
.NET CoreでPDFジェネレーターを作成する方法
PDFドキュメントは自動テストにおいて独特の課題を伴います。Selenium WebDriverはWeb要素とのやり取りに優れていますが、PDFファイルはDOM要素ではなくバイナリストリームとしてレンダリングされるため、PDF内のコンテンツを読み取ることができません。この記事では、SeleniumとIronPDFを組み合わせることで、C#でこの問題を解決する方法を紹介します。IronPDFは、実稼働環境に対応した.NET PDFライブラリであり、わずか数行のコードでPDFコンテンツを抽出、検証、処理できます。Javaのような複雑な依存関係管理は必要ありません。
Selenium が PDF コンテンツの処理に苦労するのはなぜですか?
ブラウザで PDF を開くと、Selenium はページに移動してブラウザ コントロールを操作できますが、ドキュメント内のテキストやデータを照会することはできません。 PDF は、 WebDriver プロトコルが通過できる HTML 要素としてではなく、埋め込みオブジェクトまたはプラグインとしてレンダリングされます。 ブラウザの PDF ビューアはドキュメントを視覚的にレンダリングしますが、Selenium が検査できるアクセス可能な DOM がないため、すべての XPath クエリまたは CSS セレクタは何も返しません。
従来の回避策では、ファイルをディスクにダウンロードし、別の解析ライブラリを呼び出して、すべてを手動で接続する必要がありました。 この複数ステップのプロセスにより、複雑さが増し、脆弱なテスト コードが作成され、ファイル パスとアクセス許可の制御が困難になる CI/CD パイプラインが複雑になります。 IronPDF を使用すると、URL またはローカル パスから PDF をロードし、1 回の呼び出しでそのテキストを抽出できるため、中間ファイルや構成を使用せずに、既存 for .NETテスト プロジェクト内で直接、これらの手順をすべて省略できます。
実際の結果として、テスト コードは短くなり、読みやすくなり、テスト環境が変更されても壊れる可能性が大幅に低くなります。 テキスト抽出以外のIronPDF の機能について詳しくは、 IronPDFドキュメント ハブをご覧ください。

Selenium テスト用にIronPDFをインストールするにはどうすればよいでしょうか?
必要なパッケージを配置するには 1 分もかかりません。 Visual StudioでPackage Manager Consoleを開き、実行してください:
Install-Package IronPdf
プロジェクトにまだ Selenium パッケージが含まれていない場合は、それも必要になります。
Install-Package Selenium.WebDriver
Install-Package Selenium.WebDriver.ChromeDriverInstall-Package Selenium.WebDriver
Install-Package Selenium.WebDriver.ChromeDriver
パッケージがインストールされたら、テスト ファイルの先頭に次の using ディレクティブを追加します。
using IronPdf;
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
using System.IO;using IronPdf;
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
using System.IO;Imports IronPdf
Imports OpenQA.Selenium
Imports OpenQA.Selenium.Chrome
Imports System.IOIronPDF は.NET 10 を対象としており、Windows、Linux、macOS のクロスプラットフォームで動作するため、Docker コンテナーやクラウド CI エージェントを含むすべての環境で同じテスト コードが実行されます。
URL から直接 PDF を読み取るにはどうすればよいでしょうか?
