
OCR.netとIronPDFを使用してPDF OCRワークフローを構築する方法
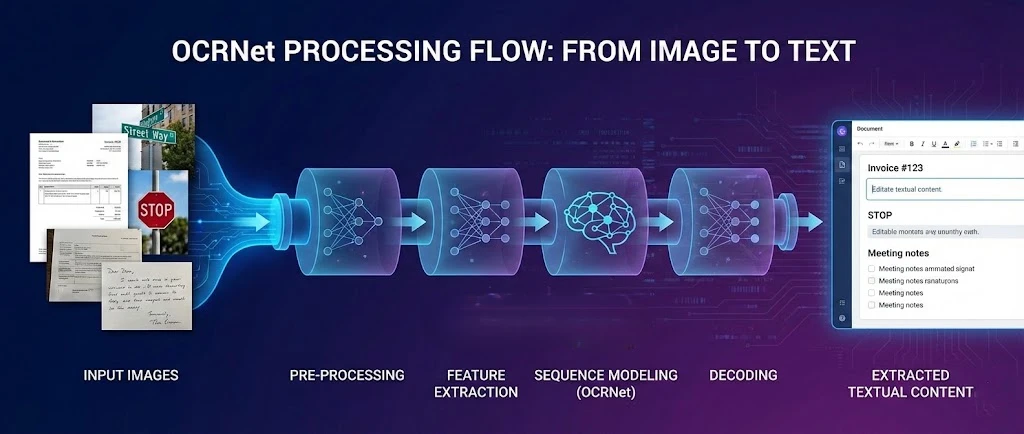
OCR .NET は、 IronPDFと組み合わせて PDF からテキストを抽出し、 .NETアプリケーションで検索可能なドキュメントを作成する、光学文字認識用のディープ ラーニング フレームワークです。 このチュートリアルでは、これら 2 つのツールを接続して、アプリケーションでスキャンされたファイルを処理し、OCR 用に PDF ページをラスタライズし、認識されたテキストを新しい検索可能な PDF に再構成する方法を説明します。
OCR .NETモデルは、複雑な環境でのシーンテキスト検出と文字認識に優れています。 これを IronPDF のレンダリング エンジンと組み合わせると、PDF を生成または読み込み、そのページを高解像度画像としてエクスポートし、それらの画像を OCR .NETに送信し、結果を完全に検索可能なドキュメントとして再構築する完全なパイプラインが得られます。
IronPDFを始めるにはどうすればいいですか?
OCR ワークフローを構築する前に、プロジェクトにIronPDFがインストールされている必要があります。 最も速いパスは、 NuGetパッケージ マネージャー コンソールです。
Install-Package IronPdfまたは、 IronPDFを検索してNuGet UI から直接追加することもできます。 インストールが完了したら、アプリケーションの起動時にライセンス キーを適用します。
using IronPdf;
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";using IronPdf;
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";Imports IronPdf
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY"無料の試用ライセンスが用意されているので、制限なしに完全な機能セットをテストできます。 IronPDF は、Windows、Linux、macOS で.NET 6、7、8、10 をサポートしているため、デスクトップ アプリ、 ASP.NET Core Web サービス、コンテナー化されたデプロイメントで同じコードが実行されます。
Docker環境向けに、 IronPDFは事前構成済みのLinuxデプロイメントガイドと、イメージサイズを縮小するスリムパッケージバリアントを提供しています。リモートレンダリングアーキテクチャをご希望の場合は、 IronPDFエンジンを、サポートされている任意のプラットフォーム上のクライアントで独立したサービスとして実行できます。
OCRNetとは何ですか、光学式文字認識はどのように機能しますか?
OCR .NETは、さまざまなフォント スタイルの英数字を認識する光学式文字認識 (OCR) に対するディープ ラーニング アプローチです。 このモデルは、最適化されたニューラル ネットワーク アーキテクチャを使用して、入力画像から空間的な特徴をキャプチャします。 これらのトレーニング済みモデルは、 PDF 生成機能と組み合わせることで、一般的なドキュメント タイプ全体にわたって高い精度の認識を実現します。
OCR .NETの背後にある認識フレームワークには、特徴学習を改善し、画像ベースのシーケンス認識タスクを処理するための Gated Recurrent Unit (GRU) が組み込まれています。 このハイブリッド モデルは、もともとシーケンス ラベル付け用に導入され、ドキュメント OCR にもうまく移行できる手法であるコネクショニスト時間分類 (CTC) を通じて、顕著な精度を実現します。 継続的な改善により、特にPDF テキスト抽出ツールと統合された場合、OCR.net の言語サポートが拡張され続けます。
最新の OCR パイプラインの主要コンポーネントは次のとおりです。
-テキスト検出:訓練されたモデルを使用して画像内のテキストコンテンツ領域を識別する -シーンテキスト検出:複雑な背景や動的な環境におけるテキストの検出 -英数字文字認識:訓練されたモデルを使用して、高い検証精度で文字を認識します -パターン認識:軽量シーンテキスト認識のための画像処理技術の適用
GRU ベースのアーキテクチャとコネクショニスト時間分類により、コンテナ化された環境での効率的なリソース使用が可能になり、メモリと CPU の制約が重要となるKubernetes デプロイメントにとって OCR .NETは実用的な選択肢となります。 軽量アーキテクチャにより、強力な認識精度を維持しながらDocker イメージのサイズを管理しやすくなります。
従来の OCR ライブラリではなく OCR .NETを使用すべきなのはどのような場合ですか?
