
Wie man einen PDF-OCR-Workflow mit OCR.net und IronPDF in C# erstellt
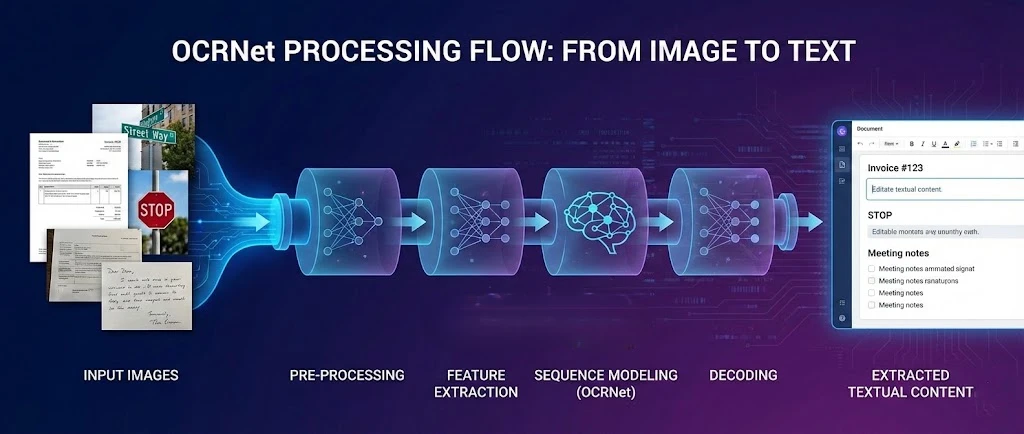
OCR.net ist ein Deep-Learning-Framework für die optische Zeichenerkennung, das in Verbindung mit IronPDF Text aus PDFs extrahiert und durchsuchbare Dokumente in .NET Anwendungen erzeugt. Dieses Tutorial zeigt Ihnen, wie Sie diese beiden Tools verbinden, damit Ihre Anwendung gescannte Dateien verarbeiten, PDF-Seiten für die OCR rastern und den erkannten Text zu einem neuen durchsuchbaren PDF zusammensetzen kann.
Das OCR.net Modell zeichnet sich durch hervorragende Szenentexterkennung und Zeichenerkennung in komplexen Umgebungen aus. In Kombination mit der Rendering-Engine von IronPDF erhalten Sie eine vollständige Pipeline: Sie generieren oder laden ein PDF, exportieren dessen Seiten als hochauflösende Bilder, senden diese Bilder an OCR.net und rekonstruieren die Ergebnisse zu einem vollständig durchsuchbaren Dokument.
Wie fängt man mit IronPDF an?
Bevor Sie den OCR-Workflow erstellen, müssen Sie IronPDF in Ihrem Projekt installieren. Der schnellste Weg führt über die NuGet Paket-Manager-Konsole:
Install-Package IronPDFOder fügen Sie es direkt über die NuGet Benutzeroberfläche hinzu, indem Sie nach IronPDF suchen. Nach der Installation geben Sie Ihren Lizenzschlüssel beim Start der Anwendung ein:
using IronPdf;
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";using IronPdf;
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";Imports IronPdf
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY"Es ist eine kostenlose Testlizenz erhältlich, mit der Sie den vollen Funktionsumfang ohne Einschränkungen testen können. IronPDF unterstützt .NET 6, 7, 8 und 10 unter Windows, Linux und macOS, was bedeutet, dass derselbe Code in Desktop-Anwendungen, ASP.NET Core -Webdiensten und containerisierten Bereitstellungen ausgeführt werden kann.
Für Docker-Umgebungen bietet IronPDF eine vorkonfigurierte Linux-Bereitstellungsanleitung und schlanke Paketvarianten , die die Image-Größe reduzieren. Wenn Sie eine Architektur für Remote-Rendering bevorzugen, kann die IronPDF Engine als separater Dienst mit Clients auf jeder unterstützten Plattform ausgeführt werden.
Was ist OCRNet und wie funktioniert die optische Zeichenerkennung?
OCR.net ist ein Deep-Learning-Ansatz zur optischen Zeichenerkennung (OCR), der alphanumerische Zeichen über verschiedene Schriftarten hinweg erkennt. Das Modell verwendet eine optimierte neuronale Netzwerkarchitektur, um räumliche Merkmale aus den Eingangsbildern zu erfassen. In Kombination mit Funktionen zur PDF-Generierung ermöglichen diese trainierten Modelle eine hochpräzise Erkennung gängiger Dokumenttypen.
Das Erkennungsframework von OCR.net verwendet eine Gated Recurrent Unit (GRU), um das Feature-Lernen zu verbessern und bildbasierte Sequenzerkennungsaufgaben zu verarbeiten. Dieses Hybridmodell erzielt eine bemerkenswerte Genauigkeit durch connectionist temporal classification (CTC), eine Technik , die ursprünglich für die Sequenzkennzeichnung eingeführt wurde und sich gut auf die Dokumenten-OCR übertragen lässt. Kontinuierliche Verbesserungen erweitern die Sprachunterstützung von OCR.net stetig, insbesondere in Kombination mit PDF-Textextraktionswerkzeugen .
Zu den wichtigsten Komponenten einer modernen OCR-Pipeline gehören:
- Texterkennung: Identifizierung von Textinhaltsbereichen in einem Bild mithilfe trainierter Modelle
- Szenentexterkennung: Auffinden von Text in komplexen Hintergründen und dynamischen Umgebungen
- Alphanumerische Zeichenerkennung: Verwendung trainierter Modelle zur Erkennung von Zeichen mit hoher Validierungsgenauigkeit
-
Mustererkennung: Anwendung von Bildverarbeitungstechniken zur einfachen Szenentexterkennung
Die schlanke Architektur sorgt für überschaubare Docker-Image-Größen bei gleichzeitig hoher Erkennungsgenauigkeit.
