

Traitement par lots des PDF en C# : Automatiser les flux de documents à grande échelle
Le traitement PDF par lots en C# avec IronPDF permet aux développeurs .NET d'automatiser les flux de documents à grande échelle - de la conversion parallèle HTML vers PDF et de la fusion/division en bloc aux pipelines PDF asynchrones avec gestion intégrée des erreurs, logique de relance et point de contrôle. Le moteur Chromium thread-safe d'IronPDF et sa gestion de la mémoire basée sur IDisposable en font un outil spécialement conçu pour l'automatisation PDF à haut débit , que vous l'exécutiez sur site, dans Azure Functions , AWS Lambda ou Kubernetes .
TL;DR : Guide de démarrage rapide
Ce tutoriel couvre l'automatisation évolutive des PDF en C# - de la conversion parallèle et des opérations en masse au déploiement dans le cloud et aux modèles de pipeline résilients.
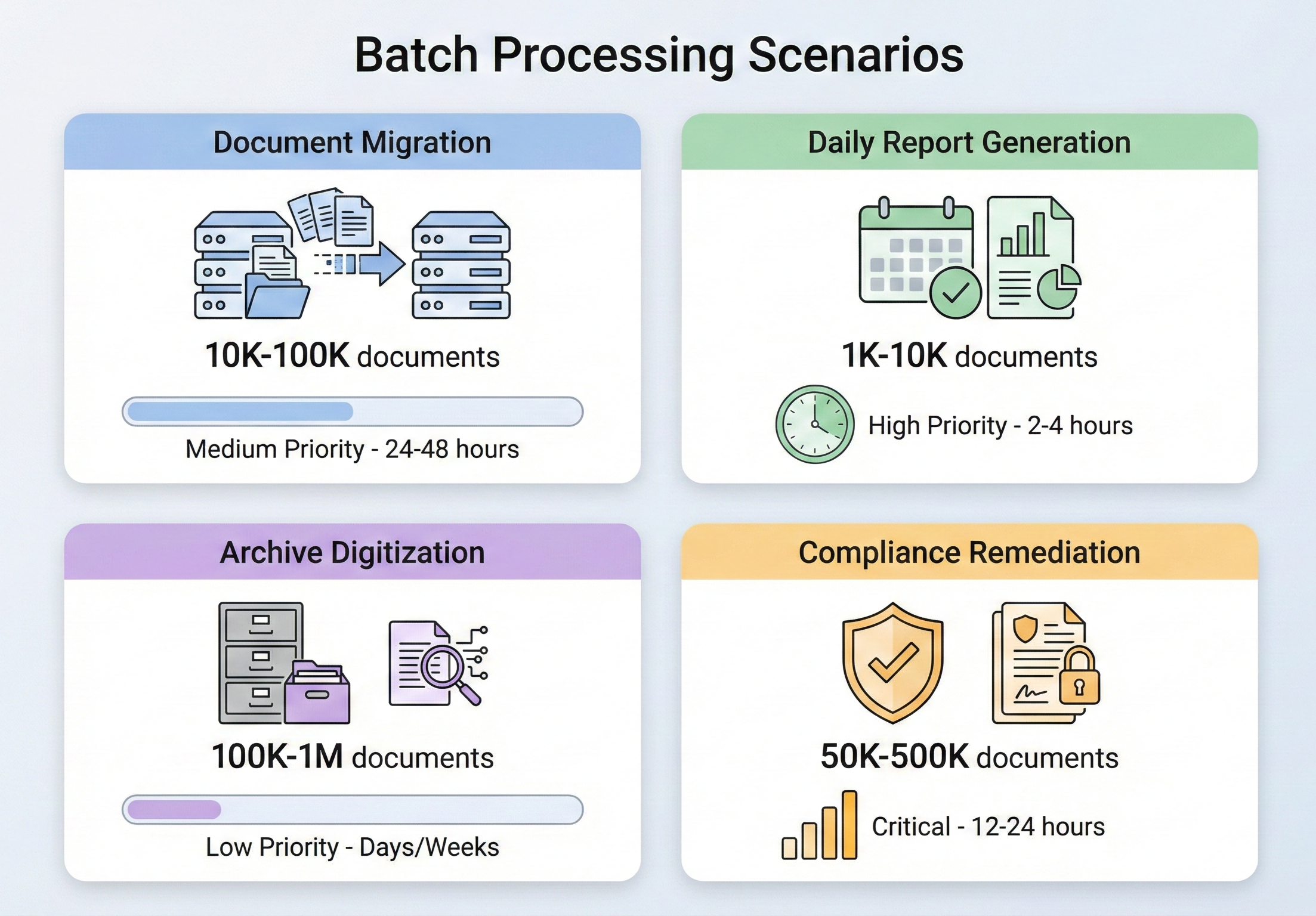
- À qui s'adresse ce document: Les développeurs et architectes .NET responsables de flux de travail à forte intensité documentaire - projets de migration de documents, pipelines de génération de rapports quotidiens, balayages de remédiation de conformité, ou efforts de numérisation d'archives où le traitement séquentiel n'est pas réalisable.
- Ce que vous construirez : Conversion parallèle HTML-PDF avec
Parallel.ForEach, opérations de fusion et de division par lots, pipelines asynchrones avecSemaphoreSlimpour le contrôle de la concurrence, gestion des erreurs avec logique de saut en cas d'échec et de nouvelle tentative, modèles de point de contrôle/reprise pour la récupération après incident et configurations de déploiement cloud pour Azure Functions, AWS Lambda et Kubernetes. - Où ça marche: .NET 6+, .NET Framework 4.6.2+, .NET Standard 2.0. Tous les rendus utilisent le moteur Chromium intégré d'IronPDF - aucune dépendance de navigateur headless ni aucun service externe n'est nécessaire.
- Quand utiliser cette approche: Lorsque vous devez traiter plus de PDF que ne le permet l'exécution séquentielle - migration de documents à grande échelle, tâches programmées par lots avec des délais serrés, ou plateformes multi-locataires avec des charges de documents variables.
- Pourquoi c'est important techniquement : IronPDF's
ChromePdfRendererest thread-safe et sans état par rendu, ce qui signifie que plusieurs threads peuvent partager en toute sécurité une seule instance de rendu. Combiné avec la bibliothèque parallèle de tâches de .NET etIDisposablesurPdfDocument, vous obtenez un comportement de mémoire prévisible et une saturation du processeur sans conditions de concurrence ni fuites de mémoire.
Convertissez par lots un répertoire entier de fichiers HTML en PDF avec seulement quelques lignes de code :
-
Installez IronPDF avec le Gestionnaire de Packages NuGet
PM > Install-Package IronPdf -
Copiez et exécutez cet extrait de code.
using IronPdf; using System.IO; using System.Threading.Tasks; var renderer = new ChromePdfRenderer(); var htmlFiles = Directory.GetFiles("input/", "*.html"); Parallel.ForEach(htmlFiles, htmlFile => { var pdf = renderer.RenderHtmlFileAsPdf(htmlFile); pdf.SaveAs($"output/{Path.GetFileNameWithoutExtension(htmlFile)}.pdf"); }); -
Déployez pour tester sur votre environnement de production.
Commencez à utiliser IronPDF dans votre projet dès aujourd'hui avec un essai gratuit

Après avoir acheté ou vous être inscrit à une version d'essai de 30 jours d'IronPDF, ajoutez votre clé de licence au début de votre application.
IronPdf.License.LicenseKey = "KEY";IronPdf.License.LicenseKey = "KEY";Imports IronPdf
IronPdf.License.LicenseKey = "KEY"Commencez à utiliser IronPDF dans votre projet aujourd'hui avec un essai gratuit.
Table des matières
- Comprendre le problème
- Fondation
- Opérations de base
- Résilience
- Performance
- Déploiement
- Mettre tout cela ensemble
Lorsque vous avez des milliers de PDF à traiter
Le traitement PDF par lots n'est pas une exigence de niche - c'est un élément de routine de la gestion des documents d'entreprise. Les scénarios qui requièrent ce type de traitement se rencontrent dans tous les secteurs d'activité et ont un point commun : il n'est pas possible de faire les choses une par une.
Les projets de migration de documents sont l'un des déclencheurs les plus courants. Lorsqu'une organisation passe d'un système de gestion documentaire à un autre, des milliers (parfois des millions) de documents doivent être convertis, reformatés ou réétiquetés. Une compagnie d'assurance migrant d'un ancien système de gestion des sinistres pourrait avoir besoin de convertir 500 000 documents de sinistres au format TIFF en PDF consultables. Un cabinet d'avocats qui passe à une nouvelle plateforme de gestion des dossiers peut avoir besoin de fusionner des correspondances éparses dans des dossiers unifiés. Il s'agit de travaux ponctuels, mais de grande envergure et qui ne pardonnent pas les erreurs.
la génération de rapports quotidiens est la version stable du même problème. Les institutions financières qui produisent des rapports de portefeuille de fin de journée pour des milliers de clients, les entreprises de logistique qui génèrent des manifestes d'expédition pour chaque conteneur sortant, les systèmes de santé qui créent des résumés quotidiens pour les patients dans des centaines de départements - tous génèrent des sorties PDF à une échelle où le traitement séquentiel dépasserait les fenêtres de temps acceptables. Lorsque 10 000 rapports doivent être prêts pour 6 heures du matin et que les données ne sont pas définitives avant minuit, vous ne disposez pas de six heures pour les rendre un par un.
La numérisation des archives se situe à l'intersection de la migration et de la conformité. Les agences gouvernementales, les universités et les entreprises qui possèdent des décennies de documents papier doivent numériser et archiver leurs documents dans des formats conformes aux normes (généralement PDF/A). Les volumes sont énormes - la NARA reçoit à elle seule des millions de pages de documents fédéraux à conserver en permanence - et le processus doit être suffisamment fiable pour que vous ne découvriez pas de lacunes des années plus tard.
La mise en conformité est souvent l'élément déclencheur le plus urgent. Lorsqu'un audit révèle que vos archives documentaires ne sont pas conformes à une nouvelle norme - par exemple, vos factures stockées ne sont pas conformes à la norme PDF/A-3 pour la facturation électronique, ou vos dossiers médicaux ne comportent pas le marquage d'accessibilité exigé par la section 508 - vous devez traiter l'ensemble de vos archives existantes en fonction de la nouvelle norme. La pression est forte, le délai est serré et le volume est celui de vos archives.
Dans chacun de ces scénarios, le défi principal est le même : comment traiter un grand nombre d'opérations PDF de manière fiable et efficace, sans manquer de mémoire ni laisser un travail à moitié achevé en cas de problème ?
Architecture de traitement par lots d'IronPDF
Avant de plonger dans des opérations spécifiques, il est important de comprendre comment IronPDF est conçu pour gérer des charges de travail simultanées et quelles décisions architecturales vous devez prendre lorsque vous construisez un pipeline de traitement par lots au-dessus de lui.
Installer IronPDF
Installez IronPDF via NuGet :
Install-Package IronPdfInstall-Package IronPdfOu en utilisant l'interface de ligne de commande .NET :
dotnet add package IronPdfdotnet add package IronPdfIronPDF prend en charge .NET Framework 4.6.2+, .NET Core, .NET 5 à .NET 10, et .NET Standard 2.0. Il fonctionne sur Windows, Linux, macOS et les conteneurs Docker, ce qui le rend adapté à la fois aux travaux par lots sur site et au déploiement cloud-native.
Pour le traitement par lots de production, définissez votre clé de licence avec License.LicenseKey au démarrage de l'application avant le début de toute opération PDF. Cela permet de s'assurer que chaque appel de rendu sur tous les threads a accès à l'ensemble des fonctionnalités sans filigrane par fichier.
Concurrence et sécurité des threads
Le moteur de rendu d'IronPDF, basé sur Chromium, est à l'épreuve des threads. Vous pouvez créer plusieurs instances ChromePdfRenderer sur plusieurs threads, ou partager une seule instance — IronPDF gère la synchronisation interne. La recommandation officielle pour le traitement par lots est d'utiliser la fonction intégrée de .NET, qui répartit automatiquement le travail sur tous les cœurs de processeur disponibles.
Cela dit, " thread-safe " ne signifie pas " utiliser un nombre illimité de threads ". Chaque opération de rendu PDF simultanée consomme de la mémoire (le moteur Chromium a besoin d'espace de travail pour l'analyse DOM, la mise en page CSS et la rastérisation d'images), et le lancement de trop d'opérations parallèles sur un système à mémoire limitée dégradera les performances ou provoquera OutOfMemoryException. Le bon niveau de concurrence dépend de votre matériel : un serveur à 16 cœurs avec 64 Go de RAM peut confortablement gérer 8 à 12 rendus simultanés ; Une VM à 4 cœurs avec 8 Go pourrait être limitée à 2–4. Contrôlez cela avec ParallelOptions.MaxDegreeOfParallelism — définissez-la à environ la moitié de vos cœurs de processeur disponibles comme point de départ, puis ajustez en fonction de la pression de mémoire observée.
