How to Parse PDF File in VB.NET
This tutorial introduces how to programmatically extract texts and images from PDF files with first-class support from IronPDF.
How to Parse PDF File in VB.NET
- Download IronPDF C# library to parse PDF file
- Utilize
FromFilemethod parse PDF file in VB.NET - Extract text from opened PDF with
ExtractAllTextmethod - Use
ExtractTextFromPagesmethod to extract text from certain pages - Extract images from opened PDF with
ExtractRawImagesFromPagemethod
IronPDF
Features
Efficient PDF conversion. Almost anything a machine can do, IronPDF can as well. Thanks to this PDF library, developers can quickly create, read text content, write, load, and manipulate PDF.
IronPDF converts HTML into a PDF record with the aid of using the Chrome engine. Along with Windows Forms, HTML, ASPX, Razor HTML, .NET Core, ASP.NET, Windows Forms, and WPF. IronPDF also supports Xamarin, Blazor, Unity, and HoloLens applications. IronPDF supports both Microsoft .NET and .NET Core applications (Both ASP.NET Web packages and conventional Windows packages). IronPDF can be used to make aesthetically appealing PDFs.
IronPDF can create a PDF using HTML5, JavaScript, CSS, and images. IronPDF also has a powerful HTML-to-PDF converter that integrates with PDF. A strong PDF conversion mechanism is present in IronPDF using the Chromium rendering engine. It is also unconnected to any outside sources.
- A PDF image can be created from a variety of sources, including HTML, HTML5, ASPX, and Razor/MVC View. Both HTML and image assets can be converted to PDF.
- Tools that can be used to work with interactive PDFs include filling out and submitting interactive forms.
- Merge and divide PDFs, extract text and pictures from PDF files, search text in PDF files, rasterize PDFs to images, change font size and convert PDF files.
- It allows for the verification of HTML login forms using user-agents, proxies, cookies, HTTP headers, and form variables.
- Accessing secured documents is made possible by IronPDF by giving user names and passwords.
- IronPDF is a program that reads text in PDF and completes the gaps.
- Allows to add text, images, bookmarks, watermarks, and more.
- You can create a PDF file from a CSS file.
For more details, visit this IronPDF licensing information page for a free limited key and professional version.
 IronPDF- Font formatting
IronPDF- Font formatting
Extract text from PDF file
IronPDF can also read and extract text from PDF files with the help of the IronPDF libraries. Below is a pattern of IronPDF code that may be used to examine present PDF files.
Extract Text From All Pages
The code example below demonstrates the first method to acquire all the PDF content as a string with just a few lines.
Imports IronPdf
Module Program
Sub Main(args As String())
' Create a PDF Document object from an existing PDF file
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
' Extract all the text from the PDF
Dim AllText As String = pdfdoc.ExtractAllText()
' Output the extracted text to the console
Console.WriteLine(AllText)
End Sub
End ModuleImports IronPdf
Module Program
Sub Main(args As String())
' Create a PDF Document object from an existing PDF file
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
' Extract all the text from the PDF
Dim AllText As String = pdfdoc.ExtractAllText()
' Output the extracted text to the console
Console.WriteLine(AllText)
End Sub
End ModuleThe sample code above demonstrates how to use the FromFile method to read a PDF from an existing file and convert it into a PDF document object. The object provides a method called ExtractAllText that will extract plain text from the PDF and turn it into a string.
Extract Text by Page Number
The sample code below shows how to extract data from a PDF file using the page number.
Imports IronPdf
Module Program
Sub Main(args As String())
' Create a PDF Document object from an existing PDF file
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
' Extract text from the first page (page numbers are zero-based)
Dim AllText As String = pdfdoc.ExtractTextFromPage(0)
' Output the extracted text to the console
Console.WriteLine(AllText)
End Sub
End ModuleThe code above shows how to read a PDF from an existing file and turn it into a PDF document object using the FromFile function. Texts and images can be accessed on the PDF using this object. The object offers a method called ExtractTextFromPage that allows you to send a page number as a parameter to get a string that contains every word that was on that page of the PDF.
Extract Text Between Pages
The below code shows how to extract the data between multiple pages.
Imports IronPdf
Module Program
Sub Main(args As String())
' Define a list of page numbers from which to extract text
Dim Pages As List(Of Integer) = New List(Of Integer) From {3, 5, 7}
' Create a PDF Document object from an existing PDF file
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
' Extract text from the specified pages
Dim AllText As String = pdfdoc.ExtractTextFromPages(Pages)
' Output the extracted text to the console
Console.WriteLine(AllText)
End Sub
End ModuleImports IronPdf
Module Program
Sub Main(args As String())
' Define a list of page numbers from which to extract text
Dim Pages As List(Of Integer) = New List(Of Integer) From {3, 5, 7}
' Create a PDF Document object from an existing PDF file
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
' Extract text from the specified pages
Dim AllText As String = pdfdoc.ExtractTextFromPages(Pages)
' Output the extracted text to the console
Console.WriteLine(AllText)
End Sub
End ModuleThe code above demonstrates how to use the FromFile method to read a PDF from an existing file and convert it into a PDF document object. This object allows examining the text and images in the PDF. The object has a method called ExtractTextFromPages that can be used to get a string that includes all the text content on given pages of the document by passing a list of page numbers as a parameter. Below the left side is the source PDF and the right side is the data extracted.
