
如何在C#中读取PDF文件?
本文将使用IronPDF 适用于 .NET,这是一款C# PDF库,用于读取PDF文件。
如何使用IronPDF读取PDF文件
- 下载Visual Studio,如果尚未下载。 设置环境并安装IronPDF库。
- 使用
PdfDocument.FromFile方法打开并加载所需的 PDF 文件。 - 利用 IronPDF 的
ExtractAllText方法检索内容。 - 根据需要分析或操作提取的文本。
- 在控制台中打印提取的文本以供阅读。
IronPDF。
IronPDF,一个强大的C# PDF阅读库,使开发人员能够轻松处理PDF文档。 凭借其广泛的功能和特性,IronPDF简化了PDF文档处理的任务,使用户能够轻松地读取、提取和操作PDF内容。 无论您是在自动化文档流程、提取用于分析的数据和图像,还是从头创建PDF,IronPDF都提供了全面的工具集来简化这些任务。
本文探讨了在C#中使用IronPDF进行高效PDF处理的世界,展示了其多功能性和作为开发人员软件开发旅程中基本工具的价值。
创建一个新的 Visual Studio 项目
在深入编码部分之前,让我们从设置一个全新的Visual Studio C#控制台应用程序项目开始。 该项目将作为开发和实践示例的专用工作空间。
- 要开始此过程,请启动Visual Studio并通过导航到"文件"菜单并选择"新建"然后"项目"来创建新项目。
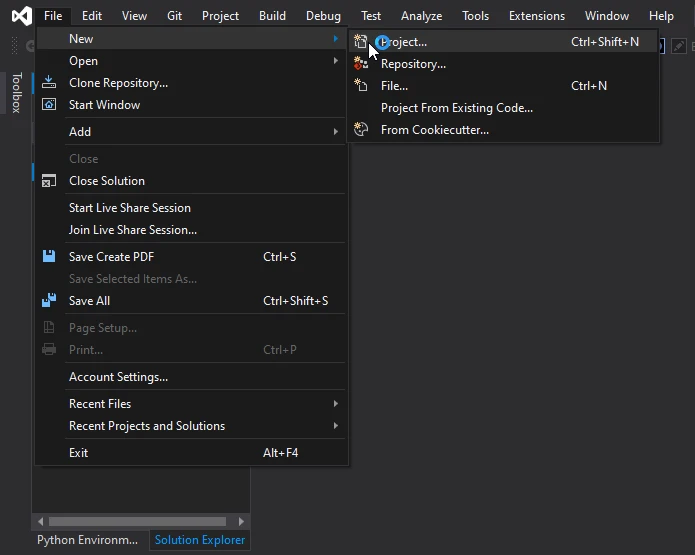 导航到Visual Studio中的创建项目对话框
导航到Visual Studio中的创建项目对话框
- 此操作将提示出现一个新窗口,提供您指定项目模板的机会。 为简单起见,选择"控制台应用程序"模板,并通过点击窗口左下角的下一步按钮继续。
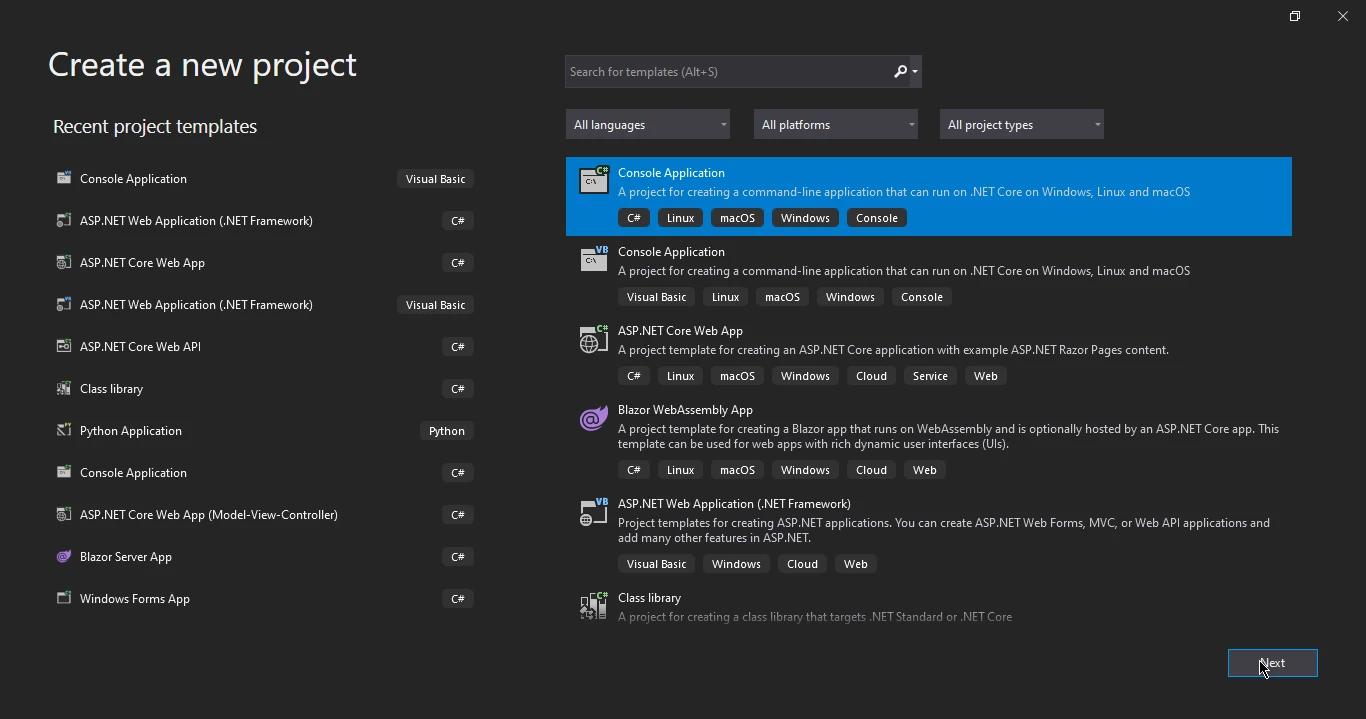 在 Visual Studio 中创建新项目
在 Visual Studio 中创建新项目
- 在接下来的窗口中,您将被提示为项目指定名称并指定项目位置。 一旦这些细节到位,点击下一步按钮继续。
