
如何使用OCR.net和IronPDF用C#構建PDF OCR工作流程
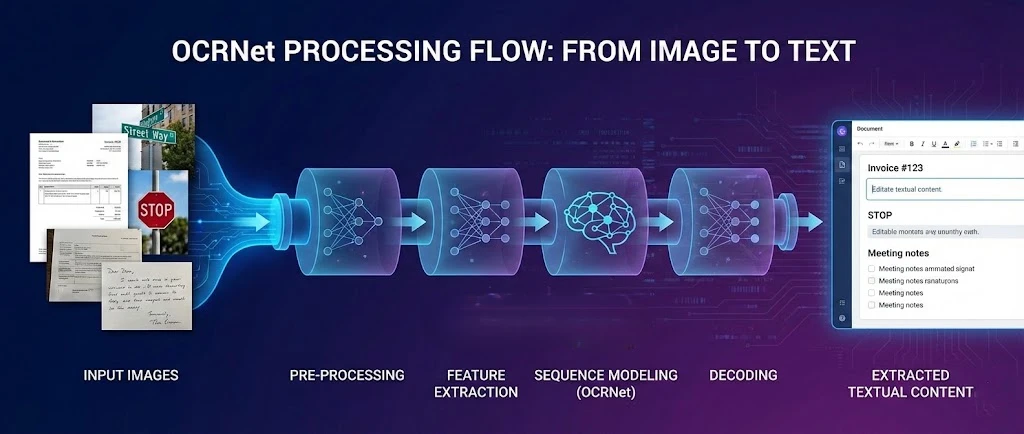
OCR.net 是一個用於光學字元辨識的深度學習框架,可與 IronPDF 搭配使用,從 PDF 檔案中擷取文字,並在 .NET Framework 應用程式中產生可搜尋的文件。 本教學將向您展示如何串接這兩項工具,讓您的應用程式能夠處理掃描檔案、將 PDF 頁面柵格化以進行 OCR,並將辨識出的文字重新組合成一份可搜尋的新 PDF 檔案。
OCR.net 模型在複雜環境中具備出色的場景文字偵測與字元辨識能力。 當您將其與 IronPDF 的渲染引擎結合使用時,即可獲得完整的處理流程:生成或載入 PDF 檔案、將其頁面匯出為高解析度圖像、將這些圖像傳送至 OCR.net,並將結果重建為可完整搜尋的文件。
!{--01001100010010010100001001010010010000010101001001011001010111110100011101000101010101 01000101111101010011010101000100000101010010010101000100010101000100010111110101011101001000110 1010101000100100001011111010100000101001001001111010001000101010101010000110101010100101010101011 10101010001010010010010010010000010100110001011111010000100100110001001111101000011010010111111010000110100101110--
如何開始使用 IronPDF?
在建立 OCR 工作流程之前,您需要在專案中安裝 IronPDF。 最快捷的方式是透過 NuGet 套件管理員主控台:
Install-Package IronPDF或透過 NuGet 介面直接搜尋 IronPdf 進行安裝。 安裝完成後,請於應用程式啟動時輸入您的授權金鑰:
using IronPdf;
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";using IronPdf;
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";Imports IronPdf
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY"我們提供免費試用授權,讓您能無限制地測試完整功能集。 IronPDF 支援 Windows、Linux 及 macOS 平台上的 .NET 6、7、8 和 10,這意味著相同的程式碼可在桌面應用程式、ASP.NET Core 網路服務以及容器化部署環境中運行。
針對 Docker 環境,IronPDF 提供預先配置的 Linux 部署指南,以及可縮小映像檔大小的精簡套件版本。若您偏好遠端渲染架構,IronPDF Engine 可作為獨立服務運行,並支援任何受支援平台上的客戶端。
什麼是 OCRNet 以及光學字元識別如何運作?