OCR .NET は、テンプレートベースの OCR が失敗する複雑なシーン テキスト、手書きの文書、または多言語コンテンツを処理する際により適切な選択肢です。 外部依存なしにハードウェア構成全体で一貫したパフォーマンスを必要とするコンテナ化されたアプリケーションでは特に優れたパフォーマンスを発揮します。 このモデルはUTF-8 エンコードを適切に処理します。これは国際言語のサポートに重要です。
従来の正規表現ベースまたはテンプレート マッチング OCR システムは、可変フォント、手書き、または照明が不均一な画像では機能しません。 OCR.net のニューラル アプローチは、固定テンプレートを一致させるのではなく、特徴を学習するため、これらのシナリオ全体でより適切に一般化されます。 ただし、ドキュメントが一貫した書式で機械入力されたクリーンなテキストである場合は、軽量のライブラリの方が高速で十分な場合があります。
運用中の OCR .NETの一般的なリソース要件は何ですか?
実稼働環境では、安定したパフォーマンスを得るために、通常、2 ~ 4 個の CPU コアと 4 ~ 8 GB の RAM が必要です。 GPUアクセラレーションは、NVIDIA Dockerランタイムを使用したコンテナ環境におけるバッチ処理を大幅に高速化します。これらの要件はAzure App ServiceおよびAWS Lambdaのデプロイメントに適していますが、Lambdaのメモリ上限を考慮すると、コミット前に具体的なドキュメントサイズをベンチマークする必要があります。
IronPDF はどのようにして OCR 処理用の PDF ドキュメントを作成するのでしょうか?
IronPDF を使用すると、 .NET開発者は PDF 生成を完全に制御できます。 このライブラリは、Chromeベースのレンダリングエンジンを使用して、 HTML文字列、 URL 、ファイル入力を洗練されたPDFに変換できます。OCRワークフローにおいて重要な機能は、PDFページを認識に適した高解像度画像としてエクスポートするRasterizeToImageFiles()です。
using IronPdf;
// Create a PDF document with IronPDF
var renderer = new ChromePdfRenderer();
// Set 300 DPI for OCR accuracy -- higher DPI preserves text sharpness
renderer.RenderingOptions.PaperSize = IronPdf.Rendering.PdfPaperSize.A4;
renderer.RenderingOptions.DPI = 300;
renderer.RenderingOptions.MarginTop = 50;
renderer.RenderingOptions.MarginBottom = 50;
var pdf = renderer.RenderHtmlAsPdf(@"
<h1>Document Report</h1>
<p>Scene text integration for computer vision analysis.</p>
<p>Text detection results for dataset and model analysis.</p>");
// Tag the document with searchable metadata
pdf.MetaData.Author = "OCR Processing Pipeline";
pdf.MetaData.Keywords = "OCR, Text Recognition, Computer Vision";
pdf.MetaData.ModifiedDate = DateTime.Now;
pdf.SaveAs("document-for-ocr.pdf");
// Export pages as PNG images for OCR.net -- 300 DPI is the recommended minimum
pdf.RasterizeToImageFiles("page-*.png", IronPdf.Imaging.ImageType.Png, 300);using IronPdf;
// Create a PDF document with IronPDF
var renderer = new ChromePdfRenderer();
// Set 300 DPI for OCR accuracy -- higher DPI preserves text sharpness
renderer.RenderingOptions.PaperSize = IronPdf.Rendering.PdfPaperSize.A4;
renderer.RenderingOptions.DPI = 300;
renderer.RenderingOptions.MarginTop = 50;
renderer.RenderingOptions.MarginBottom = 50;
var pdf = renderer.RenderHtmlAsPdf(@"
<h1>Document Report</h1>
<p>Scene text integration for computer vision analysis.</p>
<p>Text detection results for dataset and model analysis.</p>");
// Tag the document with searchable metadata
pdf.MetaData.Author = "OCR Processing Pipeline";
pdf.MetaData.Keywords = "OCR, Text Recognition, Computer Vision";
pdf.MetaData.ModifiedDate = DateTime.Now;
pdf.SaveAs("document-for-ocr.pdf");
// Export pages as PNG images for OCR.net -- 300 DPI is the recommended minimum
pdf.RasterizeToImageFiles("page-*.png", IronPdf.Imaging.ImageType.Png, 300);Imports IronPdf
' Create a PDF document with IronPDF
Dim renderer As New ChromePdfRenderer()
' Set 300 DPI for OCR accuracy -- higher DPI preserves text sharpness
renderer.RenderingOptions.PaperSize = IronPdf.Rendering.PdfPaperSize.A4
renderer.RenderingOptions.DPI = 300
renderer.RenderingOptions.MarginTop = 50
renderer.RenderingOptions.MarginBottom = 50
Dim pdf = renderer.RenderHtmlAsPdf("
<h1>Document Report</h1>
<p>Scene text integration for computer vision analysis.</p>
<p>Text detection results for dataset and model analysis.</p>")
' Tag the document with searchable metadata
pdf.MetaData.Author = "OCR Processing Pipeline"
pdf.MetaData.Keywords = "OCR, Text Recognition, Computer Vision"
pdf.MetaData.ModifiedDate = DateTime.Now
pdf.SaveAs("document-for-ocr.pdf")
' Export pages as PNG images for OCR.net -- 300 DPI is the recommended minimum
pdf.RasterizeToImageFiles("page-*.png", IronPdf.Imaging.ImageType.Png, 300)RasterizeToImageFiles() メソッドは、指定された DPI で PDF ページを PNG 画像に変換します。 300 DPI では、テキストのエッジは OCR モデルが似たような文字を区別できるほど鮮明のままです。 150 DPI 以下では、セリフ フォントや小さな文字の認識精度が著しく低下します。 エクスポート後、PNG ファイルを OCR .NETにアップロードするか、ローカル モデルに直接渡します。

DPI 設定が OCR の精度に影響するのはなぜですか?
