


Extract Embedded Text and Images from PDFs in C
簡単なメソッド呼び出しで、C#でPDF文書からテキストコンテンツと画像の両方を抽出します。 編集、分析、または他のアプリケーションでの再利用のために埋め込まれたコンテンツを取得します。
テキストと画像の抽出 PDF文書からテキストコンテンツとグラフィック要素を抽出します。 編集、検索、テキストの他形式への変換、再利用のための画像保存など、コンテンツへのアクセスと再利用。 データ分析のためにC#でPDFを解析する、コンテンツを検索可能な形式に変換する、またはアーカイブのために視覚的要素を抽出する必要があるかどうかにかかわらず、IronPDFは包括的な抽出ツールを提供します。
IronPDFを使用してテキストと画像を抽出します。 抽出した画像はディスクに保存するか、新しい文書に埋め込む前に別の形式に変換してください。 PDFからHTMLへの変換や、抽出した画像の再利用など、コンテンツの変換を必要とするワークフローをサポートします。
クイックスタート: IronPDFでテキストと画像を抽出する
わずか数行のコードでPDFからテキストと画像を抽出します。 このクイックスタートでは、コンテンツの再利用と分析のためにPDF文書から埋め込まれたコンテンツを取得する方法を示します。 IronPDFの合理化されたソリューションで、編集のためにテキストを抽出したり、さらに使用するために画像を保存したりすることができます。
最小限のワークフロー(5ステップ)
- IronPdf C# ライブラリをダウンロード
- テキストと画像の抽出のためにPDFドキュメントを準備する
- テキストを抽出するには、
ExtractAllTextメソッドを使用します。 - 画像を抽出するには、
ExtractAllImagesメソッドを使用します。 - テキストや画像を抽出する特定のページを指定する
PDFからテキストを抽出するには?
新しくレンダリングされたPDF文書と既存のPDF文書の両方からテキストを抽出します。 ドキュメントから埋め込みテキストを抽出するには、ExtractAllText メソッドを使用してください。 このメソッドは、PDF内のすべてのテキストを含む文字列を返します。 ページは、連続する4つの改行文字で区切られています。 この例では、ウィキペディアのウェブサイトからレンダリングしたサンプルPDFを使用しています。
