
C#'da Örnekteki iTextSharp ve IronPDF Kullanarak PDF'ye Baslik ve Altbilgi Ekleyin
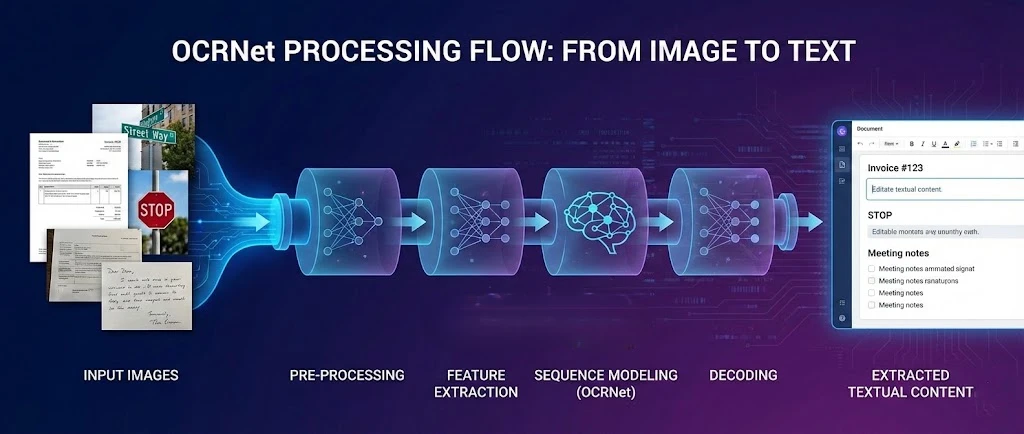
OCR.net, PDF'lerden metin çıkarmak ve .NET uygulamalarında aranabilir belgeler üretmek için IronPDF ile eşleştirilen optik karakter tanıma için derin öğrenme çerçevesidir. Bu öğretici, bu iki aracı nasıl bağlayacağınızı gösterir; böylece uygulamanız taranan dosyaları işleyebilir, PDF sayfalarını OCR için rasterize edebilir ve tanınan metni yeni bir aranabilir PDF olarak yeniden birleştirebilir.
OCR.net modeli, karmaşık ortamlarda sahne metni algılama ve karakter tanımında mükemmeldir. Bunu IronPDF'ün işleme motoru ile birleştirdiğinizde, eksiksiz bir iş akışı elde edersiniz: bir PDF oluşturma veya yükleme, sayfalarını yüksek çözünürlüklü görüntüler olarak dışa aktarma, bu görüntüleri OCR.net'e gönderme ve sonuçları tamamen aranabilir bir belge olarak yeniden oluşturma.
IronPDF'ye Nasıl Başlanır?
OCR iş akışını oluşturmadan önce, projenize IronPDF yüklemeniz gerekir. En hızlı yol, NuGet Paket Yöneticisi konsoludur:
Install-Package IronPdf
Veya doğrudan NuGet UI aracılığıyla IronPDF araması yaparak ekleyin. Yüklendikten sonra, lisans anahtarınızı uygulama başlangıcında uygulayın:
using IronPdf;
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";using IronPdf;
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";Imports IronPdf
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY"Ücretsiz deneme lisansı tam özellik kümesini herhangi bir kısıtlama olmaksızın test etmenizi sağlar. IronPDF, Windows, Linux ve macOS üzerinde .NET 6, 7, 8 ve 10'u destekler; bu da aynı kodun masaüstü uygulamalarında, ASP.NET Core web hizmetlerinde ve kapsayıcı dağıtımlarında çalıştığı anlamına gelir.
Docker ortamları için, IronPDF önceden yapılandırılmış bir Linux dağıtım kılavuzu ve görüntü boyutunu azaltan ince paket varyantları sunar. Uzaktan işleme mimarisini tercih ederseniz, IronPDF Engine herhangi bir desteklenen platformda istemcilerle ayrı bir hizmet olarak çalışabilir.
OCRNet Nedir ve Optik Karakter Tanıma Nasıl Çalışır?
OCR.net, farklı yazı tipleri üzerinden alfa-nümerik karakterleri tanıyan optik karakter tanıma (OCR) için derin öğrenme yaklaşımıdır. Model, giriş görüntülerinden mekansal özellikleri yakalamak için optimize edilmiş bir sinir ağı mimarisi kullanır. PDF oluşturma yetenekleri ile birleştiğinde, bu eğitilmiş modeller olağan belge türlerinde güçlü doğrulukla tanıma sağlar.
OCR.net'in arkasındaki tanıma çerçevesi, özellik öğrenimini iyileştirmek ve görüntü tabanlı dizi tanıma görevlerini işlemek için bir Gated Recurrent Unit (GRU) içerir. Bu karma model, bağlantıcı geçici sınıflandırmanın (CTC) dikkat çekici doğruluğunu elde ederek belge OCR'ye iyi bir şekilde geçiş yapan, orijinal olarak dizi etiketleme için tanıtılan bir teknik ile etkileyici doğruluk elde eder. Süregelen geliştirmeler, özellikle PDF metin çıkarma araçları ile entegre edildiğinde OCR.net'in dil desteğini artırmaya devam ediyor.
Modern bir OCR boru hattının kilit bileşenleri şunlardır:
- Metin Algılama: Eğitilmiş modeller kullanarak bir görüntü içindeki metin içeriği bölgelerinin belirlenmesi
- Sahne Metni Algılama: Karmaşık arka planlar ve dinamik ortamlarda metin bulma
- Alfanümerik Karakter Tanıma: Eğitilmiş modeller kullanarak yüksek doğrulama doğruluğuyla karakterleri tanıma
- Desen Tanıma: Hafif sahne metni tanıma için görüntü işleme tekniklerini uygulama
GRU tabanlı mimari ve bağlantıcı geçici sınıflandırma, kapsayıcı ortamlarda kaynak kullanımını verimli hale getirir, OCR.net'i Kubernetes dağıtımlarında hafıza ve CPU kısıtlamalarının önemli olduğu pratik bir seçenek haline getirir. Hafif mimari, Docker görüntü boyutlarını yönetilebilir tutar ve tanıma doğruluğunu güçlü bir şekilde korur.
