


C# PDF パーサー
C#でIronPDFのExtractAllTextメソッドを使用してPDFファイルを解析し、文書全体または特定のページからテキストを抽出します。 このアプローチは、わずか数行のコードで、.NETアプリケーションのためのシンプルで効率的なPDFテキスト抽出を提供します。
IronPDFはC#アプリケーションでPDFの解析を簡単にします。 このチュートリアルでは、PDF生成と操作のための包括的なC#ライブラリであるIronPDFを使用して、わずか数ステップでPDFを解析する方法を示します。
クイックスタート: IronPDFによる効率的な PDF 解析
最小限のコードでIronPDFを使ってC#でPDFを解析する。 この例では、元の書式を維持したままPDFファイルからすべてのテキストを抽出する方法を示します。 IronPDFのExtractAllTextメソッドは、.NETアプリケーションへのスムーズなPDF解析統合を可能にします。 以下の手順に従って、簡単にセットアップと実行を行ってください。
最小限のワークフロー(5ステップ)
- C#PDFパーサーライブラリをダウンロードする。
- Visual Studio にインストールする
ExtractAllTextメソッドを使用して、テキストのすべての行を抽出します。ExtractTextFromPageメソッドを使用して、1 つのページからすべてのテキストを抽出します。- 解析された PDF コンテンツを表示する
C#でPDFファイルを解析するには?
IronPDFを使えばPDFファイルの解析は簡単です。 以下のコードは、PDF文書全体からすべての行のテキストを抽出するためにExtractAllTextメソッドを使用します。 比較は、抽出されたPDFコンテンツとその出力を示しています。 このライブラリは、PDF文書の特定のセクションからテキストと画像を抽出することもサポートしています。
:path=/static-assets/pdf/content-code-examples/how-to/csharp-parse-pdf-parse-pdf.csusing IronPdf;
// Select the desired PDF File
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract all text from an pdf
string allText = pdf.ExtractAllText();
// Extract all text from page 1
string page1Text = pdf.ExtractTextFromPage(0);Imports IronPdf
' Select the desired PDF File
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract all text from an pdf
Private allText As String = pdf.ExtractAllText()
' Extract all text from page 1
Private page1Text As String = pdf.ExtractTextFromPage(0)IronPDFは様々なシナリオでPDFの解析を簡素化します。 HTMLからPDFへの変換、既存の文書からのコンテンツの抽出、高度なPDF機能の実装など、どのような作業であっても、ライブラリは包括的なサポートを提供します。
IronPDFはWindowsアプリケーションとのシームレスな統合を提供し、LinuxとmacOSプラットフォームでの展開をサポートします。 このライブラリは、クラウドベースのソリューションのAzureデプロイメントもサポートしています。
高度なテキスト抽出の例
IronPDFを使用してPDFコンテンツを解析するその他の方法はこちらです:
:path=/static-assets/pdf/content-code-examples/how-to/csharp-parse-pdf-3.csusing IronPdf;
// Parse PDF from URL
var pdfFromUrl = PdfDocument.FromUrl("https://example.com/document.pdf");
string urlPdfText = pdfFromUrl.ExtractAllText();
// Parse password-protected PDFs
var protectedPdf = PdfDocument.FromFile("protected.pdf", "password123");
string protectedText = protectedPdf.ExtractAllText();
// Extract text from specific page range
var largePdf = PdfDocument.FromFile("large-document.pdf");
for (int i = 5; i < 10; i++)
{
string pageText = largePdf.ExtractTextFromPage(i);
Console.WriteLine($"Page {i + 1}: {pageText.Substring(0, 100)}...");
}
Imports IronPdf
' Parse PDF from URL
Dim pdfFromUrl = PdfDocument.FromUrl("https://example.com/document.pdf")
Dim urlPdfText As String = pdfFromUrl.ExtractAllText()
' Parse password-protected PDFs
Dim protectedPdf = PdfDocument.FromFile("protected.pdf", "password123")
Dim protectedText As String = protectedPdf.ExtractAllText()
' Extract text from specific page range
Dim largePdf = PdfDocument.FromFile("large-document.pdf")
For i As Integer = 5 To 9
Dim pageText As String = largePdf.ExtractTextFromPage(i)
Console.WriteLine($"Page {i + 1}: {pageText.Substring(0, 100)}...")