Gestion de la mémoire à grande échelle
La gestion de la mémoire est la préoccupation la plus importante dans le traitement PDF par lots. Chaque objet PdfDocument contient le contenu binaire complet d'un PDF en mémoire, et le fait de ne pas libérer ces objets entraînera une augmentation linéaire de la mémoire avec le nombre de fichiers traités.
La règle essentielle : utilisez toujours les instructions using ou appelez explicitement Dispose() sur les objets PdfDocument. IronPDF's PdfDocument implémente IDisposable, et le fait de ne pas libérer est la cause la plus courante de problèmes de mémoire dans les scénarios par lots. Chaque itération de votre boucle de traitement doit créer un PdfDocument, effectuer son travail et le supprimer — n'accumulez jamais d'objets PdfDocument dans une liste ou une collection à moins d'avoir une raison spécifique et suffisamment de mémoire pour le gérer.
Au-delà de l'élimination, pensez à ces stratégies de gestion de la mémoire pour les lots importants :
Traiter par morceaux plutôt que de tout charger en même temps. Si vous devez traiter 50 000 fichiers, ne les énumérez pas tous dans une liste et n'effectuez pas d'itération - traitez-les par lots de 100 ou 500, en permettant au garbage collector de récupérer de la mémoire entre chaque lot.
Force garbage collection between chunks pour les lots extrêmement volumineux. Bien que vous devriez généralement laisser le GC se gérer lui-même, le traitement par lots est l'un des rares scénarios où l'appel de GC.Collect() entre les limites des blocs peut empêcher la pression sur la mémoire de s'accumuler.
Surveillez la consommation de mémoire à l'aide de GC.GetTotalMemory() ou de métriques au niveau du processus. Si l'utilisation de la mémoire dépasse un certain seuil (par exemple, 80 % de la RAM disponible), interrompez le traitement pour permettre au GC de rattraper son retard.
Rapports d'avancement et journalisation
Lorsqu'un travail par lots prend des heures, la visibilité de sa progression n'est pas facultative, elle est essentielle. Au minimum, vous devez enregistrer le début et la fin de chaque fichier, suivre le nombre de réussites et d'échecs et fournir une estimation du temps restant. Utilisez Interlocked.Increment pour les compteurs thread-safe lors de l'exécution d'opérations parallèles et enregistrez à intervalles réguliers (tous les 50 ou 100 fichiers) plutôt que sur chaque fichier unique pour éviter d'inonder votre sortie. Suivez votre temps écoulé avec System.Diagnostics.Stopwatch et calculez un débit de fichiers par seconde pour obtenir une ETA significative.
Pour les travaux de production par lots, envisagez d'écrire la progression dans une mémoire persistante (base de données, fichier ou file d'attente de messages) afin que les tableaux de bord de surveillance puissent afficher l'état en temps réel sans se connecter directement au processus de traitement par lots.
Opérations par lots courantes
Les bases architecturales étant posées, passons en revue les opérations par lots les plus courantes et leurs implémentations IronPDF.
Conversion par lots de HTML en PDF
La conversion de HTML en PDF est l'opération par lots la plus courante. Qu'il s'agisse de générer des factures à partir de modèles, de convertir une bibliothèque de documentation HTML en PDF ou de générer des rapports dynamiques à partir d'une application web, le schéma est le même : itérer sur vos entrées, effectuer le rendu de chacune d'entre elles et enregistrer la sortie.
Entrée (5 fichiers HTML)
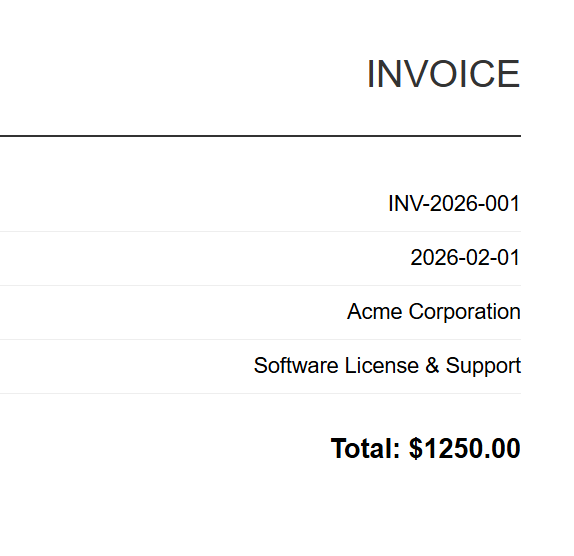
INV-2026-001
INV-2026-002
INV-2026-003
INV-2026-004
INV-2026-005
L'implémentation utilise ChromePdfRenderer avec Parallel.ForEach pour traiter tous les fichiers HTML simultanément, en contrôlant le parallélisme via MaxDegreeOfParallelism pour équilibrer le débit et la consommation de mémoire. Chaque fichier est rendu avec RenderHtmlFileAsPdf et enregistré dans le répertoire de sortie, avec un suivi de progression via des compteurs thread-safe Interlocked.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-html-to-pdf.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
using System.Threading;
// Configure paths
string inputFolder = "input/";
string outputFolder = "output/";
Directory.CreateDirectory(outputFolder);
string[] htmlFiles = Directory.GetFiles(inputFolder, "*.html");
Console.WriteLine($"Found {htmlFiles.Length} HTML files to convert");
// Create renderer instance (thread-safe, can be shared)
var renderer = new ChromePdfRenderer();
// Track progress
int processed = 0;
int failed = 0;
// Process in parallel with controlled concurrency
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(htmlFiles, options, htmlFile =>
{
try
{
string fileName = Path.GetFileNameWithoutExtension(htmlFile);
string outputPath = Path.Combine(outputFolder, $"{fileName}.pdf");
using var pdf = renderer.RenderHtmlFileAsPdf(htmlFile);
pdf.SaveAs(outputPath);
Interlocked.Increment(ref processed);
Console.WriteLine($"[OK] {fileName}.pdf");
}
catch (Exception ex)
{
Interlocked.Increment(ref failed);
Console.WriteLine($"[ERROR] {Path.GetFileName(htmlFile)}: {ex.Message}");
}
});
Console.WriteLine($"\nComplete: {processed} succeeded, {failed} failed");Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading.Tasks
Imports System.Threading
' Configure paths
Dim inputFolder As String = "input/"
Dim outputFolder As String = "output/"
Directory.CreateDirectory(outputFolder)
Dim htmlFiles As String() = Directory.GetFiles(inputFolder, "*.html")
Console.WriteLine($"Found {htmlFiles.Length} HTML files to convert")
' Create renderer instance (thread-safe, can be shared)
Dim renderer As New ChromePdfRenderer()
' Track progress
Dim processed As Integer = 0
Dim failed As Integer = 0
' Process in parallel with controlled concurrency
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(htmlFiles, options, Sub(htmlFile)
Try
Dim fileName As String = Path.GetFileNameWithoutExtension(htmlFile)
Dim outputPath As String = Path.Combine(outputFolder, $"{fileName}.pdf")
Using pdf = renderer.RenderHtmlFileAsPdf(htmlFile)
pdf.SaveAs(outputPath)
End Using
Interlocked.Increment(processed)
Console.WriteLine($"[OK] {fileName}.pdf")
Catch ex As Exception
Interlocked.Increment(failed)
Console.WriteLine($"[ERROR] {Path.GetFileName(htmlFile)}: {ex.Message}")
End Try
End Sub)
Console.WriteLine($"\nComplete: {processed} succeeded, {failed} failed")Sortie
Chaque facture HTML est convertie en un PDF correspondant. Ci-dessus, INV-2026-001.pdf - l'une des 5 sorties de lot.
Pour la génération de modèles (par exemple, factures, rapports), vous fusionnerez généralement les données dans un modèle HTML avant le rendu. L'approche est simple : chargez votre modèle HTML une seule fois, utilisez string.Replace pour injecter les données de chaque enregistrement (nom du client, totaux, dates), puis transmettez le HTML ainsi rempli à RenderHtmlAsPdf dans votre boucle parallèle. IronPDF propose également RenderHtmlAsPdfAsync pour les cas où vous souhaitez utiliser async/await au lieu de Parallel.ForEach ; nous aborderons les modèles asynchrones en détail dans une section ultérieure.
Fusion de PDF par lots
La fusion de groupes de PDF en documents combinés est courante dans les flux de travail juridiques (fusion de documents de dossiers), financiers (combinaison de relevés mensuels en rapports trimestriels) et de publication.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-merge.csusing IronPdf;
using System;
using System.IO;
using System.Linq;
using System.Collections.Generic;
string inputFolder = "documents/";
string outputFolder = "merged/";
Directory.CreateDirectory(outputFolder);
// Group PDFs by prefix (e.g., "invoice-2026-01-*.pdf" -> one merged file)
var pdfFiles = Directory.GetFiles(inputFolder, "*.pdf");
var groups = pdfFiles
.GroupBy(f => Path.GetFileName(f).Split('-').Take(3).Aggregate((a, b) => $"{a}-{b}"))
.Where(g => g.Count() > 1);
Console.WriteLine($"Found {groups.Count()} groups to merge");
foreach (var group in groups)
{
string groupName = group.Key;
var filesToMerge = group.OrderBy(f => f).ToList();
Console.WriteLine($"Merging {filesToMerge.Count} files into {groupName}.pdf");
try
{
// Load all PDFs for this group
var pdfDocs = new List<PdfDocument>();
foreach (string filePath in filesToMerge)
{
pdfDocs.Add(PdfDocument.FromFile(filePath));
}
// Merge all documents
using var merged = PdfDocument.Merge(pdfDocs);
merged.SaveAs(Path.Combine(outputFolder, $"{groupName}-merged.pdf"));
// Dispose source documents
foreach (var doc in pdfDocs)
{
doc.Dispose();
}
Console.WriteLine($" [OK] Created {groupName}-merged.pdf ({merged.PageCount} pages)");
}
catch (Exception ex)
{
Console.WriteLine($" [ERROR] {groupName}: {ex.Message}");
}
}
Console.WriteLine("\nMerge complete");Imports IronPdf
Imports System
Imports System.IO
Imports System.Linq
Imports System.Collections.Generic
Module Program
Sub Main()
Dim inputFolder As String = "documents/"
Dim outputFolder As String = "merged/"
Directory.CreateDirectory(outputFolder)
' Group PDFs by prefix (e.g., "invoice-2026-01-*.pdf" -> one merged file)
Dim pdfFiles = Directory.GetFiles(inputFolder, "*.pdf")
Dim groups = pdfFiles _
.GroupBy(Function(f) Path.GetFileName(f).Split("-"c).Take(3).Aggregate(Function(a, b) $"{a}-{b}")) _
.Where(Function(g) g.Count() > 1)
Console.WriteLine($"Found {groups.Count()} groups to merge")
For Each group In groups
Dim groupName As String = group.Key
Dim filesToMerge = group.OrderBy(Function(f) f).ToList()
Console.WriteLine($"Merging {filesToMerge.Count} files into {groupName}.pdf")
Try
' Load all PDFs for this group
Dim pdfDocs As New List(Of PdfDocument)()
For Each filePath As String In filesToMerge
pdfDocs.Add(PdfDocument.FromFile(filePath))
Next
' Merge all documents
Using merged = PdfDocument.Merge(pdfDocs)
merged.SaveAs(Path.Combine(outputFolder, $"{groupName}-merged.pdf"))
End Using
' Dispose source documents
For Each doc In pdfDocs
doc.Dispose()
Next
Console.WriteLine($" [OK] Created {groupName}-merged.pdf ({merged.PageCount} pages)")
Catch ex As Exception
Console.WriteLine($" [ERROR] {groupName}: {ex.Message}")
End Try
Next
Console.WriteLine(vbCrLf & "Merge complete")
End Sub
End ModulePour la fusion d'un grand nombre de fichiers, tenez compte de la mémoire : la méthode PdfDocument.Merge charge tous les documents sources en mémoire simultanément. Si vous devez fusionner des centaines de PDF volumineux, envisagez une fusion par étapes : combinez des groupes de 10 à 20 fichiers en documents intermédiaires, puis fusionnez les documents intermédiaires.
Division de PDF par lots
Le découpage de PDF multipages en pages individuelles (ou plages de pages) est l'inverse de la fusion. Les documents sont souvent traités dans les salles de courrier, lorsqu'un lot de documents numérisés doit être séparé en enregistrements individuels, et dans les flux de travail d'impression, lorsque des documents composites doivent être décomposés.
