
Comparação de produtos com o IronPDF
O IronPDF se destaca na conversão de HTML para PDF com a precisão do mecanismo Chrome V8 e APIs intuitivas, enquanto o ExpertPDF oferece recursos básicos de PDF com requisitos de configuração mais complexos para sistemas de produção .NET .
Os desenvolvedores de C# frequentemente enfrentam desafios ao lidar com PDFs, seja na leitura, escrita, criação ou conversão entre formatos. Muitas bibliotecas surgiram para atender a essas necessidades, oferecendo uma integração perfeita para aplicativos C#. Ao desenvolver relatórios em PDF com C# , a seleção da biblioteca correta impacta significativamente o tempo de desenvolvimento e a qualidade do resultado. Para gerar PDFs de forma completa em C# , é essencial compreender as funcionalidades das bibliotecas.
Este artigo compara duas bibliotecas PDF para desenvolvedores .NET :
- IronPDF
- ExpertPDF
Ambas as bibliotecas fornecem métodos para gerar, converter e editar PDFs em ambientes .NET . A principal consideração envolve determinar qual biblioteca melhor se adapta aos requisitos específicos do projeto. Esta análise destaca características essenciais para orientar a tomada de decisões. Seja para implementar a conversão de HTML para PDF , recursos de edição de PDF ou funcionalidades de organização de documentos , escolher a biblioteca adequada é crucial.
O que é a biblioteca IronPDF ?
O IronPDF oferece uma solução completa para PDF em .NET , especialmente benéfica para desenvolvedores C#. A biblioteca permite a implementação de todas as funcionalidades necessárias de PDF em aplicações C#. Com suporte para implantação no Azure e AWS Lambda , a biblioteca é adequada para arquiteturas nativas da nuvem. Os desenvolvedores se beneficiam do excelente suporte para Windows , implantação em Linux e compatibilidade com macOS . O guia de instalação fornece orientações completas para a configuração.
O IronPDF incorpora um mecanismo .NET Chromium que renderiza conteúdo HTML em PDF, simplificando o design de documentos sem APIs complexas. O conversor de HTML para PDF cria documentos usando HTML5, CSS, JavaScript e imagens. Além disso, os desenvolvedores podem editar PDFs , adicionar cabeçalhos e rodapés e extrair imagens . A biblioteca simplifica a leitura de texto por meio de recursos confiáveis de extração de texto . Para ambientes de produção, o mecanismo de renderização do Chrome garante uma renderização precisa.
Quais são as principais funcionalidades do IronPDF?
Como faço para criar arquivos PDF a partir de HTML?
- Crie PDFs a partir de HTML, CSS e JavaScript
- Gerar documentos a partir de URLs de sites
- Carregar URLs com credenciais e cabeçalhos HTTP
- Suporte a CSS responsivo e tipos de mídia Execução completa de JavaScript com atrasos de renderização
Como posso editar PDFs sem o Adobe Acrobat Reader?
- Preencha e leia formulários em PDF
- Extrair texto e imagens com análise sintática
- Inserir conteúdo HTML em páginas existentes
- Adicione cabeçalhos/rodapés em HTML ou cabeçalhos baseados em texto.
- Adicionar anotações e assinaturas digitais
Como faço para manipular documentos PDF?
- Carregar e analisar fluxos de memória
- Mesclar e dividir o conteúdo do documento
- Adicione marcas d'água , planos de fundo , texto e outros elementos visuais.
- Gerencie páginas de PDF com rotação de páginas.
- Aplicar transformações e manipular objetos DOM
Quais formatos de arquivo posso converter para PDF?
- Converta WebForms ASPX com o mínimo de código.
- Converter arquivos HTML e arquivos ZIP HTML
- Converter imagens para PDF (PNG, JPG, GIF, TIFF)
- Converter Markdown para PDF com suporte à formatação
- Conversão de DOCX para PDF e de XML para PDF
Como faço para salvar e imprimir PDFs?
- Salvar como dados binários ou MemoryStreams
- Tipos de mídia CSS para impressão
- Converter PDFs em objetos de documento para impressão
- Suporte à conformidade com PDF/A e acessibilidade PDF/UA
- Exportar diferentes versões de PDF e PDFs linearizados
O que é o ExpertPDF?
Visite o site oficial da ExpertPDF para explorar a biblioteca .NET que oferece conversão de HTML para PDF. A biblioteca permite a geração de relatórios em PDF sem a necessidade de softwares complexos de geração de relatórios. Para desenvolvedores que buscam documentação completa e referência de API , considere usar o IronPDF em vez do ExpertPDF para obter uma disponibilidade de recursos muito maior.
O ExpertPDF oferece recursos de edição de PDF descomplicados. O conversor de HTML para PDF integra-se rapidamente em aplicações .NET . Compatível com .NET Framework, .NET Core, .NET 5, .NET 6, .NET 7 e .NET 8, embora faltem implantação Linux e suporte a macOS. Para implantações em contêineres, o IronPDF oferece suporte ao Docker, enquanto o ExpertPDF não. O IronPDF também oferece suporte à implantação remota de contêineres e opções de mecanismo nativo versus remoto .
Esta biblioteca cria PDFs a partir de URLs de páginas da web ou de marcação HTML bruta em aplicações .NET . Para cenários avançados, como renderização de sites WebGL ou aplicativos com uso intensivo de JavaScript , o IronPDF oferece recursos de renderização superiores. O guia de início rápido ajuda os desenvolvedores a começarem rapidamente.
Quais são as principais funcionalidades do ExpertPDF?
Entre as características notáveis, incluem-se:
- Converter URLs de páginas web para PDF
- Converter strings HTML em PDF
- Opções para múltiplos arquivos de saída
- Defina as margens e o tamanho da página
- Definir cabeçalhos e rodapés
- Adicionar quebras de página automáticas e personalizadas
- Converter partes específicas de páginas da web para PDF
- Ocultar elementos durante a conversão
- Combinar várias páginas da web em um único PDF
- Converter páginas web autenticadas em PDF
- Selecione o tipo de mídia CSS para renderização
- Suporte para favoritos
- Suporte para assinatura digital
- Recuperar a posição de elementos HTML em PDF
- Suporte para HTML5/CSS3
- Suporte para fontes da web
- Conversões de tipo de arquivo:
- Conversor de PDF para Texto
- Conversor de HTML para PDF
- Conversor de HTML para Imagem
- Conversor de PDF para Imagem
- Conversor de RTF para PDF
As seções a seguir abordam:
- Crie um projeto de console
- Instalação do IronPDF
- Instalação do ExpertPDF
- Criar PDF a partir de um URL
- Criar PDF a partir de uma string de entrada HTML
- Mesclar vários PDFs em um único PDF
- Converter imagens para PDF
- Licenciamento e Preços
- Conclusão
Como faço para criar um projeto de console?
Siga estes passos para criar uma aplicação de console usando o Visual Studio 2022:
-
Abra o Visual Studio 2022 e clique em Criar um novo projeto.
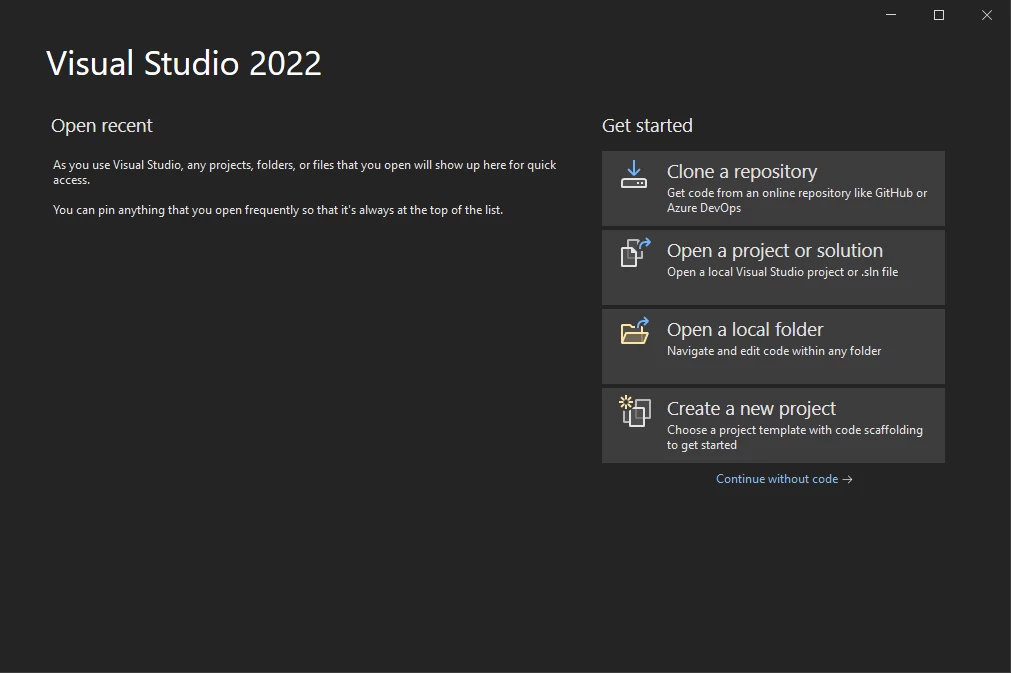
Selecione Aplicativo de Console C# e clique em Avançar.
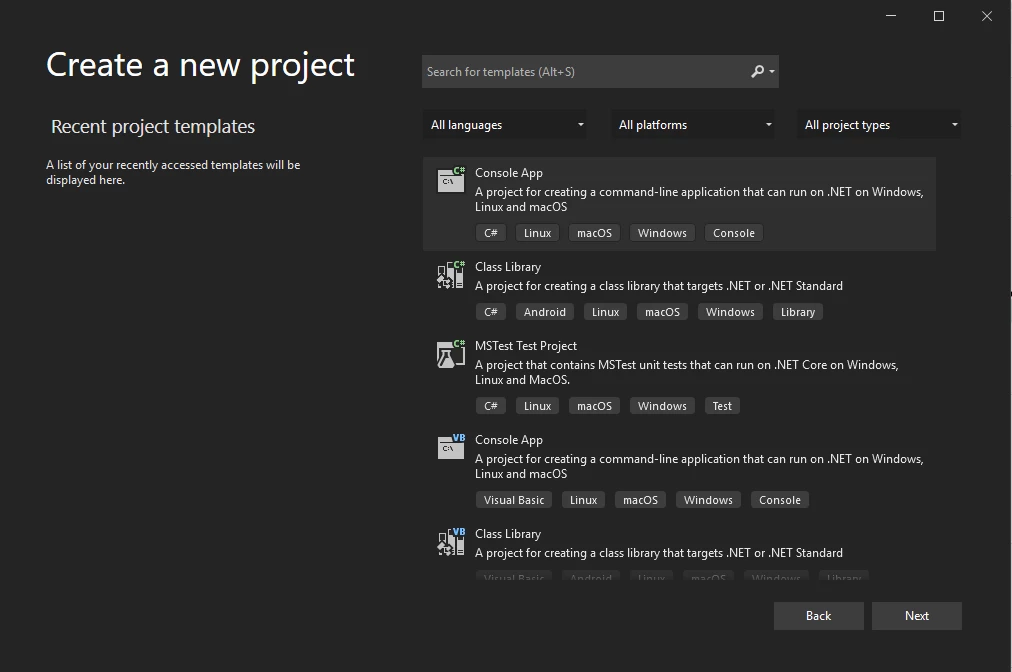-
Digite o nome do projeto e clique em Avançar.
