IronPDF vs ChatGPT - Text aus PDF-Dokumenten extrahieren
Was ist ChatGPT?
ChatGPT ist ein auf einem großen Sprachmodell basierender Chatbot, der 2022 von OpenAI veröffentlicht wurde. Er ist bemerkenswert, da er es Nutzern ermöglicht, einen Dialog in einer gewünschten Struktur, einem bestimmten Stil, Detailgrad und einer bestimmten Sprache zu gestalten. Jeder Gesprächspunkt berücksichtigt den Kontext aus früheren Eingaben und Antworten – auch bekannt als „Prompt-Engineering" über den OpenAI-API-Schlüssel.
Die Grundlage von ChatGPT bilden Transformer-Modelle, die Teil von OpenAIs exklusiver generativer Transformer-Serie sind. Diese Modelle werden durch eine Kombination aus überwachtem und verstärkendem Lernen für Konversationsanwendungen optimiert. Ursprünglich als kostenlose Forschungsvorschau veröffentlicht, wird das ChatGPT-KI-Sprachmodell aufgrund seiner Beliebtheit nun von OpenAI auf Freemium-Basis angeboten. Die leistungsfähigere GPT-4-basierte Version sowie vorrangiger Zugang zu aktualisierten Funktionen sind zahlenden Kunden unter dem Markennamen „ChatGPT Plus" vorbehalten, während Nutzer auf die kostenlose Stufe mit GPT-3.5 zugreifen können.
Kann ChatGPT PDF-Dateien lesen?
Die Antwort lautet: Jein. Mit der kostenpflichtigen Version ist das Extrahieren von Text aus einem PDF-Dokument so einfach wie das Hochladen der Datei in den Chat und die Bitte um eine Text- oder Inhaltszusammenfassung des PDFs.
Allerdings ist dies nicht ohne Einschränkungen. ChatGPT liefert die Informationen im Klartext, was bedeutet, dass das Erstellen eines neuen PDF-Dokuments mit diesen Informationen ein manueller Prozess ist. Es ist zwar möglich, ChatGPT zu bitten, eine neue PDF-Datei aus dem extrahierten Text zu erstellen, doch neigt es dabei zu Formatierungsproblemen und fehlerhaften Download-Links. Auch die Anpassungsmöglichkeiten sind bei ChatGPT eingeschränkt, was beispielsweise häufig zu Problemen beim Hinzufügen von Kopf- und Fußzeilen führt.
Derzeit unterstützt die kostenlose Stufe von ChatGPT keine Dateianhänge, was bedeutet, dass es unmöglich ist, es zu bitten, PDFs zu lesen.
Was ist IronPDF?
IronPDF wurde entwickelt, um das Erstellen, Durchsuchen und Bearbeiten von PDF-Dateien in .NET-Frameworks zu erleichtern. Es umfasst eine robuste API zur Erstellung, Bearbeitung und Veränderung von PDF-Dateien und dient zusätzlich als leistungsstarker PDF-Konverter. Xamarin, Blazor, Unity, HoloLens-Anwendungen, Windows Forms, HTML, ASPX, Razor, .NET Core, ASP und WPF sind nur einige der Erweiterungen, die mit IronPDF kompatibel sind.
IronPDF nutzt die Chrome-Engine, um HTML in PDF zu konvertieren. Es unterstützt sowohl konventionelle Windows-Programme als auch Online-ASP.NET-Apps mit Microsoft.NET und .NET Core. Es ermöglicht Ihnen, Ihre PDFs mit einer Vielzahl von Funktionen anzupassen, unterstützt HTML5, JavaScript, CSS und Bilder.
Durch die Verwendung der IronPDF-Bibliothek können Entwickler PDF-Dateien ohne Acrobat Reader lesen und bearbeiten. Darüber hinaus können sie Text und Grafiken hinzufügen, Lesezeichen, Wasserzeichen, Kopf- und Fußzeilen sowie Texteigenschaften aufteilen und übertragen, Seiten zusammenführen und Bilder aus neuen oder bestehenden PDF-Dokumenten extrahieren.
Zusätzlich können PDF-Dokumente unter Verwendung von CSS und CSS-Mediendateien erstellt werden. IronPDF ermöglicht es Ihnen, sowohl neue Office-Dokumente wie Microsoft Word als auch veraltete PDF-Formulare zu generieren, hochzuladen und zu bearbeiten.
Mit IronPDF Text aus einem PDF-Dokument extrahieren
IronPDF ermöglicht es, Text aus einem PDF zu extrahieren und in eine Vielzahl von Formaten zu konvertieren. Es kann einzelne oder mehrere PDF-Dokumente verarbeiten und ermöglicht es Ihnen, Text aus einem gesamten Dokument oder ausgewählten Seiten zu extrahieren - Sie haben die volle Kontrolle über Ihre PDF-Inhalte. So fangen Sie an:
Erstellen Sie Ihr Projekt in Visual Studio
Öffnen Sie zuerst Visual Studio und gehen Sie zu Datei -> Neues Projekt -> Konsolenanwendung. Geben Sie Ihren Projektnamen ein, wählen Sie den Speicherort aus, den Sie speichern möchten, und klicken Sie auf die Schaltfläche Weiter. Wählen Sie das neueste .NET-Framework und dann Erstellen. Sobald Ihr Projekt läuft, ist es Zeit, unsere Bibliothek hinzuzufügen.
