
Adicionar cabeçalho e rodapé em PDF usando iTextSharp e IronPDF em C# com exemplo
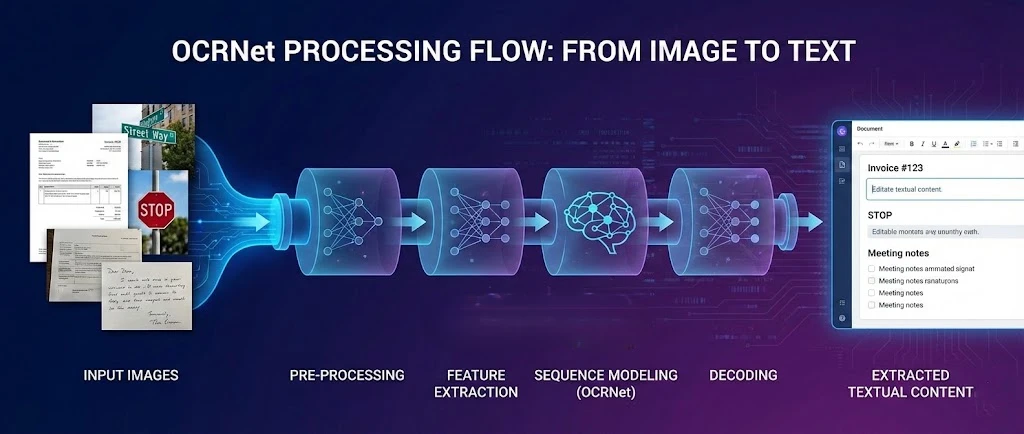
O OCR .NET é uma estrutura de aprendizado profundo para reconhecimento óptico de caracteres que funciona em conjunto com o IronPDF para extrair texto de PDFs e produzir documentos pesquisáveis em aplicativos .NET . Este tutorial mostra como conectar essas duas ferramentas para que seu aplicativo possa processar arquivos digitalizados, rasterizar páginas PDF para OCR e remontar o texto reconhecido em um novo PDF pesquisável.
O modelo OCR .NET se destaca na detecção de texto em cenas e no reconhecimento de caracteres em ambientes complexos. Ao combiná-lo com o mecanismo de renderização do IronPDF, você obtém um fluxo de trabalho completo: gerar ou carregar um PDF, exportar suas páginas como imagens de alta resolução, enviar essas imagens para o OCR .NET e reconstruir os resultados como um documento totalmente pesquisável.
Como começar a usar o IronPDF?
Antes de criar o fluxo de trabalho de OCR, você precisa ter o IronPDF instalado em seu projeto. O caminho mais rápido é o console do Gerenciador de Pacotes NuGet :
Install-Package IronPdf
Ou adicione diretamente através da interface do NuGet procurando por IronPDF. Após a instalação, aplique sua chave de licença na inicialização do aplicativo:
using IronPdf;
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";using IronPdf;
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";Imports IronPdf
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY"Está disponível uma licença de avaliação gratuita para que você possa testar todos os recursos sem restrições. O IronPDF é compatível com .NET 6, 7, 8 e 10 no Windows, Linux e macOS, o que significa que o mesmo código funciona em aplicativos de desktop, serviços web ASP.NET Core e implantações em contêineres.
Para ambientes Docker, o IronPDF oferece um guia de implantação Linux pré-configurado e versões de pacotes compactos que reduzem o tamanho da imagem. Se preferir uma arquitetura de renderização remota, o IronPDF Engine pode ser executado como um serviço separado com clientes em qualquer plataforma compatível.
O que é o OCRNet e como funciona o reconhecimento óptico de caracteres?
O OCR .NET é uma abordagem de aprendizado profundo para reconhecimento óptico de caracteres (OCR) que reconhece caracteres alfanuméricos em diferentes estilos de fonte. O modelo utiliza uma arquitetura de rede neural otimizada para capturar características espaciais de imagens de entrada. Combinados com recursos de geração de PDF , esses modelos treinados oferecem reconhecimento com alta precisão em tipos de documentos comuns.
A estrutura de reconhecimento por trás do OCR .NET incorpora uma Unidade Recorrente com Portão (GRU, na sigla em inglês) para aprimorar o aprendizado de características e processar tarefas de reconhecimento de sequências baseadas em imagens. Este modelo híbrido alcança uma precisão notável através da classificação temporal conexionista (CTC), uma técnica originalmente introduzida para rotulagem de sequências que se adapta bem ao OCR de documentos. As melhorias contínuas expandem ainda mais o suporte a idiomas do OCR.net, especialmente quando integrado a ferramentas de extração de texto de PDF .
Os principais componentes de um pipeline OCR moderno incluem:
- Detecção de texto: Identificação de regiões com conteúdo textual em uma imagem usando modelos treinados.
- Detecção de texto em cenas: localização de texto em fundos complexos e ambientes dinâmicos.
- Reconhecimento de caracteres alfanuméricos: Utilizando modelos treinados para reconhecer caracteres com alta precisão de validação.
- Reconhecimento de padrões: Aplicando técnicas de processamento de imagem para reconhecimento de texto em cenas leves
A arquitetura baseada em GRU e a classificação temporal conexionista permitem o uso eficiente de recursos em ambientes conteinerizados, tornando o OCR .NET uma escolha prática para implantações em Kubernetes onde as restrições de memória e CPU são importantes. A arquitetura leve mantém os tamanhos das imagens Docker gerenciáveis, ao mesmo tempo que preserva uma alta precisão de reconhecimento.
