

Przetwarzanie PDF w C#: Automatyzacja przepływów pracy dokumentów na skalę
Przetwarzanie PDF w C# za pomocą IronPDF umożliwia deweloperom .NET automatyzację przepływów pracy dokumentów na skalę — od równoległego przekształcania HTML na PDF i masowego łączenia/rozdzielania po asynchroniczne potoki PDF z wbudowaną obsługą błędów, logiką ponawiania i punktami kontrolnymi. bezpieczny dla wątków silnik Chromium IronPDF i zarządzanie pamięcią oparte na IDisposable sprawiają, że jest zbudowany specjalnie do automatyzacji PDF o wysokiej przepustowości, niezależnie od tego, czy działa lokalnie, w Azure Functions, AWS Lambda, czy Kubernetes.
TL;DR: Przewodnik Quickstart
Ten samouczek obejmuje skalowalną automatyzację plików PDF w języku C# — od równoległej konwersji i operacji zbiorczych po wdrażanie w chmurze i odporne wzorce potoków.
- Dla kogo to jest: programiści i architekci .NET odpowiedzialni za procesy wymagające dużej ilości dokumentacji — projekty migracji dokumentów, procesy generowania codziennych raportów, działania związane z zapewnieniem zgodności z przepisami lub digitalizację archiwów, w których przetwarzanie sekwencyjne nie jest możliwe.
- Co zbudujesz: Równoległa konwersja HTML na PDF z
Parallel.ForEach, masowe operacje łączenia i rozdzielania, asynchroniczne potoki zSemaphoreSlimdo kontroli współbieżności, obsługa błędów z logiką pomijania błędów i ponownego próby, wzorce punktów kontrolnych i wznowienia do odzyskiwania po awarii oraz konfiguracje wdrożenia chmurowego dla Azure Functions, AWS Lambda i Kubernetes. - Gdzie działa: .NET 6+, .NET Framework 4.6.2+, .NET Standard 2.0. Wszystkie operacje renderowania wykorzystują wbudowany silnik Chromium firmy IronPDF — nie są wymagane żadne zależności od przeglądarek bezinterfejsowych ani usług zewnętrznych.
- Kiedy stosować to podejście: Gdy trzeba przetworzyć więcej plików PDF, niż pozwala na to sekwencyjne wykonywanie — migracja dokumentów na dużą skalę, zaplanowane zadania wsadowe z wąskimi oknami czasowymi lub platformy wielodostępne o zmiennym obciążeniu dokumentami.
- Dlaczego to ma znaczenie techniczne:
ChromePdfRendererIronPDF jest bezpieczny dla wątków i bezstanowy dla każdego renderowania, co oznacza, że wiele wątków może bezpiecznie dzielić jednocześnie jedną instancję renderera. W połączeniu z wbudowaną biblioteką Task Parallel .NET iIDisposablenaPdfDocument, uzyskuje się przewidywalne zachowanie pamięci i nasycenie CPU bez stanów wyścigowych ani wycieków pamięci.
Zmieniaj cały katalog plików HTML na PDF za pomocą zaledwie kilku linii kodu:
-
Install IronPDF with NuGet Package Manager
PM > Install-Package IronPdf -
Skopiuj i uruchom ten fragment kodu.
using IronPdf; using System.IO; using System.Threading.Tasks; var renderer = new ChromePdfRenderer(); var htmlFiles = Directory.GetFiles("input/", "*.html"); Parallel.ForEach(htmlFiles, htmlFile => { var pdf = renderer.RenderHtmlFileAsPdf(htmlFile); pdf.SaveAs($"output/{Path.GetFileNameWithoutExtension(htmlFile)}.pdf"); }); -
Wdrożenie do testowania w środowisku produkcyjnym
Rozpocznij używanie IronPDF w swoim projekcie już dziś z darmową wersją próbną

Po zakupie lub zapisaniu się na 30-dniowy okres próbny IronPDF, należy dodać klucz licencyjny na początku aplikacji.
IronPdf.License.LicenseKey = "KEY";IronPdf.License.LicenseKey = "KEY";Imports IronPdf
IronPdf.License.LicenseKey = "KEY"Rozpocznij używanie IronPDF w swoim projekcie już dziś dzięki darmowej wersji próbnej.
Spis treści
- Zrozumienie problemu
- Podstawy
- Podstawowe operacje
- Odporność
- Wydajność
- Wdrożenie
- Podsumowanie
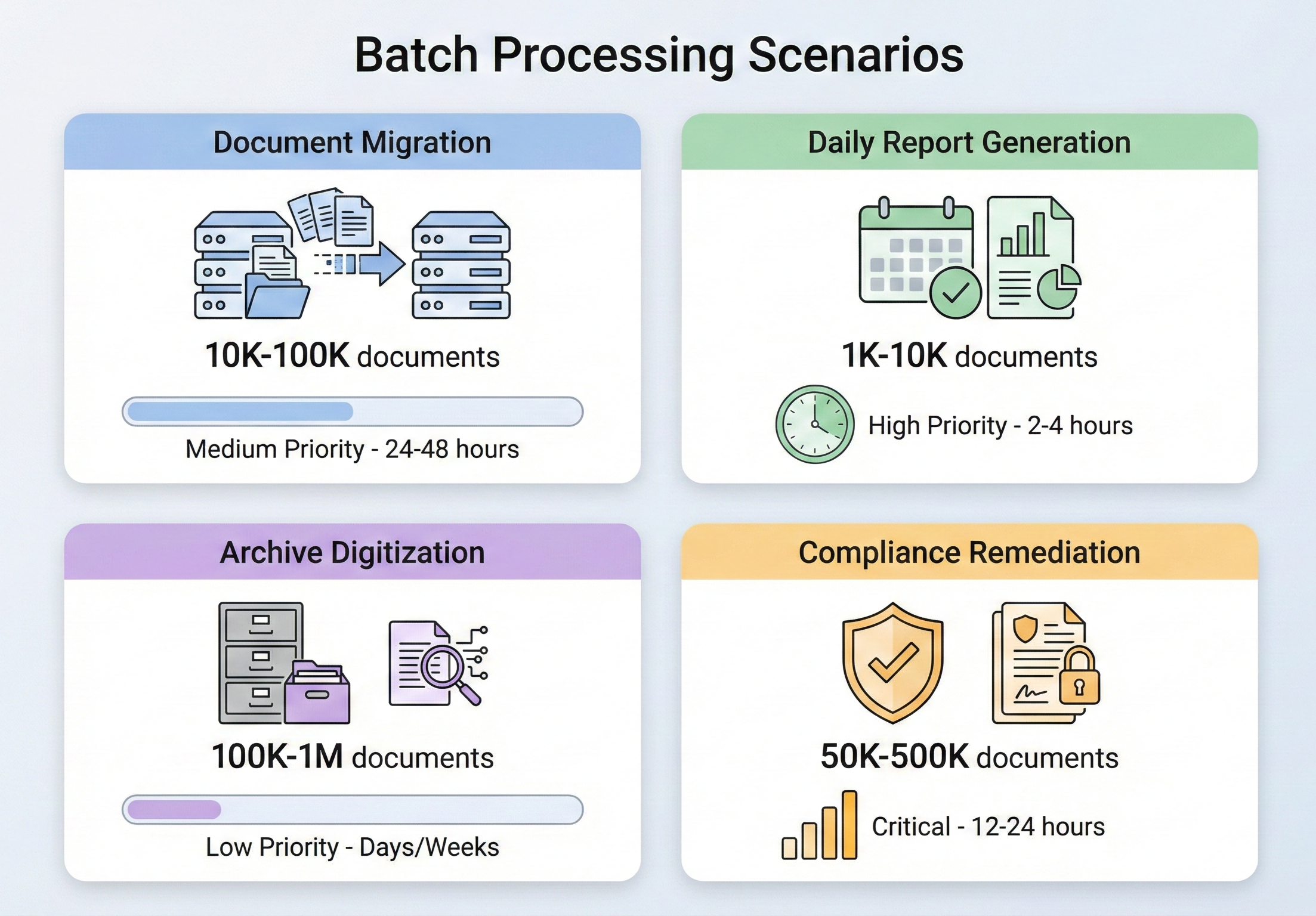
Gdy do przetworzenia są tysiące plików PDF
Przetwarzanie plików PDF w trybie wsadowym nie jest niszowym wymaganiem — to rutynowa część zarządzania dokumentami w przedsiębiorstwie. Sytuacje, w których jest to potrzebne, pojawiają się w każdej branży i mają jedną wspólną cechę: robienie rzeczy pojedynczo nie wchodzi w grę.
Jednym z najczęstszych powodów jest migracja dokumentów. Kiedy organizacja przechodzi z jednego systemu zarządzania dokumentami na inny, tysiące (czasem miliony) dokumentów wymagają konwersji, zmiany formatowania lub ponownego oznaczenia tagami. Firma ubezpieczeniowa migrująca ze starego systemu obsługi roszczeń może potrzebować przekonwertować 500 000 dokumentów roszczeniowych w formacie TIFF na pliki PDF z możliwością wyszukiwania. Kancelaria prawna przechodząca na nową platformę do zarządzania sprawami może potrzebować połączyć rozproszoną korespondencję w ujednolicone akta spraw. Są to zlecenia jednorazowe, ale mają ogromny zakres i nie ma w nich miejsca na błędy.
Codzienne generowanie raportów to stała wersja tego samego problemu. Instytucje finansowe, które generują raporty portfelowe na koniec dnia dla tysięcy klientów, firmy logistyczne, które tworzą listy przewozowe dla każdego wysyłanego kontenera, systemy opieki zdrowotnej, które tworzą codzienne podsumowania pacjentów w setkach oddziałów — wszystkie one generują pliki PDF na taką skalę, że przetwarzanie sekwencyjne przekroczyłoby dopuszczalne ramy czasowe. Kiedy 10 000 raportów musi być gotowych do godziny 6 rano, a dane są ostateczne dopiero o północy, nie ma sześciu godzin na renderowanie ich pojedynczo.
Digitalizacja archiwów znajduje się na styku migracji i zgodności z przepisami. Agencje rządowe, uczelnie i korporacje posiadające dziesiątki lat dokumentacji papierowej stoją przed koniecznością digitalizacji i archiwizacji dokumentów w formatach zgodnych ze standardami (zazwyczaj PDF/A). Ilość danych jest oszałamiająca — sama agencja NARA otrzymuje miliony stron dokumentów federalnych do trwałej archiwizacji — a proces musi być na tyle niezawodny, aby po latach nie odkrywać żadnych luk.
Najpilniejszym powodem jest często konieczność dostosowania do przepisów. Gdy audyt wykaże, że archiwum dokumentów nie spełnia nowo wprowadzonego standardu — na przykład przechowywane faktury nie są zgodne z formatem PDF/A-3 wymaganym w przepisach dotyczących e-fakturowania lub dokumentacja medyczna nie posiada oznaczeń dostępności wymaganych przez sekcję 508 — konieczne jest przetworzenie całego istniejącego archiwum zgodnie z nowym standardem. Presja jest duża, terminy są napięte, a objętość zależy od tego, co akurat znajduje się w archiwum.
W każdym z tych scenariuszy główne wyzwanie jest takie samo: jak przetwarzać dużą liczbę operacji na plikach PDF w sposób niezawodny, wydajny i bez wyczerpania pamięci lub pozostawiania niedokończonej pracy, gdy coś pójdzie nie tak?
Architektura przetwarzania wsadowego IronPDF
Zanim przejdziemy do konkretnych operacji, warto zrozumieć, w jaki sposób IronPDF radzi sobie z równoczesnymi obciążeniami oraz jakie decyzje architektoniczne należy podjąć podczas tworzenia potoku przetwarzania wsadowego w oparciu o tę platformę.
Instalacja IronPDF
Zainstaluj IronPDF za pomocą NuGet:
Install-Package IronPdfInstall-Package IronPdfLub przy użyciu interfejsu CLI platformy .NET:
dotnet add package IronPdfdotnet add package IronPdfIronPDF obsługuje .NET Framework 4.6.2+, .NET Core, .NET 5 do .NET 10 oraz .NET Standard 2.0. Działa na systemach Windows, Linux, macOS oraz w kontenerach Docker, dzięki czemu nadaje się zarówno do lokalnych zadań wsadowych, jak i wdrożeń w chmurze.
W przypadku wsadowego przetwarzania produkcyjnego należy ustawić klucz licencyjny za pomocą License.LicenseKey podczas uruchamiania aplikacji przed rozpoczęciem jakichkolwiek operacji PDF. Dzięki temu każde wywołanie renderowania we wszystkich wątkach ma dostęp do pełnego zestawu funkcji bez znaków wodnych dla poszczególnych plików.
Kontrola współbieżności i bezpieczeństwo wątków
Silnik renderujący IronPDF oparty na Chromium jest bezpieczny dla wątków. Można tworzyć wiele instancji ChromePdfRenderer w różnych wątkach lub dzielić jedną instancję — IronPDF obsługuje wewnętrzną synchronizację. Oficjalna rekomendacja dla przetwarzania wsadowego to używanie wbudowanego Parallel.ForEach .NET, który automatycznie rozdziela pracę na wszystkie dostępne rdzenie CPU.
Niemniej jednak „bezpieczeństwo wątków" nie oznacza „używania nielimitowanej liczby wątków". Każda równoległa operacja renderowania PDF zużywa pamięć (silnik Chromium potrzebuje miejsca na analizowanie DOM, układowanie CSS i rastrowanie obrazków), a uruchamianie zbyt wielu równoległych operacji na systemie z ograniczonymi zasobami pamięci spowoduje pogorszenie wydajności lub wywołanie OutOfMemoryException. Odpowiedni poziom współbieżności zależy od sprzętu: 16-rdzeniowy serwer z 64 GB pamięci RAM z łatwością obsłuży 8–12 jednoczesnych renderowań; 4-rdzeniowa VM z 8 GB może być ograniczona do 2–4. Należy to kontrolować za pomocą ParallelOptions.MaxDegreeOfParallelism — ustawić w przybliżeniu na połowę dostępnych rdzeni CPU jako punkt wyjścia, a następnie dostosować na podstawie zaobserwowanego nacisku pamięci.
Zarządzanie pamięcią na dużą skalę
Zarządzanie pamięcią jest najważniejszą kwestią w przetwarzaniu plików PDF w trybie wsadowym. Każdy obiekt PdfDocument przechowuje całą binarną zawartość PDF w pamięci, a brak usunięcia tych obiektów powoduje, że pamięć będzie rosła liniowo wraz z liczbą przetworzonych plików.
