
Jak wyodrębnić tekst ze zeskanowanego pliku PDF w języku Python
Pobieranie tekstu z plików PDF, zwłaszcza tych zeskanowanych, może stanowić wyzwanie. Proces ten można jednak uprościć dzięki odpowiednim narzędziom i technikom. Ten samouczek poprowadzi Cię przez proces korzystania z IronPDF, biblioteki Python, w celu wyodrębnienia tekstu ze zeskanowanego pliku PDF. W tym artykule omówimy, jak skonfigurować środowisko, zastosować optyczne rozpoznawanie znaków (OCR) i skutecznie przeprowadzić ekstrakcję tekstu.
1. Wprowadzenie do IronPDF
 Biblioteka PDF dla języka Python
Biblioteka PDF dla języka Python
IronPDF to wszechstronna i wydajna biblioteka przeznaczona do manipulacji i przetwarzania plików PDF w środowisku Python. Znany ze swojej zdolności do płynnej integracji z aplikacjami w języku Python, IronPDF oferuje szereg funkcji wykraczających poza podstawowe odczytywanie i zapisywanie plików PDF. Wyróżnia się możliwością konwersji HTML do PDF, renderowania dokumentów PDF ze stron internetowych lub surowych kodów HTML oraz edycji istniejących plików PDF.
Ponadto funkcja optycznego rozpoznawania znaków (OCR) jest przydatna do wyodrębniania tekstu ze skanowanych dokumentów PDF. Jest to niezbędne narzędzie dla programistów zajmujących się różnymi zadaniami związanymi z plikami PDF. Niezależnie od tego, czy chodzi o tworzenie, modyfikowanie czy wyodrębnianie danych z plików PDF, IronPDF jest solidnym i niezawodnym rozwiązaniem, zaspokajającym różnorodne potrzeby programistów Pythona w różnych zastosowaniach.
2. Wymagania wstępne
Zanim zagłębimy się w proces wyodrębniania tekstu z plików PDF, konieczne jest spełnienie kilku warunków wstępnych i zainstalowanie niezbędnych bibliotek. Zapewni to płynny i efektywny przebieg pracy w miarę postępów.
- Srodowisko Python: Upewnij się, że masz zainstalowany Python na swoim komputerze. Python jest wszechstronnym językiem programowania, a jego rozbudowana obsługa bibliotek sprawia, że idealnie nadaje się do zadań takich jak ekstrakcja tekstu. Jeśli nie masz zainstalowanego Pythona, możesz go pobrać z oficjalnej strony Pythona. Pamiętaj, aby pobrać wersję dla języka Python zgodną z Twoim systemem operacyjnym.
- Instalacja .NET 6.0 SDK: Ponieważ IronPDF for Python wykorzystuje bibliotekę IronPDF .NET, która jest oparta na .NET 6.0, konieczne jest zainstalowanie .NET 6.0 SDK w systemie. Ten zestaw SDK zapewnia środowisko uruchomieniowe i biblioteki niezbędne do prawidłowego działania biblioteki IronPDF. Pakiet .NET 6.0 SDK można pobrać i zainstalować z oficjalnej strony internetowej Microsoft .NET.
- Biblioteka IronPDF for Python: IronPDF to solidna biblioteka do pracy z dokumentami PDF w języku Python. Ułatwia nie tylko wyodrębnianie tekstu, ale oferuje również funkcje takie jak tworzenie, edycja i konwersja plików PDF.
- Zeskanowany dokument PDF: Przygotuj zeskanowany dokument PDF do wyodrębnienia tekstu. Dokument ten powinien być jasny i czytelny, ponieważ jakość zeskanowanego pliku PDF może znacząco wpłynąć na dokładność rozpoznawania OCR i wyodrębnionego tekstu.
- Znajomość podstaw języka Python: Znajomość podstaw programowania w języku Python będzie dodatkowym atutem. Znajomość pojęć takich jak zmienne, pętle i podstawowe operacje na plikach pomoże Ci poruszać się po kodzie i skuteczniej zrozumieć proces wyodrębniania tekstu.
