


Java PDF do pliku graficznego
Konwertuj dokumenty PDF na formaty obrazów, takie jak JPEG, PNG lub TIFF w Javie, używając metody toBufferedImages IronPDF. Po prostu załaduj plik PDF, wywołaj toBufferedImages, aby uzyskać listę obiektów BufferedImage, a następnie zapisz każdy obraz na dysk przy użyciu ImageIO.
Szybki start: Konwersja plików PDF na obrazy w Javie
-
Dodaj zależność IronPDF do swojego projektu Maven: ```xml :title=pom.xml
com.ironsoftware ironpdf 2022.11.0 -
Załaduj dokument PDF:
PdfDocument pdf = PdfDocument.fromFile(Paths.get("document.pdf"));PdfDocument pdf = PdfDocument.fromFile(Paths.get("document.pdf"));JAVA - Konwersja na obrazy i zapis:
List<BufferedImage> images = pdf.toBufferedImages(); for (int i = 0; i < images.size(); i++) { ImageIO.write(images.get(i), "PNG", new File("page_" + i + ".png")); }List<BufferedImage> images = pdf.toBufferedImages(); for (int i = 0; i < images.size(); i++) { ImageIO.write(images.get(i), "PNG", new File("page_" + i + ".png")); }JAVA
Czym jest konwersja plików PDF na obrazy i dlaczego jest potrzebna?
Konwersja stron PDF na pliki graficzne, takie jak JPEG, PNG lub TIFF, ma wiele zastosowań w tworzeniu oprogramowania. Być może potrzebne będą obrazy konkretnych stron PDF do wykorzystania w innym miejscu, ale jedyną dostępną opcją jest wykonanie zrzutów ekranu. Tradycyjny kod Java sprawia, że konwersja ta jest prawie niemożliwa. IronPDF rozwiązuje to wyzwanie w prosty sposób.
Konwersja plików PDF na obrazy jest niezbędna w wielu sytuacjach biznesowych: podczas tworzenia miniatur dla systemów zarządzania dokumentami, generowania obrazów podglądu dla aplikacji internetowych, wyodrębniania treści wizualnych do prezentacji lub konwersji dokumentów w celu wyświetlenia na urządzeniach, które nie obsługują renderowania plików PDF. IronPDF upraszcza to złożone zadanie, udostępniając solidny interfejs API, który wewnętrznie obsługuje wszystkie złożone procesy renderowania.
Jak przekonwertować plik PDF na obraz w Javie
- Zainstaluj bibliotekę Java, aby konwertować pliki PDF na różne formaty obrazów
- Użyj metody
toBufferedImages,aby przekonwertować plik PDF na obraz - Konwertuj adres URL na obraz, pobierając najpierw plik PDF za pomocą metody
renderUrlAsPdf - Skorzystaj z kroku 2, aby przekonwertować plik PDF do pożądanego formatu obrazu
- Użyj metody
writedo wyeksportowania każdego obrazu
Czym jest IronPDF for Java i w jaki sposób może pomóc?
IronPDF for Java to biblioteka, która umożliwia tworzenie, przygotowywanie i zarządzanie plikami PDF. Programiści używają go do odczytu, generowania i modyfikowania plików PDF bez programu Adobe Acrobat. IronPDF obsługuje niestandardowe nagłówki/stopki, podpisy, załączniki, hasła i mechanizmy zabezpieczeń. Oferuje pełną obsługę wielowątkowości i asynchroniczności w celu poprawy wydajności. IronPDF współpracuje z projektami opartymi na Maven.
Biblioteka doskonale sprawdza się w konwersji HTML do PDF, umożliwiając programistom wykorzystanie posiadanej wiedzy z zakresu HTML/CSS podczas tworzenia plików PDF. Oprócz podstawowej konwersji IronPDF oferuje zaawansowane funkcje, takie jak dodawanie tła i pierwszego planu, tworzenie i wypełnianie formularzy oraz stosowanie niestandardowych znaków wodnych. W przypadku konwersji plików PDF na obrazy IronPDF zapewnia płynne API, które zachowuje jakość, oferując jednocześnie elastyczność w zakresie formatów wyjściowych.