OCR.net'i Geleneksel OCR Kütüphaneleri Üzerinden Ne Zaman Tercih Etmelisiniz?
OCR.net, karmaşık sahne metni, el yazısı belgeler veya şablona dayalı OCR'nin başarısız olduğu çok dilli içerikleri işlerken daha iyi bir seçimdir. Dış bağımlılıklar olmadan donanım yapılandırmaları arasında tutarlı performans gerektiren kapsayıcı uygulamalar içinde özellikle iyi performans gösterir. Model, UTF-8 kodlamasını sorunsuz bir şekilde işler, bu da uluslararası dil desteği için önemlidir.
Geleneksel regex tabanlı veya şablon eşleme OCR sistemleri, değişken yazı tipleri, el yazısı veya düzensiz aydınlatmaya sahip görüntüler üzerinde bozulur. OCR.net'in nöral yaklaşımı, sabit şablonları eşleştirmek yerine özellikleri öğrendiği için bu senaryolar arasında daha iyi genelleme yapar. Bununla birlikte, belgeleriniz temiz, makine yazımlı ve tutarlı bir biçimlendirmeye sahipse, daha hafif bir kütüphane daha hızlı ve yeterli olabilir.
OCR.net'in Üretimdeki Yaygın Kaynak Gereksinimleri Nelerdir?
Üretim dağıtımları genellikle sağlam performans için 2-4 CPU çekirdeği ve 4-8 GB RAM gerektirir. GPU hızlandırma, NVIDIA Docker çalışma zamanı kullanarak konteynere alınmış ortamlarda toplu işlem için önemli bir hız artışı sağlar. Bu gereksinimler, Azure App Service ve AWS Lambda dağıtımları ile iyi uyum sağlar, ancak Lambda'nın bellek sınırı, taahhüt etmeden önce belirli belge boyutlarınızı karşılaştırmanız gerektiği anlamına gelir.
IronPDF, OCR İşlemi için PDF Belgelerini Nasıl Oluşturur?
IronPDF, .NET geliştiricilerine PDF oluşturma üzerinde tam kontrol sağlar. Kütüphane, Chrome tabanlı işleme motoru aracılığıyla HTML dizelerini, URL'leri ve dosya girişlerini cilalı PDF'lere dönüştürebilir. OCR iş akışları için kritik özellik, PDF sayfalarını tanıma için uygun yüksek çözünürlüklü görüntüler olarak dışa aktaran RasterizeToImageFiles()'dir.
using IronPdf;
// Create a PDF document with IronPDF
var renderer = new ChromePdfRenderer();
// Set 300 DPI for OCR accuracy -- higher DPI preserves text sharpness
renderer.RenderingOptions.PaperSize = IronPdf.Rendering.PdfPaperSize.A4;
renderer.RenderingOptions.DPI = 300;
renderer.RenderingOptions.MarginTop = 50;
renderer.RenderingOptions.MarginBottom = 50;
var pdf = renderer.RenderHtmlAsPdf(@"
<h1>Document Report</h1>
<p>Scene text integration for computer vision analysis.</p>
<p>Text detection results for dataset and model analysis.</p>");
// Tag the document with searchable metadata
pdf.MetaData.Author = "OCR Processing Pipeline";
pdf.MetaData.Keywords = "OCR, Text Recognition, Computer Vision";
pdf.MetaData.ModifiedDate = DateTime.Now;
pdf.SaveAs("document-for-ocr.pdf");
// Export pages as PNG images for OCR.net -- 300 DPI is the recommended minimum
pdf.RasterizeToImageFiles("page-*.png", IronPdf.Imaging.ImageType.Png, 300);using IronPdf;
// Create a PDF document with IronPDF
var renderer = new ChromePdfRenderer();
// Set 300 DPI for OCR accuracy -- higher DPI preserves text sharpness
renderer.RenderingOptions.PaperSize = IronPdf.Rendering.PdfPaperSize.A4;
renderer.RenderingOptions.DPI = 300;
renderer.RenderingOptions.MarginTop = 50;
renderer.RenderingOptions.MarginBottom = 50;
var pdf = renderer.RenderHtmlAsPdf(@"
<h1>Document Report</h1>
<p>Scene text integration for computer vision analysis.</p>
<p>Text detection results for dataset and model analysis.</p>");
// Tag the document with searchable metadata
pdf.MetaData.Author = "OCR Processing Pipeline";
pdf.MetaData.Keywords = "OCR, Text Recognition, Computer Vision";
pdf.MetaData.ModifiedDate = DateTime.Now;
pdf.SaveAs("document-for-ocr.pdf");
// Export pages as PNG images for OCR.net -- 300 DPI is the recommended minimum
pdf.RasterizeToImageFiles("page-*.png", IronPdf.Imaging.ImageType.Png, 300);Imports IronPdf
' Create a PDF document with IronPDF
Dim renderer As New ChromePdfRenderer()
' Set 300 DPI for OCR accuracy -- higher DPI preserves text sharpness
renderer.RenderingOptions.PaperSize = IronPdf.Rendering.PdfPaperSize.A4
renderer.RenderingOptions.DPI = 300
renderer.RenderingOptions.MarginTop = 50
renderer.RenderingOptions.MarginBottom = 50
Dim pdf = renderer.RenderHtmlAsPdf("
<h1>Document Report</h1>
<p>Scene text integration for computer vision analysis.</p>
<p>Text detection results for dataset and model analysis.</p>")
' Tag the document with searchable metadata
pdf.MetaData.Author = "OCR Processing Pipeline"
pdf.MetaData.Keywords = "OCR, Text Recognition, Computer Vision"
pdf.MetaData.ModifiedDate = DateTime.Now
pdf.SaveAs("document-for-ocr.pdf")
' Export pages as PNG images for OCR.net -- 300 DPI is the recommended minimum
pdf.RasterizeToImageFiles("page-*.png", IronPdf.Imaging.ImageType.Png, 300)RasterizeToImageFiles() metodu, PDF sayfalarını belirtilen DPI'da PNG görüntülerine dönüştürür. 300 DPI'de, metin kenarları, OCR modelinin benzer görünümlü karakterleri ayırt edebilmesi için yeterince keskin kalır. 150 DPI veya altında, serif yazı tipi ve küçük yazılarda tanıma doğruluğu fark edilebilir şekilde azalır. Dışa aktardıktan sonra, PNG dosyalarını OCR.net'e yükleyin veya yerel bir modele doğrudan iletin.

