


Java PDF to Image File
Convert PDF documents to image formats like JPEG, PNG, or TIFF in Java using IronPDF's toBufferedImages method. Load a PDF file, call toBufferedImages to get a list of BufferedImage objects, then write each image to disk using ImageIO. The entire conversion takes fewer than ten lines of working Java code.
Quickstart: Convert PDF to Images in Java
-
Add IronPDF dependency to your Maven project: ```xml :title=pom.xml
com.ironsoftware ironpdf 2024.9.1 -
Load your PDF document:
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/load-pdf.java PdfDocument pdf = PdfDocument.fromFile(Paths.get("document.pdf"));//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/load-pdf.java PdfDocument pdf = PdfDocument.fromFile(Paths.get("document.pdf"));JAVA - Convert to images and save:
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-and-save.java List<BufferedImage> images = pdf.toBufferedImages(); for (int i = 0; i < images.size(); i++) { ImageIO.write(images.get(i), "PNG", new File("page_" + i + ".png")); }//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-and-save.java List<BufferedImage> images = pdf.toBufferedImages(); for (int i = 0; i < images.size(); i++) { ImageIO.write(images.get(i), "PNG", new File("page_" + i + ".png")); }JAVA
How to Convert PDF to Image in Java
- Install the IronPDF Java library
- Load a PDF file using
PdfDocument.fromFile() - Call
toBufferedImages()to get aList<BufferedImage> - Set output dimensions with
ToImageOptionsif needed - Write each image to disk using
ImageIO.write()
What Is PDF to Image Conversion and Why Is It Needed?
PDF to image conversion turns each page of a PDF document into a standalone image file (JPEG, PNG, or TIFF) that can be displayed, embedded, or processed without a PDF viewer. Java's standard libraries provide no built-in mechanism for this, which makes it a persistent pain point for developers who need document previews, thumbnail generators, or archival pipelines.
Common uses include generating thumbnail previews for document management systems, producing page-level screenshots for web applications, and extracting visual content for reports or presentations. IronPDF handles all rendering complexity internally, so the application code stays short and the output is pixel-accurate regardless of fonts, vector graphics, or form fields in the source PDF. For the inverse operation of placing images into a PDF, see the image-to-PDF how-to guide.
What Is IronPDF for Java and How Does It Help?
IronPDF for Java is a library for creating, reading, and editing PDF files in Maven-based projects. Developers use it to generate PDFs from HTML, modify existing documents, and extract content without Adobe Acrobat or any PDF viewer installed on the server.
The library supports custom headers and footers, digital signatures, form creation, password protection, and multithreaded rendering. Its PDF-to-image feature exposes a clean API through two overloads of toBufferedImages: one that converts every page with default settings, and one that accepts a ToImageOptions object and a PageSelection to control resolution and page range. For a complete feature overview, visit the IronPDF for Java documentation. For the full API reference, see the Java API reference.
Beyond basic conversion, IronPDF supports HTML to PDF rendering, custom watermarks, backgrounds and foregrounds, and form creation. It also ships Maven artifacts on the Sonatype Maven Central repository, so dependency management follows standard Maven or Gradle workflows.
What Prerequisites Do I Need Before Starting?
Before starting, confirm the following are in place:
- Java installed with the path set in Environment Variables. See the official Java installation guide.
- A Java IDE installed; Eclipse or IntelliJ both work well. Download Eclipse or IntelliJ IDEA.
- Maven integrated with the IDE. See this Maven setup tutorial for IntelliJ.
- License keys configured before deploying to a production environment.
How Do I Install IronPDF for Java?
Once all prerequisites are in place, installation is a single Maven dependency declaration. For detailed setup steps, consult the getting started documentation.
Open JetBrains IntelliJ IDEA and create a new Maven project.