URL から PDF コンテンツを読み取ると、ダウンロード手順が完全にスキップされます。 Selenium がリンクを見つけ、 IronPDF がドキュメントを読み込むと、わずか数行でアサーションに使用できる完全なテキストが得られます。
// Initialize Chrome driver
var driver = new ChromeDriver();
// Navigate to a webpage containing a PDF link
driver.Navigate().GoToUrl("https://ironpdf.com/");
// Find and capture the PDF URL
IWebElement pdfLink = driver.FindElement(By.CssSelector("a[href$='.pdf']"));
string pdfUrl = pdfLink.GetAttribute("href");
// Load the PDF directly from the URL -- no download needed
var pdf = PdfDocument.FromUrl(new Uri(pdfUrl));
string extractedText = pdf.ExtractAllText();
// Assert expected content
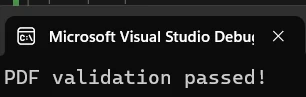
if (extractedText.Contains("IronPDF"))
{
Console.WriteLine("PDF validation passed!");
}
driver.Quit();// Initialize Chrome driver
var driver = new ChromeDriver();
// Navigate to a webpage containing a PDF link
driver.Navigate().GoToUrl("https://ironpdf.com/");
// Find and capture the PDF URL
IWebElement pdfLink = driver.FindElement(By.CssSelector("a[href$='.pdf']"));
string pdfUrl = pdfLink.GetAttribute("href");
// Load the PDF directly from the URL -- no download needed
var pdf = PdfDocument.FromUrl(new Uri(pdfUrl));
string extractedText = pdf.ExtractAllText();
// Assert expected content
if (extractedText.Contains("IronPDF"))
{
Console.WriteLine("PDF validation passed!");
}
driver.Quit();Imports OpenQA.Selenium
Imports OpenQA.Selenium.Chrome
Imports IronPdf
' Initialize Chrome driver
Dim driver As IWebDriver = New ChromeDriver()
' Navigate to a webpage containing a PDF link
driver.Navigate().GoToUrl("https://ironpdf.com/")
' Find and capture the PDF URL
Dim pdfLink As IWebElement = driver.FindElement(By.CssSelector("a[href$='.pdf']"))
Dim pdfUrl As String = pdfLink.GetAttribute("href")
' Load the PDF directly from the URL -- no download needed
Dim pdf As PdfDocument = PdfDocument.FromUrl(New Uri(pdfUrl))
Dim extractedText As String = pdf.ExtractAllText()
' Assert expected content
If extractedText.Contains("IronPDF") Then
Console.WriteLine("PDF validation passed!")
End If
driver.Quit()PdfDocument.FromUrl() はメモリ内でドキュメントを取得して解析します。 ExtractAllText() 呼び出しは、すべてのページからのテキストを単一の文字列として返し、アサーションの準備をします。 パスワードで保護されたドキュメントの場合は、テスト中に保護されたファイルにアクセスできるように、資格情報を追加パラメータとして渡します。 テキスト抽出オプションの詳細については、 IronPDFテキスト抽出ガイドを参照してください。
出力
PDF を自動的にダウンロードして処理するにはどうすればよいですか?
認証後または動的ワークフローを通じて PDF が生成される場合、最初にダウンロードすることが唯一のオプションとなる可能性があります。 Chrome を設定して PDF を既知のディレクトリに自動ダウンロードし、ファイル パスをIronPDFに渡します。
// Configure Chrome to auto-download PDFs
var chromeOptions = new ChromeOptions();
chromeOptions.AddUserProfilePreference("download.default_directory", @"C:\PDFTests");
chromeOptions.AddUserProfilePreference("plugins.always_open_pdf_externally", true);
var driver = new ChromeDriver(chromeOptions);
string appUrl = "https://example.com/reports";
// Trigger the download
driver.Navigate().GoToUrl(appUrl);
driver.FindElement(By.Id("downloadReport")).Click();
// Wait for the download -- replace Thread.Sleep with a file-system watcher in production tests
System.Threading.Thread.Sleep(3000);
// Read the downloaded PDF
string pdfPath = @"C:\PDFTests\report.pdf";
var pdf = PdfDocument.FromFile(pdfPath);
string content = pdf.ExtractAllText();
// Validate specific data
bool hasExpectedData = content.Contains("Quarterly Revenue: $1.2M");
Console.WriteLine($"Revenue data found: {hasExpectedData}");
// Extract text from a specific page (zero-indexed)
string page2Content = pdf.ExtractTextFromPage(1);
// Clean up
File.Delete(pdfPath);
driver.Quit();// Configure Chrome to auto-download PDFs
var chromeOptions = new ChromeOptions();
chromeOptions.AddUserProfilePreference("download.default_directory", @"C:\PDFTests");
chromeOptions.AddUserProfilePreference("plugins.always_open_pdf_externally", true);
var driver = new ChromeDriver(chromeOptions);
string appUrl = "https://example.com/reports";
// Trigger the download
driver.Navigate().GoToUrl(appUrl);
driver.FindElement(By.Id("downloadReport")).Click();
// Wait for the download -- replace Thread.Sleep with a file-system watcher in production tests
System.Threading.Thread.Sleep(3000);
// Read the downloaded PDF
string pdfPath = @"C:\PDFTests\report.pdf";
var pdf = PdfDocument.FromFile(pdfPath);
