
Comment construire un flux de travail OCR PDF avec OCR.net et IronPDF en C#
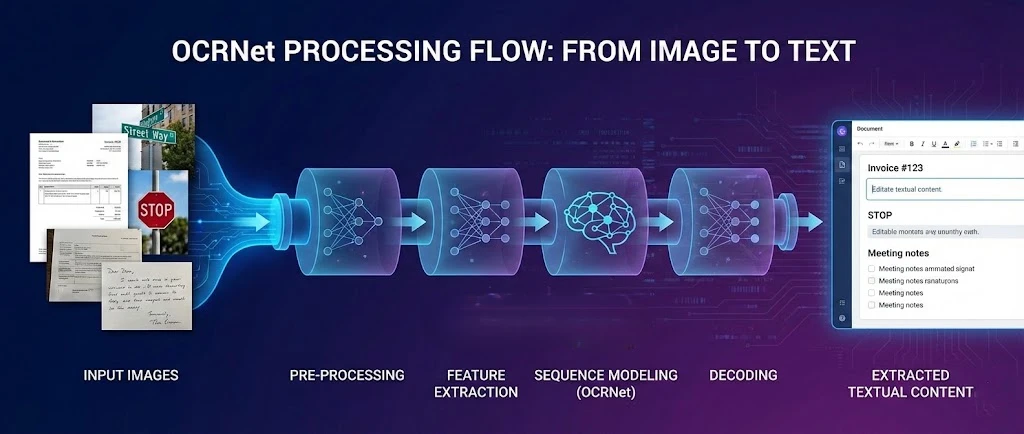
OCR .NET est un framework d'apprentissage profond pour la reconnaissance optique de caractères qui s'associe à IronPDF pour extraire du texte à partir de PDF et produire des documents consultables dans les applications .NET . Ce tutoriel vous montre comment connecter ces deux outils afin que votre application puisse traiter les fichiers numérisés, pixelliser les pages PDF pour la reconnaissance optique de caractères (OCR) et réassembler le texte reconnu dans un nouveau PDF consultable.
Le modèle OCR .NET excelle dans la détection de texte et la reconnaissance de caractères dans des environnements complexes. En l'associant au moteur de rendu d'IronPDF, vous obtenez un pipeline complet : générer ou charger un PDF, exporter ses pages sous forme d'images haute résolution, envoyer ces images à .NET et reconstruire les résultats sous forme de document entièrement consultable.
Comment commencer avec IronPDF ?
Avant de créer le flux de travail OCR, vous devez installer IronPDF dans votre projet. La méthode la plus rapide consiste à utiliser la console du gestionnaire de packages NuGet :
Install-Package IronPDFOu ajoutez-le directement via l'interface utilisateur de NuGet en recherchant IronPDF . Une fois l'application installée, appliquez votre clé de licence au démarrage de l'application :
using IronPdf;
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";using IronPdf;
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";Imports IronPdf
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY"Une licence d'essai gratuite est disponible pour vous permettre de tester l'ensemble des fonctionnalités sans aucune restriction. IronPDF prend en charge .NET 6, 7, 8 et 10 sous Windows, Linux et macOS, ce qui signifie que le même code s'exécute dans les applications de bureau, les services Web ASP.NET Core et les déploiements conteneurisés.
Pour les environnements Docker, IronPDF propose un guide de déploiement Linux préconfiguré et des versions allégées permettant de réduire la taille des images. Si vous préférez une architecture de rendu à distance, le moteur IronPDF peut fonctionner comme un service distinct avec des clients sur toutes les plateformes compatibles.
Qu'est-ce qu'OCRNet et comment fonctionne la reconnaissance optique de caractères ?
OCR .NET est une approche d'apprentissage profond de la reconnaissance optique de caractères (OCR) qui reconnaît les caractères alphanumériques dans différents styles de police. Le modèle utilise une architecture de réseau neuronal optimisée pour capturer les caractéristiques spatiales des images d'entrée. Associés à des capacités de génération de PDF , ces modèles entraînés offrent une reconnaissance d'une grande précision pour les types de documents courants.
Le cadre de reconnaissance derrière OCR .NET intègre une unité récurrente à porte (GRU) pour améliorer l'apprentissage des caractéristiques et traiter les tâches de reconnaissance de séquences basées sur l'image. Ce modèle hybride atteint une précision remarquable grâce à la classification temporelle connexionniste (CTC), une technique initialement introduite pour l'étiquetage de séquences qui se transpose bien à la reconnaissance optique de caractères (OCR) de documents. Les améliorations continues permettent d'étendre la prise en charge linguistique d'OCR.net, notamment grâce à son intégration avec les outils d'extraction de texte PDF .
Les principaux composants d'un pipeline OCR moderne comprennent :
- Détection de texte : identification des zones de contenu textuel dans une image à l'aide de modèles entraînés
- Détection de texte dans la scène : localisation de texte dans des arrière-plans complexes et des environnements dynamiques
- Reconnaissance de caractères alphanumériques : Utilisation de modèles entraînés pour reconnaître les caractères avec une précision de validation élevée
- Reconnaissance de formes : application de techniques de traitement d'images pour la reconnaissance de texte dans des scènes légères
L'architecture basée sur GRU et la classification temporelle connexionniste permettent une utilisation efficace des ressources dans les environnements conteneurisés, faisant d'OCR .NET un choix pratique pour les déploiements Kubernetes où les contraintes de mémoire et de processeur sont importantes. L'architecture légère permet de gérer la taille des images Docker tout en maintenant une précision de reconnaissance élevée.
