
Comment créer un générateur PDF .NET Core
Les documents PDF présentent un défi particulier pour les tests automatisés : si Selenium WebDriver excelle dans l'interaction avec les éléments web, il ne peut pas lire le contenu d'un PDF car le fichier est rendu sous forme de flux binaire et non d'éléments DOM. Cet article explique comment résoudre ce problème en C# en associant Selenium à IronPDF , une bibliothèque PDF .NET prête pour la production qui permet d'extraire, de valider et de traiter le contenu d'un PDF en quelques lignes de code seulement, sans avoir à gérer les dépendances complexes de type Java.
Pourquoi Selenium a-t-il des difficultés avec le contenu PDF ?
Lorsqu'un PDF s'ouvre dans un navigateur, Selenium peut naviguer jusqu'à la page et interagir avec les contrôles du navigateur, mais il ne peut pas interroger le texte ou les données à l'intérieur du document. Les fichiers PDF sont rendus sous forme d'objets intégrés ou de plugins, et non sous forme d'éléments HTML que le protocole WebDriver peut parcourir. Le visualiseur PDF du navigateur affiche le document visuellement, mais il n'y a pas de DOM accessible pour que Selenium puisse l'inspecter ; chaque requête XPath ou sélecteur CSS ne renvoie rien.
Les solutions de contournement traditionnelles nécessitent de télécharger le fichier sur le disque, d'invoquer une bibliothèque d'analyse syntaxique distincte et de tout connecter manuellement. Ce processus en plusieurs étapes ajoute de la complexité, crée un code de test fragile et complique les pipelines CI/CD où les chemins d'accès aux fichiers et les autorisations sont difficiles à contrôler. IronPDF élimine toutes ces étapes en vous permettant de charger un PDF à partir d'une URL ou d'un chemin local et d'en extraire le texte en un seul appel, directement dans votre projet de test .NET existant, sans aucun fichier intermédiaire ni configuration.
Concrètement, le résultat est que le code de test devient plus court, plus facile à lire et beaucoup moins susceptible de dysfonctionner lorsque l'environnement de test change. Pour un aperçu plus complet de tout ce IronPDF peut faire au-delà de l'extraction de texte, consultez le centre de documentation IronPDF .

Comment installer IronPDF pour les tests Selenium ?
La mise en place des colis nécessaires prend moins d'une minute. Ouvrez la console du Package Manager dans Visual Studio et exécutez :
Install-Package IronPdf
Vous aurez également besoin des packages Selenium s'ils ne sont pas déjà présents dans votre projet :
Install-Package Selenium.WebDriver
Install-Package Selenium.WebDriver.ChromeDriverInstall-Package Selenium.WebDriver
Install-Package Selenium.WebDriver.ChromeDriver
Une fois les paquets installés, ajoutez ces directives using en haut de votre fichier de test :
using IronPdf;
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
using System.IO;using IronPdf;
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
using System.IO;Imports IronPdf
Imports OpenQA.Selenium
Imports OpenQA.Selenium.Chrome
Imports System.IOIronPDF cible .NET 10 et fonctionne de manière multiplateforme sur Windows, Linux et macOS, de sorte que le même code de test s'exécute dans tous les environnements, y compris les conteneurs Docker et les agents CI cloud.
Comment lire un PDF directement à partir d'une URL ?
La lecture du contenu PDF à partir d'une URL permet de s'affranchir complètement de l'étape de téléchargement. Selenium localise le lien, IronPDF charge le document, et vous disposez du texte intégral pour les assertions en quelques lignes seulement.
