
.NET Core PDF Uretici Nasıl Oluşturulur
PDF belgeleri otomatik testte benzersiz bir zorluk sunar: Selenium WebDriver web öğeleriyle etkileşime geçme konusunda mükemmel olsa da, bir PDF'nin içeriğini okuyamaz çünkü dosya, DOM öğeleri yerine bir binary akışı olarak işler. Bu makale, Selenium ile .NET'yi eşleştirerek bu sorunu C#'da nasıl çözeceğinizi gösterir, üretim için hazır bir .NET PDF kütüphanesi ile birkaç kod satırıyla PDF içeriğini çıkarabilir, doğrulayabilir ve işleyebilirsiniz - karmaşık Java tarzı bağımlılık yönetimine gerek yoktur.
Selenium PDF İçeriğiyle Neden Zorlanıyor?
Bir PDF tarayıcıda açıldığında, Selenium sayfaya gidip tarayıcı denetimleriyle etkileşime geçebilir, ancak belge içindeki metin veya verileri sorgulayamaz. PDF'ler gömülü nesneler veya eklentiler olarak işlenir, WebDriver protokolü'nün dolaşabileceği HTML öğeleri olarak değil. Tarayıcının PDF görüntüleyicisi belgeyi görsel olarak işler, ancak Selenium'un inceleyebileceği erişilebilir bir DOM yoktur -- her XPath sorgusu veya CSS seçici hiçbir şey döndürmez.
Geleneksel geçici çözümler, dosyayı diske indirip ayrı bir ayrıştırma kütüphanesi çağırmayı ve her şeyi manuel olarak kablolamayı gerektirir. Bu çok aşamalı süreç karmaşıklık ekler, kırılgan test kodu oluşturur ve dosya yollarının ve izinlerin kontrol edilmesi zor olduğu CI/CD hatlarını karıştırır. .NET, bir URL veya yerel yoldan PDF yükleyip bir tek çağrıda metnini çıkarmanıza izin vererek bu adımların tamamını ortadan kaldırır -- mevcut .NET test projenizin içinde, herhangi bir ara dosya veya yapılandırma olmadan.
Pratik sonuç, test kodunun daha kısa, okunması kolay hale gelmesi ve test ortamı değiştiğinde kırılma olasılığının çok daha az olmasıdır. IronPDF'nin metin çıkarımının ötesinde neler yapabileceğini daha genel bir şekilde incelemek için IronPDF belgeleri merkezini ziyaret edin.

Selenium Testi İçin IronPDF Nasıl Kurulur?
Gerekli paketleri yerleştirmek bir dakikadan az sürüyor. Visual Studio'da Paket Yöneticisi Konsolunu açın ve şu komutu çalıştırın:
Install-Package IronPdf
Projede henüz yoksa Selenium paketlerine de ihtiyacınız olacak:
Install-Package Selenium.WebDriver
Install-Package Selenium.WebDriver.ChromeDriverInstall-Package Selenium.WebDriver
Install-Package Selenium.WebDriver.ChromeDriver
Paketler kurulduktan sonra, test dosyanızın üst kısmında şu using yönergelerini ekleyin:
using IronPdf;
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
using System.IO;using IronPdf;
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
using System.IO;Imports IronPdf
Imports OpenQA.Selenium
Imports OpenQA.Selenium.Chrome
Imports System.IO.NET .NET 10'u hedefler ve Windows, Linux ve macOS'ta çapraz platform olarak çalışır, böylece aynı test kodu her ortamda çalışır -- Docker konteynerleri ve bulut CI aracılar dahil.
PDF'yi URL'den Doğrudan Nasıl Okuyorsunuz?
Bir URL'den gelen PDF içeriğini okumak, indirme adımını tamamen atlar. Selenium bağlantıyı bulur, IronPDF belgeyi yükler ve birkaç satırda assert işlemleriniz için tüm metin kullanıma hazır olur.