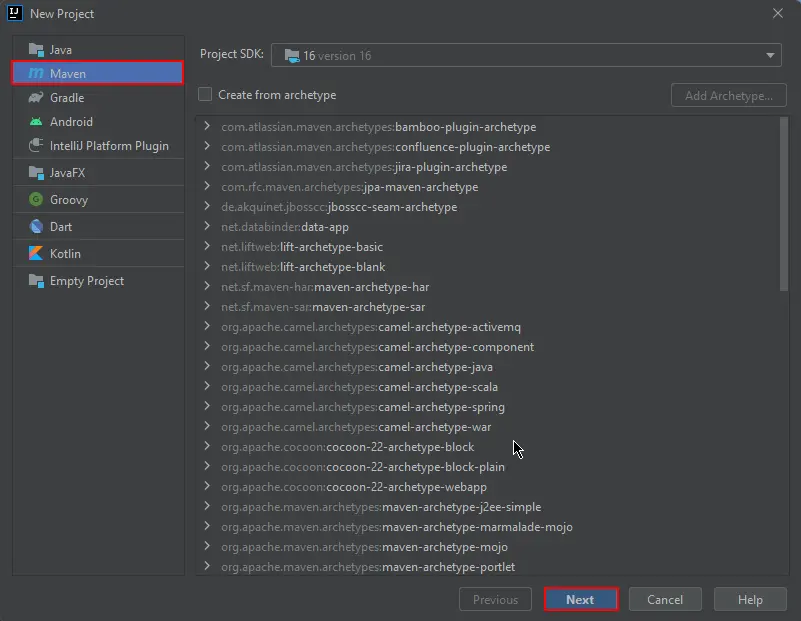
Create a new Maven Project
A new window appears. Enter the project name and click Finish.
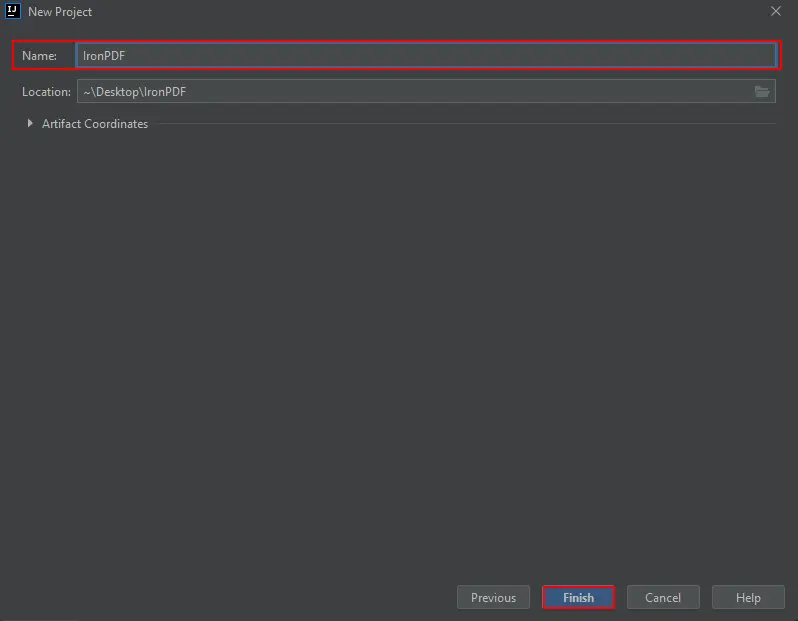
New Project Name
After clicking Finish, the new project opens with pom.xml displayed by default. Add the following dependencies to that file. The optional SLF4J entry suppresses logging noise during development; remove it if your project already includes a logging framework.
