Conversor de Excel para PDF (Lista de ferramentas online gratuitas)
O que é ChatGPT?
O ChatGPT é um chatbot de grande porte baseado em modelo de linguagem, lançado pela OpenAI em 2022. Ele se destaca por permitir que os usuários criem e moldem um diálogo de acordo com a estrutura, o estilo, o nível de detalhe e a linguagem desejados. Cada ponto de discussão leva em consideração um contexto que considera perguntas e respostas anteriores, ou "engenharia de perguntas", usando a chave da API da OpenAI.
A base do ChatGPT é composta por modelos Transformer, que fazem parte da série exclusiva de Transformers pré-treinados generativos da OpenAI. Em seguida, esses modelos são otimizados para aplicações de conversação, combinando métodos de aprendizado supervisionado e por reforço. Originalmente publicado como uma prévia gratuita para pesquisa, o modelo de linguagem de IA ChatGPT agora é oferecido em um modelo freemium pela OpenAI devido à sua popularidade. A versão mais sofisticada, baseada no GPT-4, e o acesso prioritário a recursos atualizados são disponibilizados para clientes pagantes sob a marca 'ChatGPT Plus', enquanto os usuários podem acessar a versão gratuita utilizando o GPT-3.5.
O ChatGPT consegue ler arquivos PDF?
Bem, sim e não. Com a versão paga, pedir ao ChatGPT para extrair texto de um documento PDF é tão simples quanto enviar o arquivo para a caixa de bate-papo e pedir para extrair o texto ou resumir o conteúdo do PDF.
No entanto, não está isento de desvantagens. O ChatGPT fornecerá as informações em texto simples, o que significa que será necessário criar um novo documento PDF usando essas informações manualmente. É possível solicitar ao ChatGPT que crie um novo arquivo PDF a partir do texto extraído, mas isso está sujeito a problemas de formatação e links de download com mau funcionamento. Além disso, a personalização é limitada no ChatGPT, apresentando problemas frequentes com solicitações para adicionar cabeçalhos e rodapés aos seus documentos, por exemplo.
Até o momento da redação deste texto, a versão gratuita do ChatGPT não suporta anexos de arquivos, o que significa que é impossível solicitar que ele leia PDFs.
O que é o IronPDF?
O IronPDF foi desenvolvido para facilitar a criação, a navegação e a edição de arquivos PDF em frameworks .NET . Inclui uma API robusta para produzir, editar e alterar arquivos PDF, além de funcionar como um poderoso conversor de PDF. Xamarin, Blazor, Unity, aplicações HoloLens, Windows Forms, HTML, ASPX, Razor, .NET Core, ASP e WPF são apenas algumas das extensões compatíveis com o IronPDF.
O IronPDF utiliza o mecanismo do Chrome para converter HTML em PDF. Ele oferece suporte tanto a programas convencionais do Windows quanto a aplicativos ASP.NET online usando Microsoft .NET e .NET Core. Ele permite personalizar seus PDFs com diversas funções, com suporte para HTML5, JavaScript, CSS e imagens.
Ao utilizar a biblioteca IronPDF , os desenvolvedores podem ler e editar arquivos PDF sem usar o Acrobat Reader. Além disso, podem adicionar texto e gráficos, marcadores, marcas d'água, cabeçalhos e rodapés, bem como dividir e transferir propriedades de texto, mesclar páginas e extrair imagens de documentos PDF novos ou existentes.
Além disso, documentos PDF podem ser produzidos usando CSS e arquivos de mídia CSS. O IronPDF permite gerar, carregar e editar tanto documentos de escritório novos, como os do Microsoft Word, quanto formulários PDF desatualizados.
Extrair texto de um PDF usando o IronPDF
O IronPDF permite extrair texto de um PDF e convertê-lo em diversos formatos. Ele pode lidar com um ou vários documentos PDF, além de permitir que você extraia texto de um documento inteiro ou de páginas selecionadas, dando a você controle total sobre o conteúdo do seu PDF. Veja como começar:
Crie seu projeto no Visual Studio.
Primeiramente, abra o Visual Studio e vá em Arquivo -> Novo Projeto -> Aplicativo de Console. Digite o nome do seu projeto, escolha o local onde deseja salvá-lo e clique no botão Próximo. Selecione a versão mais recente do .NET Framework e clique em Criar. Assim que seu projeto estiver em funcionamento, é hora de adicionar nossa biblioteca.