Krytyczna zasada: zawsze należy używać instrukcji using lub wyraźnie wywoływać Dispose() na obiektach PdfDocument. PdfDocument IronPDF implementuje IDisposable, a brak usunięcia to najczęstsza przyczyna problemów z pamięcią w scenariuszach wsadowych. Każda iteracja pętli przetwarzania powinna utworzyć PdfDocument, wykonać swoje zadanie i usunąć — nigdy nie należy gromadzić PdfDocument w liście lub kolekcji, chyba że istnieją specyficzne powody i wystarczająco pamięci, aby temu sprostać.
Oprócz usuwania danych, rozważ następujące strategie zarządzania pamięcią dla dużych partii:
Przetwarzaj tekst fragmentami, zamiast ładować wszystko naraz. Jeśli trzeba przetworzyć 50 000 plików, nie należy wyliczać ich wszystkich na liście, a następnie iterować — przetwarzaj je partiami po 100 lub 500, pozwalając modułowi czyszczącemu pamięć odzyskać pamięć między partiami.
W przypadku bardzo dużych partii wymuś zbieranie śmieci między fragmentami. Chociaż ogólnie należy pozwolić, aby GC zarządzał sam sobą, przetwarzanie wsadowe to jeden z rzadkich scenariuszy, w których wywołanie GC.Collect() między granicami części może zapobiec narastaniu nacisku pamięci.
Monitoruj zużycie pamięci za pomocą GC.GetTotalMemory() lub metrów na poziomie procesu. Jeśli zużycie pamięci przekroczy próg (np. 80% dostępnej pamięci RAM), należy wstrzymać przetwarzanie, aby umożliwić GC nadrobienie zaległości.
Raportowanie postępów i rejestrowanie
Kiedy wykonanie zadania wsadowego trwa wiele godzin, wgląd w jego postępy nie jest opcjonalny — jest niezbędny. Należy co najmniej rejestrować rozpoczęcie i zakończenie przetwarzania każdego pliku, śledzić liczbę sukcesów/porażek oraz podawać szacowany pozostały czas. Należy używać Interlocked.Increment dla liczników bezpiecznych dla wątków podczas wykonywania operacji równoległych i rejestrować w regularnych odstępach czasu (co 50 lub 100 plików), zamiast przy każdym pojedynczym pliku, aby uniknąć przeciążenia wyjścia. Czas należy śledzić używając System.Diagnostics.Stopwatch i obliczać współczynnik plików na sekundę, aby podawać znaczący ETA.
W przypadku zadań wsadowych produkcyjnych warto rozważyć zapisywanie postępów w trwałej pamięci (baza danych, plik lub kolejka komunikatów), aby pulpity monitorujące mogły wyświetlać status w czasie rzeczywistym bez konieczności bezpośredniego łączenia się z procesem wsadowym.
Typowe operacje wsadowe
Mając już gotową podstawę architektury, przejdźmy do omówienia najczęstszych operacji wsadowych i ich implementacji w IronPDF.
Konwersja plików HTML do formatu PDF
Konwersja HTML do PDF jest najczęstszą operacją wsadową. Niezależnie od tego, czy generujesz faktury na podstawie szablonów, konwertujesz bibliotekę dokumentacji HTML do formatu PDF, czy renderujesz dynamiczne raporty z aplikacji internetowej, schemat działania jest ten sam: iteruj dane wejściowe, renderuj każdą z nich i zapisuj wynik.
Dane wejściowe (5 plików HTML)
INV-2026-001
INV-2026-002
INV-2026-003
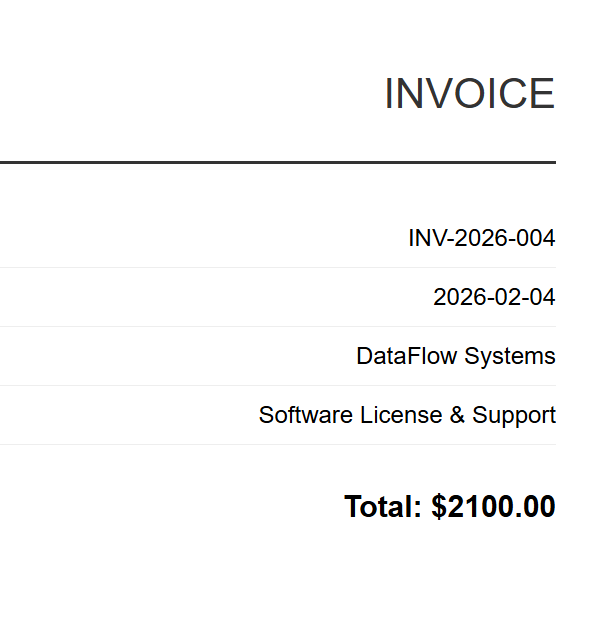
INV-2026-004
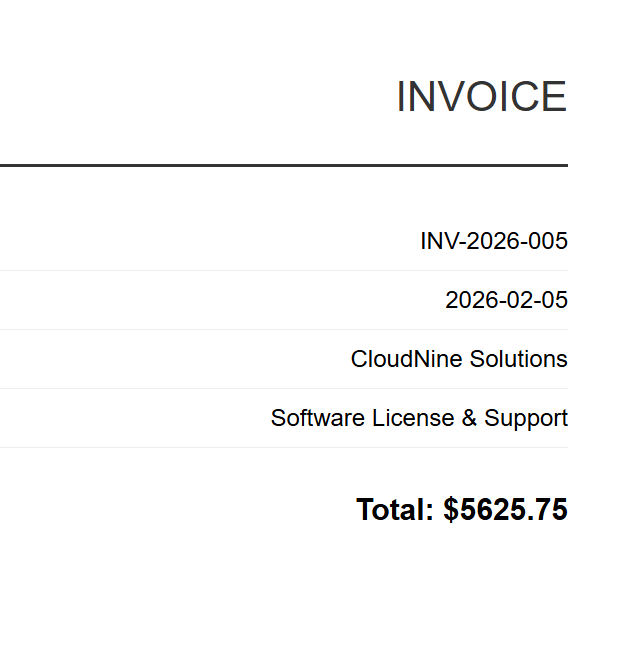
INV-2026-005
Implementacja używa ChromePdfRenderer z Parallel.ForEach do równoległego przetwarzania wszystkich plików HTML, kontrolując współbieżność za pomocą MaxDegreeOfParallelism, aby zrównoważyć przepustowość względem zużycia pamięci. Każdy plik jest renderowany za pomocą RenderHtmlFileAsPdf i zapisywany w folderze wyjściowym, z monitorowaniem postępu poprzez wątkowo bezpieczne liczniki Interlocked.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-html-to-pdf.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
using System.Threading;
// Configure paths
string inputFolder = "input/";
string outputFolder = "output/";
Directory.CreateDirectory(outputFolder);
string[] htmlFiles = Directory.GetFiles(inputFolder, "*.html");
Console.WriteLine($"Found {htmlFiles.Length} HTML files to convert");
// Create renderer instance (thread-safe, can be shared)
var renderer = new ChromePdfRenderer();
// Track progress
int processed = 0;
int failed = 0;
// Process in parallel with controlled concurrency
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(htmlFiles, options, htmlFile =>
{
try
{
string fileName = Path.GetFileNameWithoutExtension(htmlFile);
string outputPath = Path.Combine(outputFolder, $"{fileName}.pdf");
using var pdf = renderer.RenderHtmlFileAsPdf(htmlFile);
pdf.SaveAs(outputPath);
Interlocked.Increment(ref processed);
Console.WriteLine($"[OK] {fileName}.pdf");
}
catch (Exception ex)
{
Interlocked.Increment(ref failed);
Console.WriteLine($"[ERROR] {Path.GetFileName(htmlFile)}: {ex.Message}");
}
});
Console.WriteLine($"\nComplete: {processed} succeeded, {failed} failed");Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading.Tasks
Imports System.Threading
' Configure paths
Dim inputFolder As String = "input/"
Dim outputFolder As String = "output/"
Directory.CreateDirectory(outputFolder)
Dim htmlFiles As String() = Directory.GetFiles(inputFolder, "*.html")
Console.WriteLine($"Found {htmlFiles.Length} HTML files to convert")
' Create renderer instance (thread-safe, can be shared)
Dim renderer As New ChromePdfRenderer()
' Track progress
Dim processed As Integer = 0
Dim failed As Integer = 0
' Process in parallel with controlled concurrency
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(htmlFiles, options, Sub(htmlFile)
Try
Dim fileName As String = Path.GetFileNameWithoutExtension(htmlFile)
Dim outputPath As String = Path.Combine(outputFolder, $"{fileName}.pdf")
Using pdf = renderer.RenderHtmlFileAsPdf(htmlFile)
pdf.SaveAs(outputPath)
End Using
Interlocked.Increment(processed)
Console.WriteLine($"[OK] {fileName}.pdf")
Catch ex As Exception
Interlocked.Increment(failed)
Console.WriteLine($"[ERROR] {Path.GetFileName(htmlFile)}: {ex.Message}")
End Try
End Sub)
Console.WriteLine($"\nComplete: {processed} succeeded, {failed} failed")Wynik
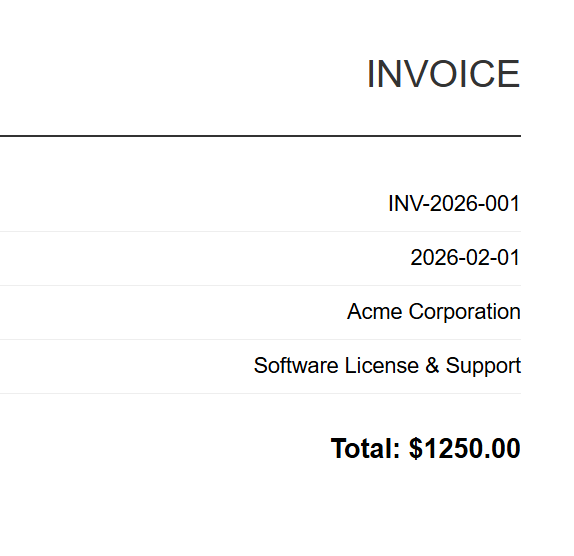
Każda faktura w formacie HTML jest renderowana do odpowiedniego pliku PDF. Powyżej znajduje się plik INV-2026-001.pdf — jeden z 5 wyników przetwarzania wsadowego.
W przypadku generowania opartego na szablonach (np. faktur, raportów) zazwyczaj przed renderowaniem dane są scalane z szablonem HTML. Podejście jest proste: należy załadować szablon HTML raz, użyć string.Replace, aby wprowadzić dane dla każdego rekordu (imię i nazwisko klienta, suma, daty) i przekazać załadowany HTML do RenderHtmlAsPdf wewnątrz równoległej pętli. IronPDF zapewnia również RenderHtmlAsPdfAsync dla scenariuszy, w których preferowane jest użycie async/await zamiast Parallel.ForEach — asynchroniczne wzorce omówione są dokładnie w późniejszej sekcji.
Zbiorcze łączenie plików PDF
Łączenie grup plików PDF w połączone dokumenty jest powszechne w procesach prawnych (łączenie dokumentów akt spraw), finansowych (łączenie miesięcznych zestawień w raporty kwartalne) oraz wydawniczych.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-merge.csusing IronPdf;
using System;
using System.IO;
using System.Linq;
using System.Collections.Generic;
string inputFolder = "documents/";
string outputFolder = "merged/";
Directory.CreateDirectory(outputFolder);
// Group PDFs by prefix (e.g., "invoice-2026-01-*.pdf" -> one merged file)
var pdfFiles = Directory.GetFiles(inputFolder, "*.pdf");
var groups = pdfFiles
.GroupBy(f => Path.GetFileName(f).Split('-').Take(3).Aggregate((a, b) => $"{a}-{b}"))
.Where(g => g.Count() > 1);
Console.WriteLine($"Found {groups.Count()} groups to merge");
foreach (var group in groups)
{
string groupName = group.Key;
var filesToMerge = group.OrderBy(f => f).ToList();
Console.WriteLine($"Merging {filesToMerge.Count} files into {groupName}.pdf");
try
{
// Load all PDFs for this group
var pdfDocs = new List<PdfDocument>();
foreach (string filePath in filesToMerge)
{
pdfDocs.Add(PdfDocument.FromFile(filePath));
}
// Merge all documents
using var merged = PdfDocument.Merge(pdfDocs);
merged.SaveAs(Path.Combine(outputFolder, $"{groupName}-merged.pdf"));
// Dispose source documents
foreach (var doc in pdfDocs)
{
doc.Dispose();
}
Console.WriteLine($" [OK] Created {groupName}-merged.pdf ({merged.PageCount} pages)");
}
catch (Exception ex)
{
Console.WriteLine($" [ERROR] {groupName}: {ex.Message}");
}
}
Console.WriteLine("\nMerge complete");Imports IronPdf
Imports System
Imports System.IO
Imports System.Linq
Imports System.Collections.Generic
Module Program
Sub Main()
Dim inputFolder As String = "documents/"
Dim outputFolder As String = "merged/"
Directory.CreateDirectory(outputFolder)
' Group PDFs by prefix (e.g., "invoice-2026-01-*.pdf" -> one merged file)
Dim pdfFiles = Directory.GetFiles(inputFolder, "*.pdf")
Dim groups = pdfFiles _
.GroupBy(Function(f) Path.GetFileName(f).Split("-"c).Take(3).Aggregate(Function(a, b) $"{a}-{b}")) _
.Where(Function(g) g.Count() > 1)
Console.WriteLine($"Found {groups.Count()} groups to merge")
For Each group In groups
Dim groupName As String = group.Key
Dim filesToMerge = group.OrderBy(Function(f) f).ToList()
Console.WriteLine($"Merging {filesToMerge.Count} files into {groupName}.pdf")
Try
' Load all PDFs for this group
Dim pdfDocs As New List(Of PdfDocument)()
For Each filePath As String In filesToMerge
pdfDocs.Add(PdfDocument.FromFile(filePath))
Next
' Merge all documents
Using merged = PdfDocument.Merge(pdfDocs)
merged.SaveAs(Path.Combine(outputFolder, $"{groupName}-merged.pdf"))
End Using
' Dispose source documents
For Each doc In pdfDocs
doc.Dispose()
Next
Console.WriteLine($" [OK] Created {groupName}-merged.pdf ({merged.PageCount} pages)")
Catch ex As Exception
Console.WriteLine($" [ERROR] {groupName}: {ex.Message}")
End Try
Next
Console.WriteLine(vbCrLf & "Merge complete")
End Sub
End ModulePrzy łączeniu dużej liczby plików należy zwracać uwagę na pamięć: metoda PdfDocument.Merge ładuje wszystkie dokumenty źródłowe do pamięci jednocześnie. Jeśli łączone są setki dużych plików PDF, warto rozważyć łączenie ich etapami — połączyć grupy po 10–20 plików w dokumenty pośrednie, a następnie połączyć te dokumenty pośrednie.
