
如何用OCR.net和IronPDF在C#中构建一个PDF OCR工作流程
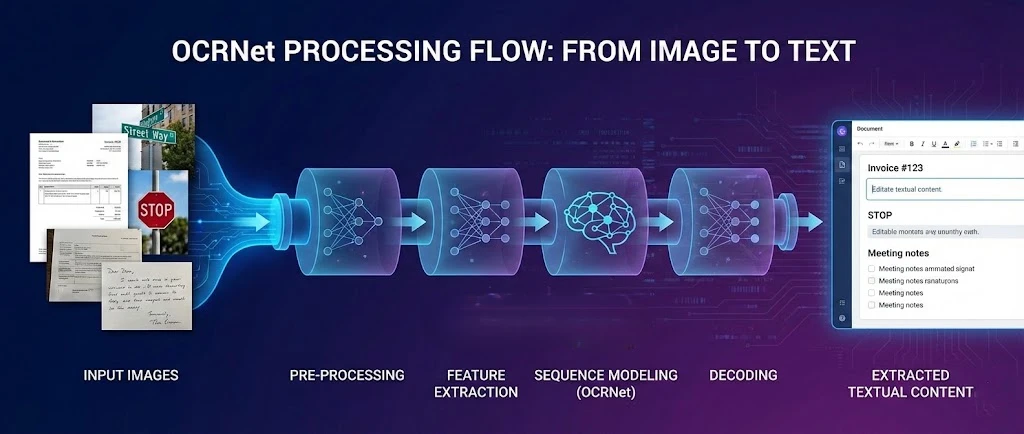
OCR.net 是一个用于光学字符识别的深度学习框架,它与 IronPDF 配合使用,可在 .NET Framework 应用程序中从 PDF 中提取文本并生成可搜索的文档。 本教程将向您展示如何连接这两款工具,使您的应用程序能够处理扫描文件、将 PDF 页面栅格化以进行 OCR 识别,并将识别出的文本重新组合成一个可搜索的新 PDF 文件。
OCR.net 模型在复杂环境下的场景文本检测和字符识别方面表现卓越。 当您将其与 IronPDF 的渲染引擎结合使用时,即可构建完整的处理流程:生成或加载 PDF 文件,将其页面导出为高分辨率图像,将这些图像发送至 OCR.net,并最终将处理结果重建为可全文检索的文档。
如何开始使用 IronPDF?
在构建 OCR 工作流之前,您需要在项目中安装 IronPDF。 最快捷的方式是使用 NuGet 包管理器控制台:
Install-Package IronPDF或者通过 NuGet 界面直接搜索 IronPdf 进行安装。 安装完成后,请在应用程序启动时输入您的许可证密钥:
using IronPdf;
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";using IronPdf;
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";Imports IronPdf
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY"提供免费试用许可证,您可以无限制地测试全部功能。 IronPDF 支持 Windows、Linux 和 macOS 平台上的 .NET 6、7、8 及 10 版本,这意味着相同的代码可在桌面应用程序、ASP.NET Core Web 服务以及容器化部署环境中运行。
针对 Docker 环境,IronPDF 提供预配置的 Linux 部署指南以及可缩小镜像大小的精简版包。若您更倾向于远程渲染架构,IronPDF Engine 可作为独立服务运行,其客户端可在任何受支持的平台上部署。
什么是 OCRNet,光学字符识别如何工作?