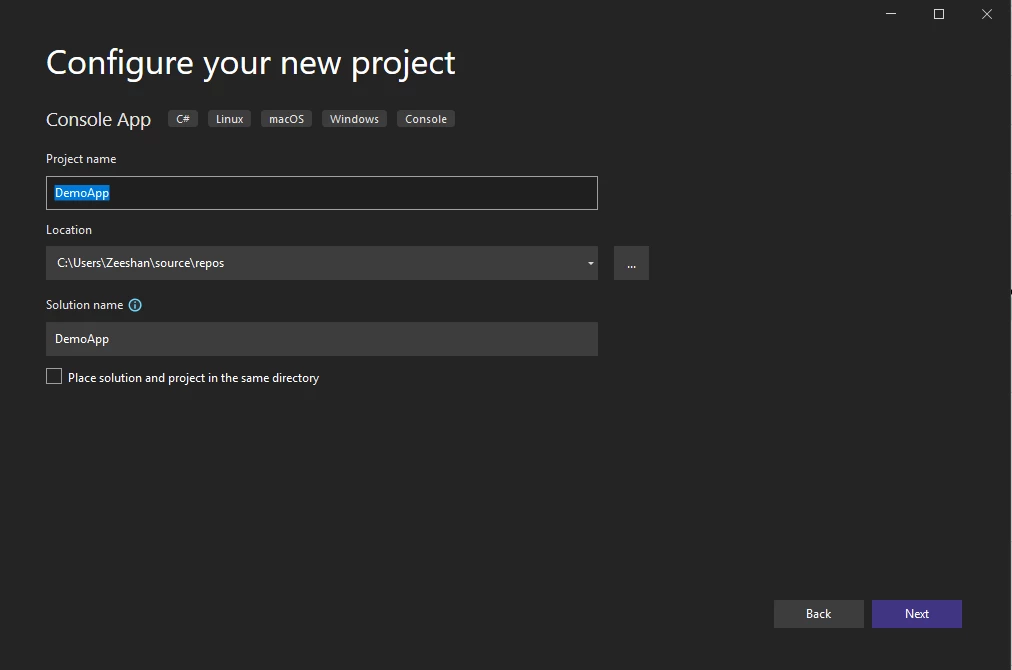
-
Selecione a versão do .NET Framework (usando a versão mais recente, 6.0)
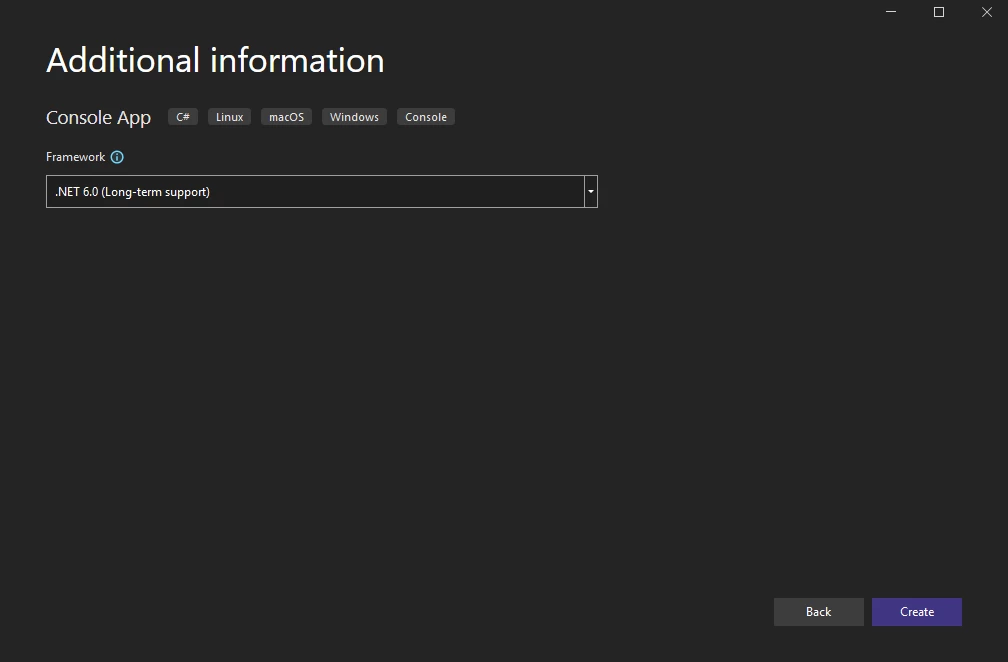
O projeto de console foi criado e está pronto para testes de biblioteca. Ambas as bibliotecas requerem instalação antes do uso. Consulte o guia de início rápido para obter mais detalhes. A documentação de visão geral fornece informações completas.
Como faço para instalar o IronPDF?
Existem vários métodos de instalação disponíveis:
- Usando o Visual Studio
- Baixe o pacote NuGet diretamente
- Baixe a biblioteca IronPDF .DLL.
Consulte a visão geral da instalação para obter mais detalhes. A biblioteca oferece suporte ao instalador do Windows para implantação em todo o sistema. As opções avançadas incluem a instalação NuGet e o uso de chaves de licença .
Como faço para instalar usando o Visual Studio?
O Visual Studio fornece o NuGet Package Manager para instalar pacotes:
- Acesse através das Ferramentas do Menu do Projeto, ou
-
Clique com o botão direito do mouse no projeto no Explorador de Soluções
Procure o pacote NuGet IronPDF e instale-o. Consulte o guia de instalação do NuGet para obter mais detalhes. Os guias específicos para cada plataforma incluem integração com Android , desenvolvimento em F# e uso de VB .NET . Para solucionar problemas de implantação, consulte o guia de falha na implantação do pacote NuGet .
Como faço para baixar o pacote NuGet diretamente?
Baixe o IronPDF do site NuGet :
- Visite o pacote NuGet IronPDF
- Selecione "Baixar pacote"
- Clique duas vezes no pacote baixado.
- O pacote instala-se automaticamente
- Recarregar o Visual Studio
Como faço para baixar e instalar o arquivo DLL do IronPDF ?
Baixe o arquivo .DLL do IronPDF diretamente do site do IronPDF . Clique em Baixar DLL do IronPDF.
Faça referência ao IronPDF no projeto:
- Clique com o botão direito do mouse na solução no Explorador de Soluções.
- Selecione "Adicionar referência"
- Procure a biblioteca IronPDF.dll
- Clique em OK
A instalação do IronPDF está concluída. Para opções adicionais, incluindo implantação do Docker e configuração remota do mecanismo , consulte a visão geral da instalação . Para solucionar problemas, consulte o guia rápido de solução de problemas ou explore o desempenho inicial de renderização e a otimização do processo da GPU . O guia da pasta de tempos de execução ajuda no gerenciamento de dependências.
Como instalo o ExpertPDF?
Existem dois métodos de instalação:
- Usando o Gerenciador de Pacotes NuGet do Visual Studio
- Baixando assemblies (versões antigas do .NET )
Instale o ExpertPDF usando o Gerenciador de Pacotes NuGet para frameworks .NET modernos. Considere usar o IronPDF em vez do ExpertPDF para obter muito mais flexibilidade com métodos de instalação avançados e otimização do tamanho do pacote .
Como faço para instalar usando o Gerenciador de Pacotes NuGet do Visual Studio?
Acesse o Gerenciador de Pacotes NuGet :
- Ferramentas do Menu do Projeto
-
Clique com o botão direito do mouse no projeto no Explorador de Soluções.
Procure o pacote NuGet ExpertPDF e instale-o. Para uma configuração melhorada, considere o guia de declaração usando do IronPDF.
Nota: IronPDF oferece suporte a Windows, Linux e macOS, oferecendo cobertura de plataforma mais ampla do que ExpertPDF, que não documenta suporte para Linux ou macOS. Para implantações em nuvem, o IronPDF oferece integração com o Azure e suporte ao AWS Lambda . O IronPDF oferece orientações completas para otimização de desempenho e gerenciamento de memória . Para plataformas específicas, consulte Suporte para Red Hat Enterprise Linux e AWS Lambda no Amazon Linux 2 .
Como faço para criar um PDF a partir de uma URL?
Ambas as bibliotecas convertem HTML para PDF. Consulte o guia em PDF no link para obter mais detalhes. Sites complexos podem exigir atrasos de renderização personalizados ou tratamento da execução de JavaScript . Para sites autenticados, consulte o guia de logins de sites e sistemas TLS . O IronPDF se destaca na conversão de HTML para PDF com precisão de pixels, utilizando a renderização do Chrome .
Como o IronPDF converte URLs em PDF?
O IronPDF renderiza HTML a partir de URLs como PDF de forma eficiente. A biblioteca oferece suporte de alto nível para CSS , JavaScript , imagens e formulários . O uso do mecanismo de renderização do Chrome garante uma conversão de HTML para PDF com perfeição de pixels . Para problemas de renderização, consulte o guia de formatação HTML perfeita em pixels . As opções avançadas de renderização incluem tamanhos de papel personalizados e configuração da área de visualização . O ouvinte de mensagens JavaScript permite o processamento dinâmico de conteúdo.
Este exemplo de código mostra como o IronPDF permite que os desenvolvedores criem PDFs a partir de URLs de sites:
// Import the IronPdf library
using IronPdf;
// Initialize a new renderer
ChromePdfRenderer renderer = new ChromePdfRenderer();
// Render the specified URL as a PDF
var pdf = renderer.RenderUrlAsPdf("___PROTECTED_URL_190___");
// Save the rendered PDF to a file
pdf.SaveAs("url.pdf");// Import the IronPdf library
using IronPdf;
// Initialize a new renderer
ChromePdfRenderer renderer = new ChromePdfRenderer();
// Render the specified URL as a PDF
var pdf = renderer.RenderUrlAsPdf("___PROTECTED_URL_190___");
// Save the rendered PDF to a file
pdf.SaveAs("url.pdf");' Import the IronPdf library
Imports IronPdf
' Initialize a new renderer
Dim renderer As New ChromePdfRenderer()
' Render the specified URL as a PDF
Dim pdf = renderer.RenderUrlAsPdf("___PROTECTED_URL_190___")
' Save the rendered PDF to a file
pdf.SaveAs("url.pdf")Para URLs autenticadas, consulte o guia de logins de sites e sistemas TLS . Configure cookies e cabeçalhos HTTP personalizados para solicitações autenticadas. Sites seguros podem exigir autenticação Kerberos . Para depurar, use o guia de depuração do Chrome . Exemplos adicionais mostram a conversão de URLs para PDF .
Como o ExpertPDF converte URLs em PDF?
ExpertPDF converte URLs usando o método savePdfFromUrlToFile, preservando a formatação da página:
// Import the ExpertPdf.HtmlToPdf namespace
using ExpertPdf.HtmlToPdf;
// Initialize a new PdfConverter
PdfConverter pdfConverter = new PdfConverter();
// Use PdfConverter to save a webpage URL directly to a PDF file
pdfConverter.SavePdfFromUrlToFile("___PROTECTED_URL_191___", "output.pdf");// Import the ExpertPdf.HtmlToPdf namespace
using ExpertPdf.HtmlToPdf;
// Initialize a new PdfConverter
PdfConverter pdfConverter = new PdfConverter();
// Use PdfConverter to save a webpage URL directly to a PDF file
pdfConverter.SavePdfFromUrlToFile("___PROTECTED_URL_191___", "output.pdf");' Import the ExpertPdf.HtmlToPdf namespace
Imports ExpertPdf.HtmlToPdf
' Initialize a new PdfConverter
Dim pdfConverter As New PdfConverter()
' Use PdfConverter to save a webpage URL directly to a PDF file
pdfConverter.SavePdfFromUrlToFile("___PROTECTED_URL_191___", "output.pdf")Nos bastidores, o IronPDF usa seu motor de renderização do Chrome para fornecer melhor suporte HTML5 e CSS3.
