


Merge PDF Files into a Single PDF Using Python
IronPDF for Python provides a simple solution to merge multiple PDF documents into a single file using the PdfDocument.Merge() method, supporting both two-file merging and batch operations for combining numerous PDFs efficiently.
The PDF format, which stands for Portable Document Format, is widely used for displaying text and graphics consistently across different platforms and software applications. Whether you're consolidating reports, combining scanned documents, or assembling multi-part forms, creating PDFs that merge content from various sources is a common requirement in business applications.
Python offers versatility and ease of use when working with various computer systems. However, handling source PDF files and input streams can present challenges. IronPDF, a Python library, provides a convenient solution for manipulating and working with existing PDF files.
This guide walks through the process of installing IronPDF for Python and demonstrates how to merge multiple PDF documents into a single PDF file. We'll cover both basic two-file merging and advanced batch operations for combining numerous documents.
Quickstart: Merge PDF Files in Python
- Install the Python library for merging PDF files
- Use
RenderHtmlAsPdfto generate individual PDF files - Apply the
Mergemethod to combine PDF files - Save the merged document with
SaveAs - Merge multiple PDFs by creating a list and using
Merge
What is IronPDF Python Library?
IronPDF is a Python library for PDF operations. It enables you to create, read, and edit PDF files. With IronPDF, you can generate PDFs from scratch, customize their appearance using HTML, CSS, JavaScript, and add metadata such as titles and author names. IronPDF allows seamless merging of multiple PDF files into a single destination file without relying on external frameworks.
The library provides comprehensive functionality for PDF manipulation, including the ability to compress PDFs after merging to reduce file size, extract text from merged documents, and fill PDF forms programmatically.
Why Should I Use IronPDF for PDF Operations?
IronPDF is cross-platform compatible, supporting Python 3.x on Windows and Linux. This ensures functionality regardless of your operating environment. The library handles complex PDF operations internally, allowing developers to focus on business logic rather than low-level PDF manipulation details.
IronPDF maintains document formatting and quality when merging PDFs, ensuring that fonts, images, and layouts remain intact throughout the process. It also supports advanced features like digital signatures and encryption for securing merged documents.
How Do I Install IronPDF via Pip?
To install the IronPDF library using pip, execute the following command:
```shell :title=Install IronPDF pip install ironpdf
For detailed installation instructions and troubleshooting common issues like ["Module Not Defined" errors](https://ironpdf.com/python/troubleshooting/module-not-defined/) or [permission problems](https://ironpdf.com/python/troubleshooting/could-not-install-package/), refer to the official documentation.
### What Import Statements Do I Need?
In your Python script, include the following import statements to utilize IronPDF's functions for generating and merging PDF files:
```python
from ironpdf import *
# Optional: Configure license key if you have one
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"For production applications, you'll need to configure your license key to unlock the full functionality of IronPDF.
How Do I Merge Two PDF Files in Python?
Merging PDF files involves two steps:
- Creating the PDF files
- Merging them into a single final PDF file
Here is a complete working example that demonstrates the process:
from ironpdf import *
# HTML content for the first PDF
html_a = """<p> [PDF_A] </p>
<p> [PDF_A] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_A] 2nd Page</p>"""
# HTML content for the second PDF
html_b = """<p> [PDF_B] </p>
<p> [PDF_B] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_B] 2nd Page</p>"""
# Initialize ChromePdfRenderer
renderer = ChromePdfRenderer()
# Convert HTML to PDF documents
pdfdoc_a = renderer.RenderHtmlAsPdf(html_a)
pdfdoc_b = renderer.RenderHtmlAsPdf(html_b)
# Merge the PDF documents
merged = PdfDocument.Merge([pdfdoc_a, pdfdoc_b])
# Save the merged document
merged.SaveAs("Merged.pdf")from ironpdf import *
# HTML content for the first PDF
html_a = """<p> [PDF_A] </p>
<p> [PDF_A] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_A] 2nd Page</p>"""
# HTML content for the second PDF
html_b = """<p> [PDF_B] </p>
<p> [PDF_B] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_B] 2nd Page</p>"""
# Initialize ChromePdfRenderer
renderer = ChromePdfRenderer()
# Convert HTML to PDF documents
pdfdoc_a = renderer.RenderHtmlAsPdf(html_a)
pdfdoc_b = renderer.RenderHtmlAsPdf(html_b)
# Merge the PDF documents
merged = PdfDocument.Merge([pdfdoc_a, pdfdoc_b])
# Save the merged document
merged.SaveAs("Merged.pdf")Why Use RenderHtmlAsPdf for PDF Generation?