Quand faut-il utiliser OCR .NET plutôt que les bibliothèques OCR traditionnelles ?
.NET est le meilleur choix pour le traitement de textes complexes, de documents manuscrits ou de contenus multilingues, là où l'OCR basé sur des modèles échoue. Il est particulièrement performant dans les applications conteneurisées qui nécessitent des performances constantes quelle que soit la configuration matérielle, sans dépendances externes. Le modèle gère parfaitement l'encodage UTF-8 , ce qui est important pour la prise en charge des langues internationales .
Les systèmes OCR traditionnels basés sur les expressions régulières ou la correspondance de modèles échouent avec les polices variables, l'écriture manuscrite ou les images présentant un éclairage inégal. L'approche neuronale d'OCR.net se généralise mieux dans ces scénarios car elle apprend les caractéristiques plutôt que de faire correspondre des modèles fixes. Cela dit, si vos documents sont des textes propres, saisis à la machine et avec une mise en forme cohérente, une bibliothèque plus légère peut être plus rapide et suffisante.
Quelles sont les ressources généralement nécessaires pour la reconnaissance optique de caractères (OCR) en .NET en production ?
Les déploiements en production nécessitent généralement 2 à 4 cœurs de processeur et 4 à 8 Go de RAM pour des performances optimales. L'accélération GPU offre un gain de vitesse considérable pour le traitement par lots dans les environnements conteneurisés utilisant le runtime NVIDIA Docker. Ces exigences sont parfaitement compatibles avec les déploiements Azure App Service et AWS Lambda . Toutefois, la limite de mémoire de Lambda implique qu'il est recommandé d'effectuer des tests de performance sur vos documents avant de procéder à l'accélération.
Comment IronPDF crée-t-il des documents PDF pour le traitement OCR ?
IronPDF offre aux développeurs .NET un contrôle total sur la génération de PDF. La bibliothèque peut convertir des chaînes HTML , des URL et des fichiers en PDF de haute qualité grâce à son moteur de rendu basé sur Chrome. Pour les flux de travail OCR, la fonctionnalité essentielle est RasterizeToImageFiles(), qui permet d'exporter les pages PDF sous forme d'images haute résolution adaptées à la reconnaissance optique de caractères (OCR).
using IronPdf;
// Create a PDF document with IronPDF
var renderer = new ChromePdfRenderer();
// Set 300 DPI for OCR accuracy -- higher DPI preserves text sharpness
renderer.RenderingOptions.PaperSize = IronPdf.Rendering.PdfPaperSize.A4;
renderer.RenderingOptions.DPI = 300;
renderer.RenderingOptions.MarginTop = 50;
renderer.RenderingOptions.MarginBottom = 50;
var pdf = renderer.RenderHtmlAsPdf(@"
<h1>Document Report</h1>
<p>Scene text integration for computer vision analysis.</p>
<p>Text detection results for dataset and model analysis.</p>");
// Tag the document with searchable metadata
pdf.MetaData.Author = "OCR Processing Pipeline";
pdf.MetaData.Keywords = "OCR, Text Recognition, Computer Vision";
pdf.MetaData.ModifiedDate = DateTime.Now;
pdf.SaveAs("document-for-ocr.pdf");
// Export pages as PNG images for OCR.net -- 300 DPI is the recommended minimum
pdf.RasterizeToImageFiles("page-*.png", IronPdf.Imaging.ImageType.Png, 300);using IronPdf;
// Create a PDF document with IronPDF
var renderer = new ChromePdfRenderer();
// Set 300 DPI for OCR accuracy -- higher DPI preserves text sharpness
renderer.RenderingOptions.PaperSize = IronPdf.Rendering.PdfPaperSize.A4;
renderer.RenderingOptions.DPI = 300;
renderer.RenderingOptions.MarginTop = 50;
renderer.RenderingOptions.MarginBottom = 50;
var pdf = renderer.RenderHtmlAsPdf(@"
<h1>Document Report</h1>
<p>Scene text integration for computer vision analysis.</p>
<p>Text detection results for dataset and model analysis.</p>");
// Tag the document with searchable metadata
pdf.MetaData.Author = "OCR Processing Pipeline";
pdf.MetaData.Keywords = "OCR, Text Recognition, Computer Vision";
pdf.MetaData.ModifiedDate = DateTime.Now;
pdf.SaveAs("document-for-ocr.pdf");
// Export pages as PNG images for OCR.net -- 300 DPI is the recommended minimum
pdf.RasterizeToImageFiles("page-*.png", IronPdf.Imaging.ImageType.Png, 300);Imports IronPdf
' Create a PDF document with IronPDF
Dim renderer As New ChromePdfRenderer()
' Set 300 DPI for OCR accuracy -- higher DPI preserves text sharpness
renderer.RenderingOptions.PaperSize = IronPdf.Rendering.PdfPaperSize.A4
renderer.RenderingOptions.DPI = 300
renderer.RenderingOptions.MarginTop = 50
renderer.RenderingOptions.MarginBottom = 50
Dim pdf = renderer.RenderHtmlAsPdf("
<h1>Document Report</h1>
<p>Scene text integration for computer vision analysis.</p>
<p>Text detection results for dataset and model analysis.</p>")
' Tag the document with searchable metadata
pdf.MetaData.Author = "OCR Processing Pipeline"
pdf.MetaData.Keywords = "OCR, Text Recognition, Computer Vision"
pdf.MetaData.ModifiedDate = DateTime.Now
pdf.SaveAs("document-for-ocr.pdf")
' Export pages as PNG images for OCR.net -- 300 DPI is the recommended minimum
pdf.RasterizeToImageFiles("page-*.png", IronPdf.Imaging.ImageType.Png, 300)La méthode RasterizeToImageFiles() convertit les pages PDF en images PNG au DPI spécifié. À 300 DPI, les contours du texte restent suffisamment nets pour que le modèle OCR puisse distinguer des caractères d'apparence similaire. À une résolution de 150 DPI ou moins, la précision de la reconnaissance diminue sensiblement pour les polices à empattement et les petits caractères. Après l'exportation, téléchargez les fichiers PNG sur OCR .NET ou transmettez-les directement à un modèle local.

