Cómo Editar un PDF sin Adobe (Tutorial para Principiantes)
¿Eres un desarrollador que necesita extraer imágenes de PDFs? Quizás necesitas extraer gráficos para reutilizarlos en otros documentos, o necesitas quitar imágenes de branding antiguo antes de actualizar los archivos PDF con nuevas. Cualesquiera que sean tus necesidades, IronPDF está aquí para hacer que todo el proceso sea fácil.
En el contexto empresarial español, la extracción de imágenes de PDFs es frecuente en flujos de trabajo como: recuperar logotipos o sellos digitales de facturas Facturae generadas bajo VeriFactu, extraer imágenes de documentos firmados con certificados FNMT conforme a eIDAS, o procesar archivos que contienen datos biométricos o fotografías sujetos a la LOPDGDD supervisada por la AEPD. IronPDF gestiona todos estos casos desde una única API .NET sin dependencias externas.
Este artículo demuestra cómo recuperar imágenes incrustadas usando los métodos sencillos de IronPDF. Aprenderás a extraer todas las imágenes de una vez o a dirigir páginas específicas, con ejemplos de código completos que funcionan inmediatamente en tus aplicaciones .NET. Al final de este artículo, serás capaz de extraer imágenes de cualquier documento PDF de manera programática con confianza.
Extracción de imágenes en flujos VeriFactu, TicketBAI y LOPDGDD en España
En el contexto de la normativa española de facturación electrónica, la extracción de imágenes de PDFs tiene casos de uso específicos y regulados:
- VeriFactu / VERI*FACTU: Las facturas generadas bajo VeriFactu incluyen un código QR verificable en la sede electrónica de la AEAT. Extraer este QR como imagen permite reutilizarlo en otros formatos de entrega o validarlo programáticamente.
- TicketBAI (Bizkaia, Gipuzkoa, Araba): Los tiques fiscales TicketBAI incluyen imágenes de QR específicas de la Hacienda foral correspondiente. IronPDF puede extraerlas para workflows de validación o reenvío.
- Facturae / FACe: Los PDFs de representación de facturas Facturae enviadas a la plataforma FACe pueden contener sellos o logotipos institucionales. IronPDF permite extraer estas imágenes para procesamiento posterior.
- Crea y Crece: En el marco de la facturación B2B obligatoria bajo la Ley Crea y Crece, los PDFs de representación pueden incluir imágenes de firma o sello que el sistema receptor necesita archivar por separado.
- LOPDGDD: Cuando las imágenes contienen datos biométricos o fotografías, la AEPD puede requerir medidas específicas de protección. IronPDF extrae las imágenes en el servidor sin exponerlas al cliente, facilitando el cumplimiento técnico.
¿Por qué los desarrolladores necesitan extraer imágenes de PDF?
La extracción de imágenes de documentos PDF sirve para numerosos propósitos comerciales. Los sistemas de procesamiento de documentos a menudo necesitan separar los activos visuales para catalogación o análisis. Las plataformas de gestión de contenido requieren la extracción de imágenes para reutilizar gráficos a través de diferentes medios. Los sistemas archivisticos se benefician de extraer y almacenar imágenes de forma independiente para una mejor organización y capacidad de búsqueda.
La extracción manual no es escalable al tratar con cientos o miles de documentos. La extracción automatizada usando IronPDF asegura consistencia, ahorra tiempo y preserva la calidad de las imágenes a lo largo del proceso. El motor de renderizado Chrome de la biblioteca proporciona precisión perfecta al trabajar con contenido PDF. Ya sea que estés construyendo un sistema de gestión documental, creando una solución de archivo, o reutilizando contenido visual, IronPDF te ofrece las herramientas necesarias para extraer imágenes incrustadas eficientemente.
¿Cómo empezar a utilizar IronPDF?
Instalar IronPDF toma solo segundos a través de NuGet Package Manager. Crea un nuevo proyecto o abre uno existente, y luego en la Consola del Administrador de Paquetes ejecuta:
Install-Package IronPdf
Después de la instalación, añade los siguientes espacios de nombres a tu archivo C#:
using IronPdf;
using System.Collections.Generic;
using System.Drawing;using IronPdf;
using System.Collections.Generic;
using System.Drawing;Imports IronPdf
Imports System.Collections.Generic
Imports System.DrawingDescarga IronPDF para empezar a extraer imágenes inmediatamente, o explora la documentación completa para características adicionales. Para obtener información detallada sobre la API, consulta la guía de referencia de objetos.
