
如何创建 .NET Core PDF 生成器
PDF 文档在自动化测试中带来了一个独特的挑战:虽然 Selenium WebDriver 擅长与 Web 元素交互,但它无法读取 PDF 文件中的内容,因为 PDF 文件是以二进制流的形式呈现,而不是 DOM 元素。本文将展示如何使用 C# 解决这个问题,方法是将 Selenium 与IronPDF结合使用。IronPDF 是一个可用于生产环境的 .NET PDF 库,只需几行代码即可提取、验证和处理 PDF 内容,无需复杂的 Java 式依赖管理。
为什么 Selenium 难以处理 PDF 内容?
当 PDF 文件在浏览器中打开时,Selenium 可以导航到该页面并与浏览器控件进行交互,但它无法查询文档中的文本或数据。 PDF 文件被渲染为嵌入式对象或插件,而不是WebDriver 协议可以遍历的 HTML 元素。 浏览器的 PDF 查看器可以直观地渲染文档,但 Selenium 无法访问 DOM 进行检查——每个 XPath 查询或 CSS 选择器都返回空值。
传统解决方法需要将文件下载到磁盘,调用单独的解析库,然后手动将所有内容连接起来。 这种多步骤流程增加了复杂性,创建了脆弱的测试代码,并使 CI/CD 管道变得复杂,因为文件路径和权限难以控制。 IronPDF 简化了所有这些步骤,允许您从 URL 或本地路径加载 PDF,并在一次调用中提取其文本——直接在您现有的 .NET 测试项目中,无需任何中间文件或配置。
实际结果是,测试代码变得更短、更容易阅读,并且在测试环境发生变化时更不容易出错。 要更全面地了解 IronPDF 除了文本提取之外还能做的所有事情,请访问IronPDF 文档中心。

如何安装 IronPDF 以进行 Selenium 测试?
准备所需包裹只需不到一分钟。 在 Visual Studio 中打开软件包管理器控制台并运行:
Install-Package IronPdf
如果你的项目中还没有 Selenium 包,你还需要安装它们:
Install-Package Selenium.WebDriver
Install-Package Selenium.WebDriver.ChromeDriverInstall-Package Selenium.WebDriver
Install-Package Selenium.WebDriver.ChromeDriver
安装完软件包后,在测试文件的顶部添加以下 using 指令:
using IronPdf;
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
using System.IO;using IronPdf;
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
using System.IO;Imports IronPdf
Imports OpenQA.Selenium
Imports OpenQA.Selenium.Chrome
Imports System.IOIronPDF 面向 .NET 10,可在 Windows、Linux 和 macOS 等跨平台环境下运行,因此相同的测试代码可以在每个环境中运行,包括 Docker 容器和云 CI 代理。
如何直接从 URL 读取 PDF 文件?