Pourquoi le réglage DPI affecte-t-il la précision de la reconnaissance optique de caractères (OCR) ?
Des paramètres DPI plus élevés (300-600) préservent la clarté du texte dont le modèle OCR a besoin pour distinguer les caractères avec précision. Le compromis réside dans la taille du fichier et le temps de traitement. À 300 DPI, une seule page A4 produit un fichier PNG d'environ 2 à 3 Mo. À 600 DPI, cela passe à 8-12 Mo. Pour la plupart des documents, 300 DPI représente le bon compromis. Les options de rendu permettent d'ajuster ces paramètres en fonction du type de document, tandis que les techniques de compression contribuent à optimiser la taille des fichiers une fois la reconnaissance optique de caractères (OCR) terminée.
Comment IronPDF gère-t-il les environnements conteneurisés ?
Le moteur natif d'IronPDF garantit un rendu cohérent sur les conteneurs Linux , Windows et macOS . Pour les services à haute disponibilité, IronPDF s'intègre aux points de terminaison de contrôle d'intégrité ASP.NET Core afin que vous puissiez implémenter des sondes de disponibilité et de vivacité qui vérifient que le rendu PDF est opérationnel avant d'acheminer le trafic vers une instance de conteneur.
using IronPdf;
// Kubernetes-compatible health check endpoint
var builder = WebApplication.CreateBuilder(args);
var app = builder.Build();
app.MapGet("/health/ready", async () =>
{
try
{
var renderer = new ChromePdfRenderer();
var testPdf = await renderer.RenderHtmlAsPdfAsync("<p>Health check</p>");
return testPdf.PageCount > 0 ? Results.Ok() : Results.Problem();
}
catch
{
return Results.Problem("PDF rendering unavailable");
}
});
await app.RunAsync();using IronPdf;
// Kubernetes-compatible health check endpoint
var builder = WebApplication.CreateBuilder(args);
var app = builder.Build();
app.MapGet("/health/ready", async () =>
{
try
{
var renderer = new ChromePdfRenderer();
var testPdf = await renderer.RenderHtmlAsPdfAsync("<p>Health check</p>");
return testPdf.PageCount > 0 ? Results.Ok() : Results.Problem();
}
catch
{
return Results.Problem("PDF rendering unavailable");
}
});
await app.RunAsync();Imports IronPdf
' Kubernetes-compatible health check endpoint
Dim builder = WebApplication.CreateBuilder(args)
Dim app = builder.Build()
app.MapGet("/health/ready", Async Function()
Try
Dim renderer = New ChromePdfRenderer()
Dim testPdf = Await renderer.RenderHtmlAsPdfAsync("<p>Health check</p>")
Return If(testPdf.PageCount > 0, Results.Ok(), Results.Problem())
Catch
Return Results.Problem("PDF rendering unavailable")
End Try
End Function)
Await app.RunAsync()Utilisez une journalisation personnalisée en complément de ce point de terminaison pour capturer les temps de rendu et identifier les conteneurs qui se dégradent avant qu'ils ne tombent complètement en panne.
Comment OCR.net extrait-il du texte à partir d'images PDF ?
Une fois que vous avez exporté vos fichiers PNG depuis IronPDF, vous les téléchargez sur .NET pour la reconnaissance de texte. Le pipeline OCR .NET traite les images et renvoie un texte normalisé pour différents styles de police. Il gère les textes imprimés et manuscrits et prend en charge plus de 60 langues de documents.