Poniżej omówimy, jak konwertować strony PDF do formatów graficznych, takich jak JPEG, JPG lub PNG, przy użyciu języka Java.
Jakie warunki wstępne muszę spełnić przed rozpoczęciem pracy?
Przed rozpoczęciem upewnij się, że spełnione są następujące warunki wstępne:
- Java zainstalowana z ścieżką ustawioną w zmiennych środowiskowych. Zobacz ten przewodnik instalacji Java.
- Zainstalowane środowisko IDE dla języka Java (Eclipse lub IntelliJ). Pobierz Eclipse lub IntelliJ.
- Maven zintegrowany z Twoim środowiskiem IDE. Zobacz ten samouczek dotyczący instalacji Mavena.
- Klucze licencyjne skonfigurowane do użytku komercyjnego.
Jak zainstalować IronPDF for Java?
Po spełnieniu wszystkich wymagań instalacja IronPDF jest prosta. Szczegółowe instrukcje konfiguracji można znaleźć w dokumentacji dotyczącej rozpoczęcia pracy.
Aby korzystać z IronPDF for Java, potrzebne jest środowisko IDE. W tym artykule używamy JetBrains IntelliJ IDEA do instalacji zależności i uruchamiania przykładów.
Najpierw otwórz JetBrains IntelliJ IDEA i utwórz nowy projekt Maven.
Utwórz nowy projekt Maven
Pojawi się nowe okno. Wpisz nazwę projektu i kliknij Zakończ.
Nazwa nowego projektu
Po kliknięciu Zakończ nowy projekt otwiera się z pom.xml wyświetlonym domyślnie. Potrzebujemy tego pliku, aby dodać zależności Maven dla IronPDF.
Nowy projekt
Dodaj następujące zależności do pliku pom.xml. Możesz również pobrać plik API JAR ze strony Maven Repository dla IronPDF. W przypadku wdrożeń w chmurze zapoznaj się z naszymi przewodnikami dotyczącymi AWS, Azure lub Google Cloud.
<dependencies>
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2022.11.0</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.36</version>
</dependency>
</dependencies><dependencies>
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2022.11.0</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.36</version>
</dependency>
</dependencies>Gdy dodasz zależności do pom.xml, w prawym górnym rogu pojawi się mała ikona.
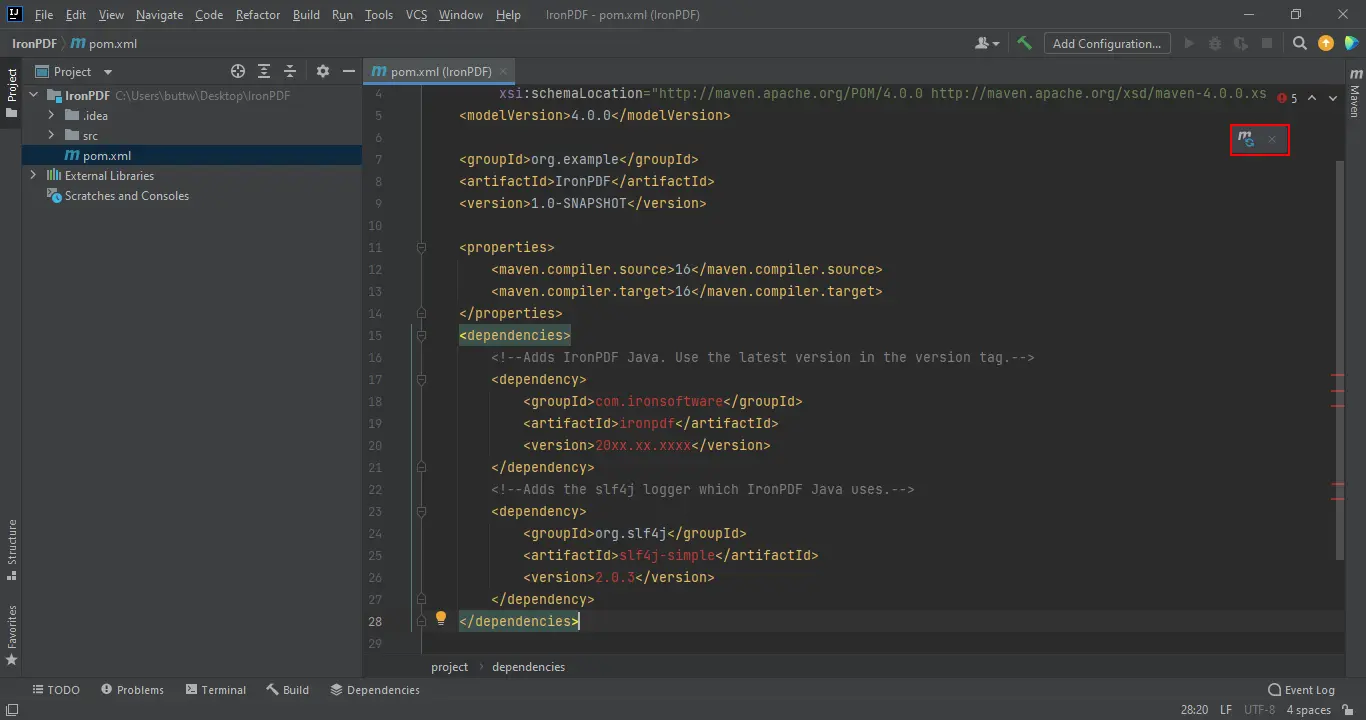
Zależności Maven
Kliknij tę ikonę, aby zainstalować zależności Maven. Instalacja zajmuje kilka minut, w zależności od szybkości połączenia internetowego. Po instalacji zapoznaj się z pełną dokumentacją API, aby zrozumieć wszystkie dostępne funkcje.
Jak przekonwertować pliki PDF na obrazy za pomocą IronPDF?
Korzystając z IronPDF for Java, konwersja plików PDF do formatów graficznych, takich jak JPEG, wymaga zaledwie kilku wierszy kodu. Konwertuje wejściowy dokument PDF na strumień wyjściowy obrazów. Metoda toBufferedImages zwraca listę obiektów List<BufferedImage> ułożonych w kolejności rosnącej według numeru strony.