从 URL 读取 PDF 内容完全跳过了下载步骤。 Selenium 定位链接,IronPDF 加载文档,只需几行代码即可获取全文以进行断言。
// Initialize Chrome driver
var driver = new ChromeDriver();
// Navigate to a webpage containing a PDF link
driver.Navigate().GoToUrl("https://ironpdf.com/");
// Find and capture the PDF URL
IWebElement pdfLink = driver.FindElement(By.CssSelector("a[href$='.pdf']"));
string pdfUrl = pdfLink.GetAttribute("href");
// Load the PDF directly from the URL -- no download needed
var pdf = PdfDocument.FromUrl(new Uri(pdfUrl));
string extractedText = pdf.ExtractAllText();
// Assert expected content
if (extractedText.Contains("IronPDF"))
{
Console.WriteLine("PDF validation passed!");
}
driver.Quit();// Initialize Chrome driver
var driver = new ChromeDriver();
// Navigate to a webpage containing a PDF link
driver.Navigate().GoToUrl("https://ironpdf.com/");
// Find and capture the PDF URL
IWebElement pdfLink = driver.FindElement(By.CssSelector("a[href$='.pdf']"));
string pdfUrl = pdfLink.GetAttribute("href");
// Load the PDF directly from the URL -- no download needed
var pdf = PdfDocument.FromUrl(new Uri(pdfUrl));
string extractedText = pdf.ExtractAllText();
// Assert expected content
if (extractedText.Contains("IronPDF"))
{
Console.WriteLine("PDF validation passed!");
}
driver.Quit();Imports OpenQA.Selenium
Imports OpenQA.Selenium.Chrome
Imports IronPdf
' Initialize Chrome driver
Dim driver As IWebDriver = New ChromeDriver()
' Navigate to a webpage containing a PDF link
driver.Navigate().GoToUrl("https://ironpdf.com/")
' Find and capture the PDF URL
Dim pdfLink As IWebElement = driver.FindElement(By.CssSelector("a[href$='.pdf']"))
Dim pdfUrl As String = pdfLink.GetAttribute("href")
' Load the PDF directly from the URL -- no download needed
Dim pdf As PdfDocument = PdfDocument.FromUrl(New Uri(pdfUrl))
Dim extractedText As String = pdf.ExtractAllText()
' Assert expected content
If extractedText.Contains("IronPDF") Then
Console.WriteLine("PDF validation passed!")
End If
driver.Quit()PdfDocument.FromUrl()获取并解析内存中的文档。 ExtractAllText()调用返回每一页的所有文本作为单一字符串,准备进行断言。 对于受密码保护的文档,请将凭据作为附加参数传递,以便在测试期间仍然可以访问受保护的文件。 要了解有关文本提取选项的更多信息,请参阅IronPDF 文本提取指南。
输出
如何自动下载和处理PDF文件?
当在身份验证后或通过动态工作流程生成 PDF 时,先下载它可能是唯一的选择。 配置 Chrome 自动将 PDF 文件下载到指定目录,然后将文件路径传递给 IronPDF:
// Configure Chrome to auto-download PDFs
var chromeOptions = new ChromeOptions();
chromeOptions.AddUserProfilePreference("download.default_directory", @"C:\PDFTests");