¿Cómo extraer todas las imágenes de un documento PDF?
El método ExtractAllImages hace que extraer cada imagen de un PDF sea notablemente sencillo. Este método devuelve una colección de objetos AnyBitmap que representan todas las imágenes encontradas dentro del documento. Para demostrar cómo funciona esto, he creado un documento de ejemplo con tres imágenes a lo largo de él:
Ahora, veamos el código que extraerá todas las imágenes de este documento:
// Load the PDF document
var pdf = PdfDocument.FromFile("document.pdf");
// Extract all images from the PDF
IEnumerable<AnyBitmap> allImages = pdf.ExtractAllImages();
// Save each image to disk
int imageIndex = 0;
foreach (var image in allImages)
{
image.SaveAs($"extracted_image_{imageIndex}.png");
imageIndex++;
}// Load the PDF document
var pdf = PdfDocument.FromFile("document.pdf");
// Extract all images from the PDF
IEnumerable<AnyBitmap> allImages = pdf.ExtractAllImages();
// Save each image to disk
int imageIndex = 0;
foreach (var image in allImages)
{
image.SaveAs($"extracted_image_{imageIndex}.png");
imageIndex++;
}Imports System.Collections.Generic
' Load the PDF document
Dim pdf = PdfDocument.FromFile("document.pdf")
' Extract all images from the PDF
Dim allImages As IEnumerable(Of AnyBitmap) = pdf.ExtractAllImages()
' Save each image to disk
Dim imageIndex As Integer = 0
For Each image In allImages
image.SaveAs($"extracted_image_{imageIndex}.png")
imageIndex += 1
NextEste código carga tu PDF, extrae todas las imágenes incrustadas, y las guarda como archivos PNG. La clase AnyBitmap maneja varios formatos de imagen sin problemas, preservando la calidad original. También puedes guardarlas en formatos de imagen JPEG, BMP, o TIFF cambiando la extensión del archivo. Para escenarios más complejos, explora trabajar con anotaciones o gestionar los metadatos del PDF.
El proceso de extracción mantiene la resolución de la imagen y la profundidad de color, asegurando que no se pierda calidad durante la extracción. IronPDF maneja automáticamente los diferentes tipos de compresión de imágenes encontradas en PDFs, incluidos formatos JPEG, PNG y TIFF incrustados dentro del documento.
Aquí, puedes ver que el código ha guardado exitosamente los archivos de imágenes extraídas:
Y si echamos un vistazo a la primera, puedes ver que ha mantenido su color y calidad original:
¿Cómo extraer imágenes de páginas específicas?
A veces solo necesitas imágenes de páginas particulares en lugar del documento completo. Los métodos ExtractImagesFromPage y ExtractImagesFromPages proporcionan esta capacidad de extracción dirigida. Para el siguiente ejemplo, usemos un documento PDF más largo para demostrar cómo IronPDF maneja la extracción de páginas específicas. Estaré utilizando un PDF renderizado de una página de Wikipedia.
// Extract images from a single page (page 2)
var singlePageImages = pdf.ExtractImagesFromPage(1); // Pages are zero-indexed
// Extract images from multiple pages (pages 1, 3, and 5)
var multiplePageImages = pdf.ExtractImagesFromPages(new[] { 0, 2, 4 });
// Process extracted images
var i = 0;
foreach (var image in multiplePageImages)
{
image.SaveAs($"C:\\Users\\kyess\\Desktop\\Desktop\\Code-Projects\\ExtractImageFromPdf\\output\\MultiPaged_image{i}.jpg");
i++;
}// Extract images from a single page (page 2)
var singlePageImages = pdf.ExtractImagesFromPage(1); // Pages are zero-indexed
// Extract images from multiple pages (pages 1, 3, and 5)
var multiplePageImages = pdf.ExtractImagesFromPages(new[] { 0, 2, 4 });
// Process extracted images
var i = 0;
foreach (var image in multiplePageImages)
{
image.SaveAs($"C:\\Users\\kyess\\Desktop\\Desktop\\Code-Projects\\ExtractImageFromPdf\\output\\MultiPaged_image{i}.jpg");
i++;
}' Extract images from a single page (page 2)
Dim singlePageImages = pdf.ExtractImagesFromPage(1) ' Pages are zero-indexed
' Extract images from multiple pages (pages 1, 3, and 5)
Dim multiplePageImages = pdf.ExtractImagesFromPages(New Integer() {0, 2, 4})
' Process extracted images
Dim i As Integer = 0
For Each image In multiplePageImages
image.SaveAs($"C:\Users\kyess\Desktop\Desktop\Code-Projects\ExtractImageFromPdf\output\MultiPaged_image{i}.jpg")
i += 1
NextEste enfoque es particularmente útil al procesar PDFs grandes donde solo ciertas secciones contienen imágenes relevantes. Reduce el uso de memoria y mejora la velocidad de procesamiento evitando operaciones de extracción innecesarias. Para manejar múltiples PDFs eficientemente, considera implementar operaciones asincrónicas o explorar técnicas de generación paralela de PDF.
