
Como converter HTML para PDF em ASP.NET usando C#
A comparação programática de documentos PDF é essencial para rastrear alterações, validar diferentes versões e automatizar fluxos de trabalho de garantia de qualidade. Seja para comparar dois arquivos PDF para gerenciamento de documentos ou para encontrar diferenças em revisões de contratos, o IronPDF oferece uma solução simplificada para comparar arquivos PDF em C#.
Este tutorial demonstra como comparar dois documentos PDF usando os recursos de extração de texto do IronPDF, desde comparações básicas até a criação de relatórios de diferenças detalhados. Você aprenderá técnicas práticas com exemplos de código que funcionam em plataformas Windows, Linux, macOS, Docker e nuvem.
Pré-requisitos e configuração
Antes de começar, certifique-se de ter instalado:
- Visual Studio 2019 ou posterior
- .NET Framework 4.6.2 ou superior ou .NET Core 3.1 ou superior
- Conhecimento básico de C#
Instalando o pacote IronPDF .NET
Instale o IronPDF através do Gerenciador de Pacotes NuGet em seu projeto .NET :
Install-Package IronPdf
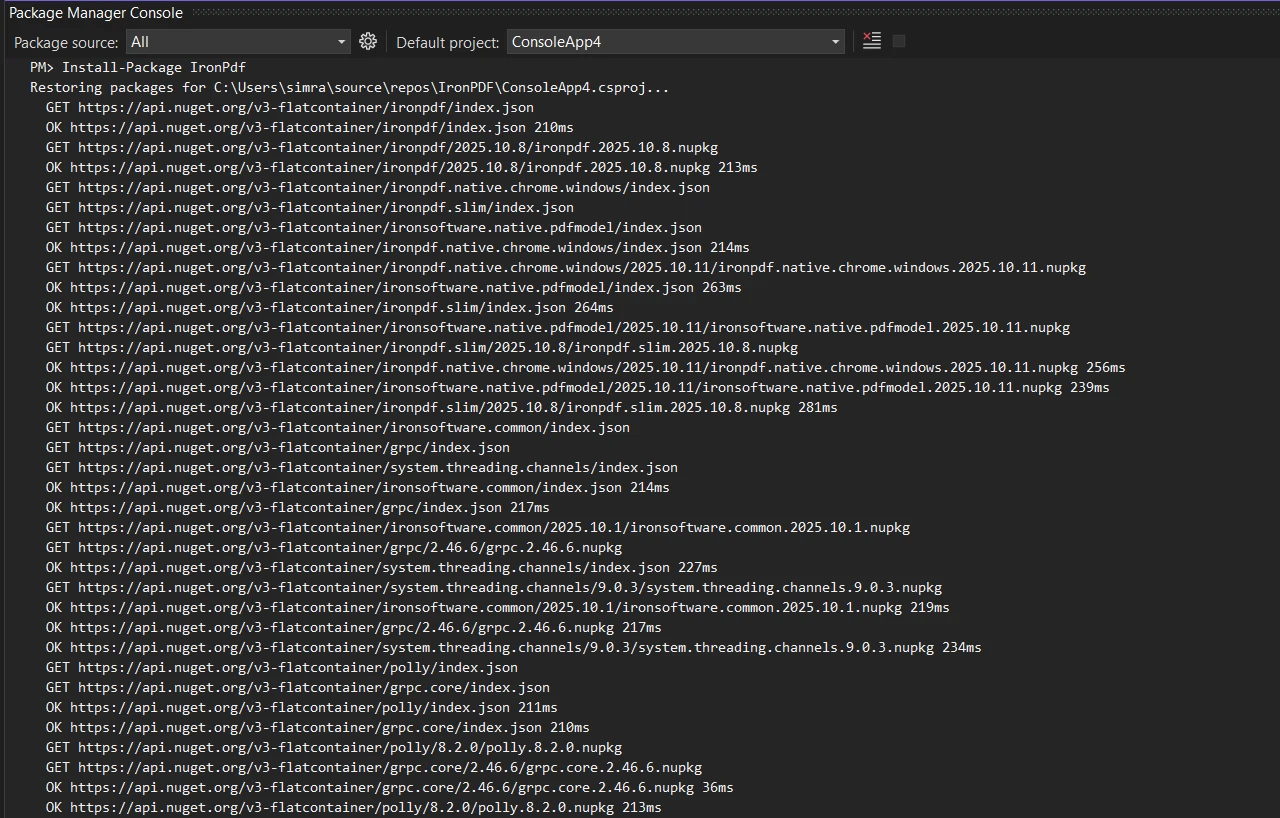
Ou usando a CLI do .NET:
dotnet add package IronPdf
Adicione a referência de namespace necessária aos seus arquivos:
using IronPdf;
using System;using IronPdf;
using System;Imports IronPdf
Imports System
Comparação básica de documentos PDF
Vamos começar com um exemplo de código para comparar arquivos PDF, extraindo e comparando seu conteúdo de texto:
public class BasicPdfComparer
{
public static bool ComparePdfFiles(string firstPdfPath, string secondPdfPath)
{
// Load two PDF documents
var pdf1 = PdfDocument.FromFile(firstPdfPath);
var pdf2 = PdfDocument.FromFile(secondPdfPath);
// Extract all text from both PDFs
string text1 = pdf1.ExtractAllText();
string text2 = pdf2.ExtractAllText();
// Compare the two documents
bool areIdentical = text1 == text2;
// Find differences and calculate similarity
double similarity = CalculateSimilarity(text1, text2);
Console.WriteLine($"Documents are {(areIdentical ? "identical" : "different")}");
Console.WriteLine($"Similarity: {similarity:F2}%");
return areIdentical;
}
private static double CalculateSimilarity(string text1, string text2)
{
if (text1 == text2) return 100.0;
if (string.IsNullOrEmpty(text1) || string.IsNullOrEmpty(text2)) return 0.0;
int matchingChars = 0;
int minLength = Math.Min(text1.Length, text2.Length);
for (int i = 0; i < minLength; i++)
{
if (text1[i] == text2[i]) matchingChars++;
}
return (double)matchingChars / Math.Max(text1.Length, text2.Length) * 100;
}
}public class BasicPdfComparer
{
public static bool ComparePdfFiles(string firstPdfPath, string secondPdfPath)
{
// Load two PDF documents
var pdf1 = PdfDocument.FromFile(firstPdfPath);
var pdf2 = PdfDocument.FromFile(secondPdfPath);
// Extract all text from both PDFs
string text1 = pdf1.ExtractAllText();
string text2 = pdf2.ExtractAllText();
// Compare the two documents
bool areIdentical = text1 == text2;
// Find differences and calculate similarity
double similarity = CalculateSimilarity(text1, text2);
Console.WriteLine($"Documents are {(areIdentical ? "identical" : "different")}");
Console.WriteLine($"Similarity: {similarity:F2}%");
return areIdentical;
}
private static double CalculateSimilarity(string text1, string text2)
{
if (text1 == text2) return 100.0;
if (string.IsNullOrEmpty(text1) || string.IsNullOrEmpty(text2)) return 0.0;
int matchingChars = 0;
int minLength = Math.Min(text1.Length, text2.Length);
for (int i = 0; i < minLength; i++)
{
if (text1[i] == text2[i]) matchingChars++;
}
return (double)matchingChars / Math.Max(text1.Length, text2.Length) * 100;
}
}Imports System
Public Class BasicPdfComparer
Public Shared Function ComparePdfFiles(firstPdfPath As String, secondPdfPath As String) As Boolean
' Load two PDF documents
Dim pdf1 = PdfDocument.FromFile(firstPdfPath)
Dim pdf2 = PdfDocument.FromFile(secondPdfPath)