// Initialize Chrome driver
var driver = new ChromeDriver();
// Navigate to a webpage containing a PDF link
driver.Navigate().GoToUrl("https://ironpdf.com/");
// Find and capture the PDF URL
IWebElement pdfLink = driver.FindElement(By.CssSelector("a[href$='.pdf']"));
string pdfUrl = pdfLink.GetAttribute("href");
// Load the PDF directly from the URL -- no download needed
var pdf = PdfDocument.FromUrl(new Uri(pdfUrl));
string extractedText = pdf.ExtractAllText();
// Assert expected content
if (extractedText.Contains("IronPDF"))
{
Console.WriteLine("PDF validation passed!");
}
driver.Quit();// Initialize Chrome driver
var driver = new ChromeDriver();
// Navigate to a webpage containing a PDF link
driver.Navigate().GoToUrl("https://ironpdf.com/");
// Find and capture the PDF URL
IWebElement pdfLink = driver.FindElement(By.CssSelector("a[href$='.pdf']"));
string pdfUrl = pdfLink.GetAttribute("href");
// Load the PDF directly from the URL -- no download needed
var pdf = PdfDocument.FromUrl(new Uri(pdfUrl));
string extractedText = pdf.ExtractAllText();
// Assert expected content
if (extractedText.Contains("IronPDF"))
{
Console.WriteLine("PDF validation passed!");
}
driver.Quit();Imports OpenQA.Selenium
Imports OpenQA.Selenium.Chrome
Imports IronPdf
' Initialize Chrome driver
Dim driver As IWebDriver = New ChromeDriver()
' Navigate to a webpage containing a PDF link
driver.Navigate().GoToUrl("https://ironpdf.com/")
' Find and capture the PDF URL
Dim pdfLink As IWebElement = driver.FindElement(By.CssSelector("a[href$='.pdf']"))
Dim pdfUrl As String = pdfLink.GetAttribute("href")
' Load the PDF directly from the URL -- no download needed
Dim pdf As PdfDocument = PdfDocument.FromUrl(New Uri(pdfUrl))
Dim extractedText As String = pdf.ExtractAllText()
' Assert expected content
If extractedText.Contains("IronPDF") Then
Console.WriteLine("PDF validation passed!")
End If
driver.Quit()PdfDocument.FromUrl() bellek içinde belgeyi alır ve ayrıştırır. ExtractAllText() çağrısı, her sayfadaki tüm metni bir dize olarak döndürür, doğrulamalarınız için hazır. Şifre korumalı belgeler için, korumalı dosyaların test sırasında erişilebilir kalmasını sağlamak amacıyla bir ek parametre olarak kimlik bilgilerini iletin. Metin çıkarım seçenekleri hakkında daha fazla bilgi edinmek için IronPDF metin çıkarma kılavuzuna bakın.
Çıktı
PDF'yi Otomatik Olarak Nasıl İndirip İşliyorsunuz?