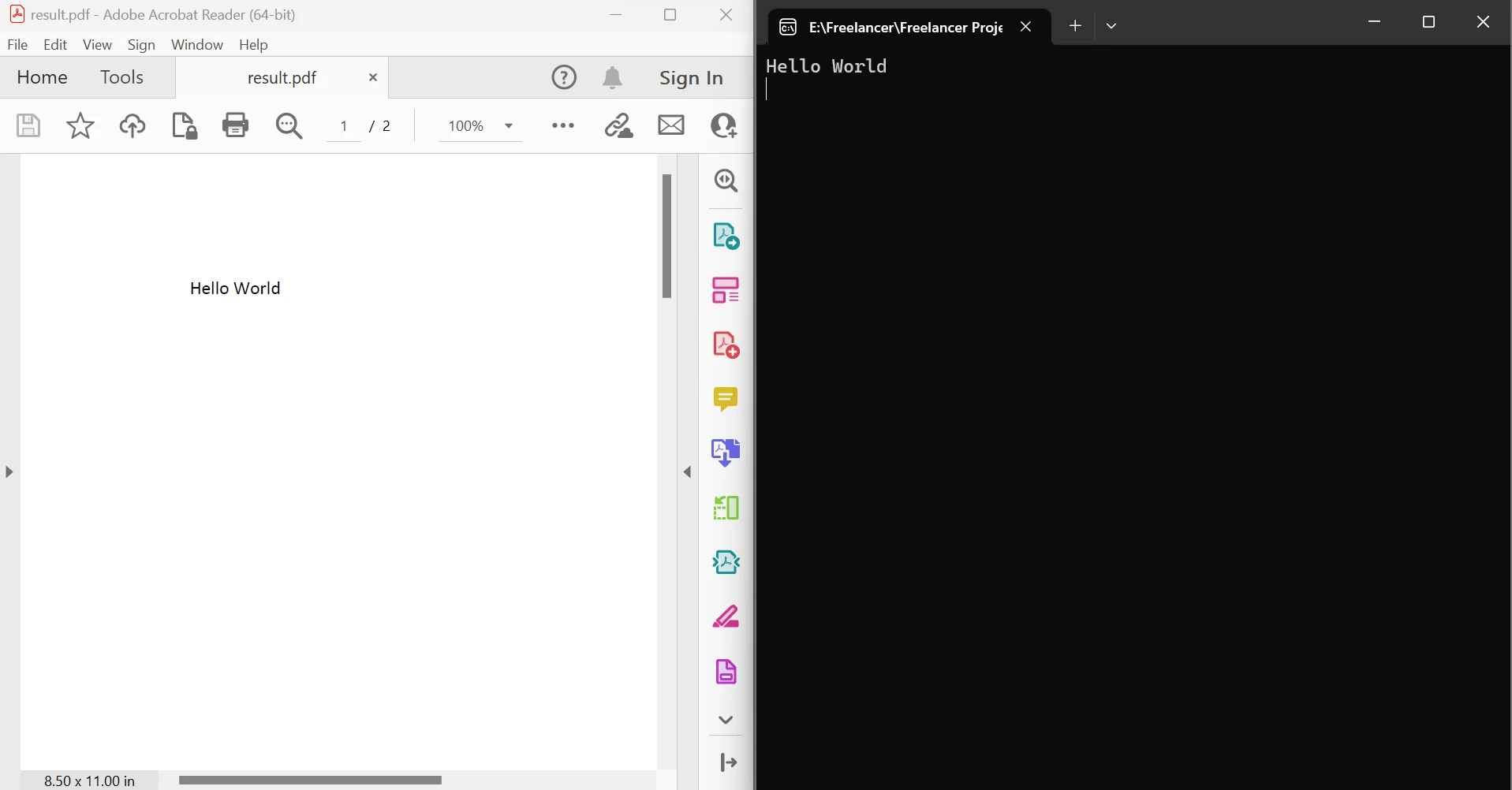 Extract text between pages output
Extract text between pages output
Extract Image from PDF file
IronPDF provides a list of methods to extract images such as:
ExtractBitmapsFromPageExtractBitmapsFromPagesExtractImagesFromPageExtractImagesFromPagesExtractRawImagesFromPageExtractRawImagesFromPages
Each method allows extracting images from a page or multiple pages of the document.