Dzielenie plików PDF partiami
Dzielenie wielostronicowych plików PDF na pojedyncze strony (lub zakresy stron) jest odwrotnością operacji łączenia. Często spotykane w przetwarzaniu korespondencji, gdzie zeskanowana partia dokumentów musi zostać podzielona na pojedyncze rekordy, oraz w procesach drukowania, gdzie dokumenty złożone muszą zostać rozdzielone.
Wejscie
Kod poniżej pokazuje, jak wyodrębniać poszczególne strony, korzystając z CopyPage w pętli równoległej, tworząc osobne pliki PDF dla każdej strony. Pomocnicza funkcja SplitByRange pokazuje, jak wyodrębnić zakres stron zamiast pojedynczych stron, co jest przydatne do dzielenia dużych dokumentów na mniejsze segmenty.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-split.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
string inputFolder = "multipage/";
string outputFolder = "split/";
Directory.CreateDirectory(outputFolder);
string[] pdfFiles = Directory.GetFiles(inputFolder, "*.pdf");
Console.WriteLine($"Found {pdfFiles.Length} PDFs to split");
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(pdfFiles, options, pdfFile =>
{
string baseName = Path.GetFileNameWithoutExtension(pdfFile);
try
{
using var pdf = PdfDocument.FromFile(pdfFile);
int pageCount = pdf.PageCount;
Console.WriteLine($"Splitting {baseName}.pdf ({pageCount} pages)");
// Extract each page as a separate PDF
for (int i = 0; i < pageCount; i++)
{
using var singlePage = pdf.CopyPage(i);
string outputPath = Path.Combine(outputFolder, $"{baseName}-page-{i + 1:D3}.pdf");
singlePage.SaveAs(outputPath);
}
Console.WriteLine($" [OK] Created {pageCount} files from {baseName}.pdf");
}
catch (Exception ex)
{
Console.WriteLine($" [ERROR] {baseName}: {ex.Message}");
}
});
// Alternative: Extract page ranges instead of individual pages
void SplitByRange(string inputFile, string outputFolder, int pagesPerChunk)
{
using var pdf = PdfDocument.FromFile(inputFile);
string baseName = Path.GetFileNameWithoutExtension(inputFile);
int totalPages = pdf.PageCount;
int chunkNumber = 1;
for (int startPage = 0; startPage < totalPages; startPage += pagesPerChunk)
{
int endPage = Math.Min(startPage + pagesPerChunk - 1, totalPages - 1);
using var chunk = pdf.CopyPages(startPage, endPage);
chunk.SaveAs(Path.Combine(outputFolder, $"{baseName}-chunk-{chunkNumber:D3}.pdf"));
chunkNumber++;
}
}
Console.WriteLine("\nSplit complete");Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading.Tasks
Module Program
Sub Main()
Dim inputFolder As String = "multipage/"
Dim outputFolder As String = "split/"
Directory.CreateDirectory(outputFolder)
Dim pdfFiles As String() = Directory.GetFiles(inputFolder, "*.pdf")
Console.WriteLine($"Found {pdfFiles.Length} PDFs to split")
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(pdfFiles, options, Sub(pdfFile)
Dim baseName As String = Path.GetFileNameWithoutExtension(pdfFile)
Try
Using pdf = PdfDocument.FromFile(pdfFile)
Dim pageCount As Integer = pdf.PageCount
Console.WriteLine($"Splitting {baseName}.pdf ({pageCount} pages)")
' Extract each page as a separate PDF
For i As Integer = 0 To pageCount - 1
Using singlePage = pdf.CopyPage(i)
Dim outputPath As String = Path.Combine(outputFolder, $"{baseName}-page-{i + 1:D3}.pdf")
singlePage.SaveAs(outputPath)
End Using
Next
Console.WriteLine($" [OK] Created {pageCount} files from {baseName}.pdf")
End Using
Catch ex As Exception
Console.WriteLine($" [ERROR] {baseName}: {ex.Message}")
End Try
End Sub)
' Alternative: Extract page ranges instead of individual pages
Sub SplitByRange(inputFile As String, outputFolder As String, pagesPerChunk As Integer)
Using pdf = PdfDocument.FromFile(inputFile)
Dim baseName As String = Path.GetFileNameWithoutExtension(inputFile)
Dim totalPages As Integer = pdf.PageCount
Dim chunkNumber As Integer = 1
For startPage As Integer = 0 To totalPages - 1 Step pagesPerChunk
Dim endPage As Integer = Math.Min(startPage + pagesPerChunk - 1, totalPages - 1)
Using chunk = pdf.CopyPages(startPage, endPage)
chunk.SaveAs(Path.Combine(outputFolder, $"{baseName}-chunk-{chunkNumber:D3}.pdf"))
chunkNumber += 1
End Using
Next
End Using
End Sub
Console.WriteLine(vbCrLf & "Split complete")
End Sub
End ModuleWynik
Strona 2 wyodrębniona jako samodzielny plik PDF (annual-report-page-2.pdf)
Metody CopyPage i CopyPages IronPDF tworzą nowe obiekty PdfDocument zawierające określone strony. Pamiętaj, aby po zapisaniu usunąć zarówno dokument źródłowy, jak i każdy wyodrębniony dokument strony.
Kompresja partii
Gdy koszty przechowywania mają znaczenie lub gdy trzeba przesyłać pliki PDF przez połączenia o ograniczonej przepustowości, kompresja partii plików może znacznie zmniejszyć zajmowaną przestrzeń archiwum. IronPDF zapewnia dwa podejścia do kompresji: CompressImages w celu zmniejszenia jakości/rozmiaru obrazu oraz CompressStructTree do usuwania metadanych strukturalnych. Nowsze API CompressAndSaveAs (wprowadzone w wersji 2025.12) zapewnia lepszą kompresję poprzez połączenie wielu technik optymalizacji.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-compression.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
using System.Threading;
string inputFolder = "originals/";
string outputFolder = "compressed/";
Directory.CreateDirectory(outputFolder);
string[] pdfFiles = Directory.GetFiles(inputFolder, "*.pdf");
Console.WriteLine($"Found {pdfFiles.Length} PDFs to compress");
long totalOriginalSize = 0;
long totalCompressedSize = 0;
int processed = 0;
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(pdfFiles, options, pdfFile =>
{
string fileName = Path.GetFileName(pdfFile);
string outputPath = Path.Combine(outputFolder, fileName);
try
{
long originalSize = new FileInfo(pdfFile).Length;
Interlocked.Add(ref totalOriginalSize, originalSize);
using var pdf = PdfDocument.FromFile(pdfFile);
// Apply compression with JPEG quality setting (0-100, lower = more compression)
pdf.CompressAndSaveAs(outputPath, 60);
long compressedSize = new FileInfo(outputPath).Length;
Interlocked.Add(ref totalCompressedSize, compressedSize);
Interlocked.Increment(ref processed);
double reduction = (1 - (double)compressedSize / originalSize) * 100;
Console.WriteLine($"[OK] {fileName}: {originalSize / 1024}KB → {compressedSize / 1024}KB ({reduction:F1}% reduction)");
}
catch (Exception ex)
{
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
});
double totalReduction = (1 - (double)totalCompressedSize / totalOriginalSize) * 100;
Console.WriteLine($"\nCompression complete:");
Console.WriteLine($" Files processed: {processed}");
Console.WriteLine($" Total original: {totalOriginalSize / 1024 / 1024}MB");
Console.WriteLine($" Total compressed: {totalCompressedSize / 1024 / 1024}MB");
Console.WriteLine($" Overall reduction: {totalReduction:F1}%");Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading.Tasks
Imports System.Threading
Module Program
Sub Main()
Dim inputFolder As String = "originals/"
Dim outputFolder As String = "compressed/"
Directory.CreateDirectory(outputFolder)
Dim pdfFiles As String() = Directory.GetFiles(inputFolder, "*.pdf")
Console.WriteLine($"Found {pdfFiles.Length} PDFs to compress")
Dim totalOriginalSize As Long = 0
Dim totalCompressedSize As Long = 0
Dim processed As Integer = 0
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(pdfFiles, options, Sub(pdfFile)
Dim fileName As String = Path.GetFileName(pdfFile)
Dim outputPath As String = Path.Combine(outputFolder, fileName)
Try
Dim originalSize As Long = New FileInfo(pdfFile).Length
Interlocked.Add(totalOriginalSize, originalSize)
Using pdf = PdfDocument.FromFile(pdfFile)
' Apply compression with JPEG quality setting (0-100, lower = more compression)
pdf.CompressAndSaveAs(outputPath, 60)
End Using
Dim compressedSize As Long = New FileInfo(outputPath).Length
Interlocked.Add(totalCompressedSize, compressedSize)
Interlocked.Increment(processed)
Dim reduction As Double = (1 - CDbl(compressedSize) / originalSize) * 100
Console.WriteLine($"[OK] {fileName}: {originalSize \ 1024}KB → {compressedSize \ 1024}KB ({reduction:F1}% reduction)")
Catch ex As Exception
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End Sub)
Dim totalReduction As Double = (1 - CDbl(totalCompressedSize) / totalOriginalSize) * 100
Console.WriteLine(vbCrLf & "Compression complete:")
Console.WriteLine($" Files processed: {processed}")
Console.WriteLine($" Total original: {totalOriginalSize \ 1024 \ 1024}MB")
Console.WriteLine($" Total compressed: {totalCompressedSize \ 1024 \ 1024}MB")
Console.WriteLine($" Overall reduction: {totalReduction:F1}%")
End Sub
End ModuleKilka rzeczy, o których należy pamiętać w związku z kompresją: ustawienia jakości JPEG poniżej 60 spowodują widoczne artefakty na większości obrazów. Opcja ShrinkImage może powodować zniekształcenia w niektórych konfiguracjach — należy przetestować z reprezentatywnymi próbkami przed uruchomieniem pełnej partii. Usunięcie drzewa strukturalnego (CompressStructTree) wpłynie na wybór i wyszukiwanie tekstu w skompresowanych PDF-ach, więc tej opcji należy używać tylko wtedy, gdy te możliwości nie są potrzebne.
Konwersja formatów wsadowych (PDF/A, PDF/UA)
Konwersja istniejącego archiwum do formatu zgodnego ze standardami — PDF/A do długoterminowej archiwizacji lub PDF/UA dla zapewnienia dostępności — jest jedną z najbardziej wartościowych operacji wsadowych. IronPDF obsługuje pełen zakres wersji PDF/A (w tym PDF/A-4, dodany w wersji 2025.11) oraz zgodność z PDF/UA (w tym PDF/UA-2, dodany w wersji 2025.12).
Wejscie
Przykład ładuje każdy PDF za pomocą PdfDocument.FromFile, a następnie konwertuje go do PDF/A-3b, korzystając z SaveAsPdfA z parametrem PdfAVersions.PdfA3b. Alternatywna funkcja ConvertToPdfUA demonstruje konwersję zgodności dostępności za pomocą SaveAsPdfUA, chociaż PDF/UA wymaga dokumentów źródłowych z odpowiednim etykietowaniem strukturalnym.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-format-conversion.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
using System.Threading;
string inputFolder = "originals/";
string outputFolder = "pdfa-archive/";
Directory.CreateDirectory(outputFolder);
string[] pdfFiles = Directory.GetFiles(inputFolder, "*.pdf");
Console.WriteLine($"Found {pdfFiles.Length} PDFs to convert to PDF/A-3b");
int converted = 0;
int failed = 0;
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(pdfFiles, options, pdfFile =>
{
string fileName = Path.GetFileName(pdfFile);
string outputPath = Path.Combine(outputFolder, fileName);
try
{
using var pdf = PdfDocument.FromFile(pdfFile);
// Convert to PDF/A-3b for long-term archival
pdf.SaveAsPdfA(outputPath, PdfAVersions.PdfA3b);
Interlocked.Increment(ref converted);
Console.WriteLine($"[OK] {fileName} → PDF/A-3b");
}
catch (Exception ex)
{
Interlocked.Increment(ref failed);
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
});
Console.WriteLine($"\nConversion complete: {converted} succeeded, {failed} failed");
// Alternative: Convert to PDF/UA for accessibility compliance
void ConvertToPdfUA(string inputFolder, string outputFolder)
{
Directory.CreateDirectory(outputFolder);
string[] files = Directory.GetFiles(inputFolder, "*.pdf");
Parallel.ForEach(files, pdfFile =>
{
string fileName = Path.GetFileName(pdfFile);
try
{
using var pdf = PdfDocument.FromFile(pdfFile);
// PDF/UA requires proper tagging - ensure source is well-structured
pdf.SaveAsPdfUA(Path.Combine(outputFolder, fileName));
Console.WriteLine($"[OK] {fileName} → PDF/UA");
}
catch (Exception ex)
{
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
});
}Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading.Tasks
Imports System.Threading
Module Program
Sub Main()
Dim inputFolder As String = "originals/"
Dim outputFolder As String = "pdfa-archive/"
Directory.CreateDirectory(outputFolder)
Dim pdfFiles As String() = Directory.GetFiles(inputFolder, "*.pdf")
Console.WriteLine($"Found {pdfFiles.Length} PDFs to convert to PDF/A-3b")
Dim converted As Integer = 0
Dim failed As Integer = 0
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(pdfFiles, options, Sub(pdfFile)
Dim fileName As String = Path.GetFileName(pdfFile)
Dim outputPath As String = Path.Combine(outputFolder, fileName)
Try
Using pdf = PdfDocument.FromFile(pdfFile)
' Convert to PDF/A-3b for long-term archival
pdf.SaveAsPdfA(outputPath, PdfAVersions.PdfA3b)
Interlocked.Increment(converted)
Console.WriteLine($"[OK] {fileName} → PDF/A-3b")
End Using
Catch ex As Exception
Interlocked.Increment(failed)
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End Sub)
Console.WriteLine($"{vbCrLf}Conversion complete: {converted} succeeded, {failed} failed")
End Sub
' Alternative: Convert to PDF/UA for accessibility compliance
Sub ConvertToPdfUA(inputFolder As String, outputFolder As String)
Directory.CreateDirectory(outputFolder)
Dim files As String() = Directory.GetFiles(inputFolder, "*.pdf")
Parallel.ForEach(files, Sub(pdfFile)
Dim fileName As String = Path.GetFileName(pdfFile)
Try
Using pdf = PdfDocument.FromFile(pdfFile)
' PDF/UA requires proper tagging - ensure source is well-structured
pdf.SaveAsPdfUA(Path.Combine(outputFolder, fileName))
Console.WriteLine($"[OK] {fileName} → PDF/UA")
End Using
Catch ex As Exception
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End Sub)
End Sub
End ModuleWynik
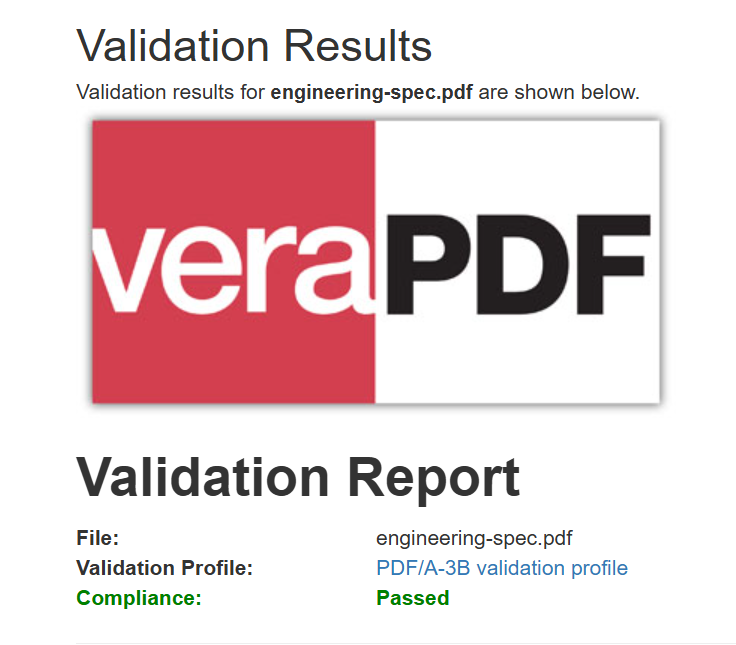
Wynikowy plik PDF jest identyczny pod względem wyglądu (bajt po bajcie), ale zawiera teraz metadane zgodności z formatem PDF/A-3b dla systemów archiwizacji.