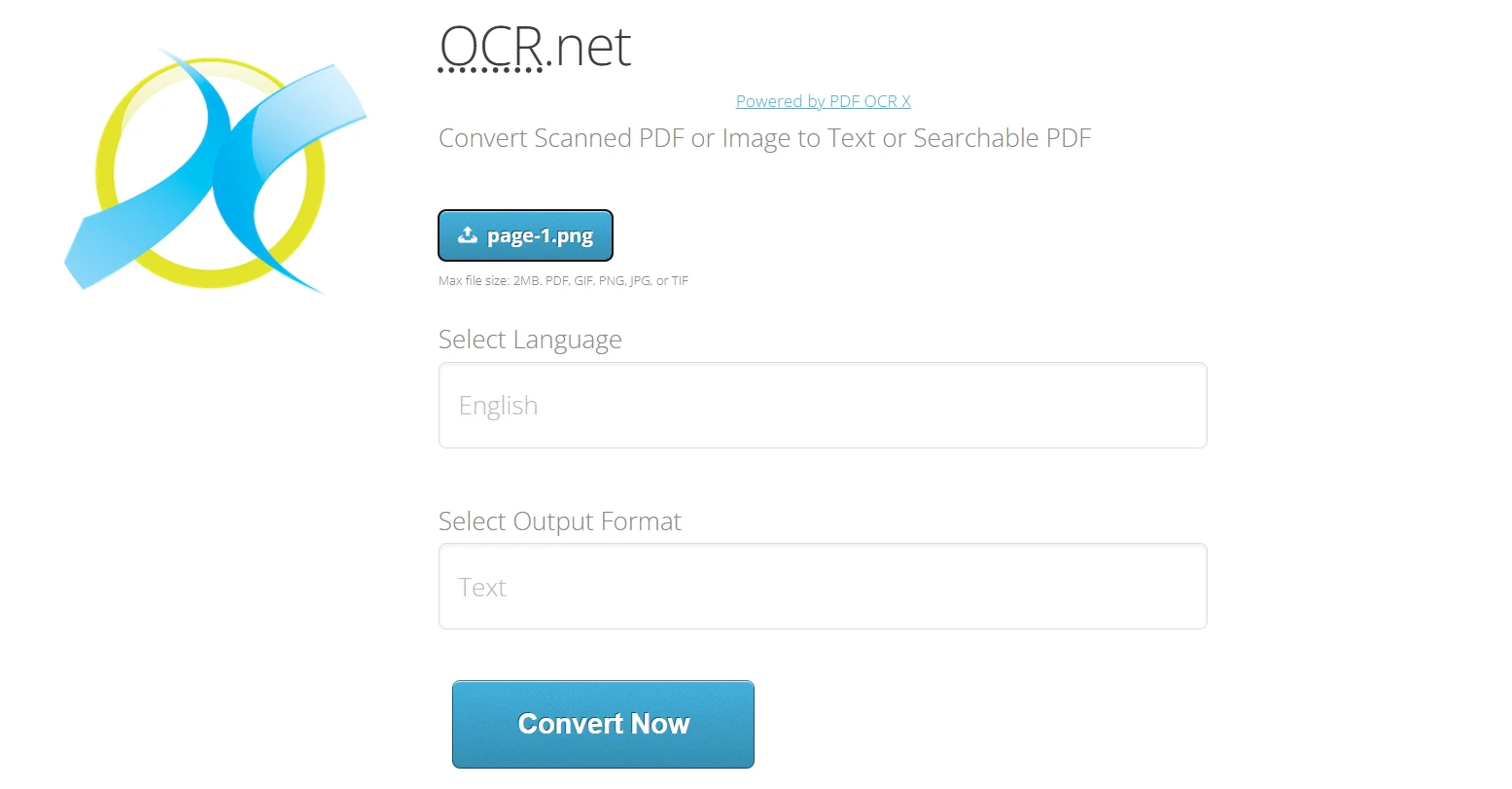
Utilisation d'OCR.net Online:
- Naviguer vers https://ocr.net/
- Téléversez l'image PNG ou JPG (2 Mo maximum) exportée depuisIronPDF.
- Sélectionnez la langue du document parmi plus de 60 options disponibles.
- Choisissez le format de sortie : texte brut ou PDF interrogeable
- Cliquez sur " Convertir maintenant " pour traiter l'image avec les modèles OCR .NET
.NET fournit également une API pour le traitement automatisé. Les comptes gratuits sont limités à 50 requêtes par heure, ce qui constitue une contrainte critique pour les pipelines automatisés. Concevez votre intégration de manière à gérer les réponses aux limitations de débit avec élégance, grâce à un délai exponentiel, plutôt que de provoquer une défaillance brutale :
using System;
using System.Net.Http;
using System.Threading.Tasks;
// Queue-based OCR processing with exponential backoff retry
async Task<string> ProcessOcrWithRetry(string imagePath, int maxRetries = 3)
{
for (int attempt = 0; attempt < maxRetries; attempt++)
{
try
{
// Replace with your actual OCR.net API call
return await CallOcrNetApi(imagePath);
}
catch (HttpRequestException ex) when (ex.Message.Contains("429"))
{
if (attempt == maxRetries - 1) throw;
var delay = TimeSpan.FromSeconds(Math.Pow(2, attempt));
await Task.Delay(delay);
}
}
throw new InvalidOperationException("OCR processing failed after all retries");
}using System;
using System.Net.Http;
using System.Threading.Tasks;
// Queue-based OCR processing with exponential backoff retry
async Task<string> ProcessOcrWithRetry(string imagePath, int maxRetries = 3)
{
for (int attempt = 0; attempt < maxRetries; attempt++)
{
try
{
// Replace with your actual OCR.net API call
return await CallOcrNetApi(imagePath);
}
catch (HttpRequestException ex) when (ex.Message.Contains("429"))
{
if (attempt == maxRetries - 1) throw;
var delay = TimeSpan.FromSeconds(Math.Pow(2, attempt));
await Task.Delay(delay);
}
}
throw new InvalidOperationException("OCR processing failed after all retries");
}Imports System
Imports System.Net.Http
Imports System.Threading.Tasks
' Queue-based OCR processing with exponential backoff retry
Async Function ProcessOcrWithRetry(imagePath As String, Optional maxRetries As Integer = 3) As Task(Of String)
For attempt As Integer = 0 To maxRetries - 1
Try
' Replace with your actual OCR.net API call
Return Await CallOcrNetApi(imagePath)
Catch ex As HttpRequestException When ex.Message.Contains("429")
If attempt = maxRetries - 1 Then Throw
Dim delay As TimeSpan = TimeSpan.FromSeconds(Math.Pow(2, attempt))
Await Task.Delay(delay)
End Try
Next
Throw New InvalidOperationException("OCR processing failed after all retries")
End FunctionPour les flux de travail d'accessibilité, l'extraction de texte par reconnaissance optique de caractères (OCR) permet aux utilisateurs malvoyants de recevoir un retour audio à partir de documents qui n'étaient auparavant que des images. L'association de la sortie OCR .NET avec la conformité PDF/UA via IronPDF crée des documents que les technologies d'assistance peuvent parcourir efficacement.
