
Flujo de trabajo OCR con IronPDF: digitalización de facturas y documentos LOPDGDD en España
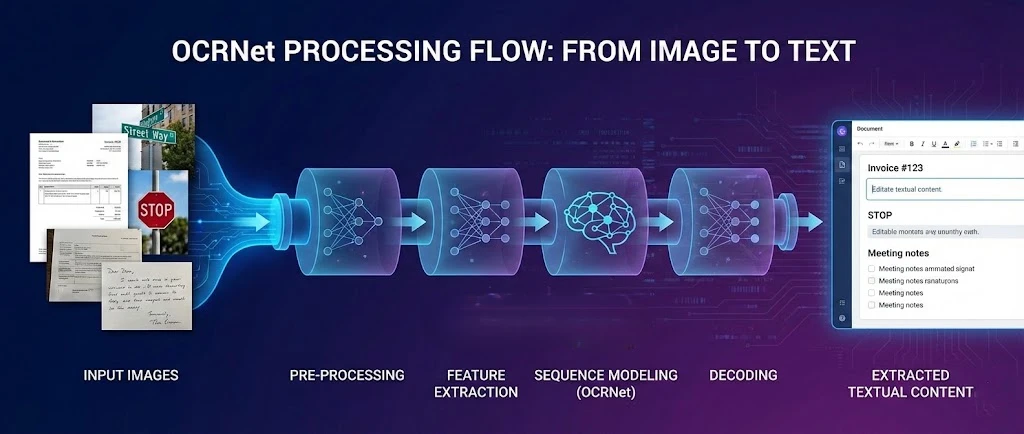
OCR .NET es un marco de aprendizaje profundo para el reconocimiento óptico de caracteres que se combina con IronPDF para extraer texto de archivos PDF y producir documentos que se pueden buscar en aplicaciones .NET. Este tutorial le muestra cómo conectar estas dos herramientas para que su aplicación pueda procesar archivos escaneados, rasterizar páginas PDF para OCR y volver a ensamblar el texto reconocido en un nuevo PDF con capacidad de búsqueda.
En el contexto del mercado español, este flujo de trabajo tiene una aplicación práctica directa: la digitalización de facturas en papel para su migración a sistemas conformes con VeriFactu o TicketBAI, el archivado de contratos y expedientes que contienen datos personales bajo los requisitos de la LOPDGDD, y la generación de PDFs con capacidad de búsqueda para cumplir con los requisitos de accesibilidad y archivado de la Ley Crea y Crece. Cuando los documentos procesados contienen datos personales de ciudadanos españoles, la AEPD (Agencia Española de Protección de Datos) exige controles de acceso que IronPDF facilita mediante cifrado y protección por contraseña en el PDF resultante.
El modelo OCR .NET se destaca en la detección de texto de escenas y el reconocimiento de caracteres en entornos complejos. Al combinarlo con el motor de renderizado de IronPDF, se obtiene un proceso completo: generar o cargar un PDF, exportar sus páginas como imágenes de alta resolución, enviar esas imágenes a OCR .NET y reconstruir los resultados como un documento totalmente buscable.
¿Cómo empezar a utilizar IronPDF?
Antes de crear el flujo de trabajo de OCR, necesita tener IronPDF instalado en su proyecto. La ruta más rápida es la consola del Administrador de paquetes NuGet :
Install-Package IronPdfO agréguelo directamente a través de la interfaz de usuario de NuGet buscando IronPDF . Una vez instalado, aplique su clave de licencia al iniciar la aplicación:
using IronPdf;
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";using IronPdf;
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";Imports IronPdf
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY"Está disponible una licencia de prueba gratuita para que pueda probar el conjunto completo de funciones sin restricciones. IronPDF es compatible con .NET 6, 7, 8 y 10 en Windows, Linux y macOS, lo que significa que el mismo código se ejecuta en aplicaciones de escritorio, servicios web ASP.NET Core e implementaciones en contenedores.
Para entornos Docker, IronPDF ofrece una guía de implementación de Linux preconfigurada y variantes de paquete Slim que reducen el tamaño de la imagen. Si prefiere una arquitectura de renderizado remoto, el motor IronPDF puede ejecutarse como un servicio independiente con clientes en cualquier plataforma compatible.
¿Qué es OCRNet y cómo funciona el reconocimiento óptico de caracteres?
OCR .NET es un enfoque de aprendizaje profundo para el reconocimiento óptico de caracteres (OCR) que reconoce caracteres alfanuméricos en diferentes estilos de fuente. El modelo utiliza una arquitectura de red neuronal optimizada para capturar características espaciales de las imágenes de entrada. Combinados con capacidades de generación de PDF , estos modelos entrenados brindan reconocimiento con gran precisión en tipos de documentos comunes.
El marco de reconocimiento detrás de OCR .NET incorpora una Unidad Recurrente Cerrada (GRU) para mejorar el aprendizaje de características y procesar tareas de reconocimiento de secuencias basadas en imágenes. Este modelo híbrido logra una precisión notable a través de la clasificación temporal conexionista (CTC), una técnica introducida originalmente para el etiquetado de secuencias que se transfiere bien al OCR de documentos. Las mejoras continuas continúan ampliando la compatibilidad de idiomas de OCR.net, especialmente cuando se integra con herramientas de extracción de texto PDF .
Los componentes clave de un moderno proceso de OCR incluyen:
- Detección de texto: identificación de regiones de contenido textual dentro de una imagen utilizando modelos entrenados
- Detección de texto en escena: localización de texto en fondos complejos y entornos dinámicos
- Reconocimiento de caracteres alfanuméricos: uso de modelos entrenados para reconocer caracteres con alta precisión de validación
- Reconocimiento de patrones: aplicación de técnicas de procesamiento de imágenes para el reconocimiento de texto en escenas ligeras
La arquitectura basada en GRU y la clasificación temporal conexionista permiten un uso eficiente de los recursos en entornos en contenedores, lo que hace de OCR .NET una opción práctica para las implementaciones de Kubernetes donde las limitaciones de memoria y CPU son importantes. La arquitectura liviana permite que los tamaños de las imágenes de Docker sean manejables y al mismo tiempo conserva una gran precisión de reconocimiento.
¿Cuándo debería utilizar OCR .NET en lugar de las bibliotecas de OCR tradicionales?