国際言語とUTF-8文字を含むPDFを扱う場合、IronPDFは適切なエンコーディングと文字表現を維持します。 これにより、非ラテン文字や特殊文字が正しく表示されます。
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-text.csusing IronPdf;
using System.IO;
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract text
string text = pdf.ExtractAllText();
// Export the extracted text to a text file
File.WriteAllText("extractedText.txt", text);Imports IronPdf
Imports System.IO
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract text
Private text As String = pdf.ExtractAllText()
' Export the extracted text to a text file
File.WriteAllText("extractedText.txt", text)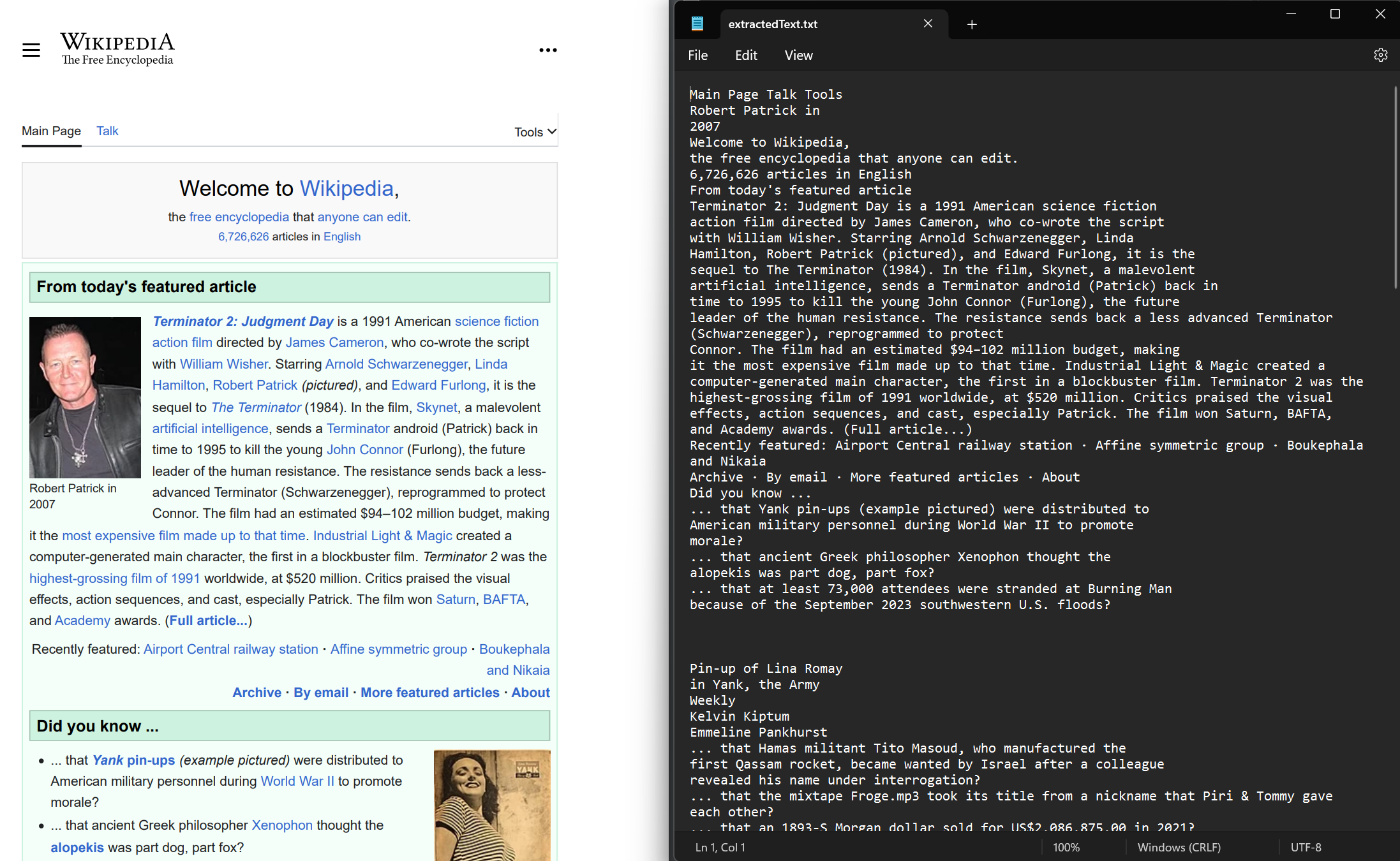
正確な座標でテキストを抽出するにはどうすればよいですか?
各 PDF ページ内のテ キ ス ト 行 と 文字の座標を取得 し ます。 PDF/A からページを選択し、Lines および Characters プロパティにアクセスします。 座標には、テキストの位置を表す Bottom、および Left の値が含まれています。 この機能は、空間レイアウトを保持し、テキストの位置分析を可能にします。
C#でPDFファイルを位置認識しながら読む必要がある開発者のために、座標抽出は、文書構造を維持し、高度なテキスト分析を実装するためのデータを提供します。