Konwersja formatów jest szczególnie ważna w przypadku projektów związanych z dostosowaniem do wymogów zgodności, w których organizacja odkrywa, że jej istniejące archiwum nie spełnia norm regulacyjnych. Schemat przetwarzania wsadowego jest prosty, ale etap walidacji ma kluczowe znaczenie — przed uznaniem zadania za zakończone należy zawsze sprawdzić, czy każdy przekonwertowany plik faktycznie przeszedł kontrolę zgodności. Szczegółowo omawiamy walidację w sekcji dotyczącej odporności poniżej.
Budowanie odpornych potoków przetwarzania wsadowego
Potok przetwarzania wsadowego, który działa idealnie na 100 plikach, a zawiesza się przy pliku nr 4327 z 50 000, nie jest użyteczny. Odporność — czyli zdolność do płynnego radzenia sobie z błędami, ponawiania prób w przypadku przejściowych awarii i wznawiania pracy po awariach — to cecha, która odróżnia potok na poziomie produkcyjnym od prototypu.
Obsługa błędów i pomijanie w przypadku niepowodzenia
Najbardziej podstawowym wzorcem odporności jest pomijanie w przypadku niepowodzenia: jeśli przetwarzanie pojedynczego pliku zakończy się niepowodzeniem, należy zarejestrować błąd i przejść do następnego pliku, zamiast przerywać całą partię. To brzmi oczywisto, ale gdy korzysta się z Parallel.ForEach — nieobsługiwany wyjątek w dowolnym równoległym zadaniu zostanie przeniesiony jako AggregateException i przerwie pętlę.
Następujący przykład pokazuje jednocześnie logikę pominięcia błędów i ponowienia — owijanie każdego pliku w try-catch dla łaskawej obsługi błędów, z wewnętrzną pętlą ponawiania z eksponencjalnym odroczeniem dla przelotnych wyjątków jak IOException i OutOfMemoryException.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-error-handling-retry.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
using System.Threading;
using System.Collections.Concurrent;
string inputFolder = "input/";
string outputFolder = "output/";
string errorLogPath = "error-log.txt";
Directory.CreateDirectory(outputFolder);
string[] htmlFiles = Directory.GetFiles(inputFolder, "*.html");
var renderer = new ChromePdfRenderer();
var errorLog = new ConcurrentBag<string>();
int processed = 0;
int failed = 0;
int retried = 0;
const int maxRetries = 3;
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(htmlFiles, options, htmlFile =>
{
string fileName = Path.GetFileNameWithoutExtension(htmlFile);
string outputPath = Path.Combine(outputFolder, $"{fileName}.pdf");
int attempt = 0;
bool success = false;
while (attempt < maxRetries && !success)
{
attempt++;
try
{
using var pdf = renderer.RenderHtmlFileAsPdf(htmlFile);
pdf.SaveAs(outputPath);
success = true;
Interlocked.Increment(ref processed);
if (attempt > 1)
{
Interlocked.Increment(ref retried);
Console.WriteLine($"[OK] {fileName}.pdf (succeeded on attempt {attempt})");
}
else
{
Console.WriteLine($"[OK] {fileName}.pdf");
}
}
catch (Exception ex) when (IsTransientException(ex) && attempt < maxRetries)
{
// Transient error - wait and retry with exponential backoff
int delayMs = (int)Math.Pow(2, attempt) * 500;
Console.WriteLine($"[RETRY] {fileName}: {ex.Message} (attempt {attempt}, waiting {delayMs}ms)");
Thread.Sleep(delayMs);
}
catch (Exception ex)
{
// Non-transient error or max retries exceeded
Interlocked.Increment(ref failed);
string errorMessage = $"{DateTime.Now:yyyy-MM-dd HH:mm:ss} | {fileName} | {ex.GetType().Name} | {ex.Message}";
errorLog.Add(errorMessage);
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
}
});
// Write error log
if (errorLog.Count > 0)
{
File.WriteAllLines(errorLogPath, errorLog);
}
Console.WriteLine($"\nBatch complete:");
Console.WriteLine($" Processed: {processed}");
Console.WriteLine($" Failed: {failed}");
Console.WriteLine($" Retried: {retried}");
if (failed > 0)
{
Console.WriteLine($" Error log: {errorLogPath}");
}
// Helper to identify transient exceptions worth retrying
bool IsTransientException(Exception ex)
{
return ex is IOException ||
ex is OutOfMemoryException ||
ex.Message.Contains("timeout", StringComparison.OrdinalIgnoreCase) ||
ex.Message.Contains("locked", StringComparison.OrdinalIgnoreCase);
}Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading
Imports System.Collections.Concurrent
Module Program
Sub Main()
Dim inputFolder As String = "input/"
Dim outputFolder As String = "output/"
Dim errorLogPath As String = "error-log.txt"
Directory.CreateDirectory(outputFolder)
Dim htmlFiles As String() = Directory.GetFiles(inputFolder, "*.html")
Dim renderer As New ChromePdfRenderer()
Dim errorLog As New ConcurrentBag(Of String)()
Dim processed As Integer = 0
Dim failed As Integer = 0
Dim retried As Integer = 0
Const maxRetries As Integer = 3
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(htmlFiles, options, Sub(htmlFile)
Dim fileName As String = Path.GetFileNameWithoutExtension(htmlFile)
Dim outputPath As String = Path.Combine(outputFolder, $"{fileName}.pdf")
Dim attempt As Integer = 0
Dim success As Boolean = False
While attempt < maxRetries AndAlso Not success
attempt += 1
Try
Using pdf = renderer.RenderHtmlFileAsPdf(htmlFile)
pdf.SaveAs(outputPath)
success = True
Interlocked.Increment(processed)
If attempt > 1 Then
Interlocked.Increment(retried)
Console.WriteLine($"[OK] {fileName}.pdf (succeeded on attempt {attempt})")
Else
Console.WriteLine($"[OK] {fileName}.pdf")
End If
End Using
Catch ex As Exception When IsTransientException(ex) AndAlso attempt < maxRetries
' Transient error - wait and retry with exponential backoff
Dim delayMs As Integer = CInt(Math.Pow(2, attempt)) * 500
Console.WriteLine($"[RETRY] {fileName}: {ex.Message} (attempt {attempt}, waiting {delayMs}ms)")
Thread.Sleep(delayMs)
Catch ex As Exception
' Non-transient error or max retries exceeded
Interlocked.Increment(failed)
Dim errorMessage As String = $"{DateTime.Now:yyyy-MM-dd HH:mm:ss} | {fileName} | {ex.GetType().Name} | {ex.Message}"
errorLog.Add(errorMessage)
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End While
End Sub)
' Write error log
If errorLog.Count > 0 Then
File.WriteAllLines(errorLogPath, errorLog)
End If
Console.WriteLine($"{vbCrLf}Batch complete:")
Console.WriteLine($" Processed: {processed}")
Console.WriteLine($" Failed: {failed}")
Console.WriteLine($" Retried: {retried}")
If failed > 0 Then
Console.WriteLine($" Error log: {errorLogPath}")
End If
End Sub
' Helper to identify transient exceptions worth retrying
Function IsTransientException(ex As Exception) As Boolean
Return TypeOf ex Is IOException OrElse
TypeOf ex Is OutOfMemoryException OrElse
ex.Message.Contains("timeout", StringComparison.OrdinalIgnoreCase) OrElse
ex.Message.Contains("locked", StringComparison.OrdinalIgnoreCase)
End Function
End ModulePo zakończeniu przetwarzania partii przejrzyj dziennik błędów, aby dowiedzieć się, które pliki nie zostały przetworzone i dlaczego. Typowe przyczyny niepowodzeń to uszkodzone pliki źródłowe, pliki PDF chronione hasłem, funkcje nieobsługiwane w treści źródłowej oraz brak pamięci w przypadku bardzo dużych dokumentów.
Logika ponownej próby w przypadku przejściowych błędów
Niektóre błędy są przejściowe — po ponownej próbie operacja zakończy się powodzeniem. Obejmują one konflikty w systemie plików (inny proces zablokował plik), tymczasowe obciążenie pamięci (moduł GC jeszcze nie nadążył) oraz przekroczenia limitów czasu sieci podczas ładowania zasobów zewnętrznych w treści HTML. Powyższy przykład kodu obsługuje te operacje za pomocą algorytmu wykładniczego cofania — zaczynając od krótkiego opóźnienia i podwajając je przy każdej kolejnej próbie, z ograniczeniem do maksymalnej liczby prób (zazwyczaj 3).
Kluczowe znaczenie ma rozróżnienie między błędami, które można ponowić, a tymi, których nie można ponowić. Wyjątek IOException (plik zablokowany) lub OutOfMemoryException (tymczasowe przeciążenie) jest wart ponawiania. Wyjątek ArgumentException (nieprawidłowe wejście) lub stały błąd renderowania nie jest — ponawianie nie pomoże i tracisz czas oraz zasoby.
Punkty kontrolne umożliwiające wznowienie pracy po awarii
Gdy zadanie wsadowe przetwarza 50 000 plików w ciągu kilku godzin, awaria przy pliku nr 35 000 nie powinna oznaczać konieczności rozpoczynania od początku. Funkcja checkpointingu — rejestrowania plików, które zostały pomyślnie przetworzone — pozwala wznowić pracę od miejsca, w którym została przerwana.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-checkpointing.csusing IronPdf;
using System;
using System.IO;
using System.Linq;
using System.Threading.Tasks;
using System.Threading;
using System.Collections.Generic;
string inputFolder = "input/";
string outputFolder = "output/";
string checkpointPath = "checkpoint.txt";
string errorLogPath = "errors.txt";
Directory.CreateDirectory(outputFolder);
// Load checkpoint - files already processed successfully
var completedFiles = new HashSet<string>();
if (File.Exists(checkpointPath))
{
completedFiles = new HashSet<string>(File.ReadAllLines(checkpointPath));
Console.WriteLine($"Resuming from checkpoint: {completedFiles.Count} files already processed");
}
// Get files to process (excluding already completed)
string[] allFiles = Directory.GetFiles(inputFolder, "*.html");
string[] filesToProcess = allFiles
.Where(f => !completedFiles.Contains(Path.GetFileName(f)))
.ToArray();
Console.WriteLine($"Files to process: {filesToProcess.Length} (skipping {completedFiles.Count} already done)");
var renderer = new ChromePdfRenderer();
var checkpointLock = new object();
int processed = 0;
int failed = 0;
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(filesToProcess, options, htmlFile =>
{
string fileName = Path.GetFileName(htmlFile);
string baseName = Path.GetFileNameWithoutExtension(htmlFile);
string outputPath = Path.Combine(outputFolder, $"{baseName}.pdf");
try
{
using var pdf = renderer.RenderHtmlFileAsPdf(htmlFile);
pdf.SaveAs(outputPath);
// Record success in checkpoint (thread-safe)
lock (checkpointLock)
{
File.AppendAllText(checkpointPath, fileName + Environment.NewLine);
}
Interlocked.Increment(ref processed);
Console.WriteLine($"[OK] {baseName}.pdf");
}
catch (Exception ex)
{
Interlocked.Increment(ref failed);
// Log error for review
lock (checkpointLock)
{
File.AppendAllText(errorLogPath,
$"{DateTime.Now:yyyy-MM-dd HH:mm:ss} | {fileName} | {ex.Message}{Environment.NewLine}");
}
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
});
Console.WriteLine($"\nBatch complete:");
Console.WriteLine($" Newly processed: {processed}");
Console.WriteLine($" Failed: {failed}");
Console.WriteLine($" Total completed: {completedFiles.Count + processed}");
Console.WriteLine($" Checkpoint saved to: {checkpointPath}");Imports IronPdf
Imports System
Imports System.IO
Imports System.Linq
Imports System.Threading.Tasks
Imports System.Threading
Imports System.Collections.Generic
Module Program
Sub Main()
Dim inputFolder As String = "input/"
Dim outputFolder As String = "output/"
Dim checkpointPath As String = "checkpoint.txt"
Dim errorLogPath As String = "errors.txt"
Directory.CreateDirectory(outputFolder)
' Load checkpoint - files already processed successfully
Dim completedFiles As New HashSet(Of String)()
If File.Exists(checkpointPath) Then
completedFiles = New HashSet(Of String)(File.ReadAllLines(checkpointPath))
Console.WriteLine($"Resuming from checkpoint: {completedFiles.Count} files already processed")
End If
' Get files to process (excluding already completed)
Dim allFiles As String() = Directory.GetFiles(inputFolder, "*.html")
Dim filesToProcess As String() = allFiles _
.Where(Function(f) Not completedFiles.Contains(Path.GetFileName(f))) _
.ToArray()
Console.WriteLine($"Files to process: {filesToProcess.Length} (skipping {completedFiles.Count} already done)")
Dim renderer As New ChromePdfRenderer()
Dim checkpointLock As New Object()
Dim processed As Integer = 0
Dim failed As Integer = 0
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(filesToProcess, options, Sub(htmlFile)
Dim fileName As String = Path.GetFileName(htmlFile)
Dim baseName As String = Path.GetFileNameWithoutExtension(htmlFile)
Dim outputPath As String = Path.Combine(outputFolder, $"{baseName}.pdf")
Try
Using pdf = renderer.RenderHtmlFileAsPdf(htmlFile)
pdf.SaveAs(outputPath)
End Using
' Record success in checkpoint (thread-safe)
SyncLock checkpointLock
File.AppendAllText(checkpointPath, fileName & Environment.NewLine)
End SyncLock
Interlocked.Increment(processed)
Console.WriteLine($"[OK] {baseName}.pdf")
Catch ex As Exception
Interlocked.Increment(failed)
' Log error for review
SyncLock checkpointLock
File.AppendAllText(errorLogPath,
$"{DateTime.Now:yyyy-MM-dd HH:mm:ss} | {fileName} | {ex.Message}{Environment.NewLine}")
End SyncLock
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End Sub)
Console.WriteLine(vbCrLf & "Batch complete:")
Console.WriteLine($" Newly processed: {processed}")
Console.WriteLine($" Failed: {failed}")
Console.WriteLine($" Total completed: {completedFiles.Count + processed}")
Console.WriteLine($" Checkpoint saved to: {checkpointPath}")
End Sub
End ModulePlik kontrolny służy jako trwały zapis wykonanej pracy. Po uruchomieniu potoku odczytuje on plik punktu kontrolnego i pomija wszystkie pliki, które zostały już pomyślnie przetworzone. Po zakończeniu przetwarzania pliku jego ścieżka jest dołączana do pliku punktu kontrolnego. To podejście jest proste, oparte na plikach i nie wymaga żadnych zewnętrznych zależności.