OCR .NET es la mejor opción al procesar textos de escenas complejas, documentos escritos a mano o contenido en varios idiomas donde el OCR basado en plantillas falla. Funciona particularmente bien en aplicaciones en contenedores que necesitan un rendimiento consistente en todas las configuraciones de hardware sin dependencias externas. El modelo maneja la codificación UTF-8 de forma limpia, lo que es importante para la compatibilidad con idiomas internacionales .
Los sistemas de OCR tradicionales basados en expresiones regulares o coincidencia de plantillas fallan cuando hay fuentes variables, escritura a mano o imágenes con iluminación desigual. El enfoque neuronal de OCR.net se generaliza mejor en estos escenarios porque aprende características en lugar de coincidir con plantillas fijas. Dicho esto, si sus documentos son texto limpio, escrito a máquina y con un formato consistente, una biblioteca más liviana puede ser más rápida y suficiente.
¿Cuáles son los requisitos de recursos comunes para OCR .NET en producción?
Las implementaciones de producción generalmente necesitan de 2 a 4 núcleos de CPU y de 4 a 8 GB de RAM para un rendimiento sólido. La aceleración de GPU proporciona una aceleración significativa del procesamiento por lotes en entornos de contenedores mediante el entorno de ejecución de NVIDIA Docker. Estos requisitos se adaptan bien a las implementaciones de Azure App Service y AWS Lambda , aunque el límite de memoria de Lambda implica que debe realizar una evaluación comparativa del tamaño específico de sus documentos antes de realizar la confirmación.
¿Cómo crea IronPDF documentos PDF para el procesamiento de OCR?
IronPDF ofrece a los desarrolladores .NET control total sobre la generación de PDF. La biblioteca puede renderizar cadenas HTML , URL y archivos de entrada en PDF optimizados mediante su motor de renderizado basado en Chrome. Para los flujos de trabajo de OCR, la función clave es RasterizeToImageFiles(), que exporta páginas PDF como imágenes de alta resolución aptas para el reconocimiento.
using IronPdf;
// Create a PDF document with IronPDF
var renderer = new ChromePdfRenderer();
// Set 300 DPI for OCR accuracy -- higher DPI preserves text sharpness
renderer.RenderingOptions.PaperSize = IronPdf.Rendering.PdfPaperSize.A4;
renderer.RenderingOptions.DPI = 300;
renderer.RenderingOptions.MarginTop = 50;
renderer.RenderingOptions.MarginBottom = 50;
var pdf = renderer.RenderHtmlAsPdf(@"
<h1>Document Report</h1>
<p>Scene text integration for computer vision analysis.</p>
<p>Text detection results for dataset and model analysis.</p>");
// Tag the document with searchable metadata
pdf.MetaData.Author = "OCR Processing Pipeline";
pdf.MetaData.Keywords = "OCR, Text Recognition, Computer Vision";
pdf.MetaData.ModifiedDate = DateTime.Now;
pdf.SaveAs("document-for-ocr.pdf");
// Export pages as PNG images for OCR.net -- 300 DPI is the recommended minimum
pdf.RasterizeToImageFiles("page-*.png", IronPdf.Imaging.ImageType.Png, 300);using IronPdf;
// Create a PDF document with IronPDF
var renderer = new ChromePdfRenderer();
// Set 300 DPI for OCR accuracy -- higher DPI preserves text sharpness
renderer.RenderingOptions.PaperSize = IronPdf.Rendering.PdfPaperSize.A4;
renderer.RenderingOptions.DPI = 300;
renderer.RenderingOptions.MarginTop = 50;
renderer.RenderingOptions.MarginBottom = 50;
var pdf = renderer.RenderHtmlAsPdf(@"
<h1>Document Report</h1>
<p>Scene text integration for computer vision analysis.</p>
<p>Text detection results for dataset and model analysis.</p>");
// Tag the document with searchable metadata
pdf.MetaData.Author = "OCR Processing Pipeline";
pdf.MetaData.Keywords = "OCR, Text Recognition, Computer Vision";
pdf.MetaData.ModifiedDate = DateTime.Now;
pdf.SaveAs("document-for-ocr.pdf");
// Export pages as PNG images for OCR.net -- 300 DPI is the recommended minimum
pdf.RasterizeToImageFiles("page-*.png", IronPdf.Imaging.ImageType.Png, 300);Imports IronPdf
' Create a PDF document with IronPDF
Dim renderer As New ChromePdfRenderer()
' Set 300 DPI for OCR accuracy -- higher DPI preserves text sharpness
renderer.RenderingOptions.PaperSize = IronPdf.Rendering.PdfPaperSize.A4
renderer.RenderingOptions.DPI = 300
renderer.RenderingOptions.MarginTop = 50
renderer.RenderingOptions.MarginBottom = 50
Dim pdf = renderer.RenderHtmlAsPdf("
<h1>Document Report</h1>
<p>Scene text integration for computer vision analysis.</p>
<p>Text detection results for dataset and model analysis.</p>")
' Tag the document with searchable metadata
pdf.MetaData.Author = "OCR Processing Pipeline"
pdf.MetaData.Keywords = "OCR, Text Recognition, Computer Vision"
pdf.MetaData.ModifiedDate = DateTime.Now
pdf.SaveAs("document-for-ocr.pdf")
' Export pages as PNG images for OCR.net -- 300 DPI is the recommended minimum
pdf.RasterizeToImageFiles("page-*.png", IronPdf.Imaging.ImageType.Png, 300)El método RasterizeToImageFiles() convierte páginas PDF en imágenes PNG en el DPI especificado. A 300 DPI, los bordes del texto permanecen lo suficientemente nítidos para que el modelo OCR distinga caracteres de aspecto similar. A 150 DPI o menos, la precisión de reconocimiento disminuye notablemente en fuentes serif y letra pequeña. Después de exportar, cargue los archivos PNG a OCR .NET o páselos directamente a un modelo local.

¿Por qué la configuración de DPI afecta la precisión del OCR?