Die IronPDF-Bibliothek installieren
IronPDF ist einfach zu verwenden, aber noch einfacher zu installieren. Es gibt einige Möglichkeiten, wie Sie dies tun können:
Methode 1: NuGet Paket-Manager-Konsole
In Visual Studio klicken Sie im Lösungsexplorer mit der rechten Maustaste auf Verweise und dann auf NuGet-Pakete verwalten. Klicken Sie auf Durchsuchen, suchen Sie nach 'IronPDF' und installieren Sie die neueste Version. Wenn Sie dies sehen, funktioniert es:
Sie können auch zu Tools -> NuGet-Paket-Manager -> Paket-Manager-Konsole gehen und folgende Zeile im Paket-Manager-Tab eingeben:
Install-Package IronPdf
Schließlich können Sie IronPDF direkt über NuGets offizielle Website mit IronPDF-Download-Anweisungen erhalten. Wählen Sie die Option Download-Paket aus dem Menü rechts auf der Seite, doppelklicken Sie auf Ihren Download, um es automatisch zu installieren, und laden Sie die Lösung neu, um sie in Ihrem Projekt zu verwenden.
Funktionierte nicht? Sie finden plattspezifische Hilfe in unseren erweiterten NuGet-Installationsmethoden.
Methode 2: Verwenden einer DLL-Datei
Sie können die IronPDF-DLL-Datei auch direkt von uns erhalten und manuell zu Visual Studio hinzufügen. Für vollständige Anweisungen und Links zu den Windows-, MacOS- und Linux-DLL-Paketen, lesen Sie unseren dedizierten IronPDF-Installationsleitfaden.
Den IronPDF-Namensraum hinzufügen
Vergessen Sie nicht, Ihren Code mit dem IronPDF-Namespace zu beginnen, wie folgt:
using IronPdf;using IronPdf;Imports IronPdfText aus ganzem PDF-Dokument extrahieren
Text aus PDF-Dokumenten zu extrahieren, ist so einfach wie zwei Zeilen Code. In diesem Codebeispiel konvertieren wir PDF-Inhalte in ein textbasiertes Format:
// Load the PDF document from a file into a PdfDocument object
var pdfDocument = IronPdf.PdfDocument.FromFile("Demo.pdf");
// Extract all text from the entire PDF and store it in a string
string AllText = pdfDocument.ExtractAllText();// Load the PDF document from a file into a PdfDocument object
var pdfDocument = IronPdf.PdfDocument.FromFile("Demo.pdf");
// Extract all text from the entire PDF and store it in a string
string AllText = pdfDocument.ExtractAllText();' Load the PDF document from a file into a PdfDocument object
Dim pdfDocument = IronPdf.PdfDocument.FromFile("Demo.pdf")
' Extract all text from the entire PDF and store it in a string
Dim AllText As String = pdfDocument.ExtractAllText()Gehen wir es durch – die Funktion FromFile() lädt die PDF-Datei von Ihrem Computer und wandelt sie in ein PdfDocument-Objekt um. Von dort aus ruft die Funktion ExtractAllText() des PdfDocument-Klassenobjekts den gesamten Text aus der gesamten PDF-Datei ab und speichert ihn in einer verarbeitbaren Zeichenkette.