' Extract all text from both PDFs
Dim text1 As String = pdf1.ExtractAllText()
Dim text2 As String = pdf2.ExtractAllText()
' Compare the two documents
Dim areIdentical As Boolean = text1 = text2
' Find differences and calculate similarity
Dim similarity As Double = CalculateSimilarity(text1, text2)
Console.WriteLine($"Documents are {(If(areIdentical, "identical", "different"))}")
Console.WriteLine($"Similarity: {similarity:F2}%")
Return areIdentical
End Function
Private Shared Function CalculateSimilarity(text1 As String, text2 As String) As Double
If text1 = text2 Then Return 100.0
If String.IsNullOrEmpty(text1) OrElse String.IsNullOrEmpty(text2) Then Return 0.0
Dim matchingChars As Integer = 0
Dim minLength As Integer = Math.Min(text1.Length, text2.Length)
For i As Integer = 0 To minLength - 1
If text1(i) = text2(i) Then matchingChars += 1
Next
Return matchingChars / Math.Max(text1.Length, text2.Length) * 100
End Function
End ClassEste código carrega dois arquivos PDF usando o método PdfDocument.FromFile() da IronPDF, extrai todo o conteúdo de texto e realiza uma comparação direta de strings. O método de comparação fornece métricas para identificar o grau de similaridade entre os documentos.
Entrada
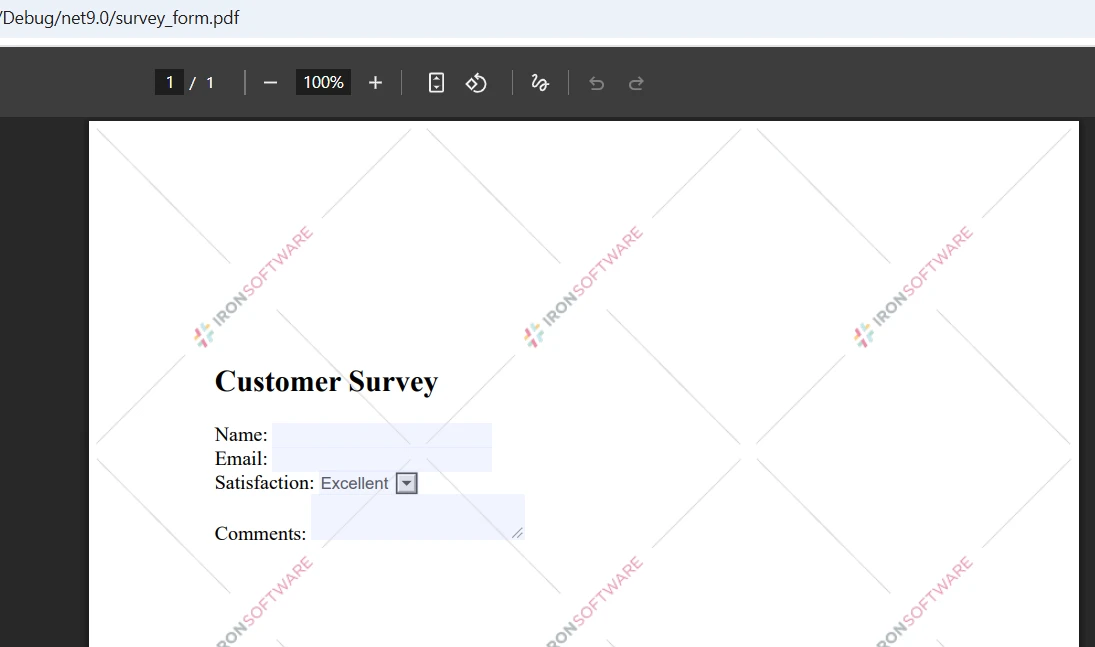
Saída
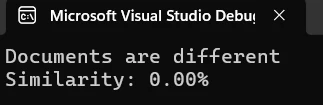
Método de comparação página por página
Para uma análise mais detalhada, compare os dois PDFs página por página para identificar exatamente onde ocorrem as diferenças:
public static void ComparePageByPage(string firstPdfPath, string secondPdfPath)
{
// Load two files
var pdf1 = PdfDocument.FromFile(firstPdfPath);
var pdf2 = PdfDocument.FromFile(secondPdfPath);
int maxPages = Math.Max(pdf1.PageCount, pdf2.PageCount);
int differencesFound = 0;
for (int i = 0; i < maxPages; i++)
{
// Process each page
string page1Text = i < pdf1.PageCount ? pdf1.ExtractTextFromPage(i) : "";
string page2Text = i < pdf2.PageCount ? pdf2.ExtractTextFromPage(i) : "";
if (page1Text != page2Text)
{
differencesFound++;
Console.WriteLine($"Page {i + 1}: Differences detected");
}
else
{
Console.WriteLine($"Page {i + 1}: Identical");
}
}
Console.WriteLine($"\nSummary: {differencesFound} page(s) with changes");
}public static void ComparePageByPage(string firstPdfPath, string secondPdfPath)
{
// Load two files
var pdf1 = PdfDocument.FromFile(firstPdfPath);
var pdf2 = PdfDocument.FromFile(secondPdfPath);
int maxPages = Math.Max(pdf1.PageCount, pdf2.PageCount);
int differencesFound = 0;
for (int i = 0; i < maxPages; i++)
{
// Process each page
string page1Text = i < pdf1.PageCount ? pdf1.ExtractTextFromPage(i) : "";
string page2Text = i < pdf2.PageCount ? pdf2.ExtractTextFromPage(i) : "";
if (page1Text != page2Text)
{
differencesFound++;
Console.WriteLine($"Page {i + 1}: Differences detected");
}
else
{
Console.WriteLine($"Page {i + 1}: Identical");
}
}
Console.WriteLine($"\nSummary: {differencesFound} page(s) with changes");
}Public Shared Sub ComparePageByPage(firstPdfPath As String, secondPdfPath As String)
' Load two files
Dim pdf1 = PdfDocument.FromFile(firstPdfPath)
Dim pdf2 = PdfDocument.FromFile(secondPdfPath)
Dim maxPages As Integer = Math.Max(pdf1.PageCount, pdf2.PageCount)
Dim differencesFound As Integer = 0
For i As Integer = 0 To maxPages - 1
' Process each page
Dim page1Text As String = If(i < pdf1.PageCount, pdf1.ExtractTextFromPage(i), "")
Dim page2Text As String = If(i < pdf2.PageCount, pdf2.ExtractTextFromPage(i), "")
If page1Text <> page2Text Then
differencesFound += 1
Console.WriteLine($"Page {i + 1}: Differences detected")
Else
Console.WriteLine($"Page {i + 1}: Identical")
End If
Next
Console.WriteLine(vbCrLf & $"Summary: {differencesFound} page(s) with changes")
End SubO método ExtractTextFromPage() permite extração direcionada de páginas específicas. Essa abordagem ajuda os desenvolvedores a identificar discrepâncias entre diferentes versões de documentos PDF.
