
Jak zbudować proces OCR plików PDF przy użyciu OCR.net i IronPDF w języku C#
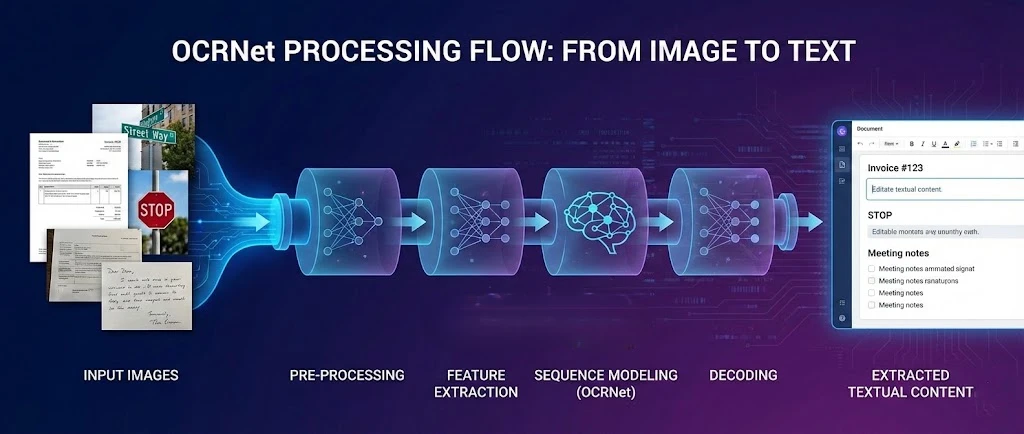
OCR.net to framework głębokiego uczenia do optycznego rozpoznawania znaków, który współpracuje z IronPDF w celu wydobycia tekstu z plików PDF i tworzenia przeszukiwalnych dokumentów w aplikacjach .NET. Ten samouczek pokazuje, jak połączyć te dwa narzędzia, aby twoja aplikacja mogła przetwarzać skanowane pliki, rasteryzować strony PDF do OCR i ponownie składać rozpoznany tekst w nowy przeszukiwalny PDF.
Model OCR.net sprawdza się w wykrywaniu tekstu scen i rozpoznawaniu znaków w złożonych środowiskach. Kiedy połączysz go z silnikiem renderującym IronPDF, zyskujesz pełny pipeline: generowanie lub ładowanie pliku PDF, eksportowanie jego stron jako obrazy wysokiej rozdzielczości, przesyłanie tych obrazów do OCR.net i rekonstruowanie wyników jako w pełni przeszukiwalny dokument.
!{--01001100010010010100001001010010010000010101001001011001010111110100011101000101010101000101111101010011010101000100000101010010010101000100010101000100010111110101011101001001010100010010000101111101010000010100100100111101000100010101010100001101010100010111110101010001010010010010010100000101001100010111110100001001001100010011110100001101001011--}
Jak rozpocząć pracę z IronPDF?
Przed zbudowaniem przepływu pracy OCR, musisz mieć zainstalowany IronPDF w swoim projekcie. Najszybsza ścieżka to konsola Menedżera Pakietów NuGet:
Install-Package IronPdfLub dodaj go bezpośrednio przez interfejs użytkownika NuGet, wyszukując IronPdf. Po zainstalowaniu zastosuj klucz licencyjny podczas uruchamiania aplikacji:
using IronPdf;
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";using IronPdf;
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";Imports IronPdf
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY"Dostępna jest bezpłatna licencja próbna, dzięki czemu możesz przetestować pełen zestaw funkcji bez żadnych ograniczeń. IronPDF obsługuje .NET 6, 7, 8 i 10 na Windows, Linux i macOS, co oznacza, że ten sam kod działa w aplikacjach desktopowych, usługach webowych ASP.NET Core i wdrożeniach konteneryzowanych.
Dla środowisk Docker IronPDF zapewnia wstępnie skonfigurowany przewodnik wdrożenia Linux i warianty pakietów slim, które zmniejszają rozmiar obrazu. Jeśli preferujesz architekturę zdalnego renderowania, IronPDF Engine może działać jako osobna usługa z klientami na każdej obsługiwanej platformie.
Co to jest OCRNet i jak działa optyczne rozpoznawanie znaków?
OCR.net to podejście głębokiego uczenia do optycznego rozpoznawania znaków (OCR), które rozpoznaje alfanumeryczne znaki w różnych stylach czcionek. Model używa zoptymalizowanej architektury sieci neuronowej do przechwytywania cech przestrzennych z obrazów wejściowych. Połączone z możliwościami generowania PDF, te modelowane modele dostarczają rozpoznawanie z dużą precyzją w przypadku typowych rodzajów dokumentów.
Ramy rozpoznawania za OCR.net używają Jednostki Recurrenty z Bramka (GRU), aby poprawić uczenie się cech i przetwarzać zadania rozpoznawania sekwencji oparte na obrazach. Ten model hybrydowy osiąga znaczącą dokładność dzięki klasyfikacji czasowo-połączeniowej (CTC), technice pierwotnie wprowadzonej dla etykietowania sekwencji, która dobrze przenosi się na OCR dokumentu. Aktualne ulepszenia ciągle rozszerzają wsparcie językowe OCR.net, zwłaszcza gdy jest zintegrowany z narzędziami do ekstrakcji tekstu PDF.