In the provided code, two HTML strings are created, each representing content spanning two pages. The RenderHtmlAsPdf method from IronPDF converts both HTML strings into separate PDF documents as PdfDocument objects. This approach offers flexibility for creating dynamic PDFs from HTML content, particularly useful when generating reports or documents from web-based templates. For more complex HTML rendering scenarios, explore the HTML to PDF tutorial.
How Does the Merge Method Work?
To merge the PDF files, the PdfDocument.Merge method is utilized. It merges the two PDF documents into a single PDF document by combining the contents of the PdfDocument objects into a new PdfDocument. The method accepts a list of PdfDocument objects and preserves the order in which they appear in the list. This makes it easy to control the sequence of pages in your final merged document.
How Do I Save the Merged PDF Document?
To save the merged PDF file to a specific destination file path, use the following concise one-liner:
# Save the merged PDF document
merged.SaveAs("Merged.pdf")
# Optional: Save with compression to reduce file size
merged.CompressImages(90)
merged.SaveAs("Merged_Compressed.pdf")# Save the merged PDF document
merged.SaveAs("Merged.pdf")
# Optional: Save with compression to reduce file size
merged.CompressImages(90)
merged.SaveAs("Merged_Compressed.pdf")You can also apply additional optimizations like PDF compression to reduce the file size of your merged document.
The output of the merged PDF file is shown below:
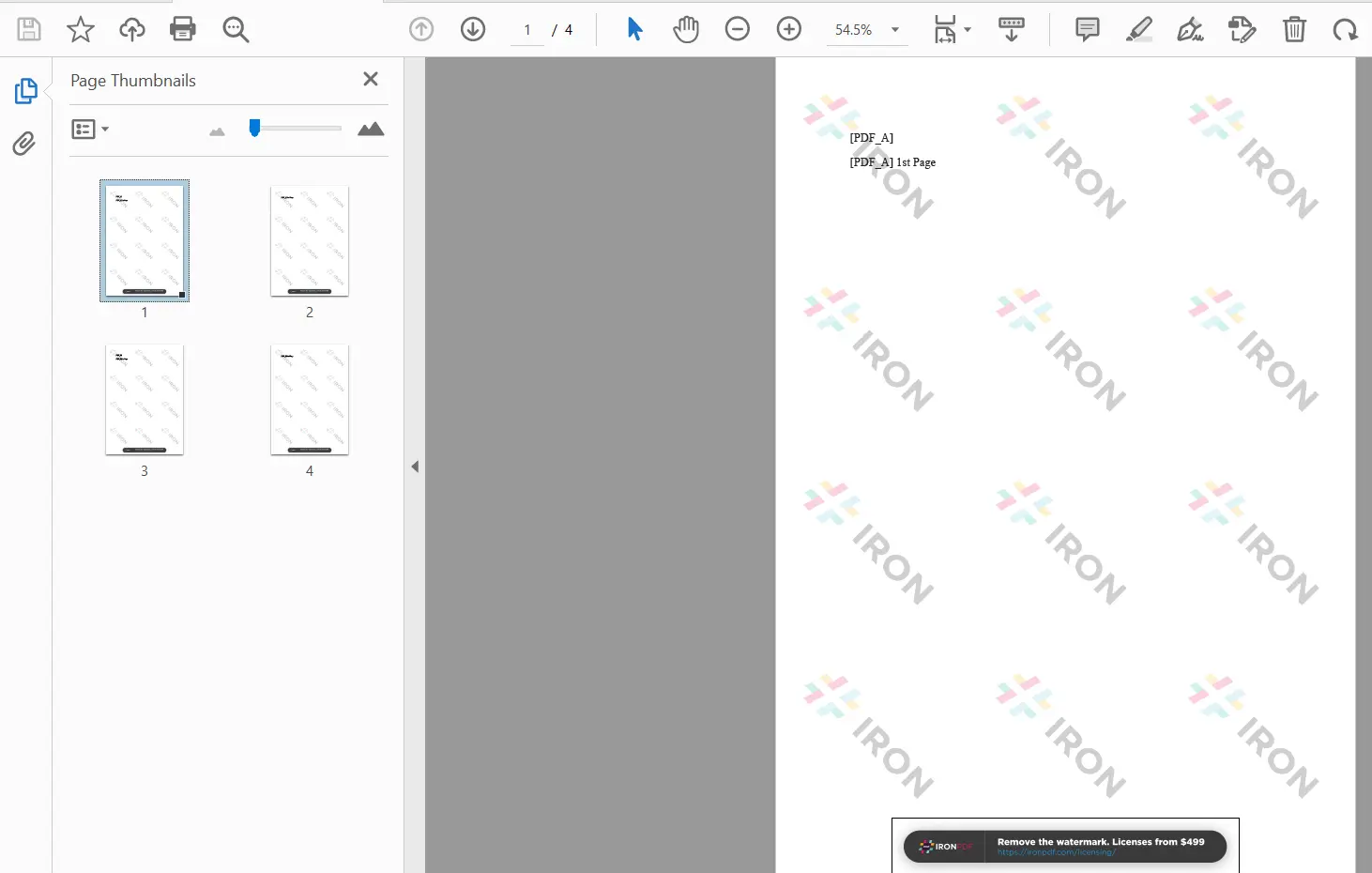
Merge Two PDF Documents
How Do I Merge More Than Two PDF Files?
