confirmar que los campos de encabezado aparecen en la página uno) funciona de manera confiable en diferentes generadores de PDF.
Para escenarios más avanzados, como extraer tablas de archivos PDF , extraer imágenes incrustadas o leer campos de formulario interactivos, IronPDF proporciona API dedicadas para cada tarea. También puede encadenar la extracción de texto con flujos de trabajo de fusión o división de PDF cuando su conjunto de pruebas necesite ensamblar o desensamblar documentos antes de la validación.
Entrada
Resultado
¿Cuáles son las mejores prácticas para probar PDF con Selenium?
La aplicación de algunos patrones desde el principio permitirá que su conjunto de pruebas PDF se pueda mantener a medida que el proyecto crezca.
Utilice esperas explícitas en lugar de retrasos fijos. Sustituya Thread.Sleep() por un observador del sistema de archivos o un bucle de sondeo que compruebe la existencia del archivo. La documentación de espera explícita de Selenium cubre las estrategias de espera del lado del navegador, y el mismo principio se aplica a las descargas. Los retrasos fijos son frágiles en máquinas CI lentas.
Centraliza las operaciones de PDF en una clase base. Crea una clase auxiliar compartida o una clase de prueba base que exponga métodos como LoadPdfFromUrl, DownloadPdf y ValidateTerms. Las pruebas individuales luego se centran en las afirmaciones en lugar de en la infraestructura PDF. Esto refleja el patrón que sigue IronPDF para la conversión de HTML a PDF y otras operaciones centrales.
Limpia los archivos descargados después de cada prueba. Llama a File.Delete() en un bloque finally o en un método de desmontaje para que los PDF temporales no se acumulen en el disco. Esto es especialmente importante en ejecuciones de pruebas paralelas donde varios archivos pueden aparecer en el mismo directorio simultáneamente.
Ejecute pruebas multiplataforma sin cambios. IronPDF funciona en Windows, Linux y macOS sin compilación condicional. El mismo ensamblaje de prueba que se ejecuta localmente se ejecutará correctamente en agentes CI basados en Linux. Consulta la guía de implementación multiplataforma para configuraciones específicas de Docker.
Mantenga las contraseñas fuera del control de origen. Al trabajar con archivos PDF protegidos, lea las credenciales de las variables de entorno o de un gestor de secretos en lugar de codificarlas. La sobrecarga PdfDocument.FromFile(path, password) de IronPDF acepta la contraseña en el momento de la carga, por lo que el sitio de llamada se mantiene limpio. La página de licencias de IronPDF cubre las licencias empresariales y de equipo para implementaciones de producción.
Limita la extracción de texto a la página que necesites. ExtractAllText() es conveniente para documentos pequeños, pero para archivos PDF grandes de varias páginas, considera llamar a ExtractTextFromPage() solo para las páginas que contengan los datos que estás validando. Esto reduce el uso de memoria y acelera la ejecución de la prueba. Consulte la referencia de la API para la extracción de texto para obtener las firmas completas del método.

¿Cómo se compara IronPDF con otras bibliotecas PDF para .NET?
| Función | IronPDF | iTextSharp | PdfPig |
|---|---|---|---|
| Cargar PDF desde URL | Sí - llamada a un solo método | Se requiere descarga HTTP manual | Se requiere descarga HTTP manual |
| Extraer todo el texto | Sí -- `ExtractAllText()` | Sí, varios pasos | Sí, varios pasos |
| Extracción a nivel de página | Sí -- `ExtractTextFromPage(n)` | Sí | Sí |
| PDFs protegidos por contraseña | Sí - sobrecarga de parámetros | Sí | Limitado |
| Compatibilidad .NET 10 | Sí | Parcial | Sí |
| Generación de HTML a PDF | Sí | Limitado | No |
| Multiplataforma (Linux, macOS) | Sí | Sí | Sí |
| Tipo de licencia | Comercial con prueba gratuita | AGPL / Comercial | MIT |
La carga directa de URL y la extracción de texto de un solo método de IronPDF le brindan una clara ventaja en contextos de automatización de pruebas donde la velocidad de desarrollo es importante. Para los equipos que también necesitan generar archivos PDF a partir de HTML o manipular documentos existentes dentro del mismo flujo de trabajo, tener una biblioteca que maneje ambas tareas simplifica considerablemente el árbol de dependencia. Las alternativas de código abierto como PdfPig son una opción razonable para necesidades de extracción simples, pero requieren más configuración para manejar la carga de URL y no ofrecen generación de PDF incorporada.