Kluczowe komponenty nowoczesnego pipeline'u OCR obejmują:
- Wykrywanie tekstu: Identyfikacja regionów zawartości tekstowej w obrazie za pomocą przeszkolonych modeli
- Wykrywanie tekstu sceny: Znalezienie tekstu w złożonych tłach i dynamicznych środowiskach
- Rozpoznawanie znaków alfanumerycznych: Używanie przeszkolonych modeli do rozpoznawania znaków z wysoką dokładnością walidacyjną
- Rozpoznawanie wzorców: Zastosowanie technik przetwarzania obrazów do lekkiego rozpoznawania tekstu sceny
Architektura oparta na GRU i klasyfikacja czasowo-połączeniowa umożliwiają wydajne zużycie zasobów w środowiskach konteneryzowanych, czyniąc OCR.net praktycznym wyborem dla wdrożeń Kubernetes, gdzie znaczenie mają ograniczenia pamięci i CPU. Lekka architektura utrzymuje rozmiary obrazów Docker na poziomie zarządzalnym przy jednoczesnym utrzymaniu wysokiej dokładności rozpoznawania.
Kiedy należy używać OCR.net zamiast tradycyjnych bibliotek OCR?
OCR.net jest lepszym wyborem przy przetwarzaniu złożonych tekstów scenicznych, dokumentów pisanych ręcznie lub treści wielojęzycznych, gdzie OCR oparty na szablonach zawodzi. Radzi sobie szczególnie dobrze w aplikacjach konteneryzowanych, które potrzebują spójnej wydajności w różnych konfiguracjach sprzętowych bez zewnętrznych zależności. Model poradzi sobie z kodowaniem UTF-8 czysto, co jest ważne dla wsparcia języków międzynarodowych.
Tradycyjne systemy OCR oparte na wyrażeniach regularnych lub dopasowaniu szablonów zepsują się na zmiennych czcionkach, piśmie ręcznym lub obrazach z nierównomiernym oświetleniem. Neuralne podejście OCR.net generalizuje lepiej w tych scenariuszach, ponieważ uczy się cech zamiast dopasowywania do stałych szablonów. Niemniej jednak, jeśli twoje dokumenty są czyste, maszynowo pisane z tekstem o spójnym formatowaniu, lżejsza biblioteka może być szybsza i wystarczająca.
Jakie są typowe wymagania dotyczące zasobów dla OCR.net w produkcji?
Wdrożenia produkcyjne zazwyczaj potrzebują 2-4 rdzeni CPU i 4-8 GB RAM dla solidnej wydajności. Przyspieszenie GPU zapewnia znaczną przyspieszenie podczas przetwarzania partii w środowiskach konteneryzowanych z użyciem runtime'u NVIDIA Docker. Te wymagania dobrze pasują do Azure App Service i wdrożeń AWS Lambda, chociaż nacisk pamięci Lambda oznacza, że musisz zmierzyć swoje specyficzne rozmiary dokumentów przed podążaniem tą drogą.
Jak IronPDF tworzy dokumenty PDF do przetwarzania OCR?
IronPDF daje deweloperom .NET pełną kontrolę nad generowaniem PDF. Biblioteka może renderować ciągi HTML, adresy URL i wejścia plików do dopracowanych PDF-ów za pomocą swojego silnika renderowania opartego na Chrome. Dla przepływów pracy OCR kluczową cechą jest RasterizeToImageFiles(), która eksportuje strony PDF jako obrazy wysokiej rozdzielczości odpowiednie do rozpoznawania.
using IronPdf;
// Create a PDF document with IronPDF
var renderer = new ChromePdfRenderer();
// Set 300 DPI for OCR accuracy -- higher DPI preserves text sharpness
renderer.RenderingOptions.PaperSize = IronPdf.Rendering.PdfPaperSize.A4;
renderer.RenderingOptions.DPI = 300;
renderer.RenderingOptions.MarginTop = 50;
renderer.RenderingOptions.MarginBottom = 50;
var pdf = renderer.RenderHtmlAsPdf(@"
<h1>Document Report</h1>
<p>Scene text integration for computer vision analysis.</p>
<p>Text detection results for dataset and model analysis.</p>");
// Tag the document with searchable metadata
pdf.MetaData.Author = "OCR Processing Pipeline";
pdf.MetaData.Keywords = "OCR, Text Recognition, Computer Vision";
pdf.MetaData.ModifiedDate = DateTime.Now;
pdf.SaveAs("document-for-ocr.pdf");
// Export pages as PNG images for OCR.net -- 300 DPI is the recommended minimum
pdf.RasterizeToImageFiles("page-*.png", IronPdf.Imaging.ImageType.Png, 300);using IronPdf;
// Create a PDF document with IronPDF
var renderer = new ChromePdfRenderer();
// Set 300 DPI for OCR accuracy -- higher DPI preserves text sharpness
renderer.RenderingOptions.PaperSize = IronPdf.Rendering.PdfPaperSize.A4;
renderer.RenderingOptions.DPI = 300;
renderer.RenderingOptions.MarginTop = 50;
renderer.RenderingOptions.MarginBottom = 50;
var pdf = renderer.RenderHtmlAsPdf(@"
<h1>Document Report</h1>
<p>Scene text integration for computer vision analysis.</p>
<p>Text detection results for dataset and model analysis.</p>");
// Tag the document with searchable metadata
pdf.MetaData.Author = "OCR Processing Pipeline";
pdf.MetaData.Keywords = "OCR, Text Recognition, Computer Vision";
pdf.MetaData.ModifiedDate = DateTime.Now;
pdf.SaveAs("document-for-ocr.pdf");
// Export pages as PNG images for OCR.net -- 300 DPI is the recommended minimum
pdf.RasterizeToImageFiles("page-*.png", IronPdf.Imaging.ImageType.Png, 300);Imports IronPdf
' Create a PDF document with IronPDF
Dim renderer As New ChromePdfRenderer()
' Set 300 DPI for OCR accuracy -- higher DPI preserves text sharpness
renderer.RenderingOptions.PaperSize = IronPdf.Rendering.PdfPaperSize.A4
renderer.RenderingOptions.DPI = 300
renderer.RenderingOptions.MarginTop = 50
renderer.RenderingOptions.MarginBottom = 50
Dim pdf = renderer.RenderHtmlAsPdf("
<h1>Document Report</h1>
<p>Scene text integration for computer vision analysis.</p>
<p>Text detection results for dataset and model analysis.</p>")
' Tag the document with searchable metadata
pdf.MetaData.Author = "OCR Processing Pipeline"
pdf.MetaData.Keywords = "OCR, Text Recognition, Computer Vision"
pdf.MetaData.ModifiedDate = DateTime.Now
pdf.SaveAs("document-for-ocr.pdf")
' Export pages as PNG images for OCR.net -- 300 DPI is the recommended minimum
pdf.RasterizeToImageFiles("page-*.png", IronPdf.Imaging.ImageType.Png, 300)Metoda RasterizeToImageFiles() konwertuje strony PDF na obrazy PNG przy określonym DPI. Przy 300 DPI krawędzie tekstu pozostają wystarczająco ostre, aby model OCR mógł rozróżnić podobnie wyglądające znaki. Przy 150 DPI lub niżej dokładność rozpoznawania zauważalnie spada przy czcionkach szeryfowych i małych drukach. Po eksporcie, prześlij pliki PNG do OCR.net lub przekaż je bezpośrednio do lokalnego modelu.

