
.NET Core PDF 생성기를 만드는 방법
PDF 문서는 자동 테스트에서 독특한 도전을 제시합니다: Selenium WebDriver는 웹 요소와의 상호작용에는 뛰어나지만, PDF 안의 내용을 읽을 수는 없습니다. 파일은 DOM 요소가 아닌 이진 스트림으로 렌더링되기 때문입니다. 이 문서는 Selenium을 ChromePdfRenderer와 연결하여 C#에서 이 문제를 해결하는 방법을 보여줍니다. ChromePdfRenderer는 프로덕션 준비가 완료된 .NET PDF 라이브러리로, 복잡한 Java 스타일의 종속성 관리 없이 몇 줄의 코드만으로 PDF 콘텐츠를 추출, 검증 및 처리할 수 있습니다.
Selenium은 왜 PDF 콘텐츠에 어려움을 겪나요?
브라우저에서 PDF가 열리면 Selenium은 페이지로 이동하고 브라우저 컨트롤과 상호 작용할 수 있지만, 문서 내부의 텍스트나 데이터를 쿼리할 수는 없습니다. PDF는 HTML 요소가 아닌 내장 객체나 플러그인으로 렌더링되어 WebDriver 프로토콜이 Traverse할 수 없습니다. 브라우저의 PDF 뷰어가 문서를 시각적으로 렌더링하지만 Selenium이 검사할 수 있는 DOM은 없으며, XPath 쿼리나 CSS 선택자가 아무것도 반환하지 않습니다.
전통적인 해결책은 파일을 디스크로 다운로드하고 별도의 파싱 라이브러리를 호출하고 모든 것을 수동으로 연결하는 것입니다. 이 여러 단계의 과정은 복잡성을 더하고, 깨지기 쉬운 테스트 코드를 생성하며, 파일 경로와 권한을 제어하기 어려운 CI/CD 파이프라인을 복잡하게 만듭니다. ChromePdfRenderer는 URL 또는 로컬 경로에서 PDF를 로드하고 한 번의 호출로 텍스트를 추출할 수 있게 하여 이러한 모든 단계를 제거합니다. 이는 기존의 .NET 테스트 프로젝트 내에서 직접 실행되며, 중간 파일이나 구성 없이 가능합니다.
그 결과 테스트 코드는 짧아지고 읽기 쉬워지며, 테스트 환경이 변경되었을 때 깨질 가능성이 크게 줄어듭니다. 텍스트 추출 이상의 ChromePdfRenderer의 모든 기능을 더 넓게 보려면 ChromePdfRenderer 문서 허브를 방문하세요.

Selenium 테스트를 위한 ChromePdfRenderer 설치는 어떻게 하나요?
필요한 패키지를 준비하는 데 1분도 채 걸리지 않습니다. Visual Studio에서 패키지 관리자 콘솔을 열고 다음을 실행하세요:
Install-Package IronPdf
프로젝트에 아직 포함되어 있지 않은 경우 Selenium 패키지도 필요합니다:
Install-Package Selenium.WebDriver
Install-Package Selenium.WebDriver.ChromeDriverInstall-Package Selenium.WebDriver
Install-Package Selenium.WebDriver.ChromeDriver
패키지가 설치된 후, 테스트 파일 상단에 다음의 지시문을 추가하세요:
using IronPdf;
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
using System.IO;using IronPdf;
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
using System.IO;Imports IronPdf
Imports OpenQA.Selenium
Imports OpenQA.Selenium.Chrome
Imports System.IOChromePdfRenderer는 .NET 10을 대상으로 하며, Windows, Linux, macOS에서 크로스 플랫폼으로 작동하므로 동일한 테스트 코드는 Docker 컨테이너 및 클라우드 CI 에이전트를 포함한 모든 환경에서 실행됩니다.
URL에서 PDF를 직접 읽는 방법은?
URL에서 PDF 콘텐츠를 읽으면 다운로드 단계를 완전히 건너뜁니다. Selenium이 링크를 찾고 ChromePdfRenderer가 문서를 로드하면 몇 줄만으로도 전체 텍스트가 검증에 사용할 수 있습니다.