Bir PDF kimlik doğrulama sonrası veya dinamik bir iş akışı aracılığıyla oluşturulduğunda, öncelikle indirilmeyi gerektirebilir. Chrome'u PDF'leri bilinen bir dizine otomatik olarak indirmesi için yapılandırın, ardından dosya yolunu IronPDF'ye verin:
// Configure Chrome to auto-download PDFs
var chromeOptions = new ChromeOptions();
chromeOptions.AddUserProfilePreference("download.default_directory", @"C:\PDFTests");
chromeOptions.AddUserProfilePreference("plugins.always_open_pdf_externally", true);
var driver = new ChromeDriver(chromeOptions);
string appUrl = "https://example.com/reports";
// Trigger the download
driver.Navigate().GoToUrl(appUrl);
driver.FindElement(By.Id("downloadReport")).Click();
// Wait for the download -- replace Thread.Sleep with a file-system watcher in production tests
System.Threading.Thread.Sleep(3000);
// Read the downloaded PDF
string pdfPath = @"C:\PDFTests\report.pdf";
var pdf = PdfDocument.FromFile(pdfPath);
string content = pdf.ExtractAllText();
// Validate specific data
bool hasExpectedData = content.Contains("Quarterly Revenue: $1.2M");
Console.WriteLine($"Revenue data found: {hasExpectedData}");
// Extract text from a specific page (zero-indexed)
string page2Content = pdf.ExtractTextFromPage(1);
// Clean up
File.Delete(pdfPath);
driver.Quit();// Configure Chrome to auto-download PDFs
var chromeOptions = new ChromeOptions();
chromeOptions.AddUserProfilePreference("download.default_directory", @"C:\PDFTests");
chromeOptions.AddUserProfilePreference("plugins.always_open_pdf_externally", true);
var driver = new ChromeDriver(chromeOptions);
string appUrl = "https://example.com/reports";
// Trigger the download
driver.Navigate().GoToUrl(appUrl);
driver.FindElement(By.Id("downloadReport")).Click();
// Wait for the download -- replace Thread.Sleep with a file-system watcher in production tests
System.Threading.Thread.Sleep(3000);
// Read the downloaded PDF
string pdfPath = @"C:\PDFTests\report.pdf";
var pdf = PdfDocument.FromFile(pdfPath);
string content = pdf.ExtractAllText();
// Validate specific data
bool hasExpectedData = content.Contains("Quarterly Revenue: $1.2M");
Console.WriteLine($"Revenue data found: {hasExpectedData}");
// Extract text from a specific page (zero-indexed)
string page2Content = pdf.ExtractTextFromPage(1);
// Clean up
File.Delete(pdfPath);
driver.Quit();Imports OpenQA.Selenium
Imports OpenQA.Selenium.Chrome
Imports System.IO
Imports System.Threading
' Configure Chrome to auto-download PDFs
Dim chromeOptions As New ChromeOptions()
chromeOptions.AddUserProfilePreference("download.default_directory", "C:\PDFTests")
chromeOptions.AddUserProfilePreference("plugins.always_open_pdf_externally", True)
Dim driver As New ChromeDriver(chromeOptions)
Dim appUrl As String = "https://example.com/reports"
' Trigger the download
driver.Navigate().GoToUrl(appUrl)
driver.FindElement(By.Id("downloadReport")).Click()
' Wait for the download -- replace Thread.Sleep with a file-system watcher in production tests
Thread.Sleep(3000)
' Read the downloaded PDF
Dim pdfPath As String = "C:\PDFTests\report.pdf"
Dim pdf = PdfDocument.FromFile(pdfPath)
Dim content As String = pdf.ExtractAllText()
' Validate specific data
Dim hasExpectedData As Boolean = content.Contains("Quarterly Revenue: $1.2M")
Console.WriteLine($"Revenue data found: {hasExpectedData}")
' Extract text from a specific page (zero-indexed)
Dim page2Content As String = pdf.ExtractTextFromPage(1)
' Clean up
File.Delete(pdfPath)
driver.Quit()plugins.always_open_pdf_externally tercihi, Chrome'un yerleşik PDF görüntüleyicisini atlar, böylece dosyanın tarayıcıda açılması yerine diske kaydedilir. ExtractTextFromPage() farklı sayfalarda farklı doğrulama verileri içeren çok sayfalı bir raporda sayfa seviyesinde hassasiyet sağlar. Büyük belgelerle verimli bir şekilde çalışmak için IronPDF performans ipuçlarını inceleyin.
Otomatik Testlerde PDF İçeriğini Nasıl Doğrularsınız?