string content = pdf.ExtractAllText();
// Validate specific data
bool hasExpectedData = content.Contains("Quarterly Revenue: $1.2M");
Console.WriteLine($"Revenue data found: {hasExpectedData}");
// Extract text from a specific page (zero-indexed)
string page2Content = pdf.ExtractTextFromPage(1);
// Clean up
File.Delete(pdfPath);
driver.Quit();Imports OpenQA.Selenium
Imports OpenQA.Selenium.Chrome
Imports System.IO
Imports System.Threading
' Configure Chrome to auto-download PDFs
Dim chromeOptions As New ChromeOptions()
chromeOptions.AddUserProfilePreference("download.default_directory", "C:\PDFTests")
chromeOptions.AddUserProfilePreference("plugins.always_open_pdf_externally", True)
Dim driver As New ChromeDriver(chromeOptions)
Dim appUrl As String = "https://example.com/reports"
' Trigger the download
driver.Navigate().GoToUrl(appUrl)
driver.FindElement(By.Id("downloadReport")).Click()
' Wait for the download -- replace Thread.Sleep with a file-system watcher in production tests
Thread.Sleep(3000)
' Read the downloaded PDF
Dim pdfPath As String = "C:\PDFTests\report.pdf"
Dim pdf = PdfDocument.FromFile(pdfPath)
Dim content As String = pdf.ExtractAllText()
' Validate specific data
Dim hasExpectedData As Boolean = content.Contains("Quarterly Revenue: $1.2M")
Console.WriteLine($"Revenue data found: {hasExpectedData}")
' Extract text from a specific page (zero-indexed)
Dim page2Content As String = pdf.ExtractTextFromPage(1)
' Clean up
File.Delete(pdfPath)
driver.Quit()plugins.always_open_pdf_externally の設定はChromeの内蔵PDFビューアをバイパスし、ファイルをブラウザで開くのではなくディスクに保存します。 ExtractTextFromPage() は、異なる検証データが多ページのレポートの異なるページに現れるときにページレベルの精度を提供します。 大きなドキュメントを効率的に処理するには、 IronPDF のパフォーマンスのヒントを確認してください。
自動テストで PDF コンテンツを検証するにはどうすればよいですか?
ドキュメントに適切な用語が含まれているかどうかを確認することが、最も一般的なテスト シナリオです。 以下のヘルパーメソッドはファイルパスと必須用語の配列を受け取り、期待される用語が欠けたタイミングで false を返します。
bool ValidatePdfContent(string pdfPath, string[] expectedTerms)
{
var pdf = PdfDocument.FromFile(pdfPath);
string fullText = pdf.ExtractAllText();
// Verify each required term
foreach (string term in expectedTerms)
{
if (!fullText.Contains(term, StringComparison.OrdinalIgnoreCase))
{
Console.WriteLine($"Missing expected term: {term}");
return false;
}
}
// Validate first-page structure
if (pdf.PageCount > 0)
{
string firstPageText = pdf.ExtractTextFromPage(0);
if (!firstPageText.Contains("Invoice #") && !firstPageText.Contains("Date:"))
{
Console.WriteLine("Header validation failed");
return false;
}
}
return true;
}bool ValidatePdfContent(string pdfPath, string[] expectedTerms)
{
var pdf = PdfDocument.FromFile(pdfPath);
string fullText = pdf.ExtractAllText();
// Verify each required term
foreach (string term in expectedTerms)
{
if (!fullText.Contains(term, StringComparison.OrdinalIgnoreCase))
{
Console.WriteLine($"Missing expected term: {term}");
return false;
}
}
// Validate first-page structure
if (pdf.PageCount > 0)
{
string firstPageText = pdf.ExtractTextFromPage(0);
if (!firstPageText.Contains("Invoice #") && !firstPageText.Contains("Date:"))
{
Console.WriteLine("Header validation failed");
return false;
}
}
return true;
}Imports System
Function ValidatePdfContent(pdfPath As String, expectedTerms As String()) As Boolean
Dim pdf = PdfDocument.FromFile(pdfPath)
Dim fullText As String = pdf.ExtractAllText()
' Verify each required term
For Each term As String In expectedTerms
If Not fullText.Contains(term, StringComparison.OrdinalIgnoreCase) Then
Console.WriteLine($"Missing expected term: {term}")
Return False
End If
Next
' Validate first-page structure
If pdf.PageCount > 0 Then
Dim firstPageText As String = pdf.ExtractTextFromPage(0)
If Not firstPageText.Contains("Invoice #") AndAlso Not firstPageText.Contains("Date:") Then
Console.WriteLine("Header validation failed")
Return False
End If
End If
Return True
End FunctionStringComparison.OrdinalIgnoreCase により、生成されたドキュメントの大文字小文字の違いによるテストの破損が防がれます。 IronPDF は抽出中にテキストのレイアウトと書式を保持するため、位置検証 (ヘッダー フィールドが 1 ページ目に表示されるか確認するなど) はさまざまな PDF ジェネレーター間で確実に機能します。
PDF ファイルから表を抽出したり、埋め込まれた画像を取り出したり、インタラクティブなフォーム フィールドを読み取ったりするなど、より高度なシナリオでは、 IronPDF は各タスク専用の API を提供します。 テスト スイートで検証前にドキュメントをアセンブルまたは分解する必要がある場合は、テキスト抽出をPDF の結合または分割ワークフローと連鎖させることもできます。
入力
出力
Selenium を使用した PDF テストのベストプラクティスは何ですか?