IronPDF konwertuje dokumenty PDF na obrazy, a także może tworzyć obrazy bezpośrednio z adresów URL i kodu HTML. Ta elastyczność sprawia, że idealnie nadaje się do różnych zastosowań, od tworzenia podglądów dokumentów po generowanie miniatur dla systemów zarządzania treścią.
Jak przekonwertować istniejący dokument PDF na obrazy?
Ten przykład konwertuje cały dokument PDF na obrazy. Napisz poniższy kod i uruchom program. Aby zapoznać się z innymi przykładami konwersji plików PDF na obrazy, odwiedź naszą sekcję przykładów kodu rasteryzacji.
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String [] args) throws IOException {
// Load the PDF document from a file
PdfDocument instance = PdfDocument.fromFile(Paths.get("business_plan.pdf"));
// Convert the PDF pages into a list of BufferedImage objects
List<BufferedImage> extractedImages = instance.toBufferedImages();
// Set image conversion options
ToImageOptions rasterOptions = new ToImageOptions();
rasterOptions.setImageMaxHeight(800);
rasterOptions.setImageMaxWidth(500);
// Convert the pages using the specified options
List<BufferedImage> sizedExtractedImages = instance.toBufferedImages(rasterOptions, PageSelection.allPages());
int pageIndex = 1;
// Loop through each image and write to the file system
for (BufferedImage extractedImage : sizedExtractedImages) {
String fileName = "assets/images/" + pageIndex++ + ".png";
ImageIO.write(extractedImage, "PNG", new File(fileName));
}
}
}import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String [] args) throws IOException {
// Load the PDF document from a file
PdfDocument instance = PdfDocument.fromFile(Paths.get("business_plan.pdf"));
// Convert the PDF pages into a list of BufferedImage objects
List<BufferedImage> extractedImages = instance.toBufferedImages();
// Set image conversion options
ToImageOptions rasterOptions = new ToImageOptions();
rasterOptions.setImageMaxHeight(800);
rasterOptions.setImageMaxWidth(500);
// Convert the pages using the specified options
List<BufferedImage> sizedExtractedImages = instance.toBufferedImages(rasterOptions, PageSelection.allPages());
int pageIndex = 1;
// Loop through each image and write to the file system
for (BufferedImage extractedImage : sizedExtractedImages) {
String fileName = "assets/images/" + pageIndex++ + ".png";
ImageIO.write(extractedImage, "PNG", new File(fileName));
}
}
}Wynik zostanie zapisany w folderze zasobów projektu (należy utworzyć ten folder przed uruchomieniem programu) z numeracją zaczynającą się od 1 i zwiększającą się dla każdej strony PDF. Zastosuj zaawansowane funkcje, takie jak kompresja obrazów lub dodawanie znaków wodnych do plików wyjściowych.