Las configuraciones de DPI más altas (300-600) preservan la claridad del texto que el modelo OCR necesita para distinguir caracteres con precisión. La desventaja es el tamaño del archivo y el tiempo de procesamiento. A 300 ppp, una sola página A4 produce un PNG de aproximadamente 2-3 MB. A 600 DPI, este aumenta hasta 8-12 MB. Para la mayoría de los documentos, 300 DPI es el equilibrio adecuado. Las opciones de representación le permiten ajustar esto según el tipo de documento, mientras que las técnicas de compresión ayudan a optimizar el tamaño de los archivos una vez que se completa el OCR.
¿Cómo gestiona IronPDF los entornos en contenedores?
El motor nativo de IronPDF garantiza una representación consistente en contenedores Linux , Windows y macOS . Para servicios de alta disponibilidad, IronPDF se integra con los puntos finales de verificación de estado de ASP.NET Core para que pueda implementar sondas de preparación y actividad que verifiquen que la representación de PDF esté operativa antes de enrutar el tráfico a una instancia de contenedor.
using IronPdf;
// Kubernetes-compatible health check endpoint
var builder = WebApplication.CreateBuilder(args);
var app = builder.Build();
app.MapGet("/health/ready", async () =>
{
try
{
var renderer = new ChromePdfRenderer();
var testPdf = await renderer.RenderHtmlAsPdfAsync("<p>Health check</p>");
return testPdf.PageCount > 0 ? Results.Ok() : Results.Problem();
}
catch
{
return Results.Problem("PDF rendering unavailable");
}
});
await app.RunAsync();using IronPdf;
// Kubernetes-compatible health check endpoint
var builder = WebApplication.CreateBuilder(args);
var app = builder.Build();
app.MapGet("/health/ready", async () =>
{
try
{
var renderer = new ChromePdfRenderer();
var testPdf = await renderer.RenderHtmlAsPdfAsync("<p>Health check</p>");
return testPdf.PageCount > 0 ? Results.Ok() : Results.Problem();
}
catch
{
return Results.Problem("PDF rendering unavailable");
}
});
await app.RunAsync();Imports IronPdf
' Kubernetes-compatible health check endpoint
Dim builder = WebApplication.CreateBuilder(args)
Dim app = builder.Build()
app.MapGet("/health/ready", Async Function()
Try
Dim renderer = New ChromePdfRenderer()
Dim testPdf = Await renderer.RenderHtmlAsPdfAsync("<p>Health check</p>")
Return If(testPdf.PageCount > 0, Results.Ok(), Results.Problem())
Catch
Return Results.Problem("PDF rendering unavailable")
End Try
End Function)
Await app.RunAsync()Utilice el registro personalizado junto con este punto final para capturar los tiempos de renderizado e identificar los contenedores que se están degradando antes de que fallen por completo.
¿Cómo extrae OCR.net texto de imágenes PDF?
Una vez que tenga exportaciones PNG de IronPDF, cárguelas en OCR .NET para el reconocimiento de texto. El canal de OCR .NET procesa imágenes y devuelve una salida de texto normalizada en varios estilos de fuente. Maneja tanto texto impreso como escrito a mano y admite más de 60 idiomas de documentos.
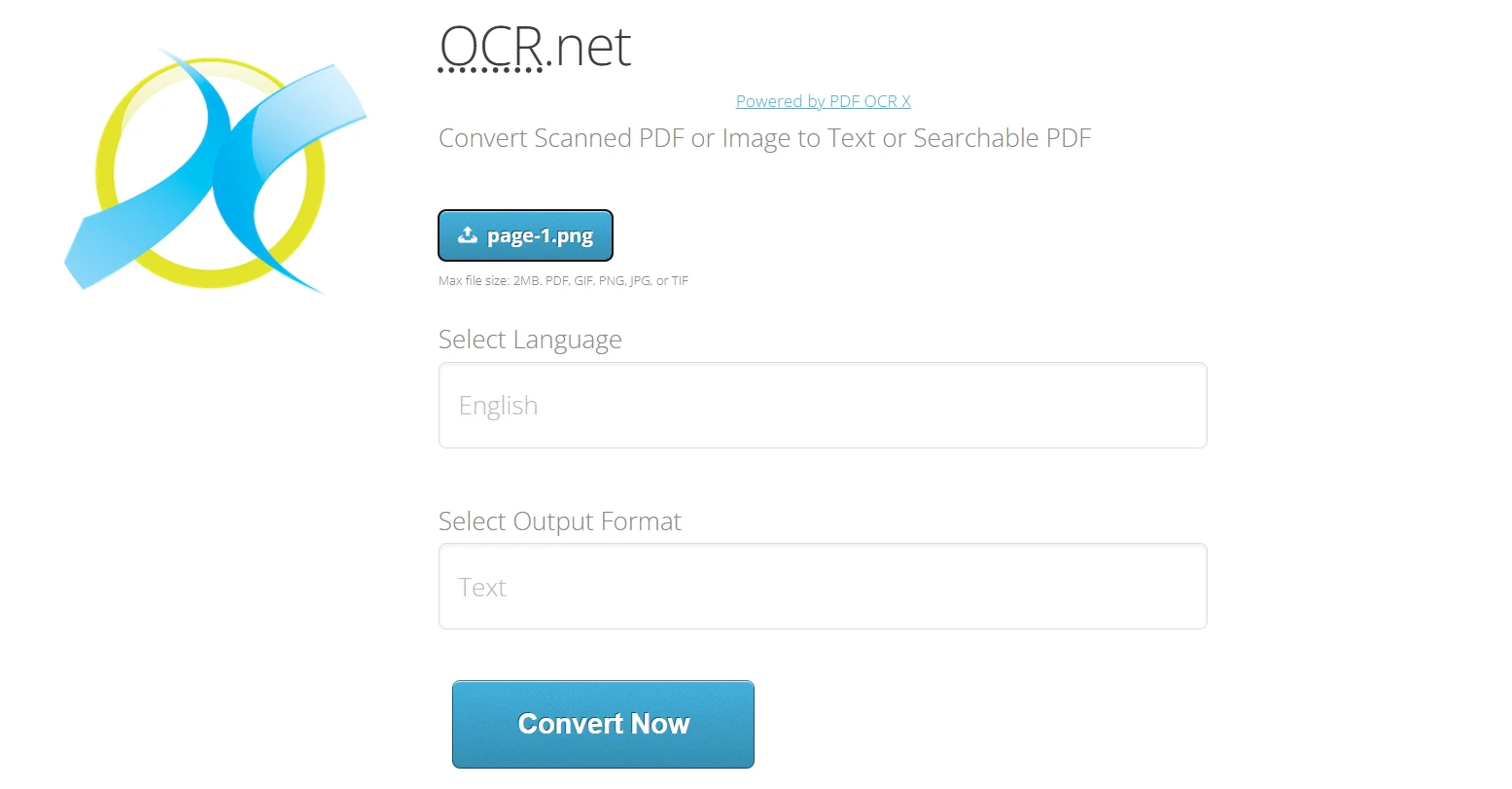
Utilización de OCR.net Online:
- Ir a https://ocr.net/
- Sube la imagen PNG o JPG (máximo 2 MB) exportada desdeIronPDF
- Seleccione el idioma del documento entre las más de 60 opciones disponibles.