Wann sollte man OCR.net gegenüber herkömmlichen OCR-Bibliotheken bevorzugen?
OCR.net ist die bessere Wahl bei der Verarbeitung komplexer Szenentexte, handgeschriebener Dokumente oder mehrsprachiger Inhalte, bei denen vorlagenbasierte OCR versagt. Es eignet sich besonders gut für containerisierte Anwendungen , die eine gleichbleibende Leistung über verschiedene Hardwarekonfigurationen hinweg ohne externe Abhängigkeiten benötigen. Das Modell verarbeitet die UTF-8-Kodierung problemlos, was für die Unterstützung internationaler Sprachen wichtig ist.
Herkömmliche OCR-Systeme, die auf regulären Ausdrücken oder Vorlagen basieren, versagen bei variablen Schriftarten, Handschrift oder Bildern mit ungleichmäßiger Beleuchtung. Der neuronale Ansatz von OCR.net generalisiert besser über diese Szenarien hinweg, da er Merkmale lernt, anstatt feste Vorlagen abzugleichen. Allerdings kann eine kleinere Bibliothek schneller und ausreichend sein, wenn es sich bei Ihren Dokumenten um sauberen, maschinell erstellten Text mit einheitlicher Formatierung handelt.
Welche allgemeinen Ressourcenanforderungen gelten für OCR.net im Produktivbetrieb?
Für einen reibungslosen Produktiveinsatz werden typischerweise 2-4 CPU-Kerne und 4-8 GB RAM benötigt. Die GPU-Beschleunigung ermöglicht eine deutliche Beschleunigung der Stapelverarbeitung in containerisierten Umgebungen mit der NVIDIA Docker-Laufzeitumgebung. Diese Anforderungen eignen sich gut für Azure App Service- und AWS Lambda-Bereitstellungen . Aufgrund der Speicherbegrenzung von Lambda sollten Sie jedoch Ihre spezifischen Dokumentgrößen vor der endgültigen Implementierung testen.
Wie erstellt IronPDF PDF-Dokumente für die OCR-Verarbeitung?
IronPDF gibt .NET -Entwicklern die volle Kontrolle über die PDF-Generierung. Die Bibliothek kann HTML-Strings , URLs und Dateieingaben mithilfe ihrer Chrome-basierten Rendering-Engine in ansprechende PDFs umwandeln. Für OCR-Workflows ist die entscheidende Funktion RasterizeToImageFiles(), die PDF-Seiten als hochauflösende, für die Texterkennung geeignete Bilder exportiert.
using IronPdf;
// Create a PDF document with IronPDF
var renderer = new ChromePdfRenderer();
// Set 300 DPI for OCR accuracy -- higher DPI preserves text sharpness
renderer.RenderingOptions.PaperSize = IronPdf.Rendering.PdfPaperSize.A4;
renderer.RenderingOptions.DPI = 300;
renderer.RenderingOptions.MarginTop = 50;
renderer.RenderingOptions.MarginBottom = 50;
var pdf = renderer.RenderHtmlAsPdf(@"
<h1>Document Report</h1>
<p>Scene text integration for computer vision analysis.</p>
<p>Text detection results for dataset and model analysis.</p>");
// Tag the document with searchable metadata
pdf.MetaData.Author = "OCR Processing Pipeline";
pdf.MetaData.Keywords = "OCR, Text Recognition, Computer Vision";
pdf.MetaData.ModifiedDate = DateTime.Now;
pdf.SaveAs("document-for-ocr.pdf");
// Export pages as PNG images for OCR.net -- 300 DPI is the recommended minimum
pdf.RasterizeToImageFiles("page-*.png", IronPdf.Imaging.ImageType.Png, 300);using IronPdf;
// Create a PDF document with IronPDF
var renderer = new ChromePdfRenderer();
// Set 300 DPI for OCR accuracy -- higher DPI preserves text sharpness
renderer.RenderingOptions.PaperSize = IronPdf.Rendering.PdfPaperSize.A4;
renderer.RenderingOptions.DPI = 300;
renderer.RenderingOptions.MarginTop = 50;
renderer.RenderingOptions.MarginBottom = 50;
var pdf = renderer.RenderHtmlAsPdf(@"
<h1>Document Report</h1>
<p>Scene text integration for computer vision analysis.</p>
<p>Text detection results for dataset and model analysis.</p>");
// Tag the document with searchable metadata
pdf.MetaData.Author = "OCR Processing Pipeline";
pdf.MetaData.Keywords = "OCR, Text Recognition, Computer Vision";
pdf.MetaData.ModifiedDate = DateTime.Now;
pdf.SaveAs("document-for-ocr.pdf");
// Export pages as PNG images for OCR.net -- 300 DPI is the recommended minimum
pdf.RasterizeToImageFiles("page-*.png", IronPdf.Imaging.ImageType.Png, 300);Imports IronPdf
' Create a PDF document with IronPDF
Dim renderer As New ChromePdfRenderer()
' Set 300 DPI for OCR accuracy -- higher DPI preserves text sharpness
renderer.RenderingOptions.PaperSize = IronPdf.Rendering.PdfPaperSize.A4
renderer.RenderingOptions.DPI = 300
renderer.RenderingOptions.MarginTop = 50
renderer.RenderingOptions.MarginBottom = 50
Dim pdf = renderer.RenderHtmlAsPdf("
<h1>Document Report</h1>
<p>Scene text integration for computer vision analysis.</p>
<p>Text detection results for dataset and model analysis.</p>")
' Tag the document with searchable metadata
pdf.MetaData.Author = "OCR Processing Pipeline"
pdf.MetaData.Keywords = "OCR, Text Recognition, Computer Vision"
pdf.MetaData.ModifiedDate = DateTime.Now
pdf.SaveAs("document-for-ocr.pdf")
' Export pages as PNG images for OCR.net -- 300 DPI is the recommended minimum
pdf.RasterizeToImageFiles("page-*.png", IronPdf.Imaging.ImageType.Png, 300)Die Methode RasterizeToImageFiles() wandelt PDF-Seiten in PNG-Bilder mit der angegebenen DPI-Zahl um. Bei einer Auflösung von 300 DPI bleiben die Textkanten scharf genug, damit das OCR-Modell ähnlich aussehende Zeichen unterscheiden kann. Bei einer Auflösung von 150 DPI oder darunter nimmt die Erkennungsgenauigkeit bei Serifenschriften und Kleingedrucktem merklich ab. Nach dem Export laden Sie die PNG-Dateien in OCR.net hoch oder übergeben sie direkt an ein lokales Modell.