// Initialize Chrome driver
var driver = new ChromeDriver();
// Navigate to a webpage containing a PDF link
driver.Navigate().GoToUrl("https://ironpdf.com/");
// Find and capture the PDF URL
IWebElement pdfLink = driver.FindElement(By.CssSelector("a[href$='.pdf']"));
string pdfUrl = pdfLink.GetAttribute("href");
// Load the PDF directly from the URL -- no download needed
var pdf = PdfDocument.FromUrl(new Uri(pdfUrl));
string extractedText = pdf.ExtractAllText();
// Assert expected content
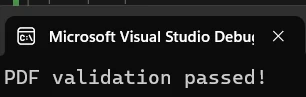
if (extractedText.Contains("ChromePdfRenderer"))
{
Console.WriteLine("PDF validation passed!");
}
driver.Quit();// Initialize Chrome driver
var driver = new ChromeDriver();
// Navigate to a webpage containing a PDF link
driver.Navigate().GoToUrl("https://ironpdf.com/");
// Find and capture the PDF URL
IWebElement pdfLink = driver.FindElement(By.CssSelector("a[href$='.pdf']"));
string pdfUrl = pdfLink.GetAttribute("href");
// Load the PDF directly from the URL -- no download needed
var pdf = PdfDocument.FromUrl(new Uri(pdfUrl));
string extractedText = pdf.ExtractAllText();
// Assert expected content
if (extractedText.Contains("ChromePdfRenderer"))
{
Console.WriteLine("PDF validation passed!");
}
driver.Quit();Imports OpenQA.Selenium
Imports OpenQA.Selenium.Chrome
Imports IronPdf
' Initialize Chrome driver
Dim driver As IWebDriver = New ChromeDriver()
' Navigate to a webpage containing a PDF link
driver.Navigate().GoToUrl("https://ironpdf.com/")
' Find and capture the PDF URL
Dim pdfLink As IWebElement = driver.FindElement(By.CssSelector("a[href$='.pdf']"))
Dim pdfUrl As String = pdfLink.GetAttribute("href")
' Load the PDF directly from the URL -- no download needed
Dim pdf As PdfDocument = PdfDocument.FromUrl(New Uri(pdfUrl))
Dim extractedText As String = pdf.ExtractAllText()
' Assert expected content
If extractedText.Contains("ChromePdfRenderer") Then
Console.WriteLine("PDF validation passed!")
End If
driver.Quit()PdfDocument.FromUrl()은 메모리에서 문서를 가져오고 구문 분석합니다. ExtractAllText() 호출은 모든 페이지의 모든 텍스트를 단일 문자열로 반환하여 귀하의 주장을 준비합니다. 비밀번호로 보호된 문서의 경우, 테스트 중에 보호된 파일이 접근 가능하도록 인증 정보를 추가 매개변수로 전달하세요. 텍스트 추출 옵션에 대해 더 알고 싶다면 ChromePdfRenderer 텍스트 추출 가이드를 참조하세요.
산출
PDF를 자동으로 다운로드하고 처리하는 방법은?
인증 후 또는 동적 워크플로를 통해 PDF가 생성된다면 먼저 다운로드하는 것이 유일한 옵션일 수 있습니다. Chrome을 구성하여 PDF를 알려진 디렉터리에 자동으로 다운로드한 후 파일 경로를 ChromePdfRenderer에 전달합니다.