Utilizando o padrão de classe Comparer
Crie uma classe de comparação dedicada para aprimorar sua funcionalidade de comparação:
public class PdfComparer
{
private PdfDocument pdf1;
private PdfDocument pdf2;
private bool disposed;
public PdfComparer(string file1Path, string file2Path)
{
// Load the two PDFs
pdf1 = PdfDocument.FromFile(file1Path);
pdf2 = PdfDocument.FromFile(file2Path);
}
public ComparisonResult Compare()
{
var result = new ComparisonResult();
// Compare PDF documents
string text1 = pdf1?.ExtractAllText() ?? string.Empty;
string text2 = pdf2?.ExtractAllText() ?? string.Empty;
result.AreIdentical = string.Equals(text1, text2, StringComparison.Ordinal);
result.SimilarityPercent = CalculateSimilarity(text1, text2);
result.Differences = FindDifferences(text1, text2);
return result;
}
private List<string> FindDifferences(string text1, string text2)
{
var differences = new List<string>();
// Normalize nulls
text1 ??= string.Empty;
text2 ??= string.Empty;
if (string.Equals(text1, text2, StringComparison.Ordinal))
return differences;
// Page-aware comparisons aren't possible here because we only have full-text;
// produce a concise, actionable difference entry:
int min = Math.Min(text1.Length, text2.Length);
int firstDiff = -1;
for (int i = 0; i < min; i++)
{
if (text1[i] != text2[i])
{
firstDiff = i;
break;
}
}
if (firstDiff == -1 && text1.Length != text2.Length)
{
// No differing character in the overlap, but lengths differ
firstDiff = min;
}
// Create short excerpts around the first difference for context
int excerptLength = 200;
string excerpt1 = string.Empty;
string excerpt2 = string.Empty;
if (firstDiff >= 0)
{
int start1 = Math.Max(0, firstDiff);
int len1 = Math.Min(excerptLength, Math.Max(0, text1.Length - start1));
excerpt1 = start1 < text1.Length ? text1.Substring(start1, len1) : string.Empty;
int start2 = Math.Max(0, firstDiff);
int len2 = Math.Min(excerptLength, Math.Max(0, text2.Length - start2));
excerpt2 = start2 < text2.Length ? text2.Substring(start2, len2) : string.Empty;
}
// HTML-encode excerpts if they will be embedded into HTML reports
string safeExcerpt1 = System.Net.WebUtility.HtmlEncode(excerpt1);
string safeExcerpt2 = System.Net.WebUtility.HtmlEncode(excerpt2);
double similarity = CalculateSimilarity(text1, text2);
differences.Add($"Similarity: {similarity:F2}%. Lengths: [{text1.Length}, {text2.Length}]. First difference index: {firstDiff}. Excerpt1: \"{safeExcerpt1}\" Excerpt2: \"{safeExcerpt2}\"");
return differences;
}
public void Close()
{
Dispose();
}
public void Dispose()
{
if (disposed) return;
disposed = true;
pdf1?.Dispose();
pdf2?.Dispose();
}
}
public class ComparisonResult
{
// True when extracted text is exactly the same
public bool AreIdentical { get; set; }
// Similarity expressed as percent (0..100)
public double SimilarityPercent { get; set; }
// Human readable difference entries
public List<string> Differences { get; set; } = new List<string>();
}public class PdfComparer
{
private PdfDocument pdf1;
private PdfDocument pdf2;
private bool disposed;
public PdfComparer(string file1Path, string file2Path)
{
// Load the two PDFs
pdf1 = PdfDocument.FromFile(file1Path);
pdf2 = PdfDocument.FromFile(file2Path);
}
public ComparisonResult Compare()
{
var result = new ComparisonResult();
// Compare PDF documents
string text1 = pdf1?.ExtractAllText() ?? string.Empty;
string text2 = pdf2?.ExtractAllText() ?? string.Empty;
result.AreIdentical = string.Equals(text1, text2, StringComparison.Ordinal);
result.SimilarityPercent = CalculateSimilarity(text1, text2);
result.Differences = FindDifferences(text1, text2);
return result;
}
private List<string> FindDifferences(string text1, string text2)
{
var differences = new List<string>();
// Normalize nulls
text1 ??= string.Empty;
text2 ??= string.Empty;
if (string.Equals(text1, text2, StringComparison.Ordinal))
return differences;
// Page-aware comparisons aren't possible here because we only have full-text;