To merge more than two PDF documents in Python using IronPDF, follow these two simple steps:
- Create a list and add the PdfDocument objects of the PDFs you want to merge
- Pass this list as a single argument to the
PdfDocument.Mergemethod
What's the Process for Multiple PDF Merging?
The code snippet below illustrates the process:
from ironpdf import *
# HTML content for the first PDF
html_a = """<p> [PDF_A] </p>
<p> [PDF_A] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_A] 2nd Page</p>"""
# HTML content for the second PDF
html_b = """<p> [PDF_B] </p>
<p> [PDF_B] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_B] 2nd Page</p>"""
# HTML content for the third PDF
html_c = """<p> [PDF_C] </p>
<p> [PDF_C] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_C] 2nd Page</p>"""
# HTML content for the fourth PDF (adding more documents)
html_d = """<p> [PDF_D] </p>
<p> [PDF_D] Content Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_D] Summary Page</p>"""
# Initialize ChromePdfRenderer
renderer = ChromePdfRenderer()
# Convert HTML to PDF documents
pdfdoc_a = renderer.RenderHtmlAsPdf(html_a)
pdfdoc_b = renderer.RenderHtmlAsPdf(html_b)
pdfdoc_c = renderer.RenderHtmlAsPdf(html_c)
pdfdoc_d = renderer.RenderHtmlAsPdf(html_d)
# List of PDF documents to merge
pdfs = [pdfdoc_a, pdfdoc_b, pdfdoc_c, pdfdoc_d]
# Merge the list of PDFs into a single PDF
pdf = PdfDocument.Merge(pdfs)
# Save the merged PDF document
pdf.SaveAs("merged_multiple.pdf")
# Optional: Add metadata to the merged document
pdf.MetaData.Author = "IronPDF Python"
pdf.MetaData.Title = "Merged Document Collection"
pdf.SaveAs("merged_with_metadata.pdf")from ironpdf import *
# HTML content for the first PDF
html_a = """<p> [PDF_A] </p>
<p> [PDF_A] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_A] 2nd Page</p>"""
# HTML content for the second PDF
html_b = """<p> [PDF_B] </p>
<p> [PDF_B] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_B] 2nd Page</p>"""
# HTML content for the third PDF
html_c = """<p> [PDF_C] </p>
<p> [PDF_C] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_C] 2nd Page</p>"""
# HTML content for the fourth PDF (adding more documents)
html_d = """<p> [PDF_D] </p>
<p> [PDF_D] Content Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_D] Summary Page</p>"""
# Initialize ChromePdfRenderer
renderer = ChromePdfRenderer()
# Convert HTML to PDF documents
pdfdoc_a = renderer.RenderHtmlAsPdf(html_a)
pdfdoc_b = renderer.RenderHtmlAsPdf(html_b)
pdfdoc_c = renderer.RenderHtmlAsPdf(html_c)
pdfdoc_d = renderer.RenderHtmlAsPdf(html_d)
# List of PDF documents to merge
pdfs = [pdfdoc_a, pdfdoc_b, pdfdoc_c, pdfdoc_d]
# Merge the list of PDFs into a single PDF
pdf = PdfDocument.Merge(pdfs)
# Save the merged PDF document
pdf.SaveAs("merged_multiple.pdf")
# Optional: Add metadata to the merged document
pdf.MetaData.Author = "IronPDF Python"
pdf.MetaData.Title = "Merged Document Collection"
pdf.SaveAs("merged_with_metadata.pdf")How Does List-Based Merging Differ?