Warum beeinflusst die DPI-Einstellung die Genauigkeit der OCR-Texturierung?
Höhere DPI-Einstellungen (300-600) erhalten die Textklarheit, die das OCR-Modell benötigt, um Zeichen genau zu unterscheiden. Der Kompromiss besteht in der Dateigröße und der Verarbeitungszeit. Bei 300 DPI erzeugt eine einzelne A4-Seite eine PNG-Datei von etwa 2-3 MB. Bei 600 DPI wächst die Dateigröße auf 8-12 MB an. Für die meisten Dokumente ist eine Auflösung von 300 DPI der richtige Wert. Die Rendering-Optionen ermöglichen es Ihnen, dies für jeden Dokumenttyp individuell anzupassen, während Komprimierungstechniken dazu beitragen, die Dateigrößen nach Abschluss der OCR zu optimieren.
Wie geht IronPDF mit containerisierten Umgebungen um?
Die native Engine von IronPDF gewährleistet eine konsistente Darstellung in Linux- , Windows- und macOS -Containern. Für hochverfügbare Dienste integriert IronPDF sich in die Integritätsprüfungs-Endpunkte von ASP.NET Core , sodass Sie Bereitschafts- und Lebendigkeitsprüfungen implementieren können, die überprüfen, ob das PDF-Rendering betriebsbereit ist, bevor der Datenverkehr an eine Containerinstanz weitergeleitet wird.
using IronPdf;
// Kubernetes-compatible health check endpoint
var builder = WebApplication.CreateBuilder(args);
var app = builder.Build();
app.MapGet("/health/ready", async () =>
{
try
{
var renderer = new ChromePdfRenderer();
var testPdf = await renderer.RenderHtmlAsPdfAsync("<p>Health check</p>");
return testPdf.PageCount > 0 ? Results.Ok() : Results.Problem();
}
catch
{
return Results.Problem("PDF rendering unavailable");
}
});
await app.RunAsync();using IronPdf;
// Kubernetes-compatible health check endpoint
var builder = WebApplication.CreateBuilder(args);
var app = builder.Build();
app.MapGet("/health/ready", async () =>
{
try
{
var renderer = new ChromePdfRenderer();
var testPdf = await renderer.RenderHtmlAsPdfAsync("<p>Health check</p>");
return testPdf.PageCount > 0 ? Results.Ok() : Results.Problem();
}
catch
{
return Results.Problem("PDF rendering unavailable");
}
});
await app.RunAsync();Imports IronPdf
' Kubernetes-compatible health check endpoint
Dim builder = WebApplication.CreateBuilder(args)
Dim app = builder.Build()
app.MapGet("/health/ready", Async Function()
Try
Dim renderer = New ChromePdfRenderer()
Dim testPdf = Await renderer.RenderHtmlAsPdfAsync("<p>Health check</p>")
Return If(testPdf.PageCount > 0, Results.Ok(), Results.Problem())
Catch
Return Results.Problem("PDF rendering unavailable")
End Try
End Function)
Await app.RunAsync()Verwenden Sie benutzerdefinierte Protokollierung zusammen mit diesem Endpunkt, um Renderzeiten zu erfassen und Container zu identifizieren, deren Leistung nachlässt, bevor sie vollständig ausfallen.
Wie extrahiert OCR.net Text aus PDF-Bildern?
Sobald Sie PNG-Exporte aus IronPDF erstellt haben, laden Sie diese zur Texterkennung in OCR.net hoch. Die OCR.net Pipeline verarbeitet Bilder und gibt normalisierten Text in verschiedenen Schriftarten aus. Es verarbeitet sowohl gedruckten als auch handgeschriebenen Text und unterstützt über 60 Dokumentensprachen.