- Elija el formato de salida: texto simple o PDF con capacidad de búsqueda.
- Haga clic en "Convertir ahora" para procesar la imagen con modelos OCR .NET.
OCR .NET también proporciona una API para el procesamiento automatizado. Las cuentas gratuitas están limitadas a 50 solicitudes por hora, lo que constituye una restricción crítica para las canalizaciones automatizadas. Diseñe su integración para manejar respuestas de límite de velocidad con elegancia y retroceso exponencial en lugar de fallar drásticamente:
using System;
using System.Net.Http;
using System.Threading.Tasks;
// Queue-based OCR processing with exponential backoff retry
async Task<string> ProcessOcrWithRetry(string imagePath, int maxRetries = 3)
{
for (int attempt = 0; attempt < maxRetries; attempt++)
{
try
{
// Replace with your actual OCR.net API call
return await CallOcrNetApi(imagePath);
}
catch (HttpRequestException ex) when (ex.Message.Contains("429"))
{
if (attempt == maxRetries - 1) throw;
var delay = TimeSpan.FromSeconds(Math.Pow(2, attempt));
await Task.Delay(delay);
}
}
throw new InvalidOperationException("OCR processing failed after all retries");
}using System;
using System.Net.Http;
using System.Threading.Tasks;
// Queue-based OCR processing with exponential backoff retry
async Task<string> ProcessOcrWithRetry(string imagePath, int maxRetries = 3)
{
for (int attempt = 0; attempt < maxRetries; attempt++)
{
try
{
// Replace with your actual OCR.net API call
return await CallOcrNetApi(imagePath);
}
catch (HttpRequestException ex) when (ex.Message.Contains("429"))
{
if (attempt == maxRetries - 1) throw;
var delay = TimeSpan.FromSeconds(Math.Pow(2, attempt));
await Task.Delay(delay);
}
}
throw new InvalidOperationException("OCR processing failed after all retries");
}Imports System
Imports System.Net.Http
Imports System.Threading.Tasks
' Queue-based OCR processing with exponential backoff retry
Async Function ProcessOcrWithRetry(imagePath As String, Optional maxRetries As Integer = 3) As Task(Of String)
For attempt As Integer = 0 To maxRetries - 1
Try
' Replace with your actual OCR.net API call
Return Await CallOcrNetApi(imagePath)
Catch ex As HttpRequestException When ex.Message.Contains("429")
If attempt = maxRetries - 1 Then Throw
Dim delay As TimeSpan = TimeSpan.FromSeconds(Math.Pow(2, attempt))
Await Task.Delay(delay)
End Try
Next
Throw New InvalidOperationException("OCR processing failed after all retries")
End FunctionPara los flujos de trabajo de accesibilidad, la extracción de texto OCR permite que los usuarios con discapacidad visual reciban comentarios de audio de documentos que antes solo tenían imágenes. La combinación de la salida OCR .NET con la compatibilidad PDF/UA a través de IronPDF crea documentos que las tecnologías de asistencia pueden navegar de manera eficaz. En España, la producción de PDFs accesibles mediante PDF/UA es relevante para organismos públicos y empresas que deben cumplir con la normativa de accesibilidad del sector público (Real Decreto 1112/2018) y los requisitos de la LOPDGDD cuando los documentos procesados contienen datos personales.
¿Cómo crear un flujo de trabajo completo de IronPDF y OCR .NET ?
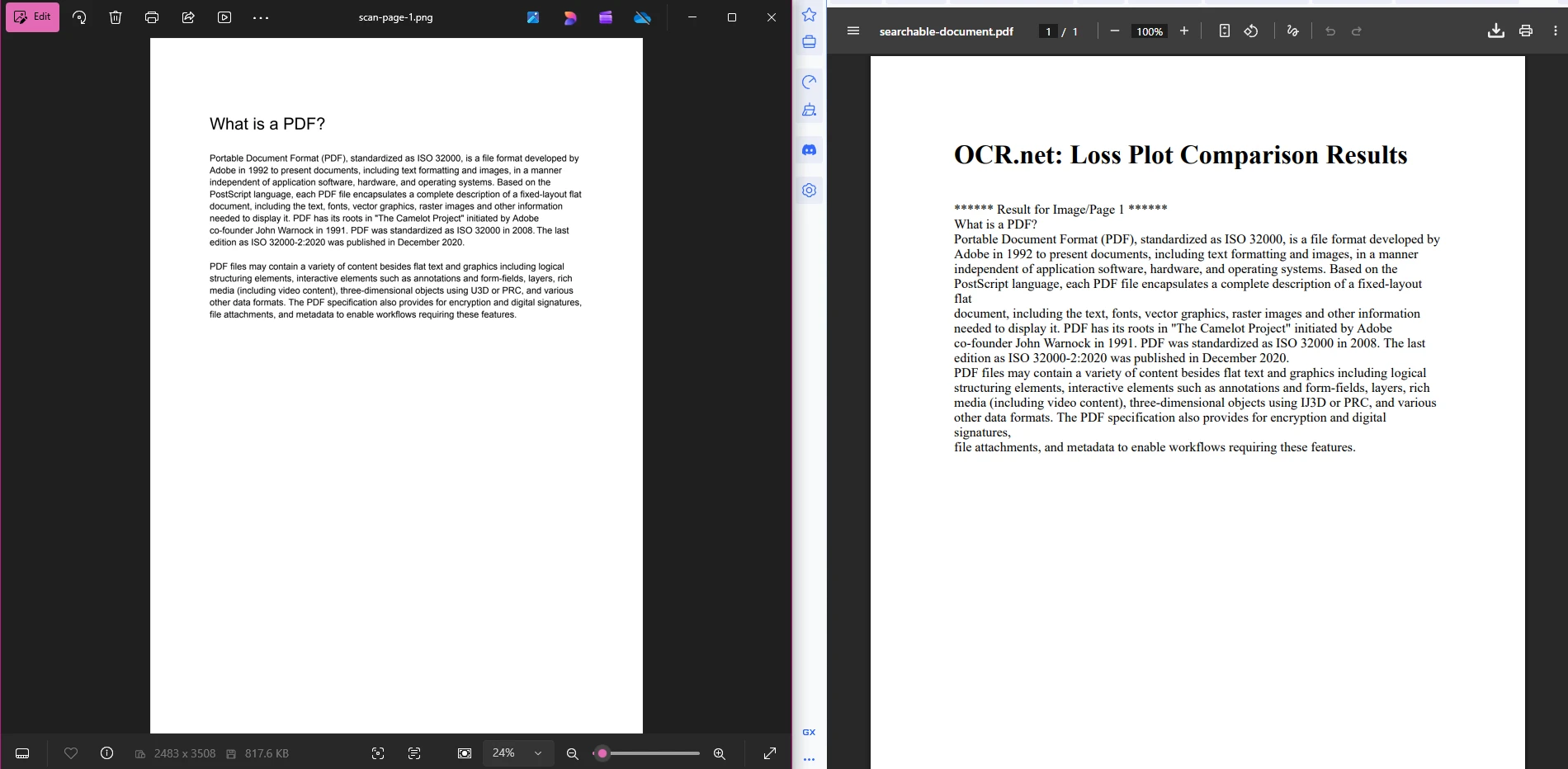
La conexión de IronPDF con OCR .NET produce soluciones de documentos de extremo a extremo. El flujo de trabajo tiene tres etapas: exportar páginas PDF como imágenes, enviar imágenes a OCR .NET para la extracción de texto y reconstruir el texto reconocido como un nuevo PDF con capacidad de búsqueda.
using IronPdf;
using System;
using System.Collections.Generic;
using System.Net.Http;
using System.Text;
using System.Threading.Tasks;
// --- Stage 1: Export PDF pages as images for OCR ---
