
如何在.NET中从PDF中提取数据
PDF文档在商业中无处不在; 现代例子包括发票、报告、合同和手册。 但是以编程方式从中提取重要信息可能很棘手。 PDF关注的是外观,而不是数据访问方式。
对于.NET开发人员,IronPDF是一个强大的.NET PDF库,使从PDF文件中提取数据变得容易。 您可以直接从输入的PDF文档中提取文本、表格、表单字段、图像和附件。 无论您是在自动化发票处理、构建知识库还是生成报告,这个库都可以节省大量时间。
本指南将通过实际示例向您介绍如何提取文本内容、表格数据和表单字段值,并在每个代码片段之后进行说明,以便您可以将其适应到自己的项目中。
开始使用 IronPDF
通过NuGet包管理器安装IronPDF只需几秒钟。 打开包管理器控制台并运行:
Install-Package IronPdf
安装后,您可以立即开始处理输入的PDF文档。 这是一个展示IronPDF API简单性的最简.NET示例:
using IronPdf;
// Load any PDF document
var pdf = PdfDocument.FromFile("document.pdf");
// Extract all text with one line
string allText = pdf.ExtractAllText();
Console.WriteLine(allText);using IronPdf;
// Load any PDF document
var pdf = PdfDocument.FromFile("document.pdf");
// Extract all text with one line
string allText = pdf.ExtractAllText();
Console.WriteLine(allText);IRON VB CONVERTER ERROR developers@ironsoftware.com此代码加载一个PDF并提取每一处文本。 IronPDF自动处理复杂的PDF结构、表单数据和可能导致其他库问题的编码。 从PDF文档中提取的数据可以保存到文本文件,或进一步处理以进行分析。
实用提示:您可以将提取的文本保存为.txt文件以便后续处理,或者解析它以填充数据库、Excel表格或知识库。 此方法适用于报告、合同或任何您只需要快速获取原始文本的PDF。
从PDF文档中提取数据
现实世界中的应用程序通常需要精确的数据提取。 IronPDF提供多种方法来从PDF中特定页面中获取有价值的信息。 在本例中,我们将使用以下PDF:
以下代码将从此PDF的特定页面中提取数据,并将结果返回到我们的控制台。
using IronPdf;
using System;
// Load any PDF document
var pdf = PdfDocument.FromFile("AnnualReport2024.pdf");
// Extract from selected pages
int[] pagesToExtract = { 0, 2, 4 }; // Pages 1, 3, and 5
foreach (var pageIndex in pagesToExtract)
{
string pageText = pdf.ExtractTextFromPage(pageIndex);
// Split on 2 or more spaces (tables often flatten into space-separated values)
var tokens = Regex.Split(pageText, @"\s{2,}");
foreach (string token in tokens)
{
// Match totals, invoice headers, and invoice rows
if (token.Contains("Invoice") || token.Contains("Total") || token.StartsWith("INV-"))
{
Console.WriteLine($"Important: {token.Trim()}");
}
}
}using IronPdf;
using System;
// Load any PDF document
var pdf = PdfDocument.FromFile("AnnualReport2024.pdf");
// Extract from selected pages
int[] pagesToExtract = { 0, 2, 4 }; // Pages 1, 3, and 5
foreach (var pageIndex in pagesToExtract)