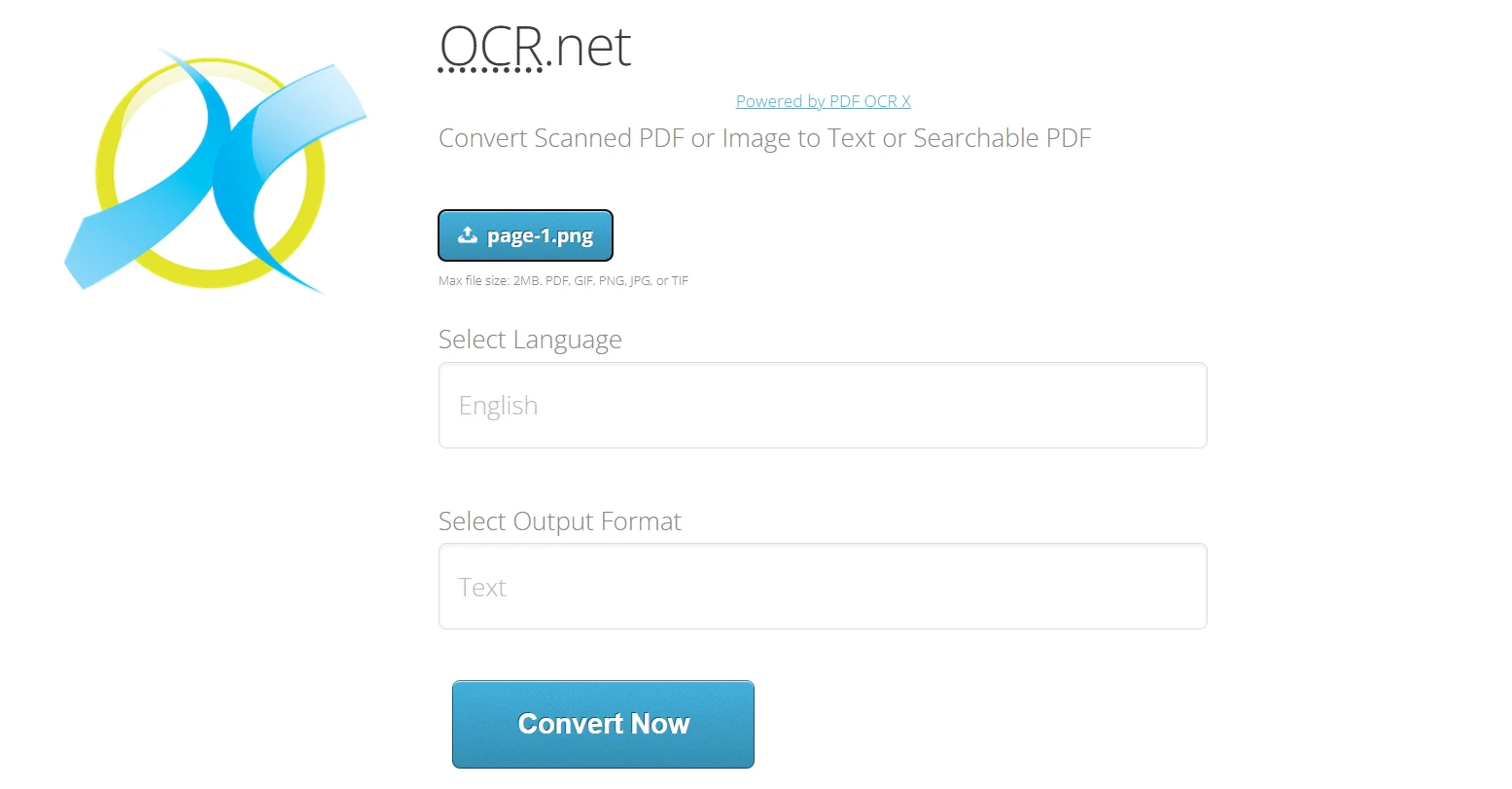
Verwendung von OCR.net Online:
- Navigieren Sie zu https://ocr.net/
- Laden Sie das ausIronPDF exportierte PNG- oder JPG-Bild (maximal 2 MB) hoch.
- Wählen Sie die Dokumentsprache aus den über 60 verfügbaren Optionen aus.
- Wählen Sie das Ausgabeformat: reiner Text oder durchsuchbares PDF
- Klicken Sie auf "Jetzt konvertieren", um das Bild mit OCR.net-Modellen zu verarbeiten.
OCR.net bietet außerdem eine API für die automatisierte Verarbeitung. Kostenlose Konten sind auf 50 Anfragen pro Stunde beschränkt, was eine kritische Einschränkung für automatisierte Pipelines darstellt. Gestalten Sie Ihre Integration so, dass sie Ratenbegrenzungsantworten mit exponentiellem Backoff elegant verarbeitet, anstatt mit einem harten Fehler zu reagieren:
using System;
using System.Net.Http;
using System.Threading.Tasks;
// Queue-based OCR processing with exponential backoff retry
async Task<string> ProcessOcrWithRetry(string imagePath, int maxRetries = 3)
{
for (int attempt = 0; attempt < maxRetries; attempt++)
{
try
{
// Replace with your actual OCR.net API call
return await CallOcrNetApi(imagePath);
}
catch (HttpRequestException ex) when (ex.Message.Contains("429"))
{
if (attempt == maxRetries - 1) throw;
var delay = TimeSpan.FromSeconds(Math.Pow(2, attempt));
await Task.Delay(delay);
}
}
throw new InvalidOperationException("OCR processing failed after all retries");
}using System;
using System.Net.Http;
using System.Threading.Tasks;
// Queue-based OCR processing with exponential backoff retry
async Task<string> ProcessOcrWithRetry(string imagePath, int maxRetries = 3)
{
for (int attempt = 0; attempt < maxRetries; attempt++)
{
try
{
// Replace with your actual OCR.net API call
return await CallOcrNetApi(imagePath);
}
catch (HttpRequestException ex) when (ex.Message.Contains("429"))
{
if (attempt == maxRetries - 1) throw;
var delay = TimeSpan.FromSeconds(Math.Pow(2, attempt));
await Task.Delay(delay);
}
}
throw new InvalidOperationException("OCR processing failed after all retries");
}Imports System
Imports System.Net.Http
Imports System.Threading.Tasks
' Queue-based OCR processing with exponential backoff retry
Async Function ProcessOcrWithRetry(imagePath As String, Optional maxRetries As Integer = 3) As Task(Of String)
For attempt As Integer = 0 To maxRetries - 1
Try
' Replace with your actual OCR.net API call
Return Await CallOcrNetApi(imagePath)
Catch ex As HttpRequestException When ex.Message.Contains("429")
If attempt = maxRetries - 1 Then Throw
Dim delay As TimeSpan = TimeSpan.FromSeconds(Math.Pow(2, attempt))
Await Task.Delay(delay)
End Try
Next
Throw New InvalidOperationException("OCR processing failed after all retries")
End FunctionFür barrierefreie Arbeitsabläufe ermöglicht die OCR-Textextraktion sehbehinderten Nutzern, Audio-Feedback zu Dokumenten zu erhalten, die zuvor nur als Bilder vorlagen. Durch die Kombination von OCR.net Ausgabe mit PDF/UA-Konformität mittels IronPDF entstehen Dokumente, die von Hilfstechnologien effektiv navigiert werden können.