Como criar um PDF a partir de uma string HTML?
Ambas as bibliotecas criam PDFs a partir de strings HTML. Consulte o guia de conversão de string HTML para PDF para obter mais detalhes. Use CSS para tela e impressão e incorpore fontes da web e fontes de ícones . O IronPDF oferece excelente suporte a Bootstrap e Flexbox CSS . O exemplo de utilização de HTML para criar um PDF demonstra a implementação prática.
Como o IronPDF converte uma string HTML em PDF?
Este exemplo de código mostra como o IronPDF permite que os desenvolvedores gerem documentos PDF a partir de strings HTML:
// Import the IronPdf library
using IronPdf;
// Initialize a new renderer
ChromePdfRenderer renderer = new ChromePdfRenderer();
// Render a PDF from HTML string and save it
var pdfDoc1 = renderer.RenderHtmlAsPdf("<h1>Html with CSS and Images</h1>");
pdfDoc1.SaveAs("pixel-perfect.pdf");
// Render HTML with external assets and save it
var pdfDoc2 = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
pdfDoc2.SaveAs("html-with-assets.pdf");// Import the IronPdf library
using IronPdf;
// Initialize a new renderer
ChromePdfRenderer renderer = new ChromePdfRenderer();
// Render a PDF from HTML string and save it
var pdfDoc1 = renderer.RenderHtmlAsPdf("<h1>Html with CSS and Images</h1>");
pdfDoc1.SaveAs("pixel-perfect.pdf");
// Render HTML with external assets and save it
var pdfDoc2 = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", @"C:\site\assets\");
pdfDoc2.SaveAs("html-with-assets.pdf");' Import the IronPdf library
Imports IronPdf
' Initialize a new renderer
Private renderer As New ChromePdfRenderer()
' Render a PDF from HTML string and save it
Private pdfDoc1 = renderer.RenderHtmlAsPdf("<h1>Html with CSS and Images</h1>")
pdfDoc1.SaveAs("pixel-perfect.pdf")
' Render HTML with external assets and save it
Dim pdfDoc2 = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", "C:\site\assets\")
pdfDoc2.SaveAs("html-with-assets.pdf")O IronPDF suporta URLs base para caminhos relativos e DataURIs para incorporar imagens. Para HTML complexo, consulte o guia de conversão de arquivo HTML para PDF . Para configurações específicas de viewport, consulte o guia de configurações de viewport e zoom . A biblioteca lida perfeitamente com idiomas internacionais e UTF-8 . Os recursos avançados incluem configurações de renderização HTML e conversão responsiva de HTML para PDF .
Como o ExpertPDF converte uma string HTML em PDF?
O conversor ExpertPDF de HTML para PDF suporta a conversão de strings HTML:
// Import the ExpertPdf.HtmlToPdf namespace
using ExpertPdf.HtmlToPdf;
// Initialize a new PdfConverter
PdfConverter pdfConverter = new PdfConverter();
// Use PdfConverter to save an HTML string to a PDF file
pdfConverter.SavePdfFromHtmlStringToFile("<h1>PDF using Expert PDF</h1>", "html-to-pdf.pdf");// Import the ExpertPdf.HtmlToPdf namespace
using ExpertPdf.HtmlToPdf;
// Initialize a new PdfConverter
PdfConverter pdfConverter = new PdfConverter();
// Use PdfConverter to save an HTML string to a PDF file
pdfConverter.SavePdfFromHtmlStringToFile("<h1>PDF using Expert PDF</h1>", "html-to-pdf.pdf");' Import the ExpertPdf.HtmlToPdf namespace
Imports ExpertPdf.HtmlToPdf
' Initialize a new PdfConverter
Private pdfConverter As New PdfConverter()
' Use PdfConverter to save an HTML string to a PDF file
pdfConverter.SavePdfFromHtmlStringToFile("<h1>PDF using Expert PDF</h1>", "html-to-pdf.pdf")O primeiro argumento especifica a string HTML, o segundo especifica o nome do arquivo de saída. Considere usar o suporte a Unicode e UTF-8 do IronPDF em vez da renderização HTML básica para obter um suporte muito maior a idiomas internacionais.
Como posso gerar PDFs de documentação técnica?
A documentação técnica se beneficia de layouts estruturados com exemplos de código. Esta demonstração do Bootstrap 5 mostra a capacidade do IronPDF de renderizar documentação com realce de sintaxe e alertas. Consulte o guia de suporte a CSS do Bootstrap e Flexbox para obter mais detalhes. O IronPDF oferece suporte ao gerenciamento de fontes e ao espaçamento entre letras para tipografia profissional. Para resultados melhorados, confira o guia de solução de problemas de fontes e suporte a idiomas internacionais.
using IronPdf;
var renderer = new ChromePdfRenderer();
string technicalDocs = @"
<!DOCTYPE html>
<html>
<head>
<meta charset='utf-8'>
<link href='___PROTECTED_URL_192___ rel='stylesheet'>
<style>
.code-block { background: #f8f9fa; border-left: 3px solid #0d6efd; padding: 15px; border-radius: 4px; }
.api-method { font-family: 'Courier New', monospace; color: #0d6efd; }
@media print { .card, .alert { page-break-inside: avoid; } }
</style>
</head>
<body class='bg-light'>
<div class='container py-4'>
<div class='card shadow-sm mb-4'>
<div class='card-header bg-dark text-white'>
<h2 class='mb-0'>API Reference - HTML to PDF Conversion</h2>
</div>
<div class='card-body'>
<h4>RenderHtmlAsPdf() Method</h4>
<p class='lead'>Converts HTML content to PDF with full CSS3 and JavaScript support.</p>
<div class='code-block mb-3'>
<code class='api-method'>PdfDocument RenderHtmlAsPdf(string htmlContent)</code>
</div>
<div class='row mt-4'>
<div class='col-md-6'>
<h5 class='text-primary'>Parameters</h5>
<table class='table table-sm table-bordered'>
<tr>
<td><code>htmlContent</code></td>
<td>String containing HTML to convert</td>
</tr>
</table>
</div>
<div class='col-md-6'>
<h5 class='text-success'>Returns</h5>
<table class='table table-sm table-bordered'>
<tr>
<td><code>PdfDocument</code></td>
<td>Generated PDF document object</td>
</tr>
</table>
</div>
</div>
</div>
</div>
<div class='row g-3 mb-4'>
<div class='col-md-4'>
<div class='alert alert-success mb-0'>
<h6 class='alert-heading'>✓ Supported Features</h6>
<ul class='mb-0 small'>
<li>HTML5 semantic tags</li>
<li>CSS3 with Flexbox/Grid</li>
<li>JavaScript execution</li>
<li>External stylesheets</li>
</ul>
</div>
</div>
<div class='col-md-4'>
<div class='alert alert-info mb-0'>
<h6 class='alert-heading'>ⓘ Rendering Engine</h6>
<ul class='mb-0 small'>
<li>Chrome V8 Engine</li>
<li>High-fidelity rendering</li>
<li>Fast HTML-to-PDF conversion</li>
<li>Async/await support</li>
</ul>
</div>
</div>
<div class='col-md-4'>
<div class='alert alert-warning mb-0'>
<h6 class='alert-heading'>ⓘ IronPDF Advantages</h6>
<ul class='mb-0 small'>
<li>Intuitive API design</li>
<li>Full CSS3 and JS support</li>
<li>Cross-platform deployment</li>
<li>Minimal configuration needed</li>
</ul>
</div>
</div>
</div>
<div class='card shadow-sm'>
<div class='card-header bg-primary text-white'>
<h5 class='mb-0'>Code Example Comparison</h5>
</div>
<div class='card-body'>
<div class='row'>
<div class='col-md-6'>
<h6 class='text-primary'>IronPDF (Simple)</h6>
<div class='code-block'>
<pre class='mb-0'><code>var renderer = new ChromePdfRenderer();
var pdf = renderer.RenderHtmlAsPdf(html);
pdf.SaveAs("output.pdf");</code></pre>
</div>
<div class='badge bg-success mt-2'>3 Lines</div>
</div>
<div class='col-md-6'>
<h6 class='text-warning'>ExpertPDF (Complex)</h6>
<div class='code-block'>
<pre class='mb-0'><code>var converter = new HtmlToPdfConverter();
converter.PdfDocumentOptions.PdfPageSize = PdfPageSize.A4;
converter.NavigationTimeout = 60;
byte[] result = converter.GetPdfBytesFromHtmlString(html);
File.WriteAllBytes("output.pdf", result);</code></pre>
</div>
<div class='badge bg-warning text-dark mt-2'>5+ Lines</div>
</div>
</div>
</div>
<div class='card-footer text-muted'>
<small><strong>Comparison:</strong> IronPDF provides a more intuitive API with less configuration overhead for common use cases.</small>
</div>
</div>
</div>
</body>
</html>";
var pdf = renderer.RenderHtmlAsPdf(technicalDocs);
pdf.SaveAs("technical-documentation.pdf");using IronPdf;
var renderer = new ChromePdfRenderer();
string technicalDocs = @"
<!DOCTYPE html>
<html>
<head>
<meta charset='utf-8'>
<link href='___PROTECTED_URL_192___ rel='stylesheet'>
<style>
.code-block { background: #f8f9fa; border-left: 3px solid #0d6efd; padding: 15px; border-radius: 4px; }
.api-method { font-family: 'Courier New', monospace; color: #0d6efd; }
@media print { .card, .alert { page-break-inside: avoid; } }
</style>
</head>
<body class='bg-light'>
<div class='container py-4'>
<div class='card shadow-sm mb-4'>
<div class='card-header bg-dark text-white'>
<h2 class='mb-0'>API Reference - HTML to PDF Conversion</h2>
</div>
<div class='card-body'>
<h4>RenderHtmlAsPdf() Method</h4>
<p class='lead'>Converts HTML content to PDF with full CSS3 and JavaScript support.</p>
<div class='code-block mb-3'>
<code class='api-method'>PdfDocument RenderHtmlAsPdf(string htmlContent)</code>
</div>
<div class='row mt-4'>
<div class='col-md-6'>
<h5 class='text-primary'>Parameters</h5>
<table class='table table-sm table-bordered'>
<tr>
<td><code>htmlContent</code></td>
<td>String containing HTML to convert</td>
</tr>
</table>
</div>
<div class='col-md-6'>
<h5 class='text-success'>Returns</h5>
<table class='table table-sm table-bordered'>
<tr>
<td><code>PdfDocument</code></td>
<td>Generated PDF document object</td>
</tr>
</table>
</div>
</div>
</div>
</div>
<div class='row g-3 mb-4'>
<div class='col-md-4'>
<div class='alert alert-success mb-0'>
<h6 class='alert-heading'>✓ Supported Features</h6>
<ul class='mb-0 small'>
<li>HTML5 semantic tags</li>
<li>CSS3 with Flexbox/Grid</li>
<li>JavaScript execution</li>
<li>External stylesheets</li>
</ul>
</div>
</div>
<div class='col-md-4'>
<div class='alert alert-info mb-0'>
<h6 class='alert-heading'>ⓘ Rendering Engine</h6>
<ul class='mb-0 small'>
<li>Chrome V8 Engine</li>
<li>High-fidelity rendering</li>
<li>Fast HTML-to-PDF conversion</li>
<li>Async/await support</li>
</ul>
</div>
</div>
<div class='col-md-4'>
<div class='alert alert-warning mb-0'>
<h6 class='alert-heading'>ⓘ IronPDF Advantages</h6>
<ul class='mb-0 small'>
<li>Intuitive API design</li>
<li>Full CSS3 and JS support</li>
<li>Cross-platform deployment</li>
<li>Minimal configuration needed</li>
</ul>
</div>
</div>
</div>
<div class='card shadow-sm'>
<div class='card-header bg-primary text-white'>