- Odpowiednie srodowisko programistyczne: Chociaż nie jest to absolutnie konieczne, posiadanie srodowiska programistycznego, takiego jak Visual Studio Code, PyCharm, a nawet Jupyter Notebook, może ułatwić pisanie kodu. Środowiska te oferują funkcje takie jak podświetlanie składni, autouzupełnianie kodu oraz narzędzia do debugowania, które są niezwykle pomocne podczas pracy ze skryptami w języku Python.
Mając te informacje, jesteś dobrze przygotowany do rozpoczęcia wyodrębniania tekstu ze skanowanych dokumentów PDF przy użyciu biblioteki IronPDF for Python. Poniższe kroki poprowadzą Cię przez proces instalacji IronPDF, wczytania dokumentu PDF, zastosowania OCR, wyodrębnienia tekstu oraz wykorzystania wyodrębnionych danych do konkretnych potrzeb.
3. Przewodnik krok po kroku dotyczący wyodrębniania tekstu ze skanowanych plików PDF
Krok 1: Zainstaluj IronPDF
Najpierw musisz zainstalować bibliotekę IronPDF Python w swoim środowisku Python. Zazwyczaj robi się to za pomocą menedżera pakietów Pythona, pip. Otwórz interfejs wiersza poleceń i uruchom następujące polecenie:
pip install ironpdf
 Zainstaluj pakiet IronPDF
Zainstaluj pakiet IronPDF
Krok 2: Importuj IronPDF
Po instalacji zaimportuj bibliotekę IronPDF do swojego skryptu w języku Python. Ten krok jest kluczowy, aby uzyskać dostęp do funkcji oferowanych przez IronPDF:
import ironpdfimport ironpdfPo zaimportowaniu biblioteki IronPDF można teraz korzystać z jej klas i metod w swoim skrypcie.
Krok 3: Zastosuj swój klucz licencyjny
IronPDF wymaga klucza licencyjnego, aby korzystać z pełnej funkcjonalności. Jeśli zakupiłeś licencję, zastosuj swój klucz licencyjny w następujący sposób:
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"Zastąp "YOUR-LICENSE-KEY-HERE" swoim rzeczywistym kluczem licencyjnym IronPDF. Ten krok jest niezbędny, aby odblokować wszystkie funkcje IronPDF bez żadnych ograniczeń.
Krok 4: Załaduj zeskanowany plik PDF
Aby wyodrębnić tekst, zacznij od załadowania dokumentu PDF do swojego skryptu:
pdf = ironpdf.PdfDocument.FromFile("scannedpdf.pdf")pdf = ironpdf.PdfDocument.FromFile("scannedpdf.pdf")W tym miejscu "scannedpdf.pdf" należy zastąpić rzeczywistą ścieżką do pliku PDF, który zamierzasz przetworzyć. To polecenie odczytuje plik PDF i przygotowuje go do wyodrębnienia tekstu.
Krok 5: Wyodrębnij tekst z pliku PDF
Po załadowaniu pliku PDF można teraz wyodrębnić tekst za pomocą metody ExtractAllText() biblioteki IronPDF, jak pokazano w poniższym kodzie:
text = pdf.ExtractAllText()text = pdf.ExtractAllText()Ten fragment kodu przetwarza cały dokument PDF i wyodrębnia jego zawartość tekstową, zapisując ją w zmiennej text.
Krok 6: Przetwarzanie i wykorzystanie wyodrębnionego tekstu
Po wyodrębnieniu dane tekstowe są dostępne w zmiennej text. Możesz wyświetlić ten tekst w konsoli lub przetworzyć go dalej zgodnie z własnymi potrzebami:
print(text)
# Additional code here to process or utilize the extracted textprint(text)
# Additional code here to process or utilize the extracted textTen etap może obejmować różne operacje, takie jak zapisanie wyodrębnionego tekstu do pliku, przeprowadzenie analizy danych tekstowych lub zintegrowanie ich z bazą danych lub aplikacją internetową. Tutaj można zobaczyć wynik działania powyższego kodu.