// produce a concise, actionable difference entry:
int min = Math.Min(text1.Length, text2.Length);
int firstDiff = -1;
for (int i = 0; i < min; i++)
{
if (text1[i] != text2[i])
{
firstDiff = i;
break;
}
}
if (firstDiff == -1 && text1.Length != text2.Length)
{
// No differing character in the overlap, but lengths differ
firstDiff = min;
}
// Create short excerpts around the first difference for context
int excerptLength = 200;
string excerpt1 = string.Empty;
string excerpt2 = string.Empty;
if (firstDiff >= 0)
{
int start1 = Math.Max(0, firstDiff);
int len1 = Math.Min(excerptLength, Math.Max(0, text1.Length - start1));
excerpt1 = start1 < text1.Length ? text1.Substring(start1, len1) : string.Empty;
int start2 = Math.Max(0, firstDiff);
int len2 = Math.Min(excerptLength, Math.Max(0, text2.Length - start2));
excerpt2 = start2 < text2.Length ? text2.Substring(start2, len2) : string.Empty;
}
// HTML-encode excerpts if they will be embedded into HTML reports
string safeExcerpt1 = System.Net.WebUtility.HtmlEncode(excerpt1);
string safeExcerpt2 = System.Net.WebUtility.HtmlEncode(excerpt2);
double similarity = CalculateSimilarity(text1, text2);
differences.Add($"Similarity: {similarity:F2}%. Lengths: [{text1.Length}, {text2.Length}]. First difference index: {firstDiff}. Excerpt1: \"{safeExcerpt1}\" Excerpt2: \"{safeExcerpt2}\"");
return differences;
}
public void Close()
{
Dispose();
}
public void Dispose()
{
if (disposed) return;
disposed = true;
pdf1?.Dispose();
pdf2?.Dispose();
}
}
public class ComparisonResult
{
// True when extracted text is exactly the same
public bool AreIdentical { get; set; }
// Similarity expressed as percent (0..100)
public double SimilarityPercent { get; set; }
// Human readable difference entries
public List<string> Differences { get; set; } = new List<string>();
}Imports System
Imports System.Collections.Generic
Imports System.Net
Public Class PdfComparer
Implements IDisposable
Private pdf1 As PdfDocument
Private pdf2 As PdfDocument
Private disposed As Boolean
Public Sub New(file1Path As String, file2Path As String)
' Load the two PDFs
pdf1 = PdfDocument.FromFile(file1Path)
pdf2 = PdfDocument.FromFile(file2Path)
End Sub
Public Function Compare() As ComparisonResult
Dim result As New ComparisonResult()
' Compare PDF documents
Dim text1 As String = If(pdf1?.ExtractAllText(), String.Empty)
Dim text2 As String = If(pdf2?.ExtractAllText(), String.Empty)
result.AreIdentical = String.Equals(text1, text2, StringComparison.Ordinal)
result.SimilarityPercent = CalculateSimilarity(text1, text2)
result.Differences = FindDifferences(text1, text2)
Return result
End Function
Private Function FindDifferences(text1 As String, text2 As String) As List(Of String)
Dim differences As New List(Of String)()
' Normalize nulls
text1 = If(text1, String.Empty)
text2 = If(text2, String.Empty)
If String.Equals(text1, text2, StringComparison.Ordinal) Then
Return differences
End If
' Page-aware comparisons aren't possible here because we only have full-text;
' produce a concise, actionable difference entry:
Dim min As Integer = Math.Min(text1.Length, text2.Length)
Dim firstDiff As Integer = -1
For i As Integer = 0 To min - 1
If text1(i) <> text2(i) Then
firstDiff = i
Exit For
End If
Next
If firstDiff = -1 AndAlso text1.Length <> text2.Length Then
' No differing character in the overlap, but lengths differ
firstDiff = min
End If
' Create short excerpts around the first difference for context
Dim excerptLength As Integer = 200
Dim excerpt1 As String = String.Empty
Dim excerpt2 As String = String.Empty
If firstDiff >= 0 Then
Dim start1 As Integer = Math.Max(0, firstDiff)
Dim len1 As Integer = Math.Min(excerptLength, Math.Max(0, text1.Length - start1))
excerpt1 = If(start1 < text1.Length, text1.Substring(start1, len1), String.Empty)
Dim start2 As Integer = Math.Max(0, firstDiff)