DPI Ayarı Neden OCR Doğruluğunu Etkiler?
Daha yüksek DPI ayarları (300-600), OCR modelinin karakterleri doğru bir şekilde ayırt edebilmesi için gereken metin netliğini korur. Taviz dosya boyutu ve işlem süresidir. 300 DPI'de, tek bir A4 sayfası yaklaşık olarak 2-3 MB'lık bir PNG üretir. 600 DPI'de bu, 8-12 MB'a çıkar. Çoğu belge için 300 DPI doğru dengedir. Rendere etme seçenekleri bu ayarı belge türüne göre yapmanızı sağlarken, sıkıştırma teknikleri OCR tamamlandıktan sonra dosya boyutlarını optimize etmenize yardımcı olur.
IronPDF, Konteynerize Ortamları Nasıl Ele Alır?
IronPDF'nin yerel motoru, Linux, Windows ve macOS konteynerleri arasında tutarlı bir şekilde işlenmesini sağlar. Yüksek kullanılabilirlik hizmetleri için, IronPDF, ASP.NET Core sağlık kontrol uç noktaları ile entegre olur, böylece trafiği bir konteyner örneğine yönlendirmeden önce PDF oluşturmanın çalışır durumda olduğunu doğrulayan hazırlık ve canlılık problarını uygulayabilirsiniz.
using IronPdf;
// Kubernetes-compatible health check endpoint
var builder = WebApplication.CreateBuilder(args);
var app = builder.Build();
app.MapGet("/health/ready", async () =>
{
try
{
var renderer = new ChromePdfRenderer();
var testPdf = await renderer.RenderHtmlAsPdfAsync("<p>Health check</p>");
return testPdf.PageCount > 0 ? Results.Ok() : Results.Problem();
}
catch
{
return Results.Problem("PDF rendering unavailable");
}
});
await app.RunAsync();using IronPdf;
// Kubernetes-compatible health check endpoint
var builder = WebApplication.CreateBuilder(args);
var app = builder.Build();
app.MapGet("/health/ready", async () =>
{
try
{
var renderer = new ChromePdfRenderer();
var testPdf = await renderer.RenderHtmlAsPdfAsync("<p>Health check</p>");
return testPdf.PageCount > 0 ? Results.Ok() : Results.Problem();
}
catch
{
return Results.Problem("PDF rendering unavailable");
}
});
await app.RunAsync();Imports IronPdf
' Kubernetes-compatible health check endpoint
Dim builder = WebApplication.CreateBuilder(args)
Dim app = builder.Build()
app.MapGet("/health/ready", Async Function()
Try
Dim renderer = New ChromePdfRenderer()
Dim testPdf = Await renderer.RenderHtmlAsPdfAsync("<p>Health check</p>")
Return If(testPdf.PageCount > 0, Results.Ok(), Results.Problem())
Catch
Return Results.Problem("PDF rendering unavailable")
End Try
End Function)
Await app.RunAsync()Bu uç noktayı kullanarak özel kayıtlar oluşturun, render sürelerini yakalayın ve tamamen arızalanmadan önce kötüleşen konteynerleri tespit edin.
OCR.net, PDF Görüntülerinden Metni Nasıl Çıkartır?
IronPDF ile PNG çıktıları aldıktan sonra, bunları metin tanıma için OCR.net'e yüklersiniz. OCR.net hattı, görüntüleri işler ve çeşitli yazı tipi stilleri arasında normalize edilmiş metin çıktısı verir. Hem basılı hem de el yazısı metinlerle ilgilenir ve 60'tan fazla belge dilini destekler.