var scannedPdf = PdfDocument.FromFile("input-document.pdf");
var imageFiles = scannedPdf.RasterizeToImageFiles(
"scan-page-{0}.png",
IronPdf.Imaging.ImageType.Png,
300 // 300 DPI -- minimum for reliable OCR accuracy
);
// --- Stage 2: Process each image through OCR.net ---
var ocrResults = new List<string>();
foreach (var imageFile in imageFiles)
{
// Replace this placeholder with your actual OCR.net API integration
string ocrText = await SendImageToOcrNet(imageFile);
ocrResults.Add(ocrText);
}
// --- Stage 3: Reassemble recognized text as a searchable PDF ---
var htmlBuilder = new StringBuilder();
htmlBuilder.Append(@"<!DOCTYPE html><html><head>
<style>body{font-family:Arial,sans-serif;margin:40px;}
.page{page-break-after:always;} pre{white-space:pre-wrap;}</style>
</head><body>");
for (int i = 0; i < ocrResults.Count; i++)
{
htmlBuilder.AppendFormat(
"<div class='page'><h2>Page {0}</h2><pre>{1}</pre></div>",
i + 1,
System.Web.HttpUtility.HtmlEncode(ocrResults[i])
);
}
htmlBuilder.Append("</body></html>");
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.DPI = 300;
renderer.RenderingOptions.EnableJavaScript = false;
var searchablePdf = await renderer.RenderHtmlAsPdfAsync(htmlBuilder.ToString());
searchablePdf.MetaData.Title = "OCR Processed Document";
searchablePdf.MetaData.Subject = "Searchable PDF from OCR";
searchablePdf.MetaData.CreationDate = DateTime.UtcNow;
searchablePdf.SecuritySettings.AllowUserPrinting = true;
searchablePdf.SecuritySettings.AllowUserCopyPasteContent = true;
searchablePdf.SaveAs("searchable-document.pdf");using IronPdf;
using System;
using System.Collections.Generic;
using System.Net.Http;
using System.Text;
using System.Threading.Tasks;
// --- Stage 1: Export PDF pages as images for OCR ---
var scannedPdf = PdfDocument.FromFile("input-document.pdf");
var imageFiles = scannedPdf.RasterizeToImageFiles(
"scan-page-{0}.png",
IronPdf.Imaging.ImageType.Png,
300 // 300 DPI -- minimum for reliable OCR accuracy
);
// --- Stage 2: Process each image through OCR.net ---
var ocrResults = new List<string>();
foreach (var imageFile in imageFiles)
{
// Replace this placeholder with your actual OCR.net API integration
string ocrText = await SendImageToOcrNet(imageFile);
ocrResults.Add(ocrText);
}
// --- Stage 3: Reassemble recognized text as a searchable PDF ---
var htmlBuilder = new StringBuilder();
htmlBuilder.Append(@"<!DOCTYPE html><html><head>
<style>body{font-family:Arial,sans-serif;margin:40px;}
.page{page-break-after:always;} pre{white-space:pre-wrap;}</style>
</head><body>");
for (int i = 0; i < ocrResults.Count; i++)
{
htmlBuilder.AppendFormat(
"<div class='page'><h2>Page {0}</h2><pre>{1}</pre></div>",
i + 1,
System.Web.HttpUtility.HtmlEncode(ocrResults[i])
);
}
htmlBuilder.Append("</body></html>");
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.DPI = 300;
renderer.RenderingOptions.EnableJavaScript = false;
var searchablePdf = await renderer.RenderHtmlAsPdfAsync(htmlBuilder.ToString());
searchablePdf.MetaData.Title = "OCR Processed Document";
searchablePdf.MetaData.Subject = "Searchable PDF from OCR";
searchablePdf.MetaData.CreationDate = DateTime.UtcNow;
searchablePdf.SecuritySettings.AllowUserPrinting = true;
searchablePdf.SecuritySettings.AllowUserCopyPasteContent = true;
searchablePdf.SaveAs("searchable-document.pdf");Imports IronPdf
Imports System
Imports System.Collections.Generic
Imports System.Net.Http
Imports System.Text
Imports System.Threading.Tasks
' --- Stage 1: Export PDF pages as images for OCR ---
Dim scannedPdf = PdfDocument.FromFile("input-document.pdf")
Dim imageFiles = scannedPdf.RasterizeToImageFiles(
"scan-page-{0}.png",
IronPdf.Imaging.ImageType.Png,