Quando você deve usar o OCR .NET em vez das bibliotecas OCR tradicionais?
O OCR .NET é a melhor opção para processar textos complexos em cenas, documentos manuscritos ou conteúdo multilíngue, situações em que o OCR baseado em modelos falha. Ele apresenta um desempenho particularmente bom em aplicações conteinerizadas que necessitam de desempenho consistente em diferentes configurações de hardware, sem dependências externas. O modelo lida com a codificação UTF-8 de forma limpa, o que é importante para o suporte a idiomas internacionais .
Os sistemas tradicionais de OCR baseados em expressões regulares ou em correspondência de modelos falham em fontes variáveis, escrita à mão ou imagens com iluminação irregular. A abordagem neural do OCR.net generaliza melhor nesses cenários porque aprende características em vez de corresponder a modelos fixos. Dito isso, se seus documentos forem textos limpos, digitados por máquina e com formatação consistente, uma biblioteca mais leve pode ser mais rápida e suficiente.
Quais são os requisitos de recursos comuns para OCR .NET em produção?
Em ambientes de produção, normalmente são necessários de 2 a 4 núcleos de CPU e de 4 a 8 GB de RAM para um desempenho sólido. A aceleração por GPU proporciona um aumento significativo de velocidade no processamento em lote em ambientes conteinerizados usando o runtime NVIDIA Docker. Esses requisitos se encaixam bem com as implantações do Azure App Service e do AWS Lambda , embora o limite de memória do Lambda signifique que você deve avaliar o tamanho específico dos seus documentos antes de confirmar a implementação.
Como o IronPDF cria documentos PDF para processamento OCR?
O IronPDF oferece aos desenvolvedores .NET controle total sobre a geração de PDFs. A biblioteca pode renderizar strings HTML, URLs e entradas de arquivos em PDFs refinados através de seu mecanismo de renderização baseado no Chrome. Para fluxos de trabalho OCR, o recurso crítico é RasterizeToImageFiles(), que exporta páginas PDF como imagens de alta resolução adequadas para reconhecimento.
using IronPdf;
// Create a PDF document with IronPDF
var renderer = new ChromePdfRenderer();
// Set 300 DPI for OCR accuracy -- higher DPI preserves text sharpness
renderer.RenderingOptions.PaperSize = IronPdf.Rendering.PdfPaperSize.A4;
renderer.RenderingOptions.DPI = 300;
renderer.RenderingOptions.MarginTop = 50;
renderer.RenderingOptions.MarginBottom = 50;
var pdf = renderer.RenderHtmlAsPdf(@"
<h1>Document Report</h1>
<p>Scene text integration for computer vision analysis.</p>
<p>Text detection results for dataset and model analysis.</p>");
// Tag the document with searchable metadata
pdf.MetaData.Author = "OCR Processing Pipeline";
pdf.MetaData.Keywords = "OCR, Text Recognition, Computer Vision";
pdf.MetaData.ModifiedDate = DateTime.Now;
pdf.SaveAs("document-for-ocr.pdf");
// Export pages as PNG images for OCR.net -- 300 DPI is the recommended minimum
pdf.RasterizeToImageFiles("page-*.png", IronPdf.Imaging.ImageType.Png, 300);using IronPdf;
// Create a PDF document with IronPDF
var renderer = new ChromePdfRenderer();
// Set 300 DPI for OCR accuracy -- higher DPI preserves text sharpness
renderer.RenderingOptions.PaperSize = IronPdf.Rendering.PdfPaperSize.A4;
renderer.RenderingOptions.DPI = 300;
renderer.RenderingOptions.MarginTop = 50;
renderer.RenderingOptions.MarginBottom = 50;
var pdf = renderer.RenderHtmlAsPdf(@"
<h1>Document Report</h1>
<p>Scene text integration for computer vision analysis.</p>
<p>Text detection results for dataset and model analysis.</p>");
// Tag the document with searchable metadata
pdf.MetaData.Author = "OCR Processing Pipeline";
pdf.MetaData.Keywords = "OCR, Text Recognition, Computer Vision";
pdf.MetaData.ModifiedDate = DateTime.Now;
pdf.SaveAs("document-for-ocr.pdf");
// Export pages as PNG images for OCR.net -- 300 DPI is the recommended minimum
pdf.RasterizeToImageFiles("page-*.png", IronPdf.Imaging.ImageType.Png, 300);Imports IronPdf
' Create a PDF document with IronPDF
Dim renderer As New ChromePdfRenderer()
' Set 300 DPI for OCR accuracy -- higher DPI preserves text sharpness
renderer.RenderingOptions.PaperSize = IronPdf.Rendering.PdfPaperSize.A4
renderer.RenderingOptions.DPI = 300
renderer.RenderingOptions.MarginTop = 50
renderer.RenderingOptions.MarginBottom = 50
Dim pdf = renderer.RenderHtmlAsPdf("
<h1>Document Report</h1>
<p>Scene text integration for computer vision analysis.</p>
<p>Text detection results for dataset and model analysis.</p>")
' Tag the document with searchable metadata
pdf.MetaData.Author = "OCR Processing Pipeline"
pdf.MetaData.Keywords = "OCR, Text Recognition, Computer Vision"
pdf.MetaData.ModifiedDate = DateTime.Now
pdf.SaveAs("document-for-ocr.pdf")
' Export pages as PNG images for OCR.net -- 300 DPI is the recommended minimum
pdf.RasterizeToImageFiles("page-*.png", IronPdf.Imaging.ImageType.Png, 300)O método RasterizeToImageFiles() converte páginas PDF em imagens PNG na DPI especificada. Com 300 DPI, as bordas do texto permanecem nítidas o suficiente para que o modelo de OCR distinga caracteres de aparência semelhante. Com resolução de 150 DPI ou inferior, a precisão do reconhecimento diminui consideravelmente em fontes serifadas e letras pequenas. Após a exportação, carregue os arquivos PNG no OCR .NET ou passe-os diretamente para um modelo local.