Dim len2 As Integer = Math.Min(excerptLength, Math.Max(0, text2.Length - start2))
excerpt2 = If(start2 < text2.Length, text2.Substring(start2, len2), String.Empty)
End If
' HTML-encode excerpts if they will be embedded into HTML reports
Dim safeExcerpt1 As String = WebUtility.HtmlEncode(excerpt1)
Dim safeExcerpt2 As String = WebUtility.HtmlEncode(excerpt2)
Dim similarity As Double = CalculateSimilarity(text1, text2)
differences.Add($"Similarity: {similarity:F2}%. Lengths: [{text1.Length}, {text2.Length}]. First difference index: {firstDiff}. Excerpt1: ""{safeExcerpt1}"" Excerpt2: ""{safeExcerpt2}""")
Return differences
End Function
Public Sub Close()
Dispose()
End Sub
Public Sub Dispose() Implements IDisposable.Dispose
If disposed Then Return
disposed = True
pdf1?.Dispose()
pdf2?.Dispose()
End Sub
End Class
Public Class ComparisonResult
' True when extracted text is exactly the same
Public Property AreIdentical As Boolean
' Similarity expressed as percent (0..100)
Public Property SimilarityPercent As Double
' Human readable difference entries
Public Property Differences As List(Of String) = New List(Of String)()
End ClassEssa estrutura de classes oferece uma maneira clara de comparar documentos PDF, gerenciando objetos e referências de documentos de forma adequada.
Saída
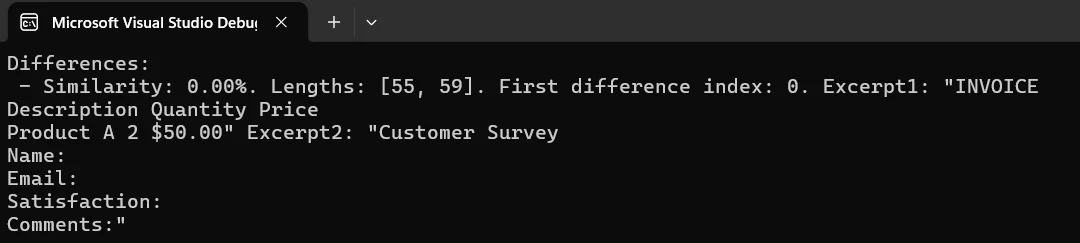
Criando um relatório de comparação visual
Gere um relatório em HTML que destaque as diferenças entre dois documentos e salve-o como um arquivo PDF:
public static void CreateComparisonReport(string pdf1Path, string pdf2Path, string outputPath)
{
// Load PDFs for comparison
var pdf1 = PdfDocument.FromFile(pdf1Path);
var pdf2 = PdfDocument.FromFile(pdf2Path);
// Build HTML report with details
string htmlReport = @"
<html>
<head>
<style>
body { font-family: Arial, sans-serif; margin: 20px; }
.identical { color: green; }
.different { color: red; }
table { width: 100%; border-collapse: collapse; }
th, td { border: 1px solid #ddd; padding: 8px; }
</style>
</head>
<body>
<h1>PDF Comparison Report</h1>
<table>
<tr><th>Page</th><th>Status</th></tr>";
// Process each page
for (int i = 0; i < Math.Max(pdf1.PageCount, pdf2.PageCount); i++)
{
string page1 = i < pdf1.PageCount ? pdf1.ExtractTextFromPage(i) : "";
string page2 = i < pdf2.PageCount ? pdf2.ExtractTextFromPage(i) : "";
bool identical = page1 == page2;
string status = identical ? "Identical" : "Different";
htmlReport += $"<tr><td>Page {i + 1}</td><td class='{status.ToLower()}'>{status}</td></tr>";
}
htmlReport += "</table></body></html>";
// Create and save the report
var renderer = new ChromePdfRenderer();
var reportPdf = renderer.RenderHtmlAsPdf(htmlReport);
reportPdf.SaveAs(outputPath);
Console.WriteLine($"Report saved to: {outputPath}");
}public static void CreateComparisonReport(string pdf1Path, string pdf2Path, string outputPath)
{
// Load PDFs for comparison
var pdf1 = PdfDocument.FromFile(pdf1Path);
var pdf2 = PdfDocument.FromFile(pdf2Path);
// Build HTML report with details
string htmlReport = @"
<html>
<head>
<style>
body { font-family: Arial, sans-serif; margin: 20px; }
.identical { color: green; }
.different { color: red; }
table { width: 100%; border-collapse: collapse; }
th, td { border: 1px solid #ddd; padding: 8px; }
</style>
</head>
<body>
<h1>PDF Comparison Report</h1>
<table>
<tr><th>Page</th><th>Status</th></tr>";
// Process each page
for (int i = 0; i < Math.Max(pdf1.PageCount, pdf2.PageCount); i++)
{
string page1 = i < pdf1.PageCount ? pdf1.ExtractTextFromPage(i) : "";
string page2 = i < pdf2.PageCount ? pdf2.ExtractTextFromPage(i) : "";
bool identical = page1 == page2;
string status = identical ? "Identical" : "Different";
htmlReport += $"<tr><td>Page {i + 1}</td><td class='{status.ToLower()}'>{status}</td></tr>";
}
htmlReport += "</table></body></html>";
// Create and save the report
var renderer = new ChromePdfRenderer();
var reportPdf = renderer.RenderHtmlAsPdf(htmlReport);
reportPdf.SaveAs(outputPath);