<h5 class='mb-0'>Code Example Comparison</h5>
</div>
<div class='card-body'>
<div class='row'>
<div class='col-md-6'>
<h6 class='text-primary'>IronPDF (Simple)</h6>
<div class='code-block'>
<pre class='mb-0'><code>var renderer = new ChromePdfRenderer();
var pdf = renderer.RenderHtmlAsPdf(html);
pdf.SaveAs("output.pdf");</code></pre>
</div>
<div class='badge bg-success mt-2'>3 Lines</div>
</div>
<div class='col-md-6'>
<h6 class='text-warning'>ExpertPDF (Complex)</h6>
<div class='code-block'>
<pre class='mb-0'><code>var converter = new HtmlToPdfConverter();
converter.PdfDocumentOptions.PdfPageSize = PdfPageSize.A4;
converter.NavigationTimeout = 60;
byte[] result = converter.GetPdfBytesFromHtmlString(html);
File.WriteAllBytes("output.pdf", result);</code></pre>
</div>
<div class='badge bg-warning text-dark mt-2'>5+ Lines</div>
</div>
</div>
</div>
<div class='card-footer text-muted'>
<small><strong>Comparison:</strong> IronPDF provides a more intuitive API with less configuration overhead for common use cases.</small>
</div>
</div>
</div>
</body>
</html>";
var pdf = renderer.RenderHtmlAsPdf(technicalDocs);
pdf.SaveAs("technical-documentation.pdf");Imports IronPdf
Dim renderer As New ChromePdfRenderer()
Dim technicalDocs As String = "
<!DOCTYPE html>
<html>
<head>
<meta charset='utf-8'>
<link href='___PROTECTED_URL_192___ rel='stylesheet'>
<style>
.code-block { background: #f8f9fa; border-left: 3px solid #0d6efd; padding: 15px; border-radius: 4px; }
.api-method { font-family: 'Courier New', monospace; color: #0d6efd; }
@media print { .card, .alert { page-break-inside: avoid; } }
</style>
</head>
<body class='bg-light'>
<div class='container py-4'>
<div class='card shadow-sm mb-4'>
<div class='card-header bg-dark text-white'>
<h2 class='mb-0'>API Reference - HTML to PDF Conversion</h2>
</div>
<div class='card-body'>
<h4>RenderHtmlAsPdf() Method</h4>
<p class='lead'>Converts HTML content to PDF with full CSS3 and JavaScript support.</p>
<div class='code-block mb-3'>
<code class='api-method'>PdfDocument RenderHtmlAsPdf(string htmlContent)</code>
</div>
<div class='row mt-4'>
<div class='col-md-6'>
<h5 class='text-primary'>Parameters</h5>
<table class='table table-sm table-bordered'>
<tr>
<td><code>htmlContent</code></td>
<td>String containing HTML to convert</td>
</tr>
</table>
</div>
<div class='col-md-6'>
<h5 class='text-success'>Returns</h5>
<table class='table table-sm table-bordered'>
<tr>
<td><code>PdfDocument</code></td>
<td>Generated PDF document object</td>
</tr>
</table>
</div>
</div>
</div>
</div>
<div class='row g-3 mb-4'>
<div class='col-md-4'>
<div class='alert alert-success mb-0'>
<h6 class='alert-heading'>✓ Supported Features</h6>
<ul class='mb-0 small'>
<li>HTML5 semantic tags</li>
<li>CSS3 with Flexbox/Grid</li>
<li>JavaScript execution</li>
<li>External stylesheets</li>
</ul>
</div>
</div>
<div class='col-md-4'>
<div class='alert alert-info mb-0'>
<h6 class='alert-heading'>ⓘ Rendering Engine</h6>
<ul class='mb-0 small'>
<li>Chrome V8 Engine</li>
<li>High-fidelity rendering</li>
<li>Fast HTML-to-PDF conversion</li>
<li>Async/await support</li>
</ul>
</div>
</div>
<div class='col-md-4'>
<div class='alert alert-warning mb-0'>
<h6 class='alert-heading'>ⓘ IronPDF Advantages</h6>
<ul class='mb-0 small'>
<li>Intuitive API design</li>
<li>Full CSS3 and JS support</li>
<li>Cross-platform deployment</li>
<li>Minimal configuration needed</li>
</ul>
</div>
</div>
</div>
<div class='card shadow-sm'>
<div class='card-header bg-primary text-white'>
<h5 class='mb-0'>Code Example Comparison</h5>
</div>
<div class='card-body'>
<div class='row'>
<div class='col-md-6'>
<h6 class='text-primary'>IronPDF (Simple)</h6>
<div class='code-block'>
<pre class='mb-0'><code>var renderer = new ChromePdfRenderer();
var pdf = renderer.RenderHtmlAsPdf(html);
pdf.SaveAs(""output.pdf"");</code></pre>
</div>
<div class='badge bg-success mt-2'>3 Lines</div>
</div>
<div class='col-md-6'>
<h6 class='text-warning'>ExpertPDF (Complex)</h6>
<div class='code-block'>
<pre class='mb-0'><code>var converter = new HtmlToPdfConverter();
converter.PdfDocumentOptions.PdfPageSize = PdfPageSize.A4;
converter.NavigationTimeout = 60;
byte[] result = converter.GetPdfBytesFromHtmlString(html);
File.WriteAllBytes(""output.pdf"", result);</code></pre>
</div>
<div class='badge bg-warning text-dark mt-2'>5+ Lines</div>
</div>
</div>
</div>
<div class='card-footer text-muted'>
<small><strong>Comparison:</strong> IronPDF provides a more intuitive API with less configuration overhead for common use cases.</small>
</div>
</div>
</div>
</body>
</html>"
Dim pdf = renderer.RenderHtmlAsPdf(technicalDocs)
pdf.SaveAs("technical-documentation.pdf")Resultado: Um PDF de documentação técnica profissional com cartões, alertas, tabelas e blocos de código do Bootstrap 5. O IronPDF renderiza com precisão toda a tipografia, espaçamento e layouts de grade, demonstrando capacidades superiores de geração de documentação.
Como posso criar relatórios financeiros com layouts complexos?
A elaboração de relatórios financeiros exige formatação precisa de tabelas e cálculos. Este exemplo demonstra a renderização de layouts financeiros complexos do IronPDF com CSS Grid e JavaScript dinâmico. Consulte o guia JavaScript em PDFs , incluindo a execução personalizada de JavaScript, para obter mais detalhes. Documentos financeiros podem precisar de compressão PDF para otimização de arquivos e gerenciamento de metadados para fins de conformidade. O guia de renderização de gráficos em PDFs auxilia na visualização de dados.
using IronPdf;
var renderer = new ChromePdfRenderer();
// Enable JavaScript for dynamic calculations
renderer.RenderingOptions.EnableJavaScript = true;
renderer.RenderingOptions.RenderDelay = 500; // Allow JS to execute
string financialReport = @"
<!DOCTYPE html>
<html>
<head>
<meta charset='utf-8'>
<style>
@page { size: A4; margin: 20mm; }
body { font-family: Arial, sans-serif; line-height: 1.6; }
.header { text-align: center; margin-bottom: 30px; }
.financial-grid { display: grid; grid-template-columns: 2fr 1fr 1fr; gap: 10px; margin-bottom: 20px; }
.grid-header { background: #2c3e50; color: white; padding: 10px; font-weight: bold; }
.grid-row { padding: 10px; border-bottom: 1px solid #ddd; }
.grid-row:hover { background: #f9f9f9; }
.amount { text-align: right; font-family: 'Courier New', monospace; }
.positive { color: #27ae60; }
.negative { color: #e74c3c; }
.total-row { background: #ecf0f1; font-weight: bold; margin-top: 10px; }
.footer-note { font-size: 0.8em; color: #666; margin-top: 30px; text-align: center; }
@media print {
.grid-row:hover { background: transparent; }
.financial-grid { page-break-inside: avoid; }
}
</style>
</head>
<body>
<div class='header'>
<h1>Quarterly Financial Report</h1>
<p>Q4 2023 - Consolidated Statement</p>
</div>
<div class='financial-grid'>
<div class='grid-header'>Revenue Stream</div>
<div class='grid-header amount'>Q3 2023</div>
<div class='grid-header amount'>Q4 2023</div>
<div class='grid-row'>Software Licenses</div>
<div class='grid-row amount'>$2,150,000</div>
<div class='grid-row amount positive'>$2,875,000</div>
<div class='grid-row'>Support Services</div>
<div class='grid-row amount'>$850,000</div>
<div class='grid-row amount positive'>$975,000</div>
<div class='grid-row'>Consulting</div>
<div class='grid-row amount'>$425,000</div>
<div class='grid-row amount negative'>$380,000</div>
<div class='grid-row total-row'>Total Revenue</div>
<div class='grid-row total-row amount'>$3,425,000</div>
<div class='grid-row total-row amount positive' id='total'>$4,230,000</div>
</div>
<div class='financial-grid'>
<div class='grid-header'>Operating Expenses</div>
<div class='grid-header amount'>Q3 2023</div>
<div class='grid-header amount'>Q4 2023</div>
<div class='grid-row'>R&D</div>
<div class='grid-row amount'>$1,200,000</div>
<div class='grid-row amount'>$1,350,000</div>
<div class='grid-row'>Sales & Marketing</div>
<div class='grid-row amount'>$800,000</div>
<div class='grid-row amount'>$950,000</div>
<div class='grid-row'>General & Admin</div>
<div class='grid-row amount'>$400,000</div>
<div class='grid-row amount'>$425,000</div>
<div class='grid-row total-row'>Total Expenses</div>
<div class='grid-row total-row amount'>$2,400,000</div>
<div class='grid-row total-row amount'>$2,725,000</div>
</div>
<script>
// Calculate growth percentage
const q3Total = 3425000;
const q4Total = 4230000;
const growth = ((q4Total - q3Total) / q3Total * 100).toFixed(1);
// Add growth indicator
const totalEl = document.getElementById('total');
totalEl.innerHTML += ` <small>(+${growth}%)</small>`;
</script>
<div class='footer-note'>
<p>This report was generated using IronPDF's advanced rendering engine.<br>
All financial figures are in USD. Report generated on: <span id='date'></span></p>
</div>
<script>
document.getElementById('date').textContent = new Date().toLocaleDateString();
</script>
</body>
</html>";
var pdf = renderer.RenderHtmlAsPdf(financialReport);
pdf.SaveAs("financial-report.pdf");using IronPdf;
var renderer = new ChromePdfRenderer();
// Enable JavaScript for dynamic calculations
renderer.RenderingOptions.EnableJavaScript = true;
renderer.RenderingOptions.RenderDelay = 500; // Allow JS to execute
string financialReport = @"
<!DOCTYPE html>
<html>
<head>
<meta charset='utf-8'>
<style>
@page { size: A4; margin: 20mm; }
body { font-family: Arial, sans-serif; line-height: 1.6; }
.header { text-align: center; margin-bottom: 30px; }
.financial-grid { display: grid; grid-template-columns: 2fr 1fr 1fr; gap: 10px; margin-bottom: 20px; }
.grid-header { background: #2c3e50; color: white; padding: 10px; font-weight: bold; }
.grid-row { padding: 10px; border-bottom: 1px solid #ddd; }
.grid-row:hover { background: #f9f9f9; }
.amount { text-align: right; font-family: 'Courier New', monospace; }
.positive { color: #27ae60; }
.negative { color: #e74c3c; }
.total-row { background: #ecf0f1; font-weight: bold; margin-top: 10px; }
.footer-note { font-size: 0.8em; color: #666; margin-top: 30px; text-align: center; }
@media print {
