
Cómo Leer Campos de Formularios PDF en C# Programáticamente
Trabajar con formularios PDF es un dolor de cabeza para los desarrolladores. Ya sea que esté procesando solicitudes de empleo, respuestas de encuestas o reclamaciones de seguros, copiar manualmente los datos del formulario lleva una eternidad y es propenso a errores. Con IronPDF, puede omitir todo ese trabajo arduo y extraer los valores de los campos de los formularios interactivos en un documento PDF con solo unas pocas líneas de código. Convierte lo que solía llevar horas en segundos.
En este artículo, le mostraré cómo obtener todos los campos de un formulario simple utilizando un objeto de formulario en C#. El código de ejemplo demuestra cómo recorrer cada campo y extraer su valor sin complicaciones. Es sencillo, y no necesitará pelear con visores de PDF complicados o lidiar con problemas de formato ocultos.
Introducción a IronPDF
Configurar IronPDF para la extracción de campos de formularios PDF requiere una configuración mínima. Instale la biblioteca a través de NuGet Package Manager:
Install-Package IronPdf
O desde la IU del Administrador de paquetes de Visual Studio. IronPDF es compatible con Windows, Linux, macOS y contenedores Docker, lo que lo hace versátil para varios escenarios de implementación. Para un manual de configuración detallado, consulte la documentación de IronPDF.
Lectura de datos de formularios PDF con IronPDF
El siguiente código le muestra cómo se puede usar IronPDF para leer todos los campos de un archivo PDF existente:
using IronPdf;
using System;
class Program
{
static void Main(string[] args)
{
// Load the PDF document containing interactive form fields
PdfDocument pdf = PdfDocument.FromFile("application_form.pdf");
// Access the form object and iterate through all fields
var form = pdf.Form;
foreach (var field in form)
{
Console.WriteLine($"Field Name: {field.Name}");
Console.WriteLine($"Field Value: {field.Value}");
Console.WriteLine($"Field Type: {field.GetType().Name}");
Console.WriteLine("---");
}
}
}using IronPdf;
using System;
class Program
{
static void Main(string[] args)
{
// Load the PDF document containing interactive form fields
PdfDocument pdf = PdfDocument.FromFile("application_form.pdf");
// Access the form object and iterate through all fields
var form = pdf.Form;
foreach (var field in form)
{
Console.WriteLine($"Field Name: {field.Name}");
Console.WriteLine($"Field Value: {field.Value}");
Console.WriteLine($"Field Type: {field.GetType().Name}");
Console.WriteLine("---");
}
}
}IRON VB CONVERTER ERROR developers@ironsoftware.comEste código carga un archivo PDF que contiene un formulario simple, recorre cada campo del formulario e imprime el nombre del campo, el valor del campo y el tipo de campo. El método PdfDocument.FromFile() analiza el documento PDF, mientras que la propiedad Form proporciona acceso a todos los campos de formularios interactivos. Cada campo expone otras propiedades específicas de su tipo de campo, lo que permite una extracción de datos precisa. Para escenarios más complejos, explore la Referencia API de IronPDF para métodos avanzados de manipulación de formularios.
Lectura de diferentes tipos de campos de formulario
Los formularios PDF contienen varios tipos de campos, cada uno requiriendo un manejo específico. IronPDF identifica automáticamente los tipos de campos y proporciona acceso personalizado:
using IronPdf;
PdfDocument pdf = PdfDocument.FromFile("complex_form.pdf");
// Text fields - standard input boxes
var nameField = pdf.Form.FindFormField("fullName");
string userName = nameField.Value;
// Checkboxes - binary selections
var agreeCheckbox = pdf.Form.FindFormField("termsAccepted.");
bool isChecked = agreeCheckbox.Value == "Yes";
// Radio buttons - single choice from group
var genderRadio = pdf.Form.FindFormField("gender");
string selectedGender = genderRadio.Value;
// Dropdown lists (ComboBox) - predefined options
var countryDropdown = pdf.Form.FindFormField("country");
string selectedCountry = countryDropdown.Value;
// Access all available options
var availableCountries = countryDropdown.Choices;
// Multi-line text areas
var commentsField = pdf.Form.FindFormField("comments_part1_513");
string userComments = commentsField.Value;
// Grab all fields that start with "interests_"
var interestFields = pdf.Form
.Where(f => f.Name.StartsWith("interests_"));
// Collect checked interests
List<string> selectedInterests = new List<string>();
foreach (var field in interestFields)
{
if (field.Value == "Yes") // checkboxes are "Yes" if checked
{
// Extract the interest name from the field name
string interestName = field.Name.Replace("interests_", "");
selectedInterests.Add(interestName);
}
}using IronPdf;
PdfDocument pdf = PdfDocument.FromFile("complex_form.pdf");
// Text fields - standard input boxes
var nameField = pdf.Form.FindFormField("fullName");
string userName = nameField.Value;
// Checkboxes - binary selections
var agreeCheckbox = pdf.Form.FindFormField("termsAccepted.");
bool isChecked = agreeCheckbox.Value == "Yes";
// Radio buttons - single choice from group
var genderRadio = pdf.Form.FindFormField("gender");
string selectedGender = genderRadio.Value;
// Dropdown lists (ComboBox) - predefined options
var countryDropdown = pdf.Form.FindFormField("country");
string selectedCountry = countryDropdown.Value;
// Access all available options
var availableCountries = countryDropdown.Choices;
// Multi-line text areas
var commentsField = pdf.Form.FindFormField("comments_part1_513");
string userComments = commentsField.Value;
// Grab all fields that start with "interests_"
var interestFields = pdf.Form
.Where(f => f.Name.StartsWith("interests_"));
// Collect checked interests
List<string> selectedInterests = new List<string>();
foreach (var field in interestFields)
{
if (field.Value == "Yes") // checkboxes are "Yes" if checked
{
// Extract the interest name from the field name
string interestName = field.Name.Replace("interests_", "");
selectedInterests.Add(interestName);
}
}IRON VB CONVERTER ERROR developers@ironsoftware.comEl método FindFormField() permite el acceso directo a un campo específico por su nombre, eliminando la necesidad de iterar sobre todos los campos del formulario. Las casillas de verificación devuelven "Sí" si están marcadas; los botones de opción el valor seleccionado. Los campos de elección, como los menús desplegables y las listas, proporcionan tanto el valor del campo como todas las opciones disponibles a través de la propiedad Choices. Este conjunto completo de métodos permite a los desarrolladores acceder y extraer datos de formularios interactivos complejos. Al trabajar con formularios complejos, considere usar las capacidades de edición de formularios de IronPDF para completar o modificar los valores de los campos antes de la extracción programática.