{
string pageText = pdf.ExtractTextFromPage(pageIndex);
// Split on 2 or more spaces (tables often flatten into space-separated values)
var tokens = Regex.Split(pageText, @"\s{2,}");
foreach (string token in tokens)
{
// Match totals, invoice headers, and invoice rows
if (token.Contains("Invoice") || token.Contains("Total") || token.StartsWith("INV-"))
{
Console.WriteLine($"Important: {token.Trim()}");
}
}
}IRON VB CONVERTER ERROR developers@ironsoftware.com本示例展示了如何从PDF文档中提取文本,搜索关键信息,并准备将其存储到数据文件或知识库中。 ExtractTextFromPage()方法保持文档的阅读顺序,非常适合文档分析和内容索引任务。
从PDF文档中提取表格数据
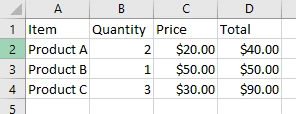
PDF文件中的表格没有原生结构; 它们只是被定位得像表格的文本内容。 IronPDF在提取表格数据时保留布局,因此您可以将其处理成Excel或文本文件。 在本例中,我们将使用这个PDF:
using IronPdf;
using System.Text;
using System.Text.RegularExpressions;
var pdf = PdfDocument.FromFile("example.pdf");
string rawText = pdf.ExtractAllText();
// Split into lines for processing
string[] lines = rawText.Split('\n');
var csvBuilder = new StringBuilder();
foreach (string line in lines)
{
if (string.IsNullOrWhiteSpace(line) || line.Contains("Page"))
continue;
string[] rawCells = Regex.Split(line.Trim(), @"\s+");
string[] cells;
// If the line starts with "Product", combine first two tokens as product name
if (rawCells[0].StartsWith("Product") && rawCells.Length >= 5)
{
cells = new string[rawCells.Length - 1];
cells[0] = rawCells[0] + " " + rawCells[1]; // Combine Product + letter
Array.Copy(rawCells, 2, cells, 1, rawCells.Length - 2);
}
else
{
cells = rawCells;
}
// Keep header or table rows
bool isTableOrHeader = cells.Length >= 2
&& (cells[0].StartsWith("Item") || cells[0].StartsWith("Product")
|| Regex.IsMatch(cells[0], @"^INV-\d+"));
if (isTableOrHeader)
{
Console.WriteLine($"Row: {string.Join("|", cells)}");
string csvRow = string.Join(",", cells).Trim();
csvBuilder.AppendLine(csvRow);
}
}
// Save as CSV for Excel import
File.WriteAllText("extracted_table.csv", csvBuilder.ToString());
Console.WriteLine("Table data exported to CSV");using IronPdf;
using System.Text;