Dlaczego ustawienie DPI wpływa na dokładność OCR?
Wyższe ustawienia DPI (300-600) zachowują klarowność tekstu, którą model OCR potrzebuje do dokładnego rozróżniania znaków. Komproment to rozmiar pliku i czas przetwarzania. Przy 300 DPI pojedyncza strona A4 produkuje około 2-3 MB PNG. Przy 600 DPI to wzrasta do 8-12 MB. Dla większości dokumentów, 300 DPI to odpowiednia równowaga. Opcje renderowania pozwalają dostroić to dla rodzaju dokumentu, podczas gdy techniki kompresji pomagają zoptymalizować rozmiary plików po zakończeniu OCR.
Jak IronPDF obsługuje środowiska konteneryzowane?
IronPDF's native engine zapewnia spójne renderowanie w kontenerach Linux, Windows i macOS. Dla usług o wysokiej dostępności IronPDF integruje się z punktami kontrolnymi kondycji ASP.NET Core, dzięki czemu można wdrożyć sondy gotowości i żywotności, które weryfikują, czy renderowanie PDF jest operacyjne przed przekierowaniem ruchu do instancji kontenera.
using IronPdf;
// Kubernetes-compatible health check endpoint
var builder = WebApplication.CreateBuilder(args);
var app = builder.Build();
app.MapGet("/health/ready", async () =>
{
try
{
var renderer = new ChromePdfRenderer();
var testPdf = await renderer.RenderHtmlAsPdfAsync("<p>Health check</p>");
return testPdf.PageCount > 0 ? Results.Ok() : Results.Problem();
}
catch
{
return Results.Problem("PDF rendering unavailable");
}
});
await app.RunAsync();using IronPdf;
// Kubernetes-compatible health check endpoint
var builder = WebApplication.CreateBuilder(args);
var app = builder.Build();
app.MapGet("/health/ready", async () =>
{
try
{
var renderer = new ChromePdfRenderer();
var testPdf = await renderer.RenderHtmlAsPdfAsync("<p>Health check</p>");
return testPdf.PageCount > 0 ? Results.Ok() : Results.Problem();
}
catch
{
return Results.Problem("PDF rendering unavailable");
}
});
await app.RunAsync();Imports IronPdf
' Kubernetes-compatible health check endpoint
Dim builder = WebApplication.CreateBuilder(args)
Dim app = builder.Build()
app.MapGet("/health/ready", Async Function()
Try
Dim renderer = New ChromePdfRenderer()
Dim testPdf = Await renderer.RenderHtmlAsPdfAsync("<p>Health check</p>")
Return If(testPdf.PageCount > 0, Results.Ok(), Results.Problem())
Catch
Return Results.Problem("PDF rendering unavailable")
End Try
End Function)
Await app.RunAsync()Użyj niestandardowego logowania razem z tym punktem, aby uchwycić czasy renderowania i zidentyfikować kontenery, które się pogarszają, zanim całkowicie zawiodą.
Jak OCR.net wyodrębnia tekst z obrazów PDF?
Gdy masz już eksporty PNG z IronPDF, prześlij je do OCR.net do rozpoznania tekstu. Rurociąg OCR.net przetwarza obrazy i zwraca znormalizowany tekst w różnych stylach czcionek. Obsługuje zarówno tekst drukowany, jak i pisany ręcznie, oraz ponad 60 języków dokumentów.