// Initialize Chrome driver
var driver = new ChromeDriver();
// Navigate to a webpage containing a PDF link
driver.Navigate().GoToUrl("https://ironpdf.com/");
// Find and capture the PDF URL
IWebElement pdfLink = driver.FindElement(By.CssSelector("a[href$='.pdf']"));
string pdfUrl = pdfLink.GetAttribute("href");
// Load the PDF directly from the URL -- no download needed
var pdf = PdfDocument.FromUrl(new Uri(pdfUrl));
string extractedText = pdf.ExtractAllText();
// Assert expected content
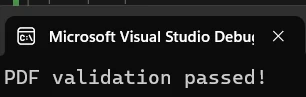
if (extractedText.Contains("IronPDF"))
{
Console.WriteLine("PDF validation passed!");
}
driver.Quit();// Initialize Chrome driver
var driver = new ChromeDriver();
// Navigate to a webpage containing a PDF link
driver.Navigate().GoToUrl("https://ironpdf.com/");
// Find and capture the PDF URL
IWebElement pdfLink = driver.FindElement(By.CssSelector("a[href$='.pdf']"));
string pdfUrl = pdfLink.GetAttribute("href");
// Load the PDF directly from the URL -- no download needed
var pdf = PdfDocument.FromUrl(new Uri(pdfUrl));
string extractedText = pdf.ExtractAllText();
// Assert expected content
if (extractedText.Contains("IronPDF"))
{
Console.WriteLine("PDF validation passed!");
}
driver.Quit();Imports OpenQA.Selenium
Imports OpenQA.Selenium.Chrome
Imports IronPdf
' Initialize Chrome driver
Dim driver As IWebDriver = New ChromeDriver()
' Navigate to a webpage containing a PDF link
driver.Navigate().GoToUrl("https://ironpdf.com/")
' Find and capture the PDF URL
Dim pdfLink As IWebElement = driver.FindElement(By.CssSelector("a[href$='.pdf']"))
Dim pdfUrl As String = pdfLink.GetAttribute("href")
' Load the PDF directly from the URL -- no download needed
Dim pdf As PdfDocument = PdfDocument.FromUrl(New Uri(pdfUrl))
Dim extractedText As String = pdf.ExtractAllText()
' Assert expected content
If extractedText.Contains("IronPDF") Then
Console.WriteLine("PDF validation passed!")
End If
driver.Quit()PdfDocument.FromUrl() charge et analyse le document en mémoire. L'appel de ExtractAllText() renvoie tout le texte de chaque page sous forme d'une seule chaîne, prête pour vos assertions. Pour les documents protégés par mot de passe, transmettez les identifiants en tant que paramètre supplémentaire afin que les fichiers protégés restent accessibles pendant les tests. Pour en savoir plus sur les options d'extraction de texte, consultez le guide d'extraction de texte IronPDF .
Sortie
Comment télécharger et traiter automatiquement un fichier PDF ?
Lorsqu'un PDF est généré après authentification ou via un flux de travail dynamique, le télécharger au préalable peut être la seule option. Configurez Chrome pour qu'il télécharge automatiquement les fichiers PDF dans un répertoire connu, puis indiquez le chemin d'accès au fichier à IronPDF:
// Configure Chrome to auto-download PDFs
var chromeOptions = new ChromeOptions();
chromeOptions.AddUserProfilePreference("download.default_directory", @"C:\PDFTests");
chromeOptions.AddUserProfilePreference("plugins.always_open_pdf_externally", true);
var driver = new ChromeDriver(chromeOptions);
string appUrl = "https://example.com/reports";
// Trigger the download
driver.Navigate().GoToUrl(appUrl);
driver.FindElement(By.Id("downloadReport")).Click();
// Wait for the download -- replace Thread.Sleep with a file-system watcher in production tests
System.Threading.Thread.Sleep(3000);
// Read the downloaded PDF
string pdfPath = @"C:\PDFTests\report.pdf";
var pdf = PdfDocument.FromFile(pdfPath);
string content = pdf.ExtractAllText();
// Validate specific data
bool hasExpectedData = content.Contains("Quarterly Revenue: $1.2M");
Console.WriteLine($"Revenue data found: {hasExpectedData}");
// Extract text from a specific page (zero-indexed)
string page2Content = pdf.ExtractTextFromPage(1);
// Clean up
File.Delete(pdfPath);
driver.Quit();// Configure Chrome to auto-download PDFs
var chromeOptions = new ChromeOptions();
chromeOptions.AddUserProfilePreference("download.default_directory", @"C:\PDFTests");
chromeOptions.AddUserProfilePreference("plugins.always_open_pdf_externally", true);
var driver = new ChromeDriver(chromeOptions);
string appUrl = "https://example.com/reports";
// Trigger the download
driver.Navigate().GoToUrl(appUrl);
driver.FindElement(By.Id("downloadReport")).Click();
// Wait for the download -- replace Thread.Sleep with a file-system watcher in production tests
System.Threading.Thread.Sleep(3000);
// Read the downloaded PDF
string pdfPath = @"C:\PDFTests\report.pdf";
var pdf = PdfDocument.FromFile(pdfPath);
string content = pdf.ExtractAllText();