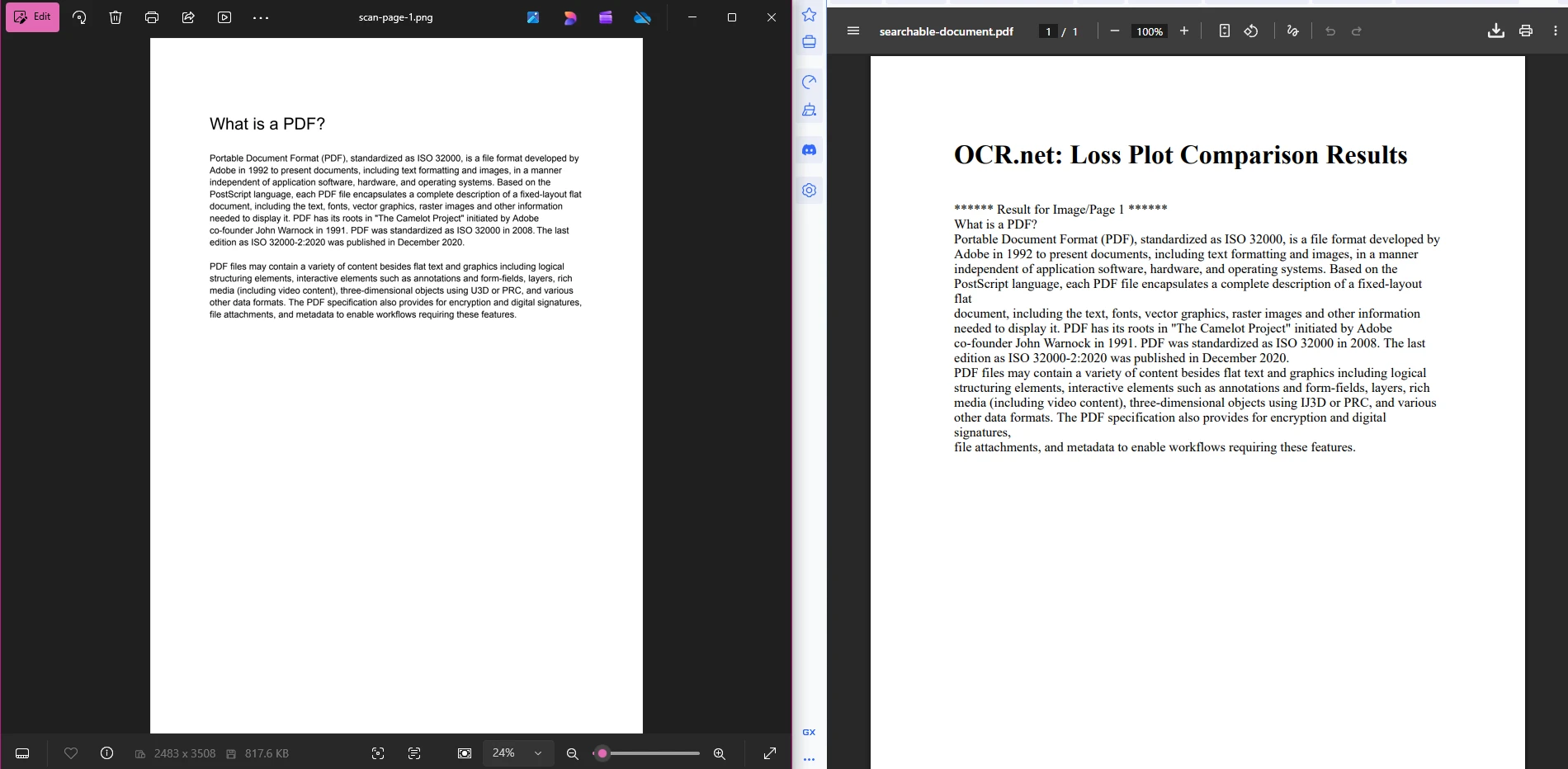
Comment créer un flux de travail complet IronPDF et OCR .NET ?
L'association IronPDF avec OCR .NET permet de créer des solutions documentaires complètes. Le flux de travail comporte trois étapes : exporter les pages PDF sous forme d'images, envoyer ces images à .NET pour l'extraction du texte et reconstruire le texte reconnu sous la forme d'un nouveau PDF consultable.