In the above code, multiple PDF documents are generated using the HTML render method. A new list collection is created to store these PDFs. This list is then passed as a single argument to the merge method, resulting in the merging of the PDFs into a single document. This approach is highly scalable and can handle dozens or even hundreds of PDFs efficiently.
For more advanced scenarios, you might want to merge existing PDF files from disk. Here's how:
# Load existing PDF files from disk
existing_pdf1 = PdfDocument.FromFile("report1.pdf")
existing_pdf2 = PdfDocument.FromFile("report2.pdf")
existing_pdf3 = PdfDocument.FromFile("report3.pdf")
# Merge existing PDFs
merged_existing = PdfDocument.Merge([existing_pdf1, existing_pdf2, existing_pdf3])
# Save the result
merged_existing.SaveAs("merged_reports.pdf")# Load existing PDF files from disk
existing_pdf1 = PdfDocument.FromFile("report1.pdf")
existing_pdf2 = PdfDocument.FromFile("report2.pdf")
existing_pdf3 = PdfDocument.FromFile("report3.pdf")
# Merge existing PDFs
merged_existing = PdfDocument.Merge([existing_pdf1, existing_pdf2, existing_pdf3])
# Save the result
merged_existing.SaveAs("merged_reports.pdf")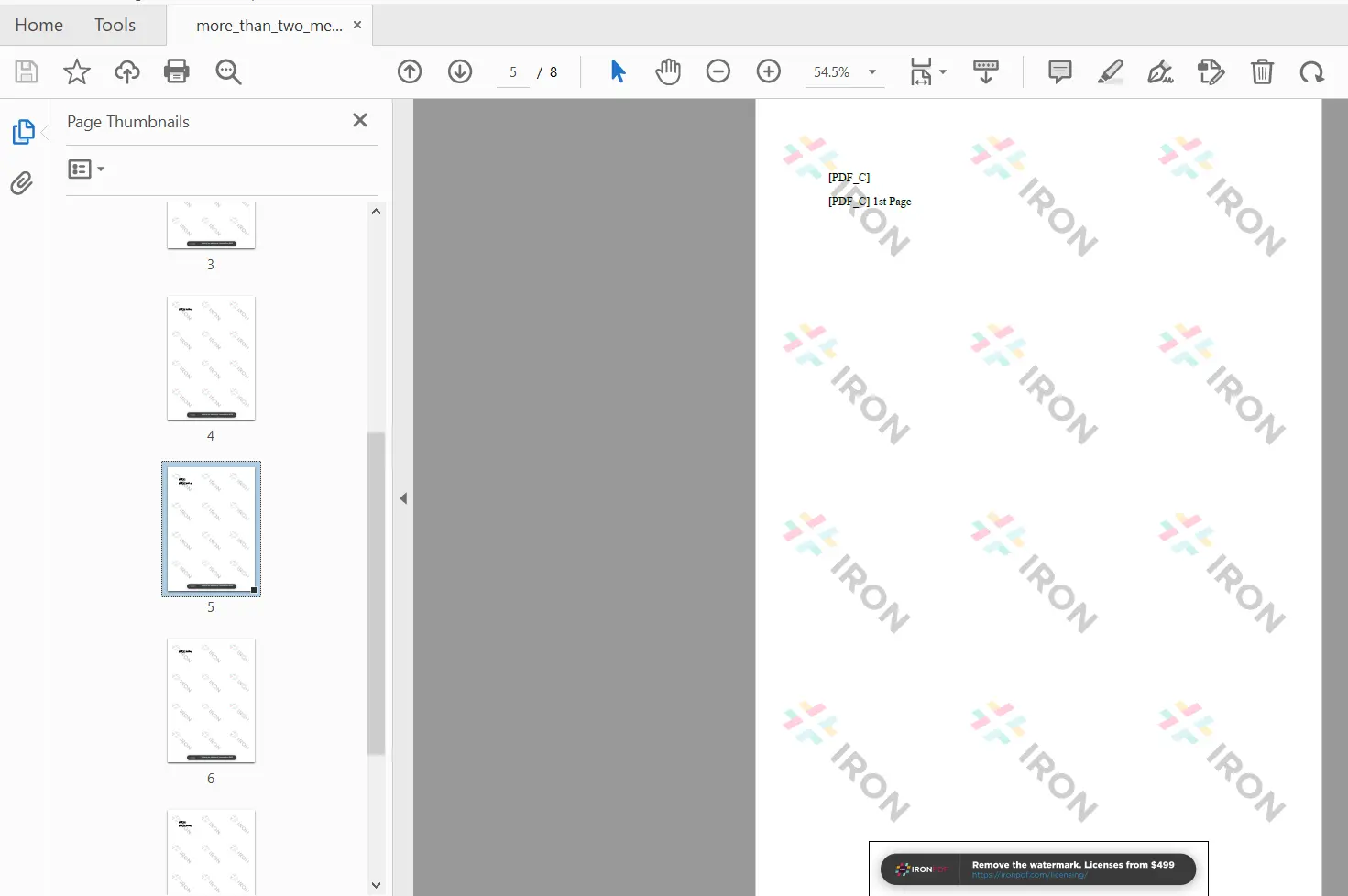
Merge More Than Two PDF Files
What Are the Key Takeaways?