chromeOptions.AddUserProfilePreference("plugins.always_open_pdf_externally", true);
var driver = new ChromeDriver(chromeOptions);
string appUrl = "https://example.com/reports";
// Trigger the download
driver.Navigate().GoToUrl(appUrl);
driver.FindElement(By.Id("downloadReport")).Click();
// Wait for the download -- replace Thread.Sleep with a file-system watcher in production tests
System.Threading.Thread.Sleep(3000);
// Read the downloaded PDF
string pdfPath = @"C:\PDFTests\report.pdf";
var pdf = PdfDocument.FromFile(pdfPath);
string content = pdf.ExtractAllText();
// Validate specific data
bool hasExpectedData = content.Contains("Quarterly Revenue: $1.2M");
Console.WriteLine($"Revenue data found: {hasExpectedData}");
// Extract text from a specific page (zero-indexed)
string page2Content = pdf.ExtractTextFromPage(1);
// Clean up
File.Delete(pdfPath);
driver.Quit();// Configure Chrome to auto-download PDFs
var chromeOptions = new ChromeOptions();
chromeOptions.AddUserProfilePreference("download.default_directory", @"C:\PDFTests");
chromeOptions.AddUserProfilePreference("plugins.always_open_pdf_externally", true);
var driver = new ChromeDriver(chromeOptions);
string appUrl = "https://example.com/reports";
// Trigger the download
driver.Navigate().GoToUrl(appUrl);
driver.FindElement(By.Id("downloadReport")).Click();
// Wait for the download -- replace Thread.Sleep with a file-system watcher in production tests
System.Threading.Thread.Sleep(3000);
// Read the downloaded PDF
string pdfPath = @"C:\PDFTests\report.pdf";
var pdf = PdfDocument.FromFile(pdfPath);
string content = pdf.ExtractAllText();
// Validate specific data
bool hasExpectedData = content.Contains("Quarterly Revenue: $1.2M");
Console.WriteLine($"Revenue data found: {hasExpectedData}");
// Extract text from a specific page (zero-indexed)
string page2Content = pdf.ExtractTextFromPage(1);
// Clean up
File.Delete(pdfPath);
driver.Quit();Imports OpenQA.Selenium
Imports OpenQA.Selenium.Chrome
Imports System.IO
Imports System.Threading
' Configure Chrome to auto-download PDFs
Dim chromeOptions As New ChromeOptions()
chromeOptions.AddUserProfilePreference("download.default_directory", "C:\PDFTests")
chromeOptions.AddUserProfilePreference("plugins.always_open_pdf_externally", True)
Dim driver As New ChromeDriver(chromeOptions)