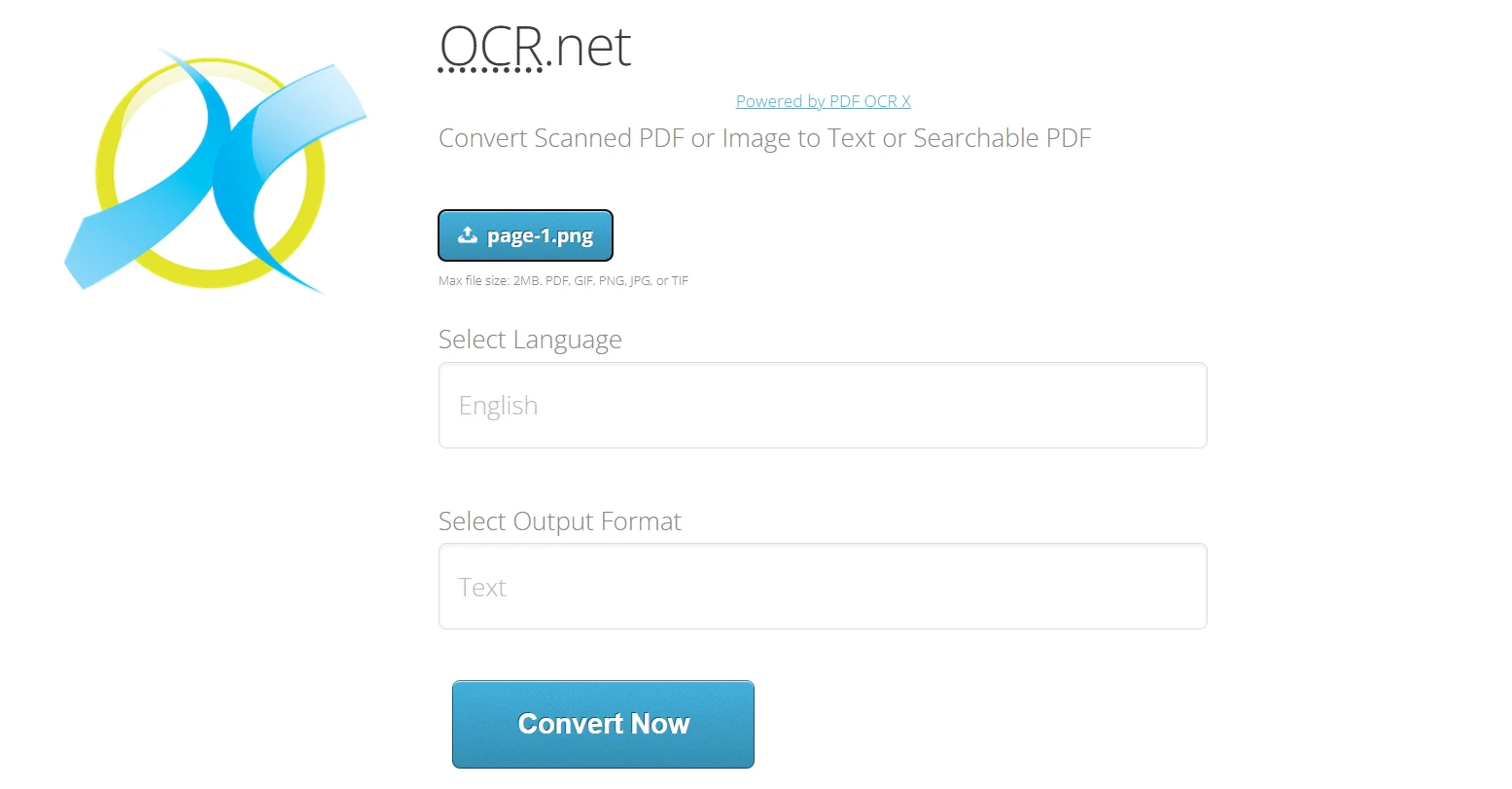
OCR.net Çevrimiçi Kullanımı:
-
https://ocr.net/ adresine gidin
-
IronPDF'den dışa aktarılan PNG veya JPG resmi (en fazla 2 MB) yükleyin.
- Mevcut 60'tan fazla seçenek arasından belge dilini seçin
- Çıktı formatını seçin: düz Metin veya Aranabilir PDF
- Görüntüyü OCR.net modelleri ile işlemek için "Şimdi Dönüştür"e tıklayın
OCR.net ayrıca otomatik işlem için bir API sağlar. Ücretsiz hesaplar saatte 50 istek ile sınırlıdır, bu da otomatikleştirilmiş hatlar için kritik bir kısıtlamadır. Entegrasyonunuzu, beklenmedik arızalardan ziyade üstel geri çekilmeyle hız limitine bağlı yanıtları zarif bir şekilde işlemek üzere tasarlayın:
using System;
using System.Net.Http;
using System.Threading.Tasks;
// Queue-based OCR processing with exponential backoff retry
async Task<string> ProcessOcrWithRetry(string imagePath, int maxRetries = 3)
{
for (int attempt = 0; attempt < maxRetries; attempt++)
{
try
{
// Replace with your actual OCR.net API call
return await CallOcrNetApi(imagePath);
}
catch (HttpRequestException ex) when (ex.Message.Contains("429"))
{
if (attempt == maxRetries - 1) throw;
var delay = TimeSpan.FromSeconds(Math.Pow(2, attempt));
await Task.Delay(delay);
}
}
throw new InvalidOperationException("OCR processing failed after all retries");
}using System;
using System.Net.Http;
using System.Threading.Tasks;
// Queue-based OCR processing with exponential backoff retry
async Task<string> ProcessOcrWithRetry(string imagePath, int maxRetries = 3)
{
for (int attempt = 0; attempt < maxRetries; attempt++)
{
try
{
// Replace with your actual OCR.net API call
return await CallOcrNetApi(imagePath);
}
catch (HttpRequestException ex) when (ex.Message.Contains("429"))
{
if (attempt == maxRetries - 1) throw;
var delay = TimeSpan.FromSeconds(Math.Pow(2, attempt));
await Task.Delay(delay);
}
}
throw new InvalidOperationException("OCR processing failed after all retries");
}Imports System
Imports System.Net.Http
Imports System.Threading.Tasks
' Queue-based OCR processing with exponential backoff retry
Async Function ProcessOcrWithRetry(imagePath As String, Optional maxRetries As Integer = 3) As Task(Of String)
For attempt As Integer = 0 To maxRetries - 1
Try
' Replace with your actual OCR.net API call
Return Await CallOcrNetApi(imagePath)
Catch ex As HttpRequestException When ex.Message.Contains("429")
If attempt = maxRetries - 1 Then Throw
Dim delay As TimeSpan = TimeSpan.FromSeconds(Math.Pow(2, attempt))
Await Task.Delay(delay)
End Try
Next
Throw New InvalidOperationException("OCR processing failed after all retries")
End FunctionErişilebilirlik iş akışları için, OCR metin çıkarımı, görme engelli kullanıcıların önceden yalnızca görüntü olan belgelerden sesli geri bildirim almasını sağlar. IronPDF ile PDF/UA uyumluluğu sağlanarak OCR.net çıktısının eşleştirilmesi, yardımcı teknolojilerin etkili bir şekilde gezinebileceği belgeler oluşturur.
