
How to Extract Table From PDF in Python
This article will demonstrate how to use IronPDF, a powerful PDF-processing library, to effortlessly extract data from complex tables in any PDF file.
IronPDF
Python provides significantly more flexibility for programmers compared to other languages and allows developers to easily and efficiently design graphical user interfaces. Therefore, incorporating the IronPDF library into Python is a straightforward process. To quickly and securely create a fully functional GUI, a range of pre-installed tools, including PyQt, wxWidgets, Kivy, and various other packages and libraries, can be utilized.
IronPDF simplifies Python web design and development. This is primarily due to the abundance of Python web development frameworks available, such as Django, Flask, and Pyramid. Some notable websites and online services that have employed these frameworks include Reddit, Mozilla, and Spotify.
How to Extract Table From PDF in Python
- Download a Python module for extracting table from PDF
- Use the
FromFilemethod to import the PDF file - Extract text from the tables with the
ExtractAllTextmethod - Iterate through the extracted text to split rows
- Output the extracted text to the console or a text file
Features of IronPDF
Below are some features of IronPDF:
- PDF files can be created from a variety of sources such as HTML, HTML5, ASP, PHP, and more. Additionally, image files can be converted to PDF along with HTML files.
- IronPDF enables the creation of interactive PDF documents. It offers features such as dividing and combining PDF files, extracting text and images from PDF files, rasterizing PDF pages into images, converting PDF to HTML, printing PDF files, filling out and submitting interactive forms, and splitting and merging PDF files.
- With IronPDF, it is possible to generate a document from a URL. It also supports user agents that log in using HTML login forms, proxies, cookies, HTTP headers, special network login credentials, form variables, and user agents.
- The IronPDF program allows for the inspection and annotation of PDF files.
- IronPDF enables the extraction of images from documents.
- IronPDF provides users with the ability to add headers, footers, text, photos, bookmarks, watermarks, and more to documents.
- Using IronPDF, you can divide and merge pages in a new or existing document.
- Converting documents to PDF objects is possible without the need for an Acrobat viewer.
- IronPDF allows for the creation of a PDF document from a CSS file.
- Documents can be created using CSS files that contain media-type definitions with IronPDF.
Configure Python Environment
Setup Python
Make sure Python is installed on your computer. To download and set up the most recent version of Python for your operating system, go to the official Python website. Once Python is installed, segregate the requirements for your project by creating a virtual environment. With the help of the venv module, you can create and manage virtual environments to offer your conversion project a neat and organized workspace.
New Project in PyCharm
For this tutorial, PyCharm, an IDE for Python development, is recommended.
After launching the PyCharm IDE, select "New Project" from the menu, as shown in the figure below.
 PyCharm IDE
PyCharm IDE
As seen in the picture below, when you choose "New Project," a new window will appear and allow you to define the project's location and Python environment.
 Create a new project in PyCharm
Create a new project in PyCharm
After selecting the location and environment for the project, click the Create button to initiate it. Python files can be opened in the newly launched window for you to enter your code. This guide utilizes Python 3.9.
 the main Python file
the main Python file
IronPDF Library Requirement
IronPDF for Python relies on .NET 6.0 as its core technology. Therefore, in order to use IronPDF for Python, your computer must have the .NET 6.0 runtime installed. Linux and Mac users may need to install .NET before they can utilize this Python module. Download the necessary runtime environment from Microsoft.
IronPDF Library Setup
The ironpdf package needs to be installed in order to create, edit, and open files with the ".pdf" extension. To install the package in PyCharm, open a terminal window and type the following command:
pip install ironpdf
The screenshot below illustrates the installation process of the ironpdf package.