W bardziej złożonych scenariuszach warto rozważyć użycie tabeli bazy danych lub pamięci podręcznej rozproszonej (takiej jak Redis) jako magazynu punktów kontrolnych, zwłaszcza jeśli wiele procesów przetwarza pliki równolegle na różnych maszynach.
Weryfikacja przed i po przetworzeniu
Walidacja stanowi podstawę niezawodnego procesu. Walidacja przed przetwarzaniem pozwala wychwycić problematyczne dane wejściowe, zanim spowodują one stratę czasu przetwarzania; walidacja po przetwarzaniu gwarantuje, że wynik spełnia wymagania dotyczące jakości i zgodności.
Wejscie
Implementacja ta owija pętlę przetwarzania przy użyciu zarówno pomocniczych funkcji PreValidate, jak i PostValidate. Wstępna walidacja sprawdza rozmiar pliku, typ zawartości i podstawową strukturę HTML przed przetworzeniem. Weryfikacja końcowa sprawdza, czy plik PDF ma prawidłową liczbę stron i rozsądny rozmiar, przenosząc zatwierdzone pliki do osobnego folderu, a te z błędami do folderu odrzuconych do ręcznej weryfikacji.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-validation.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
using System.Threading;
using System.Collections.Concurrent;
string inputFolder = "input/";
string outputFolder = "output/";
string validatedFolder = "validated/";
string rejectedFolder = "rejected/";
Directory.CreateDirectory(outputFolder);
Directory.CreateDirectory(validatedFolder);
Directory.CreateDirectory(rejectedFolder);
string[] inputFiles = Directory.GetFiles(inputFolder, "*.html");
var renderer = new ChromePdfRenderer();
int preValidationFailed = 0;
int processingFailed = 0;
int postValidationFailed = 0;
int succeeded = 0;
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(inputFiles, options, inputFile =>
{
string fileName = Path.GetFileNameWithoutExtension(inputFile);
string outputPath = Path.Combine(outputFolder, $"{fileName}.pdf");
// Pre-validation: Check input file
if (!PreValidate(inputFile))
{
Interlocked.Increment(ref preValidationFailed);
Console.WriteLine($"[SKIP] {fileName}: Failed pre-validation");
return;
}
try
{
// Process
using var pdf = renderer.RenderHtmlFileAsPdf(inputFile);
pdf.SaveAs(outputPath);
// Post-validation: Check output file
if (PostValidate(outputPath))
{
// Move to validated folder
string validatedPath = Path.Combine(validatedFolder, $"{fileName}.pdf");
File.Move(outputPath, validatedPath, overwrite: true);
Interlocked.Increment(ref succeeded);
Console.WriteLine($"[OK] {fileName}.pdf (validated)");
}
else
{
// Move to rejected folder for manual review
string rejectedPath = Path.Combine(rejectedFolder, $"{fileName}.pdf");
File.Move(outputPath, rejectedPath, overwrite: true);
Interlocked.Increment(ref postValidationFailed);
Console.WriteLine($"[REJECT] {fileName}.pdf: Failed post-validation");
}
}
catch (Exception ex)
{
Interlocked.Increment(ref processingFailed);
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
});
Console.WriteLine($"\nValidation summary:");
Console.WriteLine($" Succeeded: {succeeded}");
Console.WriteLine($" Pre-validation failed: {preValidationFailed}");
Console.WriteLine($" Processing failed: {processingFailed}");
Console.WriteLine($" Post-validation failed: {postValidationFailed}");
// Pre-validation: Quick checks on input file
bool PreValidate(string filePath)
{
try
{
var fileInfo = new FileInfo(filePath);
// Check file exists and is readable
if (!fileInfo.Exists) return false;
// Check file is not empty
if (fileInfo.Length == 0) return false;
// Check file is not too large (e.g., 50MB limit)
if (fileInfo.Length > 50 * 1024 * 1024) return false;
// Quick content check - must be valid HTML
string content = File.ReadAllText(filePath);
if (string.IsNullOrWhiteSpace(content)) return false;
if (!content.Contains("<html", StringComparison.OrdinalIgnoreCase) &&
!content.Contains("<!DOCTYPE", StringComparison.OrdinalIgnoreCase))
{
return false;
}
return true;
}
catch
{
return false;
}
}
// Post-validation: Verify output PDF meets requirements
bool PostValidate(string pdfPath)
{
try
{
using var pdf = PdfDocument.FromFile(pdfPath);
// Check PDF has at least one page
if (pdf.PageCount < 1) return false;
// Check file size is reasonable (not just header, not corrupted)
var fileInfo = new FileInfo(pdfPath);
if (fileInfo.Length < 1024) return false;
return true;
}
catch
{
return false;
}
}Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading.Tasks
Imports System.Threading
Imports System.Collections.Concurrent
Module Program
Sub Main()
Dim inputFolder As String = "input/"
Dim outputFolder As String = "output/"
Dim validatedFolder As String = "validated/"
Dim rejectedFolder As String = "rejected/"
Directory.CreateDirectory(outputFolder)
Directory.CreateDirectory(validatedFolder)
Directory.CreateDirectory(rejectedFolder)
Dim inputFiles As String() = Directory.GetFiles(inputFolder, "*.html")
Dim renderer As New ChromePdfRenderer()
Dim preValidationFailed As Integer = 0
Dim processingFailed As Integer = 0
Dim postValidationFailed As Integer = 0
Dim succeeded As Integer = 0
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(inputFiles, options, Sub(inputFile)
Dim fileName As String = Path.GetFileNameWithoutExtension(inputFile)
Dim outputPath As String = Path.Combine(outputFolder, $"{fileName}.pdf")
' Pre-validation: Check input file
If Not PreValidate(inputFile) Then
Interlocked.Increment(preValidationFailed)
Console.WriteLine($"[SKIP] {fileName}: Failed pre-validation")
Return
End If
Try
' Process
Using pdf = renderer.RenderHtmlFileAsPdf(inputFile)
pdf.SaveAs(outputPath)
' Post-validation: Check output file
If PostValidate(outputPath) Then
' Move to validated folder
Dim validatedPath As String = Path.Combine(validatedFolder, $"{fileName}.pdf")
File.Move(outputPath, validatedPath, overwrite:=True)
Interlocked.Increment(succeeded)
Console.WriteLine($"[OK] {fileName}.pdf (validated)")
Else
' Move to rejected folder for manual review
Dim rejectedPath As String = Path.Combine(rejectedFolder, $"{fileName}.pdf")
File.Move(outputPath, rejectedPath, overwrite:=True)
Interlocked.Increment(postValidationFailed)
Console.WriteLine($"[REJECT] {fileName}.pdf: Failed post-validation")
End If
End Using
Catch ex As Exception
Interlocked.Increment(processingFailed)
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End Sub)
Console.WriteLine(vbCrLf & "Validation summary:")
Console.WriteLine($" Succeeded: {succeeded}")
Console.WriteLine($" Pre-validation failed: {preValidationFailed}")
Console.WriteLine($" Processing failed: {processingFailed}")
Console.WriteLine($" Post-validation failed: {postValidationFailed}")
End Sub
' Pre-validation: Quick checks on input file
Function PreValidate(filePath As String) As Boolean
Try
Dim fileInfo As New FileInfo(filePath)
' Check file exists and is readable
If Not fileInfo.Exists Then Return False
' Check file is not empty
If fileInfo.Length = 0 Then Return False
' Check file is not too large (e.g., 50MB limit)
If fileInfo.Length > 50 * 1024 * 1024 Then Return False
' Quick content check - must be valid HTML
Dim content As String = File.ReadAllText(filePath)
If String.IsNullOrWhiteSpace(content) Then Return False
If Not content.Contains("<html", StringComparison.OrdinalIgnoreCase) AndAlso
Not content.Contains("<!DOCTYPE", StringComparison.OrdinalIgnoreCase) Then
Return False
End If
Return True
Catch
Return False
End Try
End Function
' Post-validation: Verify output PDF meets requirements
Function PostValidate(pdfPath As String) As Boolean
Try
Using pdf = PdfDocument.FromFile(pdfPath)
' Check PDF has at least one page
If pdf.PageCount < 1 Then Return False
' Check file size is reasonable (not just header, not corrupted)
Dim fileInfo As New FileInfo(pdfPath)
If fileInfo.Length < 1024 Then Return False
Return True
End Using
Catch
Return False
End Try
End Function
End ModuleWynik
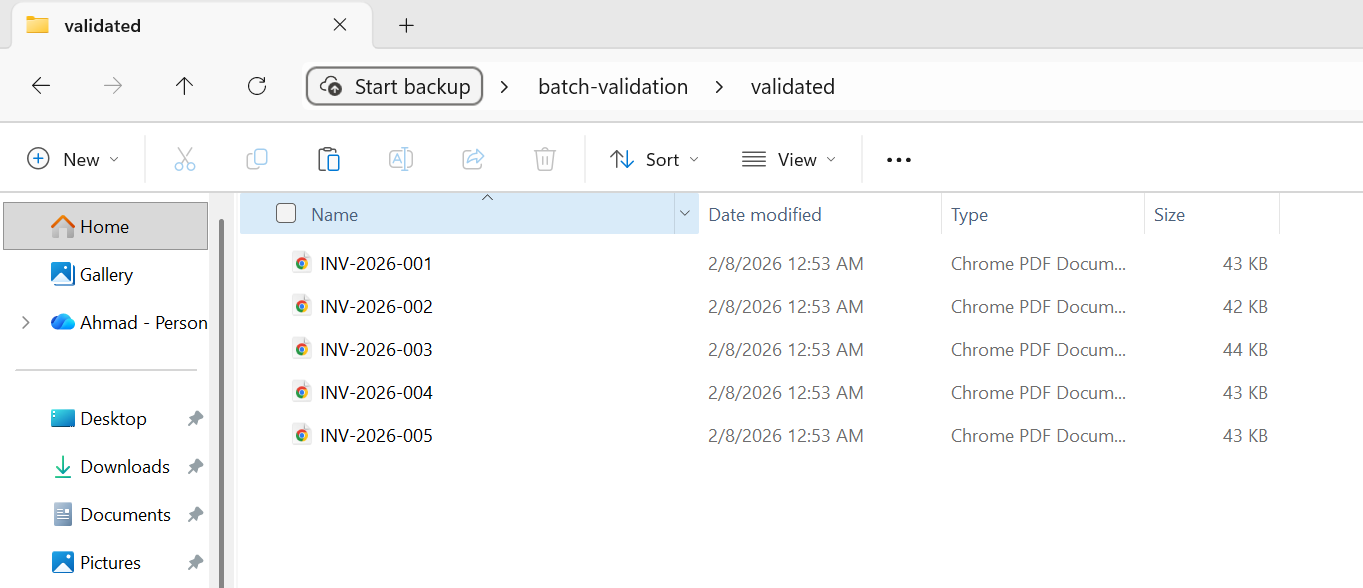
Wszystkie 5 plików przeszło walidację i zostało przeniesionych do folderu "validated".
Walidacja przed przetwarzaniem powinna przebiegać szybko — sprawdzasz tylko na obecność ewidentnie błędnych danych wejściowych, a nie przeprowadzasz pełnego przetwarzania. Walidacja po przetworzeniu może być bardziej szczegółowa, zwłaszcza w przypadku konwersji zgodnościowych, gdzie wynik musi spełniać określone standardy (PDF/A, PDF/UA). Każdy plik, który nie przejdzie walidacji po przetworzeniu, powinien zostać oznaczony do ręcznej weryfikacji, a nie akceptowany bez komentarza.
Wzorce przetwarzania asynchronicznego i równoległego
IronPDF obsługuje zarówno Parallel.ForEach (równoległość w oparciu o wątki), jak i async/await (asynchroniczne operacje I/O). Zrozumienie, kiedy używać każdego z nich — i jak skutecznie je łączyć — jest kluczem do maksymalizacji wydajności.