より高い DPI 設定 (300 ~ 600) では、OCR モデルが文字を正確に区別するために必要なテキストの明瞭さが維持されます。 トレードオフはファイルサイズと処理時間です。300DPIの場合、A4ページ1枚で約2~3MBのPNGファイルが生成されます。 600 DPI では 8 ~ 12 MB に増加します。 ほとんどのドキュメントでは、300 DPI が適切なバランスです。 レンダリング オプションを使用すると、ドキュメントの種類ごとにこれを調整できます。また、圧縮技術を使用すると、OCR 完了後のファイル サイズを最適化できます。
IronPDF はコンテナ化された環境をどのように処理しますか?
IronPDF のネイティブ エンジンにより、 Linux 、 Windows 、 macOSコンテナー間で一貫したレンダリングが保証されます。 高可用性サービスの場合、 IronPDF はASP.NET Coreヘルスチェック エンドポイントと統合されるため、トラフィックをコンテナー インスタンスにルーティングする前に PDF レンダリングが動作していることを確認する準備および稼働プローブを実装できます。
using IronPdf;
// Kubernetes-compatible health check endpoint
var builder = WebApplication.CreateBuilder(args);
var app = builder.Build();
app.MapGet("/health/ready", async () =>
{
try
{
var renderer = new ChromePdfRenderer();
var testPdf = await renderer.RenderHtmlAsPdfAsync("<p>Health check</p>");
return testPdf.PageCount > 0 ? Results.Ok() : Results.Problem();
}
catch
{
return Results.Problem("PDF rendering unavailable");
}
});
await app.RunAsync();using IronPdf;
// Kubernetes-compatible health check endpoint
var builder = WebApplication.CreateBuilder(args);
var app = builder.Build();
app.MapGet("/health/ready", async () =>
{
try
{
var renderer = new ChromePdfRenderer();
var testPdf = await renderer.RenderHtmlAsPdfAsync("<p>Health check</p>");
return testPdf.PageCount > 0 ? Results.Ok() : Results.Problem();
}
catch
{
return Results.Problem("PDF rendering unavailable");
}
});
await app.RunAsync();Imports IronPdf
' Kubernetes-compatible health check endpoint
Dim builder = WebApplication.CreateBuilder(args)
Dim app = builder.Build()
app.MapGet("/health/ready", Async Function()
Try
Dim renderer = New ChromePdfRenderer()
Dim testPdf = Await renderer.RenderHtmlAsPdfAsync("<p>Health check</p>")
Return If(testPdf.PageCount > 0, Results.Ok(), Results.Problem())
Catch
Return Results.Problem("PDF rendering unavailable")
End Try
End Function)
Await app.RunAsync()このエンドポイントと一緒にカスタム ログを使用してレンダリング時間を取得し、完全に失敗する前に劣化しているコンテナーを特定します。
OCR.netはどのようにPDF画像からテキストを抽出しますか?
IronPDFから PNG をエクスポートしたら、それを OCR .NETにアップロードしてテキスト認識を行います。 OCR .NETパイプラインは画像を処理し、さまざまなフォント スタイルにわたって正規化されたテキスト出力を返します。 印刷されたテキストと手書きのテキストの両方を処理し、60 を超えるドキュメント言語をサポートします。
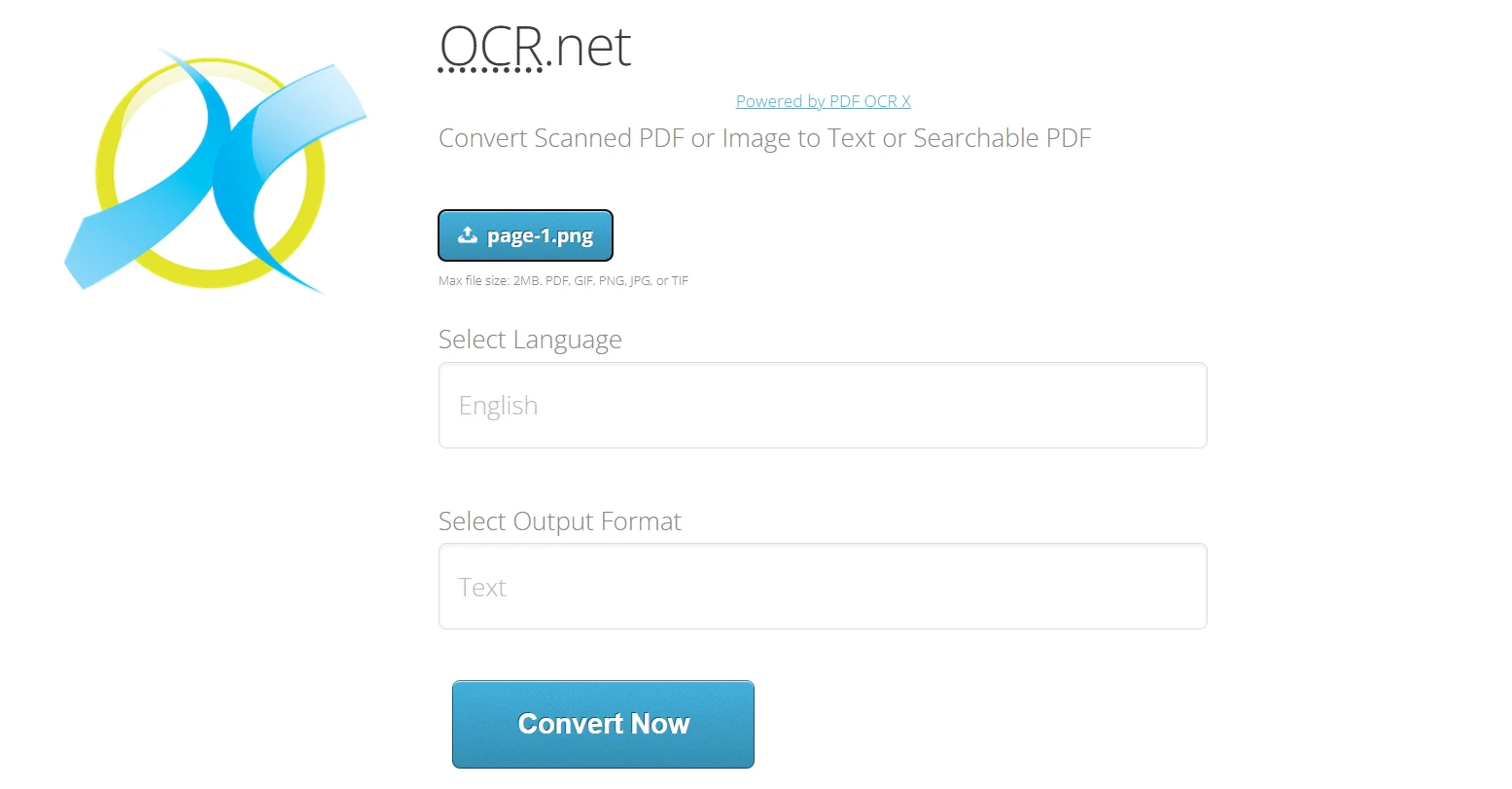
OCR.netオンラインを使用する:
1.https://ocr.net/に移動する 2.IronPDFからエクスポートしたPNGまたはJPG画像(最大2MB)をアップロードします。
- 60以上のオプションから文書の言語を選択する