OCR.net 是一種基於深度學習的光學字元辨識(OCR)技術,能夠辨識不同字型風格的英數字元。 該模型採用優化的神經網路架構,用於從輸入影像中擷取空間特徵。 結合 PDF 生成功能,這些經過訓練的模型能在常見文件類型上提供高精度的識別效果。
OCR.net 背後的識別框架整合了門控循環單元(GRU),用以提升特徵學習能力,並處理基於圖像的序列識別任務。 此混合模型透過聯結主義時序分類(CTC)技術實現顯著的準確度,該技術最初用於序列標記,現已成功應用於文件 OCR。 OCR.net 持續進行的改進正不斷擴展其語言支援範圍,特別是在與 PDF 文字擷取工具整合時。
現代 OCR 處理流程的主要組成部分包括:
- 文字偵測:利用訓練好的模型識別圖像中的文字內容區域
- 場景文字偵測:在複雜背景與動態環境中定位文字
- 字母數字字元識別:運用訓練好的模型,以高驗證準確度識別字元
- 模式識別:運用影像處理技術進行輕量級場景文字識別
基於 GRU 的架構與聯結主義時序分類技術,能在容器化環境中實現高效的資源利用,使 OCR.net 成為記憶體與 CPU 資源受限的 Kubernetes 部署場景中,極具實用性的選擇。 輕量級架構在維持高識別精度的同時,也能讓 Docker 映像檔大小保持在可控範圍內。
何時應選用 OCR.net 而非傳統的 OCR 函式庫?
當處理複雜場景文字、手寫文件或多語言內容時,若基於範本的 OCR 無法成功,OCR.net 便是更佳的選擇。 它在容器化應用程式中表現尤為出色,這類應用程式需要在不同硬體配置下保持一致的效能,且不依賴外部元件。 該模型能完美處理 UTF-8 編碼,這對於支援多國語言至關重要。
傳統基於正規表達式或模板匹配的 OCR 系統在處理變體字型、手寫文字或光線不均勻的圖像時往往會失效。 OCR.net 的神經網路方法在這些情境下具有更佳的泛化能力,因為它透過學習特徵來運作,而非僅匹配固定的模板。 話雖如此,若您的文件是格式一致、由機器輸入的乾淨文字,使用較輕量級的函式庫可能更快且已足夠。
OCR.net 在生產環境中有哪些常見的資源需求?
生產環境部署通常需要 2 至 4 個 CPU 核心以及 4 至 8 GB 記憶體,才能確保穩定的效能。 在採用 NVIDIA Docker 執行環境的容器化環境中,GPU 加速能顯著提升批次處理的速度。這些需求非常適合用於 Azure App Service 和 AWS Lambda 的部署,不過由於 Lambda 的記憶體上限限制,您應在正式部署前針對特定文件大小進行效能測試。
IronPDF 是如何建立供 OCR 處理的 PDF 文件的?
IronPDF 讓 .NET 開發人員能完全掌控 PDF 的生成。 該庫可以透過其基於 Chrome 的渲染引擎,將HTML 字串、 URL和文件輸入渲染成精美的 PDF 文件。對於 OCR 工作流程而言,關鍵功能是 RasterizeToImageFiles(),它可以將 PDF 頁面匯出為適合識別的高解析度影像。
using IronPdf;
// Create a PDF document with IronPDF
var renderer = new ChromePdfRenderer();
// Set 300 DPI for OCR accuracy -- higher DPI preserves text sharpness
renderer.RenderingOptions.PaperSize = IronPdf.Rendering.PdfPaperSize.A4;
renderer.RenderingOptions.DPI = 300;
renderer.RenderingOptions.MarginTop = 50;
renderer.RenderingOptions.MarginBottom = 50;
var pdf = renderer.RenderHtmlAsPdf(@"
<h1>Document Report</h1>
<p>Scene text integration for computer vision analysis.</p>
<p>Text detection results for dataset and model analysis.</p>");
// Tag the document with searchable metadata
pdf.MetaData.Author = "OCR Processing Pipeline";
pdf.MetaData.Keywords = "OCR, Text Recognition, Computer Vision";
pdf.MetaData.ModifiedDate = DateTime.Now;
pdf.SaveAs("document-for-ocr.pdf");
// Export pages as PNG images for OCR.net -- 300 DPI is the recommended minimum
pdf.RasterizeToImageFiles("page-*.png", IronPdf.Imaging.ImageType.Png, 300);using IronPdf;
// Create a PDF document with IronPDF