OCR.net 是一种基于深度学习的光学字符识别(OCR)技术,能够识别不同字体样式下的字母和数字。 该模型采用优化后的神经网络架构,用于从输入图像中提取空间特征。 结合 PDF 生成功能,这些经过训练的模型在常见文档类型上可提供高精度的识别结果。
OCR.net 背后的识别框架集成了门控循环单元(GRU),以增强特征学习能力并处理基于图像的序列识别任务。 这种混合模型通过联结主义时序分类(CTC)实现了显著的准确率,该技术最初用于序列标注,现已成功应用于文档OCR领域。 OCR.net 正在持续改进,不断扩展其语言支持范围,尤其是在与 PDF 文本提取工具集成时。
现代 OCR 管道的关键组件包括:
- 文本检测:利用训练好的模型识别图像中的文本内容区域
- 场景文本检测:在复杂背景和动态环境中定位文本
- 字母数字字符识别:利用训练好的模型以高验证精度识别字符
- 模式识别:应用图像处理技术实现轻量级场景文本识别
基于 GRU 的架构和联结主义时序分类机制,使 OCR.net 能够在容器化环境中高效利用资源,因此在内存和 CPU 资源受限的 Kubernetes 部署场景中,OCR.net 是一个实用的选择。 轻量级架构在保持高识别准确率的同时,确保 Docker 镜像大小处于可控范围。
何时应优先使用 OCR.net 而非传统 OCR 库?
在处理复杂场景文本、手写文档或多语言内容时,若基于模板的 OCR 无法胜任,OCR.net 将是更优的选择。 它在容器化应用程序中表现尤为出色,这类应用需要在不同硬件配置下保持一致的性能,且不依赖外部组件。 该模型能完美处理 UTF-8 编码,这对支持多语言至关重要。
传统的基于正则表达式或模板匹配的 OCR 系统在处理可变字体、手写内容或光线不均匀的图像时会失效。 OCR.net 的神经网络方法在这些场景中具有更强的泛化能力,因为它通过学习特征而非匹配固定模板来实现识别。 话虽如此,如果您的文档是格式统一、排版整洁的纯文本,使用更轻量级的库可能更快且已足够。
OCR.net 在生产环境中通常有哪些资源需求?
生产环境部署通常需要 2-4 个 CPU 核心和 4-8 GB 内存,以确保稳定的性能。 在采用 NVIDIA Docker 运行时的容器化环境中,GPU 加速可显著提升批处理速度。这些特性非常适合 Azure App Service 和 AWS Lambda 部署场景,但鉴于 Lambda 的内存上限限制,建议在正式部署前针对具体文档大小进行性能测试。
IronPDF 如何生成用于 OCR 处理的 PDF 文档?
IronPDF 让 .NET 开发人员能够完全掌控 PDF 的生成过程。 该库可以通过其基于 Chrome 的渲染引擎,将HTML 字符串、 URL和文件输入渲染成精美的 PDF 文件。对于 OCR 工作流程而言,关键功能是 RasterizeToImageFiles(),它可以将 PDF 页面导出为适合识别的高分辨率图像。
using IronPdf;
// Create a PDF document with IronPDF
var renderer = new ChromePdfRenderer();
// Set 300 DPI for OCR accuracy -- higher DPI preserves text sharpness
renderer.RenderingOptions.PaperSize = IronPdf.Rendering.PdfPaperSize.A4;
renderer.RenderingOptions.DPI = 300;
renderer.RenderingOptions.MarginTop = 50;
renderer.RenderingOptions.MarginBottom = 50;
var pdf = renderer.RenderHtmlAsPdf(@"
<h1>Document Report</h1>
<p>Scene text integration for computer vision analysis.</p>
<p>Text detection results for dataset and model analysis.</p>");
// Tag the document with searchable metadata
pdf.MetaData.Author = "OCR Processing Pipeline";
pdf.MetaData.Keywords = "OCR, Text Recognition, Computer Vision";
pdf.MetaData.ModifiedDate = DateTime.Now;
pdf.SaveAs("document-for-ocr.pdf");
// Export pages as PNG images for OCR.net -- 300 DPI is the recommended minimum
pdf.RasterizeToImageFiles("page-*.png", IronPdf.Imaging.ImageType.Png, 300);using IronPdf;
// Create a PDF document with IronPDF
var renderer = new ChromePdfRenderer();
// Set 300 DPI for OCR accuracy -- higher DPI preserves text sharpness
renderer.RenderingOptions.PaperSize = IronPdf.Rendering.PdfPaperSize.A4;
renderer.RenderingOptions.DPI = 300;
renderer.RenderingOptions.MarginTop = 50;
renderer.RenderingOptions.MarginBottom = 50;
var pdf = renderer.RenderHtmlAsPdf(@"
<h1>Document Report</h1>
<p>Scene text integration for computer vision analysis.</p>
<p>Text detection results for dataset and model analysis.</p>");
// Tag the document with searchable metadata
pdf.MetaData.Author = "OCR Processing Pipeline";
pdf.MetaData.Keywords = "OCR, Text Recognition, Computer Vision";
pdf.MetaData.ModifiedDate = DateTime.Now;
pdf.SaveAs("document-for-ocr.pdf");
// Export pages as PNG images for OCR.net -- 300 DPI is the recommended minimum