- 出力形式を選択します: プレーンテキストまたは検索可能なPDF
- "今すぐ変換"をクリックして、OCR .NETモデルで画像を処理します。
OCR .NETは自動処理用の API も提供します。 無料アカウントでは 1 時間あたり 50 件のリクエストに制限されており、これは自動化されたパイプラインにとって重要な制約となります。 重大な失敗ではなく、指数バックオフを使用してレート制限応答を適切に処理するように統合を設計します。
using System;
using System.Net.Http;
using System.Threading.Tasks;
// Queue-based OCR processing with exponential backoff retry
async Task<string> ProcessOcrWithRetry(string imagePath, int maxRetries = 3)
{
for (int attempt = 0; attempt < maxRetries; attempt++)
{
try
{
// Replace with your actual OCR.net API call
return await CallOcrNetApi(imagePath);
}
catch (HttpRequestException ex) when (ex.Message.Contains("429"))
{
if (attempt == maxRetries - 1) throw;
var delay = TimeSpan.FromSeconds(Math.Pow(2, attempt));
await Task.Delay(delay);
}
}
throw new InvalidOperationException("OCR processing failed after all retries");
}using System;
using System.Net.Http;
using System.Threading.Tasks;
// Queue-based OCR processing with exponential backoff retry
async Task<string> ProcessOcrWithRetry(string imagePath, int maxRetries = 3)
{
for (int attempt = 0; attempt < maxRetries; attempt++)
{
try
{
// Replace with your actual OCR.net API call
return await CallOcrNetApi(imagePath);
}
catch (HttpRequestException ex) when (ex.Message.Contains("429"))
{
if (attempt == maxRetries - 1) throw;
var delay = TimeSpan.FromSeconds(Math.Pow(2, attempt));
await Task.Delay(delay);
}
}
throw new InvalidOperationException("OCR processing failed after all retries");
}Imports System
Imports System.Net.Http
Imports System.Threading.Tasks
' Queue-based OCR processing with exponential backoff retry
Async Function ProcessOcrWithRetry(imagePath As String, Optional maxRetries As Integer = 3) As Task(Of String)
For attempt As Integer = 0 To maxRetries - 1
Try
' Replace with your actual OCR.net API call
Return Await CallOcrNetApi(imagePath)
Catch ex As HttpRequestException When ex.Message.Contains("429")
If attempt = maxRetries - 1 Then Throw
Dim delay As TimeSpan = TimeSpan.FromSeconds(Math.Pow(2, attempt))
Await Task.Delay(delay)
End Try
Next
Throw New InvalidOperationException("OCR processing failed after all retries")
End Functionアクセシビリティ ワークフローでは、OCR テキスト抽出により、視覚障害のあるユーザーは、以前は画像のみだったドキュメントから音声フィードバックを受け取ることができます。 IronPDFを介して OCR .NET出力とPDF/UA 準拠を組み合わせると、支援技術が効果的にナビゲートできるドキュメントが作成されます。
完全なIronPDFと OCR .NETワークフローを構築するにはどうすればよいですか?