Instale a biblioteca IronPDF.
O IronPDF é fácil de usar, mas é ainda mais fácil de instalar. Existem algumas maneiras de fazer isso:
Método 1: Console do Gerenciador de Pacotes NuGet
No Visual Studio, no Solution Explorer, clique com o botão direito do mouse em Referências e, em seguida, clique em Gerenciar Pacotes NuGet . Clique em "Procurar", pesquise por "IronPDF" e instale a versão mais recente. Se você vir isso, significa que está funcionando:
Você também pode acessar Ferramentas -> Gerenciador de Pacotes NuGet -> Console do Gerenciador de Pacotes e inserir a seguinte linha na guia Gerenciador de Pacotes:
Install-Package IronPdf
Por fim, você pode obter o IronPDF diretamente do site oficial do NuGet, IronPDF as instruções de download . Selecione a opção "Baixar Pacote" no menu à direita da página, clique duas vezes no arquivo baixado para instalá-lo automaticamente e recarregue a solução para começar a usá-la em seu projeto.
Não funcionou? Você pode encontrar ajuda específica para cada plataforma em nossos métodos avançados de instalação do NuGet .
Método 2: Utilizando um arquivo DLL
Você também pode obter o arquivo DLL do IronPDF diretamente conosco e adicioná-lo manualmente ao Visual Studio. Para obter instruções completas e links para os pacotes DLL do Windows, MacOS e Linux, consulte nosso guia de instalação dedicado ao IronPDF .
Adicione o namespace IronPDF
Lembre-se sempre de iniciar seu código com o namespace IronPDF , assim:
using IronPdf;using IronPdf;Imports IronPdfExtrair texto de um documento PDF inteiro
Extrair texto de documentos PDF é tão simples quanto duas linhas de código. Neste exemplo de código, convertemos o conteúdo de um PDF em um formato baseado em texto:
// Load the PDF document from a file into a PdfDocument object
var pdfDocument = IronPdf.PdfDocument.FromFile("Demo.pdf");
// Extract all text from the entire PDF and store it in a string
string AllText = pdfDocument.ExtractAllText();// Load the PDF document from a file into a PdfDocument object
var pdfDocument = IronPdf.PdfDocument.FromFile("Demo.pdf");
// Extract all text from the entire PDF and store it in a string
string AllText = pdfDocument.ExtractAllText();' Load the PDF document from a file into a PdfDocument object
Dim pdfDocument = IronPdf.PdfDocument.FromFile("Demo.pdf")
' Extract all text from the entire PDF and store it in a string
Dim AllText As String = pdfDocument.ExtractAllText()Vamos analisá-lo - a função FromFile() carrega o arquivo PDF do seu computador e o transforma em um objeto PdfDocument. A partir daí, a função ExtractAllText() do objeto da classe PdfDocument recupera todo o texto do arquivo PDF inteiro e o armazena em uma string processável.