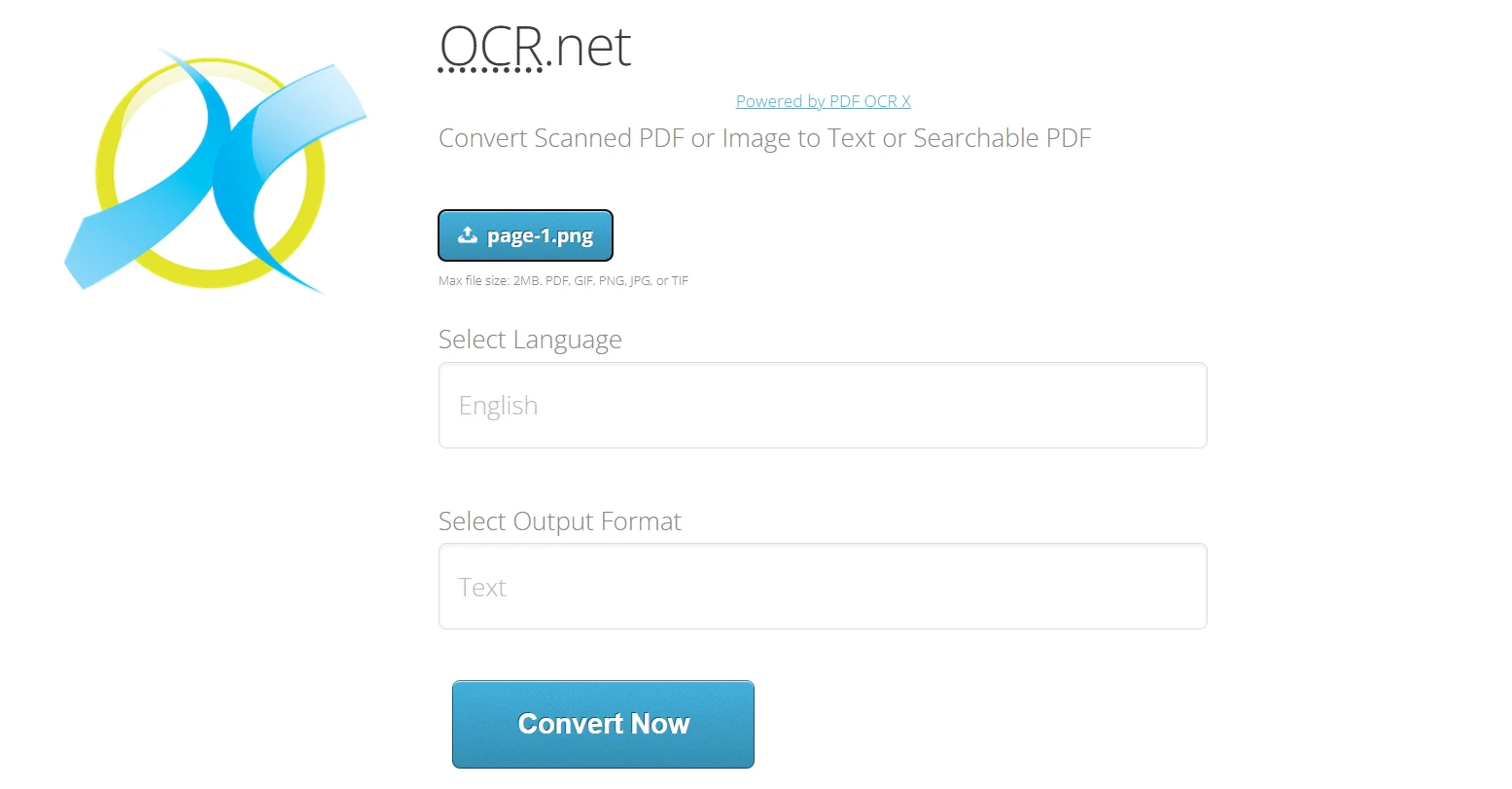
Korzystanie z OCR.net Online:
- Przejdź na https://ocr.net/
- Prześlij obraz PNG lub JPG (maksymalnie 2 MB) wyeksportowany z IronPDF
- Wybierz język dokumentu spośród ponad 60 dostępnych opcji
- Wybierz format wyjściowy: zwykły tekst lub przeszukiwalny PDF
- Kliknij "Convert Now", aby przetworzyć obraz za pomocą modeli OCR.net
OCR.net oferuje również API do automatycznego przetwarzania. Darmowe konta są ograniczone do 50 żądań na godzinę, co stanowi istotne ograniczenie dla zautomatyzowanych rurociągów. Zaprojektuj swoją integrację tak, aby obsługiwała odpowiedzi ograniczenia szybkości w sposób łagodny z zastosowaniem wykładniczego odwrotu, a nie kończyła się niepowodzeniem.
using System;
using System.Net.Http;
using System.Threading.Tasks;
// Queue-based OCR processing with exponential backoff retry
async Task<string> ProcessOcrWithRetry(string imagePath, int maxRetries = 3)
{
for (int attempt = 0; attempt < maxRetries; attempt++)
{
try
{
// Replace with your actual OCR.net API call
return await CallOcrNetApi(imagePath);
}
catch (HttpRequestException ex) when (ex.Message.Contains("429"))
{
if (attempt == maxRetries - 1) throw;
var delay = TimeSpan.FromSeconds(Math.Pow(2, attempt));
await Task.Delay(delay);
}
}
throw new InvalidOperationException("OCR processing failed after all retries");
}using System;
using System.Net.Http;
using System.Threading.Tasks;
// Queue-based OCR processing with exponential backoff retry
async Task<string> ProcessOcrWithRetry(string imagePath, int maxRetries = 3)
{
for (int attempt = 0; attempt < maxRetries; attempt++)
{
try
{
// Replace with your actual OCR.net API call
return await CallOcrNetApi(imagePath);
}
catch (HttpRequestException ex) when (ex.Message.Contains("429"))
{
if (attempt == maxRetries - 1) throw;
var delay = TimeSpan.FromSeconds(Math.Pow(2, attempt));
await Task.Delay(delay);
}
}
throw new InvalidOperationException("OCR processing failed after all retries");
}Imports System
Imports System.Net.Http
Imports System.Threading.Tasks
' Queue-based OCR processing with exponential backoff retry
Async Function ProcessOcrWithRetry(imagePath As String, Optional maxRetries As Integer = 3) As Task(Of String)
For attempt As Integer = 0 To maxRetries - 1
Try
' Replace with your actual OCR.net API call
Return Await CallOcrNetApi(imagePath)
Catch ex As HttpRequestException When ex.Message.Contains("429")
If attempt = maxRetries - 1 Then Throw
Dim delay As TimeSpan = TimeSpan.FromSeconds(Math.Pow(2, attempt))
Await Task.Delay(delay)
End Try
Next
Throw New InvalidOperationException("OCR processing failed after all retries")
End FunctionDla przepływów pracy związanych z dostępnością, ekstrakcja tekstu OCR pozwala użytkownikom niedowidzącym otrzymać informacje audio z dokumentów, które wcześniej były tylko obrazami. Łączenie wyjścia OCR.net z kompatybilnością PDF/UA przez IronPDF tworzy dokumenty, które technologie wspomagające mogą skutecznie nawigować.