Bir belgenin doğru terimler içerdiğini kontrol etmek en yaygın test senaryosudur. Aşağıdaki yardımcı yöntem, bir dosya yolu ve gerekli terimlerin bir dizisini kabul eder, ardından beklenen herhangi bir terim eksik olduğunda anında false döndürür.
bool ValidatePdfContent(string pdfPath, string[] expectedTerms)
{
var pdf = PdfDocument.FromFile(pdfPath);
string fullText = pdf.ExtractAllText();
// Verify each required term
foreach (string term in expectedTerms)
{
if (!fullText.Contains(term, StringComparison.OrdinalIgnoreCase))
{
Console.WriteLine($"Missing expected term: {term}");
return false;
}
}
// Validate first-page structure
if (pdf.PageCount > 0)
{
string firstPageText = pdf.ExtractTextFromPage(0);
if (!firstPageText.Contains("Invoice #") && !firstPageText.Contains("Date:"))
{
Console.WriteLine("Header validation failed");
return false;
}
}
return true;
}bool ValidatePdfContent(string pdfPath, string[] expectedTerms)
{
var pdf = PdfDocument.FromFile(pdfPath);
string fullText = pdf.ExtractAllText();
// Verify each required term
foreach (string term in expectedTerms)
{
if (!fullText.Contains(term, StringComparison.OrdinalIgnoreCase))
{
Console.WriteLine($"Missing expected term: {term}");
return false;
}
}
// Validate first-page structure
if (pdf.PageCount > 0)
{
string firstPageText = pdf.ExtractTextFromPage(0);
if (!firstPageText.Contains("Invoice #") && !firstPageText.Contains("Date:"))
{
Console.WriteLine("Header validation failed");
return false;
}
}
return true;
}Imports System
Function ValidatePdfContent(pdfPath As String, expectedTerms As String()) As Boolean
Dim pdf = PdfDocument.FromFile(pdfPath)
Dim fullText As String = pdf.ExtractAllText()
' Verify each required term
For Each term As String In expectedTerms
If Not fullText.Contains(term, StringComparison.OrdinalIgnoreCase) Then
Console.WriteLine($"Missing expected term: {term}")
Return False
End If
Next
' Validate first-page structure
If pdf.PageCount > 0 Then
Dim firstPageText As String = pdf.ExtractTextFromPage(0)
If Not firstPageText.Contains("Invoice #") AndAlso Not firstPageText.Contains("Date:") Then
Console.WriteLine("Header validation failed")
Return False
End If
End If
Return True
End FunctionStringComparison.OrdinalIgnoreCase oluşturulan belgelerdeki büyük/küçük harf farklarından dolayı testlerin bozulmasını önler. IronPDF, metin düzenini ve biçimlendirmeyi çıkarırken korur, bu nedenle başlık alanlarının birinci sayfada göründüğünü doğrulamak gibi konum doğrulaması, farklı PDF oluşturucular arasında güvenilir bir şekilde çalışır.
Daha gelişmiş senaryolar için, PDF dosyalarından tablolar çıkarın, gömülü görüntüleri çekin veya etkileşimli form alanlarını okuyun, IronPDF her görev için özel API'ler sağlar. Test süitinizin belgeleri doğrulama öncesinde toplaması veya dağıtması gerektiğinde metin çıkarımıyla PDF birleştirme veya bölme iş akışlarını da zincirleyebilirsiniz.
Giriş
Çıktı
Selenium ile PDF Testi İçin En İyi Uygulamalar Nelerdir?
Projeyle birlikte büyüdükçe PDF test süitinizi sürdürülebilir kılmanın birkaç deseni başlangıçta uygulanabilir.
Sabit gecikmeler yerine açık beklemeler kullanın. Thread.Sleep() ifadesini bir dosya sistemi izleyicisi veya dosyanın varlığını kontrol eden bir döngü ile değiştirin. Selenium'un belirgin bekleme belgesi tarayıcı tarafı bekleme stratejilerini kapsar ve aynı ilke indirmelere de uygulanır. Sabit gecikmeler, yavaş CI makinelerinde kırılgandır.
PDF işlemlerini bir temel sınıfta merkezileştirin. LoadPdfFromUrl, DownloadPdf ve ValidateTerms gibi yöntemleri açığa çıkaran ortak bir yardımcı veya temel test sınıfı oluşturun. Bireysel testler sonra PDF tesisatı yerine iddialar üzerinde odaklanır. Bu, IronPDF'nin HTML'den PDF'ye dönüşüm ve diğer temel işlemler için izlediği düzeni yansıtır.
