
Como criar um gerador de PDF em .NET Core
Documentos PDF apresentam um desafio único em testes automatizados: embora o Selenium WebDriver seja excelente na interação com elementos da web, ele não consegue ler o conteúdo de um PDF porque o arquivo é renderizado como um fluxo binário em vez de elementos DOM. Este artigo mostra como resolver esse problema em C# combinando o Selenium com o IronPDF , uma biblioteca .NET pronta para produção que permite extrair, validar e processar conteúdo de PDF com apenas algumas linhas de código — sem a necessidade de gerenciamento complexo de dependências no estilo Java.
Por que o Selenium tem dificuldades com conteúdo em PDF?
Quando um PDF é aberto em um navegador, o Selenium pode navegar até a página e interagir com os controles do navegador, mas não pode consultar o texto ou os dados dentro do documento. Os PDFs são renderizados como objetos incorporados ou plugins, e não como elementos HTML que o protocolo WebDriver possa percorrer. O visualizador de PDF do navegador renderiza o documento visualmente, mas não há um DOM acessível para o Selenium inspecionar — toda consulta XPath ou seletor CSS não retorna nada.
As soluções alternativas tradicionais exigem o download do arquivo para o disco, a invocação de uma biblioteca de análise sintática separada e a integração manual de tudo. Esse processo de várias etapas adiciona complexidade, cria código de teste frágil e complica os pipelines de CI/CD, onde os caminhos de arquivo e as permissões são difíceis de controlar. O IronPDF elimina todas essas etapas, permitindo que você carregue um PDF a partir de uma URL ou de um caminho local e extraia seu texto em uma única chamada — diretamente dentro do seu projeto de teste .NET existente, sem arquivos ou configurações intermediárias.
Na prática, o resultado é que o código de teste fica mais curto, mais fácil de ler e muito menos propenso a falhas quando o ambiente de teste muda. Para uma visão mais abrangente de tudo o que o IronPDF pode fazer além da extração de texto, visite a central de documentação do IronPDF .

Como instalar o IronPDF para testes com Selenium?
Preparar os pacotes necessários leva menos de um minuto. Abra o Console do Gerenciador de Pacotes no Visual Studio e execute:
Install-Package IronPdf
Você também precisará dos pacotes do Selenium, caso eles ainda não estejam presentes em seu projeto:
Install-Package Selenium.WebDriver
Install-Package Selenium.WebDriver.ChromeDriverInstall-Package Selenium.WebDriver
Install-Package Selenium.WebDriver.ChromeDriver
Após a instalação dos pacotes, adicione as seguintes diretivas using no início do seu arquivo de teste:
using IronPdf;
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
using System.IO;using IronPdf;
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
using System.IO;Imports IronPdf
Imports OpenQA.Selenium
Imports OpenQA.Selenium.Chrome
Imports System.IOO IronPDF é compatível com o .NET 10 e funciona em várias plataformas, como Windows, Linux e macOS, permitindo que o mesmo código de teste seja executado em todos os ambientes, incluindo contêineres Docker e agentes de CI na nuvem.
Como ler um PDF diretamente de uma URL?
A leitura de conteúdo PDF a partir de um URL dispensa completamente a etapa de download. O Selenium localiza o link, o IronPDF carrega o documento e você tem o texto completo disponível para verificações em apenas algumas linhas de código.