// Validate specific data
bool hasExpectedData = content.Contains("Quarterly Revenue: $1.2M");
Console.WriteLine($"Revenue data found: {hasExpectedData}");
// Extract text from a specific page (zero-indexed)
string page2Content = pdf.ExtractTextFromPage(1);
// Clean up
File.Delete(pdfPath);
driver.Quit();Imports OpenQA.Selenium
Imports OpenQA.Selenium.Chrome
Imports System.IO
Imports System.Threading
' Configure Chrome to auto-download PDFs
Dim chromeOptions As New ChromeOptions()
chromeOptions.AddUserProfilePreference("download.default_directory", "C:\PDFTests")
chromeOptions.AddUserProfilePreference("plugins.always_open_pdf_externally", True)
Dim driver As New ChromeDriver(chromeOptions)
Dim appUrl As String = "https://example.com/reports"
' Trigger the download
driver.Navigate().GoToUrl(appUrl)
driver.FindElement(By.Id("downloadReport")).Click()
' Wait for the download -- replace Thread.Sleep with a file-system watcher in production tests
Thread.Sleep(3000)
' Read the downloaded PDF
Dim pdfPath As String = "C:\PDFTests\report.pdf"
Dim pdf = PdfDocument.FromFile(pdfPath)
Dim content As String = pdf.ExtractAllText()
' Validate specific data
Dim hasExpectedData As Boolean = content.Contains("Quarterly Revenue: $1.2M")
Console.WriteLine($"Revenue data found: {hasExpectedData}")
' Extract text from a specific page (zero-indexed)
Dim page2Content As String = pdf.ExtractTextFromPage(1)
' Clean up
File.Delete(pdfPath)
driver.Quit()La préférence plugins.always_open_pdf_externally contourne le visualiseur PDF intégré de Chrome pour que le fichier soit enregistré sur disque au lieu de s'ouvrir dans le navigateur. ExtractTextFromPage() vous donne une précision au niveau des pages lorsque les données de validation apparaissent sur différentes pages d'un rapport multipages. Pour travailler efficacement avec des documents volumineux, consultez les conseils de performance IronPDF .
Comment valider le contenu PDF dans les tests automatisés ?
Vérifier qu'un document contient les termes appropriés est le scénario de test le plus courant. La méthode utilitaire suivante accepte un chemin de fichier et un tableau de termes requis, puis renvoie false dès qu'un terme attendu est manquant :
bool ValidatePdfContent(string pdfPath, string[] expectedTerms)
{
var pdf = PdfDocument.FromFile(pdfPath);
string fullText = pdf.ExtractAllText();
// Verify each required term
foreach (string term in expectedTerms)
{
if (!fullText.Contains(term, StringComparison.OrdinalIgnoreCase))
{
Console.WriteLine($"Missing expected term: {term}");
return false;
}
}
// Validate first-page structure
if (pdf.PageCount > 0)
{
string firstPageText = pdf.ExtractTextFromPage(0);
if (!firstPageText.Contains("Invoice #") && !firstPageText.Contains("Date:"))
{
Console.WriteLine("Header validation failed");
return false;
}
}
return true;
}bool ValidatePdfContent(string pdfPath, string[] expectedTerms)
{
var pdf = PdfDocument.FromFile(pdfPath);
string fullText = pdf.ExtractAllText();
// Verify each required term
foreach (string term in expectedTerms)
{
if (!fullText.Contains(term, StringComparison.OrdinalIgnoreCase))
{
Console.WriteLine($"Missing expected term: {term}");
return false;
}
}
// Validate first-page structure
if (pdf.PageCount > 0)
{
string firstPageText = pdf.ExtractTextFromPage(0);
if (!firstPageText.Contains("Invoice #") && !firstPageText.Contains("Date:"))
{
Console.WriteLine("Header validation failed");
return false;
}
}
return true;
}Imports System
Function ValidatePdfContent(pdfPath As String, expectedTerms As String()) As Boolean
Dim pdf = PdfDocument.FromFile(pdfPath)
Dim fullText As String = pdf.ExtractAllText()
' Verify each required term
For Each term As String In expectedTerms
If Not fullText.Contains(term, StringComparison.OrdinalIgnoreCase) Then
Console.WriteLine($"Missing expected term: {term}")
Return False
End If
Next
' Validate first-page structure
If pdf.PageCount > 0 Then
Dim firstPageText As String = pdf.ExtractTextFromPage(0)
If Not firstPageText.Contains("Invoice #") AndAlso Not firstPageText.Contains("Date:") Then
Console.WriteLine("Header validation failed")
Return False
End If
End If
Return True
End FunctionStringComparison.OrdinalIgnoreCase empêche les tests de se casser en raison de différences de casse dans les documents générés. IronPDF préserve la mise en page et le formatage du texte lors de l'extraction, de sorte que la validation positionnelle — comme la vérification que les champs d'en-tête apparaissent sur la première page — fonctionne de manière fiable avec différents générateurs de PDF.