Her testten sonra indirilen dosyaları temizleyin. Geçici PDF'lerin disk üzerinde birikmemesi için bir finally bloğunda veya bir yıkım yönteminde File.Delete() çağırın. Özellikle aynı dizine aynı anda birden fazla dosyanın gelmiş olabileceği paralel test çalıştırmalarında bu önemlidir.
Değişiklik yapmadan çapraz platform testlerini çalıştırın. IronPDF, Windows, Linux ve macOS'ta koşulsuz derleme olmadan çalışır. Yerel olarak çalışan aynı test derlemesi, Linux tabanlı CI aracılarında doğru şekilde çalışacaktır. Docker'a özgü yapılandırma için çapraz platform dağıtım kılavuzuna bakın.
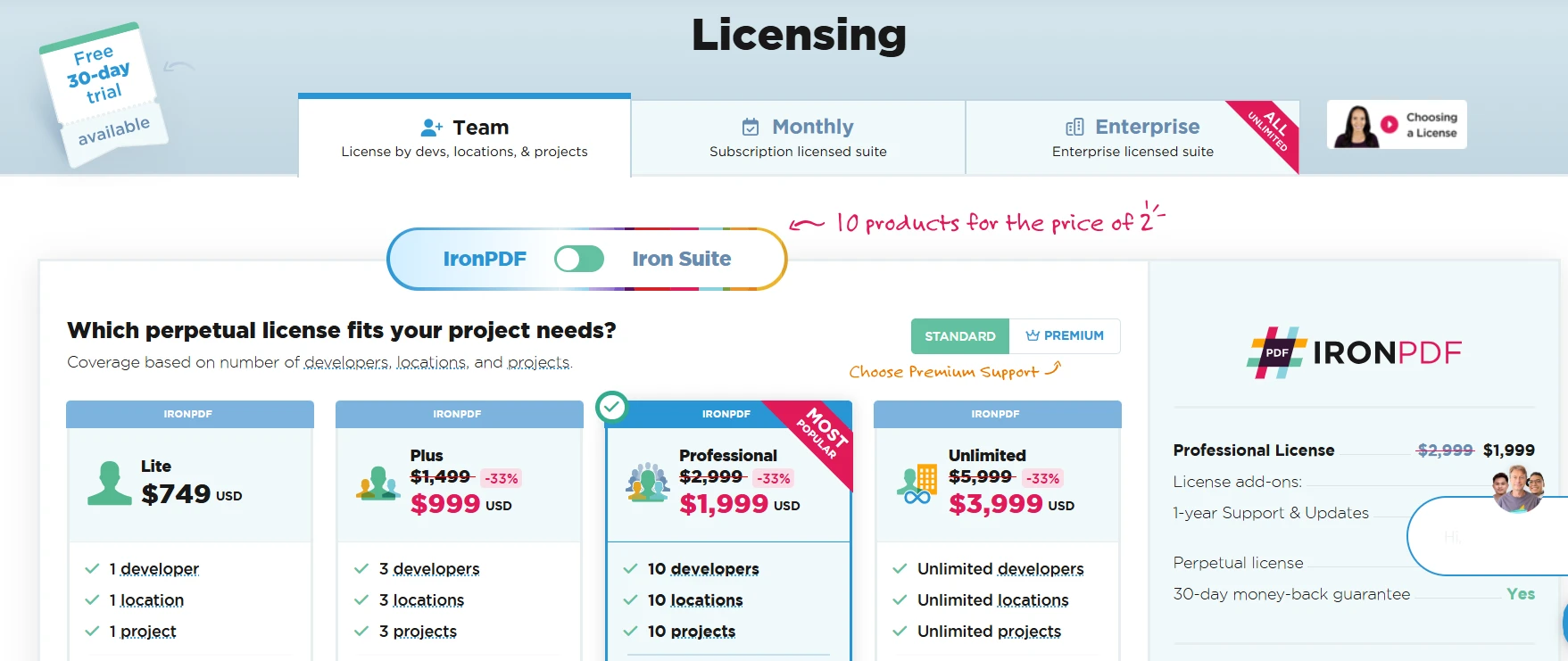
Şifreleri kaynak kontrol dışında tutun. Korumalı PDF'lerle çalışırken, kimlik bilgilerini ortam değişkenlerinden veya bir sır yöneticisinden okuyarak kodlamayın. IronPDF'nin PdfDocument.FromFile(path, password) overload'ı yükleme anında şifreyi kabul eder, böylece çağrı sitesi temiz kalır. IronPDF lisanslama sayfası, üretim dağıtımları için ekip ve kurumsal lisansı içerir.