IronPDF をOCR .NETに接続すると、エンドツーエンドのドキュメント ソリューションが生成されます。 ワークフローには、PDF ページを画像としてエクスポートする、テキスト抽出のために画像を OCR .NETに送信する、認識されたテキストを新しい検索可能な PDF として再構築する、という 3 つの段階があります。
using IronPdf;
using System;
using System.Collections.Generic;
using System.Net.Http;
using System.Text;
using System.Threading.Tasks;
// --- Stage 1: Export PDF pages as images for OCR ---
var scannedPdf = PdfDocument.FromFile("input-document.pdf");
var imageFiles = scannedPdf.RasterizeToImageFiles(
"scan-page-{0}.png",
IronPdf.Imaging.ImageType.Png,
300 // 300 DPI -- minimum for reliable OCR accuracy
);
// --- Stage 2: Process each image through OCR.net ---
var ocrResults = new List<string>();
foreach (var imageFile in imageFiles)
{
// Replace this placeholder with your actual OCR.net API integration
string ocrText = await SendImageToOcrNet(imageFile);
ocrResults.Add(ocrText);
}
// --- Stage 3: Reassemble recognized text as a searchable PDF ---
var htmlBuilder = new StringBuilder();
htmlBuilder.Append(@"<!DOCTYPE html><html><head>
<style>body{font-family:Arial,sans-serif;margin:40px;}
.page{page-break-after:always;} pre{white-space:pre-wrap;}</style>
</head><body>");
for (int i = 0; i < ocrResults.Count; i++)
{
htmlBuilder.AppendFormat(
"<div class='page'><h2>Page {0}</h2><pre>{1}</pre></div>",
i + 1,
System.Web.HttpUtility.HtmlEncode(ocrResults[i])
);
}
htmlBuilder.Append("</body></html>");
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.DPI = 300;
renderer.RenderingOptions.EnableJavaScript = false;
var searchablePdf = await renderer.RenderHtmlAsPdfAsync(htmlBuilder.ToString());
searchablePdf.MetaData.Title = "OCR Processed Document";
searchablePdf.MetaData.Subject = "Searchable PDF from OCR";
searchablePdf.MetaData.CreationDate = DateTime.UtcNow;
searchablePdf.SecuritySettings.AllowUserPrinting = true;
searchablePdf.SecuritySettings.AllowUserCopyPasteContent = true;
searchablePdf.SaveAs("searchable-document.pdf");using IronPdf;
using System;
using System.Collections.Generic;
using System.Net.Http;
using System.Text;
using System.Threading.Tasks;
// --- Stage 1: Export PDF pages as images for OCR ---
var scannedPdf = PdfDocument.FromFile("input-document.pdf");
var imageFiles = scannedPdf.RasterizeToImageFiles(
"scan-page-{0}.png",
IronPdf.Imaging.ImageType.Png,
300 // 300 DPI -- minimum for reliable OCR accuracy
);
// --- Stage 2: Process each image through OCR.net ---
var ocrResults = new List<string>();
foreach (var imageFile in imageFiles)
{
// Replace this placeholder with your actual OCR.net API integration
string ocrText = await SendImageToOcrNet(imageFile);
ocrResults.Add(ocrText);
}
// --- Stage 3: Reassemble recognized text as a searchable PDF ---
var htmlBuilder = new StringBuilder();
htmlBuilder.Append(@"<!DOCTYPE html><html><head>
<style>body{font-family:Arial,sans-serif;margin:40px;}
.page{page-break-after:always;} pre{white-space:pre-wrap;}</style>
