
Wie man einen .NET Core PDF-Generator erstellt
PDF-Dokumente stellen eine besondere Herausforderung für automatisierte Tests dar: Selenium WebDriver eignet sich zwar hervorragend für die Interaktion mit Webelementen, kann aber den Inhalt von PDFs nicht lesen, da die Datei als Binärstrom und nicht als DOM-Element gerendert wird. Dieser Artikel zeigt, wie sich dieses Problem in C# lösen lässt, indem Selenium mit IronPDF kombiniert wird – einer produktionsreifen .NET PDF-Bibliothek, mit der sich PDF-Inhalte mit nur wenigen Codezeilen extrahieren, validieren und verarbeiten lassen. Komplexe Abhängigkeitsverwaltung im Java-Stil ist nicht erforderlich.
Warum hat Selenium Probleme mit PDF-Inhalten?
Wenn sich eine PDF-Datei in einem Browser öffnet, kann Selenium zur Seite navigieren und mit den Browser-Steuerelementen interagieren, aber es kann den Text oder die Daten im Dokument nicht abfragen. PDFs werden als eingebettete Objekte oder Plugins gerendert, nicht als HTML-Elemente, die das WebDriver-Protokoll durchlaufen kann. Der PDF-Viewer des Browsers stellt das Dokument visuell dar, aber es gibt kein zugängliches DOM, das Selenium untersuchen könnte – jede XPath-Abfrage oder jeder CSS-Selektor liefert nichts.
Herkömmliche Lösungsansätze erfordern das Herunterladen der Datei auf die Festplatte, den Aufruf einer separaten Parsing-Bibliothek und das manuelle Zusammenfügen aller Komponenten. Dieser mehrstufige Prozess erhöht die Komplexität, erzeugt fehleranfälligen Testcode und erschwert CI/CD-Pipelines, da Dateipfade und Berechtigungen schwer zu kontrollieren sind. IronPDF eliminiert all diese Schritte, indem es Ihnen ermöglicht, eine PDF-Datei von einer URL oder einem lokalen Pfad zu laden und ihren Text in einem einzigen Aufruf zu extrahieren – direkt innerhalb Ihres bestehenden .NET -Testprojekts, ohne Zwischendateien oder Konfigurationen.
Das praktische Ergebnis ist, dass der Testcode kürzer und leichter lesbar wird und viel seltener Fehler auftreten, wenn sich die Testumgebung ändert. Einen umfassenderen Überblick über alle Funktionen von IronPDF , die über die Textextraktion hinausgehen, finden Sie im IronPDF -Dokumentationsportal .

Wie installiert man IronPDF für Selenium-Tests?
Das Bereitstellen der benötigten Pakete dauert weniger als eine Minute. Öffnen Sie die Paketmanager-Konsole in Visual Studio und führen Sie den Befehl aus:
Install-Package IronPdf
Sie benötigen außerdem die Selenium-Pakete, falls diese noch nicht in Ihrem Projekt vorhanden sind:
Install-Package Selenium.WebDriver
Install-Package Selenium.WebDriver.ChromeDriverInstall-Package Selenium.WebDriver
Install-Package Selenium.WebDriver.ChromeDriver
Sobald die Pakete installiert sind, fügen Sie diese using-Anweisungen am Anfang Ihrer Testdatei hinzu:
using IronPdf;
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
using System.IO;using IronPdf;
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
using System.IO;Imports IronPdf
Imports OpenQA.Selenium
Imports OpenQA.Selenium.Chrome
Imports System.IOIronPDF zielt auf .NET 10 ab und funktioniert plattformübergreifend unter Windows, Linux und macOS, sodass derselbe Testcode in jeder Umgebung ausgeführt werden kann – einschließlich Docker-Containern und Cloud-CI-Agenten.
Wie liest man eine PDF-Datei direkt von einer URL?
Beim Lesen von PDF-Inhalten über eine URL wird der Download-Schritt komplett übersprungen. Selenium findet den Link, IronPDF lädt das Dokument, und Sie haben den vollständigen Text für Assertions in nur wenigen Zeilen zur Verfügung.