pdf.RasterizeToImageFiles("page-*.png", IronPdf.Imaging.ImageType.Png, 300);Imports IronPdf
' Create a PDF document with IronPDF
Dim renderer As New ChromePdfRenderer()
' Set 300 DPI for OCR accuracy -- higher DPI preserves text sharpness
renderer.RenderingOptions.PaperSize = IronPdf.Rendering.PdfPaperSize.A4
renderer.RenderingOptions.DPI = 300
renderer.RenderingOptions.MarginTop = 50
renderer.RenderingOptions.MarginBottom = 50
Dim pdf = renderer.RenderHtmlAsPdf("
<h1>Document Report</h1>
<p>Scene text integration for computer vision analysis.</p>
<p>Text detection results for dataset and model analysis.</p>")
' Tag the document with searchable metadata
pdf.MetaData.Author = "OCR Processing Pipeline"
pdf.MetaData.Keywords = "OCR, Text Recognition, Computer Vision"
pdf.MetaData.ModifiedDate = DateTime.Now
pdf.SaveAs("document-for-ocr.pdf")
' Export pages as PNG images for OCR.net -- 300 DPI is the recommended minimum
pdf.RasterizeToImageFiles("page-*.png", IronPdf.Imaging.ImageType.Png, 300)RasterizeToImageFiles() 方法将 PDF 页面转换为指定 DPI 的 PNG 图像。 在 300 DPI 分辨率下,文本边缘仍足够清晰,足以让 OCR 模型区分外观相似的字符。 在 150 DPI 或以下分辨率下,衬线字体和小字体的识别准确率会明显下降。 导出后,请将 PNG 文件上传至 OCR.net 或直接传入本地模型。

为什么 DPI 设置会影响 OCR 准确率?
较高的 DPI 设置(300-600)能保持文本清晰度,这是 OCR 模型准确识别字符所必需的。 权衡点在于文件大小与处理时间。在 300 DPI 分辨率下,单张 A4 页面生成的 PNG 文件大小约为 2-3 MB。 在 600 DPI 分辨率下,文件大小将增至 8-12 MB。 对于大多数文档而言,300 DPI 是最佳平衡点。 渲染选项允许您根据文档类型进行调整,而压缩技术则有助于在 OCR 完成后优化文件大小。
IronPDF 如何处理容器化环境?
IronPDF 的原生引擎确保在 Linux、Windows 和 macOS 容器中实现一致的渲染效果。 对于高可用性服务,IronPDF 可与 .NET Core 健康检查端点集成,从而允许您实现就绪性和在线性探针,在将流量路由至容器实例之前,验证 PDF 渲染功能是否正常运行。
using IronPdf;
// Kubernetes-compatible health check endpoint
var builder = WebApplication.CreateBuilder(args);
var app = builder.Build();
app.MapGet("/health/ready", async () =>
{
try
{
var renderer = new ChromePdfRenderer();
var testPdf = await renderer.RenderHtmlAsPdfAsync("<p>Health check</p>");
return testPdf.PageCount > 0 ? Results.Ok() : Results.Problem();
}
catch
{
return Results.Problem("PDF rendering unavailable");
}
});
await app.RunAsync();using IronPdf;
// Kubernetes-compatible health check endpoint
var builder = WebApplication.CreateBuilder(args);
var app = builder.Build();
app.MapGet("/health/ready", async () =>
{
try
{
var renderer = new ChromePdfRenderer();
var testPdf = await renderer.RenderHtmlAsPdfAsync("<p>Health check</p>");
return testPdf.PageCount > 0 ? Results.Ok() : Results.Problem();
}
catch
{
return Results.Problem("PDF rendering unavailable");
}
});
await app.RunAsync();Imports IronPdf
' Kubernetes-compatible health check endpoint
Dim builder = WebApplication.CreateBuilder(args)
Dim app = builder.Build()
app.MapGet("/health/ready", Async Function()
Try
Dim renderer = New ChromePdfRenderer()
Dim testPdf = Await renderer.RenderHtmlAsPdfAsync("<p>Health check</p>")
Return If(testPdf.PageCount > 0, Results.Ok(), Results.Problem())
Catch
Return Results.Problem("PDF rendering unavailable")
End Try
End Function)
Await app.RunAsync()请配合此端点使用自定义日志记录功能,以捕获渲染时间,并在容器完全故障前识别出性能下降的容器。
OCR.net 如何从 PDF 图像中提取文本?