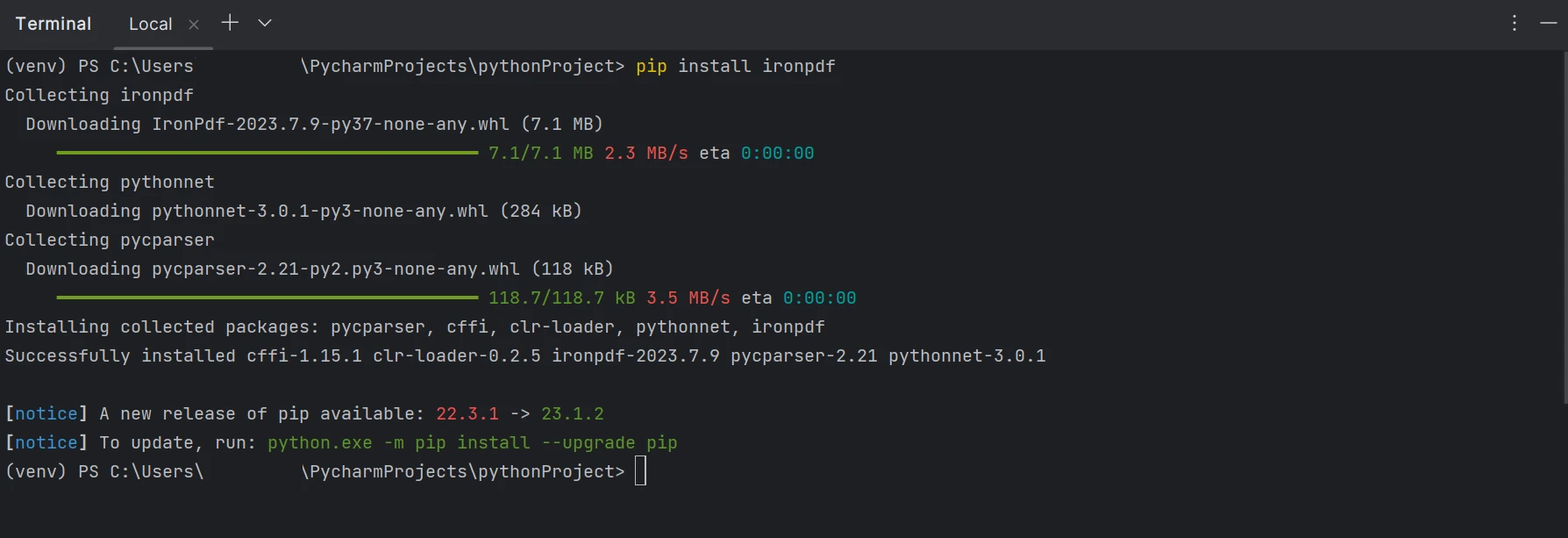 Install the IronPDF package
Install the IronPDF package
Extracting Table Data from a PDF File
We can effortlessly extract data from PDF files using the IronPDF for Python library. IronPDF facilitates the analysis of text data and the extraction of tables from PDF files. Below is a sample code that demonstrates how to extract data from PDF tables, utilizing the provided image as a reference.
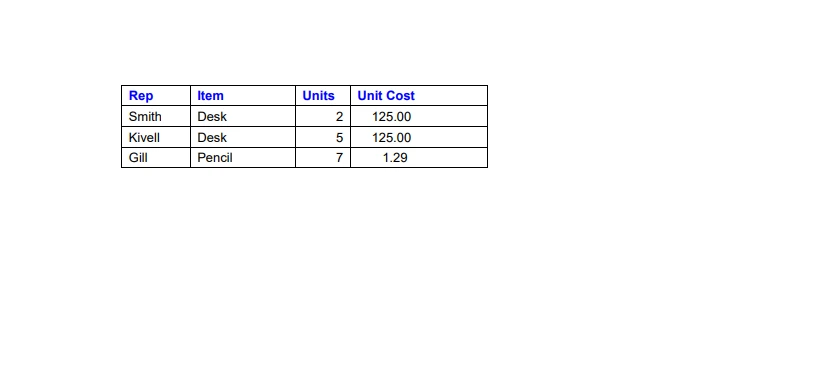 The sample data from a PDF file
The sample data from a PDF file
from ironpdf import PdfDocument
# Load the PDF document
pdf = PdfDocument.FromFile("sampleData.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Split the extracted text into rows and print each row
for row in all_text.split("\n"):
print(row)from ironpdf import PdfDocument
# Load the PDF document
pdf = PdfDocument.FromFile("sampleData.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Split the extracted text into rows and print each row
for row in all_text.split("\n"):
print(row)The provided code demonstrates how IronPDF can be used to extract tables from PDF files using just a few lines of Python code. Initially, we import the IronPDF library to access its functionality and to gain access to all of IronPDF's features. Next, with the help of the PdfDocument class, existing PDF files can be processed to perform various operations on them.
When using the FromFile function, the argument for loading the input PDF file is available. Afterward, the ExtractAllText function extracts all the table data from all the pages within the PDF files. Then, the split function is used to divide the extracted table data into multiple rows and display them on the console screen.