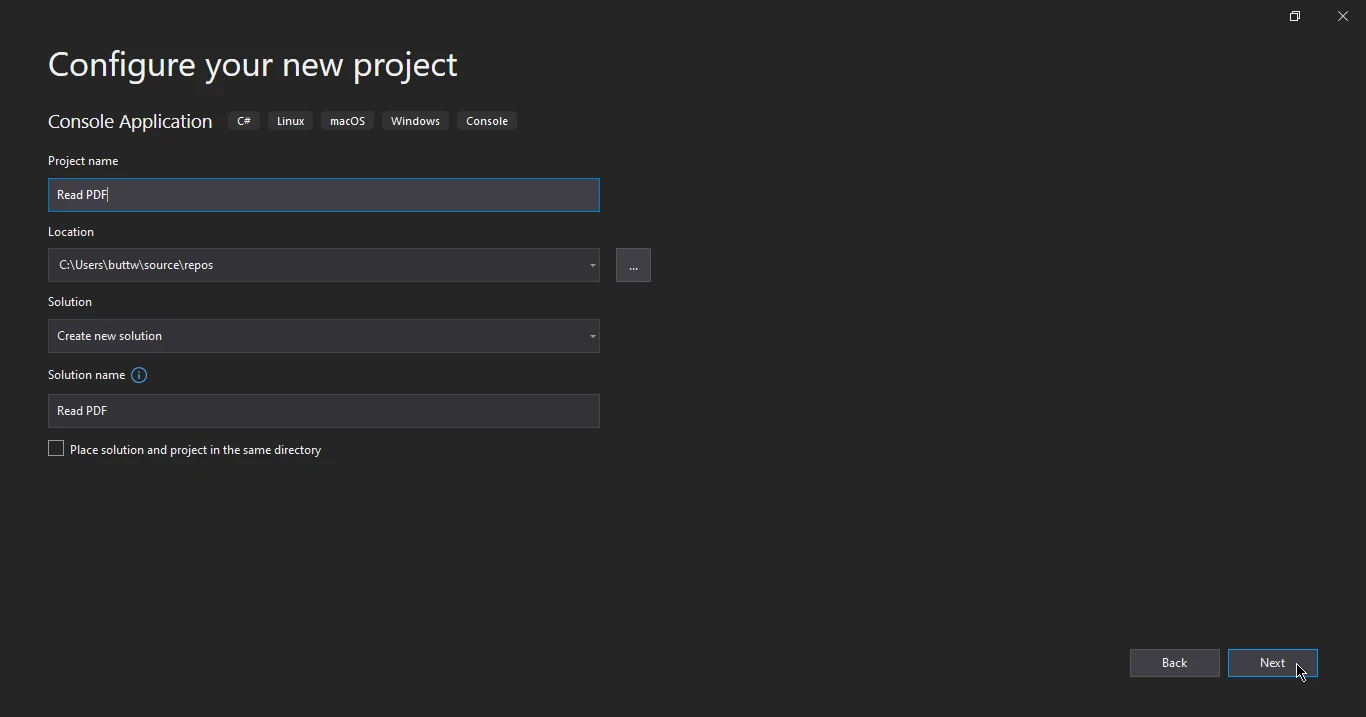 配置项目
配置项目
- 在此步骤中,选择您偏好的目标框架并通过点击创建按钮完成项目创建过程。
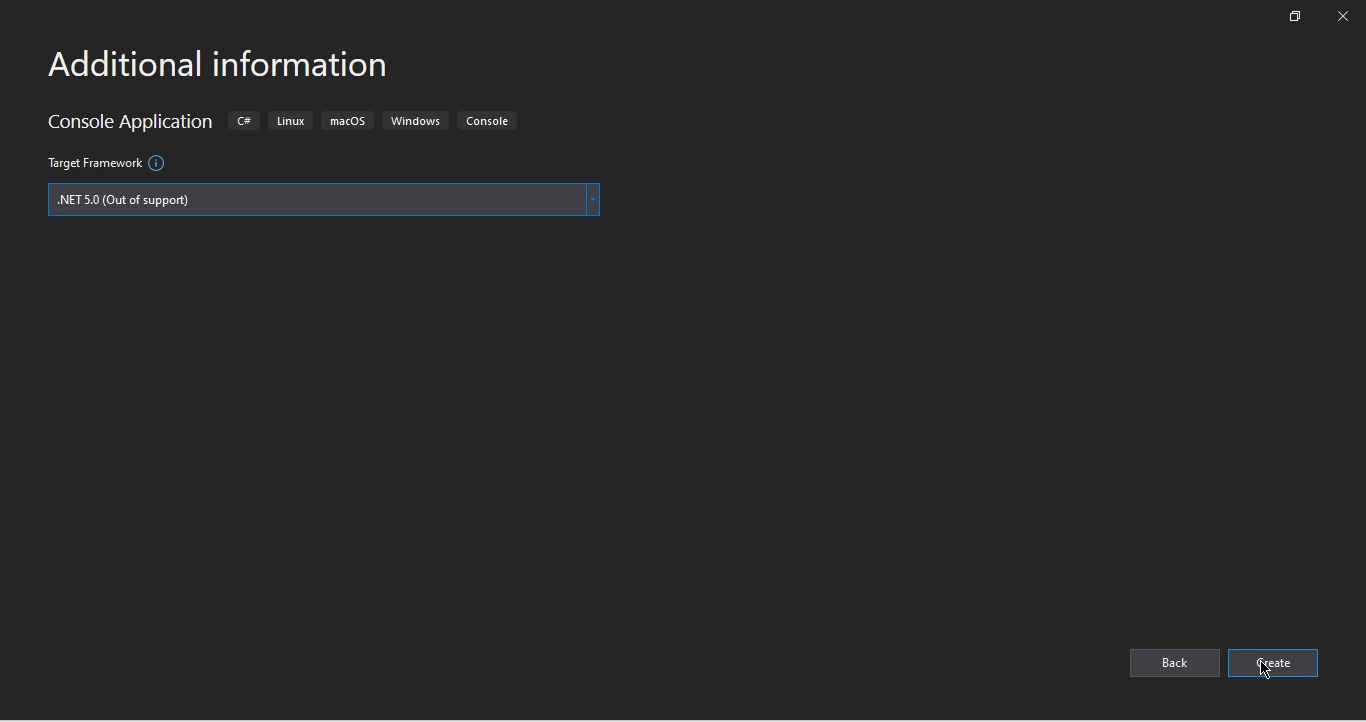 .NET 框架选择
.NET 框架选择
现在项目已牢固建立,下一关键步骤涉及安装IronPDF。
安装 IronPDF
IronPDF提供多种下载和安装PDF库的选项。 为了此指南的目的,将重点放在使用NuGet包管理器安装IronPDF上,这是一种高效且广泛采用的方法。
- 在Visual Studio中,导航到"工具"菜单并优雅地将光标悬停在"NuGet包管理器"选项上。
- 从扩展菜单中选择"NuGet包管理器用于解决方案"。
 导航到 NuGet 包管理器
导航到 NuGet 包管理器
- 选择此选项时,将打开一个新窗口。 在此精致窗口中,导航到"浏览"菜单并在搜索栏中输入"IronPDF"。
- 然后屏幕将显示可用的IronPDF包。 要继续,请从列表中选择最新包,并通过点击"安装"选项执行此选择。
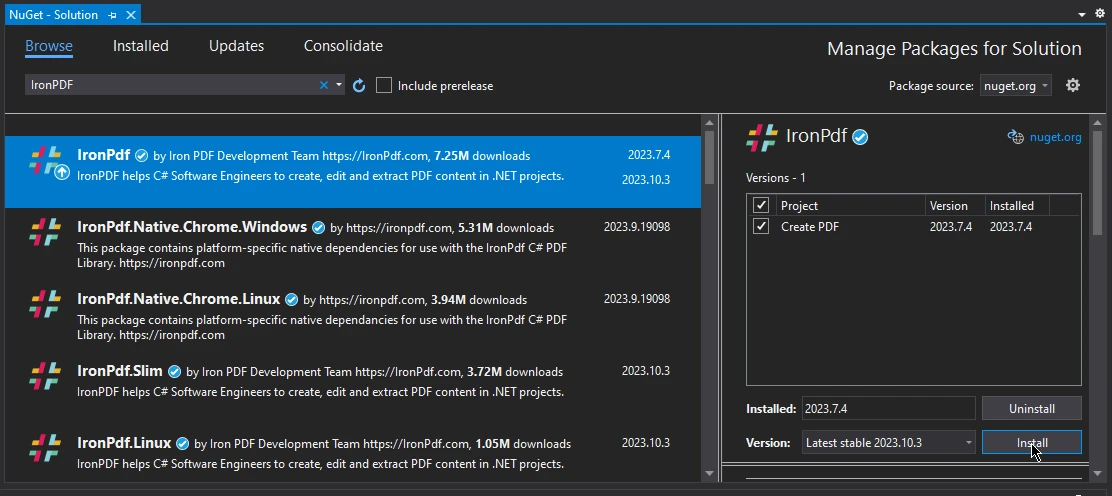 在NuGet包管理器UI中搜索并安装IronPDF包
在NuGet包管理器UI中搜索并安装IronPDF包
对于那些更喜欢命令行方法的人,NuGet包管理器控制台提供了一条优雅的途径。 只需打开此控制台,输入以下命令,并按"Enter":
Install-Package IronPdf
您还可以选择直接从NuGet网站链接获取包。
使用IronPDF读取PDF文件
本节将展示如何使用C#编程语言和IronPDF打开并读取完整PDF文件。
using IronPdf;
using System;
class Program
{
static void Main()
{
// Set the license key for IronPDF if available
IronPdf.License.LicenseKey = "Your_License_Key_Here";
// Load the PDF document from a specified file path