从 IronPDF 导出 PNG 文件后,将其上传至 OCR.net 进行文本识别。 OCR.net 处理管道可处理图像,并针对各种字体样式返回标准化文本输出。 它既能处理打印文本,也能识别手写文本,并支持 60 多种文档语言。
使用 OCR.net 在线:
1.导航至 https://ocr.net/
- 上传从 IronPDF 导出的 PNG 或 JPG 图片(最大 2 MB)
- 从 60 多种可用选项中选择文档语言
- 选择输出格式:纯文本或可搜索 PDF
- 点击"立即转换"以使用 OCR.net 模型处理图像
OCR.net 网页界面显示文件上传页面 page-1.png,语言设置为英语,输出格式设置为文本。
OCR.net 还提供用于自动化处理的 API。 免费账户每小时限额 50 次请求,这对自动化管道而言是一个关键限制。 设计您的集成方案时,应采用指数退避机制优雅地处理速率限制响应,而非直接报错:
using System;
using System.Net.Http;
using System.Threading.Tasks;
// Queue-based OCR processing with exponential backoff retry
async Task<string> ProcessOcrWithRetry(string imagePath, int maxRetries = 3)
{
for (int attempt = 0; attempt < maxRetries; attempt++)
{
try
{
// Replace with your actual OCR.net API call
return await CallOcrNetApi(imagePath);
}
catch (HttpRequestException ex) when (ex.Message.Contains("429"))
{
if (attempt == maxRetries - 1) throw;
var delay = TimeSpan.FromSeconds(Math.Pow(2, attempt));
await Task.Delay(delay);
}
}
throw new InvalidOperationException("OCR processing failed after all retries");
}using System;
using System.Net.Http;
using System.Threading.Tasks;
// Queue-based OCR processing with exponential backoff retry
async Task<string> ProcessOcrWithRetry(string imagePath, int maxRetries = 3)
{
for (int attempt = 0; attempt < maxRetries; attempt++)
{
try
{
// Replace with your actual OCR.net API call
return await CallOcrNetApi(imagePath);
}
catch (HttpRequestException ex) when (ex.Message.Contains("429"))
{
if (attempt == maxRetries - 1) throw;
var delay = TimeSpan.FromSeconds(Math.Pow(2, attempt));
await Task.Delay(delay);
}
}
throw new InvalidOperationException("OCR processing failed after all retries");
}Imports System
Imports System.Net.Http
Imports System.Threading.Tasks
' Queue-based OCR processing with exponential backoff retry
Async Function ProcessOcrWithRetry(imagePath As String, Optional maxRetries As Integer = 3) As Task(Of String)
For attempt As Integer = 0 To maxRetries - 1
Try
' Replace with your actual OCR.net API call
Return Await CallOcrNetApi(imagePath)
Catch ex As HttpRequestException When ex.Message.Contains("429")
If attempt = maxRetries - 1 Then Throw
Dim delay As TimeSpan = TimeSpan.FromSeconds(Math.Pow(2, attempt))
Await Task.Delay(delay)
End Try
Next
Throw New InvalidOperationException("OCR processing failed after all retries")
End Function在无障碍工作流程中,OCR 文本提取功能使视障用户能够从原本仅为图像的文档中获取语音反馈。 通过将 OCR.net 的输出与 IronPDF 的 PDF/UA 合规性相结合,可生成辅助技术能够有效导航的文档。
如何构建完整的 IronPDF 和 OCR.net 工作流?