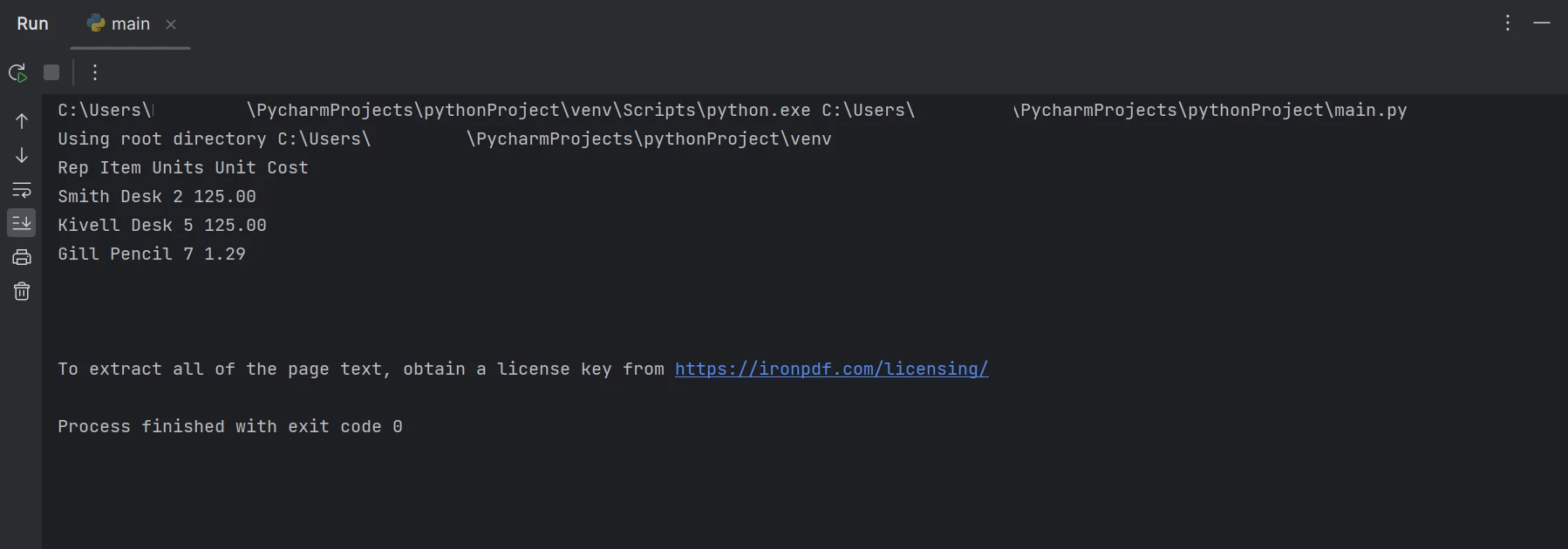 The extracted data
The extracted data
In the above output, the data is displayed row by row, showcasing how table data can be extracted. Learn more about IronPDF by perusing the product documentation.
Conclusion
The IronPDF library provides robust security measures to minimize potential risks and ensure data security. It is compatible with all popular browsers and not limited to any specific one. With IronPDF, programmers can efficiently create and read PDF files using just a few lines of code. To cater to the diverse needs of developers, the IronPDF library offers various licensing options, including a free developer license and additional development licenses available for purchase.
The Lite bundle, priced at $799, includes a perpetual license, a 30-day money-back guarantee, one year of software maintenance, and upgrade possibilities. There are no further charges after the initial purchase, and these licenses can be used in production, staging, and development environments. IronPDF also provides free licenses with some time and redistribution limitations. Users can test the product in a real-world environment with a free trial period that does not include a watermark. For detailed information regarding the cost and licensing of IronPDF's trial version, please click the following licensing page.
Frequently Asked Questions
How can I extract tables from a PDF in Python?
To extract tables from a PDF using IronPDF in Python, you can utilize the PdfDocument.FromFile() method to load the PDF, then use ExtractAllText() to extract the text. The text can subsequently be processed and split into rows to retrieve table data.
What are the steps to set up the Python environment for using IronPDF?
To set up your Python environment for using IronPDF, ensure you have Python installed, create a virtual environment, and install the .NET 6.0 runtime. You can then install IronPDF using the command pip install ironpdf.
What PDF manipulation features does IronPDF offer in Python?
IronPDF offers a wide range of PDF manipulation features in Python, including the ability to create PDFs from HTML, images, and other sources, extract text and images, and create interactive PDFs with annotations, headers, footers, and watermarks.
Can I convert HTML to PDF using IronPDF in Python?
Yes, IronPDF allows you to convert HTML to PDF in Python. You can render HTML strings or files as PDFs using IronPDF's methods, facilitating the creation of PDF documents from web content.
What licensing options are available for IronPDF in Python?
IronPDF provides several licensing options, including a free developer license for testing, a Lite bundle with a perpetual license, and additional licensing packages for purchase, supported by a 30-day money-back guarantee.
How do I troubleshoot common issues when extracting tables from PDF using IronPDF?
To troubleshoot extraction issues with IronPDF, ensure your Python environment is correctly set up with all necessary installations. Verify the PDF file is accessible and check your code syntax for using PdfDocument.FromFile() and ExtractAllText() methods. Consult the IronPDF documentation for further guidance.
What security features does IronPDF offer for PDF handling?
IronPDF incorporates robust security features for handling PDFs, such as password protection and encryption, ensuring your documents are secure during processing and distribution.
Is there support for extracting images from PDFs using IronPDF in Python?
Yes, IronPDF supports extracting images from PDFs in Python, allowing you to isolate and save images from PDF documents as part of your data processing tasks.
What is the recommended IDE for Python development with IronPDF?
PyCharm is recommended for Python development with IronPDF, as it offers a comprehensive IDE with advanced features for coding, debugging, and managing Python projects effectively.
