Metin çıkarımını ihtiyacınız olan sayfayla sınırlandırın. ExtractAllText() küçük belgeler için uygundur, ancak büyük çok sayfalı PDF'ler için yalnızca doğruladığınız verilerin bulunduğu sayfalar için ExtractTextFromPage() çağrılmasını düşünün. Bu, bellek kullanımını azaltır ve test yürütmesini hızlandırır. Metin çıkarımı için API referansına tam yöntem imzaları için başvurun.

.NET, .NET İçin Diğer PDF Kütüphaneleriyle Nasıl Karşılaştırılır?
| Özellik | IronPDF | iText | PdfPig |
|---|---|---|---|
| URL'den PDF Yükle | Evet -- tek yöntem çağrısı | Manuel HTTP indirimi gerekir | Manuel HTTP indirimi gerekir |
| Tüm metni çıkarın | Evet -- `ExtractAllText()` | Evet -- çok adımlı | Evet -- çok adımlı |
| Sayfa düzeyi çıkarım | Evet -- `ExtractTextFromPage(n)` | Evet | Evet |
| Şifreli PDF'ler | Evet -- parametre aşırı yükleme | Evet | Sınırlı |
| .NET 10 desteği | Evet | Kısmi | Evet |
| HTML'den PDF'ye oluşturma | Evet | Sınırlı | Hayır |
| Çapraz platform (Linux, macOS) | Evet | Evet | Evet |
| Lisans türü | Ücretli, ücretsiz deneme sürümü ile | AGPL / Ticari | MIT |
IronPDF'nin doğrudan URL yüklemesi ve tek yöntemle metin çıkarımı, gelişim hızı önemli olduğunda test otomasyon bağlamlarında net bir avantaj sağlar. Hem HTML'den PDF oluşturmaya hem de mevcut belgeleri düzenlemeye ihtiyaç duyan ekipler için, her iki işlemi de aynı iş akışında tek bir kütüphanenin yönetiyor olması, bağımlılık ağacını önemli ölçüde basitleştirir. PdfPig gibi açık kaynak alternatifler, basit çıkarım ihtiyaçları için makul bir uyum sağlayabilir, ancak URL yüklemeyi yönetmek için daha fazla kurulum gerektirirler ve dahili PDF oluşturma imkânı sunmazlar.
Ücretsiz Bir Deneme ile Nasıl Başlanır?
IronPDF, lisans taahhüdü öncesinde kütüphaneyi test ortamınızda doğrulamanız için tam özellikli bir ücretsiz deneme sunar. Deneme süresi boyunca filigran sınırlamaları, metin çıkarımı veya doğrulama iş akışlarını etkilemez.
Başlamak için:
- NuGet paketini yükleyin:
dotnet add package IronPdf - Test dosyanıza
using IronPdf;ekleyin. PdfDocument.FromUrl()veyaPdfDocument.FromFile()çağırın ve metin çıkarmaya başlayın.
IronPDF ücretsiz deneme sayfasını ziyaret ederek deneme anahtarınızı indirin. Ekipler veya kurumsal dağıtımlar için, IronPDF lisans seçeneklerini inceleyerek ihtiyaçlarınıza uygun planı bulun.