将 IronPDF 与 OCR.net 结合使用,可提供端到端的文档解决方案。 该工作流包含三个阶段:将 PDF 页面导出为图像,将图像发送至 OCR.net 进行文本提取,并将识别出的文本重组为新的可搜索 PDF。
using IronPdf;
using System;
using System.Collections.Generic;
using System.Net.Http;
using System.Text;
using System.Threading.Tasks;
// --- Stage 1: Export PDF pages as images for OCR ---
var scannedPdf = PdfDocument.FromFile("input-document.pdf");
var imageFiles = scannedPdf.RasterizeToImageFiles(
"scan-page-{0}.png",
IronPdf.Imaging.ImageType.Png,
300 // 300 DPI -- minimum for reliable OCR accuracy
);
// --- Stage 2: Process each image through OCR.net ---
var ocrResults = new List<string>();
foreach (var imageFile in imageFiles)
{
// Replace this placeholder with your actual OCR.net API integration
string ocrText = await SendImageToOcrNet(imageFile);
ocrResults.Add(ocrText);
}
// --- Stage 3: Reassemble recognized text as a searchable PDF ---
var htmlBuilder = new StringBuilder();
htmlBuilder.Append(@"<!DOCTYPE html><html><head>
<style>body{font-family:Arial,sans-serif;margin:40px;}
.page{page-break-after:always;} pre{white-space:pre-wrap;}</style>
</head><body>");
for (int i = 0; i < ocrResults.Count; i++)
{
htmlBuilder.AppendFormat(
"<div class='page'><h2>Page {0}</h2><pre>{1}</pre></div>",
i + 1,
System.Web.HttpUtility.HtmlEncode(ocrResults[i])
);
}
htmlBuilder.Append("</body></html>");
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.DPI = 300;
renderer.RenderingOptions.EnableJavaScript = false;
var searchablePdf = await renderer.RenderHtmlAsPdfAsync(htmlBuilder.ToString());
searchablePdf.MetaData.Title = "OCR Processed Document";
searchablePdf.MetaData.Subject = "Searchable PDF from OCR";
searchablePdf.MetaData.CreationDate = DateTime.UtcNow;
searchablePdf.SecuritySettings.AllowUserPrinting = true;
searchablePdf.SecuritySettings.AllowUserCopyPasteContent = true;
searchablePdf.SaveAs("searchable-document.pdf");using IronPdf;
using System;
using System.Collections.Generic;
using System.Net.Http;
using System.Text;
using System.Threading.Tasks;
// --- Stage 1: Export PDF pages as images for OCR ---
var scannedPdf = PdfDocument.FromFile("input-document.pdf");
var imageFiles = scannedPdf.RasterizeToImageFiles(
"scan-page-{0}.png",
IronPdf.Imaging.ImageType.Png,
300 // 300 DPI -- minimum for reliable OCR accuracy
);
// --- Stage 2: Process each image through OCR.net ---
var ocrResults = new List<string>();
foreach (var imageFile in imageFiles)
{
// Replace this placeholder with your actual OCR.net API integration
string ocrText = await SendImageToOcrNet(imageFile);
ocrResults.Add(ocrText);
}
// --- Stage 3: Reassemble recognized text as a searchable PDF ---
var htmlBuilder = new StringBuilder();
htmlBuilder.Append(@"<!DOCTYPE html><html><head>
<style>body{font-family:Arial,sans-serif;margin:40px;}
.page{page-break-after:always;} pre{white-space:pre-wrap;}</style>
</head><body>");
for (int i = 0; i < ocrResults.Count; i++)
{
htmlBuilder.AppendFormat(
"<div class='page'><h2>Page {0}</h2><pre>{1}</pre></div>",
i + 1,
System.Web.HttpUtility.HtmlEncode(ocrResults[i])
);
}