Wie erstellt man einen vollständigen IronPDF und OCR.net Workflow?
Die Verbindung von IronPDF mit OCR.net ermöglicht die Erstellung von Komplettlösungen für Dokumente. Der Workflow umfasst drei Schritte: Export der PDF-Seiten als Bilder, Senden der Bilder an OCR.net zur Textextraktion und Rekonstruktion des erkannten Textes zu einem neuen durchsuchbaren PDF.
using IronPdf;
using System;
using System.Collections.Generic;
using System.Net.Http;
using System.Text;
using System.Threading.Tasks;
// --- Stage 1: Export PDF pages as images for OCR ---
var scannedPdf = PdfDocument.FromFile("input-document.pdf");
var imageFiles = scannedPdf.RasterizeToImageFiles(
"scan-page-{0}.png",
IronPdf.Imaging.ImageType.Png,
300 // 300 DPI -- minimum for reliable OCR accuracy
);
// --- Stage 2: Process each image through OCR.net ---
var ocrResults = new List<string>();
foreach (var imageFile in imageFiles)
{
// Replace this placeholder with your actual OCR.net API integration
string ocrText = await SendImageToOcrNet(imageFile);
ocrResults.Add(ocrText);
}
// --- Stage 3: Reassemble recognized text as a searchable PDF ---
var htmlBuilder = new StringBuilder();
htmlBuilder.Append(@"<!DOCTYPE html><html><head>
<style>body{font-family:Arial,sans-serif;margin:40px;}
.page{page-break-after:always;} pre{white-space:pre-wrap;}</style>
</head><body>");
for (int i = 0; i < ocrResults.Count; i++)
{
htmlBuilder.AppendFormat(
"<div class='page'><h2>Page {0}</h2><pre>{1}</pre></div>",
i + 1,
System.Web.HttpUtility.HtmlEncode(ocrResults[i])
);
}
htmlBuilder.Append("</body></html>");
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.DPI = 300;
renderer.RenderingOptions.EnableJavaScript = false;
var searchablePdf = await renderer.RenderHtmlAsPdfAsync(htmlBuilder.ToString());
searchablePdf.MetaData.Title = "OCR Processed Document";
searchablePdf.MetaData.Subject = "Searchable PDF from OCR";
searchablePdf.MetaData.CreationDate = DateTime.UtcNow;
searchablePdf.SecuritySettings.AllowUserPrinting = true;
searchablePdf.SecuritySettings.AllowUserCopyPasteContent = true;
searchablePdf.SaveAs("searchable-document.pdf");using IronPdf;
using System;
using System.Collections.Generic;
using System.Net.Http;
using System.Text;
using System.Threading.Tasks;
// --- Stage 1: Export PDF pages as images for OCR ---
var scannedPdf = PdfDocument.FromFile("input-document.pdf");
var imageFiles = scannedPdf.RasterizeToImageFiles(
"scan-page-{0}.png",
IronPdf.Imaging.ImageType.Png,
300 // 300 DPI -- minimum for reliable OCR accuracy
);
// --- Stage 2: Process each image through OCR.net ---
var ocrResults = new List<string>();
foreach (var imageFile in imageFiles)
{
// Replace this placeholder with your actual OCR.net API integration
string ocrText = await SendImageToOcrNet(imageFile);
ocrResults.Add(ocrText);
}
// --- Stage 3: Reassemble recognized text as a searchable PDF ---
var htmlBuilder = new StringBuilder();
htmlBuilder.Append(@"<!DOCTYPE html><html><head>
<style>body{font-family:Arial,sans-serif;margin:40px;}
.page{page-break-after:always;} pre{white-space:pre-wrap;}</style>
</head><body>");
for (int i = 0; i < ocrResults.Count; i++)