.grid-row:hover { background: transparent; }
.financial-grid { page-break-inside: avoid; }
}
</style>
</head>
<body>
<div class='header'>
<h1>Quarterly Financial Report</h1>
<p>Q4 2023 - Consolidated Statement</p>
</div>
<div class='financial-grid'>
<div class='grid-header'>Revenue Stream</div>
<div class='grid-header amount'>Q3 2023</div>
<div class='grid-header amount'>Q4 2023</div>
<div class='grid-row'>Software Licenses</div>
<div class='grid-row amount'>$2,150,000</div>
<div class='grid-row amount positive'>$2,875,000</div>
<div class='grid-row'>Support Services</div>
<div class='grid-row amount'>$850,000</div>
<div class='grid-row amount positive'>$975,000</div>
<div class='grid-row'>Consulting</div>
<div class='grid-row amount'>$425,000</div>
<div class='grid-row amount negative'>$380,000</div>
<div class='grid-row total-row'>Total Revenue</div>
<div class='grid-row total-row amount'>$3,425,000</div>
<div class='grid-row total-row amount positive' id='total'>$4,230,000</div>
</div>
<div class='financial-grid'>
<div class='grid-header'>Operating Expenses</div>
<div class='grid-header amount'>Q3 2023</div>
<div class='grid-header amount'>Q4 2023</div>
<div class='grid-row'>R&D</div>
<div class='grid-row amount'>$1,200,000</div>
<div class='grid-row amount'>$1,350,000</div>
<div class='grid-row'>Sales & Marketing</div>
<div class='grid-row amount'>$800,000</div>
<div class='grid-row amount'>$950,000</div>
<div class='grid-row'>General & Admin</div>
<div class='grid-row amount'>$400,000</div>
<div class='grid-row amount'>$425,000</div>
<div class='grid-row total-row'>Total Expenses</div>
<div class='grid-row total-row amount'>$2,400,000</div>
<div class='grid-row total-row amount'>$2,725,000</div>
</div>
<script>
// Calculate growth percentage
const q3Total = 3425000;
const q4Total = 4230000;
const growth = ((q4Total - q3Total) / q3Total * 100).toFixed(1);
// Add growth indicator
const totalEl = document.getElementById('total');
totalEl.innerHTML += ` <small>(+${growth}%)</small>`;
</script>
<div class='footer-note'>
<p>This report was generated using IronPDF's advanced rendering engine.<br>
All financial figures are in USD. Report generated on: <span id='date'></span></p>
</div>
<script>
document.getElementById('date').textContent = new Date().toLocaleDateString();
</script>
</body>
</html>";
var pdf = renderer.RenderHtmlAsPdf(financialReport);
pdf.SaveAs("financial-report.pdf");Imports IronPdf
Dim renderer As New ChromePdfRenderer()
' Enable JavaScript for dynamic calculations
renderer.RenderingOptions.EnableJavaScript = True
renderer.RenderingOptions.RenderDelay = 500 ' Allow JS to execute
Dim financialReport As String = "
<!DOCTYPE html>
<html>
<head>
<meta charset='utf-8'>
<style>
@page { size: A4; margin: 20mm; }
body { font-family: Arial, sans-serif; line-height: 1.6; }
.header { text-align: center; margin-bottom: 30px; }
.financial-grid { display: grid; grid-template-columns: 2fr 1fr 1fr; gap: 10px; margin-bottom: 20px; }
.grid-header { background: #2c3e50; color: white; padding: 10px; font-weight: bold; }
.grid-row { padding: 10px; border-bottom: 1px solid #ddd; }
.grid-row:hover { background: #f9f9f9; }
.amount { text-align: right; font-family: 'Courier New', monospace; }
.positive { color: #27ae60; }
.negative { color: #e74c3c; }
.total-row { background: #ecf0f1; font-weight: bold; margin-top: 10px; }
.footer-note { font-size: 0.8em; color: #666; margin-top: 30px; text-align: center; }
@media print {
.grid-row:hover { background: transparent; }
.financial-grid { page-break-inside: avoid; }
}
</style>
</head>
<body>
<div class='header'>
<h1>Quarterly Financial Report</h1>
<p>Q4 2023 - Consolidated Statement</p>
</div>
<div class='financial-grid'>
<div class='grid-header'>Revenue Stream</div>
<div class='grid-header amount'>Q3 2023</div>
<div class='grid-header amount'>Q4 2023</div>
<div class='grid-row'>Software Licenses</div>
<div class='grid-row amount'>$2,150,000</div>
<div class='grid-row amount positive'>$2,875,000</div>
<div class='grid-row'>Support Services</div>
<div class='grid-row amount'>$850,000</div>
<div class='grid-row amount positive'>$975,000</div>
<div class='grid-row'>Consulting</div>
<div class='grid-row amount'>$425,000</div>
<div class='grid-row amount negative'>$380,000</div>
<div class='grid-row total-row'>Total Revenue</div>
<div class='grid-row total-row amount'>$3,425,000</div>
<div class='grid-row total-row amount positive' id='total'>$4,230,000</div>
</div>
<div class='financial-grid'>
<div class='grid-header'>Operating Expenses</div>
<div class='grid-header amount'>Q3 2023</div>
<div class='grid-header amount'>Q4 2023</div>
<div class='grid-row'>R&D</div>
<div class='grid-row amount'>$1,200,000</div>
<div class='grid-row amount'>$1,350,000</div>
<div class='grid-row'>Sales & Marketing</div>
<div class='grid-row amount'>$800,000</div>
<div class='grid-row amount'>$950,000</div>
<div class='grid-row'>General & Admin</div>
<div class='grid-row amount'>$400,000</div>
<div class='grid-row amount'>$425,000</div>
<div class='grid-row total-row'>Total Expenses</div>
<div class='grid-row total-row amount'>$2,400,000</div>
<div class='grid-row total-row amount'>$2,725,000</div>
</div>
<script>
// Calculate growth percentage
const q3Total = 3425000;
const q4Total = 4230000;
const growth = ((q4Total - q3Total) / q3Total * 100).toFixed(1);
// Add growth indicator
const totalEl = document.getElementById('total');
totalEl.innerHTML += ` <small>(+${growth}%)</small>`;
</script>
<div class='footer-note'>
<p>This report was generated using IronPDF's advanced rendering engine.<br>
All financial figures are in USD. Report generated on: <span id='date'></span></p>
</div>
<script>
document.getElementById('date').textContent = new Date().toLocaleDateString();
</script>
</body>
</html>"
Dim pdf = renderer.RenderHtmlAsPdf(financialReport)
pdf.SaveAs("financial-report.pdf")Este exemplo de código mostra como o IronPDF permite que os desenvolvedores usem layouts CSS Grid , execução de JavaScript e CSS específico para impressão . Adicione cabeçalhos e rodapés personalizados aos relatórios, implemente planos de fundo e primeiros planos para identidade visual, marcas d'água para segurança e assinaturas digitais para autenticação. Consulte o guia de geração de relatórios em PDF para obter mais detalhes.
Como faço para mesclar vários arquivos PDF em um único PDF?
Ambas as bibliotecas combinam vários PDFs em documentos únicos, consolidando os dados para uma transmissão eficiente. Consulte o guia de mesclagem ou divisão de PDFs para obter mais detalhes. Documentos com várias páginas podem exigir gerenciamento de páginas ou divisão de PDFs com várias páginas . Para otimizar o desempenho com arquivos grandes, considere a geração assíncrona de PDFs ou o processamento paralelo . O exemplo de fusão de dois ou mais PDFs fornece uma implementação prática. Para organizar PDFs , o IronPDF oferece ferramentas completas.
Como o IronPDF mescla arquivos PDF?
Este exemplo de código mostra como o IronPDF permite que os desenvolvedores renderizem dois PDFs a partir de strings HTML e os mesclem. A abordagem direta oferece opções de configuração adicionais. Para informações sobre números de página e quebras de página em documentos mesclados, consulte os respectivos guias. Copie também páginas entre PDFs para um controle mais preciso. Para obter informações sobre formulários, consulte a documentação sobre gerenciamento e edição de formulários . O exemplo de numeração e quebra de páginas mostra uma implementação combinada.
// Import the IronPdf library
using IronPdf;
// Define HTML strings to convert to PDF
var htmlA = @"<p> [PDF_A] </p>
<p> [PDF_A] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_A] 2nd Page</p>";
var htmlB = @"<p> [PDF_B] </p>
<p> [PDF_B] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_B] 2nd Page</p>";
// Initialize a new renderer
var renderer = new ChromePdfRenderer();
// Render HTML strings as PDFs
var pdfDocA = renderer.RenderHtmlAsPdf(htmlA);
var pdfDocB = renderer.RenderHtmlAsPdf(htmlB);
// Merge the PDF documents
var mergedPdf = PdfDocument.Merge(pdfDocA, pdfDocB);
// Save the merged PDF
mergedPdf.SaveAs("Merged.pdf");// Import the IronPdf library
using IronPdf;
// Define HTML strings to convert to PDF
var htmlA = @"<p> [PDF_A] </p>
<p> [PDF_A] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_A] 2nd Page</p>";
var htmlB = @"<p> [PDF_B] </p>
<p> [PDF_B] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_B] 2nd Page</p>";
// Initialize a new renderer
var renderer = new ChromePdfRenderer();
// Render HTML strings as PDFs
var pdfDocA = renderer.RenderHtmlAsPdf(htmlA);
var pdfDocB = renderer.RenderHtmlAsPdf(htmlB);
// Merge the PDF documents
var mergedPdf = PdfDocument.Merge(pdfDocA, pdfDocB);
// Save the merged PDF
mergedPdf.SaveAs("Merged.pdf");' Import the IronPdf library
Imports IronPdf
' Define HTML strings to convert to PDF
Private htmlA = "<p> [PDF_A] </p>
<p> [PDF_A] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_A] 2nd Page</p>"
Private htmlB = "<p> [PDF_B] </p>
<p> [PDF_B] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_B] 2nd Page</p>"
' Initialize a new renderer
Private renderer = New ChromePdfRenderer()
' Render HTML strings as PDFs
Private pdfDocA = renderer.RenderHtmlAsPdf(htmlA)
Private pdfDocB = renderer.RenderHtmlAsPdf(htmlB)
' Merge the PDF documents
Private mergedPdf = PdfDocument.Merge(pdfDocA, pdfDocB)
' Save the merged PDF
mergedPdf.SaveAs("Merged.pdf")O método Merge aceita múltiplos documentos como objetos Enumerable. Veja o exemplo de código IronPDF para mesclar PDFs . Para adicionar capas ou criar um sumário , consulte os guias específicos. Você também pode adicionar novos conteúdos ou anexos . O exemplo de dividir um PDF e extrair páginas demonstra operações inversas.
Observe que os PDFs mesclados que contêm formulários editáveis têm os nomes dos campos do formulário acrescidos de números de índice. Consulte o guia de tratamento de dados do formulário para obter mais detalhes.
Como o ExpertPDF mescla arquivos PDF?