// Initialize Chrome driver
var driver = new ChromeDriver();
// Navigate to a webpage containing a PDF link
driver.Navigate().GoToUrl("https://ironpdf.com/");
// Find and capture the PDF URL
IWebElement pdfLink = driver.FindElement(By.CssSelector("a[href$='.pdf']"));
string pdfUrl = pdfLink.GetAttribute("href");
// Load the PDF directly from the URL -- no download needed
var pdf = PdfDocument.FromUrl(new Uri(pdfUrl));
string extractedText = pdf.ExtractAllText();
// Assert expected content
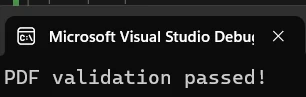
if (extractedText.Contains("IronPDF"))
{
Console.WriteLine("PDF validation passed!");
}
driver.Quit();// Initialize Chrome driver
var driver = new ChromeDriver();
// Navigate to a webpage containing a PDF link
driver.Navigate().GoToUrl("https://ironpdf.com/");
// Find and capture the PDF URL
IWebElement pdfLink = driver.FindElement(By.CssSelector("a[href$='.pdf']"));
string pdfUrl = pdfLink.GetAttribute("href");
// Load the PDF directly from the URL -- no download needed
var pdf = PdfDocument.FromUrl(new Uri(pdfUrl));
string extractedText = pdf.ExtractAllText();
// Assert expected content
if (extractedText.Contains("IronPDF"))
{
Console.WriteLine("PDF validation passed!");
}
driver.Quit();Imports OpenQA.Selenium
Imports OpenQA.Selenium.Chrome
Imports IronPdf
' Initialize Chrome driver
Dim driver As IWebDriver = New ChromeDriver()
' Navigate to a webpage containing a PDF link
driver.Navigate().GoToUrl("https://ironpdf.com/")
' Find and capture the PDF URL
Dim pdfLink As IWebElement = driver.FindElement(By.CssSelector("a[href$='.pdf']"))
Dim pdfUrl As String = pdfLink.GetAttribute("href")
' Load the PDF directly from the URL -- no download needed
Dim pdf As PdfDocument = PdfDocument.FromUrl(New Uri(pdfUrl))
Dim extractedText As String = pdf.ExtractAllText()
' Assert expected content
If extractedText.Contains("IronPDF") Then
Console.WriteLine("PDF validation passed!")
End If
driver.Quit()PdfDocument.FromUrl() busca e analisa o documento na memória. A chamada ExtractAllText() retorna todo o texto de cada página como uma única string, pronta para suas asserções. Para documentos protegidos por senha, passe as credenciais como um parâmetro adicional para que os arquivos protegidos permaneçam acessíveis durante os testes. Para saber mais sobre as opções de extração de texto, consulte o guia de extração de texto do IronPDF .
Saída
Como baixar e processar um PDF automaticamente?
Quando um PDF é gerado após a autenticação ou por meio de um fluxo de trabalho dinâmico, baixá-lo primeiro pode ser a única opção. Configure o Chrome para baixar automaticamente PDFs para um diretório conhecido e, em seguida, passe o caminho do arquivo para o IronPDF:
// Configure Chrome to auto-download PDFs
var chromeOptions = new ChromeOptions();
chromeOptions.AddUserProfilePreference("download.default_directory", @"C:\PDFTests");
chromeOptions.AddUserProfilePreference("plugins.always_open_pdf_externally", true);
var driver = new ChromeDriver(chromeOptions);
string appUrl = "https://example.com/reports";
// Trigger the download
driver.Navigate().GoToUrl(appUrl);
driver.FindElement(By.Id("downloadReport")).Click();
// Wait for the download -- replace Thread.Sleep with a file-system watcher in production tests
System.Threading.Thread.Sleep(3000);
// Read the downloaded PDF
string pdfPath = @"C:\PDFTests\report.pdf";
var pdf = PdfDocument.FromFile(pdfPath);
string content = pdf.ExtractAllText();
// Validate specific data
bool hasExpectedData = content.Contains("Quarterly Revenue: $1.2M");
Console.WriteLine($"Revenue data found: {hasExpectedData}");
// Extract text from a specific page (zero-indexed)
string page2Content = pdf.ExtractTextFromPage(1);
// Clean up
File.Delete(pdfPath);
driver.Quit();// Configure Chrome to auto-download PDFs
var chromeOptions = new ChromeOptions();
chromeOptions.AddUserProfilePreference("download.default_directory", @"C:\PDFTests");
chromeOptions.AddUserProfilePreference("plugins.always_open_pdf_externally", true);
var driver = new ChromeDriver(chromeOptions);
string appUrl = "https://example.com/reports";
// Trigger the download
driver.Navigate().GoToUrl(appUrl);
driver.FindElement(By.Id("downloadReport")).Click();
// Wait for the download -- replace Thread.Sleep with a file-system watcher in production tests
System.Threading.Thread.Sleep(3000);
// Read the downloaded PDF
string pdfPath = @"C:\PDFTests\report.pdf";
var pdf = PdfDocument.FromFile(pdfPath);
string content = pdf.ExtractAllText();
// Validate specific data