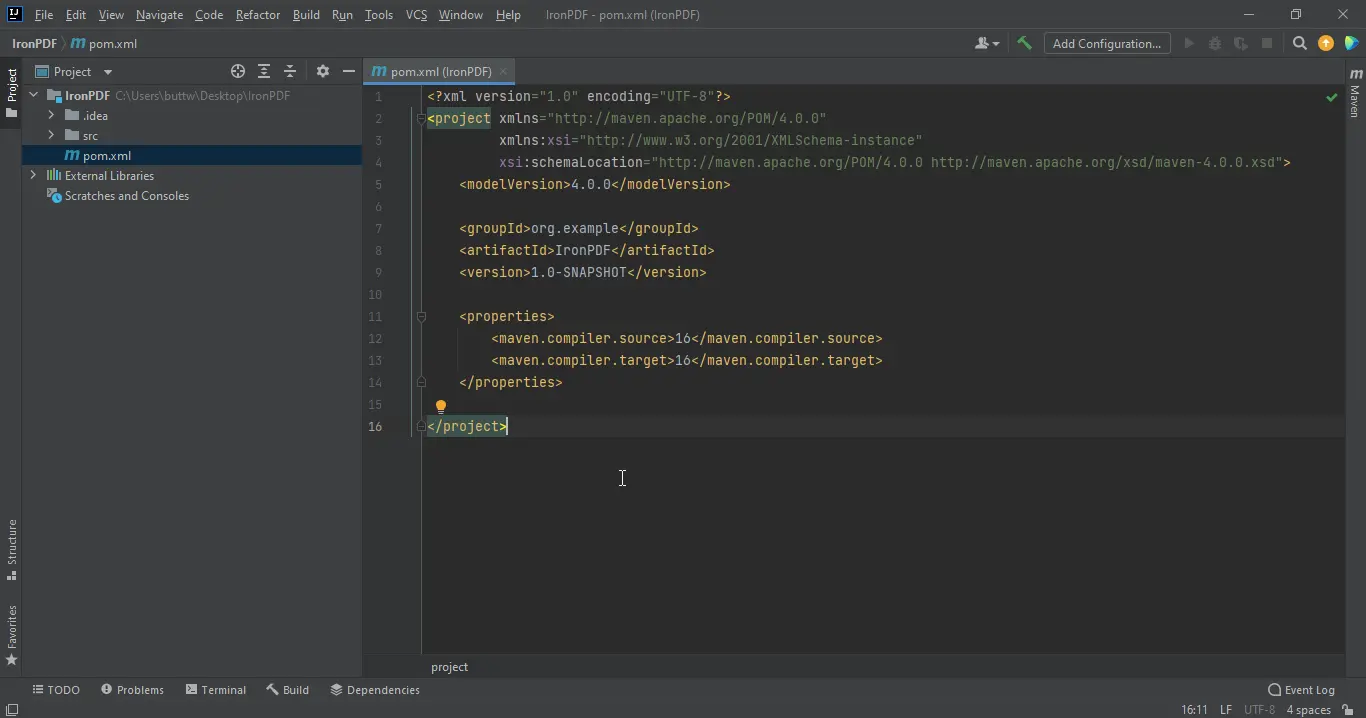
New Project: default pom.xml
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/pom-dependencies.xml
<dependencies>
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2024.9.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.36</version>
</dependency>
</dependencies>//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/pom-dependencies.xml
<dependencies>
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2024.9.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.36</version>
</dependency>
</dependencies>Once the dependencies are added to pom.xml, a Maven sync icon appears in the top-right corner of the editor.
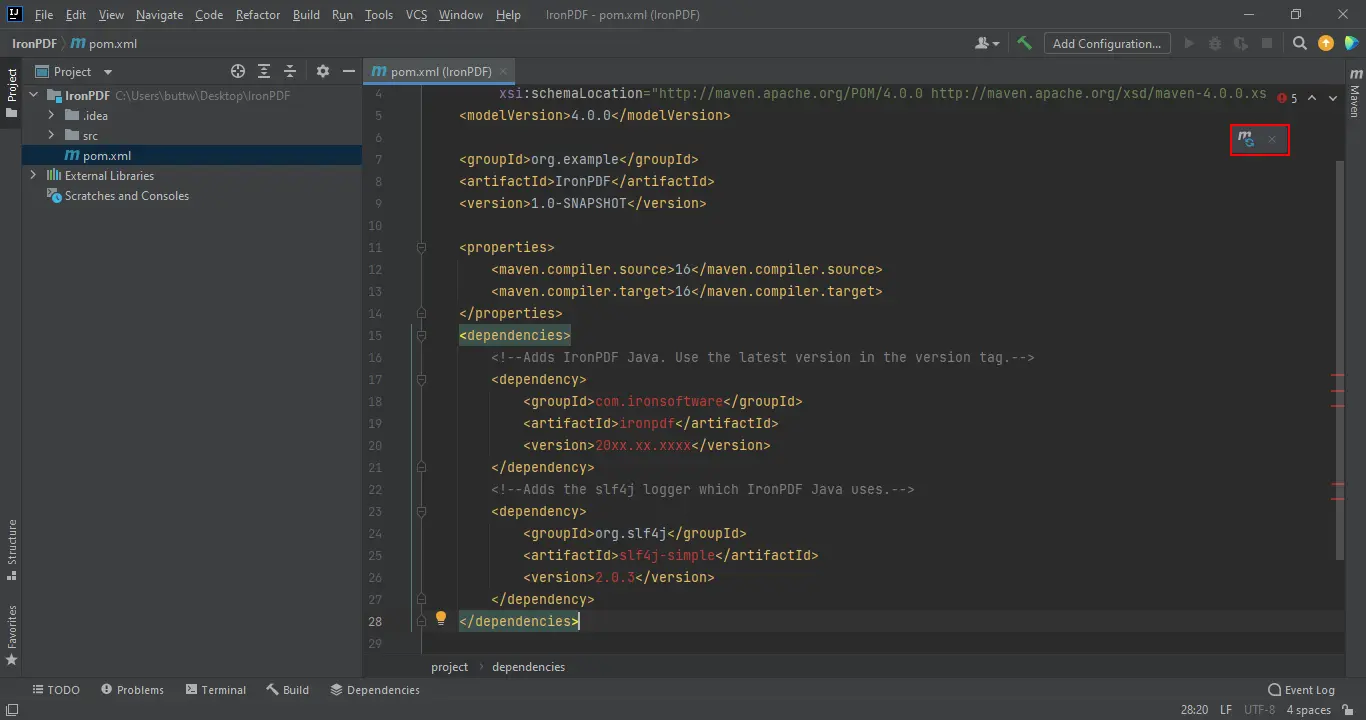
Maven Dependencies Added
Click the sync icon to download the IronPDF JAR. Download time depends on connection speed, typically under two minutes. After installation, review the Java API reference to see all available methods and configuration options. For cloud deployment targets, IronPDF has tested guides for AWS, Azure, and Google Cloud.
My favorite library of this kind is IronPDF. It allows for fast and efficient manipulation of PDF files. It also has many valuable features, like exporting to PDF/A format and digitally signing PDF documents.
IronOCR means we can save $40,000 annually from manual processing, while enhancing productivity and freeing up resources for high-impact tasks. I would highly recommend it.
The IronSuite play a crucial role in our operations. These are tools that increase efficiencies across the business including creating floor plans and improving inventory management.
How Do I Convert PDF Files to Images Using IronPDF?
Calling toBufferedImages on a PdfDocument object produces a List<BufferedImage> where each element corresponds to one PDF page in ascending page-number order. The result can then be written to disk, passed to an image processing pipeline, or returned directly to a web response.
IronPDF also converts URLs and HTML strings to PDF on the fly, so it is possible to capture any web page or rendered HTML document as images in a single pipeline without a separate rendering step.