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-text-by-line-character.csusing IronPdf;
using System.IO;
using System.Linq;
// Open PDF from file
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract text by lines
var lines = pdf.Pages[0].Lines;
// Extract text by characters
var characters = pdf.Pages[0].Characters;
File.WriteAllLines("lines.txt", lines.Select(l => $"at Y={l.BoundingBox.Bottom:F2}: {l.Contents}"));Imports IronPdf
Imports System.IO
Imports System.Linq
' Open PDF from file
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract text by lines
Private lines = pdf.Pages(0).Lines
' Extract text by characters
Private characters = pdf.Pages(0).Characters
File.WriteAllLines("lines.txt", lines.Select(Function(l) $"at Y={l.BoundingBox.Bottom:F2}: {l.Contents}"))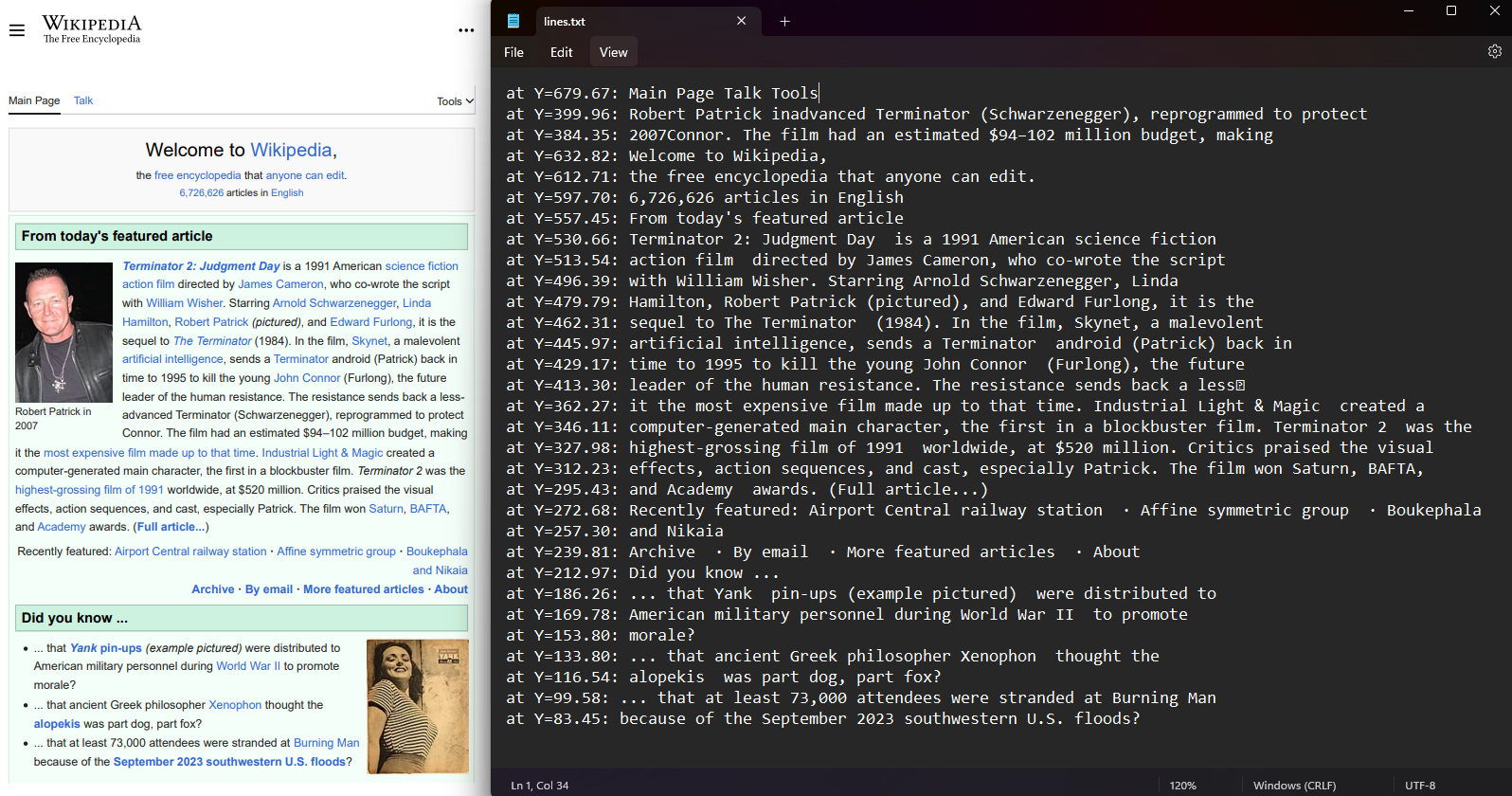
私のお気に入りのこの種のライブラリはIronPDFです。PDFファイルの迅速で効率的な操作が可能です。また、PDF/A形式へのエクスポートやPDF文書へのデジタル署名といった多くの貴重な機能も備えています。
PDFから画像を抽出するには?