Console.WriteLine($"Report saved to: {outputPath}");
}Imports System
Public Shared Sub CreateComparisonReport(pdf1Path As String, pdf2Path As String, outputPath As String)
' Load PDFs for comparison
Dim pdf1 = PdfDocument.FromFile(pdf1Path)
Dim pdf2 = PdfDocument.FromFile(pdf2Path)
' Build HTML report with details
Dim htmlReport As String = "
<html>
<head>
<style>
body { font-family: Arial, sans-serif; margin: 20px; }
.identical { color: green; }
.different { color: red; }
table { width: 100%; border-collapse: collapse; }
th, td { border: 1px solid #ddd; padding: 8px; }
</style>
</head>
<body>
<h1>PDF Comparison Report</h1>
<table>
<tr><th>Page</th><th>Status</th></tr>"
' Process each page
For i As Integer = 0 To Math.Max(pdf1.PageCount, pdf2.PageCount) - 1
Dim page1 As String = If(i < pdf1.PageCount, pdf1.ExtractTextFromPage(i), "")
Dim page2 As String = If(i < pdf2.PageCount, pdf2.ExtractTextFromPage(i), "")
Dim identical As Boolean = page1 = page2
Dim status As String = If(identical, "Identical", "Different")
htmlReport &= $"<tr><td>Page {i + 1}</td><td class='{status.ToLower()}'>{status}</td></tr>"
Next
htmlReport &= "</table></body></html>"
' Create and save the report
Dim renderer = New ChromePdfRenderer()
Dim reportPdf = renderer.RenderHtmlAsPdf(htmlReport)
reportPdf.SaveAs(outputPath)
Console.WriteLine($"Report saved to: {outputPath}")
End SubEste código demonstra como criar um documento PDF profissional com resultados de comparação. O relatório foi salvo no caminho especificado.
Comparando vários documentos PDF
Quando precisar comparar vários documentos PDF simultaneamente, use este método:
public static void CompareMultiplePdfs(params string[] pdfPaths)
{
if (pdfPaths.Length < 2)
{
Console.WriteLine("Need at least two files to compare");
return;
}
// Load multiple PDF documents
var pdfs = new List<PdfDocument>();
foreach (var path in pdfPaths)
{
pdfs.Add(PdfDocument.FromFile(path));
}
// Compare all documents
for (int i = 0; i < pdfs.Count - 1; i++)
{
for (int j = i + 1; j < pdfs.Count; j++)
{
string text1 = pdfs[i].ExtractAllText();
string text2 = pdfs[j].ExtractAllText();
bool identical = text1 == text2;
Console.WriteLine($"File {i+1} vs File {j+1}: {(identical ? "Identical" : "Different")}");
}
}
// Close all documents
pdfs.ForEach(pdf => pdf.Dispose());
}public static void CompareMultiplePdfs(params string[] pdfPaths)
{
if (pdfPaths.Length < 2)
{
Console.WriteLine("Need at least two files to compare");
return;
}
// Load multiple PDF documents
var pdfs = new List<PdfDocument>();
foreach (var path in pdfPaths)
{
pdfs.Add(PdfDocument.FromFile(path));
}
// Compare all documents
for (int i = 0; i < pdfs.Count - 1; i++)
{
for (int j = i + 1; j < pdfs.Count; j++)
{
string text1 = pdfs[i].ExtractAllText();
string text2 = pdfs[j].ExtractAllText();
bool identical = text1 == text2;
Console.WriteLine($"File {i+1} vs File {j+1}: {(identical ? "Identical" : "Different")}");
}
}
// Close all documents
pdfs.ForEach(pdf => pdf.Dispose());
}Imports System
Imports System.Collections.Generic
Public Shared Sub CompareMultiplePdfs(ParamArray pdfPaths As String())
If pdfPaths.Length < 2 Then
Console.WriteLine("Need at least two files to compare")
Return
End If
' Load multiple PDF documents
Dim pdfs As New List(Of PdfDocument)()
For Each path As String In pdfPaths
pdfs.Add(PdfDocument.FromFile(path))
Next
' Compare all documents
For i As Integer = 0 To pdfs.Count - 2
For j As Integer = i + 1 To pdfs.Count - 1
Dim text1 As String = pdfs(i).ExtractAllText()
Dim text2 As String = pdfs(j).ExtractAllText()
Dim identical As Boolean = text1 = text2
Console.WriteLine($"File {i + 1} vs File {j + 1}: {(If(identical, "Identical", "Different"))}")
Next
Next
' Close all documents
pdfs.ForEach(Sub(pdf) pdf.Dispose())
End SubEssa abordagem permite comparar vários documentos PDF em uma única execução, sendo útil para requisitos de processamento em lote.
