
How to Extract Text From PDF in Python
This article will demonstrate how to extract all the text from PDF files using IronPDF in Python, providing you with the knowledge and Python code snippets to accomplish this task efficiently.
How to Extract Text From PDF in Python
- Download a Python module for extracting text from PDF
- Use the
FromFilemethod to import the PDF file - Extract text from the imported PDF with the
ExtractTextmethod - Extract text from specific pages with the
ExtractTextFromPagemethod - Output the extracted text to the console or a text file
IronPDF - Python Library
IronPDF for Python is a powerful Python PDF library that allows developers to extract text from PDF documents. With IronPDF, you can automate the data extraction part of textual content from PDF files, making it easier to process and analyze the information contained within PDF documents.
IronPDF provides Python programmers with the ability to manipulate, extract data from, and interact with PDF files using Python, making it easier to automate various PDF-related tasks. Whether you need to generate PDFs, modify existing PDFs, extract data from content, or perform other PDF operations, IronPDF simplifies the process with its intuitive API and powerful capabilities.
Key Features
Some features of the IronPDF for Python library include:
- Create new PDF file from scratch
- Editing existing PDF files
- Extract text, metadata, and images from PDF files
- Converting PDF files to other formats
- Secure PDF files with passwords and restrictions
- Split and merge PDFs
Prerequisites
Before proceeding with text extraction using IronPDF, ensure that you have the following prerequisites in place:
- Python Installation: Make sure you have Python installed on your system. IronPDF is compatible with Python 3.x versions, so ensure that you have a compatible Python installation.
IronPDF Library: Install the IronPDF library using
pip, the Python package manager. Open your command-line interface and execute the following command:pip install ironpdfpip install ironpdfSHELLNote: Python must be added to the PATH environment variable in order to use pip commands.
- Integrated Development Environment (IDE): While not strictly necessary, using an IDE can greatly enhance your development experience. It provides features like code completion, debugging, and a more streamlined workflow. One popular IDE for Python development is PyCharm. You can download and install PyCharm from the JetBrains website https://www.jetbrains.com/pycharm/.
- Text Editor: Alternatively, if you prefer to work with a lightweight text editor, you can use any text editor of your choice, such as Visual Studio Code, Sublime Text, or Atom. These editors provide syntax highlighting and other useful features for Python development. You can also use Python's own IDLE App.
Creating a Python Project using PyCharm
After installing PyCharm IDE, create a PyCharm Python project by following the below steps:
- Launch PyCharm: Open PyCharm from your system's application launcher or desktop shortcut.
Create a New Project: Click on "Create New Project" or open an existing Python project.
 PyCharm IDE
PyCharm IDEConfigure Project Settings: Provide a name for your project and choose the location to create the project directory. Select the Python interpreter for your project. Then click "Create".
 Create a new Python project in Pycharm
Create a new Python project in Pycharm- Create Source Files: PyCharm will create the project structure, including a main Python file and a directory for additional source files. Start writing code and click the run button or press Shift+F10 to execute the script.
Extracting Text from PDF in Python using IronPDF
Now let's dive into the steps involved in extracting plain text from PDF files using IronPDF in Python programming language.
Import the Required Libraries
To begin, import the necessary libraries in your Python script. In this case, the code sample needs to import the IronPDF library, which provides the functionality for working with PDF files.
import ironpdfimport ironpdfSet the License Key
In order to extract full text from a PDF file using IronPDF, you need to have IronPDF licensed. Apply the license or trial key using the following command:
# Apply your license key
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"# Apply your license key
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"Note: Without a license key, IronPDF extracting data is restricted to a few characters only from the PDF extension file. Obtain a license key by purchasing IronPDF or by signing up for a free trial.
Load the PDF Document
Next, load the PDF file using the PdfDocument.FromFile() method from IronPDF. Provide the path to the PDF file as the argument to this method. This will load the PDF file into a PdfDocument object.
pdf = ironpdf.PdfDocument.FromFile("path/to/your/pdf_file.pdf")pdf = ironpdf.PdfDocument.FromFile("path/to/your/pdf_file.pdf")Input File
To extract text from the input PDF file and print it on the screen, the following document is used:
 The input file
The input file
Extract Text from PDF files
Once the PDF document is loaded, you can extract the text content using the ExtractText method. This method returns the extracted text as a string.
text = pdf.ExtractText()text = pdf.ExtractText()Process and Utilize the Extracted Text
Now that you have extracted the text from the PDF, you can process and utilize it according to your requirements. You can perform tasks such as parsing the text, analyzing it, storing it in a database, or using it for further data processing.