{
htmlBuilder.AppendFormat(
"<div class='page'><h2>Page {0}</h2><pre>{1}</pre></div>",
i + 1,
System.Web.HttpUtility.HtmlEncode(ocrResults[i])
);
}
htmlBuilder.Append("</body></html>");
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.DPI = 300;
renderer.RenderingOptions.EnableJavaScript = false;
var searchablePdf = await renderer.RenderHtmlAsPdfAsync(htmlBuilder.ToString());
searchablePdf.MetaData.Title = "OCR Processed Document";
searchablePdf.MetaData.Subject = "Searchable PDF from OCR";
searchablePdf.MetaData.CreationDate = DateTime.UtcNow;
searchablePdf.SecuritySettings.AllowUserPrinting = true;
searchablePdf.SecuritySettings.AllowUserCopyPasteContent = true;
searchablePdf.SaveAs("searchable-document.pdf");Imports IronPdf
Imports System
Imports System.Collections.Generic
Imports System.Net.Http
Imports System.Text
Imports System.Threading.Tasks
' --- Stage 1: Export PDF pages as images for OCR ---
Dim scannedPdf = PdfDocument.FromFile("input-document.pdf")
Dim imageFiles = scannedPdf.RasterizeToImageFiles(
"scan-page-{0}.png",
IronPdf.Imaging.ImageType.Png,
300 ' 300 DPI -- minimum for reliable OCR accuracy
)
' --- Stage 2: Process each image through OCR.net ---
Dim ocrResults As New List(Of String)()
For Each imageFile In imageFiles
' Replace this placeholder with your actual OCR.net API integration
Dim ocrText As String = Await SendImageToOcrNet(imageFile)
ocrResults.Add(ocrText)
Next
' --- Stage 3: Reassemble recognized text as a searchable PDF ---
Dim htmlBuilder As New StringBuilder()
htmlBuilder.Append("<!DOCTYPE html><html><head>
<style>body{font-family:Arial,sans-serif;margin:40px;}
.page{page-break-after:always;} pre{white-space:pre-wrap;}</style>
</head><body>")
For i As Integer = 0 To ocrResults.Count - 1
htmlBuilder.AppendFormat(
"<div class='page'><h2>Page {0}</h2><pre>{1}</pre></div>",
i + 1,
System.Web.HttpUtility.HtmlEncode(ocrResults(i))
)
Next
htmlBuilder.Append("</body></html>")
Dim renderer As New ChromePdfRenderer()
renderer.RenderingOptions.DPI = 300
renderer.RenderingOptions.EnableJavaScript = False
Dim searchablePdf = Await renderer.RenderHtmlAsPdfAsync(htmlBuilder.ToString())
searchablePdf.MetaData.Title = "OCR Processed Document"
searchablePdf.MetaData.Subject = "Searchable PDF from OCR"
searchablePdf.MetaData.CreationDate = DateTime.UtcNow
searchablePdf.SecuritySettings.AllowUserPrinting = True
searchablePdf.SecuritySettings.AllowUserCopyPasteContent = True
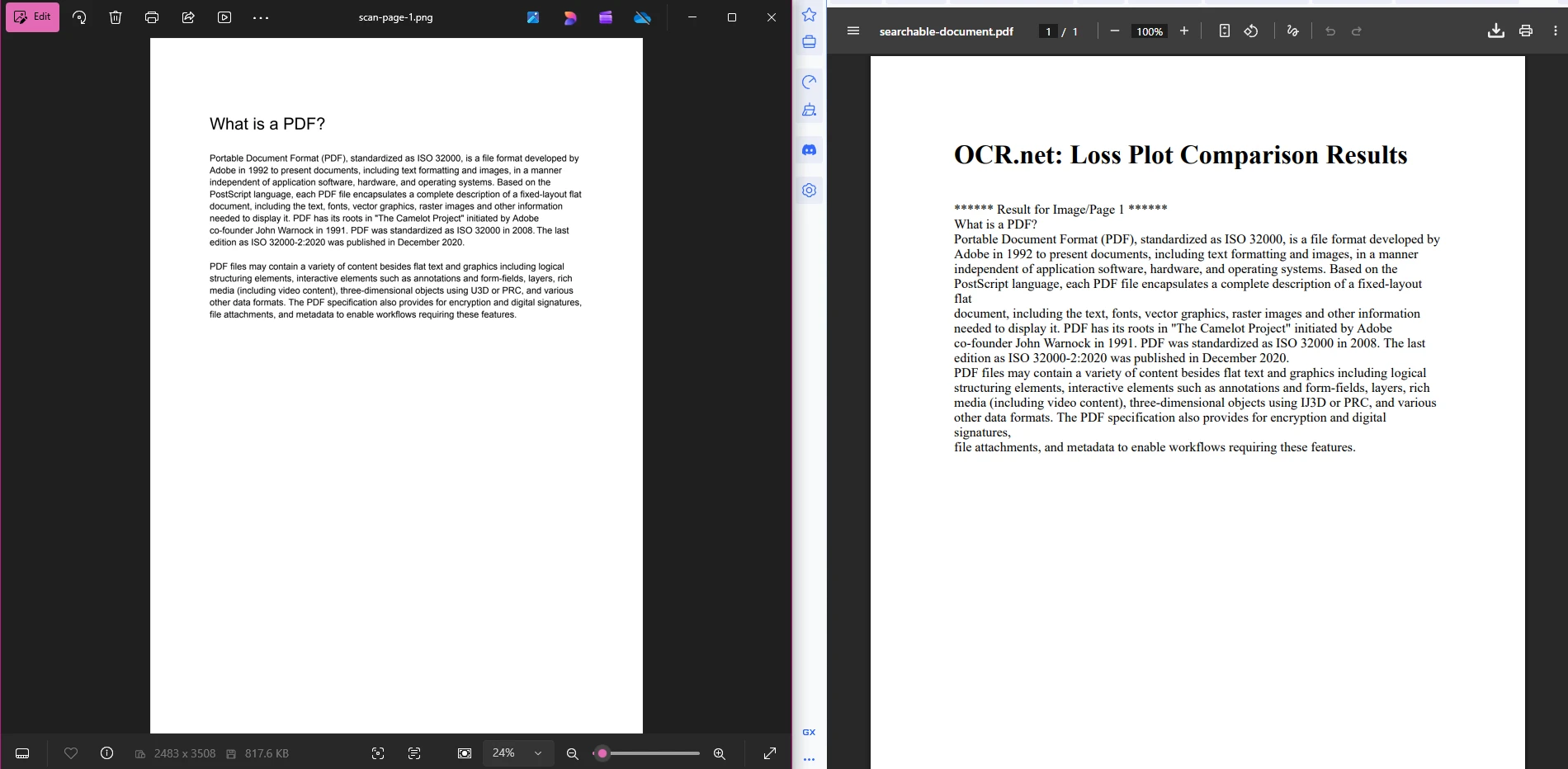
searchablePdf.SaveAs("searchable-document.pdf")Diese Pipeline ist bewusst einfach gehalten. In Phase 1 werden nummerierte PNG-Dateien erzeugt. In Phase 2 wird jede Datei an OCR.net gesendet und die zurückgegebenen Textzeichenfolgen werden gesammelt. In Phase 3 werden diese Zeichenketten in HTML eingebettet und mithilfe von IronPDF ein endgültiges PDF erstellt, in dem der Text vollständig auswählbar und durchsuchbar ist. Sie können Phase 3 erweitern, um PDF-Metadaten für die Dokumentenverwaltung oder Sicherheitseinstellungen für die Zugriffskontrolle anzuwenden.
Welche Docker-Konfiguration eignet sich am besten für diesen Workflow?