var pdf = PdfDocument.FromFile("document_scaled_compressed.pdf");
// Extract all text from the loaded PDF
string text = pdf.ExtractAllText();
// Output the extracted text to the console
Console.WriteLine(text);
}
}using IronPdf;
using System;
class Program
{
static void Main()
{
// Set the license key for IronPDF if available
IronPdf.License.LicenseKey = "Your_License_Key_Here";
// Load the PDF document from a specified file path
var pdf = PdfDocument.FromFile("document_scaled_compressed.pdf");
// Extract all text from the loaded PDF
string text = pdf.ExtractAllText();
// Output the extracted text to the console
Console.WriteLine(text);
}
}Imports IronPdf
Imports System
Friend Class Program
Shared Sub Main()
' Set the license key for IronPDF if available
IronPdf.License.LicenseKey = "Your_License_Key_Here"
' Load the PDF document from a specified file path
Dim pdf = PdfDocument.FromFile("document_scaled_compressed.pdf")
' Extract all text from the loaded PDF
Dim text As String = pdf.ExtractAllText()
' Output the extracted text to the console
Console.WriteLine(text)
End Sub
End Class1. 导入必要的库
要开始,您需要导入所需的命名空间。 在上面的代码示例中,导入了 IronPdf 命名空间,其中包含处理 PDF 的基本函数。 此外,还导入了 System 命名空间,用于一般的系统级操作。
using IronPdf;
using System;using IronPdf;
using System;Imports IronPdf
Imports System2. 设置IronPDF许可证密钥
IronPDF需要有效的许可证密钥才能在生产环境中使用。 在代码示例中,有一行用于设置许可证密钥。 但是,在您提供的代码中,许可证密钥为空 ""。 确保在生产环境中使用时,将空字符串替换为IronPDF的有效许可证密钥。
IronPdf.License.LicenseKey = "Your_License_Key_Here";IronPdf.License.LicenseKey = "Your_License_Key_Here";IronPdf.License.LicenseKey = "Your_License_Key_Here"3. 加载PDF文档
下一步是加载并解析 PDF 文件。在提供的代码中,使用 PdfDocument.FromFile 方法加载文件名为"document_scaled_compressed.pdf"的 PDF 文件,并将其赋值给pdf变量。 此PDF文件将用于文本提取。
var pdf = PdfDocument.FromFile("document_scaled_compressed.pdf");var pdf = PdfDocument.FromFile("document_scaled_compressed.pdf");Dim pdf = PdfDocument.FromFile("document_scaled_compressed.pdf")4. 从PDF文档中提取文本