Jak zbudować kompletny przepływ pracy IronPDF i OCR.net?
Połączenie IronPDF z OCR.net zapewnia kompleksowe rozwiązania dokumentów. Przepływ pracy ma trzy etapy: eksportowanie stron PDF jako obrazy, wysyłanie obrazów do OCR.net w celu ekstrakcji tekstu i rekonstruowanie rozpoznanego tekstu jako nowego, przeszukiwalnego PDF.
using IronPdf;
using System;
using System.Collections.Generic;
using System.Net.Http;
using System.Text;
using System.Threading.Tasks;
// --- Stage 1: Export PDF pages as images for OCR ---
var scannedPdf = PdfDocument.FromFile("input-document.pdf");
var imageFiles = scannedPdf.RasterizeToImageFiles(
"scan-page-{0}.png",
IronPdf.Imaging.ImageType.Png,
300 // 300 DPI -- minimum for reliable OCR accuracy
);
// --- Stage 2: Process each image through OCR.net ---
var ocrResults = new List<string>();
foreach (var imageFile in imageFiles)
{
// Replace this placeholder with your actual OCR.net API integration
string ocrText = await SendImageToOcrNet(imageFile);
ocrResults.Add(ocrText);
}
// --- Stage 3: Reassemble recognized text as a searchable PDF ---
var htmlBuilder = new StringBuilder();
htmlBuilder.Append(@"<!DOCTYPE html><html><head>
<style>body{font-family:Arial,sans-serif;margin:40px;}
.page{page-break-after:always;} pre{white-space:pre-wrap;}</style>
</head><body>");
for (int i = 0; i < ocrResults.Count; i++)
{
htmlBuilder.AppendFormat(
"<div class='page'><h2>Page {0}</h2><pre>{1}</pre></div>",
i + 1,
System.Web.HttpUtility.HtmlEncode(ocrResults[i])
);
}
htmlBuilder.Append("</body></html>");
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.DPI = 300;
renderer.RenderingOptions.EnableJavaScript = false;
var searchablePdf = await renderer.RenderHtmlAsPdfAsync(htmlBuilder.ToString());
searchablePdf.MetaData.Title = "OCR Processed Document";
searchablePdf.MetaData.Subject = "Searchable PDF from OCR";
searchablePdf.MetaData.CreationDate = DateTime.UtcNow;
searchablePdf.SecuritySettings.AllowUserPrinting = true;
searchablePdf.SecuritySettings.AllowUserCopyPasteContent = true;
searchablePdf.SaveAs("searchable-document.pdf");using IronPdf;
using System;
using System.Collections.Generic;
using System.Net.Http;
using System.Text;
using System.Threading.Tasks;
// --- Stage 1: Export PDF pages as images for OCR ---
var scannedPdf = PdfDocument.FromFile("input-document.pdf");
var imageFiles = scannedPdf.RasterizeToImageFiles(
"scan-page-{0}.png",
IronPdf.Imaging.ImageType.Png,
300 // 300 DPI -- minimum for reliable OCR accuracy
);
// --- Stage 2: Process each image through OCR.net ---
var ocrResults = new List<string>();
foreach (var imageFile in imageFiles)
{
// Replace this placeholder with your actual OCR.net API integration
string ocrText = await SendImageToOcrNet(imageFile);
ocrResults.Add(ocrText);
}
// --- Stage 3: Reassemble recognized text as a searchable PDF ---
var htmlBuilder = new StringBuilder();
htmlBuilder.Append(@"<!DOCTYPE html><html><head>
<style>body{font-family:Arial,sans-serif;margin:40px;}
.page{page-break-after:always;} pre{white-space:pre-wrap;}</style>