最初からいくつかのパターンを適用することで、プロジェクトの拡大に合わせて PDF テスト スイートを保守しやすくなります。
固定の遅延ではなく明示的な待機を使用してください。 Thread.Sleep() をファイルシステムウォッチャーやポーリングループに置き換えて、ファイルの存在を確認してください。 Selenium の明示的な待機ドキュメントでは、ブラウザ側の待機戦略について説明されており、同じ原則がダウンロードにも適用されます。 固定遅延は、低速の CI マシンでは脆弱です。
PDF操作を基底クラスに集中させる。 LoadPdfFromUrl, DownloadPdf, ValidateTerms などのメソッドを公開する共有ヘルパーや基底テストクラスを作成してください。 個々のテストは、PDF 配管ではなくアサーションに重点を置きます。 これは、HTML から PDF への変換やその他のコア操作でIronPDF自体が従うパターンを反映しています。
各テストの後にダウンロードしたファイルをクリーンアップする。 File.Delete() をfinallyブロックや解体メソッドで呼び出し、一時的なPDFがディスクに蓄積しないようにしてください。 これは、複数のファイルが同時に同じディレクトリに格納される可能性がある並列テスト実行では特に重要です。
変更なしでクロスプラットフォームでテストを実行できます。IronPDFは条件付きコンパイルなしで Windows、Linux、macOS で動作します。 ローカルで実行される同じテスト アセンブリは、Linux ベースの CI エージェントでも正しく実行されます。 Docker固有の設定については、クロスプラットフォーム展開ガイドを参照してください。
パスワードはソース管理から除外してください。保護されたPDFを扱う際は、資格情報をハードコードするのではなく、環境変数やシークレットマネージャーから読み取りましょう。 IronPDFの PdfDocument.FromFile(path, password) オーバーロードは読み込み時にパスワードを受け取り、呼び出し元を綺麗に保ちます。 IronPDF のライセンス ページでは、本番環境展開向けのチーム ライセンスとエンタープライズ ライセンスについて説明します。
必要なページにテキスト抽出を限定する。 ExtractAllText() は小さなドキュメントに便利ですが、大規模な多ページPDFの場合は検証するデータが含まれるページに対してのみ ExtractTextFromPage() を呼び出すことを検討してください。 これにより、メモリ使用量が削減され、テストの実行が高速化されます。 完全なメソッド シグネチャについては、テキスト抽出の API リファレンスを参照してください。

IronPDF は.NET用の他の PDF ライブラリと比べてどうですか?
| 特徴 | IronPDF | iText | PdfPig |
|---|---|---|---|
| URLからPDFを読み込む | はい - 単一のメソッド呼び出し | 手動のHTTPダウンロードが必要です | 手動のHTTPダウンロードが必要です |
| すべてのテキストを抽出 | はい -- `ExtractAllText()` | はい -- 複数ステップ | はい -- 複数ステップ |
| ページレベルの抽出 | はい -- `ExtractTextFromPage(n)` | はい | はい |
| パスワード保護された PDF | はい -- パラメータオーバーロード | はい | 制限あり |
| IronWordを.NETプロジェクトにインストールし、Windows環境でWordドキュメントを作成・編集します。 | はい | 部分的 | はい |
| HTMLからPDFへの生成 | はい | 制限あり | なし |
| クロスプラットフォーム(Linux、macOS) | はい | はい | はい |
| ライセンスの種類 | 無料トライアル付きの商用 | AGPL / 商用 | マサチューセッツ工科大学 |
IronPDF の直接 URL 読み込みと単一メソッドのテキスト抽出により、開発速度が重要となるテスト自動化のコンテキストで明らかな利点が得られます。 同じワークフロー内でHTML から PDF を生成したり、既存のドキュメントを操作したりする必要があるチームの場合、1 つのライブラリで両方のタスクを処理すると、依存関係ツリーが大幅に簡素化されます。 PdfPig のようなオープンソースの代替品は、単純な抽出のニーズには適していますが、URL の読み込みを処理するために追加の設定が必要であり、PDF 生成機能は組み込まれていません。
無料トライアルを始めるにはどうすればいいですか?
