
Jak przekonwertować PDF na tekst w Python (samouczek)
W tym artykule pokażemy, jak używać IronPDF for Python, jednej z najpotężniejszych bibliotek PDF, do wyodrębniania dowolnego tekstu dostępnego w dokumencie PDF.
Jak przekonwertować plik PDF na tekst w języku Python
- Zainstaluj bibliotekę Python do konwersji plików PDF na tekst
- Załaduj istniejący dokument PDF lub utwórz nowy
- Użyj metody
ExtractAllText,aby odczytać tekst z otwartego pliku - Użyj innego przeciążenia tej metody, aby odczytać tekst z określonych stron.
- PRINT wyodrębniony tekst do konsoli lub zapisz go do pliku tekstowego
2.0 Jak wyodrębnić tekst z pliku PDF za pomocą języka Python?
- Zainstaluj najnowszą wersję języka Python ze strony pobierania Python
- Otwórz dowolne narzędzie IDE dla języka Python
- Zainstaluj środowisko uruchomieniowe .NET Core
- Zainstaluj bibliotekę IronPDF for Python lub pobierz ją ze strony pobierania PyPI
- Wyodrębnij tekst z pliku PDF
2.1 Czym jest IronPDF for Python?
Integracja biblioteki IronPDF z językiem Python jest prosta, ponieważ jest to język znacznie bardziej dynamiczny w porównaniu z innymi językami i umożliwia programistom szybkie i łatwe tworzenie graficznych interfejsów użytkownika. Posiada mnóstwo preinstalowanych narzędzi, w tym PyQT, wxWidgets, kivy oraz liczne dodatkowe pakiety i biblioteki, z których wszystkie mogą być wykorzystane do szybkiego i bezpiecznego tworzenia w pełni kompletnego GUI.
IronPDF for Python to niezwykle wydajna biblioteka, szczególnie przydatna w tworzeniu stron internetowych. Częściowo winę za to ponosi dostępność tak wielu paradygmatów tworzenia stron internetowych w języku Python, takich jak Django, Flask i Pyramid. Frameworki te są wykorzystywane przez wiele stron internetowych i serwisów online, w tym Reddit, Mozilla i Spotify.
2.2 Funkcje IronPDF
- Plik PDF można utworzyć z różnych źródeł, w tym ze stron internetowych w formatach HTML, HTML5, ASP i PHP. Oprócz plików HTML można również konwertować pliki graficzne do formatu PDF.
- IronPDF umożliwia tworzenie interaktywnych dokumentów PDF, wypełnianie i wysyłanie interaktywnych formularzy, dzielenie i łączenie plików PDF, wyodrębnianie tekstu i obrazów z plików PDF, wyszukiwanie określonych słów w pliku PDF, rasteryzację stron PDF do obrazów, konwersję PDF do HTML oraz drukowanie plików PDF.
- IronPDF umożliwia otwieranie plików PDF i drukowanie z adresu URL. Ponadto umożliwia agentom użytkownika logowanie się za formularzami logowania HTML, serwerami proxy, plikami cookie, nagłówkami HTTP, niestandardowymi danymi logowania do sieci, zmiennymi formularzy i agentami użytkownika.
- Obrazy można wyodrębnić z dokumentów za pomocą IronPDF.
- Dzięki IronPDF bardzo łatwo jest dodawać do dokumentów nagłówki i stopki, tekst i obrazy, zakładki i znaki wodne oraz wiele innych elementów.
- Za pomocą IronPDF można łączyć i rozdzielać strony, korzystając z nowego lub istniejącego dokumentu.
- Bez korzystania z przeglądarki Acrobat dokumenty można konwertować na obiekty PDF.
- Plik CSS może służyć do tworzenia dokumentów PDF.
- Tworzenie dokumentów jest możliwe przy użyciu plików CSS typu media.