How Do I Convert an Existing PDF Document to Images?
toBufferedImages accepts an optional ToImageOptions argument for controlling output dimensions, and a PageSelection argument for targeting specific pages. When no arguments are passed, all pages are converted at their natural resolution.
The example below converts all pages of a PDF to PNG files, using ToImageOptions to cap each output image at 800x500 pixels:
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-pdf-to-images.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from disk
PdfDocument pdf = PdfDocument.fromFile(Paths.get("business_plan.pdf"));
// Configure output image dimensions
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert all pages to BufferedImage objects with the configured dimensions
List<BufferedImage> pages = pdf.toBufferedImages(options, PageSelection.allPages());
// Write each page image to the assets/images folder (create the folder first)
int pageIndex = 1;
for (BufferedImage page : pages) {
String fileName = "assets/images/" + pageIndex++ + ".png";
ImageIO.write(page, "PNG", new File(fileName));
}
}
}//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-pdf-to-images.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from disk
PdfDocument pdf = PdfDocument.fromFile(Paths.get("business_plan.pdf"));
// Configure output image dimensions
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert all pages to BufferedImage objects with the configured dimensions
List<BufferedImage> pages = pdf.toBufferedImages(options, PageSelection.allPages());
// Write each page image to the assets/images folder (create the folder first)
int pageIndex = 1;
for (BufferedImage page : pages) {
String fileName = "assets/images/" + pageIndex++ + ".png";
ImageIO.write(page, "PNG", new File(fileName));
}
}
}The output images are saved to assets/images/ with numeric filenames starting at 1. Create that folder before running the program, as ImageIO.write does not create missing directories. The setImageMaxHeight and setImageMaxWidth calls set upper bounds on each dimension; IronPDF preserves the original aspect ratio and does not stretch the image.