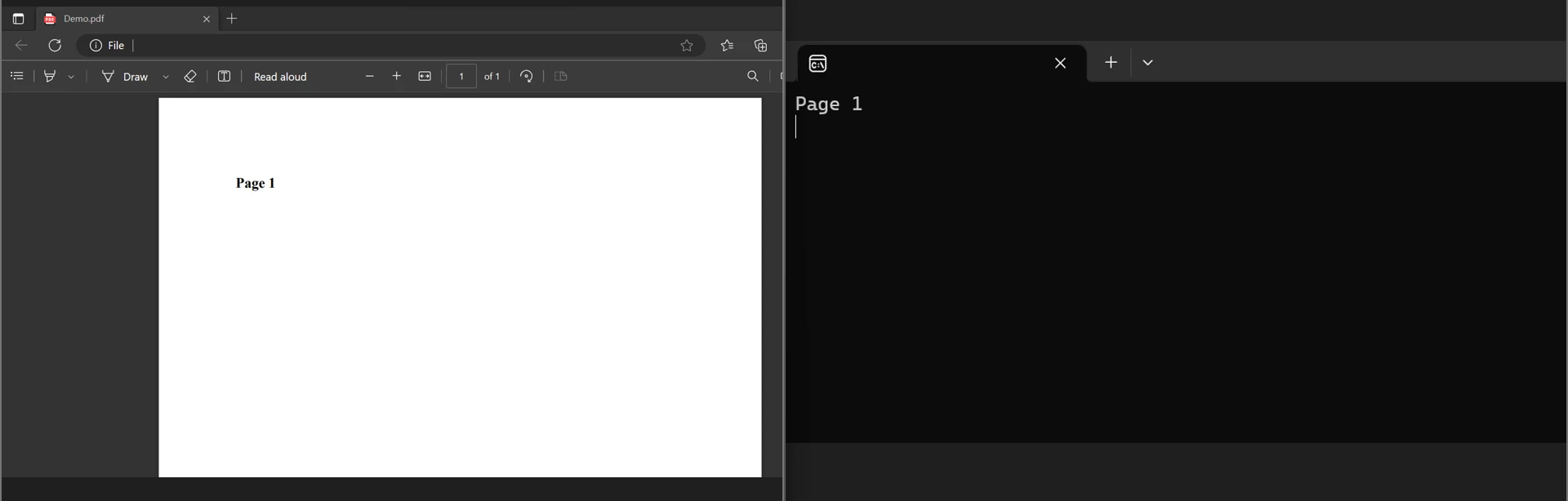
Unten sehen Sie die PDF- und Textausgabe in der Konsole:
Text aus einzelnen Seiten eines PDF-Dokuments extrahieren
using IronPdf;
// Load the PDF document from a file
PdfDocument PDF = PdfDocument.FromFile("result.pdf");
// Loop through each page of the PDF document
for (var index = 0; index < PDF.PageCount; index++)
{
// Page numbers are typically 1-based, so we add 1 to the index
int PageNumber = index + 1;
// Extract text from the current page
string Text = PDF.ExtractTextFromPage(index);
}using IronPdf;
// Load the PDF document from a file
PdfDocument PDF = PdfDocument.FromFile("result.pdf");
// Loop through each page of the PDF document
for (var index = 0; index < PDF.PageCount; index++)
{
// Page numbers are typically 1-based, so we add 1 to the index
int PageNumber = index + 1;
// Extract text from the current page
string Text = PDF.ExtractTextFromPage(index);
}Imports IronPdf
' Load the PDF document from a file
Private PDF As PdfDocument = PdfDocument.FromFile("result.pdf")
' Loop through each page of the PDF document
For index = 0 To PDF.PageCount - 1
' Page numbers are typically 1-based, so we add 1 to the index
Dim PageNumber As Integer = index + 1
' Extract text from the current page
Dim Text As String = PDF.ExtractTextFromPage(index)
Next indexÄhnlich wie im vorherigen Code wird hier das gesamte PDF-Dokument geladen, bevor es in ein PDF-Objekt konvertiert wird. Die Methode PageCount gibt die Gesamtzahl der Seiten in der Datei zurück, die Methode ExtractTextFromPage() extrahiert den Text, während die Schleife for die Seitenvielfalt als Parameter verarbeitet. Von dort aus wird unser Text in der Zeichenfolgenvariablen gespeichert. Um Informationen seitenweise aus der PDF-Datei zu extrahieren, verwenden wir die for Schleife.
Für weitere Informationen zur Extraktion eingebetteter Texte und Bilder aus PDFs, lesen Sie diesen detaillierten Leitfaden zur Text- und Bilderextraktion aus PDFs.
IronPDF vs. ChatGPT – Was ist besser?
Es gibt viele Werkzeuge, die das Extrahieren von Inhalten aus einem PDF ermöglichen, darunter auch ChatGPT. IronPDF wurde jedoch mit dem Ziel entwickelt, maximale Anpassung und Entwicklerkontrolle zu bieten, und ist damit ein branchenführendes PDF-Werkzeug. Das Lesen von PDFs ist dabei erst der Anfang – mit HTML-zu-PDF-Konvertierung, PDF-Formatierungswerkzeugen, integrierten Sicherheits- und Compliance-Funktionen und vielem mehr ist IronPDF das erstklassige Tool für alle Ihre PDF-Anforderungen.
IronPDF bietet auch eine große Kompatibilität. Gebaut für das .NET-Ökosystem, unterstützt es .NET Framework, .NET Standard, und .NET Core 3.1 bis 8 und wird kontinuierlich aktualisiert, um auf dem neuesten Stand der Technik zu bleiben.
Bereit, IronPDF selbst auszuprobieren? Sie können mit unserem 30-tägigen kostenlosen Test beginnen und die IronPDF-Funktionen erkunden. Es ist auch völlig kostenlos für Entwicklungszwecke, sodass Sie wirklich sehen können, woraus es besteht. Und wenn Ihnen gefällt, was Sie sehen, erhalten Sie IronPDF bereits ab $999 für den vollen Zugriff auf die IronPDF -Tools . Wenn Sie noch mehr sparen möchten, sollten Sie sich das Iron Suite-Paket anschauen, das 9 Tools zum Preis von zwei bietet. Viel Spaß beim Coden!