Integracja biblioteki Task Parallel Library
Parallel.ForEach to najprostsze i najbardziej efektywne podejście do operacji wsadowych obciążonych na CPU. Silnik renderujący IronPDF jest obciążający dla CPU (analiza HTML, układowanie CSS, rastrowanie obrazu), a Parallel.ForEach automatycznie rozdziela tę pracę na wszystkie dostępne rdzenie.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-tpl.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
using System.Threading;
using System.Diagnostics;
string inputFolder = "input/";
string outputFolder = "output/";
Directory.CreateDirectory(outputFolder);
string[] htmlFiles = Directory.GetFiles(inputFolder, "*.html");
var renderer = new ChromePdfRenderer();
Console.WriteLine($"Processing {htmlFiles.Length} files with {Environment.ProcessorCount} CPU cores");
int processed = 0;
var stopwatch = Stopwatch.StartNew();
// Configure parallelism based on system resources
// Rule of thumb: ProcessorCount / 2 for memory-intensive operations
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Math.Max(1, Environment.ProcessorCount / 2)
};
Console.WriteLine($"Max parallelism: {options.MaxDegreeOfParallelism}");
// Use Parallel.ForEach for CPU-bound batch operations
Parallel.ForEach(htmlFiles, options, htmlFile =>
{
string fileName = Path.GetFileNameWithoutExtension(htmlFile);
string outputPath = Path.Combine(outputFolder, $"{fileName}.pdf");
try
{
// Render HTML to PDF
using var pdf = renderer.RenderHtmlFileAsPdf(htmlFile);
pdf.SaveAs(outputPath);
int current = Interlocked.Increment(ref processed);
// Progress reporting every 10 files
if (current % 10 == 0)
{
double elapsed = stopwatch.Elapsed.TotalSeconds;
double rate = current / elapsed;
double remaining = (htmlFiles.Length - current) / rate;
Console.WriteLine($"Progress: {current}/{htmlFiles.Length} ({rate:F1} files/sec, ~{remaining:F0}s remaining)");
}
}
catch (Exception ex)
{
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
});
stopwatch.Stop();
double totalRate = processed / stopwatch.Elapsed.TotalSeconds;
Console.WriteLine($"\nComplete:");
Console.WriteLine($" Files processed: {processed}/{htmlFiles.Length}");
Console.WriteLine($" Total time: {stopwatch.Elapsed.TotalSeconds:F1}s");
Console.WriteLine($" Average rate: {totalRate:F1} files/sec");
Console.WriteLine($" Time per file: {stopwatch.Elapsed.TotalMilliseconds / processed:F0}ms");
// Memory monitoring helper (call between chunks for large batches)
void CheckMemoryPressure()
{
const long memoryThreshold = 4L * 1024 * 1024 * 1024; // 4 GB
long currentMemory = GC.GetTotalMemory(forceFullCollection: false);
if (currentMemory > memoryThreshold)
{
Console.WriteLine($"Memory pressure detected ({currentMemory / 1024 / 1024}MB), forcing GC...");
GC.Collect();
GC.WaitForPendingFinalizers();
GC.Collect();
}
}Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading.Tasks
Imports System.Threading
Imports System.Diagnostics
Module Program
Sub Main()
Dim inputFolder As String = "input/"
Dim outputFolder As String = "output/"
Directory.CreateDirectory(outputFolder)
Dim htmlFiles As String() = Directory.GetFiles(inputFolder, "*.html")
Dim renderer As New ChromePdfRenderer()
Console.WriteLine($"Processing {htmlFiles.Length} files with {Environment.ProcessorCount} CPU cores")
Dim processed As Integer = 0
Dim stopwatch As Stopwatch = Stopwatch.StartNew()
' Configure parallelism based on system resources
' Rule of thumb: ProcessorCount / 2 for memory-intensive operations
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Math.Max(1, Environment.ProcessorCount \ 2)
}
Console.WriteLine($"Max parallelism: {options.MaxDegreeOfParallelism}")
' Use Parallel.ForEach for CPU-bound batch operations
Parallel.ForEach(htmlFiles, options, Sub(htmlFile)
Dim fileName As String = Path.GetFileNameWithoutExtension(htmlFile)
Dim outputPath As String = Path.Combine(outputFolder, $"{fileName}.pdf")
Try
' Render HTML to PDF
Using pdf = renderer.RenderHtmlFileAsPdf(htmlFile)
pdf.SaveAs(outputPath)
End Using
Dim current As Integer = Interlocked.Increment(processed)
' Progress reporting every 10 files
If current Mod 10 = 0 Then
Dim elapsed As Double = stopwatch.Elapsed.TotalSeconds
Dim rate As Double = current / elapsed
Dim remaining As Double = (htmlFiles.Length - current) / rate
Console.WriteLine($"Progress: {current}/{htmlFiles.Length} ({rate:F1} files/sec, ~{remaining:F0}s remaining)")
End If
Catch ex As Exception
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End Sub)
stopwatch.Stop()
Dim totalRate As Double = processed / stopwatch.Elapsed.TotalSeconds
Console.WriteLine(vbCrLf & "Complete:")
Console.WriteLine($" Files processed: {processed}/{htmlFiles.Length}")
Console.WriteLine($" Total time: {stopwatch.Elapsed.TotalSeconds:F1}s")
Console.WriteLine($" Average rate: {totalRate:F1} files/sec")
Console.WriteLine($" Time per file: {stopwatch.Elapsed.TotalMilliseconds / processed:F0}ms")
' Memory monitoring helper (call between chunks for large batches)
CheckMemoryPressure()
End Sub
Sub CheckMemoryPressure()
Const memoryThreshold As Long = 4L * 1024 * 1024 * 1024 ' 4 GB
Dim currentMemory As Long = GC.GetTotalMemory(forceFullCollection:=False)
If currentMemory > memoryThreshold Then
Console.WriteLine($"Memory pressure detected ({currentMemory \ 1024 \ 1024}MB), forcing GC...")
GC.Collect()
GC.WaitForPendingFinalizers()
GC.Collect()
End If
End Sub
End ModuleOpcja MaxDegreeOfParallelism jest kluczowa. W przeciwnym razie TPL będzie próbował wykorzystać wszystkie dostępne rdzenie, co może przeciążyć pamięć, jeśli każde renderowanie wymaga dużej ilości zasobów. Ustaw tę wartość na podstawie dostępnej pamięci RAM systemu podzielonej przez typowe zużycie pamięci na renderowanie (zwykle 100–300 MB na równoległe renderowanie złożonego kodu HTML).
Kontrola współbieżności (SemaphoreSlim)
Gdy potrzebna jest dokładniejsza kontrola nad współbieżnością niż zapewnia Parallel.ForEach, np. przy łączeniu asynchronicznego I/O z renderowaniem obciążonym na CPU — SemaphoreSlim zapewnia explicite kontrolę nad tym, ile operacji działa jednocześnie. Wzorzec jest prosty: należy utworzyć SemaphoreSlim z pożądanym limitem współbieżności (np. 4 jednoczesne renderowania), wywołać WaitAsync przed każdym renderowaniem i Release w bloku finally po. Następnie uruchomić wszystkie zadania za pomocą Task.WhenAll.
Ten wzorzec jest szczególnie przydatny, gdy proces obejmuje zarówno etapy związane z operacjami wejścia/wyjścia (odczyt plików z magazynu obiektów blob, zapisywanie wyników do bazy danych), jak i etapy związane z obciążeniem procesora (renderowanie plików PDF). Semafor ogranicza współbieżność renderowania związaną z obciążeniem procesora, jednocześnie umożliwiając wykonywanie operacji związanych z wejściem/wyjściem bez ograniczania przepustowości.
Najlepsze praktyki dotyczące Async/Await
IronPDF zapewnia asynchroniczne warianty swoich metod renderowania, w tym RenderHtmlAsPdfAsync, RenderUrlAsPdfAsync i RenderHtmlFileAsPdfAsync. Są one idealne dla aplikacji internetowych (gdzie blokowanie wątku żądania jest niedopuszczalne) oraz dla potoków łączących renderowanie plików PDF z asynchronicznymi operacjami wejścia/wyjścia.
Kilka ważnych najlepszych praktyk dotyczących asynchroniczności w przetwarzaniu wsadowym:
Nie należy używać Task.Run do owijania synchronicznych metod IronPDF — zamiast tego należy używać natywnych wariantów async. Owijanie metod synchronicznych w Task.Run marnuje wątek puli wątków i dodaje narzut bez żadnych korzyści.
Nie należy używać .Result ani .Wait() na zadaniach asynchronicznych — blokuje to wywołujący wątek i może powodować deadlocki w kontekstach UI lub ASP.NET. Zawsze należy używać await.
Należy grupować wywołania Task.WhenAll zamiast oczekiwania na wszystkie zadania naraz. Jeśli jest 10 000 zadań i wywoła się Task.WhenAll na wszystkich z nich jednocześnie, uruchomi się 10 000 równoczesnych operacji. Zamiast tego należy użyć .Chunk(10) lub podobnego podejścia, aby przetwarzać je w grupach, oczekując na każdą grupę sekwencyjnie.
Unikanie wyczerpania pamięci
Wyczerpanie pamięci jest najczęstszym trybem awarii w przetwarzaniu wsadowym PDF. Defensywne podejście to monitorowanie zużycia pamięci za pomocą GC.GetTotalMemory() przed każdym renderowaniem i wywołanie kolekcji, gdy zużycie przekracza próg (np. 4 GB lub 80% dostępnej pamięci RAM). Wywołaj GC.Collect(), a następnie GC.WaitForPendingFinalizers() i drugie GC.Collect(), aby odzyskać jak najwięcej pamięci przed kontynuowaniem. Powoduje to małą przerwę, ale zapobiega katastrofalnej alternatywie OutOfMemoryException, który powoduje awarię całego wsadu na pliku nr 30 000.
Połącz to z MaxDegreeOfParallelism z sekcji TPL i wzorcami usuwania using z sekcji zarządzania pamięcią, a uzyskasz trójwarstwową obronę przed problemami z pamięcią: ogranicz współbieżność, usuwaj agresywnie i monitoruj z zaworem bezpieczeństwa.
Wdrożenie w chmurze dla zadań wsadowych
Nowoczesne przetwarzanie wsadowe coraz częściej działa w chmurze, gdzie można skalować zasoby obliczeniowe, aby odpowiadały potrzebom obciążenia i płacić tylko za to, co się używa. IronPDF działa na wszystkich głównych platformach chmurowych — oto jak opracować pipeline'y wsadowe dla każdej z nich.
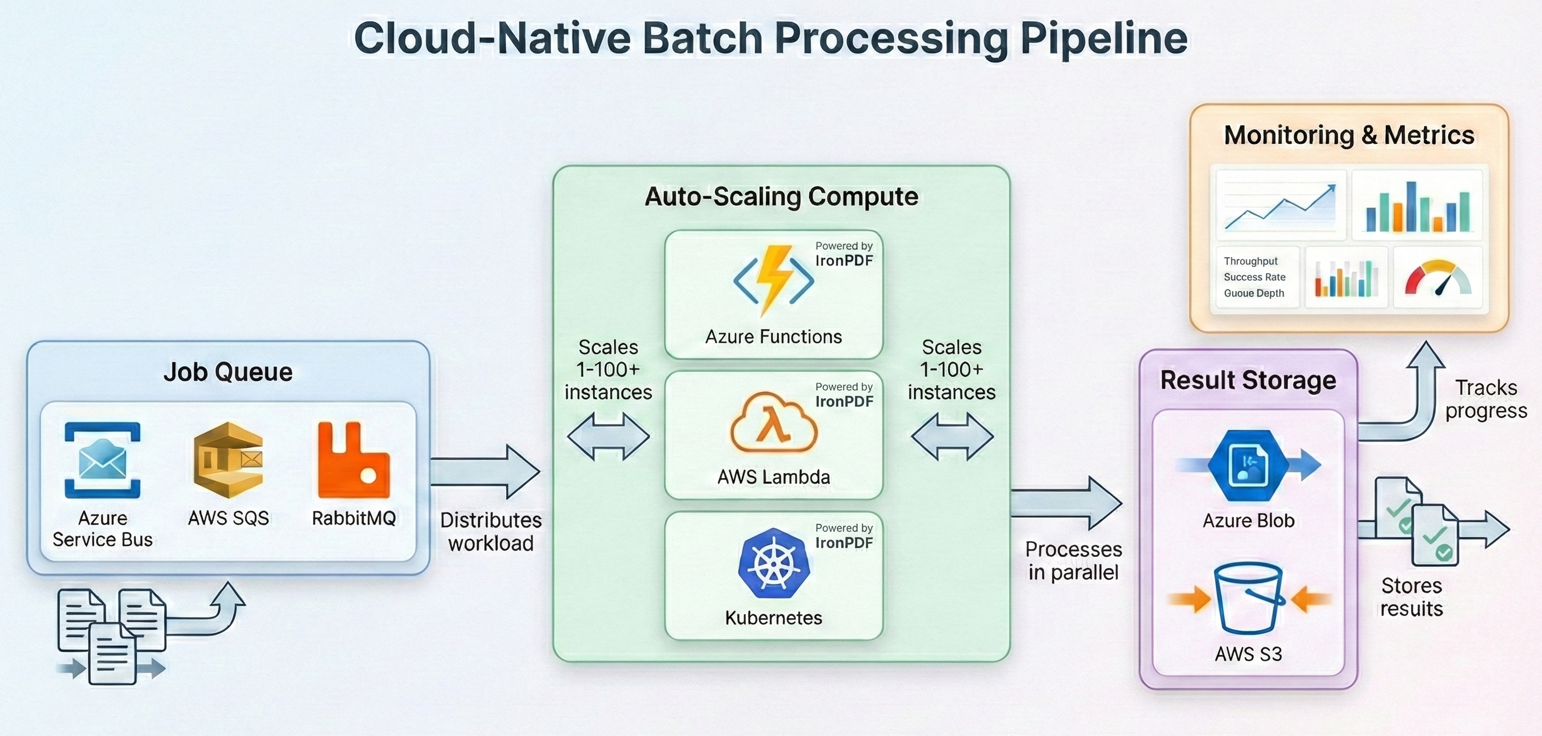
Azure Functions z Durable Functions
Trwałe funkcje Azure zapewniają wbudowaną orkiestrację dla wzorców fan-out/fan-in, co czyni je naturalnym rozwiązaniem dla przetwarzania wsadowego PDF. Funkcja orkiestratora rozdziela pracę na wiele instancji funkcyjnych, z których każda przetwarza podzbiór plików. Orkiestrator wywołuje CallActivityAsync w pętli fan-out, każda funkcja aktywności inicjuje ChromePdfRenderer, przetwarza swoją część plików, a orkiestrator zbiera wyniki.
Kluczowe do rozważenia w przypadku Azure Functions: domyślny plan zużycia ma 5-minutowy limit czasu na wywołanie funkcji i ograniczoną pamięć. Do przetwarzania wsadowego należy używać planu Premium lub Dedykowanego, który obsługuje dłuższe limity czasowe i większą pamięć. IronPDF wymaga całego środowiska uruchomieniowego .NET (nieskróconego), dlatego aplikacja funkcyjna musi być skonfigurowana pod kątem .NET 8+ z odpowiednim identyfikatorem środowiska uruchomieniowego.
AWS Lambda z Step Functions
AWS Step Functions zapewniają możliwości orkiestracyjne podobne do trwałych funkcji Azure. Każdy krok w maszynie stanów wywołuje funkcję Lambda, która przetwarza część plików. Uchwyt Lambda odbiera partię kluczy obiektów S3, ładuje każdy PDF za pomocą PdfDocument.FromFile, stosuje pipeline przetwarzania (kompresja, konwersja formatu itp.) i zapisuje wyniki do wyjściowego koszyka S3.