IronPDF ve OCR.net ile Tam Bir İş Akışı Nasıl Oluşturulur?
IronPDF ile OCR.net'i birleştirmek, uçtan uca belge çözümleri üretir. İş akışında üç aşama vardır: PDF sayfalarını görüntü olarak dışa aktarma, görüntüleri metin çıkarımı için OCR.net'e gönderme ve tanınan metni yeni aranabilir bir PDF olarak yeniden oluşturma.
using IronPdf;
using System;
using System.Collections.Generic;
using System.Net.Http;
using System.Text;
using System.Threading.Tasks;
// --- Stage 1: Export PDF pages as images for OCR ---
var scannedPdf = PdfDocument.FromFile("input-document.pdf");
var imageFiles = scannedPdf.RasterizeToImageFiles(
"scan-page-{0}.png",
IronPdf.Imaging.ImageType.Png,
300 // 300 DPI -- minimum for reliable OCR accuracy
);
// --- Stage 2: Process each image through OCR.net ---
var ocrResults = new List<string>();
foreach (var imageFile in imageFiles)
{
// Replace this placeholder with your actual OCR.net API integration
string ocrText = await SendImageToOcrNet(imageFile);
ocrResults.Add(ocrText);
}
// --- Stage 3: Reassemble recognized text as a searchable PDF ---
var htmlBuilder = new StringBuilder();
htmlBuilder.Append(@"<!DOCTYPE html><html><head>
<style>body{font-family:Arial,sans-serif;margin:40px;}
.page{page-break-after:always;} pre{white-space:pre-wrap;}</style>
</head><body>");
for (int i = 0; i < ocrResults.Count; i++)
{
htmlBuilder.AppendFormat(
"<div class='page'><h2>Page {0}</h2><pre>{1}</pre></div>",
i + 1,
System.Web.HttpUtility.HtmlEncode(ocrResults[i])
);
}
htmlBuilder.Append("</body></html>");
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.DPI = 300;
renderer.RenderingOptions.EnableJavaScript = false;
var searchablePdf = await renderer.RenderHtmlAsPdfAsync(htmlBuilder.ToString());
searchablePdf.MetaData.Title = "OCR Processed Document";
searchablePdf.MetaData.Subject = "Searchable PDF from OCR";
searchablePdf.MetaData.CreationDate = DateTime.UtcNow;
searchablePdf.SecuritySettings.AllowUserPrinting = true;
searchablePdf.SecuritySettings.AllowUserCopyPasteContent = true;
searchablePdf.SaveAs("searchable-document.pdf");using IronPdf;
using System;
using System.Collections.Generic;
using System.Net.Http;
using System.Text;
using System.Threading.Tasks;
// --- Stage 1: Export PDF pages as images for OCR ---
var scannedPdf = PdfDocument.FromFile("input-document.pdf");
var imageFiles = scannedPdf.RasterizeToImageFiles(
"scan-page-{0}.png",
IronPdf.Imaging.ImageType.Png,
300 // 300 DPI -- minimum for reliable OCR accuracy
);
// --- Stage 2: Process each image through OCR.net ---
var ocrResults = new List<string>();
foreach (var imageFile in imageFiles)
{
// Replace this placeholder with your actual OCR.net API integration
string ocrText = await SendImageToOcrNet(imageFile);
ocrResults.Add(ocrText);
}
// --- Stage 3: Reassemble recognized text as a searchable PDF ---
var htmlBuilder = new StringBuilder();
htmlBuilder.Append(@"<!DOCTYPE html><html><head>
<style>body{font-family:Arial,sans-serif;margin:40px;}
.page{page-break-after:always;} pre{white-space:pre-wrap;}</style>