Por que a configuração de DPI afeta a precisão do OCR?
Configurações de DPI mais altas (300-600) preservam a nitidez do texto que o modelo de OCR precisa para distinguir os caracteres com precisão. A desvantagem reside no tamanho do arquivo e no tempo de processamento. A 300 DPI, uma única página A4 gera um PNG de aproximadamente 2 a 3 MB. A 600 DPI, esse tamanho aumenta para 8-12 MB. Para a maioria dos documentos, 300 DPI é o equilíbrio ideal. As opções de renderização permitem ajustar isso para cada tipo de documento, enquanto as técnicas de compressão ajudam a otimizar o tamanho dos arquivos após a conclusão do OCR.
Como o IronPDF lida com ambientes conteinerizados?
O mecanismo nativo do IronPDF garante uma renderização consistente em contêineres Linux , Windows e macOS . Para serviços de alta disponibilidade, o IronPDF se integra aos endpoints de verificação de integridade do ASP.NET Core , permitindo implementar sondagens de prontidão e atividade que verificam se a renderização de PDF está operacional antes de rotear o tráfego para uma instância de contêiner.
using IronPdf;
// Kubernetes-compatible health check endpoint
var builder = WebApplication.CreateBuilder(args);
var app = builder.Build();
app.MapGet("/health/ready", async () =>
{
try
{
var renderer = new ChromePdfRenderer();
var testPdf = await renderer.RenderHtmlAsPdfAsync("<p>Health check</p>");
return testPdf.PageCount > 0 ? Results.Ok() : Results.Problem();
}
catch
{
return Results.Problem("PDF rendering unavailable");
}
});
await app.RunAsync();using IronPdf;
// Kubernetes-compatible health check endpoint
var builder = WebApplication.CreateBuilder(args);
var app = builder.Build();
app.MapGet("/health/ready", async () =>
{
try
{
var renderer = new ChromePdfRenderer();
var testPdf = await renderer.RenderHtmlAsPdfAsync("<p>Health check</p>");
return testPdf.PageCount > 0 ? Results.Ok() : Results.Problem();
}
catch
{
return Results.Problem("PDF rendering unavailable");
}
});
await app.RunAsync();Imports IronPdf
' Kubernetes-compatible health check endpoint
Dim builder = WebApplication.CreateBuilder(args)
Dim app = builder.Build()
app.MapGet("/health/ready", Async Function()
Try
Dim renderer = New ChromePdfRenderer()
Dim testPdf = Await renderer.RenderHtmlAsPdfAsync("<p>Health check</p>")
Return If(testPdf.PageCount > 0, Results.Ok(), Results.Problem())
Catch
Return Results.Problem("PDF rendering unavailable")
End Try
End Function)
Await app.RunAsync()Utilize o registro personalizado em conjunto com este endpoint para capturar os tempos de renderização e identificar contêineres que estejam apresentando degradação antes que falhem completamente.
Como o OCR .NET extrai texto de imagens PDF?
Depois de exportar os arquivos PNG do IronPDF, você os carrega no .NET para reconhecimento de texto. O pipeline OCR .NET processa imagens e retorna texto normalizado em vários estilos de fonte. Ele processa textos impressos e manuscritos e suporta mais de 60 idiomas de documentos.