using IronPdf;
using System;
using System.Collections.Generic;
using System.Net.Http;
using System.Text;
using System.Threading.Tasks;
// --- Stage 1: Export PDF pages as images for OCR ---
var scannedPdf = PdfDocument.FromFile("input-document.pdf");
var imageFiles = scannedPdf.RasterizeToImageFiles(
"scan-page-{0}.png",
IronPdf.Imaging.ImageType.Png,
300 // 300 DPI -- minimum for reliable OCR accuracy
);
// --- Stage 2: Process each image through OCR.net ---
var ocrResults = new List<string>();
foreach (var imageFile in imageFiles)
{
// Replace this placeholder with your actual OCR.net API integration
string ocrText = await SendImageToOcrNet(imageFile);
ocrResults.Add(ocrText);
}
// --- Stage 3: Reassemble recognized text as a searchable PDF ---
var htmlBuilder = new StringBuilder();
htmlBuilder.Append(@"<!DOCTYPE html><html><head>
<style>body{font-family:Arial,sans-serif;margin:40px;}
.page{page-break-after:always;} pre{white-space:pre-wrap;}</style>
</head><body>");
for (int i = 0; i < ocrResults.Count; i++)
{
htmlBuilder.AppendFormat(
"<div class='page'><h2>Page {0}</h2><pre>{1}</pre></div>",
i + 1,
System.Web.HttpUtility.HtmlEncode(ocrResults[i])
);
}
htmlBuilder.Append("</body></html>");
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.DPI = 300;
renderer.RenderingOptions.EnableJavaScript = false;
var searchablePdf = await renderer.RenderHtmlAsPdfAsync(htmlBuilder.ToString());
searchablePdf.MetaData.Title = "OCR Processed Document";
searchablePdf.MetaData.Subject = "Searchable PDF from OCR";
searchablePdf.MetaData.CreationDate = DateTime.UtcNow;
searchablePdf.SecuritySettings.AllowUserPrinting = true;
searchablePdf.SecuritySettings.AllowUserCopyPasteContent = true;
searchablePdf.SaveAs("searchable-document.pdf");using IronPdf;
using System;
using System.Collections.Generic;
using System.Net.Http;
using System.Text;
using System.Threading.Tasks;
// --- Stage 1: Export PDF pages as images for OCR ---
var scannedPdf = PdfDocument.FromFile("input-document.pdf");
var imageFiles = scannedPdf.RasterizeToImageFiles(
"scan-page-{0}.png",
IronPdf.Imaging.ImageType.Png,
300 // 300 DPI -- minimum for reliable OCR accuracy
);
// --- Stage 2: Process each image through OCR.net ---
var ocrResults = new List<string>();
foreach (var imageFile in imageFiles)
{
// Replace this placeholder with your actual OCR.net API integration
string ocrText = await SendImageToOcrNet(imageFile);
ocrResults.Add(ocrText);
}
// --- Stage 3: Reassemble recognized text as a searchable PDF ---
var htmlBuilder = new StringBuilder();
htmlBuilder.Append(@"<!DOCTYPE html><html><head>
<style>body{font-family:Arial,sans-serif;margin:40px;}
.page{page-break-after:always;} pre{white-space:pre-wrap;}</style>
</head><body>");
for (int i = 0; i < ocrResults.Count; i++)
{
htmlBuilder.AppendFormat(
"<div class='page'><h2>Page {0}</h2><pre>{1}</pre></div>",
i + 1,
System.Web.HttpUtility.HtmlEncode(ocrResults[i])
);
}
htmlBuilder.Append("</body></html>");
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.DPI = 300;
renderer.RenderingOptions.EnableJavaScript = false;
var searchablePdf = await renderer.RenderHtmlAsPdfAsync(htmlBuilder.ToString());
searchablePdf.MetaData.Title = "OCR Processed Document";
searchablePdf.MetaData.Subject = "Searchable PDF from OCR";
searchablePdf.MetaData.CreationDate = DateTime.UtcNow;
searchablePdf.SecuritySettings.AllowUserPrinting = true;
searchablePdf.SecuritySettings.AllowUserCopyPasteContent = true;
searchablePdf.SaveAs("searchable-document.pdf");Imports IronPdf
Imports System
Imports System.Collections.Generic
Imports System.Net.Http
Imports System.Text
Imports System.Threading.Tasks
' --- Stage 1: Export PDF pages as images for OCR ---
Dim scannedPdf = PdfDocument.FromFile("input-document.pdf")
Dim imageFiles = scannedPdf.RasterizeToImageFiles(
"scan-page-{0}.png",
IronPdf.Imaging.ImageType.Png,
300 ' 300 DPI -- minimum for reliable OCR accuracy
)
' --- Stage 2: Process each image through OCR.net ---
Dim ocrResults As New List(Of String)()
For Each imageFile In imageFiles
' Replace this placeholder with your actual OCR.net API integration
Dim ocrText As String = Await SendImageToOcrNet(imageFile)
ocrResults.Add(ocrText)
Next
' --- Stage 3: Reassemble recognized text as a searchable PDF ---
Dim htmlBuilder As New StringBuilder()
htmlBuilder.Append("<!DOCTYPE html><html><head>
<style>body{font-family:Arial,sans-serif;margin:40px;}
.page{page-break-after:always;} pre{white-space:pre-wrap;}</style>
</head><body>")
For i As Integer = 0 To ocrResults.Count - 1
htmlBuilder.AppendFormat(
"<div class='page'><h2>Page {0}</h2><pre>{1}</pre></div>",
i + 1,
System.Web.HttpUtility.HtmlEncode(ocrResults(i))
)
Next
htmlBuilder.Append("</body></html>")
Dim renderer As New ChromePdfRenderer()
renderer.RenderingOptions.DPI = 300
renderer.RenderingOptions.EnableJavaScript = False
Dim searchablePdf = Await renderer.RenderHtmlAsPdfAsync(htmlBuilder.ToString())
searchablePdf.MetaData.Title = "OCR Processed Document"
searchablePdf.MetaData.Subject = "Searchable PDF from OCR"
searchablePdf.MetaData.CreationDate = DateTime.UtcNow
searchablePdf.SecuritySettings.AllowUserPrinting = True
searchablePdf.SecuritySettings.AllowUserCopyPasteContent = True
searchablePdf.SaveAs("searchable-document.pdf")Ce processus est volontairement simple. L'étape 1 produit des fichiers PNG numérotés. L'étape 2 envoie chaque fichier à OCR .NET et collecte les chaînes de texte renvoyées. L'étape 3 encapsule ces chaînes de caractères dans du HTML et utilise IronPDF pour générer un PDF final où le texte est entièrement sélectionnable et consultable. Vous pouvez étendre l'étape 3 pour appliquer des métadonnées PDF à des fins de gestion documentaire ou des paramètres de sécurité pour le contrôle d'accès.