Nextこれらの例は、異なるPDFソースやシナリオを扱う際のIronPDFの柔軟性を示しています。 複雑な構文解析が必要な場合は、PDF DOM オブジェクトアクセスで構造化されたコンテンツを扱ってください。
異なるPDFタイプを扱う
IronPDFは様々なPDFタイプの解析に優れています:
:path=/static-assets/pdf/content-code-examples/how-to/csharp-parse-pdf-4.csusing IronPdf;
using System.Text.RegularExpressions;
// Parse scanned PDFs with OCR (requires IronOcr)
var scannedPdf = PdfDocument.FromFile("scanned-document.pdf");
string ocrText = scannedPdf.ExtractAllText();
// Parse PDFs with forms
var formPdf = PdfDocument.FromFile("form.pdf");
string formText = formPdf.ExtractAllText();
// Extract and filter specific content
string invoiceText = pdf.ExtractAllText();
var invoiceNumber = Regex.Match(invoiceText, @"Invoice #: (\d+)").Groups[1].Value;
var totalAmount = Regex.Match(invoiceText, @"Total: \$([0-9,]+\.\d{2})").Groups[1].Value;
Imports IronPdf
Imports System.Text.RegularExpressions
' Parse scanned PDFs with OCR (requires IronOcr)
Dim scannedPdf = PdfDocument.FromFile("scanned-document.pdf")
Dim ocrText As String = scannedPdf.ExtractAllText()
' Parse PDFs with forms
Dim formPdf = PdfDocument.FromFile("form.pdf")
Dim formText As String = formPdf.ExtractAllText()
' Extract and filter specific content
Dim invoiceText As String = pdf.ExtractAllText()
Dim invoiceNumber = Regex.Match(invoiceText, "Invoice #: (\d+)").Groups(1).Value
Dim totalAmount = Regex.Match(invoiceText, "Total: \$([0-9,]+\.\d{2})").Groups(1).ValueパースされたPDFコンテンツを表示するにはどうすればよいですか?
C#フォームは、上記のコード実行から解析されたPDFコンテンツを表示します。 この出力は、文書処理のニーズに合わせてPDFから正確なテキストを提供します。
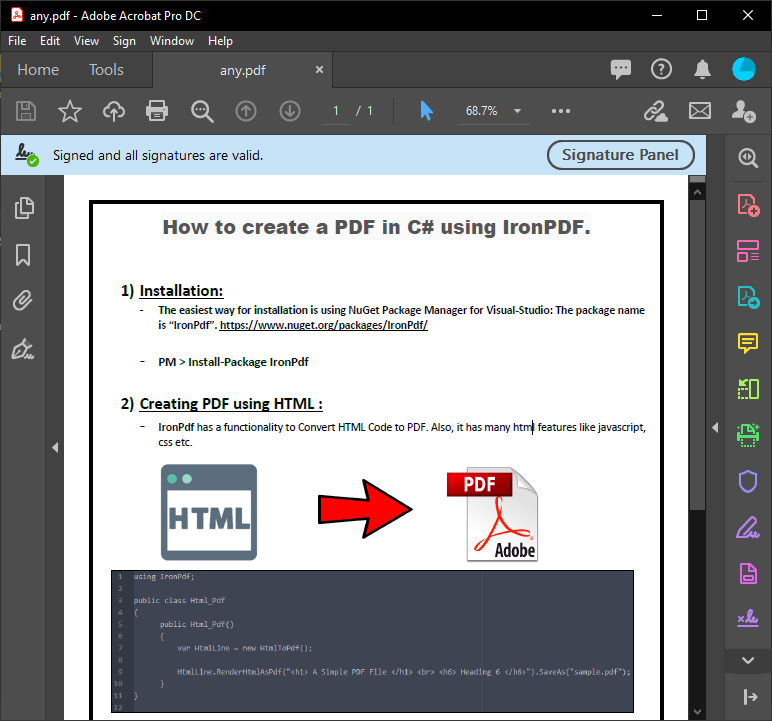
~ C# フォーム
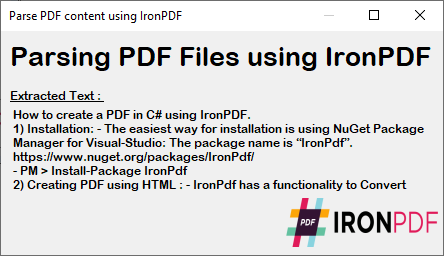
抽出されたテキストは、PDFの元の書式と構造を維持しているため、データ処理、コンテンツ分析、移行作業に最適です。 特定のコンテンツを検索して置き換えたり、他の形式にエクスポートしたりして、このテキストをさらに加工します。
PDF解析をアプリケーションに統合する
IronPDFの解析機能は様々なアプリケーションに統合されます:
// ASP.NET Core example
public IActionResult ParseUploadedPdf(IFormFile pdfFile)
{
using var stream = pdfFile.OpenReadStream();
var pdf = PdfDocument.FromStream(stream);
var extractedText = pdf.ExtractAllText();
// Process or store the extracted text
return Json(new {
success = true,
textLength = extractedText.Length,
preview = extractedText.Substring(0, Math.Min(500, extractedText.Length))
});
}