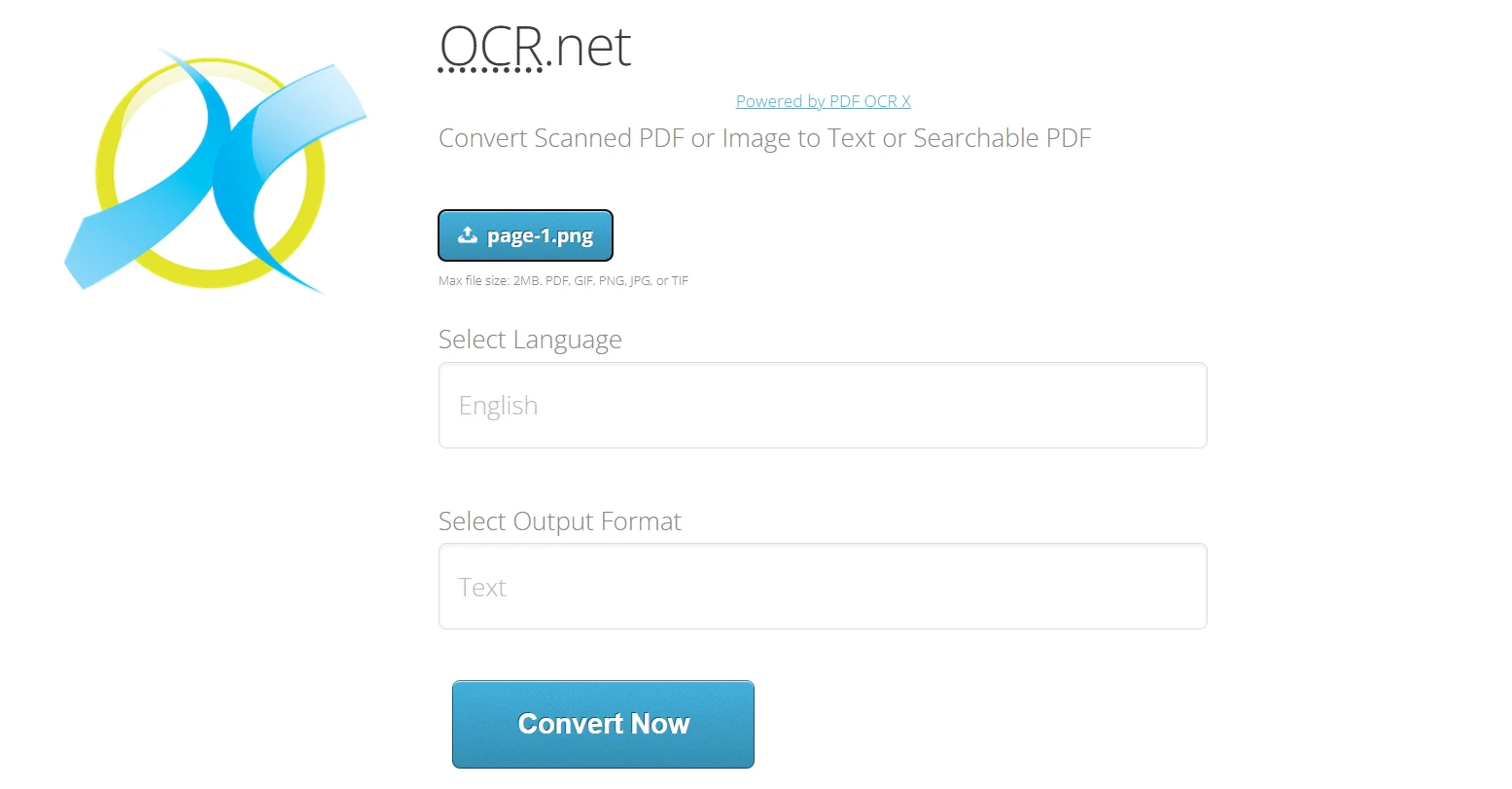
Utilizando o OCR .NET Online:
- Navegue atéhttps://ocr.net/
- Carregue a imagem PNG ou JPG (máximo de 2 MB) exportada doIronPDF.
- Selecione o idioma do documento dentre as mais de 60 opções disponíveis.
- Escolha o formato de saída: texto simples ou PDF pesquisável
- Clique em "Converter agora" para processar a imagem com modelos OCR .NET.
O OCR .NET também fornece uma API para processamento automatizado. As contas gratuitas são limitadas a 50 solicitações por hora, o que é uma restrição crítica para pipelines automatizados. Projete sua integração para lidar com respostas de limite de taxa de forma elegante, com recuo exponencial, em vez de falhar abruptamente:
using System;
using System.Net.Http;
using System.Threading.Tasks;
// Queue-based OCR processing with exponential backoff retry
async Task<string> ProcessOcrWithRetry(string imagePath, int maxRetries = 3)
{
for (int attempt = 0; attempt < maxRetries; attempt++)
{
try
{
// Replace with your actual OCR.net API call
return await CallOcrNetApi(imagePath);
}
catch (HttpRequestException ex) when (ex.Message.Contains("429"))
{
if (attempt == maxRetries - 1) throw;
var delay = TimeSpan.FromSeconds(Math.Pow(2, attempt));
await Task.Delay(delay);
}
}
throw new InvalidOperationException("OCR processing failed after all retries");
}using System;
using System.Net.Http;
using System.Threading.Tasks;
// Queue-based OCR processing with exponential backoff retry
async Task<string> ProcessOcrWithRetry(string imagePath, int maxRetries = 3)
{
for (int attempt = 0; attempt < maxRetries; attempt++)
{
try
{
// Replace with your actual OCR.net API call
return await CallOcrNetApi(imagePath);
}
catch (HttpRequestException ex) when (ex.Message.Contains("429"))
{
if (attempt == maxRetries - 1) throw;
var delay = TimeSpan.FromSeconds(Math.Pow(2, attempt));
await Task.Delay(delay);
}
}
throw new InvalidOperationException("OCR processing failed after all retries");
}Imports System
Imports System.Net.Http
Imports System.Threading.Tasks
' Queue-based OCR processing with exponential backoff retry
Async Function ProcessOcrWithRetry(imagePath As String, Optional maxRetries As Integer = 3) As Task(Of String)
For attempt As Integer = 0 To maxRetries - 1
Try
' Replace with your actual OCR.net API call
Return Await CallOcrNetApi(imagePath)
Catch ex As HttpRequestException When ex.Message.Contains("429")
If attempt = maxRetries - 1 Then Throw
Dim delay As TimeSpan = TimeSpan.FromSeconds(Math.Pow(2, attempt))
Await Task.Delay(delay)
End Try
Next
Throw New InvalidOperationException("OCR processing failed after all retries")
End FunctionPara fluxos de trabalho de acessibilidade, a extração de texto por OCR permite que usuários com deficiência visual recebam feedback de áudio de documentos que antes eram apenas imagens. A combinação da saída OCR .NET com a conformidade com PDF/UA por meio do IronPDF cria documentos que as tecnologias assistivas podem navegar com eficácia.