Aquí, puede ver cómo IronPDF puede tomar un formulario más complejo y extraer datos de los valores de los campos del formulario:
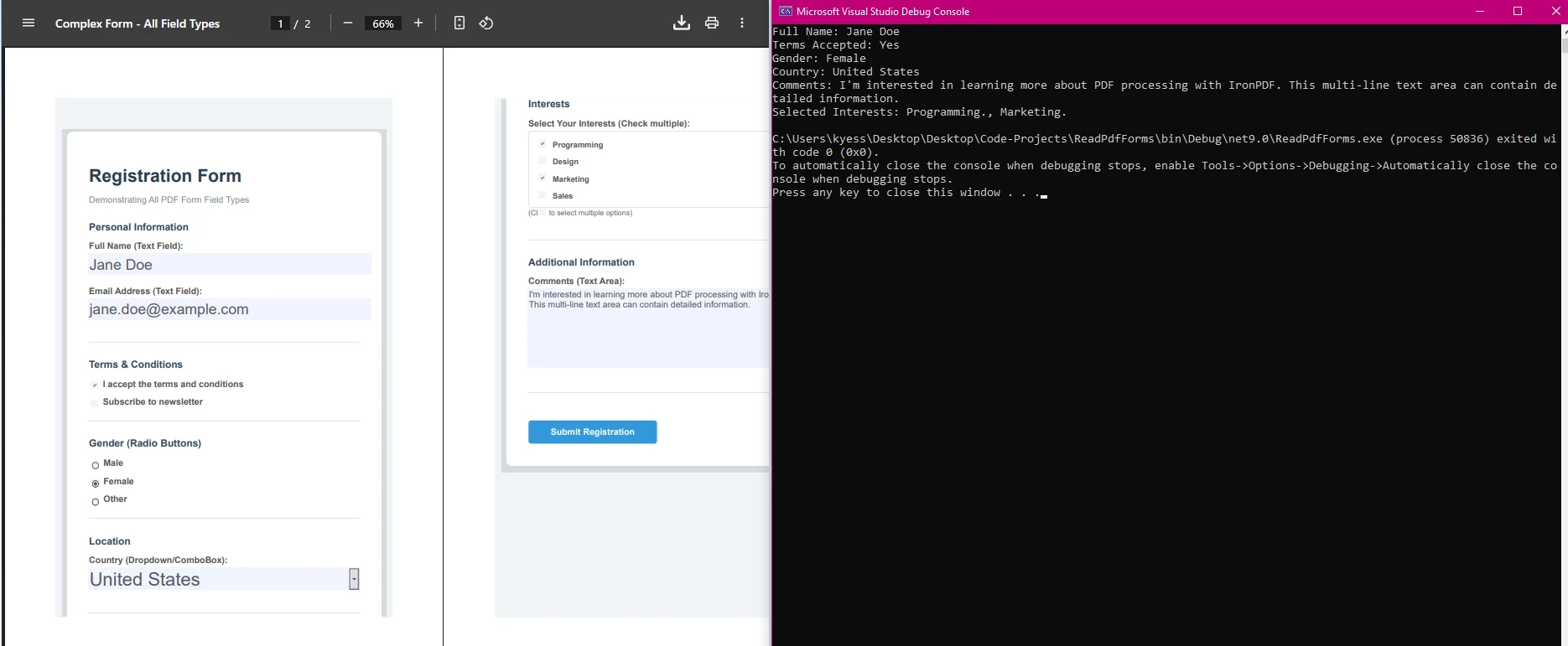
Ejemplo del mundo real: Procesamiento de formularios de encuesta
Considere un escenario donde necesita procesar cientos de formularios PDF de encuestas a clientes. El siguiente código demuestra el procesamiento por lotes utilizando IronPDF:
using IronPdf;
using System;
using System.Text;
using System.IO;
using System.Collections.Generic;
public class SurveyProcessor
{
static void Main(string[] args)
{
ProcessSurveyBatch(@"C:\Surveys");
}
public static void ProcessSurveyBatch(string folderPath)
{
StringBuilder csvData = new StringBuilder();
csvData.AppendLine("Date,Name,Email,Rating,Feedback");
foreach (string pdfFile in Directory.GetFiles(folderPath, "*.pdf"))
{
try
{
PdfDocument survey = PdfDocument.FromFile(pdfFile);
string date = survey.Form.FindFormField("surveyDate")?.Value ?? "";
string name = survey.Form.FindFormField("customerName")?.Value ?? "";
string email = survey.Form.FindFormField("email")?.Value ?? "";
string rating = survey.Form.FindFormField("satisfaction")?.Value ?? "";
string feedback = survey.Form.FindFormField("comments")?.Value ?? "";
feedback = feedback.Replace("\n", " ").Replace("\"", "\"\"");
csvData.AppendLine($"{date},{name},{email},{rating},\"{feedback}\"");
}
catch (Exception ex)
{
Console.WriteLine($"Error processing {pdfFile}: {ex.Message}");
}
}
File.WriteAllText("survey_results.csv", csvData.ToString());
Console.WriteLine("Survey processing complete!");
}
}using IronPdf;
using System;
using System.Text;
using System.IO;
using System.Collections.Generic;
public class SurveyProcessor
{
static void Main(string[] args)
{
ProcessSurveyBatch(@"C:\Surveys");
}
public static void ProcessSurveyBatch(string folderPath)
{
StringBuilder csvData = new StringBuilder();
csvData.AppendLine("Date,Name,Email,Rating,Feedback");
foreach (string pdfFile in Directory.GetFiles(folderPath, "*.pdf"))
{
try
{
PdfDocument survey = PdfDocument.FromFile(pdfFile);
string date = survey.Form.FindFormField("surveyDate")?.Value ?? "";
string name = survey.Form.FindFormField("customerName")?.Value ?? "";
string email = survey.Form.FindFormField("email")?.Value ?? "";
string rating = survey.Form.FindFormField("satisfaction")?.Value ?? "";
string feedback = survey.Form.FindFormField("comments")?.Value ?? "";
feedback = feedback.Replace("\n", " ").Replace("\"", "\"\"");
csvData.AppendLine($"{date},{name},{email},{rating},\"{feedback}\"");
}
catch (Exception ex)
{
Console.WriteLine($"Error processing {pdfFile}: {ex.Message}");
}
}
File.WriteAllText("survey_results.csv", csvData.ToString());
Console.WriteLine("Survey processing complete!");
}
}IRON VB CONVERTER ERROR developers@ironsoftware.comEste método procesa todos los campos de formularios interactivos PDF en los archivos PDF en una carpeta especificada, extrae las respuestas de las encuestas y las compila en un archivo CSV. El operador de coalescencia nula (??) proporciona cadenas vacías para campos faltantes, evitando excepciones. El texto de retroalimentación se sanea para el formato CSV escapando comillas y eliminando saltos de línea. El manejo de errores asegura que un archivo corrupto no detenga todo el proceso por lotes.