Imports IronPdf
Imports System.Drawing
Module Program
Sub Main(args As String())
' Create a PDF Document object from an existing PDF file
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
' Extract raw images from the first page
Dim images = pdfdoc.ExtractRawImagesFromPage(1)
' Iterate over extracted images
For Each imgData As Byte() In images
' Create a memory stream from byte data
Using ms As New IO.MemoryStream(imgData)
' Create a Bitmap object from the memory stream
Dim image = New Bitmap(ms)
' Save the image to the specified output directory
image.Save("output/test.jpg")
End Using
Next
End Sub
End ModuleImports IronPdf
Imports System.Drawing
Module Program
Sub Main(args As String())
' Create a PDF Document object from an existing PDF file
Dim pdfdoc = PdfDocument.FromFile("result.pdf")
' Extract raw images from the first page
Dim images = pdfdoc.ExtractRawImagesFromPage(1)
' Iterate over extracted images
For Each imgData As Byte() In images
' Create a memory stream from byte data
Using ms As New IO.MemoryStream(imgData)
' Create a Bitmap object from the memory stream
Dim image = New Bitmap(ms)
' Save the image to the specified output directory
image.Save("output/test.jpg")
End Using
Next
End Sub
End ModuleThe code above shows how to read a document from an existing file and turn it into a PDF document object using the FromFile function. By passing a page number to the object's ExtractRawImagesFromPage method, a list of bytes can be obtained that contains every picture that was present on that page of the document. Using a For Each loop, each byte stream is handled and turned into a memory stream, then into a Bitmap, which aids in picture saving. The below image shows the output from the above code.
 Extract Images from PDF output
Extract Images from PDF output
To know more about the IronPDF API code tutorial, refer to the IronPDF documentation. You can also visit other tutorials to learn how to parse PDF text using C#.
Conclusion
The development license for the library IronPDF is gratis. If using IronPDF in a production environment, different licenses can be bought depending on the developer's needs. The Lite plan starts at $999 and has no ongoing costs. SaaS and OEM redistribution alternatives are also provided. All licenses include updates, a year of product support, and a permanent license. They are also useful for manufacturing, staging, and development. It is a one-time purchase. There are additional free, time-limited licenses accessible. Visit the comprehensive IronPDF licensing information to read the complete pricing and licensing details for IronPDF. IronPDF also provides free licenses for copy protection.
Frequently Asked Questions
How can I extract text from a PDF in VB.NET?
Using the IronPDF library, you can extract text from a PDF by utilizing the ExtractAllText method. This allows you to retrieve text from all pages of a PDF document in your VB.NET project.
Is it possible to extract images from specific pages of a PDF using VB.NET?
Yes, IronPDF allows you to extract images from specific pages using its ExtractRawImagesFromPage method. This method returns the image data as byte arrays, which you can convert into image files.
How can I convert HTML content to a PDF document in VB.NET?
IronPDF offers powerful HTML-to-PDF conversion using the Chromium rendering engine. You can use methods like RenderHtmlAsPdf to convert HTML strings or files into PDF documents efficiently.
What are the benefits of using IronPDF for PDF parsing in VB.NET applications?
IronPDF provides versatile APIs for extracting text and images, supports HTML-to-PDF conversion, and is compatible with various .NET platforms, including ASP.NET, Windows Forms, and Blazor. It also offers different licensing options to suit development and production needs.
How do I integrate IronPDF into my VB.NET project?
To integrate IronPDF, download the library from NuGet and add it to your VB.NET project. This will allow you to access its methods for parsing and manipulating PDF files programmatically.
Can IronPDF handle both PDF parsing and conversion tasks?
Yes, IronPDF is designed to handle both parsing (text and image extraction) and conversion tasks (such as HTML-to-PDF) efficiently, making it a comprehensive solution for PDF manipulation in VB.NET.
What licensing options are available for IronPDF?
IronPDF offers a free development license and various production licenses, including Lite, SaaS, and OEM redistribution. These licenses include updates and support for one year, catering to different project needs.
Is IronPDF dependent on any external resources for its functionality?
No, IronPDF is self-contained and uses the Chromium rendering engine internally, ensuring robust functionality without reliance on external resources for PDF conversion and parsing.
Does IronPDF support .NET 10 and how does it benefit VB.NET developers?
Yes, IronPDF fully supports .NET 10, along with earlier versions like .NET 9, 8, 7, 6, Core, Standard, and Framework. This means VB.NET projects targeting .NET 10 can use IronPDF without additional configuration. Developers benefit from the new runtime performance improvements in .NET 10 — such as reduced heap allocations, better runtime & JIT optimizations — which enhance PDF generation, text/image extraction, and HTML-to-PDF rendering.