ImageIO.write from "PNG" to "JPEG" and update the file extension accordingly.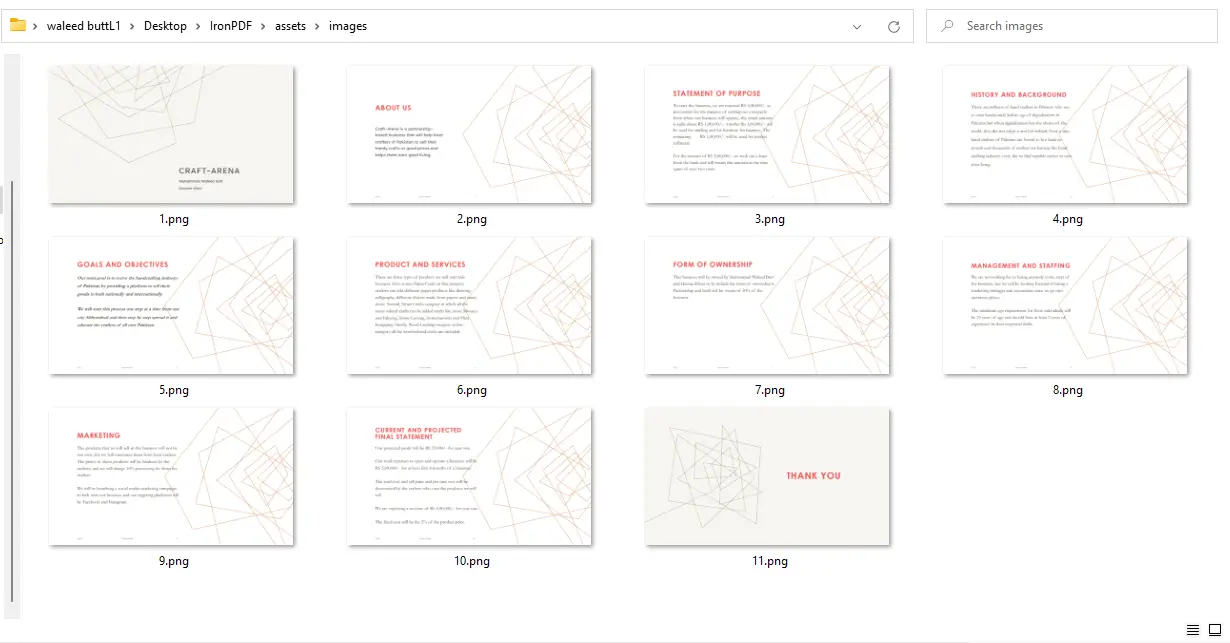
PDF to Images Output - 11 PNG files, one per page
For more conversion examples, visit the PDF rasterization examples page.
How Do I Convert a URL to Images Using IronPDF?
PdfDocument.renderUrlAsPdf fetches the URL, renders it with the built-in Chromium engine, and returns a PdfDocument that can be immediately passed to toBufferedImages. This makes it straightforward to capture any publicly accessible web page as a series of images.