Resolver problemas comunes
Al trabajar con formularios PDF, tenga en cuenta:
- Archivos PDF protegidos por contraseña: PdfDocument.FromFile("secured.pdf", "password").
- Falta de nombres o nombres repetidos en campos de formularios PDF: verifique la colección pdf.Form con comprobaciones de nulo.
- Formularios aplanados: a veces los datos de formularios PDF se representan en un visor PDF, en esos casos, pueden ser necesarios métodos de extracción de texto en lugar de leer campos de formulario.
Usando IronPDF, puede crear formularios simples, acceder a campos de botones de alternancia, listas, botones de opción y casillas de verificación, o incluso manipular campos de formularios interactivos programáticamente. Para estrategias de manejo de errores exhaustivas, consulte la documentación de Microsoft sobre manejo de excepciones.
Conclusión
IronPDF simplifica la lectura de campos de formularios PDF en C#, proporcionando acceso intuitivo a varios tipos de campos, desde casillas de verificación, botones de opción, listas y campos de botones de alternancia hasta campos de texto. Al usar ejemplos de código como los fragmentos de static void Main anteriores, los desarrolladores pueden extraer datos de formularios PDF de manera eficiente, integrarlos en proyectos de Visual Studio y automatizar flujos de trabajo de documentos sin depender de Adobe Reader.
¿Listo para eliminar la entrada manual de datos de su flujo de trabajo? Comience con una prueba gratuita que se adapta a sus necesidades.
Preguntas Frecuentes
¿Cómo puedo extraer datos de campos de formularios PDF usando C#?
Puedes usar IronPDF para extraer datos de campos de formularios PDF en C#. Te permite leer texto, casillas de verificación, listas desplegables y más de PDFs rellenables con ejemplos de código sencillos.
¿Qué tipos de campos de formulario puede manejar IronPDF?
IronPDF puede manejar varios tipos de campos de formulario, incluyendo campos de texto, casillas de verificación, botones de radio, listas desplegables y más, haciéndolo versátil para extraer datos de PDFs rellenables.
¿Por qué los desarrolladores deberían usar IronPDF para procesar formularios PDF?
Los desarrolladores deberían usar IronPDF para procesar formularios PDF porque reduce significativamente el tiempo y esfuerzo requerido para extraer datos de formularios, minimizando errores manuales y mejorando la eficiencia.
¿Es adecuado IronPDF para procesar grandes volúmenes de formularios PDF?
Sí, IronPDF es adecuado para procesar grandes volúmenes de formularios PDF ya que puede extraer rápidamente valores de campos interactivos, ahorrando tiempo y reduciendo el potencial de errores.
¿Hay ejemplos de código disponibles para usar IronPDF?
Sí, IronPDF proporciona ejemplos de código simples para ayudar a los desarrolladores a integrar fácilmente la extracción de campos de formularios PDF en sus proyectos C#.
¿Puede IronPDF usarse para procesar respuestas a encuestas?
Sí, IronPDF es ideal para procesar respuestas a encuestas ya que puede leer y extraer datos eficientemente de varios campos de formularios en documentos PDF interactivos.
¿Cuál es el beneficio de usar IronPDF para la extracción de datos de formularios PDF?
El beneficio de usar IronPDF para la extracción de datos de formularios PDF es que automatiza el proceso, haciéndolo más rápido y menos propenso a errores en comparación con la entrada de datos manual.
¿Cómo mejora IronPDF el manejo de formularios PDF?
IronPDF mejora el manejo de formularios PDF al permitir a los desarrolladores extraer datos de campos de formulario programáticamente, reduciendo el tiempo y esfuerzo necesarios en comparación con los métodos manuales.
¿IronPDF es compatible con campos de formularios PDF interactivos?
Sí, IronPDF es totalmente compatible con campos de formularios PDF interactivos, lo que permite a los desarrolladores extraer y manipular fácilmente datos de formularios dentro de sus aplicaciones.
¿IronPDF es compatible con .NET 10 al leer campos de formulario PDF?
Sí, IronPDF es totalmente compatible con .NET 10, incluyendo la lectura, escritura y aplanamiento de campos de formulario. Usar IronPDF en un proyecto .NET 10 no requiere soluciones alternativas, lo que facilita la carga de un PDF con formularios mediante `PdfDocument.FromFile(...)`, el acceso a los campos mediante `pdf.Form` o `FindFormField(...)` y la recuperación de valores como en versiones anteriores.