Como criar um fluxo de trabalho completo com IronPDF e OCR .NET ?
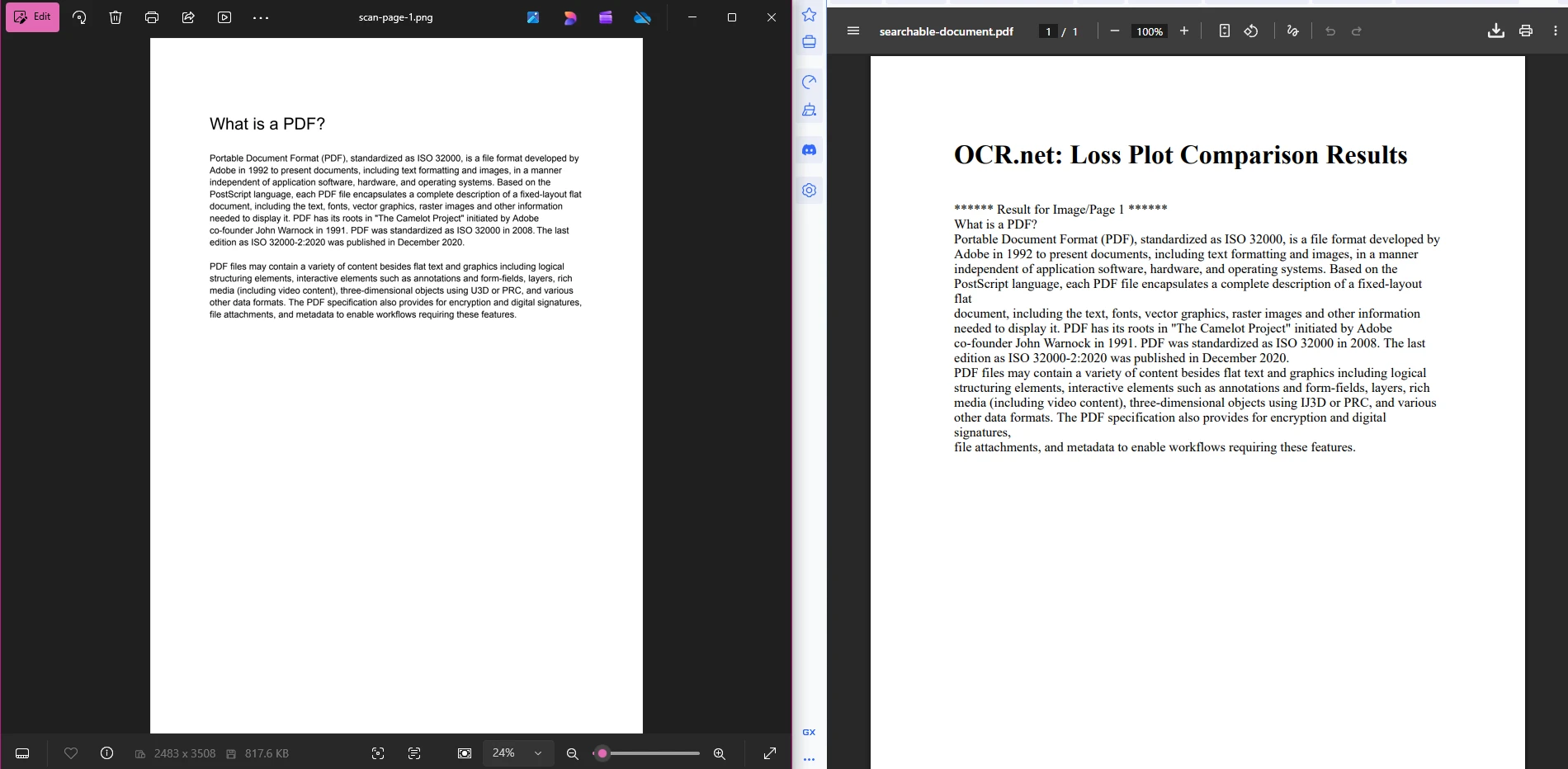
A integração do IronPDF com o OCR .NET gera soluções completas para documentos. O fluxo de trabalho possui três etapas: exportar as páginas do PDF como imagens, enviar as imagens para o OCR .NET para extração de texto e reconstruir o texto reconhecido como um novo PDF pesquisável.