O ExpertPDF utiliza um componente de mesclagem de PDF que requer instalação separada. O método AppendPDFFile anexa arquivos a objetos PDFMerge:
// Import the ExpertPdf.MergePdf namespace
using ExpertPdf.MergePdf;
// Initialize a new PDFMerge object
PDFMerge pdfMerge = new PDFMerge();
// Append PDF files to the merge object
pdfMerge.AppendPDFFile("output.pdf");
pdfMerge.AppendPDFFile("html-to-pdf.pdf");
// Save the merged PDF to a file
pdfMerge.SaveMergedPDFToFile("merged.pdf");// Import the ExpertPdf.MergePdf namespace
using ExpertPdf.MergePdf;
// Initialize a new PDFMerge object
PDFMerge pdfMerge = new PDFMerge();
// Append PDF files to the merge object
pdfMerge.AppendPDFFile("output.pdf");
pdfMerge.AppendPDFFile("html-to-pdf.pdf");
// Save the merged PDF to a file
pdfMerge.SaveMergedPDFToFile("merged.pdf");' Import the ExpertPdf.MergePdf namespace
Imports ExpertPdf.MergePdf
' Initialize a new PDFMerge object
Private pdfMerge As New PDFMerge()
' Append PDF files to the merge object
pdfMerge.AppendPDFFile("output.pdf")
pdfMerge.AppendPDFFile("html-to-pdf.pdf")
' Save the merged PDF to a file
pdfMerge.SaveMergedPDFToFile("merged.pdf")Nos bastidores, o IronPDF usa algoritmos de fusão mais eficientes. Considere usar a geração assíncrona de PDFs e a geração multithread do IronPDF em vez de operações síncronas para obter um desempenho muito superior.
Como posso implementar a fusão avançada de PDFs com organização de documentos?
Aplicações empresariais exigem recursos avançados, como marcadores, organização de páginas e preservação de metadados, ao mesclar PDFs. Este exemplo demonstra o gerenciamento de favoritos , o tratamento de metadados e a organização de documentos. Para garantir a conformidade, implemente o histórico de revisões , a conversão para PDF/A e a acessibilidade para PDF/UA . O exemplo de estrutura de tópicos e marcadores fornece detalhes adicionais de implementação. Consulte o guia de configuração e edição de metadados e a seção de solução de problemas de visibilidade de metadados para obter mais detalhes.
using IronPdf;
using System.Collections.Generic;
using System.Linq;
public class AdvancedPdfMerger
{
public static void MergeDocumentsWithBookmarks()
{
var renderer = new ChromePdfRenderer();
var documentsToMerge = new List<PdfDocument>();
// Create chapter PDFs with proper structure
string[] chapters = { "Introduction", "Technical Overview", "Implementation", "Conclusion" };
foreach (var chapter in chapters)
{
string html = $@"
<html>
<head>
<style>
body {{font-family: Georgia, serif; margin: 40px;}}
h1 {{color: #2c3e50; border-bottom: 2px solid #3498db; padding-bottom: 10px;}}
.chapter-number {{color: #7f8c8d; font-size: 0.8em;}}
</style>
</head>
<body>
<h1><span class='chapter-number'>Chapter {Array.IndexOf(chapters, chapter) + 1}</span><br>{chapter}</h1>
<p>This is the content for the {chapter} chapter. In a real document, this would contain
extensive content, diagrams, and detailed explanations.</p>
<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit. Sed do eiusmod tempor
incididunt ut labore et dolore magna aliqua.</p>
</body>
</html>";
var pdf = renderer.RenderHtmlAsPdf(html);
// Add metadata to each chapter
pdf.MetaData.Title = $"Chapter: {chapter}";
pdf.MetaData.Author = "Technical Documentation Team";
pdf.MetaData.Subject = "Enterprise PDF Generation";
documentsToMerge.Add(pdf);
}
// Create a table of contents
string tocHtml = @"
<html>
<head>
<style>
body { font-family: Georgia, serif; margin: 40px; }
h1 { text-align: center; color: #2c3e50; margin-bottom: 40px; }
.toc-entry { margin: 15px 0; font-size: 1.1em; }
.toc-entry a { text-decoration: none; color: #3498db; }
.page-number { float: right; color: #7f8c8d; }
</style>
</head>
<body>
<h1>Table of Contents</h1>";
int pageNumber = 2; // Starting after TOC page
foreach (var chapter in chapters)
{
tocHtml += $@"
<div class='toc-entry'>
<a href='#'>Chapter {Array.IndexOf(chapters, chapter) + 1}: {chapter}</a>
<span class='page-number'>{pageNumber}</span>
</div>";
pageNumber += 2; // Assuming each chapter is 2 pages
}
tocHtml += @"
</body>
</html>";
var tocPdf = renderer.RenderHtmlAsPdf(tocHtml);
// Merge all documents with TOC first
var allDocuments = new List<PdfDocument> { tocPdf };
allDocuments.AddRange(documentsToMerge);
var finalPdf = PdfDocument.Merge(allDocuments);
// Add bookmarks for navigation
finalPdf.BookMarks.AddBookMarkAtStart("Table of Contents", 0);
int currentPage = 1; // After TOC
foreach (var chapter in chapters)
{
finalPdf.BookMarks.AddBookMarkAtStart($"Chapter {Array.IndexOf(chapters, chapter) + 1}: {chapter}", currentPage);
currentPage += 2;
}
// Set document properties
finalPdf.MetaData.Title = "Complete Technical Documentation";
finalPdf.MetaData.Keywords = "IronPDF, Documentation, Enterprise, .NET";
finalPdf.MetaData.CreationDate = System.DateTime.Now;
// Add page numbers to footer
finalPdf.AddTextFooters("Page {page} of {total-pages}",
new ChromePdfRenderer.ChromePdfRenderOptions()
{
MarginBottom = 20,
MarginLeft = 50,
MarginRight = 50
});
finalPdf.SaveAs("advanced-merged-document.pdf");
}
}using IronPdf;
using System.Collections.Generic;
using System.Linq;
public class AdvancedPdfMerger
{
public static void MergeDocumentsWithBookmarks()
{
var renderer = new ChromePdfRenderer();
var documentsToMerge = new List<PdfDocument>();
// Create chapter PDFs with proper structure
string[] chapters = { "Introduction", "Technical Overview", "Implementation", "Conclusion" };
foreach (var chapter in chapters)
{
string html = $@"
<html>
<head>
<style>
body {{font-family: Georgia, serif; margin: 40px;}}
h1 {{color: #2c3e50; border-bottom: 2px solid #3498db; padding-bottom: 10px;}}
.chapter-number {{color: #7f8c8d; font-size: 0.8em;}}
</style>
</head>
<body>
<h1><span class='chapter-number'>Chapter {Array.IndexOf(chapters, chapter) + 1}</span><br>{chapter}</h1>
<p>This is the content for the {chapter} chapter. In a real document, this would contain
extensive content, diagrams, and detailed explanations.</p>
<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit. Sed do eiusmod tempor
incididunt ut labore et dolore magna aliqua.</p>
</body>
</html>";
var pdf = renderer.RenderHtmlAsPdf(html);
// Add metadata to each chapter
pdf.MetaData.Title = $"Chapter: {chapter}";
pdf.MetaData.Author = "Technical Documentation Team";
pdf.MetaData.Subject = "Enterprise PDF Generation";
documentsToMerge.Add(pdf);
}
// Create a table of contents
string tocHtml = @"
<html>
<head>
<style>
body { font-family: Georgia, serif; margin: 40px; }
h1 { text-align: center; color: #2c3e50; margin-bottom: 40px; }
.toc-entry { margin: 15px 0; font-size: 1.1em; }
.toc-entry a { text-decoration: none; color: #3498db; }
.page-number { float: right; color: #7f8c8d; }
</style>
</head>
<body>
<h1>Table of Contents</h1>";
int pageNumber = 2; // Starting after TOC page
foreach (var chapter in chapters)
{
tocHtml += $@"
<div class='toc-entry'>
<a href='#'>Chapter {Array.IndexOf(chapters, chapter) + 1}: {chapter}</a>
<span class='page-number'>{pageNumber}</span>
</div>";
pageNumber += 2; // Assuming each chapter is 2 pages
}
tocHtml += @"
</body>
</html>";
var tocPdf = renderer.RenderHtmlAsPdf(tocHtml);
// Merge all documents with TOC first
var allDocuments = new List<PdfDocument> { tocPdf };
allDocuments.AddRange(documentsToMerge);
var finalPdf = PdfDocument.Merge(allDocuments);
// Add bookmarks for navigation
finalPdf.BookMarks.AddBookMarkAtStart("Table of Contents", 0);
int currentPage = 1; // After TOC
foreach (var chapter in chapters)
{
finalPdf.BookMarks.AddBookMarkAtStart($"Chapter {Array.IndexOf(chapters, chapter) + 1}: {chapter}", currentPage);
currentPage += 2;
}
// Set document properties
finalPdf.MetaData.Title = "Complete Technical Documentation";
finalPdf.MetaData.Keywords = "IronPDF, Documentation, Enterprise, .NET";
finalPdf.MetaData.CreationDate = System.DateTime.Now;
// Add page numbers to footer
finalPdf.AddTextFooters("Page {page} of {total-pages}",
new ChromePdfRenderer.ChromePdfRenderOptions()
{
MarginBottom = 20,
MarginLeft = 50,
MarginRight = 50
});
finalPdf.SaveAs("advanced-merged-document.pdf");
}
}Imports IronPdf
Imports System.Collections.Generic
Imports System.Linq
Public Class AdvancedPdfMerger
Public Shared Sub MergeDocumentsWithBookmarks()
Dim renderer As New ChromePdfRenderer()
Dim documentsToMerge As New List(Of PdfDocument)()
' Create chapter PDFs with proper structure
Dim chapters As String() = {"Introduction", "Technical Overview", "Implementation", "Conclusion"}
For Each chapter In chapters
Dim html As String = $"
<html>
<head>
<style>
body {{font-family: Georgia, serif; margin: 40px;}}
h1 {{color: #2c3e50; border-bottom: 2px solid #3498db; padding-bottom: 10px;}}
.chapter-number {{color: #7f8c8d; font-size: 0.8em;}}
</style>
</head>
<body>
<h1><span class='chapter-number'>Chapter {Array.IndexOf(chapters, chapter) + 1}</span><br>{chapter}</h1>
<p>This is the content for the {chapter} chapter. In a real document, this would contain
extensive content, diagrams, and detailed explanations.</p>
<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit. Sed do eiusmod tempor
incididunt ut labore et dolore magna aliqua.</p>
</body>
</html>"
Dim pdf As PdfDocument = renderer.RenderHtmlAsPdf(html)
' Add metadata to each chapter
pdf.MetaData.Title = $"Chapter: {chapter}"
pdf.MetaData.Author = "Technical Documentation Team"
pdf.MetaData.Subject = "Enterprise PDF Generation"
documentsToMerge.Add(pdf)
Next
' Create a table of contents
Dim tocHtml As String = "
<html>
<head>
<style>
body { font-family: Georgia, serif; margin: 40px; }
h1 { text-align: center; color: #2c3e50; margin-bottom: 40px; }
.toc-entry { margin: 15px 0; font-size: 1.1em; }
.toc-entry a { text-decoration: none; color: #3498db; }
.page-number { float: right; color: #7f8c8d; }
</style>
</head>
<body>
<h1>Table of Contents</h1>"
Dim pageNumber As Integer = 2 ' Starting after TOC page
For Each chapter In chapters
tocHtml += $"
<div class='toc-entry'>
<a href='#'>Chapter {Array.IndexOf(chapters, chapter) + 1}: {chapter}</a>
<span class='page-number'>{pageNumber}</span>
</div>"
pageNumber += 2 ' Assuming each chapter is 2 pages
Next
tocHtml += "
</body>
</html>"
Dim tocPdf As PdfDocument = renderer.RenderHtmlAsPdf(tocHtml)
' Merge all documents with TOC first
Dim allDocuments As New List(Of PdfDocument) From {tocPdf}
allDocuments.AddRange(documentsToMerge)
Dim finalPdf As PdfDocument = PdfDocument.Merge(allDocuments)
' Add bookmarks for navigation
finalPdf.BookMarks.AddBookMarkAtStart("Table of Contents", 0)
Dim currentPage As Integer = 1 ' After TOC
For Each chapter In chapters
finalPdf.BookMarks.AddBookMarkAtStart($"Chapter {Array.IndexOf(chapters, chapter) + 1}: {chapter}", currentPage)
currentPage += 2
Next
' Set document properties
finalPdf.MetaData.Title = "Complete Technical Documentation"
finalPdf.MetaData.Keywords = "IronPDF, Documentation, Enterprise, .NET"
finalPdf.MetaData.CreationDate = DateTime.Now
' Add page numbers to footer
finalPdf.AddTextFooters("Page {page} of {total-pages}",
New ChromePdfRenderer.ChromePdfRenderOptions() With {
.MarginBottom = 20,
.MarginLeft = 50,
.MarginRight = 50
})
finalPdf.SaveAs("advanced-merged-document.pdf")
End Sub
End ClassEsta implementação avançada demonstra o gerenciamento de favoritos , o tratamento de metadados e a numeração de páginas . Consulte o tutorial sobre como organizar PDFs para obter mais detalhes. Explore técnicas de compressão de PDF após a fusão. Para segurança, implemente proteção por senha e criptografia . O exemplo "Adicionar cabeçalhos e rodapés de texto clássico" fornece opções de formatação. Para recursos adicionais, explore os guias "Adicionar números de página" e "Adicionar um índice" . O exemplo de senhas, segurança e metadados mostra uma implementação integrada.