Como puedes ver, el código extrajo fácilmente las imágenes que estaban en las páginas especificadas, así como la única imagen de la página 2:

¿Qué funciones avanzadas ofrece IronPDF?
IronPDF soporta escenarios de extracción más sofisticados más allá de la recuperación básica de imágenes. El método ExtractAllRawImages proporciona acceso a datos de imagen crudos como matrices de bytes, perfecto para almacenamiento directo en base de datos o pipelines de procesamiento personalizados.
// Extract raw image data for advanced processing
var rawImages = pdf.ExtractAllRawImages();
foreach (byte[] imageData in rawImages)
{
// Process raw bytes - store in database, apply filters, etc.
System.IO.File.WriteAllBytes("raw_image.dat", imageData);
}// Extract raw image data for advanced processing
var rawImages = pdf.ExtractAllRawImages();
foreach (byte[] imageData in rawImages)
{
// Process raw bytes - store in database, apply filters, etc.
System.IO.File.WriteAllBytes("raw_image.dat", imageData);
}' Extract raw image data for advanced processing
Dim rawImages = pdf.ExtractAllRawImages()
For Each imageData As Byte() In rawImages
' Process raw bytes - store in database, apply filters, etc.
System.IO.File.WriteAllBytes("raw_image.dat", imageData)
Next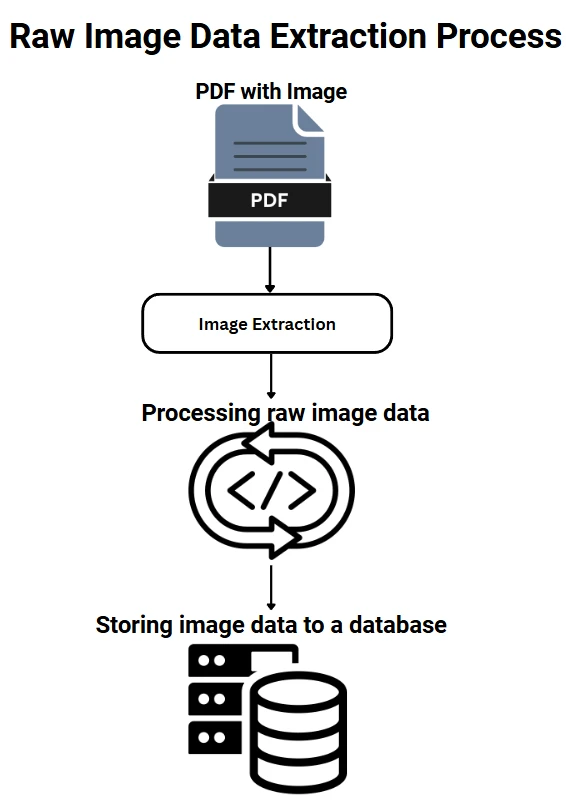
IronPDF también maneja PDFs cifrados sin problemas. Proporciona la contraseña al cargar el documento, y la extracción de imágenes funciona de manera idéntica a los archivos no cifrados. La biblioteca gestiona varios niveles de seguridad de PDF respetando los permisos del documento. La documentación de Microsoft sobre trabajar con imágenes en .NET proporciona un contexto adicional para operaciones de procesamiento de imágenes.
¿Qué debe saber sobre los problemas comunes?
Al extraer imágenes de PDFs, varias consideraciones aseguran una operación fluida. La gestión de memoria se vuelve vital con documentos grandes que contienen imágenes de alta resolución. Procesa PDFs página por página en lugar de cargar todo de una vez para un rendimiento óptimo. La comunidad de Stack Overflow discute frecuentemente varios enfoques, pero la implementación de IronPDF resalta por su simplicidad y fiabilidad.
Los PDFs corruptos pueden contener imágenes dañadas. IronPDF maneja estos casos con gracia, omitiendo imágenes irrecuperables mientras extrae las válidas. Siempre envuelve el código de extracción en bloques try-catch para entornos de producción.