using System.Text.RegularExpressions;
var pdf = PdfDocument.FromFile("example.pdf");
string rawText = pdf.ExtractAllText();
// Split into lines for processing
string[] lines = rawText.Split('\n');
var csvBuilder = new StringBuilder();
foreach (string line in lines)
{
if (string.IsNullOrWhiteSpace(line) || line.Contains("Page"))
continue;
string[] rawCells = Regex.Split(line.Trim(), @"\s+");
string[] cells;
// If the line starts with "Product", combine first two tokens as product name
if (rawCells[0].StartsWith("Product") && rawCells.Length >= 5)
{
cells = new string[rawCells.Length - 1];
cells[0] = rawCells[0] + " " + rawCells[1]; // Combine Product + letter
Array.Copy(rawCells, 2, cells, 1, rawCells.Length - 2);
}
else
{
cells = rawCells;
}
// Keep header or table rows
bool isTableOrHeader = cells.Length >= 2
&& (cells[0].StartsWith("Item") || cells[0].StartsWith("Product")
|| Regex.IsMatch(cells[0], @"^INV-\d+"));
if (isTableOrHeader)
{
Console.WriteLine($"Row: {string.Join("|", cells)}");
string csvRow = string.Join(",", cells).Trim();
csvBuilder.AppendLine(csvRow);
}
}
// Save as CSV for Excel import
File.WriteAllText("extracted_table.csv", csvBuilder.ToString());
Console.WriteLine("Table data exported to CSV");IRON VB CONVERTER ERROR developers@ironsoftware.comPDF中的表格通常只是被定位得像网格的文本。 此检查有助于确定一行是否属于表格行或标题。 通过过滤掉标题、页脚和无关文本,您可以从PDF中提取干净的表格数据,并且它将准备好用于CSV或Excel。
此工作流程适用于PDF表单、财务文件和报告。 您可以稍后将PDF中的数据转换为xlsx文件或将其合并为包含所有有用数据的zip文件。 对于具有合并单元格的复杂表格,您可能需要根据列位置调整解析逻辑。
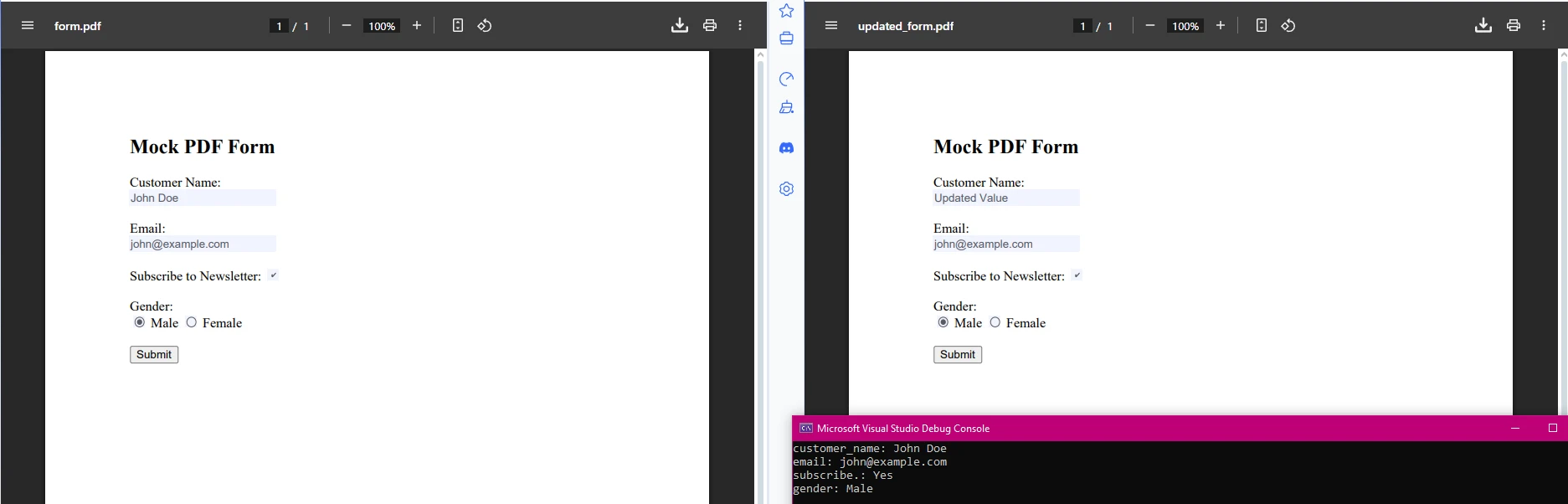
从PDF中提取表单字段数据
IronPDF还允许表单字段数据提取和修改:
using IronPdf;
using System.Drawing;
using System.Linq;
var pdf = PdfDocument.FromFile("form_document.pdf");
// Extract form field data
var form = pdf.Form;
foreach (var field in form) // Removed '.Fields' as 'FormFieldCollection' is enumerable
{
Console.WriteLine($"{field.Name}: {field.Value}");
// Update form values if needed
if (field.Name == "customer_name")
{
field.Value = "Updated Value";
}
}
// Save modified form
pdf.SaveAs("updated_form.pdf");using IronPdf;