IronPDF提供了一种简单的方法从加载的PDF文档中提取文本。 ExtractAllText方法可以从 PDF 的每一页中提取所有文本内容,并将其存储在名为text 的**字符串**变量中,其作用相当于将 PDF 转换为文本。
string text = pdf.ExtractAllText();string text = pdf.ExtractAllText();Dim text As String = pdf.ExtractAllText()5. 显示提取的文本
最后一步是显示提取的文本。 在代码中,Console.WriteLine将打印并写入提取的文本到控制台。 这是一个有用的方法,用于调试或向用户展示文本。
Console.WriteLine(text);Console.WriteLine(text);Console.WriteLine(text)PDF文件中提取的输出文本
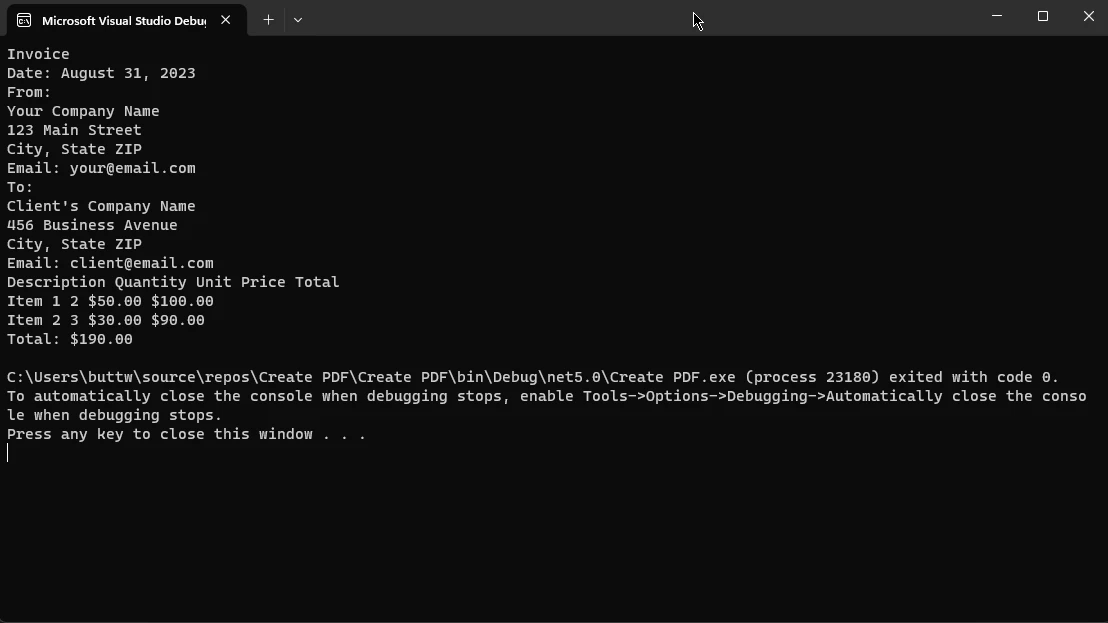 从PDF文件中提取的文本
从PDF文件中提取的文本
结论
本文指导开发者如何使用IronPDF库在C#中有效地处理PDF文件。 它首先展示了设置专用的Visual Studio项目,然后通过NuGet包管理器安装IronPDF的简单过程。 随后,该文章提供了逐步说明如何导入必要的库、设置IronPDF许可证密钥、加载PDF文件、提取文本内容,并显示各页提取的文本。 您还可以使用C#将提取的文本保存到TXT文件中。
凭借其用户友好的方法和全面的功能,IronPDF是自动化文档处理、数据提取和从HTML、URL及图像创建PDF的不可或缺的工具,使其在涉及PDF文件处理的C#软件开发项目中成为一个无价的资产。
使用IronPDF读取PDF文件的完整文章可在以下如何页面找到。 该C# PDF阅读器上的代码示例也可用。 有关使用IronPDF的更多代码示例,请访问此示例页面。 IronPDF还提供丰富的文档,以回答所有开发者的问题并提供全面的动手支持。 IronPDF提供免费试用许可证,以便用户在决定购买永久许可证之前全面探索其功能。