var renderer = new ChromePdfRenderer();
// Set 300 DPI for OCR accuracy -- higher DPI preserves text sharpness
renderer.RenderingOptions.PaperSize = IronPdf.Rendering.PdfPaperSize.A4;
renderer.RenderingOptions.DPI = 300;
renderer.RenderingOptions.MarginTop = 50;
renderer.RenderingOptions.MarginBottom = 50;
var pdf = renderer.RenderHtmlAsPdf(@"
<h1>Document Report</h1>
<p>Scene text integration for computer vision analysis.</p>
<p>Text detection results for dataset and model analysis.</p>");
// Tag the document with searchable metadata
pdf.MetaData.Author = "OCR Processing Pipeline";
pdf.MetaData.Keywords = "OCR, Text Recognition, Computer Vision";
pdf.MetaData.ModifiedDate = DateTime.Now;
pdf.SaveAs("document-for-ocr.pdf");
// Export pages as PNG images for OCR.net -- 300 DPI is the recommended minimum
pdf.RasterizeToImageFiles("page-*.png", IronPdf.Imaging.ImageType.Png, 300);Imports IronPdf
' Create a PDF document with IronPDF
Dim renderer As New ChromePdfRenderer()
' Set 300 DPI for OCR accuracy -- higher DPI preserves text sharpness
renderer.RenderingOptions.PaperSize = IronPdf.Rendering.PdfPaperSize.A4
renderer.RenderingOptions.DPI = 300
renderer.RenderingOptions.MarginTop = 50
renderer.RenderingOptions.MarginBottom = 50
Dim pdf = renderer.RenderHtmlAsPdf("
<h1>Document Report</h1>
<p>Scene text integration for computer vision analysis.</p>
<p>Text detection results for dataset and model analysis.</p>")
' Tag the document with searchable metadata
pdf.MetaData.Author = "OCR Processing Pipeline"
pdf.MetaData.Keywords = "OCR, Text Recognition, Computer Vision"
pdf.MetaData.ModifiedDate = DateTime.Now
pdf.SaveAs("document-for-ocr.pdf")
' Export pages as PNG images for OCR.net -- 300 DPI is the recommended minimum
pdf.RasterizeToImageFiles("page-*.png", IronPdf.Imaging.ImageType.Png, 300)RasterizeToImageFiles() 方法將 PDF 頁面轉換為指定 DPI 的 PNG 映像。 在 300 DPI 解析度下,文字邊緣仍足夠清晰,足以讓 OCR 模型區分外觀相似的字元。 在 150 DPI 或以下解析度下,襯線字體與小字體的辨識準確度會明顯下降。 匯出後,請將 PNG 檔案上傳至 OCR.net 或直接傳送至本地模型。

為何 DPI 設定會影響 OCR 準確度?
較高的 DPI 設定(300-600)能保持文字清晰度,這是 OCR 模型準確辨識字元所必需的。 取捨點在於檔案大小與處理時間。以 300 DPI 解析度計算,單張 A4 頁面生成的 PNG 檔案大小約為 2-3 MB。 在 600 DPI 解析度下,檔案大小會增至 8-12 MB。 對於大多數文件而言,300 DPI 是最佳的平衡點。 透過渲染選項,您可以針對不同文件類型進行調整;而壓縮技術則有助於在 OCR 完成後優化檔案大小。
IronPDF 如何處理容器化環境?