IronPDF はフル機能の無料トライアルを提供しているので、ライセンスを購入する前にテスト環境でライブラリを検証できます。 試用期間中、透かしの制限はテキスト抽出や検証ワークフローに影響しません。
開始するには:
- NuGetパッケージをインストールします:
dotnet add package IronPdf - あなたのテストファイルに
using IronPdf;を追加してください。 PdfDocument.FromUrl()またはPdfDocument.FromFile()を呼び出し、テキスト抽出を開始してください。
試用キーをダウンロードするには、 IronPDF の無料試用ページにアクセスしてください。 チームまたはエンタープライズ展開の場合は、 IronPDF のライセンス オプションを確認して、ニーズに合ったプランを見つけてください。
セットアップを加速するための追加リソース:
よくある質問
なぜSelenium WebDriverはPDFファイルを直接読めないのですか?
Selenium WebDriverは、DOMの一部であるWeb要素と対話するように設計されています。しかし、PDFファイルはDOM要素ではなくバイナリストリームとしてレンダリングされるため、Seleniumはそのコンテンツと直接対話することができません。
IronPDFはSelenium WebDriverでPDFファイルを読むのにどのように役立ちますか?
IronPDFはSelenium WebDriverとシームレスに統合され、複雑なセットアップや複数のライブラリを必要とせずにテキストを抽出し、PDFデータを検証することができます。これはプロセスを大幅に簡素化し、テストの効率を高めます。
PDFテストのためにSeleniumとIronPDFを使う利点は何ですか?
IronPDFとSeleniumを使うことで、開発者は最小限のコードでPDFからテキストを抽出し、検証することができます。これにより、追加設定や外部ライブラリの必要性が減り、プロセスがより速く効率的になります。
C#でのPDFテストのためにIronPDFで追加のライブラリを使用する必要はありますか?
IronPDFはPDFの抽出と検証を行う包括的なソリューションを提供し、C#プロジェクトで複数のライブラリや複雑な設定を必要としません。
IronPDFは最新のウェブアプリケーションによって生成されたPDFファイルを扱うことができますか?
IronPDFは最新のウェブアプリケーションによって生成された新しいPDFドキュメントに特に効果的で、効率的なテキスト抽出とデータ検証を可能にします。
IronPDFがSeleniumでのPDF自動化のための強力なツールである理由は何ですか?
IronPDFの強力な機能はSelenium WebDriverとの統合を可能にし、PDFファイルを管理する効率的な方法を提供します。自動化されたテスト内でPDFコンテンツを直接読み込んで検証するプロセスを簡素化します。
IronPDFはApache PDFBoxのようなJavaソリューションと比較してどうですか?
複数のimport文やライブラリを必要とするJavaソリューションとは異なり、IronPDFはC#プロジェクトと直接統合する合理的なアプローチを提供し、SeleniumでのPDFテストプロセスを簡素化します。
IronPDFはC#のSelenium WebDriverと互換性がありますか?
IronPDFはC#のSelenium WebDriverとシームレスに動作するように設計されており、自動テストでPDFファイルを読み込んで検証するための堅牢なソリューションを提供します。
IronPDFは自動PDFテストにおいてどのような課題を解決しますか?
IronPDFは自動テストでPDFコンテンツにアクセスし検証するという課題に取り組み、複数のライブラリや複雑なセットアップの必要性をなくし、Selenium WebDriverと互換性のある簡単なソリューションを提供します。
IronPDFは自動テストワークフローの効率をどのように改善できますか?
IronPDFはSelenium WebDriverと統合することで、テキストの抽出とPDFデータの検証プロセスを簡素化し、自動テストワークフローに必要な複雑さと時間を削減します。