TEKST WYNIKOWY
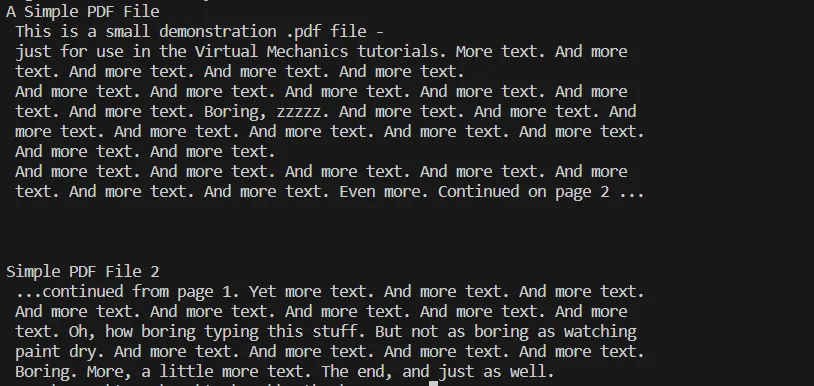 Wynik wyświetlany w konsoli dla powyższego procesu wyodrębniania tekstu z pliku PDF
Wynik wyświetlany w konsoli dla powyższego procesu wyodrębniania tekstu z pliku PDF
Krok 7: Dodatkowe operacje (opcjonalnie)
Możliwości IronPDF wykraczają poza wyodrębnianie tekstu. W zależności od wymagań projektu możesz zapoznać się z dodatkowymi funkcjami, takimi jak edycja plików PDF, konwersja plików PDF do różnych formatów, a nawet generowanie plików PDF z HTML.
4. Techniki zaawansowane
4.1 Postępowanie z elementami innymi niż tekst
Zeskanowane pliki PDF często zawierają elementy inne niż tekst, takie jak obrazy lub wykresy. Chociaż OCR skupia się na tekście, warto potraktować te elementy w inny sposób. Może być konieczne użycie dodatkowych bibliotek Pythona do przetwarzania lub ignorowania treści innych niż tekstowe.
4.2 Poprawa dokładności OCR
Dokładność wyodrębniania tekstu może się różnić w zależności od jakości zeskanowanych dokumentów. Aby poprawić wyniki OCR, upewnij się, że zeskanowany plik PDF jest wysokiej jakości, a tekst jest jak najbardziej czytelny.
4.3 Konwersja do innych formatów
Po wyodrębnieniu tekstu z pliku PDF możesz chcieć przekonwertować go na inne formaty, takie jak CSV, JSON lub XML, w celu dalszego przetwarzania. IronPDF umożliwia takie konwersje, zapewniając elastyczne opcje obsługi danych.
5. Rozwiązywanie typowych problemów
Podczas pracy z OCR i ekstrakcją tekstu mogą pojawić się takie problemy jak:
- Niska dokładność OCR spowodowana niską jakością skanów.
- Brak tekstu, jeśli OCR nie rozpozna niektórych znaków.
- Błędy podczas ładowania dużych plików PDF.
Aby rozwiązać te problemy, upewnij się, że zeskanowane pliki PDF są wyraźne i mają wysoką jakość, rozważ podzielenie dużych plików na mniejsze oraz sprawdź, czy biblioteka IronPDF jest aktualna.
Wnioski
Wyodrębnianie tekstu ze zeskanowanego pliku PDF można płynnie wykonać za pomocą biblioteki IronPDF for Python. Postępując zgodnie z instrukcjami zawartymi w tym samouczku, można przekonwertować zeskanowany dokument bez możliwości wyszukiwania na format tekstowy, który można szybko przetworzyć i przeanalizować. Pamiętaj, aby ostrożnie obchodzić się z każdą stroną pliku PDF i zastosować OCR, aby przekształcić zeskanowany plik PDF w plik PDF z możliwością wyszukiwania. Dzięki wyodrębnionemu tekstowi możliwości manipulacji danymi i ich wykorzystania są ogromne, torując drogę dla innowacyjnych rozwiązań i usprawnionych procesów pracy.