IronPDF 的原生引擎可確保在 Linux、Windows 和 macOS 容器中呈現一致的渲染效果。 針對高可用性服務,IronPDF 可與 ASP.NET Core 狀態檢查端點整合,讓您能實作就緒性與存活性探測,在將流量路由至容器實例之前,先驗證 PDF 渲染功能是否正常運作。
using IronPdf;
// Kubernetes-compatible health check endpoint
var builder = WebApplication.CreateBuilder(args);
var app = builder.Build();
app.MapGet("/health/ready", async () =>
{
try
{
var renderer = new ChromePdfRenderer();
var testPdf = await renderer.RenderHtmlAsPdfAsync("<p>Health check</p>");
return testPdf.PageCount > 0 ? Results.Ok() : Results.Problem();
}
catch
{
return Results.Problem("PDF rendering unavailable");
}
});
await app.RunAsync();using IronPdf;
// Kubernetes-compatible health check endpoint
var builder = WebApplication.CreateBuilder(args);
var app = builder.Build();
app.MapGet("/health/ready", async () =>
{
try
{
var renderer = new ChromePdfRenderer();
var testPdf = await renderer.RenderHtmlAsPdfAsync("<p>Health check</p>");
return testPdf.PageCount > 0 ? Results.Ok() : Results.Problem();
}
catch
{
return Results.Problem("PDF rendering unavailable");
}
});
await app.RunAsync();Imports IronPdf
' Kubernetes-compatible health check endpoint
Dim builder = WebApplication.CreateBuilder(args)
Dim app = builder.Build()
app.MapGet("/health/ready", Async Function()
Try
Dim renderer = New ChromePdfRenderer()
Dim testPdf = Await renderer.RenderHtmlAsPdfAsync("<p>Health check</p>")
Return If(testPdf.PageCount > 0, Results.Ok(), Results.Problem())
Catch
Return Results.Problem("PDF rendering unavailable")
End Try
End Function)
Await app.RunAsync()請配合此端點使用自訂記錄功能,以擷取渲染時間,並在容器完全故障前識別出效能下降的容器。
OCR.net 如何從 PDF 影像中萃取文字?
從 IronPDF 取得 PNG 檔案後,即可上傳至 OCR.net 進行文字辨識。 OCR.net 處理流程會處理圖像,並針對各種字型樣式返回標準化的文字輸出。 它可處理印刷及手寫文字,並支援超過 60 種文件語言。
使用 OCR.net 線上:
1.導航至 https://ocr.net/
- 上傳從 IronPDF 匯出的 PNG 或 JPG 圖片(最大 2 MB)
- 從 60 多種可用選項中選擇文件語言
- 選擇輸出格式:純文字或可搜尋 PDF
- 點擊"立即轉換"以使用 OCR.net 模型處理該圖片
OCR.net 網頁介面顯示文件上傳頁面 page-1.png,語言設定為英語,輸出格式設定為文字。
OCR.net 亦提供用於自動化處理的 API。 免費帳戶每小時限額 50 次請求,這對自動化流程而言是一項關鍵限制。 請設計您的整合方案,採用指數級回退機制來優雅地處理速率限制回應,而非直接導致操作失敗:
using System;
using System.Net.Http;
using System.Threading.Tasks;
// Queue-based OCR processing with exponential backoff retry
async Task<string> ProcessOcrWithRetry(string imagePath, int maxRetries = 3)
{
for (int attempt = 0; attempt < maxRetries; attempt++)
{
try
{
// Replace with your actual OCR.net API call
return await CallOcrNetApi(imagePath);
}
catch (HttpRequestException ex) when (ex.Message.Contains("429"))
{
if (attempt == maxRetries - 1) throw;
var delay = TimeSpan.FromSeconds(Math.Pow(2, attempt));
await Task.Delay(delay);
}
}
throw new InvalidOperationException("OCR processing failed after all retries");
}using System;
using System.Net.Http;
using System.Threading.Tasks;
// Queue-based OCR processing with exponential backoff retry
async Task<string> ProcessOcrWithRetry(string imagePath, int maxRetries = 3)
{
for (int attempt = 0; attempt < maxRetries; attempt++)
{
try
{
// Replace with your actual OCR.net API call
return await CallOcrNetApi(imagePath);
}
catch (HttpRequestException ex) when (ex.Message.Contains("429"))
{
if (attempt == maxRetries - 1) throw;
var delay = TimeSpan.FromSeconds(Math.Pow(2, attempt));
await Task.Delay(delay);
}
}
throw new InvalidOperationException("OCR processing failed after all retries");
}Imports System
Imports System.Net.Http
Imports System.Threading.Tasks
' Queue-based OCR processing with exponential backoff retry
Async Function ProcessOcrWithRetry(imagePath As String, Optional maxRetries As Integer = 3) As Task(Of String)
For attempt As Integer = 0 To maxRetries - 1
Try
' Replace with your actual OCR.net API call
Return Await CallOcrNetApi(imagePath)
Catch ex As HttpRequestException When ex.Message.Contains("429")
If attempt = maxRetries - 1 Then Throw
Dim delay As TimeSpan = TimeSpan.FromSeconds(Math.Pow(2, attempt))
Await Task.Delay(delay)
End Try
Next
Throw New InvalidOperationException("OCR processing failed after all retries")
End Function在無障礙工作流程中,OCR 文字擷取功能讓視障使用者能夠從原本僅有圖像的文件中獲得語音回饋。 透過 IronPDF 將 OCR.net 的輸出結果與 PDF/UA 標準相結合,可產生輔助技術能有效導航的文件。
如何建立完整的 IronPDF 與 OCR.net 工作流程?