Dim appUrl As String = "https://example.com/reports"
' Trigger the download
driver.Navigate().GoToUrl(appUrl)
driver.FindElement(By.Id("downloadReport")).Click()
' Wait for the download -- replace Thread.Sleep with a file-system watcher in production tests
Thread.Sleep(3000)
' Read the downloaded PDF
Dim pdfPath As String = "C:\PDFTests\report.pdf"
Dim pdf = PdfDocument.FromFile(pdfPath)
Dim content As String = pdf.ExtractAllText()
' Validate specific data
Dim hasExpectedData As Boolean = content.Contains("Quarterly Revenue: $1.2M")
Console.WriteLine($"Revenue data found: {hasExpectedData}")
' Extract text from a specific page (zero-indexed)
Dim page2Content As String = pdf.ExtractTextFromPage(1)
' Clean up
File.Delete(pdfPath)
driver.Quit()plugins.always_open_pdf_externally首选项绕过Chrome内置的PDF查看器,因此文件保存在磁盘上而不是在浏览器中打开。 ExtractTextFromPage()当多页报告的不同页面上出现不同验证数据时,为您提供页面级精度。 为了高效处理大型文档,请查看IronPDF 性能技巧。
如何在自动化测试中验证 PDF 内容?
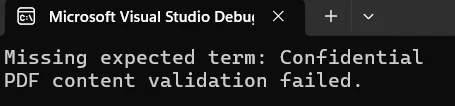
检查文档是否包含正确的术语是最常见的测试场景。 以下帮助方法接受文件路径和所需条款数组,随后返回false,当任何预期条款缺失时:
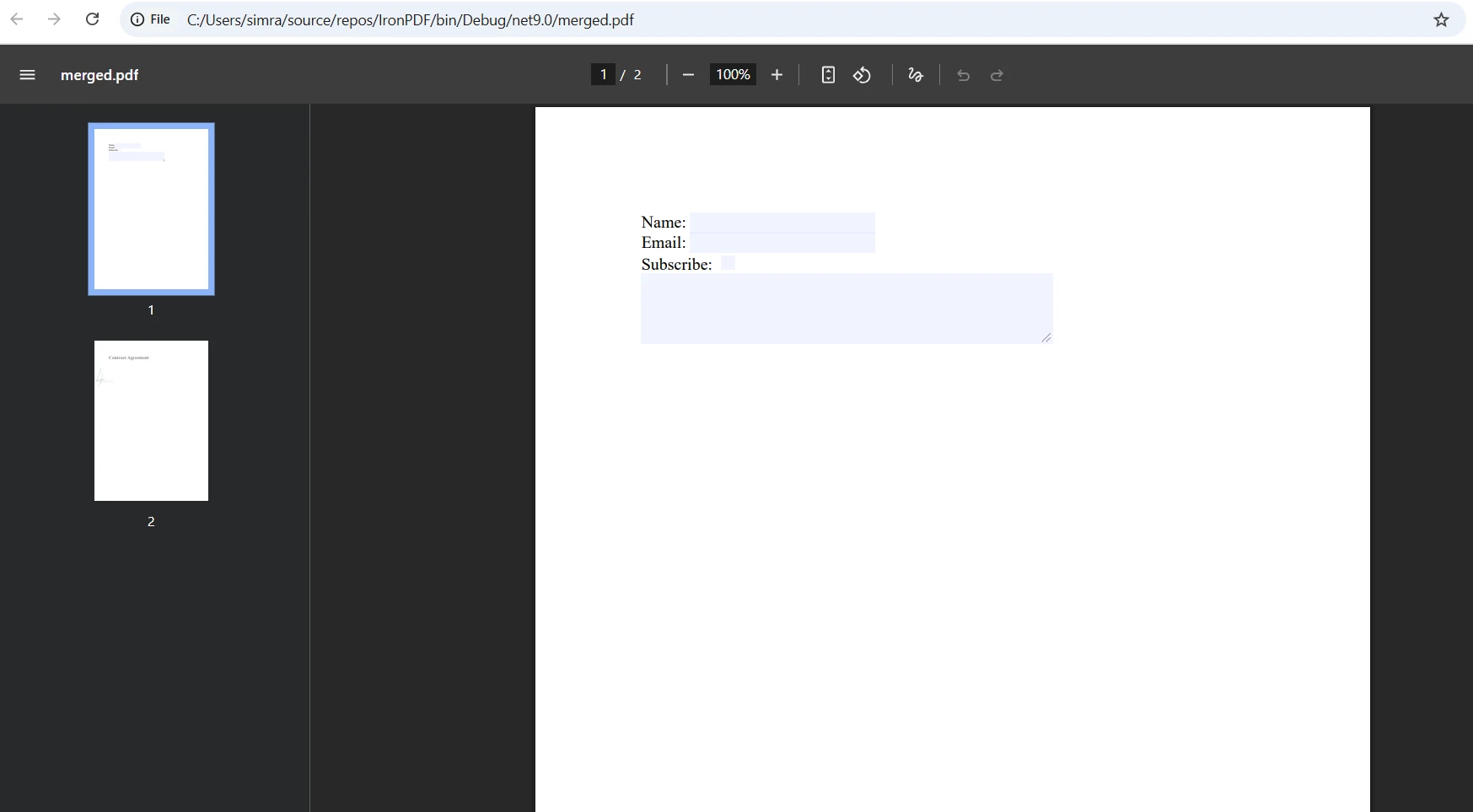
bool ValidatePdfContent(string pdfPath, string[] expectedTerms)
{
var pdf = PdfDocument.FromFile(pdfPath);
string fullText = pdf.ExtractAllText();
// Verify each required term
foreach (string term in expectedTerms)
{
if (!fullText.Contains(term, StringComparison.OrdinalIgnoreCase))
{
Console.WriteLine($"Missing expected term: {term}");
return false;
}
}
// Validate first-page structure
if (pdf.PageCount > 0)
{
string firstPageText = pdf.ExtractTextFromPage(0);
if (!firstPageText.Contains("Invoice #") && !firstPageText.Contains("Date:"))
{
Console.WriteLine("Header validation failed");
return false;
}
}
return true;
}bool ValidatePdfContent(string pdfPath, string[] expectedTerms)
{
var pdf = PdfDocument.FromFile(pdfPath);
string fullText = pdf.ExtractAllText();
// Verify each required term
foreach (string term in expectedTerms)
{
if (!fullText.Contains(term, StringComparison.OrdinalIgnoreCase))
{
Console.WriteLine($"Missing expected term: {term}");
return false;
}
}
// Validate first-page structure
if (pdf.PageCount > 0)
{
string firstPageText = pdf.ExtractTextFromPage(0);
if (!firstPageText.Contains("Invoice #") && !firstPageText.Contains("Date:"))
{
Console.WriteLine("Header validation failed");
return false;
}
}
return true;
}Imports System