¿Cómo empezar con una prueba gratuita?
IronPDF ofrece una prueba gratuita con todas las funciones para que pueda validar la biblioteca en su entorno de prueba antes de comprometerse con una licencia. Ninguna limitación de marca de agua afecta los flujos de trabajo de extracción o validación de texto durante el período de prueba.
Para empezar:
- Instala el paquete NuGet:
dotnet add package IronPdf - Añade
using IronPdf;a tu archivo de prueba. - Llama a
PdfDocument.FromUrl()oPdfDocument.FromFile()y empieza a extraer texto.
Visite la página de prueba gratuita de IronPDF para descargar su clave de prueba. Para equipos o implementaciones empresariales, revise las opciones de licencia de IronPDF para encontrar el plan que se ajuste a sus necesidades.
Recursos adicionales para acelerar su configuración:
- Guía de inicio rápido de IronPDF .NET
- Referencia completa de API para PdfDocument
- Página NuGet de IronPDF
- Apoyo comunitario y ejemplos
Preguntas Frecuentes
¿Por qué no puede Selenium WebDriver leer archivos PDF directamente?
Selenium WebDriver está diseñado para interactuar con elementos web, los cuales son parte del DOM. Sin embargo, los archivos PDF se renderizan como flujos binarios, no elementos DOM, lo que hace que la interacción directa con su contenido sea imposible para Selenium.
¿Cómo ayuda IronPDF a leer archivos PDF en Selenium WebDriver?
IronPDF se integra sin problemas con Selenium WebDriver, permitiéndote extraer texto y validar datos de PDF sin la necesidad de configuraciones complejas o bibliotecas múltiples. Esto simplifica el proceso significativamente y mejora la eficiencia de las pruebas.
¿Cuáles son los beneficios de usar IronPDF con Selenium para pruebas de PDF?
Usar IronPDF con Selenium permite un procesamiento de PDF optimizado, lo que permite a los desarrolladores extraer y validar texto de PDFs con un código mínimo. Esto reduce la necesidad de configuraciones adicionales o bibliotecas externas, haciendo el proceso más rápido y eficiente.
¿Es necesario usar bibliotecas adicionales con IronPDF para pruebas de PDF en C#?
No, IronPDF proporciona una solución completa que gestiona la extracción y validación de PDF, eliminando la necesidad de bibliotecas múltiples o configuraciones complejas en tus proyectos de C#.
¿Puede IronPDF manejar archivos PDF generados por aplicaciones web modernas?
Sí, IronPDF es particularmente efectivo con nuevos documentos PDF generados por aplicaciones web modernas, permitiendo una eficiente extracción de texto y validación de datos.
¿Qué hace que IronPDF sea una herramienta poderosa para la automatización de PDF en Selenium?
Las poderosas capacidades de IronPDF permiten integrarse con Selenium WebDriver, proporcionando una manera eficiente de gestionar archivos PDF. Simplifica el proceso de lectura y validación de contenido PDF directamente dentro de pruebas automatizadas.
¿Cómo se compara IronPDF con soluciones Java como Apache PDFBox?
A diferencia de las soluciones Java que pueden requerir múltiples declaraciones de importación y bibliotecas, IronPDF ofrece un enfoque optimizado que se integra directamente con proyectos de C#, simplificando el proceso de prueba de PDF en Selenium.
¿Es IronPDF compatible con Selenium WebDriver en C#?
Sí, IronPDF está diseñado para trabajar sin problemas con Selenium WebDriver en C#, proporcionando una sólida solución para leer y validar archivos PDF en pruebas automatizadas.
¿Qué desafíos ayuda a resolver IronPDF en pruebas automatizadas de PDF?
IronPDF aborda el desafío de acceder y validar contenido de PDF en pruebas automatizadas, eliminando la necesidad de bibliotecas múltiples y configuraciones complejas, y proporcionando una solución sencilla compatible con Selenium WebDriver.
¿Cómo puede mejorar IronPDF la eficiencia de los flujos de trabajo de pruebas automatizadas?
Al integrarse con Selenium WebDriver, IronPDF simplifica el proceso de extracción de texto y validación de datos PDF, reduciendo la complejidad y el tiempo requerido para los flujos de trabajo de pruebas automatizadas.