Saída

Controle de versão de contratos do mundo real
Eis um exemplo prático para o controle de revisões em documentos jurídicos:
public class ContractVersionControl
{
public static void CompareContractVersions(string originalPath, string revisedPath)
{
// System for comparing contract versions
Console.WriteLine("Contract Version Comparison System");
var original = PdfDocument.FromFile(originalPath);
var revised = PdfDocument.FromFile(revisedPath);
// Extract contract contents
string originalText = original.ExtractAllText();
string revisedText = revised.ExtractAllText();
if (originalText == revisedText)
{
Console.WriteLine("No changes detected");
}
else
{
Console.WriteLine("Changes detected in revised version");
// Create detailed report
string reportPath = $"contract_comparison_{DateTime.Now:yyyyMMdd}.pdf";
CreateComparisonReport(originalPath, revisedPath, reportPath);
Console.WriteLine($"Report created: {reportPath}");
}
// Close documents
original.Dispose();
revised.Dispose();
}
}public class ContractVersionControl
{
public static void CompareContractVersions(string originalPath, string revisedPath)
{
// System for comparing contract versions
Console.WriteLine("Contract Version Comparison System");
var original = PdfDocument.FromFile(originalPath);
var revised = PdfDocument.FromFile(revisedPath);
// Extract contract contents
string originalText = original.ExtractAllText();
string revisedText = revised.ExtractAllText();
if (originalText == revisedText)
{
Console.WriteLine("No changes detected");
}
else
{
Console.WriteLine("Changes detected in revised version");
// Create detailed report
string reportPath = $"contract_comparison_{DateTime.Now:yyyyMMdd}.pdf";
CreateComparisonReport(originalPath, revisedPath, reportPath);
Console.WriteLine($"Report created: {reportPath}");
}
// Close documents
original.Dispose();
revised.Dispose();
}
}Public Class ContractVersionControl
Public Shared Sub CompareContractVersions(originalPath As String, revisedPath As String)
' System for comparing contract versions
Console.WriteLine("Contract Version Comparison System")
Dim original = PdfDocument.FromFile(originalPath)
Dim revised = PdfDocument.FromFile(revisedPath)
' Extract contract contents
Dim originalText As String = original.ExtractAllText()
Dim revisedText As String = revised.ExtractAllText()
If originalText = revisedText Then
Console.WriteLine("No changes detected")
Else
Console.WriteLine("Changes detected in revised version")
' Create detailed report
Dim reportPath As String = $"contract_comparison_{DateTime.Now:yyyyMMdd}.pdf"
CreateComparisonReport(originalPath, revisedPath, reportPath)
Console.WriteLine($"Report created: {reportPath}")
End If
' Close documents
original.Dispose()
revised.Dispose()
End Sub
End ClassEste exemplo demonstra como comparar duas versões de contrato em PDF e gerar relatórios para revisão. O sistema detecta alterações automaticamente e cria a documentação.
Lidando com PDFs protegidos por senha
O IronPDF lida perfeitamente com arquivos PDF criptografados, passando a senha ao chamar o método de carregamento:
public static bool CompareProtectedPdfs(string pdf1Path, string pass1,
string pdf2Path, string pass2)
{
// Load password-protected two PDFs
var pdf1 = PdfDocument.FromFile(pdf1Path, pass1);
var pdf2 = PdfDocument.FromFile(pdf2Path, pass2);
// Extract and compare text
string text1 = pdf1.ExtractAllText();
string text2 = pdf2.ExtractAllText();
bool result = text1 == text2;
// Close and dispose
pdf1.Dispose();
pdf2.Dispose();
return result;
}public static bool CompareProtectedPdfs(string pdf1Path, string pass1,
string pdf2Path, string pass2)
{
// Load password-protected two PDFs
var pdf1 = PdfDocument.FromFile(pdf1Path, pass1);
var pdf2 = PdfDocument.FromFile(pdf2Path, pass2);
// Extract and compare text
string text1 = pdf1.ExtractAllText();
string text2 = pdf2.ExtractAllText();
bool result = text1 == text2;
// Close and dispose
pdf1.Dispose();
pdf2.Dispose();
return result;
}Public Shared Function CompareProtectedPdfs(pdf1Path As String, pass1 As String, pdf2Path As String, pass2 As String) As Boolean
' Load password-protected two PDFs
Dim pdf1 = PdfDocument.FromFile(pdf1Path, pass1)
Dim pdf2 = PdfDocument.FromFile(pdf2Path, pass2)
' Extract and compare text
Dim text1 As String = pdf1.ExtractAllText()
Dim text2 As String = pdf2.ExtractAllText()
Dim result As Boolean = text1 = text2
' Close and dispose
pdf1.Dispose()
pdf2.Dispose()
Return result
End FunctionBasta passar o parâmetro de senha ao carregar PDFs protegidos. O IronPDF lida com a descriptografia automaticamente.
Entrada
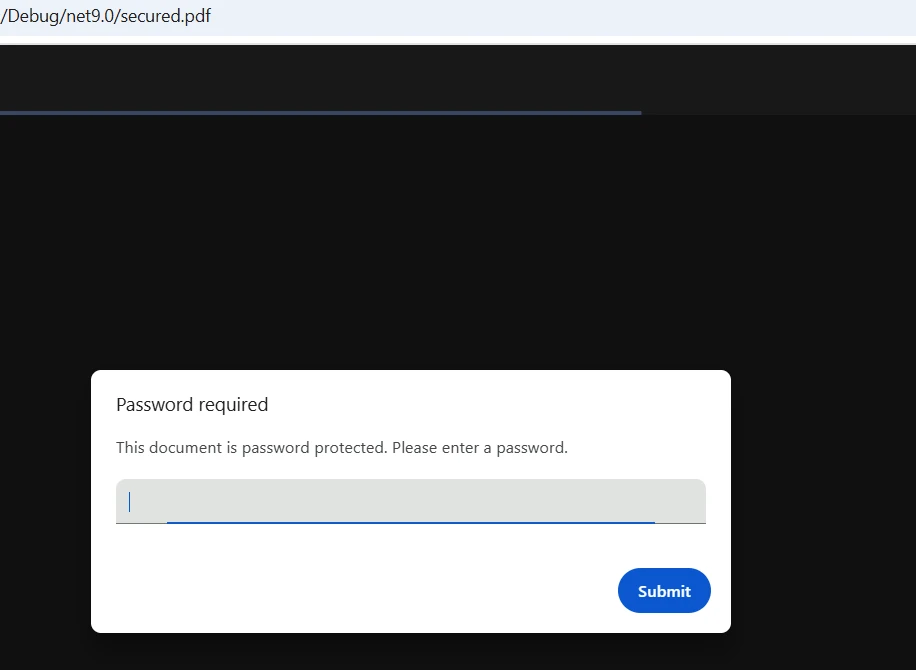
Saída
Instruções passo a passo
Siga estes passos para implementar a comparação de PDFs no seu projeto .NET :
- Instale o pacote IronPDF for .NET via NuGet.