// Initialize Chrome driver
var driver = new ChromeDriver();
// Navigate to a webpage containing a PDF link
driver.Navigate().GoToUrl("https://ironpdf.com/");
// Find and capture the PDF URL
IWebElement pdfLink = driver.FindElement(By.CssSelector("a[href$='.pdf']"));
string pdfUrl = pdfLink.GetAttribute("href");
// Load the PDF directly from the URL -- no download needed
var pdf = PdfDocument.FromUrl(new Uri(pdfUrl));
string extractedText = pdf.ExtractAllText();
// Assert expected content
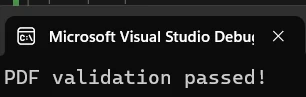
if (extractedText.Contains("IronPDF"))
{
Console.WriteLine("PDF validation passed!");
}
driver.Quit();// Initialize Chrome driver
var driver = new ChromeDriver();
// Navigate to a webpage containing a PDF link
driver.Navigate().GoToUrl("https://ironpdf.com/");
// Find and capture the PDF URL
IWebElement pdfLink = driver.FindElement(By.CssSelector("a[href$='.pdf']"));
string pdfUrl = pdfLink.GetAttribute("href");
// Load the PDF directly from the URL -- no download needed
var pdf = PdfDocument.FromUrl(new Uri(pdfUrl));
string extractedText = pdf.ExtractAllText();
// Assert expected content
if (extractedText.Contains("IronPDF"))
{
Console.WriteLine("PDF validation passed!");
}
driver.Quit();Imports OpenQA.Selenium
Imports OpenQA.Selenium.Chrome
Imports IronPdf
' Initialize Chrome driver
Dim driver As IWebDriver = New ChromeDriver()
' Navigate to a webpage containing a PDF link
driver.Navigate().GoToUrl("https://ironpdf.com/")
' Find and capture the PDF URL
Dim pdfLink As IWebElement = driver.FindElement(By.CssSelector("a[href$='.pdf']"))
Dim pdfUrl As String = pdfLink.GetAttribute("href")
' Load the PDF directly from the URL -- no download needed
Dim pdf As PdfDocument = PdfDocument.FromUrl(New Uri(pdfUrl))
Dim extractedText As String = pdf.ExtractAllText()
' Assert expected content
If extractedText.Contains("IronPDF") Then
Console.WriteLine("PDF validation passed!")
End If
driver.Quit()PdfDocument.FromUrl() ruft das Dokument ab und analysiert es im Speicher. Der ExtractAllText() Aufruf gibt den gesamten Text von jeder Seite als einen einzelnen String zurück, bereit für Ihre Prüfungen. Bei passwortgeschützten Dokumenten sollten die Zugangsdaten als zusätzlicher Parameter übergeben werden, damit die geschützten Dateien während der Testphase zugänglich bleiben. Weitere Informationen zu den Optionen der Textextraktion finden Sie im IronPDF Leitfaden zur Textextraktion .
Ausgabe
Wie lädt und verarbeitet man eine PDF-Datei automatisch?
Wenn eine PDF-Datei nach der Authentifizierung oder durch einen dynamischen Workflow generiert wird, ist das Herunterladen möglicherweise die einzige Option. Konfigurieren Sie Chrome so, dass PDFs automatisch in ein bekanntes Verzeichnis heruntergeladen werden, und übergeben Sie dann den Dateipfad an IronPDF:
// Configure Chrome to auto-download PDFs
var chromeOptions = new ChromeOptions();
chromeOptions.AddUserProfilePreference("download.default_directory", @"C:\PDFTests");
chromeOptions.AddUserProfilePreference("plugins.always_open_pdf_externally", true);
var driver = new ChromeDriver(chromeOptions);
string appUrl = "https://example.com/reports";
// Trigger the download
driver.Navigate().GoToUrl(appUrl);
driver.FindElement(By.Id("downloadReport")).Click();