Entrée
Le code ci-dessous illustre l'extraction de pages individuelles à l'aide de CopyPage dans une boucle parallèle, créant des fichiers PDF distincts pour chaque page. Une autre fonction d'assistance SplitByRange montre comment extraire des plages de pages plutôt que des pages individuelles, utile pour découper de grands documents en segments plus petits.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-split.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
string inputFolder = "multipage/";
string outputFolder = "split/";
Directory.CreateDirectory(outputFolder);
string[] pdfFiles = Directory.GetFiles(inputFolder, "*.pdf");
Console.WriteLine($"Found {pdfFiles.Length} PDFs to split");
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(pdfFiles, options, pdfFile =>
{
string baseName = Path.GetFileNameWithoutExtension(pdfFile);
try
{
using var pdf = PdfDocument.FromFile(pdfFile);
int pageCount = pdf.PageCount;
Console.WriteLine($"Splitting {baseName}.pdf ({pageCount} pages)");
// Extract each page as a separate PDF
for (int i = 0; i < pageCount; i++)
{
using var singlePage = pdf.CopyPage(i);
string outputPath = Path.Combine(outputFolder, $"{baseName}-page-{i + 1:D3}.pdf");
singlePage.SaveAs(outputPath);
}
Console.WriteLine($" [OK] Created {pageCount} files from {baseName}.pdf");
}
catch (Exception ex)
{
Console.WriteLine($" [ERROR] {baseName}: {ex.Message}");
}
});
// Alternative: Extract page ranges instead of individual pages
void SplitByRange(string inputFile, string outputFolder, int pagesPerChunk)
{
using var pdf = PdfDocument.FromFile(inputFile);
string baseName = Path.GetFileNameWithoutExtension(inputFile);
int totalPages = pdf.PageCount;
int chunkNumber = 1;
for (int startPage = 0; startPage < totalPages; startPage += pagesPerChunk)
{
int endPage = Math.Min(startPage + pagesPerChunk - 1, totalPages - 1);
using var chunk = pdf.CopyPages(startPage, endPage);
chunk.SaveAs(Path.Combine(outputFolder, $"{baseName}-chunk-{chunkNumber:D3}.pdf"));
chunkNumber++;
}
}
Console.WriteLine("\nSplit complete");Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading.Tasks
Module Program
Sub Main()
Dim inputFolder As String = "multipage/"
Dim outputFolder As String = "split/"
Directory.CreateDirectory(outputFolder)
Dim pdfFiles As String() = Directory.GetFiles(inputFolder, "*.pdf")
Console.WriteLine($"Found {pdfFiles.Length} PDFs to split")
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(pdfFiles, options, Sub(pdfFile)
Dim baseName As String = Path.GetFileNameWithoutExtension(pdfFile)
Try
Using pdf = PdfDocument.FromFile(pdfFile)
Dim pageCount As Integer = pdf.PageCount
Console.WriteLine($"Splitting {baseName}.pdf ({pageCount} pages)")
' Extract each page as a separate PDF
For i As Integer = 0 To pageCount - 1
Using singlePage = pdf.CopyPage(i)
Dim outputPath As String = Path.Combine(outputFolder, $"{baseName}-page-{i + 1:D3}.pdf")
singlePage.SaveAs(outputPath)
End Using
Next
Console.WriteLine($" [OK] Created {pageCount} files from {baseName}.pdf")
End Using
Catch ex As Exception
Console.WriteLine($" [ERROR] {baseName}: {ex.Message}")
End Try
End Sub)
' Alternative: Extract page ranges instead of individual pages
Sub SplitByRange(inputFile As String, outputFolder As String, pagesPerChunk As Integer)
Using pdf = PdfDocument.FromFile(inputFile)
Dim baseName As String = Path.GetFileNameWithoutExtension(inputFile)
Dim totalPages As Integer = pdf.PageCount
Dim chunkNumber As Integer = 1
For startPage As Integer = 0 To totalPages - 1 Step pagesPerChunk
Dim endPage As Integer = Math.Min(startPage + pagesPerChunk - 1, totalPages - 1)
Using chunk = pdf.CopyPages(startPage, endPage)
chunk.SaveAs(Path.Combine(outputFolder, $"{baseName}-chunk-{chunkNumber:D3}.pdf"))
chunkNumber += 1
End Using
Next
End Using
End Sub
Console.WriteLine(vbCrLf & "Split complete")
End Sub
End ModuleSortie
Page 2 extraite en tant que PDF indépendant (annual-report-page-2.pdf)
Les méthodes CopyPage et CopyPages d'IronPDF créent de nouveaux objets PdfDocument contenant les pages spécifiées. N'oubliez pas de supprimer le document source et chaque page extraite après l'enregistrement.
Compression par lots
Lorsque les coûts de stockage sont importants ou lorsque vous devez transmettre des PDF sur des connexions à bande passante limitée, la compression par lots peut réduire considérablement l'encombrement de vos archives. IronPDF propose deux approches de compression : CompressImages pour réduire la qualité/taille de l'image et CompressStructTree pour supprimer les métadonnées structurelles. La nouvelle API CompressAndSaveAs (introduite dans la version 2025.12) offre une compression supérieure en combinant plusieurs techniques d'optimisation.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-compression.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
using System.Threading;
string inputFolder = "originals/";
string outputFolder = "compressed/";
Directory.CreateDirectory(outputFolder);
string[] pdfFiles = Directory.GetFiles(inputFolder, "*.pdf");
Console.WriteLine($"Found {pdfFiles.Length} PDFs to compress");
long totalOriginalSize = 0;
long totalCompressedSize = 0;
int processed = 0;
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(pdfFiles, options, pdfFile =>
{
string fileName = Path.GetFileName(pdfFile);
string outputPath = Path.Combine(outputFolder, fileName);
try
{
long originalSize = new FileInfo(pdfFile).Length;
Interlocked.Add(ref totalOriginalSize, originalSize);
using var pdf = PdfDocument.FromFile(pdfFile);
// Apply compression with JPEG quality setting (0-100, lower = more compression)
pdf.CompressAndSaveAs(outputPath, 60);
long compressedSize = new FileInfo(outputPath).Length;
Interlocked.Add(ref totalCompressedSize, compressedSize);
Interlocked.Increment(ref processed);
double reduction = (1 - (double)compressedSize / originalSize) * 100;
Console.WriteLine($"[OK] {fileName}: {originalSize / 1024}KB → {compressedSize / 1024}KB ({reduction:F1}% reduction)");
}
catch (Exception ex)
{
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
});
double totalReduction = (1 - (double)totalCompressedSize / totalOriginalSize) * 100;
Console.WriteLine($"\nCompression complete:");
Console.WriteLine($" Files processed: {processed}");
Console.WriteLine($" Total original: {totalOriginalSize / 1024 / 1024}MB");
Console.WriteLine($" Total compressed: {totalCompressedSize / 1024 / 1024}MB");
Console.WriteLine($" Overall reduction: {totalReduction:F1}%");Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading.Tasks
Imports System.Threading
Module Program
Sub Main()
Dim inputFolder As String = "originals/"
Dim outputFolder As String = "compressed/"
Directory.CreateDirectory(outputFolder)
Dim pdfFiles As String() = Directory.GetFiles(inputFolder, "*.pdf")
Console.WriteLine($"Found {pdfFiles.Length} PDFs to compress")
Dim totalOriginalSize As Long = 0
Dim totalCompressedSize As Long = 0
Dim processed As Integer = 0
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(pdfFiles, options, Sub(pdfFile)
Dim fileName As String = Path.GetFileName(pdfFile)
Dim outputPath As String = Path.Combine(outputFolder, fileName)
Try
Dim originalSize As Long = New FileInfo(pdfFile).Length
Interlocked.Add(totalOriginalSize, originalSize)
Using pdf = PdfDocument.FromFile(pdfFile)
' Apply compression with JPEG quality setting (0-100, lower = more compression)
pdf.CompressAndSaveAs(outputPath, 60)
End Using
Dim compressedSize As Long = New FileInfo(outputPath).Length
Interlocked.Add(totalCompressedSize, compressedSize)
Interlocked.Increment(processed)
Dim reduction As Double = (1 - CDbl(compressedSize) / originalSize) * 100
Console.WriteLine($"[OK] {fileName}: {originalSize \ 1024}KB → {compressedSize \ 1024}KB ({reduction:F1}% reduction)")
Catch ex As Exception
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End Sub)
Dim totalReduction As Double = (1 - CDbl(totalCompressedSize) / totalOriginalSize) * 100
Console.WriteLine(vbCrLf & "Compression complete:")
Console.WriteLine($" Files processed: {processed}")
Console.WriteLine($" Total original: {totalOriginalSize \ 1024 \ 1024}MB")
Console.WriteLine($" Total compressed: {totalCompressedSize \ 1024 \ 1024}MB")
Console.WriteLine($" Overall reduction: {totalReduction:F1}%")
End Sub
End ModuleQuelques points à garder à l'esprit concernant la compression : Les paramètres de qualité JPEG inférieurs à 60 produiront des artefacts visibles dans la plupart des images. L'option ShrinkImage peut provoquer une distorsion dans certaines configurations — testez avec des échantillons représentatifs avant d'exécuter un lot complet. La suppression de l'arbre de structure (CompressStructTree) affectera la sélection et la recherche de texte dans les PDF compressés, ne l'utilisez donc que lorsque ces fonctionnalités ne sont pas nécessaires.
Conversion de format par lots (PDF/A, PDF/UA)
La conversion d'une archive existante dans un format conforme aux normes - PDF/A pour l'archivage à long terme ou PDF/UA pour l'accessibilité - est l'une des opérations par lots à plus forte valeur ajoutée. IronPDF prend en charge l'ensemble des versions PDF/A (y compris PDF/A-4, ajouté dans la version 2025.11) et la conformité PDF/UA (y compris PDF/UA-2, ajouté dans la version 2025.12).
Entrée
L'exemple charge chaque PDF avec PdfDocument.FromFile, puis le convertit en PDF/A-3b en utilisant SaveAsPdfA avec le paramètre PdfAVersions.PdfA3b. Une autre fonction ConvertToPdfUA démontre la conversion de conformité d'accessibilité en utilisant SaveAsPdfUA, bien que PDF/UA nécessite des documents sources avec un balisage structurel approprié.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-format-conversion.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
using System.Threading;
string inputFolder = "originals/";
string outputFolder = "pdfa-archive/";
Directory.CreateDirectory(outputFolder);
string[] pdfFiles = Directory.GetFiles(inputFolder, "*.pdf");
Console.WriteLine($"Found {pdfFiles.Length} PDFs to convert to PDF/A-3b");
int converted = 0;
int failed = 0;
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(pdfFiles, options, pdfFile =>
{
string fileName = Path.GetFileName(pdfFile);
string outputPath = Path.Combine(outputFolder, fileName);
try
{
using var pdf = PdfDocument.FromFile(pdfFile);
// Convert to PDF/A-3b for long-term archival
pdf.SaveAsPdfA(outputPath, PdfAVersions.PdfA3b);
Interlocked.Increment(ref converted);
Console.WriteLine($"[OK] {fileName} → PDF/A-3b");
}
catch (Exception ex)
{
Interlocked.Increment(ref failed);
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
});
Console.WriteLine($"\nConversion complete: {converted} succeeded, {failed} failed");
// Alternative: Convert to PDF/UA for accessibility compliance
void ConvertToPdfUA(string inputFolder, string outputFolder)
{
Directory.CreateDirectory(outputFolder);
string[] files = Directory.GetFiles(inputFolder, "*.pdf");
Parallel.ForEach(files, pdfFile =>
{
string fileName = Path.GetFileName(pdfFile);
try
{
using var pdf = PdfDocument.FromFile(pdfFile);
// PDF/UA requires proper tagging - ensure source is well-structured
pdf.SaveAsPdfUA(Path.Combine(outputFolder, fileName));
Console.WriteLine($"[OK] {fileName} → PDF/UA");
}
catch (Exception ex)
{
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
});
}Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading.Tasks
Imports System.Threading
Module Program
Sub Main()
Dim inputFolder As String = "originals/"
Dim outputFolder As String = "pdfa-archive/"
Directory.CreateDirectory(outputFolder)
Dim pdfFiles As String() = Directory.GetFiles(inputFolder, "*.pdf")
Console.WriteLine($"Found {pdfFiles.Length} PDFs to convert to PDF/A-3b")
Dim converted As Integer = 0
Dim failed As Integer = 0
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(pdfFiles, options, Sub(pdfFile)
Dim fileName As String = Path.GetFileName(pdfFile)
Dim outputPath As String = Path.Combine(outputFolder, fileName)
Try
Using pdf = PdfDocument.FromFile(pdfFile)
' Convert to PDF/A-3b for long-term archival
pdf.SaveAsPdfA(outputPath, PdfAVersions.PdfA3b)
Interlocked.Increment(converted)
Console.WriteLine($"[OK] {fileName} → PDF/A-3b")
End Using
Catch ex As Exception
Interlocked.Increment(failed)
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End Sub)
Console.WriteLine($"{vbCrLf}Conversion complete: {converted} succeeded, {failed} failed")
End Sub
' Alternative: Convert to PDF/UA for accessibility compliance
Sub ConvertToPdfUA(inputFolder As String, outputFolder As String)
Directory.CreateDirectory(outputFolder)
Dim files As String() = Directory.GetFiles(inputFolder, "*.pdf")
Parallel.ForEach(files, Sub(pdfFile)
Dim fileName As String = Path.GetFileName(pdfFile)
Try
Using pdf = PdfDocument.FromFile(pdfFile)
' PDF/UA requires proper tagging - ensure source is well-structured
pdf.SaveAsPdfUA(Path.Combine(outputFolder, fileName))
Console.WriteLine($"[OK] {fileName} → PDF/UA")
End Using
Catch ex As Exception
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End Sub)
End Sub
End ModuleSortie
Le PDF de sortie est identique octet par octet, mais il contient désormais des métadonnées conformes à la norme PDF/A-3b pour les systèmes d'archivage.