</head><body>");
for (int i = 0; i < ocrResults.Count; i++)
{
htmlBuilder.AppendFormat(
"<div class='page'><h2>Page {0}</h2><pre>{1}</pre></div>",
i + 1,
System.Web.HttpUtility.HtmlEncode(ocrResults[i])
);
}
htmlBuilder.Append("</body></html>");
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.DPI = 300;
renderer.RenderingOptions.EnableJavaScript = false;
var searchablePdf = await renderer.RenderHtmlAsPdfAsync(htmlBuilder.ToString());
searchablePdf.MetaData.Title = "OCR Processed Document";
searchablePdf.MetaData.Subject = "Searchable PDF from OCR";
searchablePdf.MetaData.CreationDate = DateTime.UtcNow;
searchablePdf.SecuritySettings.AllowUserPrinting = true;
searchablePdf.SecuritySettings.AllowUserCopyPasteContent = true;
searchablePdf.SaveAs("searchable-document.pdf");Imports IronPdf
Imports System
Imports System.Collections.Generic
Imports System.Net.Http
Imports System.Text
Imports System.Threading.Tasks
' --- Stage 1: Export PDF pages as images for OCR ---
Dim scannedPdf = PdfDocument.FromFile("input-document.pdf")
Dim imageFiles = scannedPdf.RasterizeToImageFiles(
"scan-page-{0}.png",
IronPdf.Imaging.ImageType.Png,
300 ' 300 DPI -- minimum for reliable OCR accuracy
)
' --- Stage 2: Process each image through OCR.net ---
Dim ocrResults As New List(Of String)()
For Each imageFile In imageFiles
' Replace this placeholder with your actual OCR.net API integration
Dim ocrText As String = Await SendImageToOcrNet(imageFile)
ocrResults.Add(ocrText)
Next
' --- Stage 3: Reassemble recognized text as a searchable PDF ---
Dim htmlBuilder As New StringBuilder()
htmlBuilder.Append("<!DOCTYPE html><html><head>
<style>body{font-family:Arial,sans-serif;margin:40px;}
.page{page-break-after:always;} pre{white-space:pre-wrap;}</style>
</head><body>")
For i As Integer = 0 To ocrResults.Count - 1
htmlBuilder.AppendFormat(
"<div class='page'><h2>Page {0}</h2><pre>{1}</pre></div>",
i + 1,
System.Web.HttpUtility.HtmlEncode(ocrResults(i))
)
Next
htmlBuilder.Append("</body></html>")
Dim renderer As New ChromePdfRenderer()
renderer.RenderingOptions.DPI = 300
renderer.RenderingOptions.EnableJavaScript = False
Dim searchablePdf = Await renderer.RenderHtmlAsPdfAsync(htmlBuilder.ToString())
searchablePdf.MetaData.Title = "OCR Processed Document"
searchablePdf.MetaData.Subject = "Searchable PDF from OCR"
searchablePdf.MetaData.CreationDate = DateTime.UtcNow
searchablePdf.SecuritySettings.AllowUserPrinting = True
searchablePdf.SecuritySettings.AllowUserCopyPasteContent = True
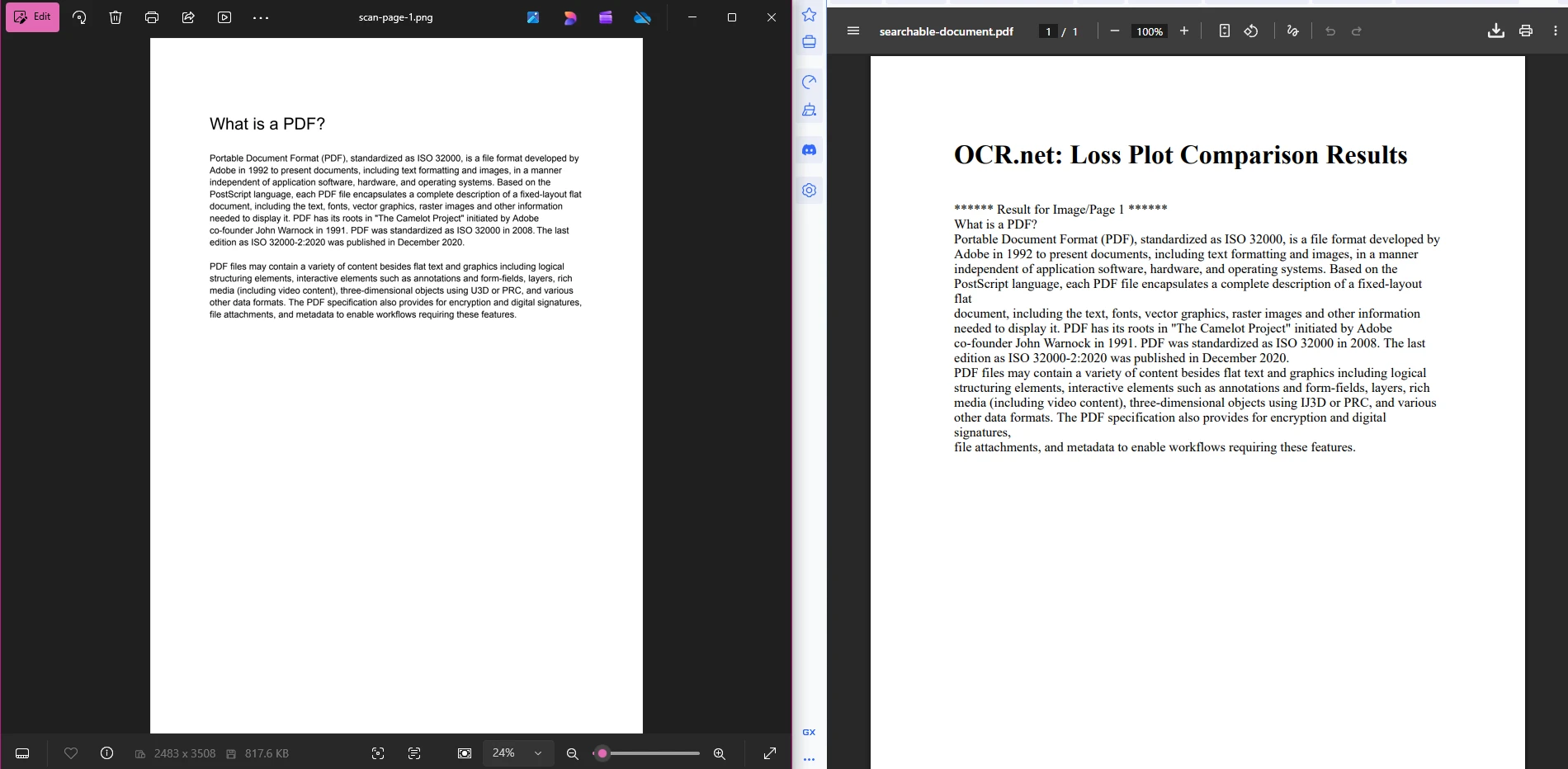
searchablePdf.SaveAs("searchable-document.pdf")このパイプラインは意図的に単純化されています。 ステージ 1 では、番号付きの PNG ファイルが生成されます。 ステージ 2 では、各ファイルを OCR .NETに送信し、返されたテキスト文字列を収集します。 ステージ 3 では、これらの文字列を HTML でラップし、 IronPDFを使用して、テキストを完全に選択および検索可能な最終的な PDF をレンダリングします。 Stage 3 を拡張して、ドキュメント管理用のPDF メタデータやアクセス制御用のセキュリティ設定を適用できます。
このワークフローに最適な Docker 構成は何ですか?