bool hasExpectedData = content.Contains("Quarterly Revenue: $1.2M");
Console.WriteLine($"Revenue data found: {hasExpectedData}");
// Extract text from a specific page (zero-indexed)
string page2Content = pdf.ExtractTextFromPage(1);
// Clean up
File.Delete(pdfPath);
driver.Quit();Imports OpenQA.Selenium
Imports OpenQA.Selenium.Chrome
Imports System.IO
Imports System.Threading
' Configure Chrome to auto-download PDFs
Dim chromeOptions As New ChromeOptions()
chromeOptions.AddUserProfilePreference("download.default_directory", "C:\PDFTests")
chromeOptions.AddUserProfilePreference("plugins.always_open_pdf_externally", True)
Dim driver As New ChromeDriver(chromeOptions)
Dim appUrl As String = "https://example.com/reports"
' Trigger the download
driver.Navigate().GoToUrl(appUrl)
driver.FindElement(By.Id("downloadReport")).Click()
' Wait for the download -- replace Thread.Sleep with a file-system watcher in production tests
Thread.Sleep(3000)
' Read the downloaded PDF
Dim pdfPath As String = "C:\PDFTests\report.pdf"
Dim pdf = PdfDocument.FromFile(pdfPath)
Dim content As String = pdf.ExtractAllText()
' Validate specific data
Dim hasExpectedData As Boolean = content.Contains("Quarterly Revenue: $1.2M")
Console.WriteLine($"Revenue data found: {hasExpectedData}")
' Extract text from a specific page (zero-indexed)
Dim page2Content As String = pdf.ExtractTextFromPage(1)
' Clean up
File.Delete(pdfPath)
driver.Quit()A preferência plugins.always_open_pdf_externally ignora o visualizador de PDF integrado do Chrome, fazendo com que o arquivo seja salvo no disco em vez de aberto no navegador. ExtractTextFromPage() oferece precisão no nível de página quando dados diferentes para validação aparecem em páginas diferentes de um relatório com várias páginas. Para trabalhar com documentos grandes de forma eficiente, consulte as dicas de desempenho do IronPDF .
Como validar o conteúdo de PDFs em testes automatizados?
Verificar se um documento contém os termos corretos é o cenário de teste mais comum. O seguinte método auxiliar aceita um caminho de arquivo e uma matriz de termos necessários, então retorna false no momento em que qualquer termo esperado estiver ausente:
bool ValidatePdfContent(string pdfPath, string[] expectedTerms)
{
var pdf = PdfDocument.FromFile(pdfPath);
string fullText = pdf.ExtractAllText();
// Verify each required term
foreach (string term in expectedTerms)
{
if (!fullText.Contains(term, StringComparison.OrdinalIgnoreCase))
{
Console.WriteLine($"Missing expected term: {term}");
return false;
}
}
// Validate first-page structure
if (pdf.PageCount > 0)
{
string firstPageText = pdf.ExtractTextFromPage(0);
if (!firstPageText.Contains("Invoice #") && !firstPageText.Contains("Date:"))
{
Console.WriteLine("Header validation failed");
return false;
}
}
return true;
}bool ValidatePdfContent(string pdfPath, string[] expectedTerms)
{
var pdf = PdfDocument.FromFile(pdfPath);
string fullText = pdf.ExtractAllText();
// Verify each required term
foreach (string term in expectedTerms)
{
if (!fullText.Contains(term, StringComparison.OrdinalIgnoreCase))
{
Console.WriteLine($"Missing expected term: {term}");
return false;
}
}
// Validate first-page structure
if (pdf.PageCount > 0)
{
string firstPageText = pdf.ExtractTextFromPage(0);
if (!firstPageText.Contains("Invoice #") && !firstPageText.Contains("Date:"))
{
Console.WriteLine("Header validation failed");
return false;
}
}
return true;
}Imports System
Function ValidatePdfContent(pdfPath As String, expectedTerms As String()) As Boolean
Dim pdf = PdfDocument.FromFile(pdfPath)
Dim fullText As String = pdf.ExtractAllText()
' Verify each required term
For Each term As String In expectedTerms
If Not fullText.Contains(term, StringComparison.OrdinalIgnoreCase) Then
Console.WriteLine($"Missing expected term: {term}")
Return False
End If
Next
' Validate first-page structure
If pdf.PageCount > 0 Then
Dim firstPageText As String = pdf.ExtractTextFromPage(0)
If Not firstPageText.Contains("Invoice #") AndAlso Not firstPageText.Contains("Date:") Then
Console.WriteLine("Header validation failed")
Return False
End If
End If
Return True
End FunctionStringComparison.OrdinalIgnoreCase impede que os testes falhem devido a diferenças de capitalização em documentos gerados. O IronPDF preserva o layout e a formatação do texto durante a extração, de modo que a validação posicional — como a confirmação de que os campos de cabeçalho aparecem na primeira página — funciona de forma confiável em diferentes geradores de PDF.