Quelle configuration Docker convient le mieux à ce flux de travail ?
Les constructions Docker multi-étapes permettent de conserver une image finale de petite taille tout en incluant toutes les dépendances d'exécution dont IronPDF a besoin sous Linux :
FROM mcr.microsoft.com/dotnet/sdk:8.0 AS build
WORKDIR /app
COPY *.csproj ./
RUN dotnet restore
COPY . ./
RUN dotnet publish -c Release -o out
FROM mcr.microsoft.com/dotnet/aspnet:8.0
WORKDIR /app
# IronPDF Linux runtime dependencies
RUN apt-get update && apt-get install -y \
libgdiplus \
libc6-dev \
libx11-dev \
&& rm -rf /var/lib/apt/lists/*
COPY --from=build /app/out .
HEALTHCHECK --interval=30s --timeout=3s --start-period=5s --retries=3 \
CMD curl -f http://localhost:8080/health/ready || exit 1
ENTRYPOINT ["dotnet", "OcrWorkflow.dll"]Pour une production à grande échelle, envisagez les tâches Kubernetes pour les opérations OCR par lots. Les tâches Kubernetes offrent une nouvelle tentative automatique, un contrôle du parallélisme et une isolation des ressources afin que les tâches de documents ayant échoué n'affectent pas les autres services. Configurez parallelism pour correspondre à votre niveau d'API OCR .NET et backoffLimit pour contrôler le nombre de tentatives d'un pod en échec avant que le travail ne marque la tâche comme ayant échoué.
Comment surveiller les indicateurs de performance en production ?
Le suivi des temps de traitement et des taux de réussite de la reconnaissance optique de caractères (OCR) permet d'identifier les goulots d'étranglement avant qu'ils n'affectent les utilisateurs finaux. Prometheus avec des métriques personnalisées est une approche pratique :
using Prometheus;
using System;
using System.Threading.Tasks;
// Prometheus metrics for OCR pipeline observability
var ocrRequestsTotal = Metrics
.CreateCounter("ocr_requests_total", "Total OCR requests processed");
var ocrDuration = Metrics
.CreateHistogram("ocr_duration_seconds", "OCR processing duration in seconds",
new HistogramConfiguration
{
Buckets = Histogram.LinearBuckets(0.1, 0.1, 10)
});
var activeOcrJobs = Metrics
.CreateGauge("ocr_active_jobs", "Currently active OCR jobs");
// Wrapper that tracks every OCR operation automatically
async Task<T> TrackOcrOperation<T>(Func<Task<T>> operation)
{
using (ocrDuration.NewTimer())
{
activeOcrJobs.Inc();
try
{
var result = await operation();
ocrRequestsTotal.Inc();
return result;
}
finally
{
activeOcrJobs.Dec();
}
}
}using Prometheus;
using System;
using System.Threading.Tasks;
// Prometheus metrics for OCR pipeline observability
var ocrRequestsTotal = Metrics
.CreateCounter("ocr_requests_total", "Total OCR requests processed");
var ocrDuration = Metrics
.CreateHistogram("ocr_duration_seconds", "OCR processing duration in seconds",
new HistogramConfiguration
{
Buckets = Histogram.LinearBuckets(0.1, 0.1, 10)
});
var activeOcrJobs = Metrics
.CreateGauge("ocr_active_jobs", "Currently active OCR jobs");
// Wrapper that tracks every OCR operation automatically
async Task<T> TrackOcrOperation<T>(Func<Task<T>> operation)
{
using (ocrDuration.NewTimer())
{
activeOcrJobs.Inc();
try
{
var result = await operation();
ocrRequestsTotal.Inc();
return result;
}
finally
{
activeOcrJobs.Dec();
}
}
}Imports Prometheus
Imports System
Imports System.Threading.Tasks
' Prometheus metrics for OCR pipeline observability
Dim ocrRequestsTotal = Metrics.CreateCounter("ocr_requests_total", "Total OCR requests processed")
Dim ocrDuration = Metrics.CreateHistogram("ocr_duration_seconds", "OCR processing duration in seconds",
New HistogramConfiguration With {
.Buckets = Histogram.LinearBuckets(0.1, 0.1, 10)
})
Dim activeOcrJobs = Metrics.CreateGauge("ocr_active_jobs", "Currently active OCR jobs")
' Wrapper that tracks every OCR operation automatically
Private Async Function TrackOcrOperation(Of T)(operation As Func(Of Task(Of T))) As Task(Of T)
Using ocrDuration.NewTimer()
activeOcrJobs.Inc()
Try
Dim result = Await operation()
ocrRequestsTotal.Inc()
Return result
Finally
activeOcrJobs.Dec()
End Try
End Using
End FunctionAssociez ces indicateurs aux capacités de journalisation d'IronPDF pour corréler les temps de rendu avec les durées de reconnaissance optique de caractères (OCR). Lorsque la durée de la reconnaissance optique de caractères (OCR) augmente brusquement sans augmentation correspondante du temps de rendu, le goulot d'étranglement se situe au niveau de l'appel à l'API .NET de l'OCR ou de votre chemin réseau vers celle-ci, et non au niveau de l'étape de génération du PDF.