マルチステージ Docker ビルドは、Linux 上でIronPDFに必要なすべてのランタイム依存関係を含めながら、最終イメージを小さく保ちます。
FROM mcr.microsoft.com/dotnet/sdk:8.0 AS build
WORKDIR /app
COPY *.csproj ./
RUN dotnet restore
COPY . ./
RUN dotnet publish -c Release -o out
FROM mcr.microsoft.com/dotnet/aspnet:8.0
WORKDIR /app
# IronPDF Linux runtime dependencies
RUN apt-get update && apt-get install -y \
libgdiplus \
libc6-dev \
libx11-dev \
&& rm -rf /var/lib/apt/lists/*
COPY --from=build /app/out .
HEALTHCHECK --interval=30s --timeout=3s --start-period=5s --retries=3 \
CMD curl -f http://localhost:8080/health/ready || exit 1
ENTRYPOINT ["dotnet", "OcrWorkflow.dll"]実稼働規模では、バッチ OCR 操作にKubernetes ジョブを検討してください。 Kubernetes ジョブは、失敗したドキュメント タスクが他のサービスに影響を与えないように、自動再試行、並列処理制御、およびリソース分離を提供します。 parallelism を OCR .NET API 層と一致するように設定し、backoffLimit をジョブがタスクを失敗としてマークする前に失敗したポッドが再試行する回数を制御します。
運用環境でパフォーマンス メトリックをどのように監視しますか?
OCR の処理時間と成功率を追跡すると、エンドユーザーに影響を与える前にボトルネックを特定するのに役立ちます。 カスタム メトリックを使用したPrometheusは、1 つの実用的なアプローチです。
using Prometheus;
using System;
using System.Threading.Tasks;
// Prometheus metrics for OCR pipeline observability
var ocrRequestsTotal = Metrics
.CreateCounter("ocr_requests_total", "Total OCR requests processed");
var ocrDuration = Metrics
.CreateHistogram("ocr_duration_seconds", "OCR processing duration in seconds",
new HistogramConfiguration
{
Buckets = Histogram.LinearBuckets(0.1, 0.1, 10)
});
var activeOcrJobs = Metrics
.CreateGauge("ocr_active_jobs", "Currently active OCR jobs");
// Wrapper that tracks every OCR operation automatically
async Task<t> TrackOcrOperation<t>(Func<Task<t>> operation)
{
using (ocrDuration.NewTimer())
{
activeOcrJobs.Inc();
try
{
var result = await operation();
ocrRequestsTotal.Inc();
return result;
}
finally
{
activeOcrJobs.Dec();
}
}
}using Prometheus;
using System;
using System.Threading.Tasks;
// Prometheus metrics for OCR pipeline observability
var ocrRequestsTotal = Metrics
.CreateCounter("ocr_requests_total", "Total OCR requests processed");
var ocrDuration = Metrics
.CreateHistogram("ocr_duration_seconds", "OCR processing duration in seconds",
new HistogramConfiguration
{
Buckets = Histogram.LinearBuckets(0.1, 0.1, 10)
});
var activeOcrJobs = Metrics
.CreateGauge("ocr_active_jobs", "Currently active OCR jobs");
// Wrapper that tracks every OCR operation automatically
async Task<t> TrackOcrOperation<t>(Func<Task<t>> operation)
{
using (ocrDuration.NewTimer())
{
activeOcrJobs.Inc();
try
{
var result = await operation();
ocrRequestsTotal.Inc();
return result;
}
finally
{
activeOcrJobs.Dec();
}
}
}Imports Prometheus
Imports System
Imports System.Threading.Tasks
' Prometheus metrics for OCR pipeline observability
Dim ocrRequestsTotal = Metrics.CreateCounter("ocr_requests_total", "Total OCR requests processed")
Dim ocrDuration = Metrics.CreateHistogram("ocr_duration_seconds", "OCR processing duration in seconds",
New HistogramConfiguration With {
.Buckets = Histogram.LinearBuckets(0.1, 0.1, 10)
})
Dim activeOcrJobs = Metrics.CreateGauge("ocr_active_jobs", "Currently active OCR jobs")
' Wrapper that tracks every OCR operation automatically
Async Function TrackOcrOperation(Of T)(operation As Func(Of Task(Of T))) As Task(Of T)
Using ocrDuration.NewTimer()
activeOcrJobs.Inc()
Try
Dim result = Await operation()
ocrRequestsTotal.Inc()
Return result
Finally
activeOcrJobs.Dec()
End Try
End Using
End FunctionこれらのメトリックをIronPDF のログ機能と組み合わせて、レンダリング時間と OCR の継続時間を相関させます。 OCR の所要時間が急増しても、対応するレンダリング時間の急増が見られない場合、ボトルネックとなっているのは PDF 生成ステップではなく、OCR .NET API 呼び出しまたはそこへのネットワーク パスです。
次のステップは何ですか?