The example below renders an Amazon product page to a PDF and then saves each resulting page as a PNG file:
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-url-to-images.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// Render a URL to a PDF document using the Chromium rendering engine
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://www.amazon.com");
// Configure output image dimensions
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert all pages and write to disk
List<BufferedImage> pages = pdf.toBufferedImages(options, PageSelection.allPages());
int pageIndex = 1;
for (BufferedImage page : pages) {
String fileName = "assets/images/" + pageIndex++ + ".png";
ImageIO.write(page, "PNG", new File(fileName));
}
}
}//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-url-to-images.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// Render a URL to a PDF document using the Chromium rendering engine
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://www.amazon.com");
// Configure output image dimensions
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert all pages and write to disk
List<BufferedImage> pages = pdf.toBufferedImages(options, PageSelection.allPages());
int pageIndex = 1;
for (BufferedImage page : pages) {
String fileName = "assets/images/" + pageIndex++ + ".png";
ImageIO.write(page, "PNG", new File(fileName));
}
}
}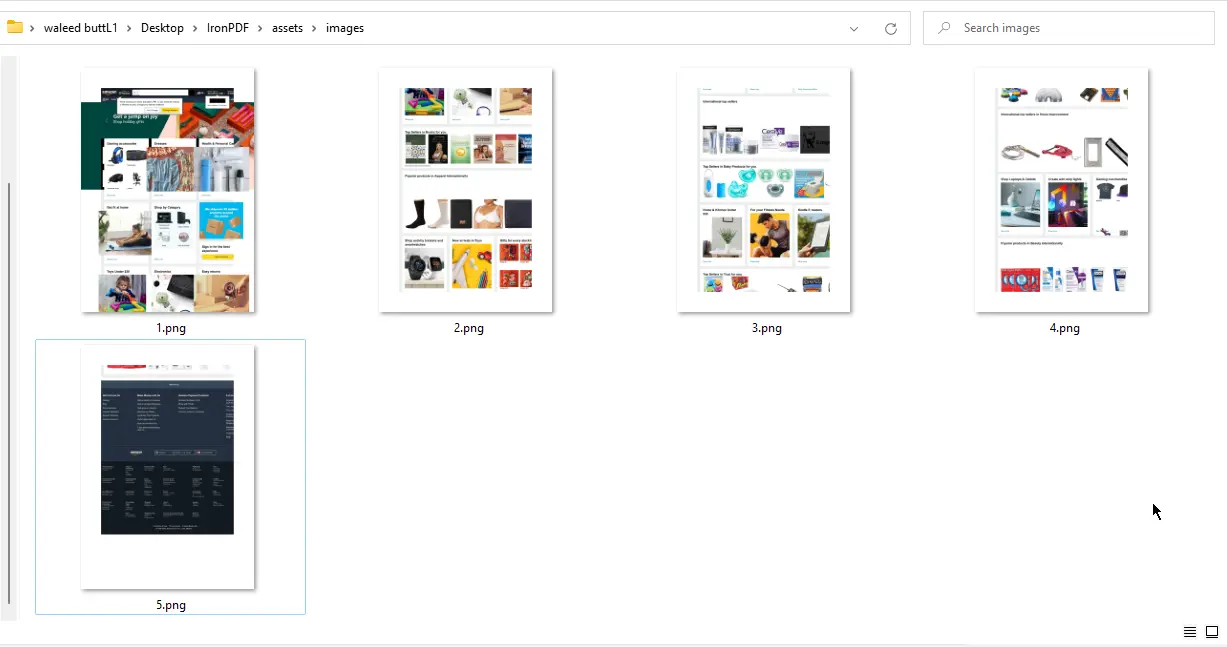
URL to Images Output - 5 PNG files
For pages that require authentication or session cookies before rendering, see the website logins guide.
renderUrlAsPdf applies the same CSS and JavaScript support as a modern desktop browser. Pages that rely on client-side JavaScript to load content will render correctly, including single-page applications.How Do I Convert Specific Pages to Images?
PageSelection provides several factory methods for targeting a subset of pages rather than the entire document. This is useful when only a cover page, a summary section, or a known page range needs to be extracted.