</head><body>");
for (int i = 0; i < ocrResults.Count; i++)
{
htmlBuilder.AppendFormat(
"<div class='page'><h2>Page {0}</h2><pre>{1}</pre></div>",
i + 1,
System.Web.HttpUtility.HtmlEncode(ocrResults[i])
);
}
htmlBuilder.Append("</body></html>");
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.DPI = 300;
renderer.RenderingOptions.EnableJavaScript = false;
var searchablePdf = await renderer.RenderHtmlAsPdfAsync(htmlBuilder.ToString());
searchablePdf.MetaData.Title = "OCR Processed Document";
searchablePdf.MetaData.Subject = "Searchable PDF from OCR";
searchablePdf.MetaData.CreationDate = DateTime.UtcNow;
searchablePdf.SecuritySettings.AllowUserPrinting = true;
searchablePdf.SecuritySettings.AllowUserCopyPasteContent = true;
searchablePdf.SaveAs("searchable-document.pdf");Imports IronPdf
Imports System
Imports System.Collections.Generic
Imports System.Net.Http
Imports System.Text
Imports System.Threading.Tasks
' --- Stage 1: Export PDF pages as images for OCR ---
Dim scannedPdf = PdfDocument.FromFile("input-document.pdf")
Dim imageFiles = scannedPdf.RasterizeToImageFiles(
"scan-page-{0}.png",
IronPdf.Imaging.ImageType.Png,
300 ' 300 DPI -- minimum for reliable OCR accuracy
)
' --- Stage 2: Process each image through OCR.net ---
Dim ocrResults As New List(Of String)()
For Each imageFile In imageFiles
' Replace this placeholder with your actual OCR.net API integration
Dim ocrText As String = Await SendImageToOcrNet(imageFile)
ocrResults.Add(ocrText)
Next
' --- Stage 3: Reassemble recognized text as a searchable PDF ---
Dim htmlBuilder As New StringBuilder()
htmlBuilder.Append("<!DOCTYPE html><html><head>
<style>body{font-family:Arial,sans-serif;margin:40px;}
.page{page-break-after:always;} pre{white-space:pre-wrap;}</style>
</head><body>")
For i As Integer = 0 To ocrResults.Count - 1
htmlBuilder.AppendFormat(
"<div class='page'><h2>Page {0}</h2><pre>{1}</pre></div>",
i + 1,
System.Web.HttpUtility.HtmlEncode(ocrResults(i))
)
Next
htmlBuilder.Append("</body></html>")
Dim renderer As New ChromePdfRenderer()
renderer.RenderingOptions.DPI = 300
renderer.RenderingOptions.EnableJavaScript = False
Dim searchablePdf = Await renderer.RenderHtmlAsPdfAsync(htmlBuilder.ToString())
searchablePdf.MetaData.Title = "OCR Processed Document"
searchablePdf.MetaData.Subject = "Searchable PDF from OCR"
searchablePdf.MetaData.CreationDate = DateTime.UtcNow
searchablePdf.SecuritySettings.AllowUserPrinting = True
searchablePdf.SecuritySettings.AllowUserCopyPasteContent = True
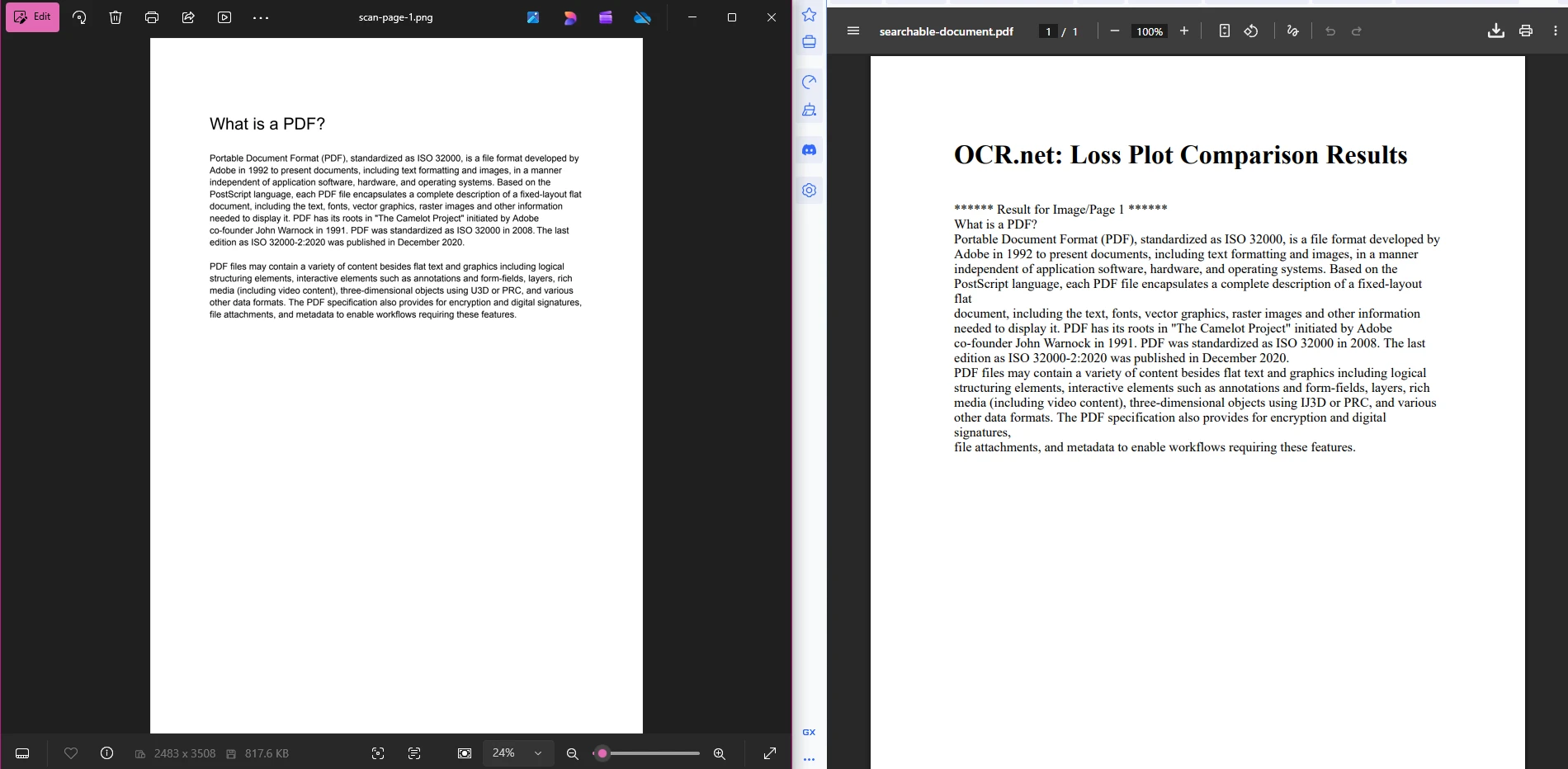
searchablePdf.SaveAs("searchable-document.pdf")Bu boru hattı kasıtlı olarak basittir. Aşama 1, numaralandırılmış PNG dosyaları üretir. Aşama 2, her dosyayı OCR.net'e gönderir ve döndürülen metin dizelerini toplar. Aşama 3, bu stringleri HTML içinde sarar ve metnin tamamen seçilebilir ve aranabilir olduğu son bir PDF'yi oluşturmak için IronPDF kullanır. Aşama 3'ü, belge yönetimi için PDF meta verileri veya erişim kontrolü için güvenlik ayarları uygulamak üzere genişletebilirsiniz.