This article provides a comprehensive guide on merging PDF files using IronPDF for Python.
We begin by discussing the installation process of IronPDF for Python. Then, we explore a straightforward approach to generate PDFs using the HTML rendering methods. Additionally, we demonstrate merging two or more PDFs into a single PDF file. The library also supports advanced features like adding headers and footers to merged documents or applying watermarks for branding purposes.
Why Choose IronPDF for Python PDF Operations?
With efficient performance and precise execution, IronPDF is an excellent choice for working with PDF files in Python. The library enables seamless conversion from HTML/URL/String to PDF. It supports popular document types such as HTML, CSS, JS, JPG, and PNG, ensuring the production of high-quality PDF documents. Built using current technology, IronPDF provides a reliable solution for PDF-related tasks in Python.
The library also offers advanced capabilities such as parallel PDF generation for high-performance scenarios and async processing for non-blocking operations, making it suitable for both desktop applications and web services.
Where Can I Find More Resources?
To gain further insights into utilizing IronPDF for Python, explore our extensive collection of Code Examples. For specific PDF manipulation tasks, check out our guides on splitting PDFs, converting PDFs to images, or printing PDFs.
IronPDF offers free usage for development purposes and provides licensing options for commercial applications. For detailed information about licensing, visit the following link.
Download the software product.
Frequently Asked Questions
How do I merge multiple PDF files into one using Python?
IronPDF for Python provides a simple solution using the PdfDocument.Merge() method. You can install IronPDF, create or load PDF documents, then use the Merge method to combine them into a single file. The library supports both two-file merging and batch operations for combining numerous PDFs efficiently.
What are the basic steps to merge PDFs in Python?
The basic steps are: 1) Install IronPDF Python library, 2) Use RenderHtmlAsPdf to generate individual PDF files or load existing PDFs, 3) Apply the Merge method to combine PDF files, 4) Save the merged document with SaveAs method. For multiple PDFs, you can create a list and use the Merge method to combine them all at once.
Does merging PDFs maintain the original document quality and formatting?
Yes, IronPDF maintains document formatting and quality when merging PDFs. The library ensures that fonts, images, and layouts remain intact throughout the merging process, preserving the original appearance of each document in the final merged PDF.
Can I perform additional operations on merged PDFs?
Absolutely! IronPDF provides comprehensive functionality beyond merging. After combining PDFs, you can compress the merged document to reduce file size, extract text from the combined file, fill PDF forms programmatically, and even add digital signatures to the final document.
Is the Python PDF merging library cross-platform compatible?
Yes, IronPDF is cross-platform compatible, supporting Python 3.x on both Windows and Linux operating systems. This ensures consistent functionality regardless of your operating environment, making it suitable for diverse development scenarios.
What makes this approach better than using external frameworks?
IronPDF allows seamless merging of multiple PDF files into a single destination file without relying on external frameworks. The library handles complex PDF operations internally, allowing developers to focus on business logic rather than low-level PDF manipulation details, resulting in cleaner and more maintainable code.


Still Scrolling?
Want proof fast?
run a sample watch your HTML become a PDF.