// Configure Chrome to auto-download PDFs
var chromeOptions = new ChromeOptions();
chromeOptions.AddUserProfilePreference("download.default_directory", @"C:\PDFTests");
chromeOptions.AddUserProfilePreference("plugins.always_open_pdf_externally", true);
var driver = new ChromeDriver(chromeOptions);
string appUrl = "https://example.com/reports";
// Trigger the download
driver.Navigate().GoToUrl(appUrl);
driver.FindElement(By.Id("downloadReport")).Click();
// Wait for the download -- replace Thread.Sleep with a file-system watcher in production tests
System.Threading.Thread.Sleep(3000);
// Read the downloaded PDF
string pdfPath = @"C:\PDFTests\report.pdf";
var pdf = PdfDocument.FromFile(pdfPath);
string content = pdf.ExtractAllText();
// Validate specific data
bool hasExpectedData = content.Contains("Quarterly Revenue: $1.2M");
Console.WriteLine($"Revenue data found: {hasExpectedData}");
// Extract text from a specific page (zero-indexed)
string page2Content = pdf.ExtractTextFromPage(1);
// Clean up
File.Delete(pdfPath);
driver.Quit();// Configure Chrome to auto-download PDFs
var chromeOptions = new ChromeOptions();
chromeOptions.AddUserProfilePreference("download.default_directory", @"C:\PDFTests");
chromeOptions.AddUserProfilePreference("plugins.always_open_pdf_externally", true);
var driver = new ChromeDriver(chromeOptions);
string appUrl = "https://example.com/reports";
// Trigger the download
driver.Navigate().GoToUrl(appUrl);
driver.FindElement(By.Id("downloadReport")).Click();
// Wait for the download -- replace Thread.Sleep with a file-system watcher in production tests
System.Threading.Thread.Sleep(3000);
// Read the downloaded PDF
string pdfPath = @"C:\PDFTests\report.pdf";
var pdf = PdfDocument.FromFile(pdfPath);
string content = pdf.ExtractAllText();
// Validate specific data
bool hasExpectedData = content.Contains("Quarterly Revenue: $1.2M");
Console.WriteLine($"Revenue data found: {hasExpectedData}");
// Extract text from a specific page (zero-indexed)
string page2Content = pdf.ExtractTextFromPage(1);
// Clean up
File.Delete(pdfPath);
driver.Quit();Imports OpenQA.Selenium
Imports OpenQA.Selenium.Chrome
Imports System.IO
Imports System.Threading
' Configure Chrome to auto-download PDFs
Dim chromeOptions As New ChromeOptions()
chromeOptions.AddUserProfilePreference("download.default_directory", "C:\PDFTests")
chromeOptions.AddUserProfilePreference("plugins.always_open_pdf_externally", True)
Dim driver As New ChromeDriver(chromeOptions)
Dim appUrl As String = "https://example.com/reports"
' Trigger the download
driver.Navigate().GoToUrl(appUrl)
driver.FindElement(By.Id("downloadReport")).Click()
' Wait for the download -- replace Thread.Sleep with a file-system watcher in production tests
Thread.Sleep(3000)
' Read the downloaded PDF
Dim pdfPath As String = "C:\PDFTests\report.pdf"
Dim pdf = PdfDocument.FromFile(pdfPath)
Dim content As String = pdf.ExtractAllText()
' Validate specific data
Dim hasExpectedData As Boolean = content.Contains("Quarterly Revenue: $1.2M")
Console.WriteLine($"Revenue data found: {hasExpectedData}")
' Extract text from a specific page (zero-indexed)
Dim page2Content As String = pdf.ExtractTextFromPage(1)
' Clean up
File.Delete(pdfPath)
driver.Quit()plugins.always_open_pdf_externally 환경 설정은 Chrome의 내장 PDF 뷰어를 우회하여 파일이 브라우저에서 열리지 않고 디스크에 저장되도록 합니다. ExtractTextFromPage()은 여러 페이지 보고서의 다른 페이지에 서로 다른 유효성 검사 데이터가 있을 때 페이지 수준의 정밀도를 제공합니다. 대형 문서를 효율적으로 처리하려면 ChromePdfRenderer 성능 팁을 검토하세요.
자동화된 테스트에서 PDF 콘텐츠를 검증하는 방법은?