Pour des scénarios plus avancés tels que l'extraction de tableaux à partir de fichiers PDF , l'extraction d'images intégrées ou la lecture de champs de formulaires interactifs, IronPDF fournit des API dédiées pour chaque tâche. Vous pouvez également enchaîner l'extraction de texte avec des flux de travail de fusion ou de division de PDF lorsque votre Suite de tests doit assembler ou désassembler des documents avant validation.
Entrée
Sortie
Quelles sont les meilleures pratiques pour tester les fichiers PDF avec Selenium ?
L'application de quelques modèles dès le départ permettra de maintenir votre Suite de tests PDF à mesure que le projet se développe.
Utilisez des attentes explicites au lieu de délais fixes. Remplacez Thread.Sleep() par un observateur de système de fichiers ou une boucle de sondage qui vérifie l'existence du fichier. La documentation explicite de Selenium sur l'attente couvre les stratégies d'attente côté navigateur, et le même principe s'applique aux téléchargements. Les délais fixes sont fragiles sur les machines d'intégration continue lentes.
Centralisez les opérations PDF dans une classe de base. Créez un utilitaire partagé ou une classe de test de base qui expose des méthodes comme LoadPdfFromUrl, DownloadPdf et ValidateTerms. Les tests individuels restent alors concentrés sur les assertions plutôt que sur la structure même du PDF. Cela reflète le modèle que suit IronPDF lui-même pour la conversion HTML vers PDF et d'autres opérations de base.
Nettoyez les fichiers téléchargés après chaque test. Appelez File.Delete() dans un bloc finally ou une méthode de nettoyage pour éviter que les PDF temporaires ne s'accumulent sur le disque. Ceci est particulièrement important lors d'exécutions de tests parallèles où plusieurs fichiers peuvent se retrouver simultanément dans le même répertoire.
Exécutez des tests multiplateformes sans modification. IronPDF fonctionne sous Windows, Linux et macOS sans compilation conditionnelle. Le même ensemble de tests exécuté localement s'exécutera correctement sur les agents CI basés sur Linux. Consultez le guide de déploiement multiplateforme pour la configuration spécifique à Docker.
Évitez d'inclure les mots de passe dans le système de contrôle de version. Lorsque vous travaillez avec des fichiers PDF protégés, lisez les identifiants depuis des variables d'environnement ou un gestionnaire de secrets plutôt que de les coder en dur. La surcharge PdfDocument.FromFile(path, password) d'IronPDF accepte le mot de passe au moment du chargement, gardant le site d'appel propre. La page relative aux licences IronPDF couvre les licences d'équipe et Enterprise pour les déploiements en production.
Limitez l'extraction de texte à la page dont vous avez besoin. ExtractAllText() est pratique pour les petits documents, mais pour les grands PDF multipages, envisagez d'appeler ExtractTextFromPage() uniquement pour les pages contenant les données que vous validez. Cela réduit l'utilisation de la mémoire et accélère l'exécution des tests. Veuillez vous référer à la documentation de l'API pour l'extraction de texte afin d'obtenir les signatures complètes des méthodes.

Comment IronPDF se compare-t-il aux autres bibliothèques PDF for .NET?
| Caractéristique | IronPDF | iText | PdfPig |
|---|---|---|---|
| Charger le PDF à partir de l'URL | Oui -- appel de méthode unique | Téléchargement HTTP manuel requis | Téléchargement HTTP manuel requis |
| Extraire tout le texte | Oui -- `ExtractAllText()` | Oui -- en plusieurs étapes | Oui -- en plusieurs étapes |
| Extraction au niveau de la page | Oui -- `ExtractTextFromPage(n)` | Oui | Oui |
| PDFs protégés par mot de passe | Oui -- surcharge de paramètres | Oui | Limitée |
| Prise en charge de .NET 10 | Oui | Partiel | Oui |
| Génération HTML vers PDF | Oui | Limitée | Non |
| Multiplateforme (Linux, macOS) | Oui | Oui | Oui |
| Type de licence | Publicité avec essai gratuit | AGPL / Commercial | MIT |
Le chargement direct des URL et l'extraction de texte par méthode unique d'IronPDF lui confèrent un avantage certain dans les contextes d'automatisation des tests où la rapidité de développement est primordiale. Pour les équipes qui ont également besoin de générer des PDF à partir de HTML ou de manipuler des documents existants dans le même flux de travail, le fait qu'une seule bibliothèque gère les deux tâches simplifie considérablement l'arbre de dépendances. Les alternatives open source comme PdfPig conviennent raisonnablement aux besoins d'extraction simples, mais elles nécessitent une configuration plus poussée pour gérer le chargement des URL et n'offrent aucune génération de PDF intégrée.