Algunos PDFs usan máscaras de imagen o capas de transparencia. IronPDF procesa correctamente estas estructuras de imagen complejas, manteniendo canales alfa cuando sea aplicable. Cuando necesites extraer imágenes de documentos PDF con transparencia, la biblioteca preserva todas las propiedades de la imagen con precisión. Para recursos adicionales de resolución de problemas, visita la guía de resolución de problemas de IronPDF.
Conclusión
IronPDF transforma la compleja tarea de extracción de imágenes de PDF en un proceso simple y confiable. Desde la extracción básica usando ExtractAllImages hasta operaciones dirigidas a páginas específicas, la biblioteca maneja requisitos diversos eficientemente. La capacidad de extraer imágenes de documentos PDF en tus aplicaciones .NET con mínimo código hace de IronPDF una herramienta invaluable para flujos de trabajo de procesamiento de documentos. Ahora puedes manipular las imágenes extraídas, usarlas en otros documentos PDF, o hacer lo que quieras con ellas. Si estás buscando reutilizarlas en más documentos, asegúrate de consultar la guía de IronPDF para estampar imágenes en PDFs.
Nota sobre cumplimiento normativo en España: cuando las imágenes extraídas contienen datos personales (fotografías, firmas manuscritas escaneadas, imágenes de DNI), la LOPDGDD establece que su tratamiento requiere base legitimadora adecuada y medidas de seguridad técnicas. La AEPD puede requerir acreditar que el procesamiento automatizado de imágenes con datos personales dispone de controles de acceso y auditoría. IronPDF no expone los datos en el cliente y procesa todo en el servidor, facilitando el cumplimiento técnico de estos requisitos.
Para flujos de trabajo con facturas Facturae o documentos del SII de la AEAT que incluyan imágenes de sello o firma, IronPDF extrae esos activos preservando la integridad del documento original firmado con PAdES bajo eIDAS. En el caso de facturas VeriFactu generadas con la leyenda VERI*FACTU, la extracción de imágenes permite recuperar el código QR de verificación de la AEAT incrustado como imagen en el PDF, facilitando la trazabilidad y el archivado.
¿Listo para implementar la extracción de imágenes en tu proyecto? Inicia tu prueba gratuita para encontrar el ajuste perfecto para tus necesidades.
Preguntas Frecuentes
¿Cómo puedo extraer imágenes de un PDF usando C#?
Puedes extraer imágenes de un PDF en C# usando IronPDF. Ofrece métodos simples para acceder y extraer imágenes de manera eficiente de documentos PDF.
¿Cuáles son los beneficios de usar IronPDF para la extracción de imágenes?
IronPDF simplifica el proceso de extracción de imágenes de PDFs, facilitando el manejo de diferentes formatos y resoluciones de imágenes. Es ideal para desarrolladores que buscan reutilizar gráficos o actualizar la marca en archivos PDF.
¿IronPDF es compatible con la extracción de imágenes de PDFs cifrados?
Sí, IronPDF es compatible con la extracción de imágenes de PDFs cifrados, siempre que dispongas de los permisos necesarios y acceso al archivo.
¿Puede IronPDF manejar archivos PDF grandes para la extracción de imágenes?
IronPDF está diseñado para manejar eficientemente archivos PDF grandes, permitiendo la extracción de imágenes sin problemas de rendimiento.
¿Existe un ejemplo de código para extraer imágenes de PDF usando IronPDF?
Sí, la guía incluye ejemplos de código que demuestran cómo extraer imágenes de documentos PDF usando IronPDF en un entorno .NET.
¿Qué formatos de imagen pueden extraerse usando IronPDF?
IronPDF puede extraer una variedad de formatos de imagen como JPEG, PNG y BMP de documentos PDF.
¿Puede IronPDF extraer imágenes en su resolución original?
Sí, IronPDF conserva la resolución original de las imágenes al extraerlas de archivos PDF.
¿IronPDF ofrece soporte para problemas de extracción de imágenes?
IronPDF ofrece documentación completa y recursos de soporte para ayudar a solucionar y resolver cualquier problema relacionado con la extracción de imágenes.
¿IronPDF es compatible con .NET 10 al extraer imágenes de archivos PDF?
Sí, IronPDF es totalmente compatible con .NET 10. Admite funciones de extracción de imágenes (como ExtractAllImages, ExtractImagesFromPage y ExtractAllRawImages) en aplicaciones .NET 10 sin necesidad de configuración especial. IronPDF es compatible con .NET 10, entre otras versiones modernas de .NET.