La conversion de format est particulièrement importante pour les projets de mise en conformité, lorsqu'une organisation découvre que ses archives existantes ne répondent pas à une norme réglementaire. Le modèle de traitement par lots est simple, mais l'étape de validation est cruciale : vérifiez toujours que chaque fichier converti passe les contrôles de conformité avant de le considérer comme terminé. La validation est abordée en détail dans la section sur la résilience ci-dessous.
Construire des pipelines de traitement par lots résilients
Un pipeline de traitement par lots qui fonctionne parfaitement sur 100 fichiers et qui tombe en panne sur le fichier n° 4 327 sur 50 000 n'est pas utile. La résilience, c'est-à-dire la capacité à gérer les erreurs de manière gracieuse, à réessayer les défaillances transitoires et à reprendre après un crash, est ce qui différencie un pipeline de niveau de production d'un prototype.
Gestion des erreurs et saut en cas d'échec
Le modèle de résilience le plus élémentaire est le saut en cas d'échec : si le traitement d'un seul fichier échoue, enregistrez l'erreur et passez au fichier suivant au lieu d'interrompre tout le lot. Cela semble évident, mais il est étonnamment facile de le manquer lorsque vous utilisez Parallel.ForEach — une exception non gérée dans une tâche parallèle se propagera comme un AggregateException et terminera la boucle.
L'exemple suivant illustre à la fois la logique de saut en cas d'échec et la logique de nouvelle tentative — en enveloppant chaque fichier dans un bloc try-catch pour une gestion élégante des erreurs, avec une boucle de nouvelle tentative interne utilisant un délai exponentiel pour les exceptions transitoires comme IOException et OutOfMemoryException :
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-error-handling-retry.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
using System.Threading;
using System.Collections.Concurrent;
string inputFolder = "input/";
string outputFolder = "output/";
string errorLogPath = "error-log.txt";
Directory.CreateDirectory(outputFolder);
string[] htmlFiles = Directory.GetFiles(inputFolder, "*.html");
var renderer = new ChromePdfRenderer();
var errorLog = new ConcurrentBag<string>();
int processed = 0;
int failed = 0;
int retried = 0;
const int maxRetries = 3;
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(htmlFiles, options, htmlFile =>
{
string fileName = Path.GetFileNameWithoutExtension(htmlFile);
string outputPath = Path.Combine(outputFolder, $"{fileName}.pdf");
int attempt = 0;
bool success = false;
while (attempt < maxRetries && !success)
{
attempt++;
try
{
using var pdf = renderer.RenderHtmlFileAsPdf(htmlFile);
pdf.SaveAs(outputPath);
success = true;
Interlocked.Increment(ref processed);
if (attempt > 1)
{
Interlocked.Increment(ref retried);
Console.WriteLine($"[OK] {fileName}.pdf (succeeded on attempt {attempt})");
}
else
{
Console.WriteLine($"[OK] {fileName}.pdf");
}
}
catch (Exception ex) when (IsTransientException(ex) && attempt < maxRetries)
{
// Transient error - wait and retry with exponential backoff
int delayMs = (int)Math.Pow(2, attempt) * 500;
Console.WriteLine($"[RETRY] {fileName}: {ex.Message} (attempt {attempt}, waiting {delayMs}ms)");
Thread.Sleep(delayMs);
}
catch (Exception ex)
{
// Non-transient error or max retries exceeded
Interlocked.Increment(ref failed);
string errorMessage = $"{DateTime.Now:yyyy-MM-dd HH:mm:ss} | {fileName} | {ex.GetType().Name} | {ex.Message}";
errorLog.Add(errorMessage);
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
}
});
// Write error log
if (errorLog.Count > 0)
{
File.WriteAllLines(errorLogPath, errorLog);
}
Console.WriteLine($"\nBatch complete:");
Console.WriteLine($" Processed: {processed}");
Console.WriteLine($" Failed: {failed}");
Console.WriteLine($" Retried: {retried}");
if (failed > 0)
{
Console.WriteLine($" Error log: {errorLogPath}");
}
// Helper to identify transient exceptions worth retrying
bool IsTransientException(Exception ex)
{
return ex is IOException ||
ex is OutOfMemoryException ||
ex.Message.Contains("timeout", StringComparison.OrdinalIgnoreCase) ||
ex.Message.Contains("locked", StringComparison.OrdinalIgnoreCase);
}Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading
Imports System.Collections.Concurrent
Module Program
Sub Main()
Dim inputFolder As String = "input/"
Dim outputFolder As String = "output/"
Dim errorLogPath As String = "error-log.txt"
Directory.CreateDirectory(outputFolder)
Dim htmlFiles As String() = Directory.GetFiles(inputFolder, "*.html")
Dim renderer As New ChromePdfRenderer()
Dim errorLog As New ConcurrentBag(Of String)()
Dim processed As Integer = 0
Dim failed As Integer = 0
Dim retried As Integer = 0
Const maxRetries As Integer = 3
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(htmlFiles, options, Sub(htmlFile)
Dim fileName As String = Path.GetFileNameWithoutExtension(htmlFile)
Dim outputPath As String = Path.Combine(outputFolder, $"{fileName}.pdf")
Dim attempt As Integer = 0
Dim success As Boolean = False
While attempt < maxRetries AndAlso Not success
attempt += 1
Try
Using pdf = renderer.RenderHtmlFileAsPdf(htmlFile)
pdf.SaveAs(outputPath)
success = True
Interlocked.Increment(processed)
If attempt > 1 Then
Interlocked.Increment(retried)
Console.WriteLine($"[OK] {fileName}.pdf (succeeded on attempt {attempt})")
Else
Console.WriteLine($"[OK] {fileName}.pdf")
End If
End Using
Catch ex As Exception When IsTransientException(ex) AndAlso attempt < maxRetries
' Transient error - wait and retry with exponential backoff
Dim delayMs As Integer = CInt(Math.Pow(2, attempt)) * 500
Console.WriteLine($"[RETRY] {fileName}: {ex.Message} (attempt {attempt}, waiting {delayMs}ms)")
Thread.Sleep(delayMs)
Catch ex As Exception
' Non-transient error or max retries exceeded
Interlocked.Increment(failed)
Dim errorMessage As String = $"{DateTime.Now:yyyy-MM-dd HH:mm:ss} | {fileName} | {ex.GetType().Name} | {ex.Message}"
errorLog.Add(errorMessage)
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End While
End Sub)
' Write error log
If errorLog.Count > 0 Then
File.WriteAllLines(errorLogPath, errorLog)
End If
Console.WriteLine($"{vbCrLf}Batch complete:")
Console.WriteLine($" Processed: {processed}")
Console.WriteLine($" Failed: {failed}")
Console.WriteLine($" Retried: {retried}")
If failed > 0 Then
Console.WriteLine($" Error log: {errorLogPath}")
End If
End Sub
' Helper to identify transient exceptions worth retrying
Function IsTransientException(ex As Exception) As Boolean
Return TypeOf ex Is IOException OrElse
TypeOf ex Is OutOfMemoryException OrElse
ex.Message.Contains("timeout", StringComparison.OrdinalIgnoreCase) OrElse
ex.Message.Contains("locked", StringComparison.OrdinalIgnoreCase)
End Function
End ModuleUne fois le lot terminé, examinez le journal des erreurs pour comprendre quels fichiers ont échoué et pourquoi. Les causes d'échec les plus courantes sont les fichiers sources corrompus, les PDF protégés par un mot de passe, les fonctionnalités non prises en charge dans le contenu source et la saturation de la mémoire pour les documents très volumineux.
Logique de réaction pour les défaillances transitoires
Certains échecs sont passagers - ils réussiront si vous réessayez. Il s'agit notamment de la contention du système de fichiers (un autre processus a verrouillé le fichier), de la pression de la mémoire temporaire (le GC n'a pas encore rattrapé son retard) et des délais d'attente du réseau lors du chargement de ressources externes dans le contenu HTML. L'exemple de code ci-dessus traite ces tentatives avec un backoff exponentiel - en commençant par un court délai et en le doublant à chaque nouvelle tentative, jusqu'à un nombre maximum de tentatives (généralement 3).
L'essentiel est de faire la distinction entre les échecs qui peuvent être répétés et ceux qui ne peuvent pas l'être. Un IOException (fichier verrouillé) ou OutOfMemoryException (pression temporaire) mérite d'être réessayé. Une erreur ArgumentException (entrée invalide) ou une erreur de rendu cohérente ne sont pas utiles — réessayer ne servira à rien et vous gaspillerez du temps et des ressources.
Création de points de contrôle pour la reprise après un crash
Lorsqu'un travail par lots traite 50 000 fichiers pendant plusieurs heures, un plantage au niveau du fichier n° 35 000 ne devrait pas signifier qu'il faut recommencer depuis le début. Le point de contrôle, qui consiste à enregistrer les fichiers qui ont été traités avec succès, vous permet de reprendre le travail là où vous l'avez laissé.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-checkpointing.csusing IronPdf;
using System;
using System.IO;
using System.Linq;
using System.Threading.Tasks;
using System.Threading;
using System.Collections.Generic;
string inputFolder = "input/";
string outputFolder = "output/";
string checkpointPath = "checkpoint.txt";
string errorLogPath = "errors.txt";
Directory.CreateDirectory(outputFolder);
// Load checkpoint - files already processed successfully
var completedFiles = new HashSet<string>();
if (File.Exists(checkpointPath))
{
completedFiles = new HashSet<string>(File.ReadAllLines(checkpointPath));
Console.WriteLine($"Resuming from checkpoint: {completedFiles.Count} files already processed");
}
// Get files to process (excluding already completed)
string[] allFiles = Directory.GetFiles(inputFolder, "*.html");
string[] filesToProcess = allFiles
.Where(f => !completedFiles.Contains(Path.GetFileName(f)))
.ToArray();
Console.WriteLine($"Files to process: {filesToProcess.Length} (skipping {completedFiles.Count} already done)");
var renderer = new ChromePdfRenderer();
var checkpointLock = new object();
int processed = 0;
int failed = 0;
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(filesToProcess, options, htmlFile =>
{
string fileName = Path.GetFileName(htmlFile);
string baseName = Path.GetFileNameWithoutExtension(htmlFile);
string outputPath = Path.Combine(outputFolder, $"{baseName}.pdf");
try
{
using var pdf = renderer.RenderHtmlFileAsPdf(htmlFile);
pdf.SaveAs(outputPath);
// Record success in checkpoint (thread-safe)
lock (checkpointLock)
{
File.AppendAllText(checkpointPath, fileName + Environment.NewLine);
}
Interlocked.Increment(ref processed);
Console.WriteLine($"[OK] {baseName}.pdf");
}
catch (Exception ex)
{
Interlocked.Increment(ref failed);
// Log error for review
lock (checkpointLock)
{
File.AppendAllText(errorLogPath,
$"{DateTime.Now:yyyy-MM-dd HH:mm:ss} | {fileName} | {ex.Message}{Environment.NewLine}");
}
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
});
Console.WriteLine($"\nBatch complete:");
Console.WriteLine($" Newly processed: {processed}");
Console.WriteLine($" Failed: {failed}");
Console.WriteLine($" Total completed: {completedFiles.Count + processed}");
Console.WriteLine($" Checkpoint saved to: {checkpointPath}");Imports IronPdf
Imports System
Imports System.IO
Imports System.Linq
Imports System.Threading.Tasks
Imports System.Threading
Imports System.Collections.Generic
Module Program
Sub Main()
Dim inputFolder As String = "input/"
Dim outputFolder As String = "output/"
Dim checkpointPath As String = "checkpoint.txt"
Dim errorLogPath As String = "errors.txt"
Directory.CreateDirectory(outputFolder)
' Load checkpoint - files already processed successfully
Dim completedFiles As New HashSet(Of String)()
If File.Exists(checkpointPath) Then
completedFiles = New HashSet(Of String)(File.ReadAllLines(checkpointPath))
Console.WriteLine($"Resuming from checkpoint: {completedFiles.Count} files already processed")
End If
' Get files to process (excluding already completed)
Dim allFiles As String() = Directory.GetFiles(inputFolder, "*.html")
Dim filesToProcess As String() = allFiles _
.Where(Function(f) Not completedFiles.Contains(Path.GetFileName(f))) _
.ToArray()
Console.WriteLine($"Files to process: {filesToProcess.Length} (skipping {completedFiles.Count} already done)")
Dim renderer As New ChromePdfRenderer()
Dim checkpointLock As New Object()
Dim processed As Integer = 0
Dim failed As Integer = 0
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(filesToProcess, options, Sub(htmlFile)
Dim fileName As String = Path.GetFileName(htmlFile)
Dim baseName As String = Path.GetFileNameWithoutExtension(htmlFile)
Dim outputPath As String = Path.Combine(outputFolder, $"{baseName}.pdf")
Try
Using pdf = renderer.RenderHtmlFileAsPdf(htmlFile)
pdf.SaveAs(outputPath)
End Using
' Record success in checkpoint (thread-safe)
SyncLock checkpointLock
File.AppendAllText(checkpointPath, fileName & Environment.NewLine)
End SyncLock
Interlocked.Increment(processed)
Console.WriteLine($"[OK] {baseName}.pdf")
Catch ex As Exception
Interlocked.Increment(failed)
' Log error for review
SyncLock checkpointLock
File.AppendAllText(errorLogPath,
$"{DateTime.Now:yyyy-MM-dd HH:mm:ss} | {fileName} | {ex.Message}{Environment.NewLine}")
End SyncLock
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End Sub)
Console.WriteLine(vbCrLf & "Batch complete:")
Console.WriteLine($" Newly processed: {processed}")
Console.WriteLine($" Failed: {failed}")
Console.WriteLine($" Total completed: {completedFiles.Count + processed}")
Console.WriteLine($" Checkpoint saved to: {checkpointPath}")
End Sub
End ModuleLe fichier de points de contrôle sert d'enregistrement permanent du travail effectué. Lorsque le pipeline démarre, il lit le fichier de point de contrôle et ignore tous les fichiers qui ont déjà été traités avec succès. Lorsqu'un fichier a terminé son traitement, son chemin d'accès est ajouté au fichier de point de contrôle. Cette approche est simple, basée sur les fichiers et ne nécessite aucune dépendance externe.