Comment bénéficier d'un essai gratuit ?
IronPDF propose une version d'essai gratuite complète vous permettant de valider la bibliothèque dans votre environnement de test avant de souscrire à une licence. Aucune limitation liée aux filigranes n'affecte les flux de travail d'extraction ou de validation de texte pendant la période d'essai.
Pour commencer :
- Installez le package NuGet :
dotnet add package IronPdf - Ajoutez
using IronPdf;à votre fichier de test. - Appelez
PdfDocument.FromUrl()ouPdfDocument.FromFile()et commencez à extraire du texte.
Rendez-vous sur la page d'essai gratuit IronPDF pour télécharger votre clé d'essai. Pour les déploiements en équipe ou en Enterprise , consultez les options de licence IronPDF pour trouver le plan qui correspond à vos besoins.
Ressources supplémentaires pour accélérer votre installation :
- Guide de démarrage rapide IronPDF .NET
- Référence API complète pour PdfDocument
- Page NuGet IronPDF
- Soutien communautaire et exemples
Questions Fréquemment Posées
Pourquoi Selenium WebDriver ne peut-il pas lire directement les fichiers PDF ?
Selenium WebDriver est conçu pour interagir avec les éléments web, qui font partie du DOM. Les fichiers PDF, cependant, sont rendus sous forme de flux binaires, et non d'éléments DOM, ce qui rend l'interaction directe avec leur contenu impossible pour Selenium.
Comment IronPDF aide-t-il à lire des fichiers PDF dans Selenium WebDriver ?
IronPDF s'intègre parfaitement à Selenium WebDriver, ce qui vous permet d'extraire du texte et de valider des données PDF sans avoir recours à des configurations complexes ou à de multiples bibliothèques. Cela simplifie considérablement le processus et améliore l'efficacité des tests.
Quels sont les avantages de l'utilisation d'IronPDF avec Selenium pour les tests PDF ?
L'utilisation d'IronPDF avec Selenium permet un traitement rationalisé des PDF, permettant aux développeurs d'extraire et de valider du texte à partir de PDF avec un minimum de code. Cela réduit le besoin de configuration supplémentaire ou de bibliothèques externes, ce qui rend le processus plus rapide et plus efficace.
Est-il nécessaire d'utiliser des bibliothèques supplémentaires avec IronPDF pour tester les PDF en C# ?
Non, IronPDF fournit une solution complète qui prend en charge l'extraction et la validation des PDF, éliminant ainsi le besoin de bibliothèques multiples ou de configurations complexes dans vos projets C#.
IronPDF peut-il gérer les fichiers PDF générés par les applications web modernes ?
Oui, IronPDF est particulièrement efficace avec les nouveaux documents PDF générés par les applications web modernes, permettant une extraction de texte et une validation des données efficaces.
Qu'est-ce qui fait d'IronPDF un outil puissant pour l'automatisation des PDF dans Selenium ?
Les puissantes capacités d'IronPDF lui permettent de s'intégrer à Selenium WebDriver, offrant ainsi un moyen efficace de gérer les fichiers PDF. Il simplifie le processus de lecture et de validation du contenu PDF directement dans les tests automatisés.
Comment IronPDF se compare-t-il aux solutions Java telles qu'Apache PDFBox ?
Contrairement aux solutions Java qui peuvent nécessiter de multiples déclarations d'importation et bibliothèques, IronPDF offre une approche rationalisée qui s'intègre directement aux projets C#, simplifiant ainsi le processus de test des PDF dans Selenium.
IronPDF est-il compatible avec Selenium WebDriver en C# ?
Oui, IronPDF est conçu pour fonctionner de manière transparente avec Selenium WebDriver en C#, fournissant une solution robuste pour la lecture et la validation des fichiers PDF dans les tests automatisés.
Quels sont les défis qu'IronPDF aide à résoudre dans le cadre des tests automatisés de PDF ?
IronPDF relève le défi de l'accès et de la validation du contenu PDF dans les tests automatisés, en éliminant le besoin de bibliothèques multiples et de configurations complexes, et en fournissant une solution directe compatible avec Selenium WebDriver.
Comment IronPDF peut-il améliorer l'efficacité des flux de travail des tests automatisés ?
En s'intégrant à Selenium WebDriver, IronPDF simplifie le processus d'extraction de texte et de validation des données PDF, réduisant ainsi la complexité et le temps requis pour les flux de travail de test automatisés.