將 IronPDF 與 OCR.net 結合,可提供端到端的文件解決方案。 工作流程包含三個階段:將 PDF 頁面匯出為圖片、將圖片傳送至 OCR.net 進行文字擷取,以及將辨識出的文字重新組建為可搜尋的 PDF 檔案。
using IronPdf;
using System;
using System.Collections.Generic;
using System.Net.Http;
using System.Text;
using System.Threading.Tasks;
// --- Stage 1: Export PDF pages as images for OCR ---
var scannedPdf = PdfDocument.FromFile("input-document.pdf");
var imageFiles = scannedPdf.RasterizeToImageFiles(
"scan-page-{0}.png",
IronPdf.Imaging.ImageType.Png,
300 // 300 DPI -- minimum for reliable OCR accuracy
);
// --- Stage 2: Process each image through OCR.net ---
var ocrResults = new List<string>();
foreach (var imageFile in imageFiles)
{
// Replace this placeholder with your actual OCR.net API integration
string ocrText = await SendImageToOcrNet(imageFile);
ocrResults.Add(ocrText);
}
// --- Stage 3: Reassemble recognized text as a searchable PDF ---
var htmlBuilder = new StringBuilder();
htmlBuilder.Append(@"<!DOCTYPE html><html><head>
<style>body{font-family:Arial,sans-serif;margin:40px;}
.page{page-break-after:always;} pre{white-space:pre-wrap;}</style>
</head><body>");
for (int i = 0; i < ocrResults.Count; i++)
{
htmlBuilder.AppendFormat(
"<div class='page'><h2>Page {0}</h2><pre>{1}</pre></div>",
i + 1,
System.Web.HttpUtility.HtmlEncode(ocrResults[i])
);
}
htmlBuilder.Append("</body></html>");
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.DPI = 300;
renderer.RenderingOptions.EnableJavaScript = false;
var searchablePdf = await renderer.RenderHtmlAsPdfAsync(htmlBuilder.ToString());
searchablePdf.MetaData.Title = "OCR Processed Document";
searchablePdf.MetaData.Subject = "Searchable PDF from OCR";
searchablePdf.MetaData.CreationDate = DateTime.UtcNow;
searchablePdf.SecuritySettings.AllowUserPrinting = true;
searchablePdf.SecuritySettings.AllowUserCopyPasteContent = true;
searchablePdf.SaveAs("searchable-document.pdf");using IronPdf;
using System;
using System.Collections.Generic;
using System.Net.Http;
using System.Text;
using System.Threading.Tasks;
// --- Stage 1: Export PDF pages as images for OCR ---
var scannedPdf = PdfDocument.FromFile("input-document.pdf");
var imageFiles = scannedPdf.RasterizeToImageFiles(
"scan-page-{0}.png",
IronPdf.Imaging.ImageType.Png,
300 // 300 DPI -- minimum for reliable OCR accuracy
);
// --- Stage 2: Process each image through OCR.net ---
var ocrResults = new List<string>();
foreach (var imageFile in imageFiles)
{
// Replace this placeholder with your actual OCR.net API integration
string ocrText = await SendImageToOcrNet(imageFile);
ocrResults.Add(ocrText);
}
// --- Stage 3: Reassemble recognized text as a searchable PDF ---
var htmlBuilder = new StringBuilder();
htmlBuilder.Append(@"<!DOCTYPE html><html><head>
<style>body{font-family:Arial,sans-serif;margin:40px;}
.page{page-break-after:always;} pre{white-space:pre-wrap;}</style>
</head><body>");
for (int i = 0; i < ocrResults.Count; i++)
{
htmlBuilder.AppendFormat(
"<div class='page'><h2>Page {0}</h2><pre>{1}</pre></div>",
i + 1,
System.Web.HttpUtility.HtmlEncode(ocrResults[i])
);
}