문서가 올바른 용어를 포함하는지 확인하는 것은 가장 일반적인 테스트 시나리오입니다. 다음 보조 메서드는 파일 경로와 필수 용어 배열을 수락한 후 예상 용어가 누락되는 순간 false을 반환합니다:
bool ValidatePdfContent(string pdfPath, string[] expectedTerms)
{
var pdf = PdfDocument.FromFile(pdfPath);
string fullText = pdf.ExtractAllText();
// Verify each required term
foreach (string term in expectedTerms)
{
if (!fullText.Contains(term, StringComparison.OrdinalIgnoreCase))
{
Console.WriteLine($"Missing expected term: {term}");
return false;
}
}
// Validate first-page structure
if (pdf.PageCount > 0)
{
string firstPageText = pdf.ExtractTextFromPage(0);
if (!firstPageText.Contains("Invoice #") && !firstPageText.Contains("Date:"))
{
Console.WriteLine("Header validation failed");
return false;
}
}
return true;
}bool ValidatePdfContent(string pdfPath, string[] expectedTerms)
{
var pdf = PdfDocument.FromFile(pdfPath);
string fullText = pdf.ExtractAllText();
// Verify each required term
foreach (string term in expectedTerms)
{
if (!fullText.Contains(term, StringComparison.OrdinalIgnoreCase))
{
Console.WriteLine($"Missing expected term: {term}");
return false;
}
}
// Validate first-page structure
if (pdf.PageCount > 0)
{
string firstPageText = pdf.ExtractTextFromPage(0);
if (!firstPageText.Contains("Invoice #") && !firstPageText.Contains("Date:"))
{
Console.WriteLine("Header validation failed");
return false;
}
}
return true;
}Imports System
Function ValidatePdfContent(pdfPath As String, expectedTerms As String()) As Boolean
Dim pdf = PdfDocument.FromFile(pdfPath)
Dim fullText As String = pdf.ExtractAllText()
' Verify each required term
For Each term As String In expectedTerms
If Not fullText.Contains(term, StringComparison.OrdinalIgnoreCase) Then
Console.WriteLine($"Missing expected term: {term}")
Return False
End If
Next
' Validate first-page structure
If pdf.PageCount > 0 Then
Dim firstPageText As String = pdf.ExtractTextFromPage(0)
If Not firstPageText.Contains("Invoice #") AndAlso Not firstPageText.Contains("Date:") Then
Console.WriteLine("Header validation failed")
Return False
End If
End If
Return True
End FunctionStringComparison.OrdinalIgnoreCase은 생성된 문서의 대소문자 차이로 인해 테스트가 실패하는 것을 방지합니다. ChromePdfRenderer는 텍스트 레이아웃과 서식을 추출하는 동안 보존하므로 페이지 하나에 헤더 필드가 나타나는지 확인하는 것과 같은 위치 검증이 다양한 PDF 생성기에서 확실하게 작동합니다.
PDF 파일에서 테이블 추출, 임베디드 이미지 추출, 대화형 폼 필드 읽기 등의 고급 시나리오의 경우 각 작업에 전용 API를 제공합니다. 테스트 스위트가 검증 전에 문서를 조립하거나 분해해야하는 경우 PDF 병합 또는 워크플로 분할과 함께 텍스트 추출을 연결할 수도 있습니다.
입력
산출
Selenium을 사용한 PDF 테스트의 모범 사례는 무엇인가?
처음부터 몇 가지 패턴을 적용하면 프로젝트가 성장함에 따라 PDF 테스트 스위트를 유지할 수 있습니다.
고정된 지연보다 명시적 대기를 사용하세요. 파일의 존재 여부를 확인하는 파일 시스템 감시자나 폴링 루프로 Thread.Sleep()을 교체하세요. Selenium의 명시적 대기 문서는 브라우저 측 대기 전략을 다루고 있으며, 다운로드에도 동일한 원칙이 적용됩니다. 고정된 지연은 느린 CI 머신에서 불안정합니다.
PDF 작업을 기본 클래스에 중앙 집중화하세요. LoadPdfFromUrl, DownloadPdf, 및 ValidateTerms와 같은 메서드를 노출하는 공용 보조 또는 기본 테스트 클래스를 만드세요. 그러면 개별 테스트는 PDF 작업이 아니라 검증에 집중할 수 있습니다. 이것은 ChromePdfRenderer 자체가 HTML을 PDF로 변환하고 다른 핵심 작업을 수행하는 패턴을 반영합니다.