Pour des scénarios plus sophistiqués, envisagez d'utiliser une table de base de données ou un cache distribué (comme Redis) comme magasin de points de contrôle, en particulier si plusieurs travailleurs traitent des fichiers en parallèle sur différentes machines.
Validation avant et après traitement
La validation est le pilier d'un pipeline résilient. La validation avant traitement permet de détecter les entrées problématiques avant qu'elles ne gaspillent du temps de traitement ; la validation après traitement garantit que les résultats répondent à vos exigences en matière de qualité et de conformité.
Entrée
Cette implémentation enveloppe la boucle de traitement avec les fonctions d'assistance PreValidate et PostValidate. La pré-validation vérifie la taille du fichier, le type de contenu et la structure HTML de base avant le traitement. La post-validation vérifie que le PDF de sortie a un nombre de pages valide et une taille de fichier raisonnable, en déplaçant les fichiers validés dans un dossier distinct et en acheminant les fichiers non validés vers un dossier de rejet pour un examen manuel.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-validation.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
using System.Threading;
using System.Collections.Concurrent;
string inputFolder = "input/";
string outputFolder = "output/";
string validatedFolder = "validated/";
string rejectedFolder = "rejected/";
Directory.CreateDirectory(outputFolder);
Directory.CreateDirectory(validatedFolder);
Directory.CreateDirectory(rejectedFolder);
string[] inputFiles = Directory.GetFiles(inputFolder, "*.html");
var renderer = new ChromePdfRenderer();
int preValidationFailed = 0;
int processingFailed = 0;
int postValidationFailed = 0;
int succeeded = 0;
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(inputFiles, options, inputFile =>
{
string fileName = Path.GetFileNameWithoutExtension(inputFile);
string outputPath = Path.Combine(outputFolder, $"{fileName}.pdf");
// Pre-validation: Check input file
if (!PreValidate(inputFile))
{
Interlocked.Increment(ref preValidationFailed);
Console.WriteLine($"[SKIP] {fileName}: Failed pre-validation");
return;
}
try
{
// Process
using var pdf = renderer.RenderHtmlFileAsPdf(inputFile);
pdf.SaveAs(outputPath);
// Post-validation: Check output file
if (PostValidate(outputPath))
{
// Move to validated folder
string validatedPath = Path.Combine(validatedFolder, $"{fileName}.pdf");
File.Move(outputPath, validatedPath, overwrite: true);
Interlocked.Increment(ref succeeded);
Console.WriteLine($"[OK] {fileName}.pdf (validated)");
}
else
{
// Move to rejected folder for manual review
string rejectedPath = Path.Combine(rejectedFolder, $"{fileName}.pdf");
File.Move(outputPath, rejectedPath, overwrite: true);
Interlocked.Increment(ref postValidationFailed);
Console.WriteLine($"[REJECT] {fileName}.pdf: Failed post-validation");
}
}
catch (Exception ex)
{
Interlocked.Increment(ref processingFailed);
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
});
Console.WriteLine($"\nValidation summary:");
Console.WriteLine($" Succeeded: {succeeded}");
Console.WriteLine($" Pre-validation failed: {preValidationFailed}");
Console.WriteLine($" Processing failed: {processingFailed}");
Console.WriteLine($" Post-validation failed: {postValidationFailed}");
// Pre-validation: Quick checks on input file
bool PreValidate(string filePath)
{
try
{
var fileInfo = new FileInfo(filePath);
// Check file exists and is readable
if (!fileInfo.Exists) return false;
// Check file is not empty
if (fileInfo.Length == 0) return false;
// Check file is not too large (e.g., 50MB limit)
if (fileInfo.Length > 50 * 1024 * 1024) return false;
// Quick content check - must be valid HTML
string content = File.ReadAllText(filePath);
if (string.IsNullOrWhiteSpace(content)) return false;
if (!content.Contains("<html", StringComparison.OrdinalIgnoreCase) &&
!content.Contains("<!DOCTYPE", StringComparison.OrdinalIgnoreCase))
{
return false;
}
return true;
}
catch
{
return false;
}
}
// Post-validation: Verify output PDF meets requirements
bool PostValidate(string pdfPath)
{
try
{
using var pdf = PdfDocument.FromFile(pdfPath);
// Check PDF has at least one page
if (pdf.PageCount < 1) return false;
// Check file size is reasonable (not just header, not corrupted)
var fileInfo = new FileInfo(pdfPath);
if (fileInfo.Length < 1024) return false;
return true;
}
catch
{
return false;
}
}Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading.Tasks
Imports System.Threading
Imports System.Collections.Concurrent
Module Program
Sub Main()
Dim inputFolder As String = "input/"
Dim outputFolder As String = "output/"
Dim validatedFolder As String = "validated/"
Dim rejectedFolder As String = "rejected/"
Directory.CreateDirectory(outputFolder)
Directory.CreateDirectory(validatedFolder)
Directory.CreateDirectory(rejectedFolder)
Dim inputFiles As String() = Directory.GetFiles(inputFolder, "*.html")
Dim renderer As New ChromePdfRenderer()
Dim preValidationFailed As Integer = 0
Dim processingFailed As Integer = 0
Dim postValidationFailed As Integer = 0
Dim succeeded As Integer = 0
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(inputFiles, options, Sub(inputFile)
Dim fileName As String = Path.GetFileNameWithoutExtension(inputFile)
Dim outputPath As String = Path.Combine(outputFolder, $"{fileName}.pdf")
' Pre-validation: Check input file
If Not PreValidate(inputFile) Then
Interlocked.Increment(preValidationFailed)
Console.WriteLine($"[SKIP] {fileName}: Failed pre-validation")
Return
End If
Try
' Process
Using pdf = renderer.RenderHtmlFileAsPdf(inputFile)
pdf.SaveAs(outputPath)
' Post-validation: Check output file
If PostValidate(outputPath) Then
' Move to validated folder
Dim validatedPath As String = Path.Combine(validatedFolder, $"{fileName}.pdf")
File.Move(outputPath, validatedPath, overwrite:=True)
Interlocked.Increment(succeeded)
Console.WriteLine($"[OK] {fileName}.pdf (validated)")
Else
' Move to rejected folder for manual review
Dim rejectedPath As String = Path.Combine(rejectedFolder, $"{fileName}.pdf")
File.Move(outputPath, rejectedPath, overwrite:=True)
Interlocked.Increment(postValidationFailed)
Console.WriteLine($"[REJECT] {fileName}.pdf: Failed post-validation")
End If
End Using
Catch ex As Exception
Interlocked.Increment(processingFailed)
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End Sub)
Console.WriteLine(vbCrLf & "Validation summary:")
Console.WriteLine($" Succeeded: {succeeded}")
Console.WriteLine($" Pre-validation failed: {preValidationFailed}")
Console.WriteLine($" Processing failed: {processingFailed}")
Console.WriteLine($" Post-validation failed: {postValidationFailed}")
End Sub
' Pre-validation: Quick checks on input file
Function PreValidate(filePath As String) As Boolean
Try
Dim fileInfo As New FileInfo(filePath)
' Check file exists and is readable
If Not fileInfo.Exists Then Return False
' Check file is not empty
If fileInfo.Length = 0 Then Return False
' Check file is not too large (e.g., 50MB limit)
If fileInfo.Length > 50 * 1024 * 1024 Then Return False
' Quick content check - must be valid HTML
Dim content As String = File.ReadAllText(filePath)
If String.IsNullOrWhiteSpace(content) Then Return False
If Not content.Contains("<html", StringComparison.OrdinalIgnoreCase) AndAlso
Not content.Contains("<!DOCTYPE", StringComparison.OrdinalIgnoreCase) Then
Return False
End If
Return True
Catch
Return False
End Try
End Function
' Post-validation: Verify output PDF meets requirements
Function PostValidate(pdfPath As String) As Boolean
Try
Using pdf = PdfDocument.FromFile(pdfPath)
' Check PDF has at least one page
If pdf.PageCount < 1 Then Return False
' Check file size is reasonable (not just header, not corrupted)
Dim fileInfo As New FileInfo(pdfPath)
If fileInfo.Length < 1024 Then Return False
Return True
End Using
Catch
Return False
End Try
End Function
End ModuleSortie
Les 5 fichiers ont passé la validation et ont été déplacés vers le dossier validé.
La validation du prétraitement doit être rapide - vous vérifiez les entrées manifestement erronées, vous ne procédez pas à un traitement complet. La validation post-traitement peut être plus approfondie, en particulier pour les conversions de conformité où le résultat doit satisfaire à des normes spécifiques (PDF/A, PDF/UA). Tout fichier qui échoue à la validation post-traitement doit être signalé pour une révision manuelle plutôt que d'être accepté silencieusement.
Modèles de traitement synchrone et parallèle
IronPDF prend en charge à la fois Parallel.ForEach (parallélisme basé sur les threads) et async/await (E/S asynchrones). Comprendre quand utiliser chacun d'entre eux - et comment les combiner efficacement - est essentiel pour maximiser le rendement.