htmlBuilder.Append("</body></html>");
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.DPI = 300;
renderer.RenderingOptions.EnableJavaScript = false;
var searchablePdf = await renderer.RenderHtmlAsPdfAsync(htmlBuilder.ToString());
searchablePdf.MetaData.Title = "OCR Processed Document";
searchablePdf.MetaData.Subject = "Searchable PDF from OCR";
searchablePdf.MetaData.CreationDate = DateTime.UtcNow;
searchablePdf.SecuritySettings.AllowUserPrinting = true;
searchablePdf.SecuritySettings.AllowUserCopyPasteContent = true;
searchablePdf.SaveAs("searchable-document.pdf");Imports IronPdf
Imports System
Imports System.Collections.Generic
Imports System.Net.Http
Imports System.Text
Imports System.Threading.Tasks
' --- Stage 1: Export PDF pages as images for OCR ---
Dim scannedPdf = PdfDocument.FromFile("input-document.pdf")
Dim imageFiles = scannedPdf.RasterizeToImageFiles(
"scan-page-{0}.png",
IronPdf.Imaging.ImageType.Png,
300 ' 300 DPI -- minimum for reliable OCR accuracy
)
' --- Stage 2: Process each image through OCR.net ---
Dim ocrResults As New List(Of String)()
For Each imageFile In imageFiles
' Replace this placeholder with your actual OCR.net API integration
Dim ocrText As String = Await SendImageToOcrNet(imageFile)
ocrResults.Add(ocrText)
Next
' --- Stage 3: Reassemble recognized text as a searchable PDF ---
Dim htmlBuilder As New StringBuilder()
htmlBuilder.Append("<!DOCTYPE html><html><head>
<style>body{font-family:Arial,sans-serif;margin:40px;}
.page{page-break-after:always;} pre{white-space:pre-wrap;}</style>
</head><body>")
For i As Integer = 0 To ocrResults.Count - 1
htmlBuilder.AppendFormat(
"<div class='page'><h2>Page {0}</h2><pre>{1}</pre></div>",
i + 1,
System.Web.HttpUtility.HtmlEncode(ocrResults(i))
)
Next
htmlBuilder.Append("</body></html>")
Dim renderer As New ChromePdfRenderer()
renderer.RenderingOptions.DPI = 300
renderer.RenderingOptions.EnableJavaScript = False
Dim searchablePdf = Await renderer.RenderHtmlAsPdfAsync(htmlBuilder.ToString())
searchablePdf.MetaData.Title = "OCR Processed Document"
searchablePdf.MetaData.Subject = "Searchable PDF from OCR"
searchablePdf.MetaData.CreationDate = DateTime.UtcNow
searchablePdf.SecuritySettings.AllowUserPrinting = True
searchablePdf.SecuritySettings.AllowUserCopyPasteContent = True
searchablePdf.SaveAs("searchable-document.pdf")此流程刻意設計得簡明扼要。 第一階段產出編號的 PNG 檔案。 第二階段將每個檔案傳送至 OCR.net,並收集返回的文字字串。 第三階段會將這些字串封裝在 HTML 中,並使用 IronPDF 渲染出最終的 PDF 檔案,其中文字可完全選取與搜尋。 您可以擴展第三階段,以應用 PDF 元資料進行文件管理,或設定存取控制的安全設定。
!螢幕截圖並排比較了兩個 PDF 檢視器視窗 - 左側顯示的是關於"什麼是 PDF?"的掃描 PDF,右側顯示的是 OCR.net 成功提取相同文字內容的結果。
哪種 Docker 配置最適合此工作流程?
多階段 Docker 建置可在包含 IronPDF 在 Linux 環境下所需的所有執行時依賴項的同時,保持最終映像檔的體積精簡:
FROM mcr.microsoft.com/dotnet/sdk:8.0 AS build
WORKDIR /app
COPY *.csproj ./
RUN dotnet restore
COPY . ./
RUN dotnet publish -c Release -o out
FROM mcr.microsoft.com/dotnet/aspnet:8.0
WORKDIR /app
# IronPDF Linux runtime dependencies
RUN apt-get update && apt-get install -y \
libgdiplus \
libc6-dev \
libx11-dev \
&& rm -rf /var/lib/apt/lists/*
COPY --from=build /app/out .