각 테스트 후 다운로드된 파일을 정리하세요. File.Delete()을 finally 블록이나 종료 메서드에서 호출하여 임시 PDF가 디스크에 누적되지 않도록 하세요. 특히 여러 파일이 동시에 같은 디렉토리에 저장될 수 있는 병렬 테스트 실행에서 중요합니다.
변경 없이 크로스 플랫폼에서 테스트 실행. ChromePdfRenderer는 조건부 컴파일 없이 Windows, Linux, macOS에서 작동합니다. 로컬에서 실행되는 동일 테스트 어셈블리는 Linux 기반 CI 에이전트에서도 정확히 실행됩니다. Docker 특정 구성을 위해 크로스 플랫폼 배포 가이드를 참조하세요.
비밀번호를 소스 제어에서 제외하세요. 보호된 PDF를 다룰 때는 환경 변수나 비밀 관리자에서 인증 정보를 읽어야 합니다. ChromePdfRenderer의 PdfDocument.FromFile(path, password) 오버로드는 로드 시 비밀번호를 허용하여 호출 사이트가 깨끗하게 유지됩니다. ChromePdfRenderer 라이선스 페이지 에는 프로덕션 배포를 위한 팀 및 Enterprise 라이선스 정보가 포함되어 있습니다.
필요한 페이지에 텍스트 추출을 범위로 지정하세요. ExtractAllText()은 작은 문서에 편리하지만, 큰 여러 페이지 PDF의 경우 ExtractTextFromPage()을 호출하여 확인 중인 데이터가 포함된 페이지만 추출하도록 고려하세요. 이것은 메모리 사용량을 줄이고 테스트 실행 속도를 높입니다. 전체 메서드 시그니처는 텍스트 추출에 대한 API 참조를 참조하세요.

ChromePdfRenderer는 다른 .NET용 PDF 라이브러리와 어떻게 비교됩니까?
| 특징 | ChromePdfRenderer | iText | PDFPig |
|---|---|---|---|
| URL에서 PDF 로드 | 예 -- 단일 메서드 호출 | 수동 HTTP 다운로드 필요 | 수동 HTTP 다운로드 필요 |
| 모든 텍스트 추출 | 예 -- `ExtractAllText()` | 예 -- 다중 단계 | 예 -- 다중 단계 |
| 페이지 수준 추출 | 예 -- `ExtractTextFromPage(n)` | 예 | 예 |
| 비밀번호로 보호된 PDF 파일 | 예 -- 매개변수 오버로드 | 예 | 제한된 |
| .NET 10 지원 | 예 | 부분적 | 예 |
| HTML을 PDF로 생성 | 예 | 제한된 | 아니요 |
| 크로스플랫폼 (리눅스, macOS) | 예 | 예 | 예 |
| 라이선스 유형 | 무료 체험 제공 상업용 | AGPL / 상업용 | MIT |
ChromePdfRenderer의 직접적인 URL 로딩과 단일 메서드 텍스트 추출은 개발 속도가 중요한 테스트 자동화 환경에서 명백한 이점을 제공합니다. 같은 워크플로우 내에서 HTML에서 PDF를 생성하거나 기존 문서를 조작할 필요가 있는 팀에게, 하나의 라이브러리가 두 작업을 처리할 수 있는 것은 의존성 트리를 상당히 단순화합니다. PDFPig 같은 오픈 소스 대안은 간단한 추출 필요에 적합하지만, URL 로딩을 처리하기 위해 더 많은 설정이 필요하고 내장된 PDF 생성 기능을 제공하지 않습니다.
무료 체험판으로 시작하는 방법은?
ChromePdfRenderer는 무료 체험판을 제공하여 라이센스를 구매하기 전에 테스트 환경에서 라이브러리를 검증할 수 있습니다. 체험 기간 동안 워터마크 제한이 텍스트 추출 또는 검증 워크플로우에 영향을 미치지 않습니다.
시작하려면:
- NuGet 패키지를 설치하세요:
dotnet add package IronPdf - 테스트 파일에
using IronPdf;을 추가하세요. PdfDocument.FromUrl()또는PdfDocument.FromFile()을 호출하고 텍스트 추출을 시작하세요.