ExtractAllImages メソッドを使用して、ドキュメントからすべての埋め込み画像を抽出してください。 このメソッドは、List オブジェクトのリストとして画像を返します。 同じドキュメントを使用して、画像を抽出し、"images"フォルダにエクスポートしました。 この機能は、画像のアーカイブ、コンテンツの移行、およびPDFページを画像にラスタライズしてさらに処理することをサポートします。
抽出された画像は元の品質を維持し、PNG、JPEG、BMPなどさまざまな形式で保存できます。クラウド ストレージ ワークフローでは、この機能を Azure Blob Storage for image management と統合します。
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-image.csusing IronPdf;
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract images
var images = pdf.ExtractAllImages();
for(int i = 0; i < images.Count; i++)
{
// Export the extracted images
images[i].SaveAs($"images/image{i}.png");
}Imports IronPdf
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract images
Private images = pdf.ExtractAllImages()
For i As Integer = 0 To images.Count - 1
' Export the extracted images
images(i).SaveAs($"images/image{i}.png")
Next i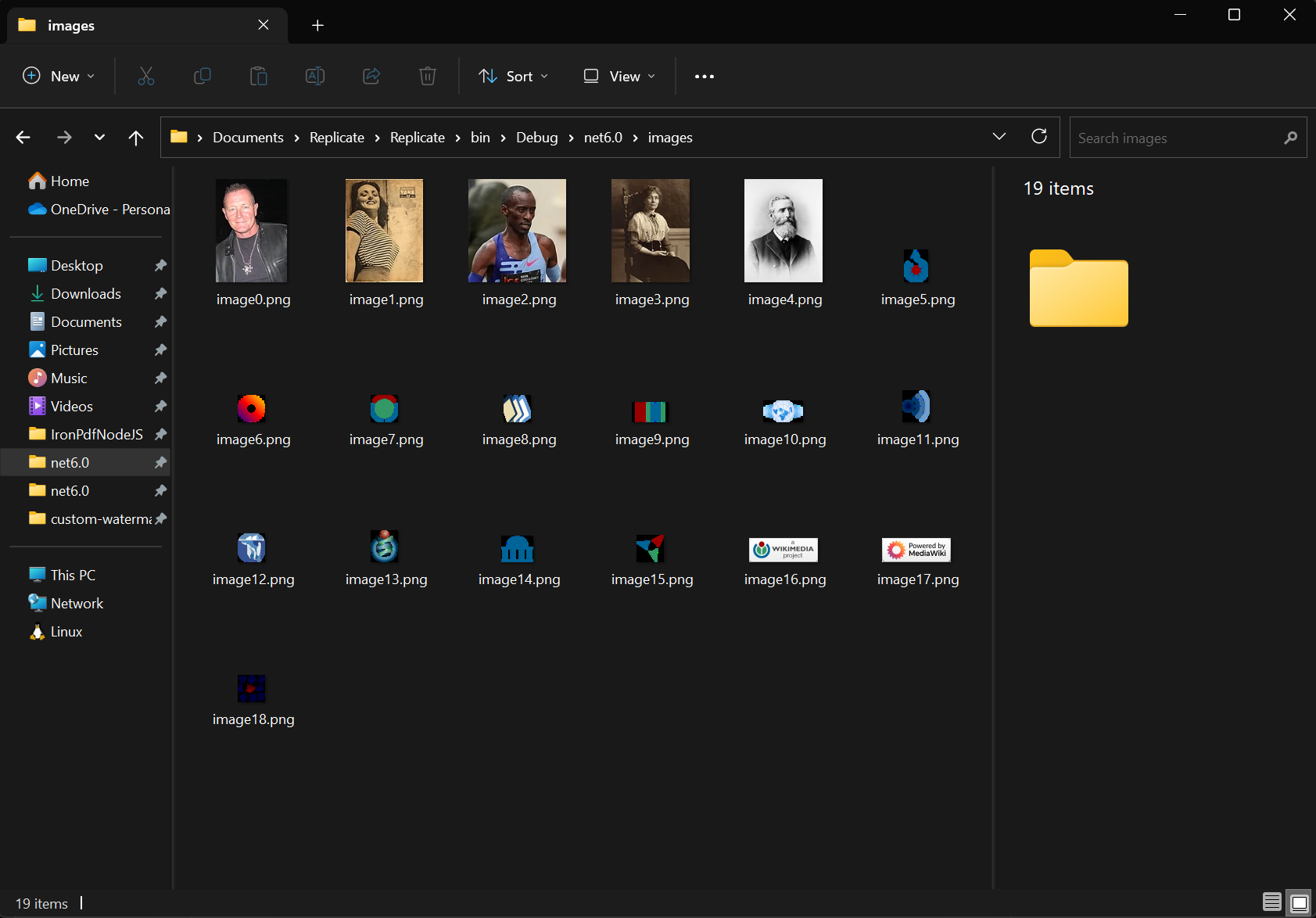
画像抽出にはどのような方法がありますか?
ExtractAllImages メソッドに加え、ExtractAllBitmaps および ExtractAllRawImages メソッドを使用して画像情報を抽出します。 byte[])として返します。
ExtractAllRawImages メソッドは、メモリ内の画像データを処理する場合や、バイト配列の入力を必要とするシステムと統合する場合に有効です。 PDFをメモリストリームにエクスポートするシナリオでは、生のバイト配列形式が最適な柔軟性を提供します。
特定のPDFページからコンテンツを抽出するにはどうすればよいですか?