Bu İş Akışı için En İyi Docker Yapılandırması Nedir?
Çok aşamalı Docker derlemeleri, Linux'ta IronPDF'nin ihtiyaç duyduğu tüm çalışma zamanı bağımlılıklarını içerirken son resmi küçük tutar:
FROM mcr.microsoft.com/dotnet/sdk:8.0 AS build
WORKDIR /app
COPY *.csproj ./
RUN dotnet restore
COPY . ./
RUN dotnet publish -c Release -o out
FROM mcr.microsoft.com/dotnet/aspnet:8.0
WORKDIR /app
# IronPDF Linux runtime dependencies
RUN apt-get update && apt-get install -y \
libgdiplus \
libc6-dev \
libx11-dev \
&& rm -rf /var/lib/apt/lists/*
COPY --from=build /app/out .
HEALTHCHECK --interval=30s --timeout=3s --start-period=5s --retries=3 \
CMD curl -f http://localhost:8080/health/ready || exit 1
ENTRYPOINT ["dotnet", "OcrWorkflow.dll"]Üretim ölçeği için, toplu OCR işlemleri için Kubernetes Jobs değerlendirin. Kubernetes İşleri, başarısız olan belge görevlerinin diğer hizmetleri etkilememesi için otomatik tekrar denemeleri, paralellik kontrolü ve kaynak izolasyonu sağlar. parallelism ayarını OCR.net API seviyenizle eşleşecek ve backoffLimit ayarını, Job görevinin başarısız olarak işaretlemesinden önce başarısız bir pod'un kaç kez yeniden deneneceğini kontrol edecek şekilde ayarlayın.
Performans Metriklerini Üretimde Nasıl İzlersiniz?
OCR işlem sürelerini ve başarı oranlarını takip etmek, son kullanıcıları etkilemeden önce darboğazları belirlemeye yardımcı olur. Prometheus ile özel metrikler, pratik bir yaklaşımdır:
using Prometheus;
using System;
using System.Threading.Tasks;
// Prometheus metrics for OCR pipeline observability
var ocrRequestsTotal = Metrics
.CreateCounter("ocr_requests_total", "Total OCR requests processed");
var ocrDuration = Metrics
.CreateHistogram("ocr_duration_seconds", "OCR processing duration in seconds",
new HistogramConfiguration
{
Buckets = Histogram.LinearBuckets(0.1, 0.1, 10)
});
var activeOcrJobs = Metrics
.CreateGauge("ocr_active_jobs", "Currently active OCR jobs");
// Wrapper that tracks every OCR operation automatically
async Task<t> TrackOcrOperation<t>(Func<Task<t>> operation)
{
using (ocrDuration.NewTimer())
{
activeOcrJobs.Inc();
try
{
var result = await operation();
ocrRequestsTotal.Inc();
return result;
}
finally
{
activeOcrJobs.Dec();
}
}
}using Prometheus;
using System;
using System.Threading.Tasks;
// Prometheus metrics for OCR pipeline observability
var ocrRequestsTotal = Metrics
.CreateCounter("ocr_requests_total", "Total OCR requests processed");
var ocrDuration = Metrics
.CreateHistogram("ocr_duration_seconds", "OCR processing duration in seconds",
new HistogramConfiguration
{
Buckets = Histogram.LinearBuckets(0.1, 0.1, 10)
});
var activeOcrJobs = Metrics
.CreateGauge("ocr_active_jobs", "Currently active OCR jobs");
// Wrapper that tracks every OCR operation automatically
async Task<t> TrackOcrOperation<t>(Func<Task<t>> operation)
{
using (ocrDuration.NewTimer())
{
activeOcrJobs.Inc();
try
{
var result = await operation();
ocrRequestsTotal.Inc();
return result;
}
finally
{
activeOcrJobs.Dec();
}
}
}Imports Prometheus
Imports System
Imports System.Threading.Tasks
' Prometheus metrics for OCR pipeline observability
Dim ocrRequestsTotal = Metrics.CreateCounter("ocr_requests_total", "Total OCR requests processed")
Dim ocrDuration = Metrics.CreateHistogram("ocr_duration_seconds", "OCR processing duration in seconds",
New HistogramConfiguration With {
.Buckets = Histogram.LinearBuckets(0.1, 0.1, 10)
})
Dim activeOcrJobs = Metrics.CreateGauge("ocr_active_jobs", "Currently active OCR jobs")
' Wrapper that tracks every OCR operation automatically
Async Function TrackOcrOperation(Of T)(operation As Func(Of Task(Of T))) As Task(Of T)
Using ocrDuration.NewTimer()
activeOcrJobs.Inc()
Try
Dim result = Await operation()
ocrRequestsTotal.Inc()
Return result
Finally
activeOcrJobs.Dec()
End Try
End Using
End FunctionBu metrikleri, IronPDF'nin kayıt tutma özellikleri ile eşleştirerek render sürelerini OCR süreleriyle ilişkilendirin. Optik Karakter Tanıma (OCR) süresi, render süresinde benzer bir artış olmaksızın yükseldiğinde, darboğaz PDF oluşturma adımında değil, OCR.net API çağrısında veya ona olan ağ yolunuzdadır.
Sonraki Adımlarınız Neler?