# Process and utilize the extracted text
print(text)
# Perform other operations with the extracted text# Process and utilize the extracted text
print(text)
# Perform other operations with the extracted textOutput
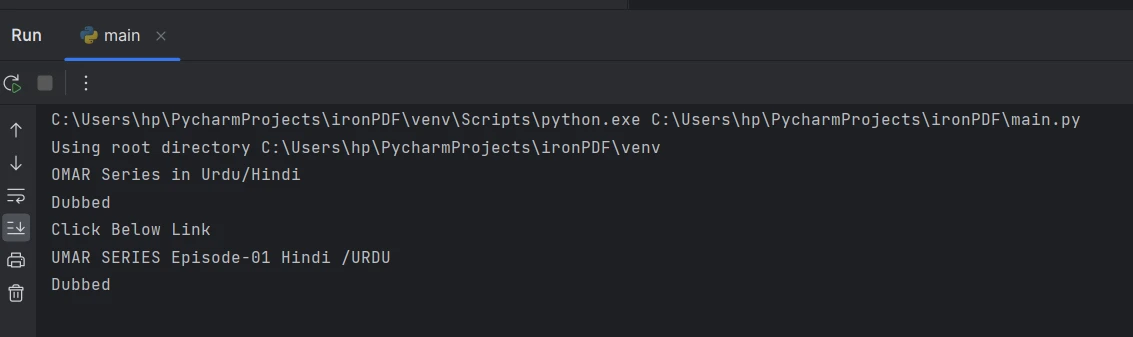 The extracted text from the console
The extracted text from the console
Extract Text from Specific Page in PDF File
IronPDF also provides a convenient method to extract text from specific pages within a PDF file. This section will explore how to extract text from a specific page using the ExtractTextFromPage method provided by IronPDF.
The following code demonstrates how to extract text from a specific page:
# Extract text from a specific page in the document
page_2_text = pdf.ExtractTextFromPage(1)# Extract text from a specific page in the document
page_2_text = pdf.ExtractTextFromPage(1)In the above sample code, pdf represents the PdfDocument object obtained after loading the PDF document. The ExtractTextFromPage() method is used to extract text from a specific page, indicated by the page index passed as an argument. In this case, the text is extracted from the second page or page number 2, which corresponds to page index 1.
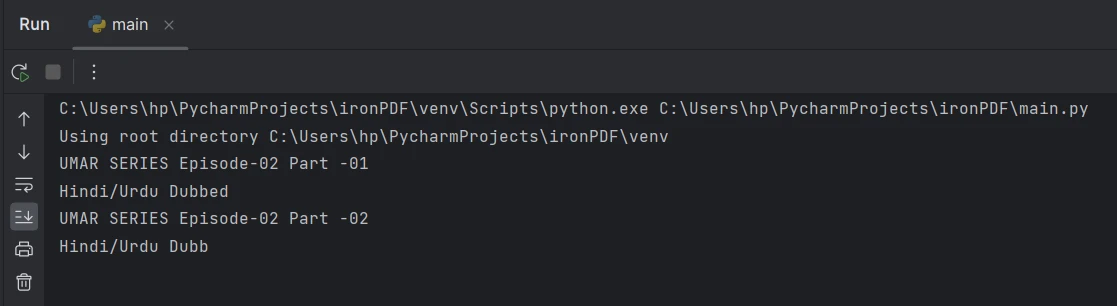 Extract text from page 2
Extract text from page 2
Conclusion
This article explored how to extract text from PDF files using IronPDF in Python. It covered the necessary steps, including importing the required library, loading the PDF document, extracting the text content, and processing the extracted text.
With IronPDF's powerful text extraction capabilities, you can automate the extraction and further processing of text from PDFs, enabling you to process and analyze the textual information within PDF documents easily. Its intuitive API and extensive capabilities make it an ideal choice for a wide range of PDF-related tasks in Python development.
IronPDF is free for development purposes, but it needs to be licensed for commercial use. To use it in production mode for testing, obtain a free trial. Download and install the latest version of IronPDF for Python and give it a try.
Frequently Asked Questions
How can I extract text from an entire PDF document using Python?
You can extract text from an entire PDF document by using IronPDF's PdfDocument.FromFile() method to load the PDF and then calling the ExtractText() method to retrieve the text content.
What is the process for extracting text from specific pages of a PDF in Python?
To extract text from specific pages of a PDF, use IronPDF's ExtractTextFromPage() method, which allows you to specify the page index to retrieve text from that particular page.
How do I install the IronPDF library for Python?
Install the IronPDF library for Python using the pip package manager by running the command: pip install ironpdf.
What are the prerequisites for extracting text from PDFs in Python?
The prerequisites include having Python installed on your system, installing IronPDF via pip, and using an IDE such as PyCharm for development.
Is there a free version of the IronPDF library available for Python?
IronPDF is free for development purposes, but you will need a license for commercial use. A free trial is available to test the library in production mode.
Do I need a license to extract full text from PDFs using IronPDF?
Yes, a license key is required to fully extract text from PDFs using IronPDF. Without a license, extraction is limited to a few characters.
What are some key features of IronPDF for Python?
Key features of IronPDF for Python include creating and editing PDFs, extracting text, metadata, and images, converting PDFs to other formats, and adding security features like passwords.
Can IronPDF for Python help with automating PDF data extraction?
Yes, IronPDF offers methods like FromFile and ExtractText that facilitate the automation of PDF data extraction, aiding in data analysis and manipulation.
What IDE is recommended for using IronPDF in Python?
PyCharm is recommended for Python development with IronPDF due to its features such as code completion, debugging tools, and a streamlined workflow.
How does IronPDF enhance my workflow in processing PDF documents?
IronPDF enhances workflow by providing an intuitive API for text extraction, PDF creation and editing, format conversion, and security settings, streamlining various PDF-related tasks.
