// Wait for the download -- replace Thread.Sleep with a file-system watcher in production tests
System.Threading.Thread.Sleep(3000);
// Read the downloaded PDF
string pdfPath = @"C:\PDFTests\report.pdf";
var pdf = PdfDocument.FromFile(pdfPath);
string content = pdf.ExtractAllText();
// Validate specific data
bool hasExpectedData = content.Contains("Quarterly Revenue: $1.2M");
Console.WriteLine($"Revenue data found: {hasExpectedData}");
// Extract text from a specific page (zero-indexed)
string page2Content = pdf.ExtractTextFromPage(1);
// Clean up
File.Delete(pdfPath);
driver.Quit();// Configure Chrome to auto-download PDFs
var chromeOptions = new ChromeOptions();
chromeOptions.AddUserProfilePreference("download.default_directory", @"C:\PDFTests");
chromeOptions.AddUserProfilePreference("plugins.always_open_pdf_externally", true);
var driver = new ChromeDriver(chromeOptions);
string appUrl = "https://example.com/reports";
// Trigger the download
driver.Navigate().GoToUrl(appUrl);
driver.FindElement(By.Id("downloadReport")).Click();
// Wait for the download -- replace Thread.Sleep with a file-system watcher in production tests
System.Threading.Thread.Sleep(3000);
// Read the downloaded PDF
string pdfPath = @"C:\PDFTests\report.pdf";
var pdf = PdfDocument.FromFile(pdfPath);
string content = pdf.ExtractAllText();
// Validate specific data
bool hasExpectedData = content.Contains("Quarterly Revenue: $1.2M");
Console.WriteLine($"Revenue data found: {hasExpectedData}");
// Extract text from a specific page (zero-indexed)
string page2Content = pdf.ExtractTextFromPage(1);
// Clean up
File.Delete(pdfPath);
driver.Quit();Imports OpenQA.Selenium
Imports OpenQA.Selenium.Chrome
Imports System.IO
Imports System.Threading
' Configure Chrome to auto-download PDFs
Dim chromeOptions As New ChromeOptions()
chromeOptions.AddUserProfilePreference("download.default_directory", "C:\PDFTests")
chromeOptions.AddUserProfilePreference("plugins.always_open_pdf_externally", True)
Dim driver As New ChromeDriver(chromeOptions)
Dim appUrl As String = "https://example.com/reports"
' Trigger the download
driver.Navigate().GoToUrl(appUrl)
driver.FindElement(By.Id("downloadReport")).Click()
' Wait for the download -- replace Thread.Sleep with a file-system watcher in production tests
Thread.Sleep(3000)
' Read the downloaded PDF
Dim pdfPath As String = "C:\PDFTests\report.pdf"
Dim pdf = PdfDocument.FromFile(pdfPath)
Dim content As String = pdf.ExtractAllText()
' Validate specific data
Dim hasExpectedData As Boolean = content.Contains("Quarterly Revenue: $1.2M")
Console.WriteLine($"Revenue data found: {hasExpectedData}")
' Extract text from a specific page (zero-indexed)
Dim page2Content As String = pdf.ExtractTextFromPage(1)
' Clean up
File.Delete(pdfPath)
driver.Quit()Die plugins.always_open_pdf_externally Einstellung umgeht den integrierten PDF-Viewer von Chrome, sodass die Datei auf der Festplatte gespeichert wird, anstatt im Browser geöffnet zu werden. ExtractTextFromPage() ermöglicht seitenweise Präzision, wenn auf unterschiedlichen Seiten eines mehrseitigen Berichts unterschiedliche Validierungsdaten erscheinen. Für effizientes Arbeiten mit großen Dokumenten sollten Sie die IronPDF Leistungstipps beachten.
Wie validiert man PDF-Inhalte in automatisierten Tests?