OCR.net ile IronPDF birleştiğinde, .NET ortamında metin çıkarma ve aranabilir PDF oluşturma için pratik bir yol sunar. Bu işlem hattı, HTML'den PDF oluşturma, sayfaları OCR uyumlu çözünürlükte dışa aktarma, görüntüleri OCR.net'e gönderme ve sonuçları tamamen aranabilir bir belgeye yeniden birleştirme gibi temel kullanım durumlarını kapsar.
Bunu üretime taşırken dikkat edilmesi gereken önemli hususlar:
- Konteyner kurulumu: IronPDF Slim paketlerini ve çok aşamalı Docker derlemelerini kullanarak imaj boyutlarını yönetilebilir tutun
- Kaynak planlama: Belge boyutlarınıza ve eşzamanlılık hedeflerinize uygun bellek limitlerini yapılandırın
- İzleme: Bozulmayı erken yakalamak için Prometheus metriklerini IronPDF loglama ile birlikte uygulayın
- Verimlilik: OCR.net'in hız limitleri dahilinde çalışmak için async işlemlerini ve toplu sıra yönetimini kullanın
- Güvenilirlik: OCR.net API çağrısı etrafında üstel geri çekilme yeniden deneme mantığı ve devre kesiciler oluşturun
Üretim lisansına geçmeden önce tüm iş akışını baştan sona test etmek için ücretsiz deneme lisansını kullanarak başlayın. Deneme sürümü, filigranı kaldırır ve tüm özellikleri açar, böylece performans test sonuçlarınız üretim davranışını doğru bir şekilde yansıtır. Dağıtıma hazır olduğunuzda, kullanım şeklinize uygun olan katmanı bulmak için IronPDF lisanslama seçeneklerini gözden geçirin.
Sıkça Sorulan Sorular
OCR.net ne yapar ve IronPDF ile nasıl bağlantı kurar?
OCR.net, görüntü girişlerini kabul eden ve tanınan metni döndüren bir derin öğrenme OCR hizmetidir. IronPDF, PDF'ler üretir ve sayfalarını resim olarak dışa aktarır. İki araç görüntü katmanında birleşir: IronPDF RasterizeToImageFiles() kullanarak sayfaları dışa aktarır, bu resimler metin çıkarımı için OCR.net'e gider ve IronPDF sonuçları aranabilir bir PDF olarak yeniden birleştirir.
OCR için PDF sayfalarını dışa aktarırken hangi DPI'yi kullanmalısınız?
300 DPI, güvenilir OCR doğruluğu için standart minimum seviyedir. 300 DPI'da, metin kenarları modelin benzer karakterleri ayırt etmesi için yeterince keskindir. 150 DPI veya daha düşük ayarlarda, doğruluk serif yazı tiplerinde ve küçük yazılarda düşer. Kullanılan belgeler çok küçük veya bozuk metin içeriyorsa, yalnızca 600 DPI kullanın; çünkü 600 DPI'da her sayfa 4-5 kat daha büyük dosyalar üretir.
Üretim ortamında OCR.net API hız sınırlarını nasıl yönetirsiniz?
OCR.net ücretsiz hesapları saatte 50 istek sağlar. OCR çağrınıza üssel geri alma deneme mantığı kurun: 429 yanıtını yakalayın, Math.Pow(2, attempt) saniye bekleyin ve yapılandırılmış bir maksimuma kadar tekrar deneyin. Daha yüksek veri işleme kapasitesi için ücretli bir OCR.net planına yükseltme yapın veya arka plan çalıştırma hizmeti ile istekleri sıraya alın.
IronPDF Linux üzerinde bir Docker konteyneri içinde çalışabilir mi?
Evet. Dockerfile'ın runtime aşamasına libgdiplus, libc6-dev ve libx11-dev ekleyin. Son görüntüyü küçük tutmak için çok aşamalı yapılar kullanın. IronPDF Slim paket varyantı, IronPDF Motorunu ayrı bir hizmet olarak çalıştırdığınızda paketlenmiş tarayıcı çalıştırımlarını dışarıda bırakarak görüntü boyutunu daha da azaltır.
OCR sonuçlarından aranabilir bir PDF nasıl oluşturursunuz?
OCR.net tarafından döndürülen metin dizilerini, her bir belge sayfası için bir sayfa sonu sınıfı ile HTML içine sarın ve HTML'yi ChromePdfRenderer.RenderHtmlAsPdfAsync()ye aktarın. Sonuçta oluşan PDF, kullanıcılar ve arama motorları tarafından indekslenebilir, seçilebilir, aranabilir metin içerir.
Bu iş akışı çok dilli belgeleri destekliyor mu?
Evet. OCR.net 60+ dili destekler. İşlem öncesi OCR.net arayüzünde veya API çağrısında hedef dili seçin. IronPDF, UTF-8 çıktısını doğal olarak işler, bu nedenle Latin harfleri dışındaki alfabelere sahip diller derlenen aranabilir PDF içinde doğru şekilde görüntülenir.
Üretim ortamında OCR hattının performansını nasıl izlersiniz?
Toplam istekleri, süre dağılımlarını ve aktif işleri izlemek için işleme servisinize Prometheus sayıcıları, histogramları ve göstergeleri ekleyin. Prometheus metriklerini, IronPDF'nin özel günlüğüyle eşleştirerek işleme sürelerini OCR API gecikmesiyle ilişkilendirin ve darboğazların nerede oluştuğunu belirleyin.
OCR.net ile IronOCR arasındaki fark nedir?
OCR.net, API üzerinden yüklediğiniz görüntülerle çalışan harici bir web hizmetidir. IronOCR, harici API çağrıları olmadan uygulamanız içinde yerel olarak OCR işlemesi yapan Iron Software'ın bir .NET kütüphanesidir. IronOCR, çevrimdışı ortamlar veya daha düşük gecikme süresi ve OCR motoru üzerinde daha fazla kontrol gerektiğinde daha uygundur.