Mehrstufige Docker-Builds sorgen dafür, dass das endgültige Image klein bleibt und gleichzeitig alle Laufzeitabhängigkeiten enthält, die IronPDF unter Linux benötigt:
FROM mcr.microsoft.com/dotnet/sdk:8.0 AS build
WORKDIR /app
COPY *.csproj ./
RUN dotnet restore
COPY . ./
RUN dotnet publish -c Release -o out
FROM mcr.microsoft.com/dotnet/aspnet:8.0
WORKDIR /app
# IronPDF Linux runtime dependencies
RUN apt-get update && apt-get install -y \
libgdiplus \
libc6-dev \
libx11-dev \
&& rm -rf /var/lib/apt/lists/*
COPY --from=build /app/out .
HEALTHCHECK --interval=30s --timeout=3s --start-period=5s --retries=3 \
CMD curl -f http://localhost:8080/health/ready || exit 1
ENTRYPOINT ["dotnet", "OcrWorkflow.dll"]Für den Produktionsmaßstab empfiehlt sich der Einsatz von Kubernetes Jobs für Batch-OCR-Operationen. Kubernetes Jobs bieten automatische Wiederholungsversuche, Parallelitätskontrolle und Ressourcenisolation, sodass fehlgeschlagene Dokumentaufgaben andere Dienste nicht beeinträchtigen. Setzen Sie parallelism auf Ihre OCR.net API-Ebene und backoffLimit auf die Anzahl der Wiederholungsversuche eines fehlgeschlagenen Pods, bevor der Job die Aufgabe als fehlgeschlagen markiert.
Wie überwacht man Leistungskennzahlen in der Produktion?
Die Überwachung der OCR-Verarbeitungszeiten und Erfolgsquoten hilft dabei, Engpässe zu erkennen, bevor sie sich auf die Endbenutzer auswirken. Prometheus mit benutzerdefinierten Metriken ist ein praktischer Ansatz:
using Prometheus;
using System;
using System.Threading.Tasks;
// Prometheus metrics for OCR pipeline observability
var ocrRequestsTotal = Metrics
.CreateCounter("ocr_requests_total", "Total OCR requests processed");
var ocrDuration = Metrics
.CreateHistogram("ocr_duration_seconds", "OCR processing duration in seconds",
new HistogramConfiguration
{
Buckets = Histogram.LinearBuckets(0.1, 0.1, 10)
});
var activeOcrJobs = Metrics
.CreateGauge("ocr_active_jobs", "Currently active OCR jobs");
// Wrapper that tracks every OCR operation automatically
async Task<t> TrackOcrOperation<t>(Func<Task<t>> operation)
{
using (ocrDuration.NewTimer())
{
activeOcrJobs.Inc();
try
{
var result = await operation();
ocrRequestsTotal.Inc();
return result;
}
finally
{
activeOcrJobs.Dec();
}
}
}using Prometheus;
using System;
using System.Threading.Tasks;
// Prometheus metrics for OCR pipeline observability
var ocrRequestsTotal = Metrics
.CreateCounter("ocr_requests_total", "Total OCR requests processed");
var ocrDuration = Metrics
.CreateHistogram("ocr_duration_seconds", "OCR processing duration in seconds",
new HistogramConfiguration
{
Buckets = Histogram.LinearBuckets(0.1, 0.1, 10)
});
var activeOcrJobs = Metrics
.CreateGauge("ocr_active_jobs", "Currently active OCR jobs");
// Wrapper that tracks every OCR operation automatically
async Task<t> TrackOcrOperation<t>(Func<Task<t>> operation)
{
using (ocrDuration.NewTimer())
{
activeOcrJobs.Inc();
try
{
var result = await operation();
ocrRequestsTotal.Inc();
return result;
}
finally
{
activeOcrJobs.Dec();
}
}
}Imports Prometheus
Imports System
Imports System.Threading.Tasks
' Prometheus metrics for OCR pipeline observability
Dim ocrRequestsTotal = Metrics.CreateCounter("ocr_requests_total", "Total OCR requests processed")
Dim ocrDuration = Metrics.CreateHistogram("ocr_duration_seconds", "OCR processing duration in seconds",
New HistogramConfiguration With {
.Buckets = Histogram.LinearBuckets(0.1, 0.1, 10)
})
Dim activeOcrJobs = Metrics.CreateGauge("ocr_active_jobs", "Currently active OCR jobs")
' Wrapper that tracks every OCR operation automatically
Async Function TrackOcrOperation(Of T)(operation As Func(Of Task(Of T))) As Task(Of T)
Using ocrDuration.NewTimer()
activeOcrJobs.Inc()
Try
Dim result = Await operation()
ocrRequestsTotal.Inc()
Return result
Finally
activeOcrJobs.Dec()
End Try
End Using
End FunctionKombinieren Sie diese Metriken mit den Protokollierungsfunktionen von IronPDF , um Renderzeiten mit OCR-Dauern zu korrelieren. Wenn die OCR-Dauer sprunghaft ansteigt, ohne dass es zu einem entsprechenden Anstieg der Renderzeit kommt, liegt der Flaschenhals im OCR.net API-Aufruf oder in Ihrem Netzwerkpfad dorthin, nicht im Schritt der PDF-Generierung.
Was sind Ihre nächsten Schritte?
Die Kombination von OCR.net und IronPDF bietet Ihnen einen praktischen Weg zur Textextraktion und zur Erstellung durchsuchbarer PDFs in .NET. Die Pipeline deckt die wichtigsten Anwendungsfälle ab: Erstellen von PDFs aus HTML, Exportieren von Seiten in OCR-kompatibler Auflösung, Senden von Bildern an OCR.net und Zusammenfügen der Ergebnisse zu einem vollständig durchsuchbaren Dokument.
Wichtige Überlegungen bei der Überführung in die Produktion:
- Container-Setup: Verwenden Sie IronPDF Slim-Pakete und mehrstufige Docker-Builds, um die Image-Größen überschaubar zu halten.