Kurulumunuzu hızlandırmak için ek kaynaklar:
- .NET .NET hızlı başlangıç rehberi
- PdfDocument için Tam API referansı
- IronPDF NuGet sayfası
- Topluluk desteği ve örnekler
Sıkça Sorulan Sorular
Neden Selenium WebDriver doğrudan PDF dosyalarını okuyamaz?
Selenium WebDriver, DOM'un parçası olan web elementleriyle etkileşim için tasarlanmıştır. Ancak PDF dosyaları, ikili akış olarak işlendikleri için DOM elementleri değildir ve bu nedenle içerikleriyle doğrudan etkileşim kurmak Selenium için imkansızdır.
IronPDF, Selenium WebDriver'da PDF dosyalarını okumaya nasıl yardımcı olur?
IronPDF, Selenium WebDriver ile sorunsuz bir şekilde entegre olur, karmaşık kurulumlara veya birden fazla kütüphaneye ihtiyaç duymadan metin çıkarmanıza ve PDF verilerini doğrulamanıza olanak tanır. Bu, süreci önemli ölçüde basitleştirir ve test verimliliğini artırır.
IronPDF'yi Selenium ile PDF testi için kullanmanın faydaları nelerdir?
Selenium ile IronPDF kullanmak, PDF işlemlerini kolaylaştırır ve geliştiricilere sadece birkaç satır kodla PDF'lerden metin çıkarmaları ve doğrulamaları sağlar. Bu, ek yapılandırma veya harici kütüphaneler ihtiyacını azaltır, süreci daha hızlı ve verimli hale getirir.
C#'da PDF testi için IronPDF ile ek kütüphaneler kullanmak gerekli mi?
Hayır, IronPDF, PDF çıkarma ve doğrulama işlemlerini yönetmek için kapsamlı bir çözüm sunarak, C# projelerinizde birden fazla kütüphane veya karmaşık yapılandırmalar ihtiyacını ortadan kaldırır.
IronPDF, modern web uygulamaları tarafından üretilen PDF dosyalarını yönetebilir mi?
Evet, IronPDF, modern web uygulamaları tarafından üretilen yeni PDF belgelerinde oldukça etkilidir, bu da verimli metin çıkarımı ve veri doğrulama sağlar.
IronPDF, Selenium'da PDF otomasyonu için güçlü bir araç yapan nedir?
IronPDF'nin güçlü yetenekleri, Selenium WebDriver ile entegre olmasına olanak tanır ve PDF dosyalarını yönetmek için etkili bir yol sağlar. Bu, PDF içeriğini otomatik testler içinde doğrudan okuma ve doğrulama sürecini basitleştirir.
IronPDF, Apache PDFBox gibi Java çözümleriyle nasıl karşılaştırılır?
Java çözümlerinin birden çok import deyimi ve kütüphane gerektirebilir olmasına karşın, IronPDF doğrudan C# projeleriyle entegre olan bir yaklaşım sunar, bu da Selenium'da PDF testi sürecini basitleştirir.
IronPDF, C#'ta Selenium WebDriver ile uyumlu mu?
Evet, IronPDF, C#'ta Selenium WebDriver ile sorunsuz çalışacak şekilde tasarlanmıştır ve otomatik testlerde PDF dosyalarını okumak ve doğrulamak için sağlam bir çözüm sunar.
IronPDF, otomatik PDF testinde hangi zorlukları çözmeye yardımcı olur?
IronPDF, otomatik testlerde PDF içeriğine erişme ve doğrulama zorluğunu ele alır, birden fazla kütüphane ve karmaşık kurulum ihtiyacını ortadan kaldırır ve Selenium WebDriver ile uyumlu basit bir çözüm sağlar.
IronPDF, otomatik test iş akışlarının verimliliğini nasıl artırabilir?
Selenium WebDriver ile entegre olarak, IronPDF, metin çıkarma ve PDF verilerini doğrulama sürecini kolaylaştırır, bu da otomatik test iş akışlarının karmaşıklığını ve gereken zamanı azaltır.