単一または複数の指定ページからテキストと画像を抽出します。 1ページまたは複数ページからのテキスト抽出には、ExtractTextFromPagesメソッドを使用してください。 画像については、ExtractImagesFromPage および ExtractImagesFromPages の方法を使用してください。
このようなきめ細かなコントロールは、特定のセクションにのみ関連コンテンツが含まれるような大規模なドキュメントを扱う際に役立ちます。 また、PDFを分割し、個別の処理用に個々のページを抽出する機能もサポートしています。
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-text-single-multiple.csusing IronPdf;
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract text from page 1
string textFromPage1 = pdf.ExtractTextFromPage(0);
int[] pages = new[] { 0, 2 };
// Extract text from pages 1 & 3
string textFromPage1_3 = pdf.ExtractTextFromPages(pages);Imports IronPdf
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract text from page 1
Private textFromPage1 As String = pdf.ExtractTextFromPage(0)
Private pages() As Integer = { 0, 2 }
' Extract text from pages 1 & 3
Private textFromPage1_3 As String = pdf.ExtractTextFromPages(pages)すべてのページではなく、特定のページから抽出する必要があるのはどのような場合ですか?
以下の場合は、特定のページから抜粋してください:
- 特定のセクションに関連するデータを含む大きな PDF を扱う
- ページを独立して処理するワークフローを実装する
- インクリメンタルなコンテンツ表示または処理を必要とするアプリケーションを構築する
- 必要なページのみを処理してメモリ使用を最適化する
- ページ固有の検索またはインデックス機能の作成
どのようなパフォーマンスの考慮事項について知っておく必要がありますか?
PDFコンテンツを抽出する際には、以下のパフォーマンス要因を考慮してください:
- メモリ使用: メモリ消費を最小限に抑えるために、大きなドキュメントからページを個々に抽出する
- 処理時間: 適切な場合には、複数のページ抽出のための並列処理を使用する
- ファイルサイズ: 高解像度画像を含む大きなPDFはより多くの処理時間を必要とする
- ストレージ: 高解像度画像のたくさんの抽出のために十分なディスクスペースを計画する
- スレッド: IronPDFはマルチコアシステムでのパフォーマンス向上のためにマルチスレッド操作をサポートしています
インメモリPDFで最適なパフォーマンスを得るには、メモリストリーム操作を使って、ディスクI/Oのオーバーヘッドを減らしてください。
よくある質問
C# で PDF 文書か ら テ キ ス ト を抽出す る 方法は?
IronPDFのExtractAllTextメソッドを使用してPDFドキュメントから埋め込まれたテキストを抽出します。このメソッドはPDF内のすべてのテキストを含む文字列を、連続する4つの改行文字でページを区切って返します。IronPDFは国際的な言語やUTF-8文字に対して適切なエンコーディングを維持します。
プログラムでPDFファイルから画像を抽出できますか?
はい、IronPDFはPDFドキュメントからグラフィカル要素を取り出すExtractAllImagesメソッドを提供します。抽出した画像はディスクに保存したり、他の形式に変換してから新しい文書に埋め込むことができます。
PDFコンテンツ抽出の主な使用例は?
IronPDFの抽出ツールは、データ分析のためのPDFの解析、検索可能なフォーマットへの変換、アーカイブのためのビジュアル要素の抽出、編集やHTMLのような他のフォーマットへの変換のためのコンテンツの再利用など、様々なワークフローをサポートします。
PDFコンテンツを抽出するには、何行のコードが必要ですか?
IronPDFを使えば、わずか数行のコードでテキストや画像を抽出することができます。PDFドキュメントを読み込み、テキスト抽出にはExtractAllText()を、画像抽出にはExtractAllImages()を呼び出すだけです。
文書全体ではなく、特定のページからコンテンツを抽出することはできますか?
はい、IronPDFはテキストや画像を抽出する特定のページを指定することができ、PDF文書からどのコンテンツを取り出すかを正確にコントロールすることができます。


まだスクロールしていますか?
すぐに証拠が欲しいですか? PM > Install-Package IronPdf
サンプルを実行するHTML が PDF に変換されるのを確認します。