using IronPdf;
using System;
using System.Collections.Generic;
using System.Net.Http;
using System.Text;
using System.Threading.Tasks;
// --- Stage 1: Export PDF pages as images for OCR ---
var scannedPdf = PdfDocument.FromFile("input-document.pdf");
var imageFiles = scannedPdf.RasterizeToImageFiles(
"scan-page-{0}.png",
IronPdf.Imaging.ImageType.Png,
300 // 300 DPI -- minimum for reliable OCR accuracy
);
// --- Stage 2: Process each image through OCR.net ---
var ocrResults = new List<string>();
foreach (var imageFile in imageFiles)
{
// Replace this placeholder with your actual OCR.net API integration
string ocrText = await SendImageToOcrNet(imageFile);
ocrResults.Add(ocrText);
}
// --- Stage 3: Reassemble recognized text as a searchable PDF ---
var htmlBuilder = new StringBuilder();
htmlBuilder.Append(@"<!DOCTYPE html><html><head>
<style>body{font-family:Arial,sans-serif;margin:40px;}
.page{page-break-after:always;} pre{white-space:pre-wrap;}</style>
</head><body>");
for (int i = 0; i < ocrResults.Count; i++)
{
htmlBuilder.AppendFormat(
"<div class='page'><h2>Page {0}</h2><pre>{1}</pre></div>",
i + 1,
System.Web.HttpUtility.HtmlEncode(ocrResults[i])
);
}
htmlBuilder.Append("</body></html>");
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.DPI = 300;
renderer.RenderingOptions.EnableJavaScript = false;
var searchablePdf = await renderer.RenderHtmlAsPdfAsync(htmlBuilder.ToString());
searchablePdf.MetaData.Title = "OCR Processed Document";
searchablePdf.MetaData.Subject = "Searchable PDF from OCR";
searchablePdf.MetaData.CreationDate = DateTime.UtcNow;
searchablePdf.SecuritySettings.AllowUserPrinting = true;
searchablePdf.SecuritySettings.AllowUserCopyPasteContent = true;
searchablePdf.SaveAs("searchable-document.pdf");using IronPdf;
using System;
using System.Collections.Generic;
using System.Net.Http;
using System.Text;
using System.Threading.Tasks;
// --- Stage 1: Export PDF pages as images for OCR ---
var scannedPdf = PdfDocument.FromFile("input-document.pdf");
var imageFiles = scannedPdf.RasterizeToImageFiles(
"scan-page-{0}.png",
IronPdf.Imaging.ImageType.Png,
300 // 300 DPI -- minimum for reliable OCR accuracy
);
// --- Stage 2: Process each image through OCR.net ---
var ocrResults = new List<string>();
foreach (var imageFile in imageFiles)
{
// Replace this placeholder with your actual OCR.net API integration
string ocrText = await SendImageToOcrNet(imageFile);
ocrResults.Add(ocrText);
}
// --- Stage 3: Reassemble recognized text as a searchable PDF ---
var htmlBuilder = new StringBuilder();
htmlBuilder.Append(@"<!DOCTYPE html><html><head>
<style>body{font-family:Arial,sans-serif;margin:40px;}
.page{page-break-after:always;} pre{white-space:pre-wrap;}</style>
</head><body>");
for (int i = 0; i < ocrResults.Count; i++)
{
htmlBuilder.AppendFormat(
"<div class='page'><h2>Page {0}</h2><pre>{1}</pre></div>",
i + 1,
System.Web.HttpUtility.HtmlEncode(ocrResults[i])
);
}
htmlBuilder.Append("</body></html>");
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.DPI = 300;
renderer.RenderingOptions.EnableJavaScript = false;
var searchablePdf = await renderer.RenderHtmlAsPdfAsync(htmlBuilder.ToString());
searchablePdf.MetaData.Title = "OCR Processed Document";
searchablePdf.MetaData.Subject = "Searchable PDF from OCR";
searchablePdf.MetaData.CreationDate = DateTime.UtcNow;
searchablePdf.SecuritySettings.AllowUserPrinting = true;
searchablePdf.SecuritySettings.AllowUserCopyPasteContent = true;
searchablePdf.SaveAs("searchable-document.pdf");Imports IronPdf
Imports System
Imports System.Collections.Generic
Imports System.Net.Http
Imports System.Text
Imports System.Threading.Tasks
' --- Stage 1: Export PDF pages as images for OCR ---
Dim scannedPdf = PdfDocument.FromFile("input-document.pdf")
Dim imageFiles = scannedPdf.RasterizeToImageFiles(
"scan-page-{0}.png",
IronPdf.Imaging.ImageType.Png,
300 ' 300 DPI -- minimum for reliable OCR accuracy
)
' --- Stage 2: Process each image through OCR.net ---
Dim ocrResults As New List(Of String)()
For Each imageFile In imageFiles
' Replace this placeholder with your actual OCR.net API integration
Dim ocrText As String = Await SendImageToOcrNet(imageFile)
ocrResults.Add(ocrText)
Next
' --- Stage 3: Reassemble recognized text as a searchable PDF ---
Dim htmlBuilder As New StringBuilder()
htmlBuilder.Append("<!DOCTYPE html><html><head>
<style>body{font-family:Arial,sans-serif;margin:40px;}
.page{page-break-after:always;} pre{white-space:pre-wrap;}</style>
</head><body>")
For i As Integer = 0 To ocrResults.Count - 1
htmlBuilder.AppendFormat(
"<div class='page'><h2>Page {0}</h2><pre>{1}</pre></div>",
i + 1,
System.Web.HttpUtility.HtmlEncode(ocrResults(i))
)
Next
htmlBuilder.Append("</body></html>")
Dim renderer As New ChromePdfRenderer()
renderer.RenderingOptions.DPI = 300
renderer.RenderingOptions.EnableJavaScript = False
Dim searchablePdf = Await renderer.RenderHtmlAsPdfAsync(htmlBuilder.ToString())
searchablePdf.MetaData.Title = "OCR Processed Document"
searchablePdf.MetaData.Subject = "Searchable PDF from OCR"
searchablePdf.MetaData.CreationDate = DateTime.UtcNow
searchablePdf.SecuritySettings.AllowUserPrinting = True
searchablePdf.SecuritySettings.AllowUserCopyPasteContent = True
searchablePdf.SaveAs("searchable-document.pdf")Este processo foi concebido de forma intencionalmente simples. A primeira etapa gera arquivos PNG numerados. A segunda etapa envia cada arquivo para o OCR .NET e coleta as sequências de texto retornadas. A terceira etapa envolve essas strings em HTML e usa o IronPDF para renderizar um PDF final onde o texto é totalmente selecionável e pesquisável. Você pode estender a Etapa 3 para aplicar metadados de PDF para gerenciamento de documentos ou configurações de segurança para controle de acesso.