Abaixo, você pode ver o PDF e o texto gerado no console:
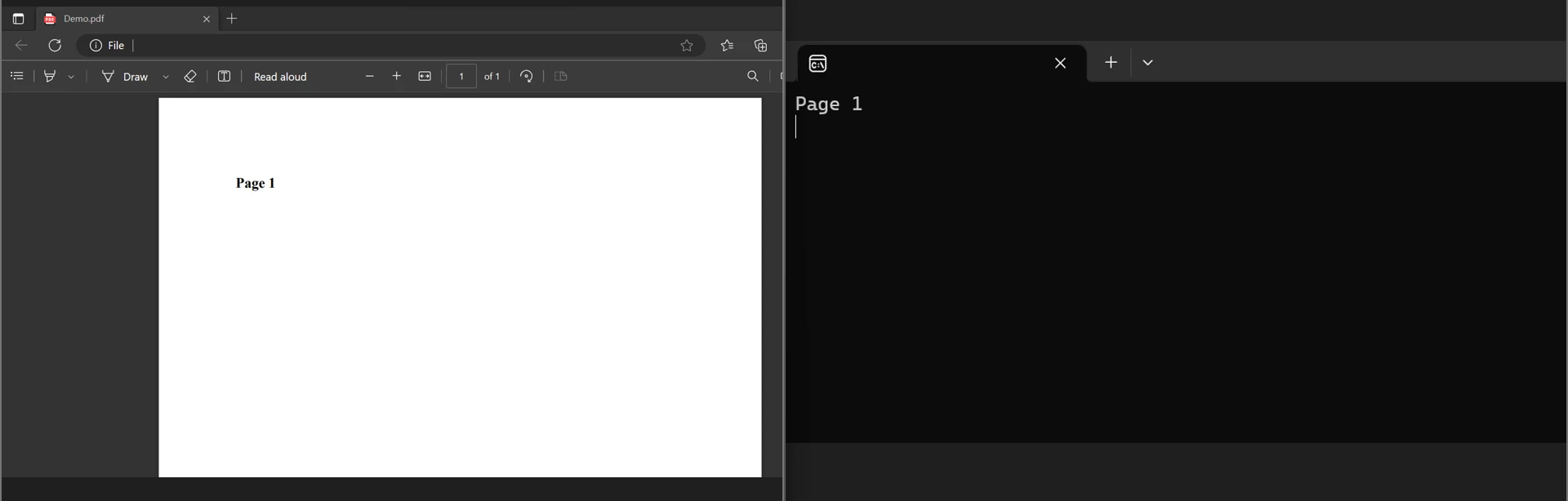
Extrair texto de páginas individuais em um documento PDF
using IronPdf;
// Load the PDF document from a file
PdfDocument PDF = PdfDocument.FromFile("result.pdf");
// Loop through each page of the PDF document
for (var index = 0; index < PDF.PageCount; index++)
{
// Page numbers are typically 1-based, so we add 1 to the index
int PageNumber = index + 1;
// Extract text from the current page
string Text = PDF.ExtractTextFromPage(index);
}using IronPdf;
// Load the PDF document from a file
PdfDocument PDF = PdfDocument.FromFile("result.pdf");
// Loop through each page of the PDF document
for (var index = 0; index < PDF.PageCount; index++)
{
// Page numbers are typically 1-based, so we add 1 to the index
int PageNumber = index + 1;
// Extract text from the current page
string Text = PDF.ExtractTextFromPage(index);
}Imports IronPdf
' Load the PDF document from a file
Private PDF As PdfDocument = PdfDocument.FromFile("result.pdf")
' Loop through each page of the PDF document
For index = 0 To PDF.PageCount - 1
' Page numbers are typically 1-based, so we add 1 to the index
Dim PageNumber As Integer = index + 1
' Extract text from the current page
Dim Text As String = PDF.ExtractTextFromPage(index)
Next indexSemelhante ao código anterior, aqui o arquivo PDF inteiro é carregado antes de ser convertido em um objeto PDF. PageCount retorna o número total de páginas no arquivo, o método ExtractTextFromPage() extrai o texto, enquanto o loop for lida com a variedade de páginas como um parâmetro. A partir daí, nosso texto é armazenado na variável de string. Para extrair informação do PDF página por página, utilizamos o loop for.
Para obter mais informações sobre como extrair texto e imagens incorporados em PDFs, consulte este guia detalhado sobre extração de texto e imagem de PDFs .