Function ValidatePdfContent(pdfPath As String, expectedTerms As String()) As Boolean
Dim pdf = PdfDocument.FromFile(pdfPath)
Dim fullText As String = pdf.ExtractAllText()
' Verify each required term
For Each term As String In expectedTerms
If Not fullText.Contains(term, StringComparison.OrdinalIgnoreCase) Then
Console.WriteLine($"Missing expected term: {term}")
Return False
End If
Next
' Validate first-page structure
If pdf.PageCount > 0 Then
Dim firstPageText As String = pdf.ExtractTextFromPage(0)
If Not firstPageText.Contains("Invoice #") AndAlso Not firstPageText.Contains("Date:") Then
Console.WriteLine("Header validation failed")
Return False
End If
End If
Return True
End FunctionStringComparison.OrdinalIgnoreCase防止由于生成文档中的大小写差异而导致测试失败。 IronPDF 在提取过程中保留文本布局和格式,因此位置验证(例如确认标题字段出现在第一页)在不同的 PDF 生成器中都能可靠地工作。
对于更高级的场景,例如从 PDF 文件中提取表格、提取嵌入的图像或读取交互式表单字段,IronPDF 为每个任务提供了专用 API。 当您的测试套件需要在验证之前组装或拆分文档时,您还可以将文本提取与PDF 合并或拆分工作流程链接起来。
输入
输出
使用 Selenium 进行 PDF 测试的最佳实践是什么?
从一开始就应用一些模式,可以使你的 PDF 测试套件在项目发展过程中保持可维护性。
使用显式等待而非固定延迟。 用文件系统监视器或轮询循环替换Thread.Sleep(),以检查文件是否存在。 Selenium 的显式等待文档涵盖了浏览器端的等待策略,同样的原理也适用于下载。 在速度较慢的持续集成机器上,固定延迟很容易失效。
将PDF操作集中在基础类中。 创建一个共享的帮助或基础测试类,公开方法如ValidateTerms。 这样,各个测试就能专注于断言,而不是 PDF 底层实现。 这与 IronPDF 本身在HTML 到 PDF 转换和其他核心操作中遵循的模式相呼应。
每次测试后清理下载的文件。 在finally块或拆卸方法中调用File.Delete(),以免临时PDF在磁盘上积累。 这在并行测试运行中尤为重要,因为多个文件可能会同时落入同一目录。
无需任何更改即可跨平台运行测试。IronPDF无需条件编译即可在 Windows、Linux 和 macOS 上运行。 同一个测试程序集在本地运行后,也能在基于 Linux 的 CI 代理上正确执行。 有关 Docker 特定配置,请参阅跨平台部署指南。
不要将密码纳入源代码控制系统。处理受保护的 PDF 文件时,应从环境变量或密钥管理器中读取凭据,而不是将其硬编码到代码中。 IronPDF的PdfDocument.FromFile(path, password)重载在加载时接受密码,因此调用站点保持整洁。 IronPDF 许可页面涵盖了生产部署的团队和企业许可。
将文本提取限定在所需页面。 ExtractTextFromPage()针对包含您要验证的数据的页面。 这样可以减少内存使用,加快测试执行速度。 有关完整的方法签名,请参阅API 参考文档以进行文本提取。

IronPDF 与其他 .NET PDF 库相比如何?
| 特征 | IronPDF | iText | PdfPig |
|---|---|---|---|
| 从 URL 加载 PDF | 是的——单方法调用 | 需要手动下载 HTTP 链接 | 需要手动下载 HTTP 链接 |
| 提取所有文本 | 是的 -- `ExtractAllText()` | 是的——多步骤 | 是的——多步骤 |
| 页面级提取 | 是的 -- `ExtractTextFromPage(n)` | 是 | 是 |
| 带密码保护的 PDF | 是的——参数过载 | 是 | 数量有限 |
| .NET 10 支持 | 是 | 部分的 | 是 |
| HTML 转 PDF 生成 | 是 | 数量有限 | 无 |
| 跨平台(Linux、macOS) | 是 | 是 | 是 |
| 许可证类型 | 提供免费试用的商业广告 | AGPL / 商业用途 | 麻省理工学院 |
IronPDF 的直接 URL 加载和单一方法文本提取使其在测试自动化环境中具有明显的优势,因为在测试自动化环境中,开发速度至关重要。 对于需要从 HTML 生成 PDF或在同一工作流程中操作现有文档的团队来说,使用一个库来处理这两个任务可以大大简化依赖关系树。 像 PdfPig 这样的开源替代方案对于简单的提取需求来说比较合适,但它们需要更多的设置来处理 URL 加载,并且不提供内置的 PDF 生成功能。
如何开始免费试用?