Intégration de la bibliothèque parallèle des tâches
Parallel.ForEach est l'approche la plus simple et la plus efficace pour les opérations par lots limitées au processeur. Le moteur de rendu d'IronPDF est gourmand en ressources CPU (analyse HTML, mise en page CSS, rastérisation d'images), et Parallel.ForEach répartit automatiquement ce travail sur tous les cœurs disponibles.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-tpl.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
using System.Threading;
using System.Diagnostics;
string inputFolder = "input/";
string outputFolder = "output/";
Directory.CreateDirectory(outputFolder);
string[] htmlFiles = Directory.GetFiles(inputFolder, "*.html");
var renderer = new ChromePdfRenderer();
Console.WriteLine($"Processing {htmlFiles.Length} files with {Environment.ProcessorCount} CPU cores");
int processed = 0;
var stopwatch = Stopwatch.StartNew();
// Configure parallelism based on system resources
// Rule of thumb: ProcessorCount / 2 for memory-intensive operations
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Math.Max(1, Environment.ProcessorCount / 2)
};
Console.WriteLine($"Max parallelism: {options.MaxDegreeOfParallelism}");
// Use Parallel.ForEach for CPU-bound batch operations
Parallel.ForEach(htmlFiles, options, htmlFile =>
{
string fileName = Path.GetFileNameWithoutExtension(htmlFile);
string outputPath = Path.Combine(outputFolder, $"{fileName}.pdf");
try
{
// Render HTML to PDF
using var pdf = renderer.RenderHtmlFileAsPdf(htmlFile);
pdf.SaveAs(outputPath);
int current = Interlocked.Increment(ref processed);
// Progress reporting every 10 files
if (current % 10 == 0)
{
double elapsed = stopwatch.Elapsed.TotalSeconds;
double rate = current / elapsed;
double remaining = (htmlFiles.Length - current) / rate;
Console.WriteLine($"Progress: {current}/{htmlFiles.Length} ({rate:F1} files/sec, ~{remaining:F0}s remaining)");
}
}
catch (Exception ex)
{
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
});
stopwatch.Stop();
double totalRate = processed / stopwatch.Elapsed.TotalSeconds;
Console.WriteLine($"\nComplete:");
Console.WriteLine($" Files processed: {processed}/{htmlFiles.Length}");
Console.WriteLine($" Total time: {stopwatch.Elapsed.TotalSeconds:F1}s");
Console.WriteLine($" Average rate: {totalRate:F1} files/sec");
Console.WriteLine($" Time per file: {stopwatch.Elapsed.TotalMilliseconds / processed:F0}ms");
// Memory monitoring helper (call between chunks for large batches)
void CheckMemoryPressure()
{
const long memoryThreshold = 4L * 1024 * 1024 * 1024; // 4 GB
long currentMemory = GC.GetTotalMemory(forceFullCollection: false);
if (currentMemory > memoryThreshold)
{
Console.WriteLine($"Memory pressure detected ({currentMemory / 1024 / 1024}MB), forcing GC...");
GC.Collect();
GC.WaitForPendingFinalizers();
GC.Collect();
}
}Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading.Tasks
Imports System.Threading
Imports System.Diagnostics
Module Program
Sub Main()
Dim inputFolder As String = "input/"
Dim outputFolder As String = "output/"
Directory.CreateDirectory(outputFolder)
Dim htmlFiles As String() = Directory.GetFiles(inputFolder, "*.html")
Dim renderer As New ChromePdfRenderer()
Console.WriteLine($"Processing {htmlFiles.Length} files with {Environment.ProcessorCount} CPU cores")
Dim processed As Integer = 0
Dim stopwatch As Stopwatch = Stopwatch.StartNew()
' Configure parallelism based on system resources
' Rule of thumb: ProcessorCount / 2 for memory-intensive operations
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Math.Max(1, Environment.ProcessorCount \ 2)
}
Console.WriteLine($"Max parallelism: {options.MaxDegreeOfParallelism}")
' Use Parallel.ForEach for CPU-bound batch operations
Parallel.ForEach(htmlFiles, options, Sub(htmlFile)
Dim fileName As String = Path.GetFileNameWithoutExtension(htmlFile)
Dim outputPath As String = Path.Combine(outputFolder, $"{fileName}.pdf")
Try
' Render HTML to PDF
Using pdf = renderer.RenderHtmlFileAsPdf(htmlFile)
pdf.SaveAs(outputPath)
End Using
Dim current As Integer = Interlocked.Increment(processed)
' Progress reporting every 10 files
If current Mod 10 = 0 Then
Dim elapsed As Double = stopwatch.Elapsed.TotalSeconds
Dim rate As Double = current / elapsed
Dim remaining As Double = (htmlFiles.Length - current) / rate
Console.WriteLine($"Progress: {current}/{htmlFiles.Length} ({rate:F1} files/sec, ~{remaining:F0}s remaining)")
End If
Catch ex As Exception
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End Sub)
stopwatch.Stop()
Dim totalRate As Double = processed / stopwatch.Elapsed.TotalSeconds
Console.WriteLine(vbCrLf & "Complete:")
Console.WriteLine($" Files processed: {processed}/{htmlFiles.Length}")
Console.WriteLine($" Total time: {stopwatch.Elapsed.TotalSeconds:F1}s")
Console.WriteLine($" Average rate: {totalRate:F1} files/sec")
Console.WriteLine($" Time per file: {stopwatch.Elapsed.TotalMilliseconds / processed:F0}ms")
' Memory monitoring helper (call between chunks for large batches)
CheckMemoryPressure()
End Sub
Sub CheckMemoryPressure()
Const memoryThreshold As Long = 4L * 1024 * 1024 * 1024 ' 4 GB
Dim currentMemory As Long = GC.GetTotalMemory(forceFullCollection:=False)
If currentMemory > memoryThreshold Then
Console.WriteLine($"Memory pressure detected ({currentMemory \ 1024 \ 1024}MB), forcing GC...")
GC.Collect()
GC.WaitForPendingFinalizers()
GC.Collect()
End If
End Sub
End ModuleL'option MaxDegreeOfParallelism est essentielle. Sans cela, la TPL essaiera d'utiliser tous les cœurs disponibles, ce qui peut saturer la mémoire si chaque rendu est gourmand en ressources. Définissez ce paramètre en fonction de la RAM disponible de votre système divisée par la consommation de mémoire typique par rendu (généralement 100-300 Mo par rendu simultané pour le HTML complexe).
Contrôle de la simultanéité (SemaphoreSlim)
Lorsque vous avez besoin d'un contrôle plus précis sur la concurrence que celui fourni par Parallel.ForEach — par exemple, lors du mélange d'E/S asynchrones avec un rendu limité par le processeur — SemaphoreSlim vous donne un contrôle explicite sur le nombre d'opérations exécutées simultanément. Le modèle est simple : créez un SemaphoreSlim avec votre limite de concurrence souhaitée (par exemple, 4 rendus simultanés), appelez WaitAsync avant chaque rendu, et Release dans un bloc finally après. Lancez ensuite toutes les tâches avec Task.WhenAll.
Ce modèle est particulièrement utile lorsque votre pipeline comprend à la fois des étapes liées aux E/S (lecture de fichiers à partir d'un stockage blob, écriture de résultats dans une base de données) et des étapes liées à l'unité centrale (rendu de PDF). Le sémaphore limite la simultanéité du rendu lié à l'unité centrale tout en permettant aux étapes liées aux entrées/sorties de se dérouler sans ralentissement.
Bonnes pratiques d'asynchronisme et d'attente
IronPDF propose des variantes asynchrones de ses méthodes de rendu, notamment RenderHtmlAsPdfAsync, RenderUrlAsPdfAsync et RenderHtmlFileAsPdfAsync. Ces outils sont idéaux pour les applications web (où le blocage du thread de requête est inacceptable) et pour les pipelines qui mélangent le rendu PDF avec des opérations d'E/S asynchrones.
Quelques bonnes pratiques asynchrones importantes pour le traitement par lots :
N'utilisez pas Task.Run pour encapsuler les méthodes IronPDF synchrones — utilisez plutôt les variantes asynchrones natives. Envelopper les méthodes synchrones dans Task.Run gaspille un thread du pool de threads et ajoute une surcharge sans aucun avantage.
N'utilisez pas .Result ou .Wait() sur les tâches asynchrones — cela bloque le thread appelant et peut provoquer des blocages dans les contextes d'interface utilisateur ou ASP.NET . Utilisez toujours await.
Regroupez vos appels Task.WhenAll au lieu d'attendre que toutes les tâches soient effectuées en même temps. Si vous avez 10 000 tâches et que vous appelez Task.WhenAll sur toutes simultanément, vous lancerez 10 000 opérations simultanées. Utilisez plutôt .Chunk(10) ou une approche similaire pour les traiter par groupes, en attendant chaque groupe séquentiellement.
Éviter l'épuisement de la mémoire
L'épuisement de la mémoire est le mode d'échec le plus courant dans le traitement PDF par lots. L'approche défensive consiste à surveiller l'utilisation de la mémoire avec GC.GetTotalMemory() avant chaque rendu et à déclencher une collecte lorsque la consommation dépasse un seuil (par exemple, 4 Go ou 80 % de la RAM disponible). Appelez GC.Collect() suivi de GC.WaitForPendingFinalizers() et d'un deuxième GC.Collect() pour récupérer autant de mémoire que possible avant de continuer. Cela ajoute une petite pause mais empêche l'alternative catastrophique d'un OutOfMemoryException faisant planter tout votre lot au fichier n° 30 000.
Combinez cela avec la limitation MaxDegreeOfParallelism de la section TPL et le modèle d'élimination using de la section de gestion de la mémoire, et vous obtenez une défense à trois niveaux contre les problèmes de mémoire : limiter la concurrence, éliminer de manière agressive et surveiller avec une soupape de sécurité.
Déploiement dans le nuage pour les travaux par lots
Le traitement par lots moderne s'exécute de plus en plus dans le nuage, où il est possible d'adapter les ressources de calcul aux exigences de la charge de travail et de ne payer que pour ce que l'on utilise. IronPDF fonctionne sur les principales plateformes cloud - voici comment architecturer des pipelines de traitement par lots pour chacune d'entre elles.
Azure Functions avec des fonctions durables
Les fonctions durables Azure offrent une orchestration intégrée pour les modèles fan-out/fan-in, ce qui en fait un outil naturel pour le traitement PDF par lots. La fonction d'orchestration répartit le travail entre plusieurs instances de fonctions d'activité, chacune traitant un sous-ensemble de fichiers. Votre orchestrateur appelle CallActivityAsync dans une boucle de diffusion, chaque fonction d'activité instancie un ChromePdfRenderer, traite son bloc de fichiers et l'orchestrateur collecte les résultats.
Principales considérations concernant Azure Functions : le plan de consommation par défaut prévoit un délai de 5 minutes par invocation de fonction et une mémoire limitée. Pour le traitement par lots, utilisez le plan Premium ou Dedicated, qui prend en charge des délais d'attente plus longs et davantage de mémoire. IronPDF nécessite le runtime .NET complet (non rogné), assurez-vous donc que votre application fonctionnelle est configurée for .NET 8+ avec l'identifiant de runtime approprié.
AWS Lambda avec Step Functions
AWS Step Functions offre une capacité d'orchestration similaire à Azure Durable Functions. Chaque étape de la machine d'état invoque une fonction Lambda qui traite un bloc de fichiers. Votre gestionnaire Lambda reçoit un lot de clés d'objets S3, charge chaque PDF avec PdfDocument.FromFile, applique votre pipeline de traitement (compression, conversion de format, etc.) et réécrit les résultats dans un compartiment S3 de sortie.
AWS Lambda a une durée d'exécution maximale de 15 minutes et un stockage limité (512 Mo par défaut, configurable jusqu'à 10 Go). Pour les gros travaux par lots, utilisez les fonctions d'étape pour diviser la charge de travail et traiter chaque morceau dans une invocation Lambda distincte. Stockez les résultats intermédiaires dans S3 plutôt qu'en local.
Planification des tâches Kubernetes
Pour les organisations qui exploitent leurs propres clusters Kubernetes, le traitement PDF par lots s'adapte bien aux Jobs Kubernetes et aux CronJobs. Chaque pod exécute un travailleur par lots qui extrait des fichiers d'une file d'attente (Azure Service Bus, RabbitMQ ou SQS), les traite avec IronPDF et écrit les résultats dans le stockage d'objets. La boucle de travail suit le même modèle que celui décrit dans les sections précédentes : retirer un message de la file d'attente, utiliser ChromePdfRenderer.RenderHtmlAsPdf() ou PdfDocument.FromFile() pour traiter le document, télécharger le résultat et accuser réception du message. Enveloppez le traitement dans le même try-catch avec la logique de nouvelle tentative des modèles de résilience, et utilisez SemaphoreSlim pour contrôler la concurrence par pod.
IronPdf assure la prise en charge officielle de Docker et fonctionne sur des conteneurs Linux. Utilisez le package NuGet IronPdf avec les packages d'exécution natifs appropriés pour le système d'exploitation de votre conteneur (par exemple, IronPdf.Linux pour les images basées sur Linux). Pour Kubernetes, définissez des demandes et des limites de ressources qui correspondent aux besoins en mémoire d'IronPDF (généralement 512 Mo-2 Go par pod en fonction de la concurrence). Horizontal Pod Autoscaler peut faire évoluer les travailleurs en fonction de la profondeur de la file d'attente, et le modèle de point de contrôle garantit qu'aucun travail n'est perdu si les pods sont expulsés.