Para cenários mais avançados, como extrair tabelas de arquivos PDF , obter imagens incorporadas ou ler campos de formulários interativos, o IronPDF fornece APIs dedicadas para cada tarefa. Você também pode encadear a extração de texto com fluxos de trabalho de mesclagem ou divisão de PDFs quando seu conjunto de testes precisar montar ou desmontar documentos antes da validação.
Entrada
Saída
Quais são as melhores práticas para testes de PDF com Selenium?
Aplicar alguns padrões desde o início ajudará a manter seu conjunto de testes em PDF organizado à medida que o projeto cresce.
Use esperas explícitas em vez de atrasos fixos. Substitua Thread.Sleep() por um observador de sistema de arquivos ou um loop de consulta que verifica a existência do arquivo. A documentação explícita de espera do Selenium abrange estratégias de espera no lado do navegador, e o mesmo princípio se aplica aos downloads. Atrasos fixos são frágeis em máquinas de CI lentas.
Centralize operações PDF em uma classe base. Crie um auxiliar compartilhado ou uma classe de teste base que exponha métodos como LoadPdfFromUrl, DownloadPdf, e ValidateTerms. Os testes individuais permanecem focados nas afirmações em vez da estrutura do PDF. Isso reflete o padrão que o próprio IronPDF segue para a conversão de HTML para PDF e outras operações principais.
Limpe os arquivos baixados após cada teste. Chame File.Delete() em um bloco finally ou um método de desmontagem para que os PDFs temporários não se acumulem no disco. Isso é especialmente importante em execuções de testes paralelos, onde vários arquivos podem ser colocados no mesmo diretório simultaneamente.
Execute testes em várias plataformas sem alterações. O IronPDF funciona no Windows, Linux e macOS sem compilação condicional. O mesmo conjunto de testes que é executado localmente será executado corretamente em agentes de CI baseados em Linux. Consulte o guia de implantação multiplataforma para configuração específica do Docker.
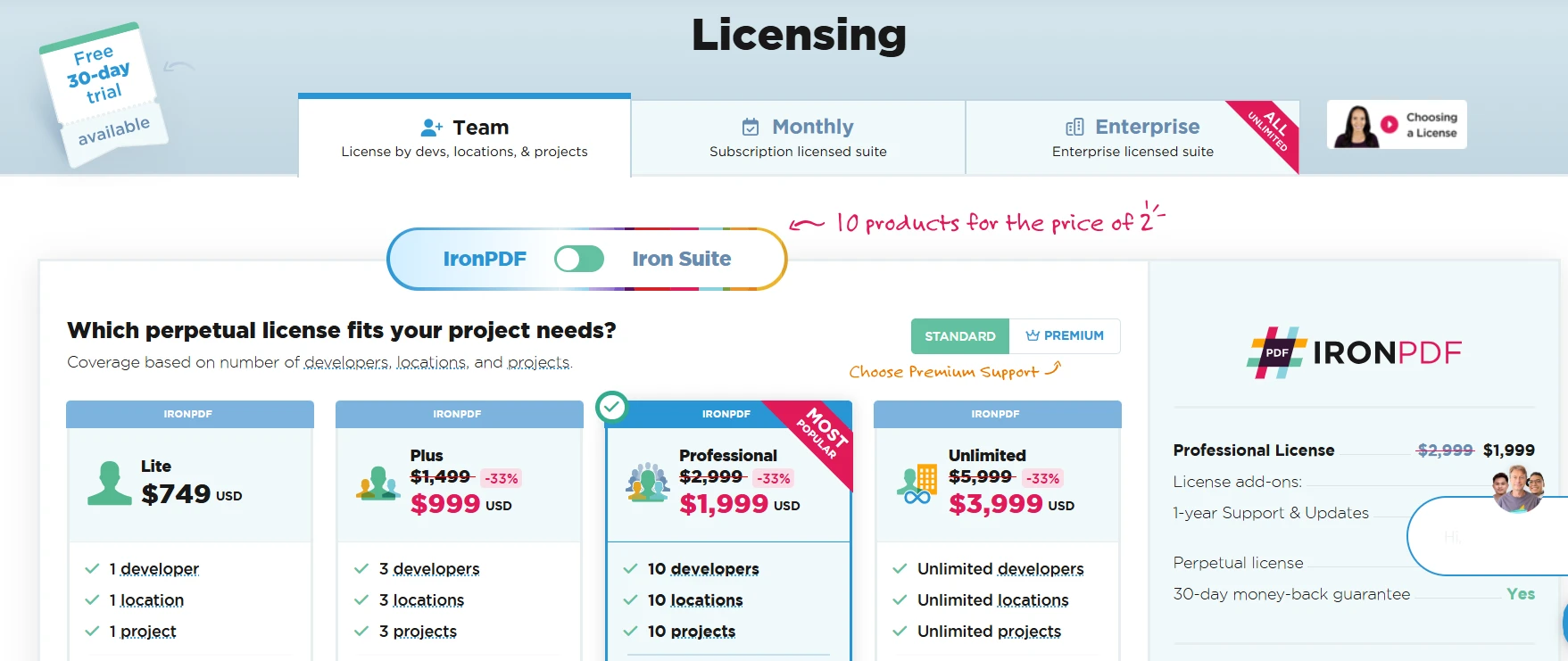