Como faço para converter imagens em PDF?
O IronPDF converte várias imagens em PDF, um recurso indisponível no ExpertPDF. No entanto, o ExpertPDF extrai imagens de PDFs e converte PDFs em imagens, funcionalidades que o IronPDF também oferece. Consulte o guia de conversão de imagem para PDF para obter mais detalhes. O IronPDF suporta a rasterização de PDFs em imagens e a extração de texto e imagens . Para cenários avançados, desenhe texto e bitmaps ou desenhe linhas e retângulos . O exemplo de conversão de imagens para PDF demonstra a implementação prática. Para obter informações sobre qualidade de imagem, consulte o exemplo "C# PDF para imagem sem perda de qualidade" .
Como o IronPDF converte imagens em PDF?
Criar PDFs a partir de imagens usa a classe ImageToPdfConverter. As imagens podem ser carregadas de qualquer pasta, com suporte a vários formatos, incluindo arquivos TIFF de várias páginas . Você também pode adicionar imagens a PDFs existentes ou trabalhar com gráficos SVG . Para otimizar o uso da memória, utilize a rasterização de imagens com MemoryStream . O exemplo de tamanho de PDF personalizado ajuda no controle do layout.
// Import the IronPdf namespace
using IronPdf;
// Specify the folder containing the image files
var imageFiles = System.IO.Directory.EnumerateFiles(@"C:\project\assets")
.Where(file => file.EndsWith(".jpg") || file.EndsWith(".jpeg"));
// Convert the images to a PDF document
var pdfDocument = ImageToPdfConverter.ImageToPdf(imageFiles);
// Save the PDF document
pdfDocument.SaveAs(@"C:\project\composite.pdf");// Import the IronPdf namespace
using IronPdf;
// Specify the folder containing the image files
var imageFiles = System.IO.Directory.EnumerateFiles(@"C:\project\assets")
.Where(file => file.EndsWith(".jpg") || file.EndsWith(".jpeg"));
// Convert the images to a PDF document
var pdfDocument = ImageToPdfConverter.ImageToPdf(imageFiles);
// Save the PDF document
pdfDocument.SaveAs(@"C:\project\composite.pdf");' Import the IronPdf namespace
Imports IronPdf
' Specify the folder containing the image files
Private imageFiles = System.IO.Directory.EnumerateFiles("C:\project\assets").Where(Function(file) file.EndsWith(".jpg") OrElse file.EndsWith(".jpeg"))
' Convert the images to a PDF document
Private pdfDocument = ImageToPdfConverter.ImageToPdf(imageFiles)
' Save the PDF document
pdfDocument.SaveAs("C:\project\composite.pdf")Além de converter imagens para PDF, o IronPDF converte documentos digitalizados e documentos comerciais em imagens usando a função "rasterizar para imagens" . A biblioteca também extrai imagens de vários tipos de arquivo. Consulte o guia de rasterização de imagens usando MemoryStream para obter informações sobre operações de memória. Para imagens grandes, considere a otimização do tamanho do arquivo ImageToPDF . O exemplo de orientação retrato e paisagem ajuda na configuração da página. Para manipulação avançada de imagens, consulte o exemplo de incorporação de bitmaps e imagens .
Como posso criar conversões avançadas de imagem para PDF com controle de layout?
Para um posicionamento controlado de imagens e layouts profissionais, este exemplo de álbum de fotos demonstra como incorporar imagens e criar layouts. Para armazenamento em nuvem, consulte o guia de imagens do Azure Blob Storage . O exemplo em tons de cinza mostra opções de processamento de imagem:
using IronPdf;
using System.IO;
public class PhotoAlbumCreator
{
public static void CreatePhotoAlbum(string imagesFolder, string outputPath)
{
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.PaperSize = IronPdf.Rendering.PdfPaperSize.A4;
renderer.RenderingOptions.MarginTop = 20;
renderer.RenderingOptions.MarginBottom = 20;
renderer.RenderingOptions.MarginLeft = 20;
renderer.RenderingOptions.MarginRight = 20;
string htmlContent = @"
<!DOCTYPE html>
<html>
<head>
<style>
body { font-family: Arial, sans-serif; }
.album-title { text-align: center; font-size: 2em; margin-bottom: 30px; color: #2c3e50; }
.photo-container { margin-bottom: 30px; text-align: center; page-break-inside: avoid; }
.photo { max-width: 100%; max-height: 500px; box-shadow: 0 4px 6px rgba(0,0,0,0.1); }
.caption { margin-top: 10px; font-style: italic; color: #666; }
.page-break { page-break-after: always; }
</style>
</head>
<body>
<h1 class='album-title'>My Photo Album</h1>";
var imageFiles = Directory.GetFiles(imagesFolder, "*.*")
.Where(file => new[] { ".jpg", ".jpeg", ".png", ".gif" }
.Contains(Path.GetExtension(file).ToLower()))
.ToList();
for (int i = 0; i < imageFiles.Count; i++)
{
string base64Image = Convert.ToBase64String(File.ReadAllBytes(imageFiles[i]));
string fileName = Path.GetFileNameWithoutExtension(imageFiles[i]);
htmlContent += $@"
<div class='photo-container'>
<img class='photo' src='data:image/jpeg;base64,{base64Image}' alt='{fileName}'>
<div class='caption'>Photo {i + 1}: {fileName}</div>
</div>";
// Add page break every 2 photos
if ((i + 1) % 2 == 0 && i < imageFiles.Count - 1)
{
htmlContent += "<div class='page-break'></div>";
}
}
htmlContent += @"
<div style='text-align: center; margin-top: 40px; color: #999;'>
<small>Created with IronPDF - Total Photos: " + imageFiles.Count + @"</small>
</div>
</body>
</html>";
var pdf = renderer.RenderHtmlAsPdf(htmlContent);
pdf.SaveAs(outputPath);
}
}
// Usage
PhotoAlbumCreator.CreatePhotoAlbum(@"C:\MyPhotos", @"C:\MyPhotoAlbum.pdf");using IronPdf;
using System.IO;
public class PhotoAlbumCreator
{
public static void CreatePhotoAlbum(string imagesFolder, string outputPath)
{
var renderer = new ChromePdfRenderer();
renderer.RenderingOptions.PaperSize = IronPdf.Rendering.PdfPaperSize.A4;
renderer.RenderingOptions.MarginTop = 20;
renderer.RenderingOptions.MarginBottom = 20;
renderer.RenderingOptions.MarginLeft = 20;
renderer.RenderingOptions.MarginRight = 20;
string htmlContent = @"
<!DOCTYPE html>
<html>
<head>
<style>
body { font-family: Arial, sans-serif; }
.album-title { text-align: center; font-size: 2em; margin-bottom: 30px; color: #2c3e50; }
.photo-container { margin-bottom: 30px; text-align: center; page-break-inside: avoid; }
.photo { max-width: 100%; max-height: 500px; box-shadow: 0 4px 6px rgba(0,0,0,0.1); }
.caption { margin-top: 10px; font-style: italic; color: #666; }
.page-break { page-break-after: always; }
</style>
</head>
<body>
<h1 class='album-title'>My Photo Album</h1>";
var imageFiles = Directory.GetFiles(imagesFolder, "*.*")
.Where(file => new[] { ".jpg", ".jpeg", ".png", ".gif" }
.Contains(Path.GetExtension(file).ToLower()))
.ToList();
for (int i = 0; i < imageFiles.Count; i++)
{
string base64Image = Convert.ToBase64String(File.ReadAllBytes(imageFiles[i]));
string fileName = Path.GetFileNameWithoutExtension(imageFiles[i]);
htmlContent += $@"
<div class='photo-container'>
<img class='photo' src='data:image/jpeg;base64,{base64Image}' alt='{fileName}'>
<div class='caption'>Photo {i + 1}: {fileName}</div>
</div>";
// Add page break every 2 photos
if ((i + 1) % 2 == 0 && i < imageFiles.Count - 1)
{
htmlContent += "<div class='page-break'></div>";
}
}
htmlContent += @"
<div style='text-align: center; margin-top: 40px; color: #999;'>
<small>Created with IronPDF - Total Photos: " + imageFiles.Count + @"</small>
</div>
</body>
</html>";
var pdf = renderer.RenderHtmlAsPdf(htmlContent);
pdf.SaveAs(outputPath);
}
}
// Usage
PhotoAlbumCreator.CreatePhotoAlbum(@"C:\MyPhotos", @"C:\MyPhotoAlbum.pdf");Imports IronPdf
Imports System.IO
Imports System.Linq
Public Class PhotoAlbumCreator
Public Shared Sub CreatePhotoAlbum(imagesFolder As String, outputPath As String)
Dim renderer = New ChromePdfRenderer()
renderer.RenderingOptions.PaperSize = IronPdf.Rendering.PdfPaperSize.A4
renderer.RenderingOptions.MarginTop = 20
renderer.RenderingOptions.MarginBottom = 20
renderer.RenderingOptions.MarginLeft = 20
renderer.RenderingOptions.MarginRight = 20
Dim htmlContent As String = "
<!DOCTYPE html>
<html>
<head>
<style>
body { font-family: Arial, sans-serif; }
.album-title { text-align: center; font-size: 2em; margin-bottom: 30px; color: #2c3e50; }
.photo-container { margin-bottom: 30px; text-align: center; page-break-inside: avoid; }
.photo { max-width: 100%; max-height: 500px; box-shadow: 0 4px 6px rgba(0,0,0,0.1); }
.caption { margin-top: 10px; font-style: italic; color: #666; }
.page-break { page-break-after: always; }
</style>
</head>
<body>
<h1 class='album-title'>My Photo Album</h1>"
Dim imageFiles = Directory.GetFiles(imagesFolder, "*.*").Where(Function(file) New String() {".jpg", ".jpeg", ".png", ".gif"}.Contains(Path.GetExtension(file).ToLower())).ToList()
For i As Integer = 0 To imageFiles.Count - 1
Dim base64Image As String = Convert.ToBase64String(File.ReadAllBytes(imageFiles(i)))
Dim fileName As String = Path.GetFileNameWithoutExtension(imageFiles(i))
htmlContent += $"
<div class='photo-container'>
<img class='photo' src='data:image/jpeg;base64,{base64Image}' alt='{fileName}'>
<div class='caption'>Photo {i + 1}: {fileName}</div>
</div>"
' Add page break every 2 photos
If (i + 1) Mod 2 = 0 AndAlso i < imageFiles.Count - 1 Then
htmlContent += "<div class='page-break'></div>"
End If
Next
htmlContent += "
<div style='text-align: center; margin-top: 40px; color: #999;'>
<small>Created with IronPDF - Total Photos: " & imageFiles.Count & "</small>
</div>
</body>
</html>"
Dim pdf = renderer.RenderHtmlAsPdf(htmlContent)
pdf.SaveAs(outputPath)
End Sub
End Class
' Usage
PhotoAlbumCreator.CreatePhotoAlbum("C:\MyPhotos", "C:\MyPhotoAlbum.pdf")Este exemplo de código mostra como o IronPDF permite que os desenvolvedores implementem a incorporação de imagens com DataURIs , gerenciem quebras de página e criem layouts profissionais. Para imagens na nuvem, consulte o guia de imagens do Armazenamento de Blobs do Azure . Para arquivos grandes, considere a otimização do tamanho do arquivo ImageToPDF . Também permite redimensionar e transladar objetos PDF para um posicionamento preciso. O exemplo de exportação de PDFs para a memória auxilia em fluxos de trabalho com uso eficiente de memória. Consulte o guia para adicionar conteúdo HTML de forma eficiente para processamento em lote.