Die Überprüfung, ob ein Dokument die richtigen Begriffe enthält, ist das häufigste Testszenario. Die folgende Hilfsmethode akzeptiert einen Dateipfad und ein Array von erforderlichen Begriffen und gibt dann false zurück, sobald ein erwarteter Begriff fehlt:
bool ValidatePdfContent(string pdfPath, string[] expectedTerms)
{
var pdf = PdfDocument.FromFile(pdfPath);
string fullText = pdf.ExtractAllText();
// Verify each required term
foreach (string term in expectedTerms)
{
if (!fullText.Contains(term, StringComparison.OrdinalIgnoreCase))
{
Console.WriteLine($"Missing expected term: {term}");
return false;
}
}
// Validate first-page structure
if (pdf.PageCount > 0)
{
string firstPageText = pdf.ExtractTextFromPage(0);
if (!firstPageText.Contains("Invoice #") && !firstPageText.Contains("Date:"))
{
Console.WriteLine("Header validation failed");
return false;
}
}
return true;
}bool ValidatePdfContent(string pdfPath, string[] expectedTerms)
{
var pdf = PdfDocument.FromFile(pdfPath);
string fullText = pdf.ExtractAllText();
// Verify each required term
foreach (string term in expectedTerms)
{
if (!fullText.Contains(term, StringComparison.OrdinalIgnoreCase))
{
Console.WriteLine($"Missing expected term: {term}");
return false;
}
}
// Validate first-page structure
if (pdf.PageCount > 0)
{
string firstPageText = pdf.ExtractTextFromPage(0);
if (!firstPageText.Contains("Invoice #") && !firstPageText.Contains("Date:"))
{
Console.WriteLine("Header validation failed");
return false;
}
}
return true;
}Imports System
Function ValidatePdfContent(pdfPath As String, expectedTerms As String()) As Boolean
Dim pdf = PdfDocument.FromFile(pdfPath)
Dim fullText As String = pdf.ExtractAllText()
' Verify each required term
For Each term As String In expectedTerms
If Not fullText.Contains(term, StringComparison.OrdinalIgnoreCase) Then
Console.WriteLine($"Missing expected term: {term}")
Return False
End If
Next
' Validate first-page structure
If pdf.PageCount > 0 Then
Dim firstPageText As String = pdf.ExtractTextFromPage(0)
If Not firstPageText.Contains("Invoice #") AndAlso Not firstPageText.Contains("Date:") Then
Console.WriteLine("Header validation failed")
Return False
End If
End If
Return True
End FunctionStringComparison.OrdinalIgnoreCase verhindert, dass Tests aufgrund von Groß-/Kleinschreibungsunterschieden in generierten Dokumenten fehlschlagen. IronPDF erhält Textlayout und Formatierung während der Extraktion, sodass die Positionsvalidierung – wie z. B. die Bestätigung, dass Kopfzeilenfelder auf Seite eins erscheinen – bei verschiedenen PDF-Generatoren zuverlässig funktioniert.
Für komplexere Szenarien wie das Extrahieren von Tabellen aus PDF-Dateien , das Herausziehen eingebetteter Bilder oder das Lesen interaktiver Formularfelder bietet IronPDF für jede Aufgabe spezielle APIs. Sie können die Textextraktion auch mit Workflows zum Zusammenführen oder Aufteilen von PDFs verknüpfen, wenn Ihre Suite Dokumente vor der Validierung zusammensetzen oder auseinandernehmen muss.
Eingabe
Ausgabe
Was sind die Best Practices für PDF-Tests mit Selenium?
Durch die Anwendung einiger weniger Muster von Anfang an bleibt Ihre PDF- Suite auch bei wachsendem Projekt wartungsfreundlich.
Verwenden Sie explizite Wartezeiten anstelle fixer Verzögerungen. Ersetzen Sie Thread.Sleep() durch einen Datei-System-Wächter oder eine Polling-Schleife, die das Vorhandensein der Datei überprüft. Die explizite Wartedokumentation von Selenium behandelt browserseitige Wartestrategien, und das gleiche Prinzip gilt auch für Downloads. Feste Verzögerungen sind auf langsamen CI-Maschinen fehleranfällig.
Zentralisieren Sie PDF-Operationen in einer Basisklasse. Erstellen Sie eine gemeinsame Helfer- oder Basistestklasse, die Methoden wie LoadPdfFromUrl, DownloadPdf und ValidateTerms bereitstellt. Die einzelnen Tests konzentrieren sich dann auf die Aussagen und nicht auf die PDF-Struktur. Dies spiegelt das Vorgehen von IronPDF selbst bei der HTML-zu-PDF-Konvertierung und anderen Kernoperationen wider.
Bereinigen Sie heruntergeladene Dateien nach jedem Test. Rufen Sie File.Delete() in einem finally-Block oder einer Teardown-Methode auf, damit sich temporäre PDFs nicht auf der Festplatte ansammeln. Dies ist besonders wichtig bei parallelen Testläufen, bei denen mehrere Dateien gleichzeitig im selben Verzeichnis landen können.