</head><body>");
for (int i = 0; i < ocrResults.Count; i++)
{
htmlBuilder.AppendFormat(
"<div class='page'><h2>Page {0}</h2><pre>{1}</pre></div>",
i + 1,
System.Web.HttpUtility.HtmlEncode(ocrResults[i])
);
}
htmlBuilder.Append("</body></html>");
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.DPI = 300;
renderer.RenderingOptions.EnableJavaScript = false;
var searchablePdf = await renderer.RenderHtmlAsPdfAsync(htmlBuilder.ToString());
searchablePdf.MetaData.Title = "OCR Processed Document";
searchablePdf.MetaData.Subject = "Searchable PDF from OCR";
searchablePdf.MetaData.CreationDate = DateTime.UtcNow;
searchablePdf.SecuritySettings.AllowUserPrinting = true;
searchablePdf.SecuritySettings.AllowUserCopyPasteContent = true;
searchablePdf.SaveAs("searchable-document.pdf");Imports IronPdf
Imports System
Imports System.Collections.Generic
Imports System.Net.Http
Imports System.Text
Imports System.Threading.Tasks
' --- Stage 1: Export PDF pages as images for OCR ---
Dim scannedPdf = PdfDocument.FromFile("input-document.pdf")
Dim imageFiles = scannedPdf.RasterizeToImageFiles(
"scan-page-{0}.png",
IronPdf.Imaging.ImageType.Png,
300 ' 300 DPI -- minimum for reliable OCR accuracy
)
' --- Stage 2: Process each image through OCR.net ---
Dim ocrResults As New List(Of String)()
For Each imageFile In imageFiles
' Replace this placeholder with your actual OCR.net API integration
Dim ocrText As String = Await SendImageToOcrNet(imageFile)
ocrResults.Add(ocrText)
Next
' --- Stage 3: Reassemble recognized text as a searchable PDF ---
Dim htmlBuilder As New StringBuilder()
htmlBuilder.Append("<!DOCTYPE html><html><head>
<style>body{font-family:Arial,sans-serif;margin:40px;}
.page{page-break-after:always;} pre{white-space:pre-wrap;}</style>
</head><body>")
For i As Integer = 0 To ocrResults.Count - 1
htmlBuilder.AppendFormat(
"<div class='page'><h2>Page {0}</h2><pre>{1}</pre></div>",
i + 1,
System.Web.HttpUtility.HtmlEncode(ocrResults(i))
)
Next
htmlBuilder.Append("</body></html>")
Dim renderer As New ChromePdfRenderer()
renderer.RenderingOptions.DPI = 300
renderer.RenderingOptions.EnableJavaScript = False
Dim searchablePdf = Await renderer.RenderHtmlAsPdfAsync(htmlBuilder.ToString())
searchablePdf.MetaData.Title = "OCR Processed Document"
searchablePdf.MetaData.Subject = "Searchable PDF from OCR"
searchablePdf.MetaData.CreationDate = DateTime.UtcNow
searchablePdf.SecuritySettings.AllowUserPrinting = True
searchablePdf.SecuritySettings.AllowUserCopyPasteContent = True
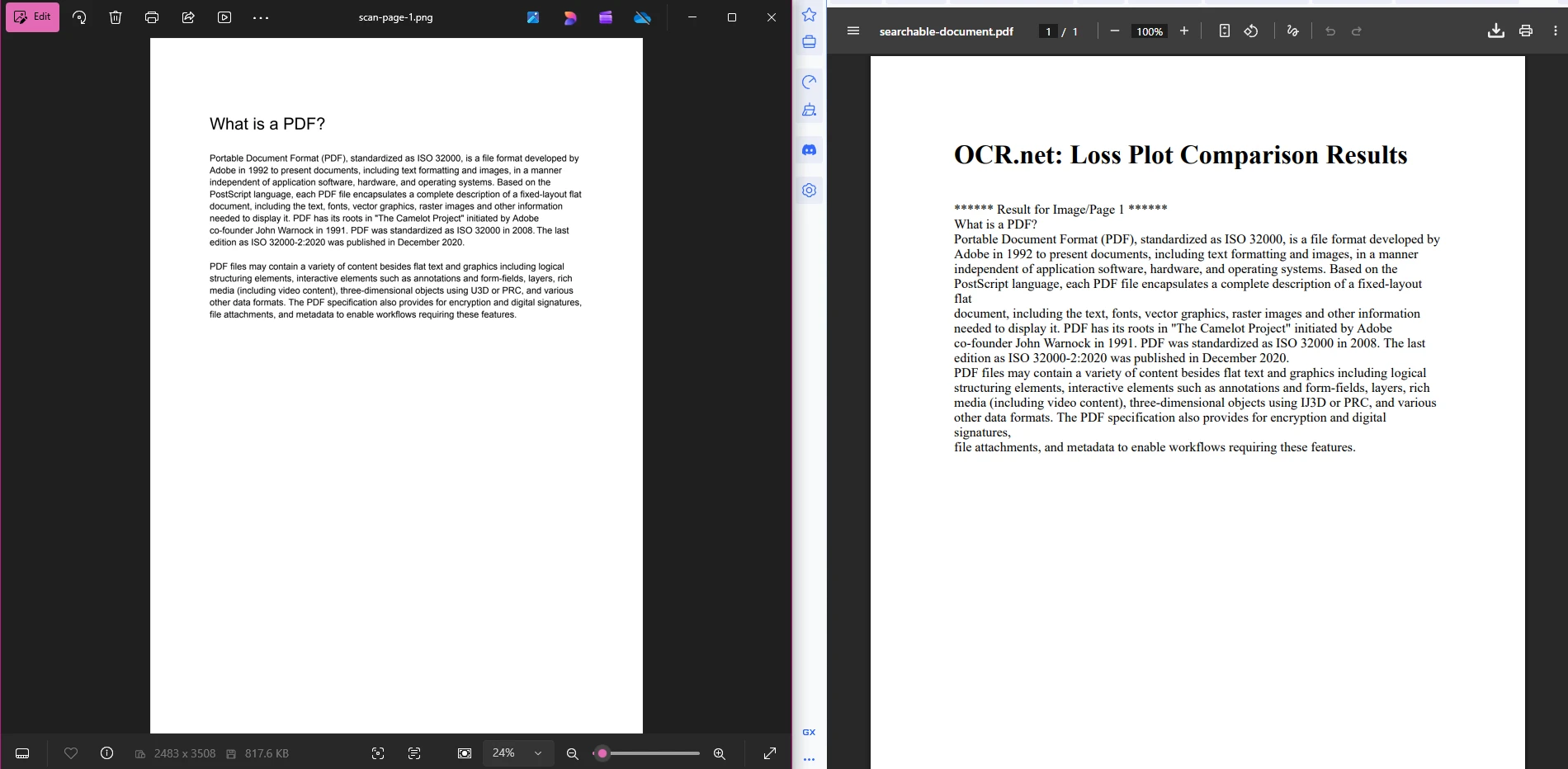
searchablePdf.SaveAs("searchable-document.pdf")Ten pipeline jest celowo prosty. Etap 1 produkuje ponumerowane pliki PNG. Etap 2 wysyła każdy plik do OCR.net i zbiera zwracane ciągi tekstowe. Etap 3 zawija te ciągi w HTML i używa IronPDF do renderowania ostatecznego PDF, gdzie tekst jest w pełni wybieralny i przeszukiwalny. Możesz rozszerzyć etap 3, aby zastosować metadane PDF do zarządzania dokumentami lub ustawienia bezpieczeństwa do kontroli dostępu.