2.3 Import biblioteki IronPDF
Aby zaimportować IronPDF, należy umieścić następujące instrukcje importu na początku plików źródłowych, w których będzie używany IronPDF:
from ironpdf import *from ironpdf import *2.4 Ustaw klucz licencyjny (jeśli jest wymagany)
Chociaż IronPDF for Python jest darmowy, w plikach PDF dla darmowych użytkowników umieszcza się znak wodny w postaci mozaikowego tła. Aby korzystać z IronPDF do tworzenia plików PDF bez znaków wodnych, należy podać bibliotece prawidłowy klucz licencyjny. Sposób konfiguracji biblioteki za pomocą klucza licencyjnego pokazano w poniższym fragmencie kodu:
# Set the license key for IronPDF
License.LicenseKey = "IRONPDF-LICENSE-KEY-ABCDEFGH"# Set the license key for IronPDF
License.LicenseKey = "IRONPDF-LICENSE-KEY-ABCDEFGH"Przed utworzeniem plików PDF lub wprowadzeniem zmian w ich treści upewnij się, że klucz licencyjny jest skonfigurowany. Metoda LicenseKey powinna być wywołana przed innymi wierszami kodu. Aby uzyskać bezpłatną licencję probną, odwiedź stronę licencyjną.
2.5 Pliki dziennika
Plik tekstowy o nazwie "Default" może przechowywać komunikaty dziennika wygenerowane przez Custom.log w katalogu skryptu Python. Poniższy fragment kodu służy do ustawienia właściwości LogFilePath oraz dostosowania nazwy i lokalizacji pliku dziennika:
# Enable debugging and set the log file path and mode
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All# Enable debugging and set the log file path and mode
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All3.0 Wyodrębnianie tekstu z plików PDF za pomocą IronPDF
Biblioteka IronPDF for Python umożliwia konwersję stron PDF na obiekty PDF oraz pozwala na wyodrębnianie tekstu z plików PDF, w tym ze skanowanych plików PDF. Oto przykład pokazujący, jak odczytać istniejący plik PDF za pomocą IronPDF.
Pierwsza metoda polega na wyodrębnieniu całego tekstu dostępnego w pliku PDF; Poniżej znajduje się przykładowy fragment kodu.
from ironpdf import *
# Load existing PDF document
pdf = PdfDocument.FromFile("content.pdf")
# Extract all the text from the entire PDF document
all_text = pdf.ExtractAllText()
# Display the extracted text
print(all_text)from ironpdf import *
# Load existing PDF document
pdf = PdfDocument.FromFile("content.pdf")
# Extract all the text from the entire PDF document
all_text = pdf.ExtractAllText()
# Display the extracted text
print(all_text)Jak pokazano w powyższym kodzie, metoda FromFile jest obiektem czytnika PDF, który ładuje istniejący plik PDF i konwertuje go na obiekty dokumentu PDF. Ten obiekt może służyć do odczytu tekstu i obrazów dostępnych na stronach pliku PDF. Obiekt udostępnia metodę o nazwie ExtractAllText, która pobiera każdy fragment tekstu z całego pliku PDF, przechowując go w ciągu znaków, który można przetwarzać. Następnie użyj funkcji print, aby wyświetlić tekst.