AWS Lambda ma maksymalny czas wykonania wynoszący 15 minut i ograniczoną pamięć /tmp (domyślnie 512 MB, konfigurowalne do 10 GB). Do dużych zadań wsadowych należy użyć Step Functions do podzielenia obciążenia i przetworzenia każdej części w osobnym wywołaniu Lambda. Wyniki pośrednie należy przechowywać w S3, a nie w pamięci lokalnej.
Planowanie działań w Kubernetes
Dla organizacji obsługujących własne klastry Kubernetes, przetwarzanie wsadowe PDF dobrze odwzorowuje się na zadania i CronJobs w Kubernetes. Każdy pod wykonuje zadanie wsadowe, które pobiera pliki z kolejki (Azure Service Bus, RabbitMQ lub SQS), przetwarza je za pomocą IronPDF i zapisuje wyniki do pamięci obiektowej. Pętla robocza podąża za tym samym wzorcem przedstawionym w wcześniejszych sekcjach: usunięcie wiadomości z kolejki, użycie ChromePdfRenderer.RenderHtmlAsPdf() lub PdfDocument.FromFile() do przetworzenia dokumentu, przesłanie wyniku i potwierdzenie wiadomości. Przetwarzanie należy owinąć w ten sam try-catch z logiką ponownego wywołania z wzorów odporności i użyć SemaphoreSlim do kontroli współbieżności na pod.
IronPDF obsługuje oficjalnie Docker i działa na kontenerach Linux. Należy użyć pakietu NuGet IronPdf wraz z odpowiednimi natywnymi pakietami środowiska uruchomieniowego dla systemu operacyjnego danego kontenera (np. IronPdf.Linux dla obrazów opartych na Linux). Dla Kubernetes należy zdefiniować żądania i limity zasobów odpowiadające wymaganiom pamięci IronPDF (zwykle 512 MB–2 GB na pod w zależności od współbieżności). Horyzontalny Pod Autoscaler może skalować pracowników na podstawie głębokości kolejki, a wzorzec punktów kontrolnych zapewnia, że żadna praca nie zostanie utracona, jeśli pody zostaną usunięte.
Strategie optymalizacji kosztów
Przetwarzanie wsadowe w chmurze może być kosztowne, jeśli nie jesteś rozważny w alokacji zasobów. Oto strategie, które mają największy wpływ:
Dostosuj obliczenia. Renderowanie PDF jest obciążające dla CPU i pamięci, nie GPU. Należy używać instancji zoptymalizowanych do obliczeń (serii C na Azure, typu C na AWS) zamiast ogólnego przeznaczenia lub zoptymalizowanego pod kątem pamięci. Zapewnia to lepsze wskaźniki cenowe na render.
Użyj instancji SPOT/przerywanych dla obciążeń wsadowych, które mogą tolerować przerwania. Przetwarzanie wsadowe PDF jest z natury wznawialne (dzięki punktom kontrolnym), co czyni go idealnym kandydatem dla cen SPOT, które zazwyczaj oferują 60–90% zniżki w porównaniu z on-demand.
Przetwarzaj poza szczytem czasu, jeśli linia czasu na to pozwala. Wielu dostawców chmurowych oferuje niższe ceny lub wyższą dostępność SPOT podczas nocy i weekendów.
Kompresuj szybko, przechowuj raz. Należy uruchomić kompresję jako część pipeline przetwarzania, a nie jako osobny krok. Przechowywanie skompresowanych PDF-ów od początku zmniejsza koszt przechowywania w czasie trwania archiwum.
Warstwy przechowywania. Przetworzone PDF-y, które są często docelowe, powinny trafić do gorącego przechowywania; zarchiwizowane PDF-y, które są rzadko używane, powinny zostać przeniesione do chłodnych lub archiwalnych warstw (Azure Cool/Archive, AWS S3 Glacier). To samo może zmniejszyć koszty przechowywania o 50–80%.
Przykład pipeline w rzeczywistości
Połączmy wszystko razem w kompletnym, w pełni produkcyjnym pipeline, który demonstruje pełny przepływ pracy: Pobierz → Waliduj → Przetwarzaj → Archiwizuj → Raportuj.
Przykład ten przetwarza katalog szablonów HTML faktur, renderuje je do PDF, kompresuje wyjście, konwertuje do PDF/A-3b dla zgodności archiwalnej, sprawdza wynik i na końcu tworzy raport podsumowujący.
Używając tych samych 5 faktur HTML z przykładu konwersji wsadowej powyżej...
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-full-pipeline.csusing IronPdf;
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Threading.Tasks;
using System.Threading;
using System.Collections.Concurrent;
using System.Diagnostics;
using System.Text.Json;
// Configuration
var config = new PipelineConfig
{
InputFolder = "input/",
OutputFolder = "output/",
ArchiveFolder = "archive/",
ErrorFolder = "errors/",
CheckpointPath = "pipeline-checkpoint.json",
ReportPath = "pipeline-report.json",
MaxConcurrency = Math.Max(1, Environment.ProcessorCount / 2),
MaxRetries = 3,
JpegQuality = 70
};
// Initialize folders
Directory.CreateDirectory(config.OutputFolder);
Directory.CreateDirectory(config.ArchiveFolder);
Directory.CreateDirectory(config.ErrorFolder);
// Load checkpoint for resume capability
var checkpoint = LoadCheckpoint(config.CheckpointPath);
var results = new ConcurrentBag<ProcessingResult>();
var stopwatch = Stopwatch.StartNew();
// Get files to process
string[] allFiles = Directory.GetFiles(config.InputFolder, "*.html");
string[] filesToProcess = allFiles
.Where(f => !checkpoint.CompletedFiles.Contains(Path.GetFileName(f)))
.ToArray();
Console.WriteLine($"Pipeline starting:");
Console.WriteLine($" Total files: {allFiles.Length}");
Console.WriteLine($" Already processed: {checkpoint.CompletedFiles.Count}");
Console.WriteLine($" To process: {filesToProcess.Length}");
Console.WriteLine($" Concurrency: {config.MaxConcurrency}");
var renderer = new ChromePdfRenderer();
var checkpointLock = new object();
var options = new ParallelOptions
{
MaxDegreeOfParallelism = config.MaxConcurrency
};
Parallel.ForEach(filesToProcess, options, inputFile =>
{
var result = new ProcessingResult
{
FileName = Path.GetFileName(inputFile),
StartTime = DateTime.UtcNow
};
try
{
// Stage: Pre-validation
if (!ValidateInput(inputFile))
{
result.Status = "PreValidationFailed";
result.Error = "Input file failed validation";
results.Add(result);
return;
}
string baseName = Path.GetFileNameWithoutExtension(inputFile);
string tempPath = Path.Combine(config.OutputFolder, $"{baseName}.pdf");
string archivePath = Path.Combine(config.ArchiveFolder, $"{baseName}.pdf");
// Stage: Process with retry
PdfDocument pdf = null;
int attempt = 0;
bool success = false;
while (attempt < config.MaxRetries && !success)
{
attempt++;
try
{
pdf = renderer.RenderHtmlFileAsPdf(inputFile);
success = true;
}
catch (Exception ex) when (IsTransient(ex) && attempt < config.MaxRetries)
{
Thread.Sleep((int)Math.Pow(2, attempt) * 500);
}
}
if (!success || pdf == null)
{
result.Status = "ProcessingFailed";
result.Error = "Max retries exceeded";
results.Add(result);
return;
}
using (pdf)
{
// Stage: Compress and convert to PDF/A-3b for archival
pdf.SaveAsPdfA(tempPath, PdfAVersions.PdfA3b);
}
// Stage: Post-validation
if (!ValidateOutput(tempPath))
{
File.Move(tempPath, Path.Combine(config.ErrorFolder, $"{baseName}.pdf"), overwrite: true);
result.Status = "PostValidationFailed";
result.Error = "Output file failed validation";
results.Add(result);
return;
}
// Stage: Archive
File.Move(tempPath, archivePath, overwrite: true);
// Update checkpoint
lock (checkpointLock)
{
checkpoint.CompletedFiles.Add(result.FileName);
SaveCheckpoint(config.CheckpointPath, checkpoint);
}
result.Status = "Success";
result.OutputSize = new FileInfo(archivePath).Length;
result.EndTime = DateTime.UtcNow;
results.Add(result);
Console.WriteLine($"[OK] {baseName}.pdf ({result.OutputSize / 1024}KB)");
}
catch (Exception ex)
{
result.Status = "Error";
result.Error = ex.Message;
result.EndTime = DateTime.UtcNow;
results.Add(result);
Console.WriteLine($"[ERROR] {result.FileName}: {ex.Message}");
}
});
stopwatch.Stop();
// Generate report
var report = new PipelineReport
{
TotalFiles = allFiles.Length,
ProcessedThisRun = results.Count,
Succeeded = results.Count(r => r.Status == "Success"),
PreValidationFailed = results.Count(r => r.Status == "PreValidationFailed"),
ProcessingFailed = results.Count(r => r.Status == "ProcessingFailed"),
PostValidationFailed = results.Count(r => r.Status == "PostValidationFailed"),
Errors = results.Count(r => r.Status == "Error"),
TotalDuration = stopwatch.Elapsed,
AverageFileTime = results.Any() ? TimeSpan.FromMilliseconds(stopwatch.Elapsed.TotalMilliseconds / results.Count) : TimeSpan.Zero
};
string reportJson = JsonSerializer.Serialize(report, new JsonSerializerOptions { WriteIndented = true });
File.WriteAllText(config.ReportPath, reportJson);
Console.WriteLine($"\n=== Pipeline Complete ===");
Console.WriteLine($"Succeeded: {report.Succeeded}");
Console.WriteLine($"Failed: {report.PreValidationFailed + report.ProcessingFailed + report.PostValidationFailed + report.Errors}");
Console.WriteLine($"Duration: {report.TotalDuration.TotalMinutes:F1} minutes");
Console.WriteLine($"Report: {config.ReportPath}");
// Helper methods
bool ValidateInput(string path)
{
try
{
var info = new FileInfo(path);
if (!info.Exists || info.Length == 0 || info.Length > 50 * 1024 * 1024) return false;
string content = File.ReadAllText(path);
return content.Contains("<html", StringComparison.OrdinalIgnoreCase) ||
content.Contains("<!DOCTYPE", StringComparison.OrdinalIgnoreCase);
}
catch { return false; }
}
bool ValidateOutput(string path)
{
try
{
using var pdf = PdfDocument.FromFile(path);
return pdf.PageCount > 0 && new FileInfo(path).Length > 1024;
}
catch { return false; }
}
bool IsTransient(Exception ex) =>
ex is IOException || ex is OutOfMemoryException ||
ex.Message.Contains("timeout", StringComparison.OrdinalIgnoreCase);
Checkpoint LoadCheckpoint(string path)
{
if (File.Exists(path))
{
string json = File.ReadAllText(path);
return JsonSerializer.Deserialize<Checkpoint>(json) ?? new Checkpoint();
}
return new Checkpoint();
}
void SaveCheckpoint(string path, Checkpoint cp) =>
File.WriteAllText(path, JsonSerializer.Serialize(cp));
ata classes
s PipelineConfig
public string InputFolder { get; set; } = "";
public string OutputFolder { get; set; } = "";
public string ArchiveFolder { get; set; } = "";
public string ErrorFolder { get; set; } = "";
public string CheckpointPath { get; set; } = "";
public string ReportPath { get; set; } = "";
public int MaxConcurrency { get; set; }
public int MaxRetries { get; set; }
public int JpegQuality { get; set; }
s Checkpoint
public HashSet<string> CompletedFiles { get; set; } = new();
s ProcessingResult
public string FileName { get; set; } = "";
public string Status { get; set; } = "";
public string Error { get; set; } = "";
public long OutputSize { get; set; }
public DateTime StartTime { get; set; }
public DateTime EndTime { get; set; }
s PipelineReport
public int TotalFiles { get; set; }
public int ProcessedThisRun { get; set; }
public int Succeeded { get; set; }
public int PreValidationFailed { get; set; }
public int ProcessingFailed { get; set; }
public int PostValidationFailed { get; set; }
public int Errors { get; set; }
public TimeSpan TotalDuration { get; set; }
public TimeSpan AverageFileTime { get; set; }Imports IronPdf
Imports System
Imports System.Collections.Generic
Imports System.IO
Imports System.Linq
Imports System.Threading.Tasks
Imports System.Threading
Imports System.Collections.Concurrent
Imports System.Diagnostics
Imports System.Text.Json
' Configuration
Dim config As New PipelineConfig With {
.InputFolder = "input/",
.OutputFolder = "output/",
.ArchiveFolder = "archive/",
.ErrorFolder = "errors/",
.CheckpointPath = "pipeline-checkpoint.json",
.ReportPath = "pipeline-report.json",
.MaxConcurrency = Math.Max(1, Environment.ProcessorCount \ 2),
.MaxRetries = 3,
.JpegQuality = 70
}
' Initialize folders
Directory.CreateDirectory(config.OutputFolder)
Directory.CreateDirectory(config.ArchiveFolder)
Directory.CreateDirectory(config.ErrorFolder)
' Load checkpoint for resume capability
Dim checkpoint As Checkpoint = LoadCheckpoint(config.CheckpointPath)
Dim results As New ConcurrentBag(Of ProcessingResult)()
Dim stopwatch As Stopwatch = Stopwatch.StartNew()
' Get files to process
Dim allFiles As String() = Directory.GetFiles(config.InputFolder, "*.html")
Dim filesToProcess As String() = allFiles.
Where(Function(f) Not checkpoint.CompletedFiles.Contains(Path.GetFileName(f))).