HEALTHCHECK --interval=30s --timeout=3s --start-period=5s --retries=3 \
CMD curl -f http://localhost:8080/health/ready || exit 1
ENTRYPOINT ["dotnet", "OcrWorkflow.dll"]若需生產規模的應用,建議考慮使用 Kubernetes Jobs 來執行批次 OCR 作業。 Kubernetes Jobs 提供自動重試、並行處理控制及資源隔離功能,確保失敗的文件處理任務不會影響其他服務。 設定 parallelism 以符合您的 OCR.net API 層,並設定 backoffLimit 以控制失敗的 pod 在 Job 將任務標記為失敗之前重試的次數。
您如何監控生產環境中的效能指標?
追蹤 OCR 處理時間與成功率,有助於在瓶頸影響終端使用者之前及早發現問題。 使用自訂指標的 Prometheus 便是一種實用的解決方案:
using Prometheus;
using System;
using System.Threading.Tasks;
// Prometheus metrics for OCR pipeline observability
var ocrRequestsTotal = Metrics
.CreateCounter("ocr_requests_total", "Total OCR requests processed");
var ocrDuration = Metrics
.CreateHistogram("ocr_duration_seconds", "OCR processing duration in seconds",
new HistogramConfiguration
{
Buckets = Histogram.LinearBuckets(0.1, 0.1, 10)
});
var activeOcrJobs = Metrics
.CreateGauge("ocr_active_jobs", "Currently active OCR jobs");
// Wrapper that tracks every OCR operation automatically
async Task<t> TrackOcrOperation<t>(Func<Task<t>> operation)
{
using (ocrDuration.NewTimer())
{
activeOcrJobs.Inc();
try
{
var result = await operation();
ocrRequestsTotal.Inc();
return result;
}
finally
{
activeOcrJobs.Dec();
}
}
}using Prometheus;
using System;
using System.Threading.Tasks;
// Prometheus metrics for OCR pipeline observability
var ocrRequestsTotal = Metrics
.CreateCounter("ocr_requests_total", "Total OCR requests processed");
var ocrDuration = Metrics
.CreateHistogram("ocr_duration_seconds", "OCR processing duration in seconds",
new HistogramConfiguration
{
Buckets = Histogram.LinearBuckets(0.1, 0.1, 10)
});
var activeOcrJobs = Metrics
.CreateGauge("ocr_active_jobs", "Currently active OCR jobs");
// Wrapper that tracks every OCR operation automatically
async Task<t> TrackOcrOperation<t>(Func<Task<t>> operation)
{
using (ocrDuration.NewTimer())
{
activeOcrJobs.Inc();
try
{
var result = await operation();
ocrRequestsTotal.Inc();
return result;
}
finally
{
activeOcrJobs.Dec();
}
}
}Imports Prometheus
Imports System
Imports System.Threading.Tasks
' Prometheus metrics for OCR pipeline observability
Dim ocrRequestsTotal = Metrics.CreateCounter("ocr_requests_total", "Total OCR requests processed")
Dim ocrDuration = Metrics.CreateHistogram("ocr_duration_seconds", "OCR processing duration in seconds",
New HistogramConfiguration With {
.Buckets = Histogram.LinearBuckets(0.1, 0.1, 10)
})
Dim activeOcrJobs = Metrics.CreateGauge("ocr_active_jobs", "Currently active OCR jobs")
' Wrapper that tracks every OCR operation automatically
Async Function TrackOcrOperation(Of T)(operation As Func(Of Task(Of T))) As Task(Of T)
Using ocrDuration.NewTimer()
activeOcrJobs.Inc()
Try
Dim result = Await operation()
ocrRequestsTotal.Inc()
Return result
Finally
activeOcrJobs.Dec()
End Try
End Using
End Function將這些指標與 IronPDF 的記錄功能結合,以關聯渲染時間與 OCR 處理時間。 當 OCR 處理時間驟增,但渲染時間並未相應增加時,瓶頸在於 OCR.net API 呼叫或您連線至該 API 的網路路徑,而非 PDF 生成步驟。
下一步計劃是什麼?