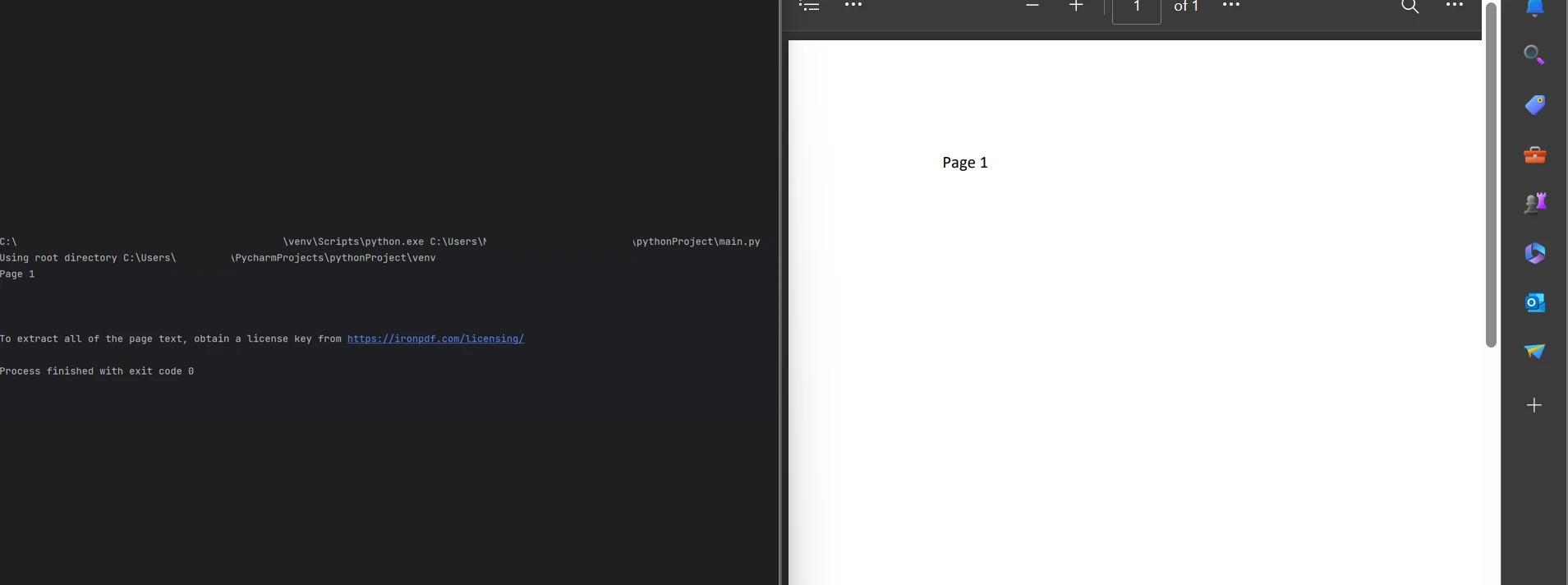 Wyświetlanie tekstu
Wyświetlanie tekstu
Przykład kodu dla drugiej metody, którą można wykorzystać do wyodrębniania tekstu z pliku PDF strona po stronie. Znajduje się on poniżej.
from ironpdf import *
# Load existing PDF document
pdf = PdfDocument.FromFile("content.pdf")
# Extract text from a specific page in the document
page_text = pdf.ExtractTextFromPage(1)
# Display the extracted text from the specified page
print(page_text)from ironpdf import *
# Load existing PDF document
pdf = PdfDocument.FromFile("content.pdf")
# Extract text from a specific page in the document
page_text = pdf.ExtractTextFromPage(1)
# Display the extracted text from the specified page
print(page_text)Metoda FromFile służy do wczytania pliku PDF z istniejącego pliku i przekształcenia go w obiekt pliku PDF, jak pokazano w powyższym kodzie. Metoda obiektu strony PDF o nazwie ExtractTextFromPage pobiera cały tekst ze strony w pliku PDF. Aby wyodrębnić tekst z konkretnej strony, należy podać numer strony jako parametr. Następnie, po wyodrębnieniu tekstu, można użyć page_text do przechowywania informacji, które mogą być przetwarzane.
Zobacz więcej przykładów wyodrębniania tekstu z plików PDF.
4.0 Podsumowanie
Natomiast biblioteka IronPDF oferuje solidne zabezpieczenia, które ograniczają potencjalne ryzyko. Nie jest dostosowany do żadnej konkretnej przeglądarki i działa ze wszystkimi powszechnie używanymi przeglądarkami. IronPDF pozwala programistom w prosty sposób tworzyć i odczytywać pliki PDF za pomocą zaledwie kilku linii kodu. Biblioteka IronPDF oferuje szereg opcji licencyjnych, w tym bezpłatną licencję dla programistów oraz dodatkowe licencje programistyczne dostępne w sprzedaży, aby zaspokoić potrzeby różnych programistów.