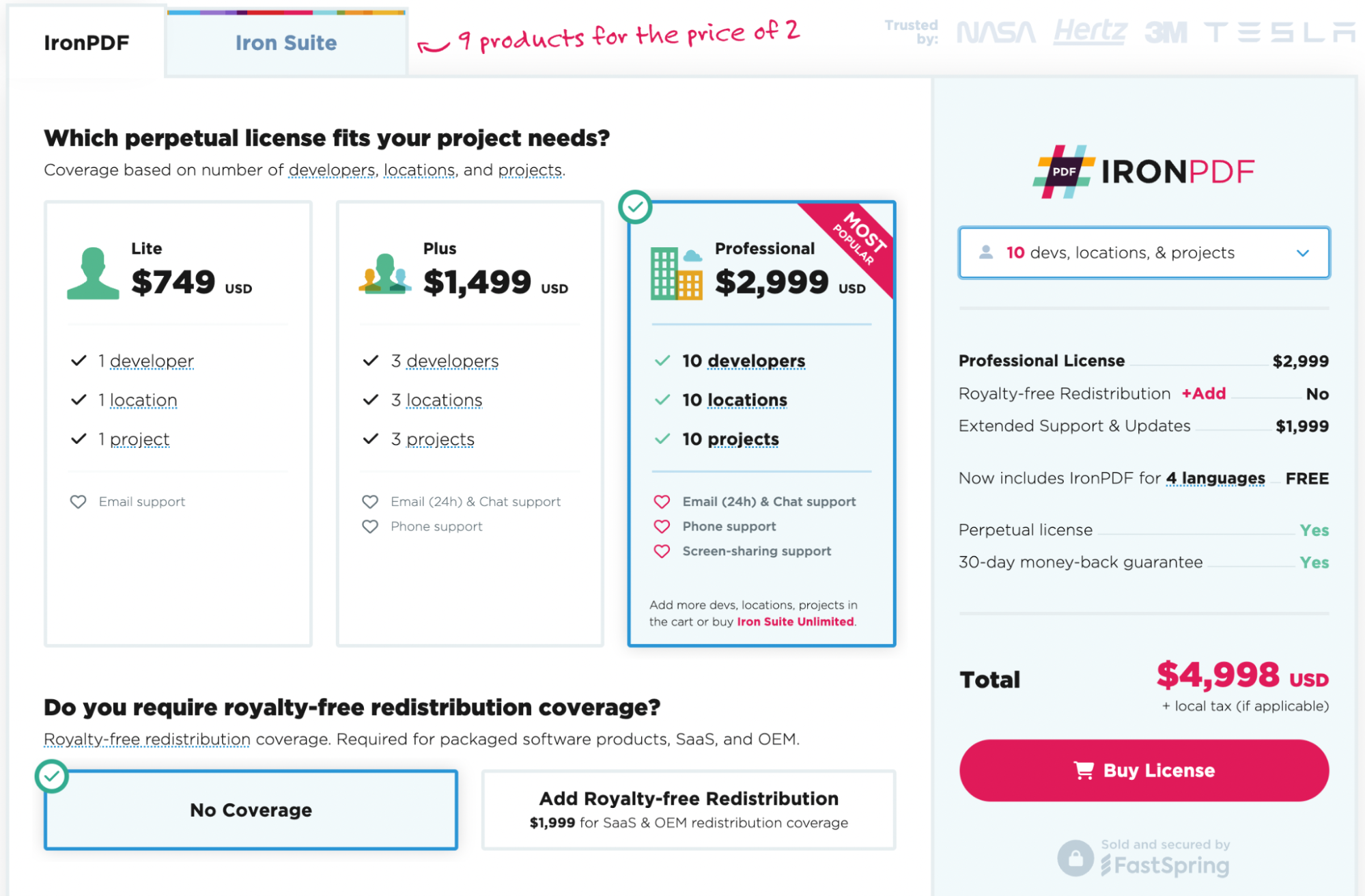
IronPDF ou ChatGPT - Qual é o melhor?
Existem muitas ferramentas disponíveis que permitem extrair conteúdo de um PDF, incluindo o ChatGPT. No entanto, o IronPDF foi desenvolvido com foco na personalização e no controle do desenvolvedor, o que o torna um leitor de PDF líder do setor. E a leitura de PDFs é apenas o começo: com conversão de HTML para PDF, ferramentas de formatação de PDF, recursos integrados de segurança e conformidade e muito mais, o IronPDF é a ferramenta número um para todas as suas necessidades de documentos PDF.
O IronPDF também oferece ampla compatibilidade. Construído para o ecossistema .NET , ele oferece suporte ao .NET Framework, .NET Standard e .NET Core 3.1 a 8, e é constantemente atualizado para se manter na vanguarda.
Pronto para colocar as mãos no IronPDF? Você pode começar com nosso teste gratuito de 30 dias e explorar os recursos do IronPDF . Além disso, é totalmente gratuito para uso em desenvolvimento, permitindo que você realmente veja do que ele é capaz. E se você gostar do que vê, o IronPDF começa a partir de $999 para acesso completo às ferramentas do IronPDF. Para economizar ainda mais, confira o pacote Iron Suite, que oferece 9 ferramentas pelo preço de duas . Boa programação!