Mantenha as senhas fora do controle de versão. Ao trabalhar com PDFs protegidos, leia as credenciais de variáveis de ambiente ou de um gerenciador de segredos em vez de codificá-las diretamente no código. A sobrecarga PdfDocument.FromFile(path, password) do IronPDF aceita a senha no momento do carregamento, mantendo o local da chamada limpo. A página de licenciamento do IronPDF abrange o licenciamento para equipes e empresas em implantações de produção.
Delimite a extração de texto à página que você precisa. ExtractAllText() é conveniente para documentos pequenos, mas para grandes PDFs com várias páginas, considere chamar ExtractTextFromPage() apenas para as páginas que contêm os dados que você está validando. Isso reduz o uso de memória e acelera a execução dos testes. Consulte a documentação da API para extração de texto para obter as assinaturas completas dos métodos.

Como o IronPDF se compara a outras bibliotecas de PDF for .NET?
| Recurso | IronPDF | iText | PdfPig |
|---|---|---|---|
| Carregar PDF a partir de URL | Sim -- chamada de método único | É necessário fazer o download manual via HTTP. | É necessário fazer o download manual via HTTP. |
| Extrair todo o texto | Sim -- `ExtractAllText()` | Sim -- várias etapas | Sim -- várias etapas |
| Extração ao nível da página | Sim -- `ExtractTextFromPage(n)` | Sim | Sim |
| PDFs protegidos por senha | Sim -- sobrecarga de parâmetros | Sim | Limitado |
| Suporte ao .NET 10 | Sim | Parcial | Sim |
| Geração de HTML para PDF | Sim | Limitado | Não |
| Multiplataforma (Linux, macOS) | Sim | Sim | Sim |
| Tipo de licença | Comercial com período de teste gratuito | AGPL / Comercial | MIT |
O carregamento direto de URLs e a extração de texto com um único método do IronPDF conferem-lhe uma clara vantagem em contextos de automação de testes onde a velocidade de desenvolvimento é crucial. Para equipes que também precisam gerar PDFs a partir de HTML ou manipular documentos existentes no mesmo fluxo de trabalho, ter uma única biblioteca que lide com ambas as tarefas simplifica consideravelmente a árvore de dependências. Alternativas de código aberto como o PdfPig são uma opção razoável para necessidades simples de extração, mas exigem mais configuração para lidar com o carregamento de URLs e não oferecem geração de PDF integrada.