OCR .NETとIronPDFを組み合わせることで、 .NETでのテキスト抽出と検索可能な PDF 生成を実際に実行できるようになります。 パイプラインは、HTML から PDF を作成し、OCR 互換の解像度でページをエクスポートし、画像を OCR .NETに送信し、結果を完全に検索可能なドキュメントに再構成するというコアユースケースをカバーします。
これを本番環境に移行する際の主な考慮事項:
-コンテナのセットアップ: IronPDF Slim パッケージとマルチステージ Docker ビルドを使用して、イメージ サイズを管理しやすい状態に保ちます。 -リソース計画:ドキュメントのサイズと同時実行ターゲットに応じてメモリ制限を設定します -モニタリング: Prometheus メトリクスをIronPDF のログと併せて実装し、劣化を早期に検出します。 -スループット:非同期操作とバッチキュー管理を使用して、OCR.net のレート制限内で作業します。 -信頼性: OCR .NET API呼び出しの周りに指数バックオフ再試行ロジックとサーキットブレーカーを構築します
実稼働ライセンスを購入する前に、無料の試用ライセンスを使用して、ワークフロー全体をエンドツーエンドでテストしてください。 トライアルでは透かしが削除され、すべての機能がロック解除されるため、ベンチマーク結果が本番環境の動作を正確に反映します。 展開の準備ができたら、 IronPDF のライセンス オプションを確認して、使用パターンに一致する層を見つけます。
よくある質問
OCR.netは何をし、どのようにIronPDFと接続していますか?
OCR.netは画像入力を受け取り、認識されたテキストを返す深層学習OCRサービスです。IronPDFはPDFを生成し、それらのページを画像としてエクスポートします。この2つのツールは画像レイヤーで接続され、IronPDFがRasterizeToImageFiles()でページをエクスポートし、これらの画像がOCR.netへテキスト抽出のために送信され、IronPDFが結果を検索可能なPDFとして再組み立てします。
OCRのためにPDFページをエクスポートする際には、どのDPIを使用するべきですか?
300 DPIは信頼性のあるOCR精度の標準最小値です。300 DPIでは、テキストのエッジがモデルが類似した文字を区別するのに十分シャープです。150 DPI以下では、セリフフォントや小さな印刷で精度が低下します。ソースドキュメントが非常に小さいか劣化したテキストを含む場合にのみ600 DPIを使用してください。600 DPIでは各ページが4〜5倍大きいファイルを生成します。
運用環境でOCR.netのAPIレート制限をどのように管理していますか?
OCR.netの無料アカウントは1時間あたり50リクエストを許可します。指数バックオフ再試行ロジックをOCR呼び出しに組み込んでください: 429レスポンスをキャッチし、Math.Pow(2, attempt)秒待機し、設定された最大値まで再試行します。より高いスループットのためには、有料のOCR.netプランにアップグレードするか、バックグラウンドワーカーサービスでリクエストをキューに入れます。
IronPDFはLinux上のDockerコンテナ内で動作しますか?
はい。libgdiplus、libc6-dev、libx11-devをDockerfileのランタイムステージに追加してください。最終イメージを小さく保つためにマルチステージビルドを使用してください。IronPDF Slimパッケージバリアントは、IronPDF エンジンを別のサービスとして実行するときにバンドルされたブラウザバイナリを除外することにより、イメージサイズをさらに削減します。
OCR結果から検索可能なPDFをどのように作成しますか?
OCR.netから取得したテキストストリングを集め、文書ページごとに改ページクラスを使ってHTMLでラップし、そのHTMLをChromePdfRenderer.RenderHtmlAsPdfAsync()に渡してください。結果のPDFには、ユーザーや検索エンジンがインデックスできる選択可能で検索可能なテキストが含まれています。
このワークフローは多言語文書をサポートしていますか?
はい。OCR.netは60以上の言語をサポートしています。処理の前にOCR.netのインターフェースまたはAPI呼び出しでターゲット言語を選択してください。IronPDFはUTF-8出力をネイティブに扱えるため、非ラテン文字を持つ言語も再構築された検索可能なPDFで正しく表示されます。
運用環境でOCRパイプラインのパフォーマンスをどのように監視しますか?
全リクエスト、期間分布、アクティブなジョブを追跡するために、処理サービスにPrometheusカウンター、ヒストグラム、ゲージを追加してください。PrometheusメトリクスとIronPDFのカスタムログを組み合わせて、レンダー時間をOCR APIのレイテンシーと関連付け、ボトルネックが発生する場所を特定します。
OCR.netとIronOCRの違いは何ですか?
OCR.netは、API経由でアップロードした画像を処理する外部Webサービスです。IronOCRは外部API呼び出しなしにアプリケーション内でローカルにOCR処理を行うIron Software製 for .NETライブラリです。IronOCRはオフライン環境やOCRエンジンをより低レイテンシーで制御したい場合に適しています。