Quelles sont vos prochaines étapes ?
L'OCR .NET combiné à IronPDF vous offre une solution pratique pour l'extraction de texte et la génération de PDF consultables en .NET. Le processus couvre les principaux cas d'utilisation : création de PDF à partir de HTML, exportation de pages à une résolution compatible avec la reconnaissance optique de caractères (OCR), envoi d'images à .NET et réassemblage des résultats dans un document entièrement consultable.
Points clés à prendre en compte lors du passage en production :
- Configuration des conteneurs : utilisez les packages IronPDF Slim et les constructions Docker multi-étapes pour limiter la taille des images.
- Planification des ressources : configurez les limites de mémoire en fonction de la taille de vos documents et de votre objectif de concurrence.
- Surveillance : Mettre en œuvre les métriques Prometheus en complément de la journalisation IronPDF afin de détecter rapidement toute dégradation.
- Débit : Utilisez les opérations asynchrones et la gestion des files d'attente par lots pour respecter les limites de débit d'OCR.net
- Fiabilité : Mettre en place une logique de nouvelle tentative avec temporisation exponentielle et des disjoncteurs autour de l'appel à l'API OCR .NET
Commencez par la licence d'essai gratuite pour tester l'intégralité du flux de travail avant de vous engager sur une licence de production. La version d'essai supprime le filigrane et débloque toutes les fonctionnalités, afin que vos résultats de référence reflètent fidèlement le comportement en production. Lorsque vous serez prêt à déployer votre solution, consultez les options de licence IronPDF pour trouver le niveau qui correspond à votre utilisation.
Questions Fréquemment Posées
Que fait OCR.net et comment se connecte-t-il avec IronPDF ?
OCR.net est un service de reconnaissance optique de caractères basé sur l'apprentissage profond qui accepte des entrées d'image et renvoie le texte reconnu. IronPDF génère des PDF et exporte leurs pages sous forme d'images. Les deux outils se connectent au niveau des images : IronPDF exporte des pages avec RasterizeToImageFiles(), ces images vont à OCR.net pour l'extraction de texte, et IronPDF réassemble les résultats en un PDF consultable.
Quelle résolution DPI devez-vous utiliser lors de l'exportation de pages PDF pour OCR ?
300 DPI est le minimum standard pour une précision OCR fiable. À 300 DPI, les bords du texte sont suffisamment nets pour que le modèle distingue des caractères similaires. À 150 DPI ou moins, la précision diminue sur les polices à empattement et les petits caractères. Utilisez 600 DPI uniquement lorsque les documents sources contiennent du texte très petit ou dégradé, car chaque page à 600 DPI produit des fichiers 4-5 fois plus volumineux.
Comment gérer les limites de taux d'API OCR.net en production ?
Les comptes gratuits d'OCR.net permettent 50 requêtes par heure. Construisez une logique de nouvelle tentative avec retour exponentiel dans votre appel OCR : interceptez la réponse 429, attendez Math.Pow(2, attempt) secondes, et réessayez jusqu'à un maximum configuré. Pour un débit plus élevé, passez à un plan OCR.net payant ou mettez en file d'attente les requêtes avec un service de travailleur en arrière-plan.
IronPDF peut-il fonctionner dans un conteneur Docker sur Linux ?
Oui. Ajoutez libgdiplus, libc6-dev, et libx11-dev à l'étape d'exécution de votre Dockerfile. Utilisez des builds multi-étapes pour garder l'image finale petite. Le variant du package IronPDF Slim réduit encore la taille de l'image en excluant les binaires de navigateur intégrés lorsque vous exécutez IronPDF Engine en tant que service distinct.
Comment créer un PDF consultable à partir des résultats OCR ?
Recueillez les chaînes de texte renvoyées par OCR.net, entourez-les dans du HTML avec une classe de saut de page par page de document, et passez le HTML à ChromePdfRenderer.RenderHtmlAsPdfAsync(). Le PDF résultant contient du texte sélectionnable, consultable que les utilisateurs et les moteurs de recherche peuvent indexer.
Ce flux de travail prend-il en charge les documents multilingues ?
Oui. OCR.net prend en charge plus de 60 langues. Sélectionnez la langue cible dans l'interface OCR.net ou l'appel d'API avant le traitement. IronPDF gère la sortie UTF-8 de manière native, de sorte que les langues avec des scripts non latins se rendent correctement dans le PDF consultable reconstruit.
Comment surveiller les performances du pipeline OCR en production ?
Ajoutez des compteurs, histogrammes et jauges Prometheus à votre service de traitement pour suivre les demandes totales, les distributions de durée et les travaux actifs. Associez les métriques Prometheus à la journalisation personnalisée d'IronPDF pour corréler les temps de rendu avec la latence de l'API OCR et identifier où les goulots d'étranglement se produisent.
Quelle est la différence entre OCR.net et IronOCR ?
OCR.net est un service web externe qui traite les images que vous téléchargez via l'API. IronOCR est une bibliothèque .NET de Iron Software qui exécute le traitement OCR localement dans votre application sans appels API externes. IronOCR est mieux adapté aux environnements hors ligne ou lorsque vous avez besoin d'une latence plus faible et d'un meilleur contrôle sur le moteur OCR.