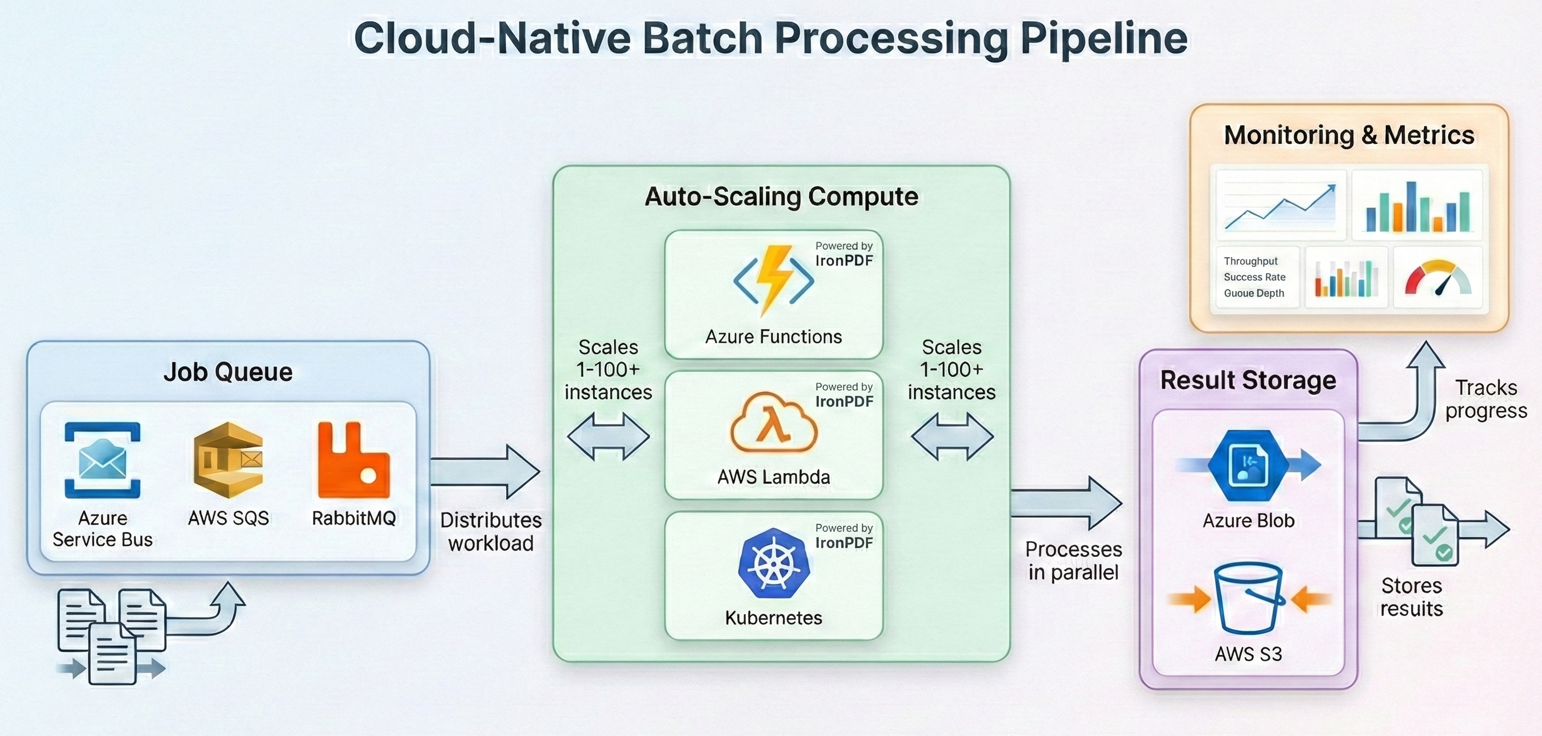
Stratégies d'optimisation des coûts
Le traitement par lots dans le nuage peut s'avérer coûteux si vous n'êtes pas attentif à l'allocation des ressources. Voici les stratégies qui ont le plus d'impact :
Dimensionnez votre calcul Le rendu PDF est gourmand en ressources processeur et mémoire, et non en ressources GPU. Utilisez des instances optimisées pour le calcul (C-series sur Azure, C-type sur AWS) plutôt que des instances polyvalentes ou optimisées pour la mémoire. Vous obtiendrez un meilleur rapport prix/rendu.
Utiliser des instances ponctuelles/préemptibles pour les charges de travail par lots qui peuvent tolérer une interruption. Le traitement PDF par lots est intrinsèquement reproductible (grâce au point de contrôle), ce qui en fait un candidat idéal pour la tarification au comptant, qui offre généralement des réductions de 60 à 90 % par rapport à la tarification à la demande.
Traiter pendant les heures creuses si votre emploi du temps le permet. De nombreux fournisseurs de services en nuage proposent des prix plus bas ou une plus grande disponibilité de l'espace pendant les nuits et les week-ends.
Compressez au plus tôt, stockez une seule fois. Intégrez la compression dans votre pipeline de traitement plutôt que comme une étape distincte. Le stockage des PDF compressés dès le départ permet de réduire les coûts de stockage tout au long de la durée de vie de l'archive.
Hiérarchisez votre stockage. Les PDF traités auxquels on accède fréquemment doivent être stockés dans un espace de stockage à chaud ; les PDF archivés qui sont rarement consultés devraient être déplacés vers des niveaux de refroidissement ou d'archivage (Azure Cool/Archive, AWS S3 Glacier). Cette seule opération peut permettre de réduire les coûts de stockage de 50 à 80 %.
Exemple réel de pipeline
Lions le tout avec un pipeline de traitement par lots complet, de qualité production, qui illustre l'ensemble du flux de travail : Ingest → Validate → Process → Archive → Report.
Cet exemple traite un répertoire de modèles de factures HTML, les convertit en PDF, compresse le résultat, le convertit en PDF/A-3b pour l'archivage, valide le résultat et produit un rapport récapitulatif à la fin.
En utilisant les mêmes 5 factures HTML que dans l'exemple de conversion par lots ci-dessus...
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-full-pipeline.csusing IronPdf;
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Threading.Tasks;
using System.Threading;
using System.Collections.Concurrent;
using System.Diagnostics;
using System.Text.Json;
// Configuration
var config = new PipelineConfig
{
InputFolder = "input/",
OutputFolder = "output/",
ArchiveFolder = "archive/",
ErrorFolder = "errors/",
CheckpointPath = "pipeline-checkpoint.json",
ReportPath = "pipeline-report.json",
MaxConcurrency = Math.Max(1, Environment.ProcessorCount / 2),
MaxRetries = 3,
JpegQuality = 70
};
// Initialize folders
Directory.CreateDirectory(config.OutputFolder);
Directory.CreateDirectory(config.ArchiveFolder);
Directory.CreateDirectory(config.ErrorFolder);
// Load checkpoint for resume capability
var checkpoint = LoadCheckpoint(config.CheckpointPath);
var results = new ConcurrentBag<ProcessingResult>();
var stopwatch = Stopwatch.StartNew();
// Get files to process
string[] allFiles = Directory.GetFiles(config.InputFolder, "*.html");
string[] filesToProcess = allFiles
.Where(f => !checkpoint.CompletedFiles.Contains(Path.GetFileName(f)))
.ToArray();
Console.WriteLine($"Pipeline starting:");
Console.WriteLine($" Total files: {allFiles.Length}");
Console.WriteLine($" Already processed: {checkpoint.CompletedFiles.Count}");
Console.WriteLine($" To process: {filesToProcess.Length}");
Console.WriteLine($" Concurrency: {config.MaxConcurrency}");
var renderer = new ChromePdfRenderer();
var checkpointLock = new object();
var options = new ParallelOptions
{
MaxDegreeOfParallelism = config.MaxConcurrency
};
Parallel.ForEach(filesToProcess, options, inputFile =>
{
var result = new ProcessingResult
{
FileName = Path.GetFileName(inputFile),
StartTime = DateTime.UtcNow
};
try
{
// Stage: Pre-validation
if (!ValidateInput(inputFile))
{
result.Status = "PreValidationFailed";
result.Error = "Input file failed validation";
results.Add(result);
return;
}
string baseName = Path.GetFileNameWithoutExtension(inputFile);
string tempPath = Path.Combine(config.OutputFolder, $"{baseName}.pdf");
string archivePath = Path.Combine(config.ArchiveFolder, $"{baseName}.pdf");
// Stage: Process with retry
PdfDocument pdf = null;
int attempt = 0;
bool success = false;
while (attempt < config.MaxRetries && !success)
{
attempt++;
try
{
pdf = renderer.RenderHtmlFileAsPdf(inputFile);
success = true;
}
catch (Exception ex) when (IsTransient(ex) && attempt < config.MaxRetries)
{
Thread.Sleep((int)Math.Pow(2, attempt) * 500);
}
}
if (!success || pdf == null)
{
result.Status = "ProcessingFailed";
result.Error = "Max retries exceeded";
results.Add(result);
return;
}
using (pdf)
{
// Stage: Compress and convert to PDF/A-3b for archival
pdf.SaveAsPdfA(tempPath, PdfAVersions.PdfA3b);
}
// Stage: Post-validation
if (!ValidateOutput(tempPath))
{
File.Move(tempPath, Path.Combine(config.ErrorFolder, $"{baseName}.pdf"), overwrite: true);
result.Status = "PostValidationFailed";
result.Error = "Output file failed validation";
results.Add(result);
return;
}
// Stage: Archive
File.Move(tempPath, archivePath, overwrite: true);
// Update checkpoint
lock (checkpointLock)
{
checkpoint.CompletedFiles.Add(result.FileName);
SaveCheckpoint(config.CheckpointPath, checkpoint);
}
result.Status = "Success";
result.OutputSize = new FileInfo(archivePath).Length;
result.EndTime = DateTime.UtcNow;
results.Add(result);
Console.WriteLine($"[OK] {baseName}.pdf ({result.OutputSize / 1024}KB)");
}
catch (Exception ex)
{
result.Status = "Error";
result.Error = ex.Message;
result.EndTime = DateTime.UtcNow;
results.Add(result);
Console.WriteLine($"[ERROR] {result.FileName}: {ex.Message}");
}
});
stopwatch.Stop();
// Generate report
var report = new PipelineReport
{
TotalFiles = allFiles.Length,
ProcessedThisRun = results.Count,
Succeeded = results.Count(r => r.Status == "Success"),
PreValidationFailed = results.Count(r => r.Status == "PreValidationFailed"),
ProcessingFailed = results.Count(r => r.Status == "ProcessingFailed"),
PostValidationFailed = results.Count(r => r.Status == "PostValidationFailed"),
Errors = results.Count(r => r.Status == "Error"),
TotalDuration = stopwatch.Elapsed,
AverageFileTime = results.Any() ? TimeSpan.FromMilliseconds(stopwatch.Elapsed.TotalMilliseconds / results.Count) : TimeSpan.Zero
};
string reportJson = JsonSerializer.Serialize(report, new JsonSerializerOptions { WriteIndented = true });
File.WriteAllText(config.ReportPath, reportJson);
Console.WriteLine($"\n=== Pipeline Complete ===");
Console.WriteLine($"Succeeded: {report.Succeeded}");
Console.WriteLine($"Failed: {report.PreValidationFailed + report.ProcessingFailed + report.PostValidationFailed + report.Errors}");
Console.WriteLine($"Duration: {report.TotalDuration.TotalMinutes:F1} minutes");
Console.WriteLine($"Report: {config.ReportPath}");
// Helper methods
bool ValidateInput(string path)
{
try
{
var info = new FileInfo(path);
if (!info.Exists || info.Length == 0 || info.Length > 50 * 1024 * 1024) return false;
string content = File.ReadAllText(path);
return content.Contains("<html", StringComparison.OrdinalIgnoreCase) ||
content.Contains("<!DOCTYPE", StringComparison.OrdinalIgnoreCase);
}
catch { return false; }
}
bool ValidateOutput(string path)
{
try
{
using var pdf = PdfDocument.FromFile(path);
return pdf.PageCount > 0 && new FileInfo(path).Length > 1024;
}
catch { return false; }
}
bool IsTransient(Exception ex) =>
ex is IOException || ex is OutOfMemoryException ||
ex.Message.Contains("timeout", StringComparison.OrdinalIgnoreCase);
Checkpoint LoadCheckpoint(string path)
{
if (File.Exists(path))
{
string json = File.ReadAllText(path);
return JsonSerializer.Deserialize<Checkpoint>(json) ?? new Checkpoint();
}
return new Checkpoint();
}
void SaveCheckpoint(string path, Checkpoint cp) =>
File.WriteAllText(path, JsonSerializer.Serialize(cp));
ata classes
s PipelineConfig
public string InputFolder { get; set; } = "";
public string OutputFolder { get; set; } = "";
public string ArchiveFolder { get; set; } = "";
public string ErrorFolder { get; set; } = "";
public string CheckpointPath { get; set; } = "";
public string ReportPath { get; set; } = "";
public int MaxConcurrency { get; set; }
public int MaxRetries { get; set; }
public int JpegQuality { get; set; }
s Checkpoint
public HashSet<string> CompletedFiles { get; set; } = new();
s ProcessingResult
public string FileName { get; set; } = "";
public string Status { get; set; } = "";
public string Error { get; set; } = "";
public long OutputSize { get; set; }
public DateTime StartTime { get; set; }
public DateTime EndTime { get; set; }
s PipelineReport
public int TotalFiles { get; set; }
public int ProcessedThisRun { get; set; }
public int Succeeded { get; set; }
public int PreValidationFailed { get; set; }
public int ProcessingFailed { get; set; }
public int PostValidationFailed { get; set; }
public int Errors { get; set; }
public TimeSpan TotalDuration { get; set; }
public TimeSpan AverageFileTime { get; set; }Imports IronPdf
Imports System
Imports System.Collections.Generic
Imports System.IO
Imports System.Linq
Imports System.Threading.Tasks
Imports System.Threading
Imports System.Collections.Concurrent
Imports System.Diagnostics
Imports System.Text.Json
' Configuration
Dim config As New PipelineConfig With {
.InputFolder = "input/",
.OutputFolder = "output/",
.ArchiveFolder = "archive/",
.ErrorFolder = "errors/",
.CheckpointPath = "pipeline-checkpoint.json",
.ReportPath = "pipeline-report.json",
.MaxConcurrency = Math.Max(1, Environment.ProcessorCount \ 2),
.MaxRetries = 3,
.JpegQuality = 70
}
' Initialize folders
Directory.CreateDirectory(config.OutputFolder)
Directory.CreateDirectory(config.ArchiveFolder)
Directory.CreateDirectory(config.ErrorFolder)
' Load checkpoint for resume capability
Dim checkpoint As Checkpoint = LoadCheckpoint(config.CheckpointPath)
Dim results As New ConcurrentBag(Of ProcessingResult)()
Dim stopwatch As Stopwatch = Stopwatch.StartNew()
' Get files to process
Dim allFiles As String() = Directory.GetFiles(config.InputFolder, "*.html")
Dim filesToProcess As String() = allFiles.