IronPDF obejmuje Licencję wieczystą, 30-dniową gwarancję zwrotu pieniędzy, roczną pomoc techniczną oraz opcje aktualizacji. Po dokonaniu pierwszego zakupu nie ma żadnych dodatkowych kosztów. Licencje te mogą być wykorzystywane w środowiskach programistycznych, testowych i produkcyjnych. Dowiedz się więcej o licencjonowaniu produktów.
Pobierz oprogramowanie.
Często Zadawane Pytania
Jak przekonwertować plik PDF na tekst w języku Python?
Możesz przekonwertować plik PDF na tekst w języku Python, używając metody PdfDocument.FromFile biblioteki IronPDF do załadowania pliku PDF, a następnie stosując metody ExtractAllText lub ExtractTextFromPage w celu wyodrębnienia wymaganego tekstu.
Jakie ustawienia są wymagane do korzystania z biblioteki PDF w języku Python?
Aby korzystać z IronPDF, należy zainstalować Python i środowisko IDE, a także środowisko uruchomieniowe .NET Core. IronPDF można zainstalować za pośrednictwem strony pobierania PyPI.
Czy mogę wyodrębnić tekst z określonej strony w pliku PDF za pomocą języka Python?
Tak, w IronPDF można użyć metody ExtractTextFromPage do wyodrębnienia tekstu z określonej strony, podając numer strony jako parametr.
Czy istnieją darmowe opcje korzystania z biblioteki PDF w języku Python?
IronPDF for Python oferuje bezpłatną wersję, która dodaje znak wodny do plików PDF. Aby usunąć znaki wodne i odblokować pełną funkcjonalność, potrzebny jest klucz licencyjny.
Jak zintegrować bibliotekę PDF z frameworkami internetowymi, takimi jak Django lub Flask?
IronPDF płynnie integruje się z frameworkami internetowymi, takimi jak Django i Flask, umożliwiając generowanie i edycję plików PDF w ramach projektów aplikacji internetowych.
Na jakie funkcje powinienem zwrócić uwagę w bibliotece PDF dla języka Python?
Kompleksowa biblioteka PDF, taka jak IronPDF, powinna umożliwiać tworzenie plików PDF z HTML i obrazów, wyodrębnianie tekstu, wypełnianie formularzy, łączenie plików PDF oraz dodawanie zakładek i znaków wodnych.
Jak ustawić klucz licencyjny dla biblioteki PDF w języku Python?
W przypadku IronPDF należy ustawić klucz licencyjny za pomocą metody License.LicenseKey przed wykonaniem jakiegokolwiek innego kodu, aby zarejestrować licencję i usunąć znaki wodne.
Czy biblioteka Python PDF obsługuje tworzenie plików PDF ze stron internetowych?
IronPDF umożliwia tworzenie plików PDF z HTML, HTML5 oraz stron internetowych zbudowanych przy użyciu ASP lub PHP, co czyni go wszechstronnym narzędziem do generowania plików PDF w sieci.
Jak włączyć debugowanie w bibliotece PDF dla języka Python?
Włącz debugowanie w IronPDF, ustawiając Logger.EnableDebugging na true i definiując ścieżkę do pliku dziennika za pomocą Logger.LogFilePath.
Jakie są funkcje bezpieczeństwa biblioteki PDF dla języka Python?
IronPDF zapewnia bezpieczeństwo i kompatybilność z różnymi przeglądarkami, oferując niezawodne rozwiązanie dla programistów poszukujących bezpiecznej obsługi plików PDF w języku Python.
