Qual configuração do Docker funciona melhor para este fluxo de trabalho?
As compilações Docker em várias etapas mantêm a imagem final pequena, incluindo todas as dependências de tempo de execução necessárias para o IronPDF no Linux:
FROM mcr.microsoft.com/dotnet/sdk:8.0 AS build
WORKDIR /app
COPY *.csproj ./
RUN dotnet restore
COPY . ./
RUN dotnet publish -c Release -o out
FROM mcr.microsoft.com/dotnet/aspnet:8.0
WORKDIR /app
# IronPDF Linux runtime dependencies
RUN apt-get update && apt-get install -y \
libgdiplus \
libc6-dev \
libx11-dev \
&& rm -rf /var/lib/apt/lists/*
COPY --from=build /app/out .
HEALTHCHECK --interval=30s --timeout=3s --start-period=5s --retries=3 \
CMD curl -f http://localhost:8080/health/ready || exit 1
ENTRYPOINT ["dotnet", "OcrWorkflow.dll"]Para escala de produção, considere o uso de Jobs do Kubernetes para operações de OCR em lote. Os Jobs do Kubernetes oferecem repetição automática, controle de paralelismo e isolamento de recursos, de forma que tarefas de documentos com falha não afetem outros serviços. Defina parallelism para corresponder ao seu nível de API OCR.net e backoffLimit para controlar quantas vezes um pod com falha tenta novamente antes que o Job marque a tarefa como falhada.
Como monitorar as métricas de desempenho em produção?
O acompanhamento dos tempos de processamento e das taxas de sucesso do OCR ajuda a identificar gargalos antes que eles afetem os usuários finais. Prometheus com métricas personalizadas é uma abordagem prática:
using Prometheus;
using System;
using System.Threading.Tasks;
// Prometheus metrics for OCR pipeline observability
var ocrRequestsTotal = Metrics
.CreateCounter("ocr_requests_total", "Total OCR requests processed");
var ocrDuration = Metrics
.CreateHistogram("ocr_duration_seconds", "OCR processing duration in seconds",
new HistogramConfiguration
{
Buckets = Histogram.LinearBuckets(0.1, 0.1, 10)
});
var activeOcrJobs = Metrics
.CreateGauge("ocr_active_jobs", "Currently active OCR jobs");
// Wrapper that tracks every OCR operation automatically
async Task<t> TrackOcrOperation<t>(Func<Task<t>> operation)
{
using (ocrDuration.NewTimer())
{
activeOcrJobs.Inc();
try
{
var result = await operation();
ocrRequestsTotal.Inc();
return result;
}
finally
{
activeOcrJobs.Dec();
}
}
}using Prometheus;
using System;
using System.Threading.Tasks;
// Prometheus metrics for OCR pipeline observability
var ocrRequestsTotal = Metrics
.CreateCounter("ocr_requests_total", "Total OCR requests processed");
var ocrDuration = Metrics
.CreateHistogram("ocr_duration_seconds", "OCR processing duration in seconds",
new HistogramConfiguration
{
Buckets = Histogram.LinearBuckets(0.1, 0.1, 10)
});
var activeOcrJobs = Metrics
.CreateGauge("ocr_active_jobs", "Currently active OCR jobs");
// Wrapper that tracks every OCR operation automatically
async Task<t> TrackOcrOperation<t>(Func<Task<t>> operation)
{
using (ocrDuration.NewTimer())
{
activeOcrJobs.Inc();
try
{
var result = await operation();
ocrRequestsTotal.Inc();
return result;
}
finally
{
activeOcrJobs.Dec();
}
}
}Imports Prometheus
Imports System
Imports System.Threading.Tasks
' Prometheus metrics for OCR pipeline observability
Dim ocrRequestsTotal = Metrics.CreateCounter("ocr_requests_total", "Total OCR requests processed")
Dim ocrDuration = Metrics.CreateHistogram("ocr_duration_seconds", "OCR processing duration in seconds",
New HistogramConfiguration With {
.Buckets = Histogram.LinearBuckets(0.1, 0.1, 10)
})
Dim activeOcrJobs = Metrics.CreateGauge("ocr_active_jobs", "Currently active OCR jobs")
' Wrapper that tracks every OCR operation automatically
Async Function TrackOcrOperation(Of T)(operation As Func(Of Task(Of T))) As Task(Of T)
Using ocrDuration.NewTimer()
activeOcrJobs.Inc()
Try
Dim result = Await operation()
ocrRequestsTotal.Inc()
Return result
Finally
activeOcrJobs.Dec()
End Try
End Using
End FunctionCombine essas métricas com os recursos de registro do IronPDF para correlacionar os tempos de renderização com as durações do OCR. Quando a duração do OCR aumenta repentinamente sem um aumento correspondente no tempo de renderização, o gargalo está na chamada da API .NET do OCR ou no seu caminho de rede até ela, e não na etapa de geração do PDF.