結合 OCR.net 與 IronPDF,為您在 .NET 環境中提供實用的文字擷取與可搜尋 PDF 生成解決方案。 此流程涵蓋核心使用情境:將 HTML 轉為 PDF、以支援 OCR 的解析度匯出頁面、將圖像傳送至 OCR.net,以及將結果重新組合成一份可完整搜尋的文件。
將此內容部署至生產環境時需注意的關鍵事項:
- 容器設定:使用 IronPDF Slim 套件與多階段 Docker 建置,以確保映像檔大小可控
- 資源規劃:根據文件大小與目標並發量設定適當的記憶體限制
- 監控:結合 Prometheus 指標與 IronPDF 日誌功能,以盡早偵測效能下降
- 吞吐量:透過非同步操作與批次佇列管理,在 OCR.net 的速率限制內運作
- 可靠性:針對 OCR.net API 呼叫建構指數級退避重試邏輯與斷路器機制
請先使用免費試用授權,在決定購買正式授權之前,完整測試整個工作流程。 試用版將移除浮水印並解鎖所有功能,因此您的基準測試結果能準確反映實際運作行為。 當您準備部署時,請檢視 IronPDF 的授權方案,以找到符合您使用模式的方案。
常見問題
OCR.net的功能是什麼,以及如何與IronPDF連接?
OCR.net是一個深度學習OCR服務,接受影像輸入並返回識別出的文字。 IronPDF生成PDF並將其頁面匯出為影像。這兩個工具在影像層面上連接:IronPDF使用RasterizeToImageFiles()匯出頁面,這些影像傳送到OCR.net進行文字提取,然後IronPDF將結果重新組裝為可搜尋的PDF。
導出PDF頁面進行OCR時應使用什麼DPI?
300 DPI是可靠OCR準確度的標準最低值。在300 DPI時,文本邊緣足夠清晰,以便模型區分相似字符。低於或等於150 DPI時,在襯線字體和小字上準確度下降。當原始文件包含非常小或退化的文本時,才使用600 DPI,因為每頁600 DPI會生成4-5倍大檔案。
在生產環境中如何處理OCR.net API的速率限制?
OCR.net免費帳號允許每小時50次請求。在您的OCR調用中構建指數退避重試邏輯:捕獲429響應,等待Math.Pow(2, attempt)秒,並設定最大重試次數。為了更高的吞吐量,升級至付費的OCR.net計畫或使用背景工作服務進行請求佇列。
IronPDF能否在Linux的Docker容器內運行?
可以。新增libgdiplus、libc6-dev和libx11-dev到Dockerfile的運行階段。使用多階段構建以保持最終映像小。IronPDF Slim包裝版本進一步減少映像大小,通過在您將IronPDF Engine作為單獨服務運行時排除捆綁的瀏覽器二進制文件。
如何從OCR結果創建可搜尋的PDF?
收集OCR.net返回的文本字符串,將它們用HTML包裹,並為每個文件頁添加分頁類別,然後將HTML傳遞給ChromePdfRenderer.RenderHtmlAsPdfAsync()。生成的PDF包含可選擇、可搜尋的文本,搜索引擎可以索引。
此工作流程是否支援多語言文檔?
是的。OCR.net支援60多種語言。在處理之前,在OCR.net界面或API調用中選擇目標語言。IronPDF本身能夠處理UTF-8輸出,因此具有非拉丁字符的語言在重建的可搜尋PDF中可正常呈現。
在生產環境中如何監控OCR流程性能?
將Prometheus計數器、直方圖和量測儀加入到您的處理服務中,以追踪總請求、持續時間分佈和活動作業。將Prometheus指標與IronPDF的自定義日誌配對,以對比渲染時間和OCR API延遲,找出瓶頸所在。
OCR.net和IronOCR有何不同?
OCR.net是一個外部網絡服務,透過API處理您上傳的圖像。IronOCR是來自Iron Software的.NET程式庫,在您的應用程序本地運行OCR處理,而不需要外部API調用。IronOCR適合離線環境或當您需要較低延遲和更可控的OCR引擎時。