Como posso começar com um teste gratuito?
O IronPDF oferece um período de avaliação gratuito completo para que você possa validar a biblioteca em seu ambiente de teste antes de adquirir uma licença. Não há limitações de marca d'água que afetem os fluxos de trabalho de extração ou validação de texto durante o período de avaliação.
Para começar:
- Instale o pacote NuGet:
dotnet add package IronPdf - Adicione
using IronPdf;ao seu arquivo de teste. - Chame
PdfDocument.FromUrl()ouPdfDocument.FromFile()e comece a extrair texto.
Visite a página de avaliação gratuita do IronPDF para baixar sua chave de avaliação. Para implantações em equipe ou corporativas, revise as opções de licenciamento do IronPDF para encontrar o plano que melhor atenda às suas necessidades.
Recursos adicionais para acelerar sua configuração:
- Guia de início rápido do IronPDF .NET
- Referência completa da API para PdfDocument
- Página do IronPDF no NuGet
- Apoio e exemplos da comunidade
Perguntas frequentes
Por que o Selenium WebDriver não consegue ler arquivos PDF diretamente?
O Selenium WebDriver foi projetado para interagir com elementos da web, que fazem parte do DOM. Os arquivos PDF, no entanto, são renderizados como fluxos binários, não como elementos do DOM, o que torna a interação direta com seu conteúdo impossível para o Selenium.
Como o IronPDF ajuda na leitura de arquivos PDF no Selenium WebDriver?
O IronPDF integra-se perfeitamente com o Selenium WebDriver, permitindo extrair texto e validar dados de PDFs sem a necessidade de configurações complexas ou múltiplas bibliotecas. Isso simplifica significativamente o processo e aumenta a eficiência dos testes.
Quais são os benefícios de usar o IronPDF com Selenium para testes de PDF?
A utilização do IronPDF com Selenium permite um processamento de PDFs simplificado, possibilitando que os desenvolvedores extraiam e validem texto de PDFs com o mínimo de código. Isso reduz a necessidade de configurações adicionais ou bibliotecas externas, tornando o processo mais rápido e eficiente.
É necessário usar bibliotecas adicionais com o IronPDF para testes de PDF em C#?
Não, o IronPDF oferece uma solução completa que lida com a extração e validação de PDFs, eliminando a necessidade de múltiplas bibliotecas ou configurações complexas em seus projetos C#.
O IronPDF consegue lidar com arquivos PDF gerados por aplicativos web modernos?
Sim, o IronPDF é particularmente eficaz com novos documentos PDF gerados por aplicativos da web modernos, permitindo extração de texto e validação de dados eficientes.
O que torna o IronPDF uma ferramenta poderosa para automação de PDFs em Selenium?
Os recursos avançados do IronPDF permitem sua integração com o Selenium WebDriver, proporcionando uma maneira eficiente de gerenciar arquivos PDF. Ele simplifica o processo de leitura e validação do conteúdo de PDFs diretamente em testes automatizados.
Como o IronPDF se compara a soluções Java como o Apache PDFBox?
Ao contrário das soluções em Java, que podem exigir várias declarações de importação e bibliotecas, o IronPDF oferece uma abordagem simplificada que se integra diretamente a projetos C#, simplificando o processo de teste de PDF no Selenium.
O IronPDF é compatível com o Selenium WebDriver em C#?
Sim, o IronPDF foi projetado para funcionar perfeitamente com o Selenium WebDriver em C#, oferecendo uma solução robusta para leitura e validação de arquivos PDF em testes automatizados.
Quais desafios o IronPDF ajuda a resolver nos testes automatizados de PDF?
O IronPDF resolve o desafio de acessar e validar conteúdo de PDFs em testes automatizados, eliminando a necessidade de múltiplas bibliotecas e configurações complexas, e fornecendo uma solução simples e compatível com o Selenium WebDriver.
Como o IronPDF pode melhorar a eficiência dos fluxos de trabalho de testes automatizados?
Ao integrar-se com o Selenium WebDriver, o IronPDF simplifica o processo de extração de texto e validação de dados em PDF, reduzindo a complexidade e o tempo necessários para fluxos de trabalho de teste automatizados.