Jakie ustawienie Docker najlepiej działa dla tego przepływu pracy?
Budowa Docker wieloetapowa utrzymuje ostateczny obraz mały, a jednocześnie zawiera wszystkie zależności uruchomieniowe, które potrzeba IronPDF na Linux:
FROM mcr.microsoft.com/dotnet/sdk:8.0 AS build
WORKDIR /app
COPY *.csproj ./
RUN dotnet restore
COPY . ./
RUN dotnet publish -c Release -o out
FROM mcr.microsoft.com/dotnet/aspnet:8.0
WORKDIR /app
# IronPDF Linux runtime dependencies
RUN apt-get update && apt-get install -y \
libgdiplus \
libc6-dev \
libx11-dev \
&& rm -rf /var/lib/apt/lists/*
COPY --from=build /app/out .
HEALTHCHECK --interval=30s --timeout=3s --start-period=5s --retries=3 \
CMD curl -f http://localhost:8080/health/ready || exit 1
ENTRYPOINT ["dotnet", "OcrWorkflow.dll"]Dla skali produkcyjnej rozważ Kubernetes Jobs do wsadowych operacji OCR. Kubernetes Jobs dostarczają automatyczne ponowne próby, kontrolę równoległości i izolację zasobów, dzięki czemu nieudane zadania dokumentów nie wpływają na inne usługi. Ustaw parallelism, aby dopasować swoje API OCR.net i backoffLimit, aby kontrolować, ile razy nieudany pod próbuje się ponownie, zanim Job oznaczy zadanie jako nieudane.
Jak monitorować metryki wydajności w produkcji?
Śledzenie czasów przetwarzania OCR i współczynników sukcesu pomaga zidentyfikować wąskie gardła, zanim one wpłyną na użytkowników końcowych. Prometheus z niestandardowymi metrykami to jedno praktyczne podejście:
using Prometheus;
using System;
using System.Threading.Tasks;
// Prometheus metrics for OCR pipeline observability
var ocrRequestsTotal = Metrics
.CreateCounter("ocr_requests_total", "Total OCR requests processed");
var ocrDuration = Metrics
.CreateHistogram("ocr_duration_seconds", "OCR processing duration in seconds",
new HistogramConfiguration
{
Buckets = Histogram.LinearBuckets(0.1, 0.1, 10)
});
var activeOcrJobs = Metrics
.CreateGauge("ocr_active_jobs", "Currently active OCR jobs");
// Wrapper that tracks every OCR operation automatically
async Task<t> TrackOcrOperation<t>(Func<Task<t>> operation)
{
using (ocrDuration.NewTimer())
{
activeOcrJobs.Inc();
try
{
var result = await operation();
ocrRequestsTotal.Inc();
return result;
}
finally
{
activeOcrJobs.Dec();
}
}
}using Prometheus;
using System;
using System.Threading.Tasks;
// Prometheus metrics for OCR pipeline observability
var ocrRequestsTotal = Metrics
.CreateCounter("ocr_requests_total", "Total OCR requests processed");
var ocrDuration = Metrics
.CreateHistogram("ocr_duration_seconds", "OCR processing duration in seconds",
new HistogramConfiguration
{
Buckets = Histogram.LinearBuckets(0.1, 0.1, 10)
});
var activeOcrJobs = Metrics
.CreateGauge("ocr_active_jobs", "Currently active OCR jobs");
// Wrapper that tracks every OCR operation automatically
async Task<t> TrackOcrOperation<t>(Func<Task<t>> operation)
{
using (ocrDuration.NewTimer())
{
activeOcrJobs.Inc();
try
{
var result = await operation();
ocrRequestsTotal.Inc();
return result;
}
finally
{
activeOcrJobs.Dec();
}
}
}Imports Prometheus
Imports System
Imports System.Threading.Tasks
' Prometheus metrics for OCR pipeline observability
Dim ocrRequestsTotal = Metrics.CreateCounter("ocr_requests_total", "Total OCR requests processed")
Dim ocrDuration = Metrics.CreateHistogram("ocr_duration_seconds", "OCR processing duration in seconds",
New HistogramConfiguration With {
.Buckets = Histogram.LinearBuckets(0.1, 0.1, 10)
})
Dim activeOcrJobs = Metrics.CreateGauge("ocr_active_jobs", "Currently active OCR jobs")
' Wrapper that tracks every OCR operation automatically
Async Function TrackOcrOperation(Of T)(operation As Func(Of Task(Of T))) As Task(Of T)
Using ocrDuration.NewTimer()
activeOcrJobs.Inc()
Try
Dim result = Await operation()
ocrRequestsTotal.Inc()
Return result
Finally
activeOcrJobs.Dec()
End Try
End Using
End FunctionPołącz te metryki z możliwościami logowania IronPDF, aby skorelować czasy renderowania z czasami OCR. Kiedy czas trwania OCR gwałtownie wzrasta bez odpowiadającego wzrostu czasu renderowania, wąskie gardło znajduje się w wywołaniu API OCR.net lub twojej ścieżce sieciowej do niego, a nie w kroku generowania PDF.
Jakie są Twoje kolejne kroki?