Wyjście z pliku PDF do obrazów
Jak przekonwertować adres URL na plik PDF, a następnie na obrazy?
IronPDF konwertuje HTML bezpośrednio do formatu PDF, a następnie konwertuje każdą stronę wygenerowanego pliku PDF na obrazy. Ta funkcja pozwala na przechwytywanie treści internetowych w postaci obrazów, co jest przydatne do archiwizacji stron internetowych, tworzenia zrzutów ekranu do dokumentacji lub generowania wizualnych raportów z internetowych pulpitów nawigacyjnych.
W tym przykładzie wykorzystano stronę internetową Amazon. Program renderuje stronę Amazon.com do formatu PDF, a następnie zapisuje każdą stronę PDF jako obrazy przechowywane w folderze zasobów. W przypadku stron zabezpieczonych wymagających uwierzytelnienia zapoznaj się z naszym przewodnikiem dotyczącym logowania do stron internetowych i systemów.
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image BufferedImage;
import java.io.File;
import java.io.IOException;
import java.util.List;
public class Main {
public static void main(String [] args) throws IOException {
// Generate a PDF from a URL
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://www.amazon.com/?tag=hp2-brobookmark-us-20");
// Convert the PDF pages into a list of BufferedImage objects
List<BufferedImage> extractedImages = pdf.toBufferedImages();
// Set image conversion options
ToImageOptions rasterOptions = new ToImageOptions();
rasterOptions.setImageMaxHeight(800);
rasterOptions.setImageMaxWidth(500);
// Convert the pages using the specified options
List<BufferedImage> sizedExtractedImages = pdf.toBufferedImages(rasterOptions, PageSelection.allPages());
int pageIndex = 1;
// Loop through each image and write to the file system
for (BufferedImage extractedImage : sizedExtractedImages) {
String fileName = "assets/images/" + pageIndex++ + ".png";
ImageIO.write(extractedImage, "PNG", new File(fileName));
}
}
}import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image BufferedImage;
import java.io.File;
import java.io.IOException;
import java.util.List;
public class Main {
public static void main(String [] args) throws IOException {
// Generate a PDF from a URL
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://www.amazon.com/?tag=hp2-brobookmark-us-20");
// Convert the PDF pages into a list of BufferedImage objects
List<BufferedImage> extractedImages = pdf.toBufferedImages();
// Set image conversion options
ToImageOptions rasterOptions = new ToImageOptions();
rasterOptions.setImageMaxHeight(800);
rasterOptions.setImageMaxWidth(500);
// Convert the pages using the specified options
List<BufferedImage> sizedExtractedImages = pdf.toBufferedImages(rasterOptions, PageSelection.allPages());
int pageIndex = 1;
// Loop through each image and write to the file system
for (BufferedImage extractedImage : sizedExtractedImages) {
String fileName = "assets/images/" + pageIndex++ + ".png";
ImageIO.write(extractedImage, "PNG", new File(fileName));
}
}
}
Wyjście z pliku PDF do obrazów
Dostosuj rozdzielczość obrazu, modyfikując te wywołania na instancji ToImageOptions:
rasterOptions.setImageMaxHeight(800);
rasterOptions.setImageMaxWidth(500);rasterOptions.setImageMaxHeight(800);
rasterOptions.setImageMaxWidth(500);Te linie dostosowują szerokość i wysokość generowanych obrazów, gdy wywoływana jest toBufferedImage. Aby uzyskać informacje na temat zaawansowanych opcji renderowania i ustawień, zapoznaj się z naszym przewodnikiem dotyczącym ustawień generowania plików PDF.