htmlBuilder.Append("</body></html>");
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.DPI = 300;
renderer.RenderingOptions.EnableJavaScript = false;
var searchablePdf = await renderer.RenderHtmlAsPdfAsync(htmlBuilder.ToString());
searchablePdf.MetaData.Title = "OCR Processed Document";
searchablePdf.MetaData.Subject = "Searchable PDF from OCR";
searchablePdf.MetaData.CreationDate = DateTime.UtcNow;
searchablePdf.SecuritySettings.AllowUserPrinting = true;
searchablePdf.SecuritySettings.AllowUserCopyPasteContent = true;
searchablePdf.SaveAs("searchable-document.pdf");Imports IronPdf
Imports System
Imports System.Collections.Generic
Imports System.Net.Http
Imports System.Text
Imports System.Threading.Tasks
' --- Stage 1: Export PDF pages as images for OCR ---
Dim scannedPdf = PdfDocument.FromFile("input-document.pdf")
Dim imageFiles = scannedPdf.RasterizeToImageFiles(
"scan-page-{0}.png",
IronPdf.Imaging.ImageType.Png,
300 ' 300 DPI -- minimum for reliable OCR accuracy
)
' --- Stage 2: Process each image through OCR.net ---
Dim ocrResults As New List(Of String)()
For Each imageFile In imageFiles
' Replace this placeholder with your actual OCR.net API integration
Dim ocrText As String = Await SendImageToOcrNet(imageFile)
ocrResults.Add(ocrText)
Next
' --- Stage 3: Reassemble recognized text as a searchable PDF ---
Dim htmlBuilder As New StringBuilder()
htmlBuilder.Append("<!DOCTYPE html><html><head>
<style>body{font-family:Arial,sans-serif;margin:40px;}
.page{page-break-after:always;} pre{white-space:pre-wrap;}</style>
</head><body>")
For i As Integer = 0 To ocrResults.Count - 1
htmlBuilder.AppendFormat(
"<div class='page'><h2>Page {0}</h2><pre>{1}</pre></div>",
i + 1,
System.Web.HttpUtility.HtmlEncode(ocrResults(i))
)
Next
htmlBuilder.Append("</body></html>")
Dim renderer As New ChromePdfRenderer()
renderer.RenderingOptions.DPI = 300
renderer.RenderingOptions.EnableJavaScript = False
Dim searchablePdf = Await renderer.RenderHtmlAsPdfAsync(htmlBuilder.ToString())
searchablePdf.MetaData.Title = "OCR Processed Document"
searchablePdf.MetaData.Subject = "Searchable PDF from OCR"
searchablePdf.MetaData.CreationDate = DateTime.UtcNow
searchablePdf.SecuritySettings.AllowUserPrinting = True
searchablePdf.SecuritySettings.AllowUserCopyPasteContent = True
searchablePdf.SaveAs("searchable-document.pdf")此流程设计上力求简洁明了。 第一阶段生成编号的 PNG 文件。 第二阶段将每个文件发送至 OCR.net,并收集返回的文本字符串。 第三阶段将这些字符串封装在 HTML 中,并使用 IronPDF 生成最终的 PDF 文件,其中文本可被完全选中并支持搜索。 您可以扩展第三阶段,应用 PDF 元数据进行文档管理,或应用访问控制的安全设置。
!屏幕截图并排比较了两个 PDF 查看器窗口 - 左侧显示的是关于"什么是 PDF?"的扫描 PDF,右侧显示的是 OCR.net 成功提取相同文本内容的结果。
对于此工作流,哪种 Docker 配置效果最佳?
多阶段 Docker 构建可在包含 IronPDF 在 Linux 环境下所需的所有运行时依赖项的同时,保持最终镜像的体积小巧:
FROM mcr.microsoft.com/dotnet/sdk:8.0 AS build
WORKDIR /app
COPY *.csproj ./
RUN dotnet restore
COPY . ./
RUN dotnet publish -c Release -o out
FROM mcr.microsoft.com/dotnet/aspnet:8.0
WORKDIR /app
# IronPDF Linux runtime dependencies
RUN apt-get update && apt-get install -y \
libgdiplus \
libc6-dev \
libx11-dev \
&& rm -rf /var/lib/apt/lists/*
COPY --from=build /app/out .