Führen Sie Tests plattformübergreifend ohne Änderungen durch. IronPDF funktioniert unter Windows, Linux und macOS ohne bedingte Kompilierung. Dieselbe Testassembly, die lokal ausgeführt wird, wird auch auf Linux-basierten CI-Agenten korrekt ausgeführt. Die Docker-spezifische Konfiguration finden Sie im Leitfaden zur plattformübergreifenden Bereitstellung .
Passwörter sollten nicht in der Quellcodeverwaltung gespeichert werden. Beim Arbeiten mit geschützten PDFs sollten Zugangsdaten aus Umgebungsvariablen oder einem Geheimnismanager gelesen werden, anstatt sie fest zu kodieren. Der Overload PdfDocument.FromFile(path, password) von IronPDF akzeptiert das Passwort zum Ladezeitpunkt, sodass der Aufrufort sauber bleibt. Die IronPDF Lizenzseite behandelt Team- und Enterprise für Produktionsumgebungen.
Begrenzen Sie die Textextraktion auf die Seite, die Sie benötigen. ExtractAllText() ist praktisch für kleine Dokumente, aber bei großen mehrseitigen PDFs sollten Sie erwägen, ExtractTextFromPage() nur für die Seiten aufzurufen, die die von Ihnen zu validierenden Daten enthalten. Dadurch wird der Speicherverbrauch reduziert und die Testausführung beschleunigt. Die vollständigen Methodensignaturen finden Sie in der API-Referenz zur Textextraktion .

Wie schneidet IronPDF im Vergleich zu anderen PDF-Bibliotheken für .NET ab?
| Merkmal | IronPDF | iText | PdfPig |
|---|---|---|---|
| PDF von URL laden | Ja – einzelner Methodenaufruf | Manueller HTTP-Download erforderlich | Manueller HTTP-Download erforderlich |
| Allen Text extrahieren | Ja -- `ExtractAllText()` | Ja – mehrstufig | Ja – mehrstufig |
| Extraktion auf Seitenebene | Ja -- `ExtractTextFromPage(n)` | Ja | Ja |
| Kennwortgeschützte PDFs | Ja – Parameterüberlastung | Ja | Begrenzt |
| .NET 10 support | Ja | Teilweise | Ja |
| HTML-zu-PDF-Generierung | Ja | Begrenzt | Nein |
| Plattformübergreifend (Linux, macOS) | Ja | Ja | Ja |
| Lizenztyp | Kommerziell mit kostenloser Testversion | AGPL / Kommerziell | MIT |
Die direkte URL-Ladefunktion und die Textextraktion mit nur einer Methode verschaffen IronPDF einen klaren Vorteil in Testautomatisierungskontexten, in denen die Entwicklungsgeschwindigkeit eine Rolle spielt. Für Teams, die im selben Workflow auch PDFs aus HTML generieren oder bestehende Dokumente bearbeiten müssen, vereinfacht die Verwendung einer einzigen Bibliothek, die beide Aufgaben übernimmt, den Abhängigkeitsbaum erheblich. Open-Source-Alternativen wie PdfPig eignen sich zwar für einfache Extraktionsanforderungen, erfordern aber mehr Aufwand beim Laden von URLs und bieten keine integrierte PDF-Generierung.
Wie starte ich eine kostenlose Testphase?
IronPDF bietet eine vollumfängliche kostenlose Testversion, damit Sie die Bibliothek in Ihrer Testumgebung überprüfen können, bevor Sie sich für eine Lizenz entscheiden. Während der Testphase gibt es keine Einschränkungen hinsichtlich der Wasserzeichen, die den Workflow zur Textextraktion oder -validierung beeinträchtigen.
Um loszulegen:
- Installieren Sie das NuGet-Paket:
dotnet add package IronPdf - Fügen Sie
using IronPdf;zu Ihrer Testdatei hinzu. - Rufen Sie
PdfDocument.FromUrl()oderPdfDocument.FromFile()auf und beginnen Sie mit der Textextraktion.
Besuchen Sie die IronPDF Testseite , um Ihren Testschlüssel herunterzuladen. Für Teams oder Enterprise sollten Sie die IronPDF -Lizenzoptionen prüfen, um den passenden Plan für Ihre Bedürfnisse zu finden.