- Adicione a referência ao namespace IronPDF.
- Crie uma instância de
PdfDocumentpara cada arquivo - Use métodos como
ExtractAllText()para obter conteúdos - Compare o texto extraído ou implemente lógica personalizada.
- Salve os resultados ou gere relatórios conforme necessário.
- Feche os objetos do documento para liberar recursos.

Definindo sua licença
Para usar o IronPDF sem marcas d'água, defina sua chave de licença:
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY"Visite a página de licenciamento para obter detalhes sobre as opções disponíveis. Baixe a versão de avaliação gratuita do IronPDF e configure arquivos PDF usando recursos de comparação de nível profissional.
Melhores práticas
- Aceite todas as revisões antes da comparação, caso esteja trabalhando com alterações controladas.
- Desenvolver tratamento de erros para operações críticas de arquivos.
- Melhore o desempenho criando comparações específicas para cada página em documentos grandes.
- Execute comparações assíncronas para vários documentos PDF.
- Atualize sua biblioteca regularmente para obter os recursos e o suporte mais recentes.
Conclusão
O IronPDF simplifica o processo de comparação de dois arquivos PDF usando C#, com sua API intuitiva e poderosos recursos de extração. Desde comparações básicas até a criação de relatórios detalhados, o IronPDF oferece todas as ferramentas necessárias para fluxos de trabalho robustos de comparação de documentos.
A combinação de fácil instalação, funcionalidade abrangente e suporte multiplataforma torna o IronPDF a escolha ideal para desenvolvedores que implementam comparação de PDFs em aplicativos .NET . Seja para desenvolver sistemas de gerenciamento de documentos ou soluções de controle de versão, a abordagem direta do IronPDF permite que você comece a usar rapidamente.
Comece hoje mesmo seu teste gratuito do IronPDF e implemente recursos profissionais de comparação de PDFs. Com suporte técnico completo e documentação abrangente, você terá funcionalidades prontas para produção em poucas horas. Consulte a documentação completa para saber mais sobre os recursos avançados.
Perguntas frequentes
O que é o IronPDF e como ele auxilia na comparação de arquivos PDF?
IronPDF é uma biblioteca .NET que fornece ferramentas para trabalhar com arquivos PDF, incluindo recursos para comparar programaticamente dois documentos PDF em busca de diferenças de conteúdo ou estrutura.
O IronPDF consegue destacar as diferenças entre dois arquivos PDF?
Sim, o IronPDF pode destacar as diferenças entre dois arquivos PDF, comparando o conteúdo deles e fornecendo um relatório detalhado das alterações ou discrepâncias.
Preciso de conhecimentos avançados de C# para comparar PDFs com o IronPDF?
Não, você não precisa de conhecimentos avançados de C#. O IronPDF oferece métodos simples e intuitivos para comparar arquivos PDF, tornando-o acessível a desenvolvedores de diferentes níveis de habilidade.
É possível comparar arquivos PDF criptografados usando o IronPDF?
Sim, o IronPDF suporta a comparação de arquivos PDF criptografados, desde que a senha correta seja fornecida para acessar o conteúdo dos documentos.
Que tipos de diferenças o IronPDF consegue detectar entre dois PDFs?
O IronPDF consegue detectar uma série de diferenças, incluindo alterações de texto, modificações de imagem e alterações estruturais, como mudanças no layout ou na formatação.
O IronPDF pode ser integrado em aplicações C# já existentes?
Sim, o IronPDF pode ser facilmente integrado a aplicativos C# existentes, permitindo que os desenvolvedores adicionem a funcionalidade de comparação de PDFs sem alterações significativas em sua base de código.
O IronPDF é compatível com outros aplicativos .NET?
O IronPDF foi projetado para ser compatível com todos os aplicativos .NET, proporcionando uma experiência perfeita para desenvolvedores que trabalham com a estrutura .NET.
O IronPDF suporta a comparação em lote de vários arquivos PDF?
Sim, o IronPDF suporta processamento em lote, permitindo que os desenvolvedores comparem vários arquivos PDF em uma única operação, o que é útil para lidar com grandes volumes de documentos.
Como o IronPDF garante a precisão das comparações de PDFs?
O IronPDF utiliza algoritmos avançados para garantir comparações precisas e confiáveis, analisando tanto o texto quanto os elementos visuais para identificar quaisquer discrepâncias.
Qual é o primeiro passo para começar a usar o IronPDF para comparação de PDFs em C#?
O primeiro passo é instalar a biblioteca IronPDF através do Gerenciador de Pacotes NuGet em seu ambiente de desenvolvimento C#, que fornece todas as ferramentas necessárias para começar a comparar PDFs.