- Ressourcenplanung: Konfigurieren Sie Speichergrenzen, die Ihren Dokumentgrößen und dem angestrebten Parallelverarbeitungsziel entsprechen.
- Überwachung: Implementieren Sie Prometheus-Metriken zusammen mit IronPDF Protokollierung , um Leistungseinbußen frühzeitig zu erkennen.
- Durchsatz: Nutzen Sie asynchrone Operationen und Batch-Warteschlangenverwaltung, um innerhalb der Ratenbegrenzungen von OCR.net zu arbeiten.
- Zuverlässigkeit: Implementierung einer exponentiellen Backoff-Wiederholungslogik und von Schutzmechanismen um den OCR.net API-Aufruf herum.
Beginnen Sie mit der kostenlosen Testlizenz , um den gesamten Workflow von Anfang bis Ende zu testen, bevor Sie sich für eine Produktionslizenz entscheiden. Die Testversion entfernt das Wasserzeichen und schaltet alle Funktionen frei, sodass Ihre Benchmark-Ergebnisse das Verhalten in der Produktionsumgebung genau widerspiegeln. Wenn Sie bereit sind, das Produkt einzusetzen, überprüfen Sie die IronPDF -Lizenzierungsoptionen, um diejenige Stufe zu finden, die Ihrem Nutzungsverhalten entspricht.
Häufig gestellte Fragen
Was macht OCR.net und wie verbindet es sich mit IronPDF?
OCR.net ist ein Deep-Learning-OCR-Dienst, der Bilddaten entgegennimmt und erkannten Text zurückgibt. IronPDF erzeugt PDFs und exportiert deren Seiten als Bilder. Die beiden Werkzeuge verbinden sich auf der Bildebene: IronPDF exportiert Seiten mit RasterizeToImageFiles(), diese Bilder gehen zu OCR.net für die Textextraktion, und IronPDF setzt die Ergebnisse als durchsuchbares PDF zusammen.
Welche DPI sollten Sie beim Exportieren von PDF-Seiten für OCR verwenden?
300 DPI ist das standardmäßige Minimum für zuverlässige OCR-Genauigkeit. Bei 300 DPI sind Textkanten scharf genug, damit das Modell ähnliche Zeichen unterscheiden kann. Bei 150 DPI oder weniger sinkt die Genauigkeit bei Serifenschriften und kleinem Druck. Verwenden Sie 600 DPI nur, wenn die Quelldokumente sehr kleinen oder beschädigten Text enthalten, da jede Seite bei 600 DPI Dateien produziert, die 4-5 Mal größer sind.
Wie gehen Sie in der Produktion mit OCR.net API-Rate-Limits um?
Kostenlose OCR.net-Konten erlauben 50 Anfragen pro Stunde. Bauen Sie eine exponentielle Backoff-Retry-Logik in Ihren OCR-Aufruf ein: Fangen Sie die Antwort 429 ab, warten Sie Math.Pow(2, attempt) Sekunden, und versuchen Sie es bis zu einem konfigurierten Maximum erneut. Für höheren Durchsatz, upgraden Sie zu einem bezahlten OCR.net-Plan oder stellen Sie Anfragen mit einem Hintergrundarbeiter in die Warteschlange.
Kann IronPDF innerhalb eines Docker-Containers unter Linux laufen?
Ja. Fügen Sie libgdiplus, libc6-dev und libx11-dev zur Laufzeitstufe Ihrer Dockerfile hinzu. Verwenden Sie Multi-Stage-Builds, um das endgültige Image klein zu halten. Die IronPDF Slim-Paketvariante reduziert die Bildgröße weiter, indem sie gebündelte Browser-Binärdateien ausschließt, wenn Sie IronPDF Engine als separaten Dienst ausführen.
Wie erstellen Sie ein durchsuchbares PDF aus OCR-Ergebnissen?
Sammeln Sie die Textstrings, die von OCR.net zurückgegeben werden, wickeln Sie sie in HTML mit einer Seitenumbruch-Klasse pro Dokumentseite ein und geben Sie das HTML an ChromePdfRenderer.RenderHtmlAsPdfAsync() weiter. Das resultierende PDF enthält auswählbaren, durchsuchbaren Text, den Benutzer und Suchmaschinen indexieren können.
Unterstützt dieser Workflow mehrsprachige Dokumente?
Ja. OCR.net unterstützt über 60 Sprachen. Wählen Sie die Zielsprache in der OCR.net-Schnittstelle oder dem API-Aufruf, bevor die Verarbeitung beginnt. IronPDF verarbeitet UTF-8-Ausgabe nativ, sodass Sprachen mit nicht-lateinischen Schriften im rekonstruierten durchsuchbaren PDF korrekt dargestellt werden.
Wie überwachen Sie die Leistung der OCR-Pipeline in der Produktion?
Fügen Sie Prometheus-Zähler, Histogramme und Pegel ein, um Ihre Bearbeitungsdienste zu verfolgen, einschließlich der gesamten Anfragen, Dauerverteilungen und aktiver Jobs. Kombinieren Sie Prometheus-Metriken mit IronPDFs benutzerdefiniertem Logging, um die Renderzeiten mit der OCR-API-Latenz zu korrelieren und Engpässe zu identifizieren.
Was ist der Unterschied zwischen OCR.net und IronOCR?
OCR.net ist ein externer Webdienst, der Bilder verarbeitet, die Sie über die API hochladen. IronOCR ist eine .NET-Bibliothek von Iron Software, die OCR-Verarbeitung lokal innerhalb Ihrer Anwendung ohne externe API-Aufrufe durchführt. IronOCR ist besser geeignet für Offline-Umgebungen oder wenn Sie geringere Latenz und mehr Kontrolle über die OCR-Engine benötigen.