Zusätzliche Ressourcen zur Beschleunigung Ihrer Einrichtung:
- IronPDF .NET Schnellstartanleitung
- Vollständige API-Referenz für PdfDocument
- IronPDF NuGet Seite
- Unterstützung aus der Gemeinschaft und Beispiele
Häufig gestellte Fragen
Warum kann Selenium WebDriver PDF-Dateien nicht direkt lesen?
Selenium WebDriver ist für die Interaktion mit Web-Elementen konzipiert, die Teil des DOM sind. PDF-Dateien werden jedoch als binäre Streams und nicht als DOM-Elemente dargestellt, was eine direkte Interaktion mit deren Inhalt für Selenium unmöglich macht.
Wie hilft IronPDF beim Lesen von PDF-Dateien in Selenium WebDriver?
IronPDF lässt sich nahtlos in Selenium WebDriver integrieren und ermöglicht es Ihnen, Text zu extrahieren und PDF-Daten zu validieren, ohne dass Sie komplexe Setups oder mehrere Bibliotheken benötigen. Dies vereinfacht den Prozess erheblich und steigert die Testeffizienz.
Welche Vorteile bietet die Verwendung von IronPDF mit Selenium für PDF-Tests?
Die Verwendung von IronPDF mit Selenium ermöglicht eine optimierte PDF-Verarbeitung, so dass Entwickler mit minimalem Code Text aus PDFs extrahieren und validieren können. Dies reduziert den Bedarf an zusätzlicher Konfiguration oder externen Bibliotheken und macht den Prozess schneller und effizienter.
Ist es notwendig, zusätzliche Bibliotheken mit IronPDF für PDF-Tests in C# zu verwenden?
Nein, IronPDF bietet eine umfassende Lösung für die PDF-Extraktion und -Validierung, die den Einsatz mehrerer Bibliotheken oder komplexer Konfigurationen in Ihren C#-Projekten überflüssig macht.
Kann IronPDF PDF-Dateien verarbeiten, die von modernen Webanwendungen erzeugt werden?
Ja, IronPDF ist besonders effektiv bei neuen PDF-Dokumenten, die von modernen Webanwendungen generiert werden, und ermöglicht eine effiziente Textextraktion und Datenvalidierung.
Was macht IronPDF zu einem leistungsstarken Tool für die PDF-Automatisierung in Selenium?
Die leistungsstarken Funktionen von IronPDF ermöglichen die Integration mit Selenium WebDriver und bieten eine effiziente Möglichkeit zur Verwaltung von PDF-Dateien. Es vereinfacht den Prozess des Lesens und Validierens von PDF-Inhalten direkt in automatisierten Tests.
Wie ist IronPDF im Vergleich zu Java-Lösungen wie Apache PDFBox?
Im Gegensatz zu Java-Lösungen, die unter Umständen mehrere Importanweisungen und Bibliotheken erfordern, bietet IronPDF einen optimierten Ansatz, der sich direkt in C#-Projekte integrieren lässt und den PDF-Testprozess in Selenium vereinfacht.
Ist IronPDF mit Selenium WebDriver in C# kompatibel?
Ja, IronPDF ist so konzipiert, dass es nahtlos mit Selenium WebDriver in C# zusammenarbeitet und eine robuste Lösung zum Lesen und Validieren von PDF-Dateien in automatisierten Tests bietet.
Welche Herausforderungen löst IronPDF bei der automatisierten PDF-Prüfung?
IronPDF stellt sich der Herausforderung, in automatisierten Tests auf PDF-Inhalte zuzugreifen und diese zu validieren. Es macht den Einsatz mehrerer Bibliotheken und komplexer Setups überflüssig und bietet eine unkomplizierte Lösung, die mit Selenium WebDriver kompatibel ist.
Wie kann IronPDF die Effizienz von automatisierten Testabläufen verbessern?
Durch die Integration mit Selenium WebDriver vereinfacht IronPDF den Prozess der Textextraktion und der Validierung von PDF-Daten und reduziert so die Komplexität und den Zeitaufwand für automatisierte Testabläufe.