using System.Drawing;
using System.Linq;
var pdf = PdfDocument.FromFile("form_document.pdf");
// Extract form field data
var form = pdf.Form;
foreach (var field in form) // Removed '.Fields' as 'FormFieldCollection' is enumerable
{
Console.WriteLine($"{field.Name}: {field.Value}");
// Update form values if needed
if (field.Name == "customer_name")
{
field.Value = "Updated Value";
}
}
// Save modified form
pdf.SaveAs("updated_form.pdf");IRON VB CONVERTER ERROR developers@ironsoftware.com此代码片段从PDF中提取表单字段值,并允许您以编程方式更新它们。 这使得处理PDF表单和提取指定信息范围用于分析或生成报告变得容易。 这对于自动化工作流程如客户入职、调查处理或数据验证非常有用。
下一步
IronPDF使.NET中的PDF数据提取变得实用高效。 您可以从各种PDF文档中提取图像、文本、表格、表单字段,甚至是提取附件,包括通常需要额外OCR处理的扫描PDF。
无论您的目标是构建知识库、自动化报告工作流程,还是从财务PDF中提取数据,该库都为您提供了无需手动复制或易出错解析来完成任务的工具。 它简单、快速,并直接集成到Visual Studio项目中。 试试看,您可能会节省大量时间,避免处理PDF的常见麻烦。
准备在您的应用程序中实现PDF数据提取了吗? IronPDF听起来是适合您的.NET库吗? 开始您的免费试用以用于商业用途。 请访问我们的文档以获取全面的指南和API参考。
常见问题解答
使用 .NET 从 PDF 文档中提取文本的最佳方法是什么?
使用 IronPDF,您可以轻松地在 .NET 应用程序中从 PDF 文档中提取文本。它提供的方法可以有效检索文本数据,确保您能访问所需的内容。
IronPDF 能否处理扫描的 PDFs 以进行数据提取?
是的,IronPDF 支持 OCR(光学字符识别)来处理和提取扫描的 PDFs 中的数据,使在图像为主的文档中访问文本成为可能。
如何使用 C# 从 PDF 中提取表格?
IronPDF 提供了在 C# 中解析和提取 PDF 文档中表格的功能。您可以使用特定的方法精准识别并获取表格数据。
使用 IronPDF 进行 PDF 数据提取有哪些好处?
IronPDF 提供了全面的 PDF 数据提取解决方案,包括文本检索、表格解析和扫描文档的 OCR。它无缝集成于 .NET 应用程序中,提供了可靠且高效的方式来处理 PDF 数据。
可以使用 IronPDF 从 PDF 中提取图片吗?
可以,IronPDF 允许您从 PDF 中提取图片。此功能在您需要访问和操作嵌入在 PDF 文档中的图片时非常有用。
IronPDF 如何在数据提取过程中处理复杂的 PDF 布局?
IronPDF 设计用来管理复杂的 PDF 布局,通过提供强大的工具来导航和提取数据,确保您能处理具有复杂格式和结构的文档。
我可以在 .NET 应用程序中自动化 PDF 数据提取吗?
当然可以。IronPDF 可以集成到 .NET 应用程序中,自动化 PDF 数据提取,简化那些需要定期和一致数据检索的流程。
我可以使用哪些编程语言与 IronPDF 一起进行 PDF 数据提取?
IronPDF 主要在 .NET 框架中使用 C#,为开发人员以编程方式从 PDF 中提取数据提供了广泛的支持和功能。
IronPDF 是否支持从 PDF 文档中提取元数据?
是的,IronPDF 可以从 PDF 文档中提取元数据,允许您访问信息,例如作者、创建日期以及其他文档属性。
有哪些用于学习使用 IronPDF 进行 PDF 数据提取的示例代码?
开发者指南提供了完整的 C# 教程以及实用的代码示例,帮助您掌握使用 IronPDF 在 .NET 应用程序中进行 PDF 数据提取。
IronPDF 是否完全兼容最新的 .NET 10 版本?这能为数据提取带来哪些好处?
是的——IronPDF 完全兼容 .NET 10,支持其所有性能、API 和运行时改进,例如减少堆分配、数组接口去虚拟化以及增强的语言特性。这些改进使得 C# 应用程序中的 PDF 数据提取工作流程更快、更高效。