IronPDF 提供功能齐全的免费试用版,因此您可以在购买许可证之前在测试环境中验证该库。 试用期间,水印限制不会影响文本提取或验证工作流程。
开始使用:
- 安装NuGet包:
dotnet add package IronPdf - 将
using IronPdf;添加到您的测试文件中。 - 调用
PdfDocument.FromFile()并开始提取文本。
访问IronPDF 免费试用页面下载试用密钥。 对于团队或企业部署,请查看IronPDF 许可选项,找到适合您需求的方案。
可加快设置速度的其他资源:
常见问题解答
为什么 Selenium WebDriver 不能直接读取 PDF 文件?
Selenium WebDriver 设计用于与作为 DOM 一部分的网页元素进行交互。然而,PDF 文件是以二进制流的形式呈现的,而不是 DOM 元素,因此 Selenium 无法与其内容直接交互。
IronPDF 如何帮助在 Selenium WebDriver 中读取 PDF 文件?
IronPDF 与 Selenium WebDriver 无缝集成,让您无需复杂设置或多个库即可提取文本并验证 PDF 数据。这大大简化了流程,提高了测试效率。
using IronPDF 和 Selenium 进行 PDF 测试有什么好处?
将 IronPDF 与 Selenium 结合使用可简化 PDF 处理,使开发人员只需使用最少的代码就能从 PDF 中提取和验证文本。这减少了对额外配置或外部库的需求,使处理过程更快、更高效。
using IronPDF 进行 C# PDF 测试是否需要使用其他库?
不,IronPDF 提供了一个全面的解决方案,可处理 PDF 提取和验证,无需在 C# 项目中使用多个库或进行复杂的配置。
IronPDF 能否处理现代网络应用程序生成的 PDF 文件?
是的,IronPDF 对现代网络应用程序生成的新 PDF 文档特别有效,可以实现高效的文本提取和数据验证。
是什么让 IronPDF 成为 Selenium PDF 自动化的强大工具?
IronPDF 的强大功能使其能够与 Selenium WebDriver 集成,提供了一种管理 PDF 文件的有效方式。它简化了在自动测试中直接读取和验证 PDF 内容的过程。
IronPDF 与 Apache PDFBox 等 Java 解决方案相比有何优势?
IronPDF for Java 解决方案可能需要多个导入语句和库,与之不同的是,IronPDF 提供了一种精简的方法,可直接与 C# 项目集成,简化 Selenium 中的 PDF 测试过程。
IronPDF 是否与 Selenium WebDriver in C# 兼容?
是的,IronPDF 可与 C# 中的 Selenium WebDriver 无缝协作,为在自动化测试中读取和验证 PDF 文件提供了强大的解决方案。
IronPDF 可帮助解决 PDF 自动测试中的哪些难题?
IronPDF 解决了在自动测试中访问和验证 PDF 内容的难题,无需使用多个库和复杂的设置,并提供了与 Selenium WebDriver 兼容的直接解决方案。
IronPDF 如何提高自动化测试工作流程的效率?
通过与 Selenium WebDriver 集成,IronPDF 简化了提取文本和验证 PDF 数据的过程,降低了自动化测试工作流程的复杂性并缩短了所需时间。