Konwersja określonych stron na obrazy
Czasami potrzebne są tylko konkretne strony, a nie cały dokument. IronPDF zapewnia elastyczne opcje wyboru stron:
// Convert only page 3 to an image
List<BufferedImage> singlePage = instance.toBufferedImages(rasterOptions, PageSelection.singlePage(3));
// Convert pages 2 through 5
List<BufferedImage> pageRange = instance.toBufferedImages(rasterOptions, PageSelection.pageRange(2, 5));
// Convert first and last pages only
PageSelection customPages = new PageSelection();
customPages.add(0); // First page (0-indexed)
customPages.add(instance.getPageCount() - 1); // Last page
List<BufferedImage> selectedPages = instance.toBufferedImages(rasterOptions, customPages);// Convert only page 3 to an image
List<BufferedImage> singlePage = instance.toBufferedImages(rasterOptions, PageSelection.singlePage(3));
// Convert pages 2 through 5
List<BufferedImage> pageRange = instance.toBufferedImages(rasterOptions, PageSelection.pageRange(2, 5));
// Convert first and last pages only
PageSelection customPages = new PageSelection();
customPages.add(0); // First page (0-indexed)
customPages.add(instance.getPageCount() - 1); // Last page
List<BufferedImage> selectedPages = instance.toBufferedImages(rasterOptions, customPages);Jakie są najważniejsze wnioski z tego przewodnika?
W niniejszym przewodniku pokazano, jak konwertować pliki PDF na obrazy przy użyciu biblioteki IronPDF for Java. Wygenerowane obrazy zachowują numery stron i nazwy dokumentów z oryginalnego pliku PDF. IronPDF obsługuje wiele formatów obrazów, w tym JPEG, JPG, TIFF i inne.
IronPDF zapewnia pełną kontrolę nad rozdzielczością obrazu wyjściowego. Więcej informacji na temat manipulacji plikami PDF przy użyciu języka Java można znaleźć w dokumentacji IronPDF for Java. Aby uzyskać dodatkowe informacje na temat konwersji plików PDF na obrazy, zapoznaj się z tym przykładem konwersji plików PDF na obrazy w IronPDF.
IronPDF for Java jest bezpłatny do celów programistycznych, ale wymaga licencji do użytku komercyjnego. Więcej informacji na temat licencji można znaleźć na stronie IronPDF for Java Licensing.
Często Zadawane Pytania
How do I convert a PDF file to PNG images in Java?
You can convert PDF files to PNG images using IronPDF's toBufferedImages method. First, load your PDF document using PdfDocument.fromFile(), then call toBufferedImages() to get a list of BufferedImage objects representing each page. Finally, use ImageIO.write() to save each BufferedImage as a PNG file.
What image formats are supported for PDF conversion?
IronPDF supports converting PDF documents to various image formats including JPEG, PNG, and TIFF. The toBufferedImages method returns BufferedImage objects that can be saved in any format supported by Java's ImageIO class.
Can I convert specific pages of a PDF to images instead of the entire document?
Yes, IronPDF allows you to convert specific pages by accessing individual BufferedImage objects from the list returned by toBufferedImages(). You can iterate through only the pages you need and save them as separate image files.
What are the common use cases for PDF to image conversion?
IronPDF's PDF to image conversion is commonly used for creating thumbnails in document management systems, generating preview images for web applications, extracting visual content for presentations, and converting documents for display on devices that don't support PDF rendering.
How do I add IronPDF to my Maven project?
To add IronPDF to your Maven project, include the following dependency in your pom.xml file:
Can I convert a URL directly to an image?
Yes, you can convert a URL to an image using IronPDF by first rendering the URL as a PDF using the renderUrlAsPdf method, then converting that PDF to images using the toBufferedImages method.
Does the PDF to image conversion maintain quality?
IronPDF maintains high quality during PDF to image conversion by handling all rendering complexities internally. The library provides a robust API that ensures the converted images retain the visual fidelity of the original PDF pages.


Wciąż przewijasz?
Czy chcesz szybko dowodu?
Uruchom przykład i zobacz, jak Twój kod HTML zamienia się w plik PDF.