ToArray()
Console.WriteLine("Pipeline starting:")
Console.WriteLine($" Total files: {allFiles.Length}")
Console.WriteLine($" Already processed: {checkpoint.CompletedFiles.Count}")
Console.WriteLine($" To process: {filesToProcess.Length}")
Console.WriteLine($" Concurrency: {config.MaxConcurrency}")
Dim renderer As New ChromePdfRenderer()
Dim checkpointLock As New Object()
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = config.MaxConcurrency
}
Parallel.ForEach(filesToProcess, options, Sub(inputFile)
Dim result As New ProcessingResult With {
.FileName = Path.GetFileName(inputFile),
.StartTime = DateTime.UtcNow
}
Try
' Stage: Pre-validation
If Not ValidateInput(inputFile) Then
result.Status = "PreValidationFailed"
result.Error = "Input file failed validation"
results.Add(result)
Return
End If
Dim baseName As String = Path.GetFileNameWithoutExtension(inputFile)
Dim tempPath As String = Path.Combine(config.OutputFolder, $"{baseName}.pdf")
Dim archivePath As String = Path.Combine(config.ArchiveFolder, $"{baseName}.pdf")
' Stage: Process with retry
Dim pdf As PdfDocument = Nothing
Dim attempt As Integer = 0
Dim success As Boolean = False
While attempt < config.MaxRetries AndAlso Not success
attempt += 1
Try
pdf = renderer.RenderHtmlFileAsPdf(inputFile)
success = True
Catch ex As Exception When IsTransient(ex) AndAlso attempt < config.MaxRetries
Thread.Sleep(CInt(Math.Pow(2, attempt)) * 500)
End Try
End While
If Not success OrElse pdf Is Nothing Then
result.Status = "ProcessingFailed"
result.Error = "Max retries exceeded"
results.Add(result)
Return
End If
Using pdf
' Stage: Compress and convert to PDF/A-3b for archival
pdf.SaveAsPdfA(tempPath, PdfAVersions.PdfA3b)
End Using
' Stage: Post-validation
If Not ValidateOutput(tempPath) Then
File.Move(tempPath, Path.Combine(config.ErrorFolder, $"{baseName}.pdf"), overwrite:=True)
result.Status = "PostValidationFailed"
result.Error = "Output file failed validation"
results.Add(result)
Return
End If
' Stage: Archive
File.Move(tempPath, archivePath, overwrite:=True)
' Update checkpoint
SyncLock checkpointLock
checkpoint.CompletedFiles.Add(result.FileName)
SaveCheckpoint(config.CheckpointPath, checkpoint)
End SyncLock
result.Status = "Success"
result.OutputSize = New FileInfo(archivePath).Length
result.EndTime = DateTime.UtcNow
results.Add(result)
Console.WriteLine($"[OK] {baseName}.pdf ({result.OutputSize \ 1024}KB)")
Catch ex As Exception
result.Status = "Error"
result.Error = ex.Message
result.EndTime = DateTime.UtcNow
results.Add(result)
Console.WriteLine($"[ERROR] {result.FileName}: {ex.Message}")
End Try
End Sub)
stopwatch.Stop()
' Generate report
Dim report As New PipelineReport With {
.TotalFiles = allFiles.Length,
.ProcessedThisRun = results.Count,
.Succeeded = results.Count(Function(r) r.Status = "Success"),
.PreValidationFailed = results.Count(Function(r) r.Status = "PreValidationFailed"),
.ProcessingFailed = results.Count(Function(r) r.Status = "ProcessingFailed"),
.PostValidationFailed = results.Count(Function(r) r.Status = "PostValidationFailed"),
.Errors = results.Count(Function(r) r.Status = "Error"),
.TotalDuration = stopwatch.Elapsed,
.AverageFileTime = If(results.Any(), TimeSpan.FromMilliseconds(stopwatch.Elapsed.TotalMilliseconds / results.Count), TimeSpan.Zero)
}
Dim reportJson As String = JsonSerializer.Serialize(report, New JsonSerializerOptions With {.WriteIndented = True})
File.WriteAllText(config.ReportPath, reportJson)
Console.WriteLine(vbCrLf & "=== Pipeline Complete ===")
Console.WriteLine($"Succeeded: {report.Succeeded}")
Console.WriteLine($"Failed: {report.PreValidationFailed + report.ProcessingFailed + report.PostValidationFailed + report.Errors}")
Console.WriteLine($"Duration: {report.TotalDuration.TotalMinutes:F1} minutes")
Console.WriteLine($"Report: {config.ReportPath}")
' Helper methods
Function ValidateInput(path As String) As Boolean
Try
Dim info As New FileInfo(path)
If Not info.Exists OrElse info.Length = 0 OrElse info.Length > 50 * 1024 * 1024 Then Return False
Dim content As String = File.ReadAllText(path)
Return content.Contains("<html", StringComparison.OrdinalIgnoreCase) OrElse
content.Contains("<!DOCTYPE", StringComparison.OrdinalIgnoreCase)
Catch
Return False
End Try
End Function
Function ValidateOutput(path As String) As Boolean
Try
Using pdf = PdfDocument.FromFile(path)
Return pdf.PageCount > 0 AndAlso New FileInfo(path).Length > 1024
End Using
Catch
Return False
End Try
End Function
Function IsTransient(ex As Exception) As Boolean
Return TypeOf ex Is IOException OrElse TypeOf ex Is OutOfMemoryException OrElse
ex.Message.Contains("timeout", StringComparison.OrdinalIgnoreCase)
End Function
Function LoadCheckpoint(path As String) As Checkpoint
If File.Exists(path) Then
Dim json As String = File.ReadAllText(path)
Return JsonSerializer.Deserialize(Of Checkpoint)(json) OrElse New Checkpoint()
End If
Return New Checkpoint()
End Function
Sub SaveCheckpoint(path As String, cp As Checkpoint)
File.WriteAllText(path, JsonSerializer.Serialize(cp))
End Sub
' Data classes
Class PipelineConfig
Public Property InputFolder As String = ""
Public Property OutputFolder As String = ""
Public Property ArchiveFolder As String = ""
Public Property ErrorFolder As String = ""
Public Property CheckpointPath As String = ""
Public Property ReportPath As String = ""
Public Property MaxConcurrency As Integer
Public Property MaxRetries As Integer
Public Property JpegQuality As Integer
End Class
Class Checkpoint
Public Property CompletedFiles As HashSet(Of String) = New HashSet(Of String)()
End Class
Class ProcessingResult
Public Property FileName As String = ""
Public Property Status As String = ""
Public Property Error As String = ""
Public Property OutputSize As Long
Public Property StartTime As DateTime
Public Property EndTime As DateTime
End Class
Class PipelineReport
Public Property TotalFiles As Integer
Public Property ProcessedThisRun As Integer
Public Property Succeeded As Integer
Public Property PreValidationFailed As Integer
Public Property ProcessingFailed As Integer
Public Property PostValidationFailed As Integer
Public Property Errors As Integer
Public Property TotalDuration As TimeSpan
Public Property AverageFileTime As TimeSpan
End ClassWynik
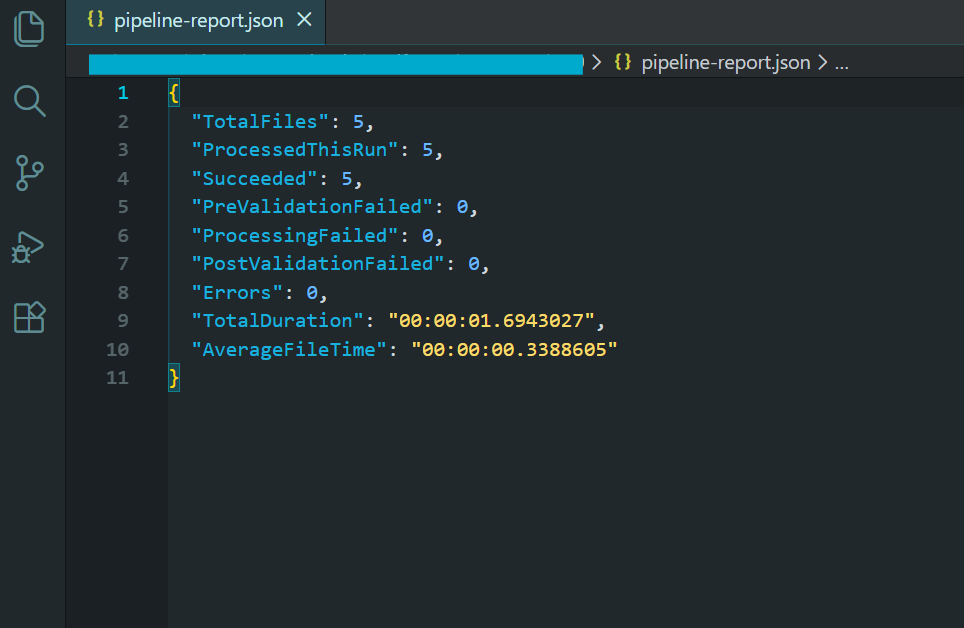
Raport pipeline pokazujący wyniki przetwarzania wsadowego.
Ten pipeline zawiera każdy wzorzec, który omówiony był w tym samouczku: przetwarzanie równoległe z kontrolowaną współbieżnością, obsługa błędów na poziomie pliku z pominięciem błędów, logika ponawiania dla przelotnych błędów, punkty kontrolne dla wznowienia po awarii, weryfikacja przed i po przetworzeniu, zarządzanie pamięcią z wyraźnym usuwaniem i pełne śledzenie z ostatecznym raportem podsumowującym.
Wynik tego pipeline to katalog skompresowanych, kompatybilnych z PDF/A-3b plików archiwalnych, plik kontrolny zapewniający zdolność do wznowienia, dziennik błędów dla plików, których nie można było przetworzyć, i raport podsumowujący ze statystykami przetwarzania. To jest wzorzec odpowiedni dla każdego poważnego obciążenia przetwarzania wsadowego PDF.
Kolejne kroki
Przetwarzanie PDF-ów na skalę to nie tylko wywołanie metody renderowania w pętli. Wymaga przemyślanej architektury wokół współbieżności, zarządzania pamięcią, obsługi błędów i wdrożenia — oraz odpowiedniej biblioteki, aby wszystko działało. IronPDF zapewnia bezpieczny dla wątków silnik renderujący, powierzchnię API async, narzędzia do kompresji i możliwość konwersji formatów, które stanowią podstawę każdej pipeline wsadowej PDF w .NET.
Niezależnie od tego, czy tworzony jest nocny generator raportów generujący tysiące PDF-ów przed wschodem słońca, migrowane jest archiwum dokumentów do zgodności PDF/A, czy też rozstawiana jest chmurowa usługa przetwarzania na Kubernetes, wzorce w tym samouczku dają sprawdzony framework do budowania. Równoległe przetwarzanie z kontrolowaną współbieżnością utrzymuje wysoką przepustowość. Logika pominięcia błędów i ponawianie utrzymuje przepływ danych, gdy pojedyncze pliki powodują problemy. Punkt kontrolny zapewnia, że postęp nigdy nie zostanie utracony. Wzorce wdrożenia chmurowego pozwalają skalować zasoby obliczeniowe, aby dopasować się do bieżącego obciążenia.
Gotowi do rozpoczęcia? Pobierz IronPDF i wypróbuj z darmową wersją próbną — ta sama biblioteka obsługuje wszystko, od renderowania pojedynczego pliku po wsadowe pipeline'y z setkami tysięcy plików. W przypadku pytań dotyczących skalowania, wdrożeń lub architektury dla konkretnego przypadku użycia, zapraszamy do kontaktu z naszym zespołem wsparcia inżynierskiego — pomagaliśmy zespołom tworzyć pipeline'y wsadowe na każdą skalę i chętnie pomożemy to właściwie zrealizować.
Często Zadawane Pytania
Czym jest przetwarzanie plików PDF w trybie wsadowym w języku C#?
Przetwarzanie plików PDF w trybie wsadowym w języku C# odnosi się do automatycznej obsługi wielu dokumentów PDF jednocześnie przy użyciu języka programowania C#. Metoda ta idealnie nadaje się do automatyzacji przepływu dokumentów na dużą skalę.
W jaki sposób IronPDF może pomóc w przetwarzaniu plików PDF w trybie wsadowym?
IronPDF zapewnia solidne narzędzia i biblioteki, które usprawniają przetwarzanie plików PDF w trybie wsadowym w języku C#. Obsługuje przetwarzanie równoległe, umożliwiając wydajną obsługę tysięcy plików PDF jednocześnie.
Jakie są zalety korzystania z przetwarzania równoległego w IronPDF?
Przetwarzanie równoległe z wykorzystaniem IronPDF pozwala na szybsze i bardziej wydajne przetwarzanie plików PDF w trybie wsadowym. Takie podejście maksymalizuje wykorzystanie zasobów i znacznie skraca czas przetwarzania.
Czy IronPDF można wdrożyć na platformach chmurowych w celu przetwarzania wsadowego?
Tak, IronPDF można wdrożyć na platformach chmurowych, takich jak Azure Functions, AWS Lambda i Kubernetes, co umożliwia skalowalne i elastyczne przetwarzanie plików PDF w trybie wsadowym.
W jaki sposób IronPDF radzi sobie z błędami podczas przetwarzania plików PDF w trybie wsadowym?
IronPDF zawiera funkcje obsługi błędów i logiki ponownych prób, które zapewniają niezawodność podczas przetwarzania plików PDF w trybie wsadowym. Funkcje te pomagają zarządzać błędami i je korygować bez konieczności ręcznej interwencji.
Jaka jest rola logiki ponownych prób w przetwarzaniu plików PDF za pomocą IronPDF?
Logika ponownych prób w IronPDF gwarantuje, że tymczasowe problemy nie zakłócą przepływu pracy w przetwarzaniu wsadowym. Jeśli wystąpi błąd, IronPDF może automatycznie podjąć próbę ponownego przetworzenia dokumentu, którego przetwarzanie zakończyło się niepowodzeniem.
Dlaczego C# jest odpowiednim językiem do przetwarzania plików PDF w trybie wsadowym?
C# to potężny język programowania z rozbudowanymi bibliotekami i frameworkami, dzięki czemu idealnie nadaje się do przetwarzania plików PDF w trybie wsadowym. Płynnie integruje się z IronPDF, umożliwiając wydajną automatyzację dokumentów.
W jaki sposób IronPDF zapewnia bezpieczeństwo dokumentów PDF podczas przetwarzania?
IronPDF wspiera bezpieczną obsługę dokumentów PDF, zapewniając funkcje szyfrowania i ochrony hasłem, gwarantując, że przetwarzane dokumenty pozostają poufne i bezpieczne.
Jakie są przykłady zastosowań przetwarzania plików PDF w trybie wsadowym w biznesie?
Firmy wykorzystują przetwarzanie plików PDF w trybie wsadowym do takich zadań, jak generowanie faktur zbiorczych, digitalizacja dokumentów i dystrybucja raportów na dużą skalę. IronPDF ułatwia realizację tych zadań poprzez automatyzację i usprawnienie przepływu pracy z dokumentami.
Czy IronPDF obsługuje różne formaty i wersje plików PDF?
Tak, IronPDF jest zaprojektowany do obsługi różnych formatów i wersji plików PDF, zapewniając kompatybilność i elastyczność w zadaniach przetwarzania wsadowego.


Wciąż przewijasz?
Czy chcesz szybko dowodu? PM > Install-Package IronPdf
Uruchom przykład i zobacz, jak Twój kod HTML zamienia się w plik PDF.