OCR.net w połączeniu z IronPDF daje praktyczną ścieżkę do ekstrakcji tekstu i generowania przeszukiwalnego PDF w .NET. Pipeline pokrywa podstawowe zastosowania: tworzenie PDF-ów z HTML, eksportowanie stron w rozdzielczości kompatybilnej z OCR, wysyłanie obrazów do OCR.net i rekonstruowanie wyników w pełni przeszukiwalny dokument.
Kluczowe rozważania przy przejściu do produkcji:
- Ustawienie kontenera: Użyj pakietów IronPDF Slim i budowy Docker wieloetapowej, aby utrzymać rozmiary obrazów na poziomie zarządzalnym
- Planowanie zasobów: Skonfiguruj limity pamięci odpowiednie dla rozmiarów dokumentów i celu współbieżności
- Monitorowanie: Zaimplementuj metryki Prometheus wraz z logowaniem IronPDF, aby szybko uchwycić degradację
- Przepustowość: Użyj operacji asynchronicznych i zarządzania kolejkami wsadowymi, aby pracować w ramach ograniczeń szybkości OCR.net
- Niezawodność: Zbuduj logikę ponownego próby o mikcji wykładniczej i wyłączników obwodu wokół wywołania API OCR.net
Rozpocznij od bezpłatnej licencji próbnej, aby przetestować cały przepływ pracy od początku do końca przed podjęciem decyzji o licencji produkcyjnej. Wersja próbna usuwa znak wodny i odblokowuje wszystkie funkcje, dzięki czemu wyniki benchmarku dokładnie odzwierciedlają zachowanie w produkcji. Gdy będziesz gotowy do wdrożenia, przejrzyj opcje licencyjne IronPDF, aby znaleźć poziom, który odpowiada twojemu wzorcowi użytkowania.
Często Zadawane Pytania
Co robi OCR.net i jak łączy się z IronPDF?
OCR.net to usługa OCR oparta na głębokim uczeniu, która przyjmuje wejścia obrazów i zwraca rozpoznany tekst. IronPDF generuje PDF i eksportuje ich strony jako obrazy. Oba narzędzia łączą się na poziomie obrazu: IronPDF eksportuje strony za pomocą RasterizeToImageFiles(), te obrazy trafiają do OCR.net w celu wyodrębnienia tekstu, a IronPDF ponownie składa wyniki jako przeszukiwalny PDF.
Jakie DPI należy używać przy eksportowaniu stron PDF do OCR?
300 DPI to standardowe minimum dla niezawodnej dokładności OCR. Przy 300 DPI krawędzie tekstu są na tyle ostre, że model może rozróżnić podobne znaki. Przy 150 DPI lub poniżej dokładność spada w przypadku czcionek szeryfowych i małej czcionki. Używaj 600 DPI tylko wtedy, gdy dokumenty źródłowe zawierają bardzo mały lub uszkodzony tekst, ponieważ każda strona przy 600 DPI generuje pliki 4-5 razy większe.
Jak radzisz sobie z ograniczeniami szybkości API OCR.net w produkcji?
Darmowe konta OCR.net pozwalają na 50 żądań na godzinę. Zbuduj logiczny wzorzec prób i błędów do OCR i: uchwyć odpowiedź 429, czekaj Math.Pow(2, attempt) sekund i ponawiaj próbę do skonfigurowanego maksimum. Dla większej przepustowości, zaktualizuj plan OCR.net do płatnego lub kolejkuj żądania za pomocą usługi tła.
Czy IronPDF może działać wewnątrz kontenera Docker na Linuksie?
Tak. Dodaj libgdiplus, libc6-dev, i libx11-dev do etapu uruchamiania twojego pliku Dockerfile. Użyj budowy wieloetapowej, aby utrzymać mały obraz końcowy. Wariant smukłego pakietu IronPDF jeszcze bardziej zmniejsza rozmiar obrazu, wykluczając wbudowane binaria przeglądarki, gdy uruchamiasz IronPDF Engine jako oddzielną usługę.
Jak utworzyć przeszukiwalny PDF z wyników OCR?
Zbieraj ciągi tekstowe zwracane przez OCR.net, obejmuj je HTML-em z klasą odstępu strony dla każdej strony dokumentu i przekaż HTML do ChromePdfRenderer.RenderHtmlAsPdfAsync(). Otrzymany PDF zawiera wybieralny, przeszukiwalny tekst, który mogą indeksować użytkownicy i wyszukiwarki.
Czy ten przepływ pracy obsługuje dokumenty wielojęzyczne?
Tak. OCR.net obsługuje ponad 60 języków. Wybierz docelowy język w interfejsie OCR.net lub wywołaniu API przed przetwarzaniem. IronPDF obsługuje natywnie wyjście UTF-8, dlatego języki z pismami niełacińskimi są renderowane poprawnie w zrekonstruowanym przeszukiwalnym PDF.
Jak monitorować wydajność linii przetwarzania OCR w produkcji?
Dodaj liczniki, histogramy i mierniki Prometheusa do swojego serwisu przetwarzającego, aby śledzić całkowitą liczbę żądań, rozkłady czasu trwania i aktywne zadania. Połącz metryki Prometheusa z niestandardowym logowaniem IronPDF, aby połączyć czasy renderowania z opóźnieniem API OCR i zidentyfikować miejsce występowania wąskich gardeł.
Jaka jest różnica między OCR.net a IronOCR?
OCR.net to zewnętrzna usługa webowa, która przetwarza obrazy, które przesyłasz za pomocą API. IronOCR jest biblioteką .NET od Iron Software, która przeprowadza przetwarzanie OCR lokalnie w twojej aplikacji bez zewnętrznych wywołań API. IronOCR jest lepiej dostosowany do środowisk offline lub gdy potrzebujesz niższych opóźnień i większej kontroli nad silnikiem OCR.