Quais são os seus próximos passos?
O OCR .NET combinado com o IronPDF oferece um caminho prático para extração de texto e geração de PDFs pesquisáveis em .NET. O pipeline abrange os principais casos de uso: criação de PDFs a partir de HTML, exportação de páginas em resolução compatível com OCR, envio de imagens para o OCR .NET e remontagem dos resultados em um documento totalmente pesquisável.
Principais considerações ao levar isso para a produção:
- Configuração do contêiner: Use pacotes IronPDF Slim e builds Docker em várias etapas para manter os tamanhos das imagens gerenciáveis.
- Planejamento de recursos: configure limites de memória adequados aos tamanhos dos seus documentos e à meta de simultaneidade.
- Monitoramento: Implemente métricas do Prometheus juntamente com o registro de logs do IronPDF para detectar degradações precocemente.
- Taxa de transferência: Utilize operações assíncronas e gerenciamento de filas de lotes para trabalhar dentro dos limites de taxa do OCR.net.
- Confiabilidade: Implementar lógica de repetição com recuo exponencial e disjuntores em torno da chamada da API OCR .NET.
Comece com a licença de avaliação gratuita para testar todo o fluxo de trabalho de ponta a ponta antes de se comprometer com uma licença de produção. A versão de avaliação remove a marca d'água e desbloqueia todos os recursos, para que seus resultados de benchmark reflitam com precisão o comportamento em produção. Quando estiver pronto para implementar, revise as opções de licenciamento do IronPDF para encontrar o plano que melhor se adapta ao seu padrão de uso.
Perguntas frequentes
O que faz o OCR.net e como ele se conecta com IronPDF?
OCR.net é um serviço de OCR de aprendizado profundo que aceita entradas de imagem e retorna texto reconhecido. IronPDF gera PDFs e exporta suas páginas como imagens. As duas ferramentas se conectam na camada de imagem: IronPDF exporta páginas com RasterizeToImageFiles(), essas imagens vão para o OCR.net para extração de texto, e IronPDF reconstituí os resultados como um PDF pesquisável.
Qual DPI você deveria usar ao exportar páginas de PDF para OCR?
300 DPI é o mínimo padrão para precisão confiável de OCR. Em 300 DPI, as bordas de texto são nítidas o suficiente para o modelo distinguir caracteres semelhantes. Em 150 DPI ou menos, a precisão cai em fontes serifadas e impressões pequenas. Use 600 DPI apenas quando os documentos fonte contiverem texto muito pequeno ou degradado, já que cada página a 600 DPI produz arquivos 4-5 vezes maiores.
Como você lida com limites de taxa da API OCR.net em produção?
Contas gratuitas do OCR.net permitem 50 solicitações por hora. Construa lógica de tentativa de repetição com recuo exponencial na sua chamada de OCR: capture a resposta 429, espere Math.Pow(2, attempt) segundos e tente novamente até um máximo configurado. Para maior rendimento, atualize para um plano pago do OCR.net ou coloque solicitações em fila com um serviço de trabalho em segundo plano.
O IronPDF pode rodar dentro de um contêiner Docker no Linux?
Sim. Adicione libgdiplus, libc6-dev e libx11-dev ao estágio de tempo de execução do seu Dockerfile. Use construções em múltiplos estágios para manter a imagem final pequena. A variante do pacote Slim do IronPDF reduz ainda mais o tamanho da imagem ao excluir binários de navegador empacotados quando você executa o IronPDF Engine como um serviço separado.
Como você cria um PDF pesquisável a partir de resultados de OCR?
Colete as strings de texto retornadas pelo OCR.net, envolva-as em HTML com uma classe de quebra de página por página de documento e passe o HTML para ChromePdfRenderer.RenderHtmlAsPdfAsync(). O PDF resultante contém texto selecionável e pesquisável que usuários e motores de busca podem indexar.
Esse fluxo de trabalho suporta documentos multilíngues?
Sim. OCR.net suporta mais de 60 idiomas. Selecione o idioma de destino na interface do OCR.net ou chamada da API antes do processamento. O IronPDF lida com saída UTF-8 nativamente, então idiomas com scripts não latinos são renderizados corretamente no PDF pesquisável reconstruído.
Como você monitora o desempenho do pipeline OCR em produção?
Adicione contadores, histogramas e medidores do Prometheus ao seu serviço de processamento para rastrear pedidos totais, distribuições de duração e trabalhos ativos. Emparelhe métricas Prometheus com o registro personalizado do IronPDF para correlacionar tempos de renderização à latência da API OCR e identificar onde ocorrem gargalos.
Qual é a diferença entre OCR.net e IronOCR?
OCR.net é um serviço web externo que processa imagens que você carrega via API. IronOCR é uma biblioteca .NET da Iron Software que realiza o processamento OCR localmente dentro de sua aplicação sem chamadas de API externas. IronOCR é mais adequado para ambientes offline ou quando você precisa de menor latência e mais controle sobre o mecanismo de OCR.