HEALTHCHECK --interval=30s --timeout=3s --start-period=5s --retries=3 \
CMD curl -f http://localhost:8080/health/ready || exit 1
ENTRYPOINT ["dotnet", "OcrWorkflow.dll"]对于生产级应用,建议使用 Kubernetes Jobs 进行批量 OCR 操作。 Kubernetes Jobs 提供自动重试、并行控制和资源隔离功能,确保失败的文档任务不会影响其他服务。 设置 parallelism 以匹配您的 OCR.net API 层,并设置 backoffLimit 以控制失败的 pod 在 Job 将任务标记为失败之前重试的次数。
如何监控生产环境中的性能指标?
追踪 OCR 处理时间和成功率有助于在影响最终用户之前识别瓶颈。 使用自定义指标的 Prometheus 是一种切实可行的方案:
using Prometheus;
using System;
using System.Threading.Tasks;
// Prometheus metrics for OCR pipeline observability
var ocrRequestsTotal = Metrics
.CreateCounter("ocr_requests_total", "Total OCR requests processed");
var ocrDuration = Metrics
.CreateHistogram("ocr_duration_seconds", "OCR processing duration in seconds",
new HistogramConfiguration
{
Buckets = Histogram.LinearBuckets(0.1, 0.1, 10)
});
var activeOcrJobs = Metrics
.CreateGauge("ocr_active_jobs", "Currently active OCR jobs");
// Wrapper that tracks every OCR operation automatically
async Task<t> TrackOcrOperation<t>(Func<Task<t>> operation)
{
using (ocrDuration.NewTimer())
{
activeOcrJobs.Inc();
try
{
var result = await operation();
ocrRequestsTotal.Inc();
return result;
}
finally
{
activeOcrJobs.Dec();
}
}
}using Prometheus;
using System;
using System.Threading.Tasks;
// Prometheus metrics for OCR pipeline observability
var ocrRequestsTotal = Metrics
.CreateCounter("ocr_requests_total", "Total OCR requests processed");
var ocrDuration = Metrics
.CreateHistogram("ocr_duration_seconds", "OCR processing duration in seconds",
new HistogramConfiguration
{
Buckets = Histogram.LinearBuckets(0.1, 0.1, 10)
});
var activeOcrJobs = Metrics
.CreateGauge("ocr_active_jobs", "Currently active OCR jobs");
// Wrapper that tracks every OCR operation automatically
async Task<t> TrackOcrOperation<t>(Func<Task<t>> operation)
{
using (ocrDuration.NewTimer())
{
activeOcrJobs.Inc();
try
{
var result = await operation();
ocrRequestsTotal.Inc();
return result;
}
finally
{
activeOcrJobs.Dec();
}
}
}Imports Prometheus
Imports System
Imports System.Threading.Tasks
' Prometheus metrics for OCR pipeline observability
Dim ocrRequestsTotal = Metrics.CreateCounter("ocr_requests_total", "Total OCR requests processed")
Dim ocrDuration = Metrics.CreateHistogram("ocr_duration_seconds", "OCR processing duration in seconds",
New HistogramConfiguration With {
.Buckets = Histogram.LinearBuckets(0.1, 0.1, 10)
})
Dim activeOcrJobs = Metrics.CreateGauge("ocr_active_jobs", "Currently active OCR jobs")
' Wrapper that tracks every OCR operation automatically
Async Function TrackOcrOperation(Of T)(operation As Func(Of Task(Of T))) As Task(Of T)
Using ocrDuration.NewTimer()
activeOcrJobs.Inc()
Try
Dim result = Await operation()
ocrRequestsTotal.Inc()
Return result
Finally
activeOcrJobs.Dec()
End Try
End Using
End Function将这些指标与 IronPDF 的日志记录功能结合使用,以关联渲染时间与 OCR 处理时长。 当 OCR 耗时骤增而渲染时间未相应增加时,瓶颈在于 OCR.net API 调用或您连接该 API 的网络路径,而非 PDF 生成步骤。
下一步计划是什么?