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/page-selection.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.List;
public class PageSelectionExample {
public static void main(String[] args) throws IOException {
PdfDocument pdf = PdfDocument.fromFile(Paths.get("report.pdf"));
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert only the first page (page index is zero-based)
List<BufferedImage> coverPage = pdf.toBufferedImages(options, PageSelection.singlePage(0));
ImageIO.write(coverPage.get(0), "PNG", new File("cover.png"));
// Convert pages 2 through 5 (zero-based indices 1 through 4)
List<BufferedImage> excerpt = pdf.toBufferedImages(options, PageSelection.pageRange(1, 4));
for (int i = 0; i < excerpt.size(); i++) {
ImageIO.write(excerpt.get(i), "PNG", new File("excerpt_" + (i + 1) + ".png"));
}
}
}//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/page-selection.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.List;
public class PageSelectionExample {
public static void main(String[] args) throws IOException {
PdfDocument pdf = PdfDocument.fromFile(Paths.get("report.pdf"));
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert only the first page (page index is zero-based)
List<BufferedImage> coverPage = pdf.toBufferedImages(options, PageSelection.singlePage(0));
ImageIO.write(coverPage.get(0), "PNG", new File("cover.png"));
// Convert pages 2 through 5 (zero-based indices 1 through 4)
List<BufferedImage> excerpt = pdf.toBufferedImages(options, PageSelection.pageRange(1, 4));
for (int i = 0; i < excerpt.size(); i++) {
ImageIO.write(excerpt.get(i), "PNG", new File("excerpt_" + (i + 1) + ".png"));
}
}
}PageSelection.singlePage(0) targets only the first page, which is useful for generating a cover thumbnail. PageSelection.pageRange(1, 4) extracts pages two through five using zero-based indices. Both return a List<BufferedImage>, so the loop pattern is identical regardless of how many pages are selected.
PageSelection are zero-based: the first page is 0, the second is 1, and so on. Passing an out-of-range index throws an IndexOutOfBoundsException at runtime.What Are the Next Steps for Java PDF to Image Conversion?
This guide covered three common patterns: converting all pages of an existing PDF, capturing a URL as a set of page images, and extracting a targeted page range. IronPDF handles resolution control and format selection through ToImageOptions and ImageIO, keeping the calling code short and predictable.
To continue building with IronPDF for Java, explore these related resources:
- Java rasterization examples - additional PDF to image code samples
- Extract images and text from a PDF - pull embedded images out of existing PDF files
- Compress PDFs in Java - reduce file size before storage or transmission
- Custom watermarks - stamp output images or PDFs with a watermark before saving
- IronPDF for Java documentation - complete API reference and setup guides
IronPDF for Java is free for development. A license is required for commercial deployment. Start your free trial or view licensing options to see which plan fits your project.
Ready to see what else IronPDF can do? Check out the full IronPDF for Java tutorial page.
Frequently Asked Questions
How do I convert a PDF file to PNG images in Java?
Load the PDF using PdfDocument.fromFile(), call toBufferedImages() to get a list of BufferedImage objects representing each page, then use ImageIO.write() to save each image as a PNG file.
What image formats are supported when converting PDF pages?
IronPDF's toBufferedImages method returns BufferedImage objects. You can save these in any format supported by Java's ImageIO class, including PNG, JPEG, and TIFF.
Can I convert only specific pages of a PDF to images?
Yes. Pass a PageSelection argument to toBufferedImages. Use PageSelection.singlePage(0) to convert one page or PageSelection.pageRange(1, 4) to convert a range. Page indices are zero-based.
What are the common use cases for PDF to image conversion in Java?
Common use cases include generating thumbnail previews for document management systems, producing page-level screenshots for web applications, extracting visual content for presentations, and archiving documents as image files for systems that do not support PDF rendering.
How do I add IronPDF to my Maven project?
Add the following dependency inside the <dependencies> block of your pom.xml: <dependency><groupId>com.ironsoftware</groupId><artifactId>ironpdf</artifactId><version>2024.9.1</version></dependency>
Can I convert a URL directly to image files?
Yes. Call PdfDocument.renderUrlAsPdf(url) to render the page using the built-in Chromium engine, then pass the resulting PdfDocument to toBufferedImages to get a list of page images.
How do I control the output image resolution?
Create a ToImageOptions instance, call setImageMaxHeight() and setImageMaxWidth() to set maximum dimensions, then pass it as the first argument to toBufferedImages. IronPDF preserves the aspect ratio and does not stretch the image.


Still Scrolling?
Want proof fast?
run a sample watch your HTML become a PDF.