300 ' 300 DPI -- minimum for reliable OCR accuracy
)
' --- Stage 2: Process each image through OCR.net ---
Dim ocrResults As New List(Of String)()
For Each imageFile In imageFiles
' Replace this placeholder with your actual OCR.net API integration
Dim ocrText As String = Await SendImageToOcrNet(imageFile)
ocrResults.Add(ocrText)
Next
' --- Stage 3: Reassemble recognized text as a searchable PDF ---
Dim htmlBuilder As New StringBuilder()
htmlBuilder.Append("<!DOCTYPE html><html><head>
<style>body{font-family:Arial,sans-serif;margin:40px;}
.page{page-break-after:always;} pre{white-space:pre-wrap;}</style>
</head><body>")
For i As Integer = 0 To ocrResults.Count - 1
htmlBuilder.AppendFormat(
"<div class='page'><h2>Page {0}</h2><pre>{1}</pre></div>",
i + 1,
System.Web.HttpUtility.HtmlEncode(ocrResults(i))
)
Next
htmlBuilder.Append("</body></html>")
Dim renderer As New ChromePdfRenderer()
renderer.RenderingOptions.DPI = 300
renderer.RenderingOptions.EnableJavaScript = False
Dim searchablePdf = Await renderer.RenderHtmlAsPdfAsync(htmlBuilder.ToString())
searchablePdf.MetaData.Title = "OCR Processed Document"
searchablePdf.MetaData.Subject = "Searchable PDF from OCR"
searchablePdf.MetaData.CreationDate = DateTime.UtcNow
searchablePdf.SecuritySettings.AllowUserPrinting = True
searchablePdf.SecuritySettings.AllowUserCopyPasteContent = True
searchablePdf.SaveAs("searchable-document.pdf")Esta tubería es intencionadamente sencilla. La etapa 1 produce archivos PNG numerados. La etapa 2 envía cada archivo a OCR .NET y recopila las cadenas de texto devueltas. La etapa 3 envuelve esas cadenas en HTML y utiliza IronPDF para generar un PDF final donde el texto es totalmente seleccionable y buscable. Puede ampliar la Etapa 3 para aplicar metadatos PDF para la gestión de documentos o configuraciones de seguridad para el control de acceso.
Cuando los documentos procesados son facturas escaneadas en papel que deben integrarse en un sistema VeriFactu o TicketBAI, el PDF con capacidad de búsqueda resultante facilita la validación y extracción de datos para los registros de facturación electrónica. Para documentos con datos personales de ciudadanos españoles (contratos, expedientes médicos, nóminas), la LOPDGDD exige que el PDF final esté protegido con cifrado adecuado antes de su almacenamiento o transmisión.
¿Qué configuración de Docker funciona mejor para este flujo de trabajo?
Las compilaciones de Docker de varias etapas mantienen la imagen final pequeña al tiempo que incluyen todas las dependencias de tiempo de ejecución que IronPDF necesita en Linux:
FROM mcr.microsoft.com/dotnet/sdk:8.0 AS build
WORKDIR /app
COPY *.csproj ./
RUN dotnet restore
COPY . ./
RUN dotnet publish -c Release -o out
FROM mcr.microsoft.com/dotnet/aspnet:8.0
WORKDIR /app
# IronPDF Linux runtime dependencies
RUN apt-get update && apt-get install -y \
libgdiplus \
libc6-dev \
libx11-dev \
&& rm -rf /var/lib/apt/lists/*
COPY --from=build /app/out .
HEALTHCHECK --interval=30s --timeout=3s --start-period=5s --retries=3 \
CMD curl -f http://localhost:8080/health/ready || exit 1
ENTRYPOINT ["dotnet", "OcrWorkflow.dll"]Para escalar la producción, considere los trabajos de Kubernetes para operaciones de OCR por lotes. Los trabajos de Kubernetes proporcionan reintentos automáticos, control de paralelismo y aislamiento de recursos para que las tareas de documentos fallidas no afecten a otros servicios. Establezca parallelism para que coincida con su nivel de API .NET de OCR y backoffLimit para controlar cuántas veces un pod fallido vuelve a intentarlo antes de que el trabajo marque la tarea como fallida.
¿Cómo supervisar las métricas de rendimiento en producción?