ChromePdfRenderer 무료 체험 페이지를 방문하여 체험 키를 다운로드하세요. 팀 또는 기업 배포를 위한 경우, ChromePdfRenderer 라이선스 옵션을 검토하여 필요에 맞는 계획을 찾으세요.
설정을 가속화하기 위한 추가 리소스:
자주 묻는 질문
Selenium WebDriver가 직접 PDF 파일을 읽을 수 없는 이유는 무엇인가요?
Selenium WebDriver는 DOM의 일부인 웹 요소와 상호 작용하도록 설계되었습니다. 그러나 PDF 파일은 이진 스트림으로 렌더링되며, DOM 요소가 아니기 때문에 Selenium과의 직접적인 상호 작용이 불가능합니다.
IronPDF가 Selenium WebDriver에서 PDF 파일을 읽는 데 어떻게 도움이 되나요?
IronPDF는 Selenium WebDriver와 매끄럽게 통합되어 복잡한 설정이나 여러 라이브러리가 필요 없이 텍스트 추출과 PDF 데이터 유효성 검증을 할 수 있도록 해줍니다. 이는 과정을 크게 단순화하고 테스트의 효율성을 높입니다.
Selenium과 IronPDF를 사용하여 PDF 테스트를 수행할 때의 이점은 무엇입니까?
Selenium과 IronPDF를 사용하면, 개발자가 최소한의 코드로 PDF에서 텍스트를 추출하고 검증할 수 있는 간소화된 PDF 처리가 가능합니다. 이는 추가 구성이나 외부 라이브러리의 필요성을 줄여주어 과정을 더 빠르고 효율적으로 만듭니다.
C#에서 PDF 테스트를 위해 IronPDF와 추가 라이브러리를 사용하는 것이 필수적인가요?
아니요, IronPDF는 PDF 추출 및 검증을 처리하는 포괄적인 솔루션을 제공하여 C# 프로젝트에서 복수의 라이브러리나 복잡한 구성의 필요성을 없애줍니다.
IronPDF는 현대 웹 애플리케이션에서 생성된 PDF 파일을 처리할 수 있나요?
네, IronPDF는 특히 현대 웹 애플리케이션에서 생성된 새로운 PDF 문서와 효과적으로 작동하여 효율적인 텍스트 추출과 데이터 검증이 가능합니다.
IronPDF가 Selenium에서 PDF 자동화에 강력한 도구가 되는 이유는 무엇인가요?
IronPDF의 강력한 기능들 덕분에 Selenium WebDriver와 통합되어 PDF 파일을 효율적으로 관리할 수 있습니다. 이는 자동화된 테스트 내에서 PDF 콘텐츠를 읽고 검증하는 과정을 단순화합니다.
IronPDF가 Apache PDFBox와 같은 Java 솔루션과 어떻게 비교되나요?
복수의 import 구문과 라이브러리가 필요할 수 있는 Java 솔루션과 달리, IronPDF는 C# 프로젝트에 직접 통합되는 간소화된 접근 방식을 제공하여 Selenium에서의 PDF 테스트 과정을 단순화합니다.
IronPDF는 C#에서 Selenium WebDriver와 호환되나요?
네, IronPDF는 C#에서 Selenium WebDriver와 매끄럽게 작동하도록 설계되었으며, 자동화된 테스트에서 PDF 파일을 읽고 검증할 수 있는 견고한 솔루션을 제공합니다.
자동화된 PDF 테스트에서 IronPDF가 해결하는 문제는 무엇인가요?
IronPDF는 자동화된 테스트에서 PDF 콘텐츠에 접근하고 검증하는 문제를 해결하여 복잡한 설정이나 복수의 라이브러리의 필요성을 없애고 Selenium WebDriver와 호환되는 단순한 솔루션을 제공합니다.
IronPDF가 자동화된 테스트 워크플로우의 효율성을 어떻게 향상시킬 수 있나요?
Selenium WebDriver와 통합하여 IronPDF는 텍스트 추출 및 PDF 데이터 검증의 과정을 단순화하여 자동화된 테스트 워크플로우에 필요한 복잡성과 시간을 줄입니다.