常见问题解答
如何在C#中加载PDF文档?
您可以使用PdfDocument.FromFile方法,通过提供您想加载的PDF的文件路径,在C#中加载PDF文档。
使用C#从PDF中提取文本的方法是什么?
ExtractAllText方法在IronPDF中用于从加载的PDF文档中提取所有文本内容,帮助进行数据检索和操作。
如何在Visual Studio中设置一个新的项目以使用C#处理PDF?
要设置一个新项目,请在Visual Studio中创建一个C#控制台应用程序,并使用NuGet包管理器安装IronPDF库。
在生产环境中实现PDF库是否需要许可证密钥?
是的,需要一个有效的许可证密钥才能在生产环境中使用IronPDF,以访问其全套功能。
我能否使用C#将HTML内容转换为PDF文档?
是的,IronPDF允许将HTML内容转换为PDF文档,使其在从网页或HTML字符串创建PDF时非常有用。
使用PDF库处理文档在C#中的优势是什么?
使用IronPDF简化了PDF自动化、数据提取和创建等任务,通过提供可靠的文档处理功能来增强软件项目。
开发人员在哪里可以找到更多使用PDF库的例子与C#?
开发人员可以在IronPDF的官方网站上找到其他示例和文档,其中包括各种用例的指南和示例代码。
PDF库是否提供评估的试用版本?
是的,IronPDF提供免费试用许可证,允许用户在决策购买前探索库的功能。
当使用C#从PDF中提取文本时,我如何排除故障?
确保使用PdfDocument.FromFile正确加载PDF文件,并在控制台输出中检查任何错误或异常以指导。
IronPDF能否通过图像创建PDF?
是的,IronPDF可以通过图像生成PDF,提供文档创建的灵活性,并支持多种输入格式。
IronPDF 是否兼容 .NET 10,能否在 C# 中读取 PDF 文件?
是的,IronPDF 完全兼容 .NET 10,支持在 .NET 10 项目中使用PdfDocument.FromFile和ExtractAllText等方法读取、提取和操作 PDF 文件。它已获得 .NET 10 及更早版本的官方支持。