El seguimiento de los tiempos de procesamiento y las tasas de éxito del OCR ayuda a identificar cuellos de botella antes de que afecten a los usuarios finales. Prometheus con métricas personalizadas es un enfoque práctico:
using Prometheus;
using System;
using System.Threading.Tasks;
// Prometheus metrics for OCR pipeline observability
var ocrRequestsTotal = Metrics
.CreateCounter("ocr_requests_total", "Total OCR requests processed");
var ocrDuration = Metrics
.CreateHistogram("ocr_duration_seconds", "OCR processing duration in seconds",
new HistogramConfiguration
{
Buckets = Histogram.LinearBuckets(0.1, 0.1, 10)
});
var activeOcrJobs = Metrics
.CreateGauge("ocr_active_jobs", "Currently active OCR jobs");
// Wrapper that tracks every OCR operation automatically
async Task<t> TrackOcrOperation<t>(Func<Task<t>> operation)
{
using (ocrDuration.NewTimer())
{
activeOcrJobs.Inc();
try
{
var result = await operation();
ocrRequestsTotal.Inc();
return result;
}
finally
{
activeOcrJobs.Dec();
}
}
}using Prometheus;
using System;
using System.Threading.Tasks;
// Prometheus metrics for OCR pipeline observability
var ocrRequestsTotal = Metrics
.CreateCounter("ocr_requests_total", "Total OCR requests processed");
var ocrDuration = Metrics
.CreateHistogram("ocr_duration_seconds", "OCR processing duration in seconds",
new HistogramConfiguration
{
Buckets = Histogram.LinearBuckets(0.1, 0.1, 10)
});
var activeOcrJobs = Metrics
.CreateGauge("ocr_active_jobs", "Currently active OCR jobs");
// Wrapper that tracks every OCR operation automatically
async Task<t> TrackOcrOperation<t>(Func<Task<t>> operation)
{
using (ocrDuration.NewTimer())
{
activeOcrJobs.Inc();
try
{
var result = await operation();
ocrRequestsTotal.Inc();
return result;
}
finally
{
activeOcrJobs.Dec();
}
}
}Imports Prometheus
Imports System
Imports System.Threading.Tasks
' Prometheus metrics for OCR pipeline observability
Dim ocrRequestsTotal = Metrics.CreateCounter("ocr_requests_total", "Total OCR requests processed")
Dim ocrDuration = Metrics.CreateHistogram("ocr_duration_seconds", "OCR processing duration in seconds",
New HistogramConfiguration With {
.Buckets = Histogram.LinearBuckets(0.1, 0.1, 10)
})
Dim activeOcrJobs = Metrics.CreateGauge("ocr_active_jobs", "Currently active OCR jobs")
' Wrapper that tracks every OCR operation automatically
Async Function TrackOcrOperation(Of T)(operation As Func(Of Task(Of T))) As Task(Of T)
Using ocrDuration.NewTimer()
activeOcrJobs.Inc()
Try
Dim result = Await operation()
ocrRequestsTotal.Inc()
Return result
Finally
activeOcrJobs.Dec()
End Try
End Using
End FunctionCombine estas métricas con las capacidades de registro de IronPDF para correlacionar los tiempos de renderizado con las duraciones de OCR. Cuando la duración del OCR aumenta sin un aumento correspondiente en el tiempo de renderizado, el cuello de botella está en la llamada a la API .NET de OCR o en su ruta de red hacia ella, no en el paso de generación de PDF.
Cumplimiento normativo en España para flujos de trabajo OCR con datos personales y facturas
Los flujos de trabajo de OCR en el mercado español están sujetos a varios marcos regulatorios que condicionan cómo se procesan, almacenan y protegen los documentos resultantes.
LOPDGDD y AEPD: protección de datos personales en documentos OCR
La Ley Orgánica de Protección de Datos y Garantía de Derechos Digitales (LOPDGDD), bajo la supervisión de la Agencia Española de Protección de Datos (AEPD), establece requisitos específicos cuando se procesan documentos que contienen datos personales de ciudadanos españoles. Facturas con NIF/CIF, contratos, nóminas o expedientes médicos procesados mediante OCR caen bajo esta normativa.
Las medidas técnicas que IronPDF facilita para el cumplimiento de la LOPDGDD incluyen:
- Cifrado del PDF resultante: aplicar contraseña de usuario y propietario mediante
SecuritySettingspara que únicamente usuarios autorizados puedan acceder al contenido extraído por OCR - Control de permisos de copia e impresión: configurar
AllowUserCopyPasteContentyAllowUserPrintingsegún el nivel de confidencialidad del documento original - Metadatos auditables: registrar en
MetaData.Author,MetaData.CreationDateyMetaData.ModifiedDatela trazabilidad del proceso de digitalización
Antes de procesar imágenes con datos personales a través de servicios externos como OCR.net, evalúe si la transferencia cumple con los artículos 44-49 del RGPD sobre transferencias internacionales. Para entornos de producción con requisitos estrictos de LOPDGDD, considere soluciones OCR que ejecuten el reconocimiento localmente, como IronOCR, que procesa los documentos sin salir de su infraestructura.
Digitalización de facturas VeriFactu y TicketBAI en papel
La digitalización de facturas en papel para su incorporación a sistemas conformes con VeriFactu (Real Decreto-Ley 15/2025) y TicketBAI (País Vasco) es un caso de uso habitual para flujos de trabajo OCR. Los proveedores de software de facturación deben garantizar que los PDFs con capacidad de búsqueda generados a partir de facturas escaneadas mantengan la integridad de los datos antes de su registro en el sistema de facturación.
Para facturas VeriFactu, el PDF digitalizado debe preservar o permitir la identificación del número de factura, importe, NIF del emisor y fecha, que son los campos que el sistema registra en la sede electrónica de la AEAT (sede.agenciatributaria.gob.es). Para facturas TicketBAI del País Vasco —en Bizkaia, Gipuzkoa y Araba— el flujo de trabajo OCR complementa la firma XAdES del registro de factura digital, pero no la sustituye: el PDF con capacidad de búsqueda sirve como representación visual accesible del documento digitalizado.
Archivado electrónico bajo la Ley Crea y Crece
La Ley 18/2022 de Creación y Crecimiento de Empresas (Crea y Crece) establece la obligación de factura electrónica entre empresas en España, con entrada en vigor prevista en 2025-2027 según el tamaño de la empresa. Las facturas en papel que deban incorporarse al sistema de facturación B2B requieren digitalización con conservación del valor probatorio.
Los PDFs con capacidad de búsqueda generados mediante el flujo de trabajo OCR .NET + IronPDF pueden servir como soporte digital para el archivo documental siempre que se apliquen las medidas de integridad apropiadas (firma digital, marca de tiempo) en el proceso de digitalización certificada.
¿Cuales son tus próximos pasos?
OCR .NET combinado con IronPDF le ofrece una ruta práctica para la extracción de texto y la generación de PDF con capacidad de búsqueda en .NET. El proceso cubre los principales casos de uso: crear archivos PDF desde HTML, exportar páginas con una resolución compatible con OCR, enviar imágenes a OCR .NET y volver a ensamblar los resultados en un documento totalmente buscable.
Consideraciones clave al trasladar esto a producción:
- Configuración del contenedor: utilice paquetes IronPDF Slim y compilaciones Docker de varias etapas para mantener tamaños de imágenes manejables
- Planificación de recursos: configure límites de memoria apropiados para el tamaño de sus documentos y su objetivo de concurrencia
- Monitoreo: Implemente métricas de Prometheus junto con el registro de IronPDF para detectar la degradación de manera temprana
- Rendimiento: utilice operaciones asincrónicas y gestión de colas por lotes para trabajar dentro de los límites de velocidad de OCR.net
- Confiabilidad: cree una lógica de reintento de retroceso exponencial y disyuntores en torno a la llamada API de OCR .NET
- Cumplimiento LOPDGDD: aplique cifrado y permisos en el PDF resultante cuando los documentos procesados contengan datos personales de ciudadanos españoles; evalúe si el procesamiento externo cumple con los artículos 44-49 del RGPD
Comience con la licencia de prueba gratuita para probar el flujo de trabajo completo de principio a fin antes de comprometerse con una licencia de producción. La versión de prueba elimina la marca de agua y desbloquea todas las funciones, por lo que los resultados de su evaluación comparativa reflejan con precisión el comportamiento de producción. Cuando esté listo para implementar, revise las opciones de licencia de IronPDF para encontrar el nivel que coincida con su patrón de uso.