Quais são as opções de licenciamento e preços?
IronPDF é uma biblioteca comercial em C# para PDF, disponível no site da IronPDF . Gratuita para desenvolvimento privado e licenciada para uso comercial. Estão disponíveis diversas licenças para projetos individuais, desenvolvedores, agências e empresas. Suporta redistribuição SaaS e OEM. Consulte o guia de chaves de licença para obter detalhes sobre a implementação. Ao realizar a implantação, aplique a chave de licença corretamente. Para aplicações web, defina as chaves de licença no arquivo Web.config . Para problemas de conexão com o servidor de licenciamento , consulte o guia de solução de problemas. O guia de utilização de chaves de licença fornece detalhes completos de implementação.
Todas as licenças incluem garantia de reembolso de 30 dias, um ano de suporte e atualizações do produto. As licenças perpétuas requerem uma compra única, sem taxas adicionais. Pacote Lite para desenvolvedor/projeto único a partir de $999. Para suporte além do primeiro ano, consulte as extensões de licença . Para atualizar e obter recursos adicionais ou informações sobre implantação, consulte as atualizações de licenciamento . Para implantação do IronPDF e IIS ou para adicionar o IronPDF a instaladores de software , consulte os guias específicos. O guia de incompatibilidade de versões do ClickOnce ajuda a resolver problemas de implementação.
A ExpertPDF oferece licenças por desenvolvedor ou por empresa. Experimente o ExpertPDF gratuitamente . Confira abaixo as características da licença. Considere usar as opções de licenciamento transparentes do IronPDF em vez do ExpertPDF para obter um valor muito maior e suporte completo.
Licença de desenvolvedor total ExpertComponents Toolkit a partir de $850, ExpertPDF Toolkit a partir de $750. Compre componentes individuais separadamente. Ver Preço Completo para ExpertPDF (em abril de 2026). Para necessidades empresariais, o licenciamento do IronPDF oferece melhor custo-benefício com conjuntos de recursos completos.
Qual biblioteca de PDFs devo escolher?
O IronPDF converte HTML para PDF localmente, sem necessidade de conexão com a internet, simulando navegadores web compatíveis com os padrões. A renderização em HTML produz uma saída precisa em formato vetorial, adequada para impressão comercial. Licenciado para uso comercial com preços transparentes. Para implantações empresariais, o IronPDF oferece suporte ao Docker e recursos de mecanismo remoto . Consulte os guias sobre como executar o IronPDF como contêiner remoto e as opções de mecanismo nativo versus remoto . A biblioteca fornece o IronPdf.Slim para reduzir o tamanho da implantação e oferece suporte à otimização do tamanho do pacote . O guia de exceções de implantação do IronPdf.Slim v2025.5.6 ajuda com problemas específicos de versão.
A biblioteca de conversão de HTML para PDF da ExpertPDF converte páginas da web e HTML em PDFs, gera relatórios a partir do ASP.NET e assina contratos eletronicamente. Uso gratuito com recursos adicionais licenciados. Ao contrário do IronPDF, que oferece suporte completo a diversas plataformas, incluindo o Android , o ExpertPDF limita-se às plataformas Windows. Nos bastidores, o IronPDF usa recursos de segurança avançada e atualizações de produto regulares. A visão geral dos marcos demonstra a melhoria contínua, incluindo o marco de renderização do Chrome , o marco de compatibilidade e o marco de estabilidade e desempenho .
Embora ambas as bibliotecas processem PDFs e convertam formatos populares, o IronPDF oferece vantagens em relação ao ExpertPDF. O IronPDF converte uma ampla variedade de formatos, incluindo XML , imagens, AngularJS , Markdown e RTF , com recursos confiáveis de geração, formatação e edição de PDFs. Isso garante que os desenvolvedores alcancem eficiência para um desenvolvimento pragmático. A biblioteca se destaca na melhoria de desempenho com suporte assíncrono para cenários de alta taxa de transferência. Para processamento simultâneo, o IronPDF suporta geração paralela de PDFs e geração multithread . Consulte o guia inicial de solução de problemas de renderização lenta para obter detalhes sobre a otimização.
O ExpertPDF requer a instalação de componentes separados, enquanto o IronPDF integra todas as funcionalidades. Isso é particularmente útil quando os projetos exigem todos os recursos do PDF. Os pacotes IronPDF oferecem licenças vitalícias sem custos adicionais, enquanto o ExpertPDF exige renovações. Além disso, o IronPDF fornece documentação completa, referência de API e exemplos de código para início rápido. A seção de demonstrações apresenta implementações reais. Para solucionar problemas, consulte o guia rápido de solução de problemas ou explore o desempenho inicial de renderização e a otimização do processo da GPU . O guia para obter o melhor suporte garante a resolução eficiente de problemas.
Para implantações em produção, o IronPDF oferece recursos de depuração superiores, registro personalizado e guias de solução de problemas abrangentes. A biblioteca oferece suporte a recursos avançados: conformidade com PDF/A , acessibilidade PDF/UA , assinaturas digitais com HSM e higienização para manuseio seguro. Para segurança empresarial, o IronPDF oferece criptografia e descriptografia , proteção por senha e recursos de segurança completos. Os recursos avançados incluem a redação de texto , o achatamento de PDFs e o gerenciamento de versões de PDF . O guia para converter PDF em base64 auxilia na transmissão de dados.
Em relação a suporte e desenvolvimento, a IronPDF oferece suporte técnico com guias detalhados para fazer solicitações de suporte . As atualizações e os marcos importantes dos produtos da biblioteca demonstram a melhoria contínua. Para desenvolvedores .NET MAUI , o IronPDF oferece recursos de visualização de PDF e conversão de XAML para PDF . Os desenvolvedores Blazor usam a integração do Blazor Server e a conversão de Razor para PDF . A biblioteca oferece suporte à conversão de CSHTML para PDF em aplicações MVC e à renderização de CSHTML sem interface gráfica . Consulte o guia do Blazor Server/WebAssembly para obter informações sobre as limitações.
Para usos especializados, o IronPDF se destaca com a integração do OpenAI para processamento inteligente , renderização de gráficos em PDFs , conversão de CSHTML para PDF em aplicativos MVC e suporte a idiomas internacionais e UTF-8 . A biblioteca lida com cenários complexos: achatamento de PDFs , linearização para visualização rápida na web e criação de formulários em PDF . Explore a transformação de páginas PDF , a remoção de objetos PDF e a definição de caminhos temporários personalizados . A visão geral completa dos recursos do IronPDF demonstra as funcionalidades para criar PDFs , converter PDFs , editar PDFs , organizar PDFs e proteger PDFs . Funcionalidades adicionais incluem leitura de arquivos PDF em C# , busca e substituição de texto e remoção de páginas específicas de PDFs .
Para considerações sobre implantação, consulte Depuração do Azure Functions em máquina local , Gerenciamento de arquivos de log do Azure , Tratamento de arquivos de log da AWS e Soluções para erros 502 Bad Gateway . O IronPDF oferece tratamento completo de erros, incluindo soluções para acesso negado a caminhos , implantação de dependências do Chrome , implantação de dependências do PDFium e soluções para erros de alocação indevida . O suporte específico para cada plataforma inclui guias específicos para Linux , exceções nativas do macOS e limitações do Windows Nano Server . Os recursos de segurança incluem o status de vulnerabilidade do Log4j e a proteção contra falhas de segmentação no AWS Lambda .
Perguntas frequentes
Como posso converter HTML para PDF em C#?
Você pode usar o método RenderHtmlAsPdf do IronPDF para converter strings HTML em PDFs. Você também pode converter arquivos HTML em PDFs usando o RenderHtmlFileAsPdf .
Quais são as principais diferenças entre o IronPDF e o ExpertPDF?
O IronPDF oferece suporte a uma gama mais ampla de formatos e funcionalidades integradas, incluindo a criação de PDFs a partir de HTML, edição e conversão de formatos. O ExpertPDF proporciona uma conversão simples de HTML para PDF, com opções para configurações de arquivos de saída e assinaturas digitais.
Posso extrair texto e imagens de um PDF usando essas bibliotecas?
Sim, o IronPDF permite extrair texto e imagens de documentos PDF, facilitando a manipulação e análise do conteúdo do PDF em aplicações .NET.
Quais opções de instalação estão disponíveis para essas bibliotecas de PDF?
Tanto o IronPDF quanto o ExpertPDF podem ser instalados usando o Gerenciador de Pacotes NuGet do Visual Studio. Além disso, a biblioteca .DLL do IronPDF pode ser baixada diretamente do site do IronPDF.
É possível mesclar vários arquivos PDF em um único documento?
Sim, o IronPDF oferece um método de mesclagem para combinar vários PDFs em um único documento. O ExpertPDF também oferece um componente PDFMerge para mesclar PDFs.
O IronPDF requer conexão com a internet para conversão de HTML em PDF?
Não, o IronPDF não requer conexão com a internet para conversão de HTML em PDF, tornando-se uma opção confiável para aplicações offline.
Quais são as opções de licenciamento disponíveis para o IronPDF?
O IronPDF oferece diversas opções de licenciamento, incluindo licenças para projeto individual, desenvolvedor, agência e corporativa. Todas as licenças são perpétuas e incluem garantia de reembolso de 30 dias e um ano de suporte e atualizações.
O ExpertPDF consegue lidar com assinaturas digitais em documentos PDF?
Sim, o ExpertPDF suporta assinatura digital de documentos PDF, permitindo arquivos PDF seguros e autenticados.
Quais são os desafios que os desenvolvedores C# enfrentam ao trabalhar com PDFs e como essas bibliotecas podem ajudar?
Os desenvolvedores C# frequentemente enfrentam desafios na leitura, escrita, criação e conversão de PDFs. Bibliotecas como IronPDF e ExpertPDF simplificam essas tarefas, fornecendo ferramentas poderosas para conversão de HTML para PDF, edição de PDF e muito mais, facilitando a integração em aplicações C#.