Where(Function(f) Not checkpoint.CompletedFiles.Contains(Path.GetFileName(f))).
ToArray()
Console.WriteLine("Pipeline starting:")
Console.WriteLine($" Total files: {allFiles.Length}")
Console.WriteLine($" Already processed: {checkpoint.CompletedFiles.Count}")
Console.WriteLine($" To process: {filesToProcess.Length}")
Console.WriteLine($" Concurrency: {config.MaxConcurrency}")
Dim renderer As New ChromePdfRenderer()
Dim checkpointLock As New Object()
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = config.MaxConcurrency
}
Parallel.ForEach(filesToProcess, options, Sub(inputFile)
Dim result As New ProcessingResult With {
.FileName = Path.GetFileName(inputFile),
.StartTime = DateTime.UtcNow
}
Try
' Stage: Pre-validation
If Not ValidateInput(inputFile) Then
result.Status = "PreValidationFailed"
result.Error = "Input file failed validation"
results.Add(result)
Return
End If
Dim baseName As String = Path.GetFileNameWithoutExtension(inputFile)
Dim tempPath As String = Path.Combine(config.OutputFolder, $"{baseName}.pdf")
Dim archivePath As String = Path.Combine(config.ArchiveFolder, $"{baseName}.pdf")
' Stage: Process with retry
Dim pdf As PdfDocument = Nothing
Dim attempt As Integer = 0
Dim success As Boolean = False
While attempt < config.MaxRetries AndAlso Not success
attempt += 1
Try
pdf = renderer.RenderHtmlFileAsPdf(inputFile)
success = True
Catch ex As Exception When IsTransient(ex) AndAlso attempt < config.MaxRetries
Thread.Sleep(CInt(Math.Pow(2, attempt)) * 500)
End Try
End While
If Not success OrElse pdf Is Nothing Then
result.Status = "ProcessingFailed"
result.Error = "Max retries exceeded"
results.Add(result)
Return
End If
Using pdf
' Stage: Compress and convert to PDF/A-3b for archival
pdf.SaveAsPdfA(tempPath, PdfAVersions.PdfA3b)
End Using
' Stage: Post-validation
If Not ValidateOutput(tempPath) Then
File.Move(tempPath, Path.Combine(config.ErrorFolder, $"{baseName}.pdf"), overwrite:=True)
result.Status = "PostValidationFailed"
result.Error = "Output file failed validation"
results.Add(result)
Return
End If
' Stage: Archive
File.Move(tempPath, archivePath, overwrite:=True)
' Update checkpoint
SyncLock checkpointLock
checkpoint.CompletedFiles.Add(result.FileName)
SaveCheckpoint(config.CheckpointPath, checkpoint)
End SyncLock
result.Status = "Success"
result.OutputSize = New FileInfo(archivePath).Length
result.EndTime = DateTime.UtcNow
results.Add(result)
Console.WriteLine($"[OK] {baseName}.pdf ({result.OutputSize \ 1024}KB)")
Catch ex As Exception
result.Status = "Error"
result.Error = ex.Message
result.EndTime = DateTime.UtcNow
results.Add(result)
Console.WriteLine($"[ERROR] {result.FileName}: {ex.Message}")
End Try
End Sub)
stopwatch.Stop()
' Generate report
Dim report As New PipelineReport With {
.TotalFiles = allFiles.Length,
.ProcessedThisRun = results.Count,
.Succeeded = results.Count(Function(r) r.Status = "Success"),
.PreValidationFailed = results.Count(Function(r) r.Status = "PreValidationFailed"),
.ProcessingFailed = results.Count(Function(r) r.Status = "ProcessingFailed"),
.PostValidationFailed = results.Count(Function(r) r.Status = "PostValidationFailed"),
.Errors = results.Count(Function(r) r.Status = "Error"),
.TotalDuration = stopwatch.Elapsed,
.AverageFileTime = If(results.Any(), TimeSpan.FromMilliseconds(stopwatch.Elapsed.TotalMilliseconds / results.Count), TimeSpan.Zero)
}
Dim reportJson As String = JsonSerializer.Serialize(report, New JsonSerializerOptions With {.WriteIndented = True})
File.WriteAllText(config.ReportPath, reportJson)
Console.WriteLine(vbCrLf & "=== Pipeline Complete ===")
Console.WriteLine($"Succeeded: {report.Succeeded}")
Console.WriteLine($"Failed: {report.PreValidationFailed + report.ProcessingFailed + report.PostValidationFailed + report.Errors}")
Console.WriteLine($"Duration: {report.TotalDuration.TotalMinutes:F1} minutes")
Console.WriteLine($"Report: {config.ReportPath}")
' Helper methods
Function ValidateInput(path As String) As Boolean
Try
Dim info As New FileInfo(path)
If Not info.Exists OrElse info.Length = 0 OrElse info.Length > 50 * 1024 * 1024 Then Return False
Dim content As String = File.ReadAllText(path)
Return content.Contains("<html", StringComparison.OrdinalIgnoreCase) OrElse
content.Contains("<!DOCTYPE", StringComparison.OrdinalIgnoreCase)
Catch
Return False
End Try
End Function
Function ValidateOutput(path As String) As Boolean
Try
Using pdf = PdfDocument.FromFile(path)
Return pdf.PageCount > 0 AndAlso New FileInfo(path).Length > 1024
End Using
Catch
Return False
End Try
End Function
Function IsTransient(ex As Exception) As Boolean
Return TypeOf ex Is IOException OrElse TypeOf ex Is OutOfMemoryException OrElse
ex.Message.Contains("timeout", StringComparison.OrdinalIgnoreCase)
End Function
Function LoadCheckpoint(path As String) As Checkpoint
If File.Exists(path) Then
Dim json As String = File.ReadAllText(path)
Return JsonSerializer.Deserialize(Of Checkpoint)(json) OrElse New Checkpoint()
End If
Return New Checkpoint()
End Function
Sub SaveCheckpoint(path As String, cp As Checkpoint)
File.WriteAllText(path, JsonSerializer.Serialize(cp))
End Sub
' Data classes
Class PipelineConfig
Public Property InputFolder As String = ""
Public Property OutputFolder As String = ""
Public Property ArchiveFolder As String = ""
Public Property ErrorFolder As String = ""
Public Property CheckpointPath As String = ""
Public Property ReportPath As String = ""
Public Property MaxConcurrency As Integer
Public Property MaxRetries As Integer
Public Property JpegQuality As Integer
End Class
Class Checkpoint
Public Property CompletedFiles As HashSet(Of String) = New HashSet(Of String)()
End Class
Class ProcessingResult
Public Property FileName As String = ""
Public Property Status As String = ""
Public Property Error As String = ""
Public Property OutputSize As Long
Public Property StartTime As DateTime
Public Property EndTime As DateTime
End Class
Class PipelineReport
Public Property TotalFiles As Integer
Public Property ProcessedThisRun As Integer
Public Property Succeeded As Integer
Public Property PreValidationFailed As Integer
Public Property ProcessingFailed As Integer
Public Property PostValidationFailed As Integer
Public Property Errors As Integer
Public Property TotalDuration As TimeSpan
Public Property AverageFileTime As TimeSpan
End ClassSortie
Rapport de pipeline montrant les résultats du traitement par lots.
Ce pipeline intègre tous les modèles abordés dans ce tutoriel : traitement parallèle avec concurrence contrôlée, gestion des erreurs par fichier avec saut en cas d'échec, logique de relance pour les erreurs transitoires, point de contrôle pour la reprise après un accident, validation avant et après le traitement, gestion de la mémoire avec élimination explicite, et journalisation complète avec un rapport de synthèse final.
Le résultat de ce pipeline est un répertoire de fichiers d'archives compressés, conformes à la norme PDF/A-3b, un fichier de point de contrôle pour la capacité de reprise, un journal d'erreurs pour les fichiers qui n'ont pas pu être traités, et un rapport récapitulatif avec des statistiques de traitement. C'est le modèle que vous recherchez pour toute charge de travail sérieuse de traitement PDF par lots.
Prochaines étapes
Le traitement PDF par lots à grande échelle ne consiste pas simplement à appeler une méthode de rendu en boucle. Il nécessite une architecture réfléchie autour de la concurrence, de la gestion de la mémoire, de la gestion des erreurs et du déploiement, ainsi que la bonne bibliothèque pour faire fonctionner le tout. IronPDF fournit le moteur de rendu à sécurité thread, la surface API asynchrone, les outils de compression, et les capacités de conversion de format qui constituent la base de tout pipeline PDF .NET par lots.
Que vous construisiez un générateur de rapports nocturnes qui produit des milliers de PDF avant le lever du soleil, que vous fassiez migrer une archive de documents hérités vers conformité PDF/A, ou que vous mettiez en place un service de traitement cloud-natif sur Kubernetes, les modèles de ce tutoriel vous donnent un cadre éprouvé sur lequel vous appuyer. Le traitement parallèle avec une concurrence contrôlée permet de maintenir un débit élevé. La logique de saut en cas d'échec et de réessai permet au pipeline de continuer à fonctionner lorsque des fichiers individuels posent problème. Les points de contrôle vous permettent de ne jamais perdre le fil de votre travail. Les modèles de déploiement dans le nuage vous permettent d'adapter le calcul à votre charge de travail.
Prêt à commencer la construction ? Téléchargez IronPDF et essayez-le avec une version d'essai gratuite - la même bibliothèque gère tout, du rendu d'un seul fichier aux pipelines de traitement par lots de cent mille fichiers. Si vous avez des questions sur la mise à l'échelle, le déploiement ou l'architecture pour votre cas d'utilisation spécifique, prenez contact avec notre équipe d'assistance technique - nous avons aidé des équipes à construire des pipelines de traitement par lots à toutes les échelles et nous sommes heureux de vous aider à bien faire les choses.
Questions Fréquemment Posées
Qu'est-ce que le traitement PDF par lots en C# ?
Le traitement PDF par lots en C# fait référence au traitement automatisé de nombreux documents PDF simultanément, à l'aide du langage de programmation C#. Cette méthode est idéale pour automatiser les flux de documents à grande échelle.
Comment IronPDF peut-il aider au traitement des PDF par lots ?
IronPDF fournit des outils et des bibliothèques robustes qui rationalisent le traitement PDF par lots en C#. Il prend en charge le traitement parallèle, ce qui permet de traiter efficacement des milliers de PDF simultanément.
Quels sont les avantages de l'utilisation du traitement parallèle avec IronPDF ?
Le traitement parallèle avec IronPDF permet un traitement par lots plus rapide et plus efficace des PDF. Cette approche maximise l'utilisation des ressources et réduit considérablement le temps de traitement.
IronPDF peut-il être déployé sur des plateformes cloud pour le traitement par lots ?
Oui, IronPDF peut être déployé sur des plateformes cloud telles que Azure Functions, AWS Lambda et Kubernetes, ce qui permet un traitement PDF par lots évolutif et flexible.
Comment IronPDF gère-t-il les erreurs lors du traitement des PDF par lots ?
IronPDF comprend des fonctionnalités de gestion des erreurs et de logique de réessai qui garantissent la fiabilité lors du traitement des PDF par lots. Ces fonctions permettent de gérer et de rectifier les erreurs sans intervention manuelle.
Quel est le rôle de la logique de relance dans le traitement des PDF avec IronPDF ?
La logique de réessai dans IronPDF garantit que les problèmes temporaires ne perturbent pas le flux de travail du traitement par lots. En cas d'erreur, IronPDF peut automatiquement tenter de retraiter le document défaillant.
Pourquoi le langage C# est-il adapté au traitement PDF par lots ?
C# est un langage de programmation puissant, doté de bibliothèques et de cadres étendus qui le rendent idéal pour le traitement PDF par lots. Il s'intègre parfaitement à IronPDF pour une automatisation efficace des documents.
Comment IronPDF assure-t-il la sécurité des documents PDF pendant leur traitement ?
IronPDF prend en charge le traitement sécurisé des documents PDF en offrant des fonctionnalités de cryptage et de protection par mot de passe, garantissant que les documents traités restent confidentiels et sécurisés.
Quels sont les cas d'utilisation du traitement PDF par lots dans les entreprises ?
Les entreprises utilisent le traitement PDF par lots pour des tâches telles que la génération de factures en masse, la numérisation de documents et la distribution de rapports à grande échelle. IronPDF facilite ces cas d'utilisation en automatisant et en rationalisant les flux de travail des documents.
IronPDF peut-il gérer différents formats et versions de PDF ?
Oui, IronPDF est conçu pour gérer différents formats et versions de PDF, ce qui garantit la compatibilité et la flexibilité des tâches de traitement par lots.


Vous faites encore défiler ?
Vous voulez une preuve rapidement ? PM > Install-Package IronPdf
exécuter un échantillon Regardez votre code HTML se transformer en PDF.