OCR.net 与 IronPDF 的结合,为您在 .NET 环境中提供了实现文本提取和生成可搜索 PDF 的实用方案。 该流程涵盖核心用例:将 HTML 转换为 PDF、以支持 OCR 的分辨率导出页面、将图像发送至 OCR.net,以及将处理结果重组为可全文检索的文档。
部署至生产环境时的关键注意事项:
- 容器配置:使用 IronPDF Slim 包和多阶段 Docker 构建,以确保镜像大小处于可控范围
- 资源规划:根据文档大小和并发目标配置合适的内存限制
- 监控:结合 Prometheus 指标与 IronPDF 日志功能,以便尽早发现性能下降
- 吞吐量:利用异步操作和批处理队列管理,在 OCR.net 的速率限制范围内进行处理
- 可靠性:围绕 OCR.net API 调用构建指数退避重试逻辑和断路器
建议先使用免费试用许可证,在决定购买正式许可证之前,全面测试整个工作流。 试用版将移除水印并解锁所有功能,因此您的基准测试结果能准确反映实际生产环境中的表现。 准备部署时,请查看 IronPDF 的许可选项,选择与您的使用模式相匹配的许可层级。
常见问题解答
OCR.net有什么作用,以及它如何与IronPDF连接?
OCR.net是一个深度学习OCR服务,接受图像输入并返回识别的文本。IronPDF生成PDF并将其页面导出为图像。这两个工具在图像层连接:IronPDF通过RasterizeToImageFiles()导出页面,这些图像用于OCR.net进行文本提取,然后IronPDF将结果重新组装为可搜索的PDF。
导出PDF页面以进行OCR时应使用哪种DPI?
300 DPI是可靠OCR准确性的标准最低值。在300 DPI时,文本边缘足够清晰以便模型区分相似字符。在150 DPI或以下,准确性在衬线字体和小字上下降。仅当源文档包含非常小或退化的文本时才使用600 DPI,因为600 DPI下每页生成的文件大小要大4-5倍。
在生产中如何处理OCR.net API速率限制?
OCR.net免费账户每小时允许50次请求。在您的OCR调用中构建指数退避重试逻辑:捕获429响应,等待Math.Pow(2, attempt)秒,然后重试直到配置的最大次数。为了更高的吞吐量,升级到付费的OCR.net计划或使用后台工作服务排队请求。
IronPDF可以在Linux的Docker容器内运行吗?
可以。在您的Dockerfile的运行时阶段添加libgdiplus、libc6-dev和libx11-dev。使用多阶段构建以保持最终映像小。IronPDF Slim包变体通过在您将IronPDF Engine作为单独的服务运行时排除捆绑的浏览器二进制文件进一步减小映像大小。
如何从OCR结果创建可搜索的PDF?
收集OCR.net返回的文本字符串,用每个文档页面一个换页类将它们包装在HTML中,然后将HTML传递给ChromePdfRenderer.RenderHtmlAsPdfAsync()。生成的PDF包含用户和搜索引擎可以索引的可选择和可搜索的文本。
此工作流程支持多语言文档吗?
支持。OCR.net支持60多种语言。在处理前在OCR.net界面或API调用中选择目标语言。IronPDF原生支持UTF-8输出,因此使用非拉丁文的语言在重建的可搜索PDF中正确呈现。
在生产中如何监控OCR管道性能?
为您的处理服务添加Prometheus计数器、直方图和仪表盘,以跟踪总请求、持续时间分布和活动作业。将Prometheus指标与IronPDF的自定义日志记录配对,以关联渲染时间与OCR API延迟,并识别瓶颈所在。
OCR.net与IronOCR的区别是什么?
OCR.net是一个外部Web服务,处理您通过API上传的图像。IronOCR是Iron Software的.NET库,在您的应用程序中本地运行OCR处理,无需外部API调用。IronOCR更适合离线环境,或者当您需要更低的延迟和对OCR引擎的更多控制时。