Preguntas Frecuentes
¿Qué hace OCR.net y cómo se conecta con IronPDF?
OCR.net es un servicio de OCR de aprendizaje profundo que acepta entradas de imágenes y devuelve el texto reconocido. IronPDF genera PDFs y exporta sus páginas como imágenes. Las dos herramientas se conectan en la capa de imágenes: IronPDF exporta páginas con RasterizeToImageFiles(), esas imágenes van a OCR.net para la extracción de texto e IronPDF reorganiza los resultados como un PDF buscable.
¿Qué DPI deberías usar al exportar páginas de PDF para OCR?
300 DPI es el mínimo estándar para una precisión de OCR confiable. A 300 DPI, los bordes del texto son lo suficientemente nítidos para que el modelo distinga caracteres similares. A 150 DPI o menos, la precisión disminuye en fuentes serif y en impresión pequeña. Usa 600 DPI solo cuando los documentos fuente contengan texto muy pequeño o degradado, ya que cada página a 600 DPI produce archivos 4-5x más grandes.
¿Cómo manejas los límites de tasa de la API de OCR.net en producción?
Las cuentas gratuitas de OCR.net permiten 50 solicitudes por hora. Construye lógica de reintento con retroceso exponencial en tu llamada de OCR: captura la respuesta 429, espera Math.Pow(2, attempt) segundos y vuelve a intentarlo hasta un máximo configurado. Para un mayor rendimiento, actualiza a un plan de pago de OCR.net o encola las solicitudes con un servicio de trabajo en segundo plano.
¿Puede IronPDF ejecutarse dentro de un contenedor Docker en Linux?
Sí. Añade libgdiplus, libc6-dev y libx11-dev a la etapa de tiempo de ejecución de tu Dockerfile. Usa construcciones de múltiples etapas para mantener la imagen final pequeña. La variante de paquete IronPDF Slim reduce aún más el tamaño de la imagen al excluir los binarios del navegador empaquetados cuando ejecutas el IronPDF Engine como un servicio separado.
¿Cómo creas un PDF buscable a partir de los resultados de OCR?
Recoge las cadenas de texto devueltas por OCR.net, envuélvelas en HTML con una clase de salto de página por página de documento y pasa el HTML a ChromePdfRenderer.RenderHtmlAsPdfAsync(). El PDF resultante contiene texto seleccionable y buscable que los usuarios y los motores de búsqueda pueden indexar.
¿Este flujo de trabajo soporta documentos multilíngües?
Sí. OCR.net soporta más de 60 idiomas. Selecciona el idioma objetivo en la interfaz de OCR.net o en la llamada de API antes de procesar. IronPDF maneja la salida UTF-8 de forma nativa, por lo que los idiomas con scripts no latinos se renderizan correctamente en el PDF buscable reconstruido.
¿Cómo monitorizas el rendimiento del flujo de trabajo de OCR en producción?
Añade contadores, histogramas e indicadores de Prometheus a tu servicio de procesamiento para rastrear solicitudes totales, distribuciones de duración y trabajos activos. Combina las métricas de Prometheus con el registro personalizado de IronPDF para correlacionar los tiempos de procesamiento con la latencia de la API de OCR e identificar dónde ocurren los cuellos de botella.
¿Cuál es la diferencia entre OCR.net e IronOCR?
OCR.net es un servicio web externo que procesa imágenes que subes a través de una API. IronOCR es una biblioteca de .NET de Iron Software que ejecuta el procesamiento OCR localmente dentro de tu aplicación sin llamadas a API externas. IronOCR es más adecuado para entornos sin conexión o cuando necesitas menor latencia y más control sobre el motor OCR. Para entornos con requisitos estrictos de LOPDGDD en España, IronOCR elimina el riesgo de transferencia internacional de datos personales a servicios externos.
¿Qué consideraciones de la LOPDGDD aplican al digitalizar facturas y documentos con datos personales en España?
La LOPDGDD, supervisada por la AEPD, exige controles de acceso y medidas de seguridad cuando se procesan documentos con datos personales de ciudadanos españoles. Al generar el PDF con capacidad de búsqueda mediante IronPDF, aplique cifrado mediante SecuritySettings para restringir el acceso. Si envía imágenes a servicios OCR externos, verifique que el proveedor cumple con los artículos 44-49 del RGPD sobre transferencias internacionales de datos. Para mayor seguridad, opte por soluciones OCR locales como IronOCR.
¿Cómo puede este flujo de trabajo OCR ayudar con la digitalización de facturas para VeriFactu y TicketBAI?
Las facturas en papel que deban incorporarse a sistemas conformes con VeriFactu (Real Decreto-Ley 15/2025) o TicketBAI (Bizkaia, Gipuzkoa, Araba) requieren digitalización previa. El flujo de trabajo OCR .NET + IronPDF produce PDFs con capacidad de búsqueda que facilitan la extracción de campos clave (NIF, importe, fecha) para el registro en el sistema de facturación. Los PDFs resultantes pueden almacenarse con los metadatos de trazabilidad requeridos por los sistemas VeriFactu de la AEAT en sede.agenciatributaria.gob.es.
¿Este flujo de trabajo cumple con los requisitos de archivado electrónico de la Ley Crea y Crece?
La Ley 18/2022 de Creación y Crecimiento de Empresas establece la obligación de factura electrónica B2B en España. Los PDFs buscables generados mediante OCR .NET + IronPDF pueden servir como representación digital de facturas en papel para el archivo documental, siempre que se apliquen medidas de integridad (firma digital, marca de tiempo) propias de la digitalización certificada. IronPDF facilita la aplicación de firmas digitales en el proceso de generación del PDF final.