Podsumowując, w tym artykule omówiono instalację i konfigurację IronPDF, ładowanie plików PDF, zastosowanie technologii OCR w celu umożliwienia przeszukiwania zeskanowanego pliku PDF, sam proces wyodrębniania tekstu oraz obsługę wielu stron PDF. Poruszono w nim również zaawansowane techniki oraz rozwiązywanie typowych problemów. Dzięki tej wiedzy możesz wyodrębniać dane tekstowe z dokumentów PDF przy użyciu języka Python.
IronPDF oferuje bezpłatną wersję próbną z pełnym dostępem do funkcji, umożliwiającą użytkownikom ocenę możliwości edycji plików PDF i wyodrębniania tekstu. Po zakończeniu okresu próbnego cena licencji płatnej zaczyna się od $799. Licencja ta jest przeznaczona do użytku profesjonalnego i komercyjnego i oferuje szeroki zestaw funkcji. IronPDF jest bezpłatny dla programistów, co pozwala im na integrację i testowanie jego funkcji bez ponoszenia kosztów na etapie tworzenia aplikacji.
Często Zadawane Pytania
Jak skonfigurować środowisko do wyodrębniania tekstu ze skanowanych plików PDF przy użyciu języka Python?
Aby skonfigurować środowisko, zainstaluj zestaw SDK .NET 6.0 oraz bibliotekę IronPDF za pomocą menedżera pakietów Pythona, wpisując pip install ironpdf. Upewnij się, że masz zainstalowane środowisko Python oraz odpowiednie środowisko programistyczne, takie jak Visual Studio Code lub PyCharm.
Czym jest optyczne rozpoznawanie znaków (OCR) i jak stosuje się je w języku Python?
Optyczne rozpoznawanie znaków (OCR) to technologia służąca do konwersji różnych typów dokumentów, takich jak zeskanowane dokumenty papierowe lub pliki PDF, na dane edytowalne i przeszukiwalne. W języku Python można zastosować OCR przy użyciu biblioteki IronPDF, ładując zeskanowany plik PDF i wykorzystując funkcje OCR biblioteki do wyodrębnienia tekstu.
Jak mogę zapewnić dokładne wyodrębnianie tekstu ze skanowanych plików PDF?
Aby zapewnić dokładne wyodrębnianie tekstu, należy używać wysokiej jakości zeskanowanych plików PDF, ponieważ dokładność OCR poprawia się wraz z wyraźniejszymi i lepszej jakości skanami. Dzięki IronPDF można zastosować OCR w celu wyodrębnienia tekstu i dalszego przetwarzania go w razie potrzeby.
Jakie kroki trzeba wykonać, żeby wyodrębnić tekst ze zeskanowanego pliku PDF za pomocą IronPDF?
Kroki obejmują instalację IronPDF, import biblioteki, zastosowanie klucza licencyjnego, załadowanie zeskanowanego pliku PDF, zastosowanie OCR oraz użycie metody ExtractAllText() do wyodrębnienia tekstu.
Czy mogę przekonwertować wyodrębniony tekst do formatów takich jak CSV, JSON lub XML?
Tak, po wyodrębnieniu tekstu ze zeskanowanego pliku PDF za pomocą IronPDF można go przekonwertować na różne formaty, takie jak CSV, JSON lub XML, w celu dalszej analizy lub przetwarzania danych.
Jakie są typowe kroki rozwiązywania problemów w przypadku niepowodzenia ekstrakcji tekstu?
Jeśli wyodrębnianie tekstu nie powiedzie się, sprawdź jakość zeskanowanego pliku PDF. Upewnij się, że IronPDF jest poprawnie zainstalowany, a środowisko programistyczne odpowiednio skonfigurowane. Sprawdź również, czy używane są właściwe metody i funkcje OCR.
Czy dostępna jest wersja próbna IronPDF?
Tak, IronPDF oferuje bezpłatną wersję próbną, dzięki której użytkownicy mogą przetestować jego możliwości. Aby uzyskać pełną funkcjonalność po zakończeniu okresu próbnego, wymagana jest płatna licencja.
