// Console application example
static void BatchParsePdfs(string folderPath)
{
var pdfFiles = Directory.GetFiles(folderPath, "*.pdf");
foreach (var file in pdfFiles)
{
var pdf = PdfDocument.FromFile(file);
var text = pdf.ExtractAllText();
// Save extracted text
var textFile = Path.ChangeExtension(file, ".txt");
File.WriteAllText(textFile, text);
Console.WriteLine($"Parsed: {Path.GetFileName(file)} - {text.Length} characters");
}
}// ASP.NET Core example
public IActionResult ParseUploadedPdf(IFormFile pdfFile)
{
using var stream = pdfFile.OpenReadStream();
var pdf = PdfDocument.FromStream(stream);
var extractedText = pdf.ExtractAllText();
// Process or store the extracted text
return Json(new {
success = true,
textLength = extractedText.Length,
preview = extractedText.Substring(0, Math.Min(500, extractedText.Length))
});
}
// Console application example
static void BatchParsePdfs(string folderPath)
{
var pdfFiles = Directory.GetFiles(folderPath, "*.pdf");
foreach (var file in pdfFiles)
{
var pdf = PdfDocument.FromFile(file);
var text = pdf.ExtractAllText();
// Save extracted text
var textFile = Path.ChangeExtension(file, ".txt");
File.WriteAllText(textFile, text);
Console.WriteLine($"Parsed: {Path.GetFileName(file)} - {text.Length} characters");
}
}Imports Microsoft.AspNetCore.Mvc
Imports System.IO
' ASP.NET Core example
Public Function ParseUploadedPdf(pdfFile As IFormFile) As IActionResult
Using stream = pdfFile.OpenReadStream()
Dim pdf = PdfDocument.FromStream(stream)
Dim extractedText = pdf.ExtractAllText()
' Process or store the extracted text
Return Json(New With {
.success = True,
.textLength = extractedText.Length,
.preview = extractedText.Substring(0, Math.Min(500, extractedText.Length))
})
End Using
End Function
' Console application example
Private Shared Sub BatchParsePdfs(folderPath As String)
Dim pdfFiles = Directory.GetFiles(folderPath, "*.pdf")
For Each file In pdfFiles
Dim pdf = PdfDocument.FromFile(file)
Dim text = pdf.ExtractAllText()
' Save extracted text
Dim textFile = Path.ChangeExtension(file, ".txt")
File.WriteAllText(textFile, text)
Console.WriteLine($"Parsed: {Path.GetFileName(file)} - {text.Length} characters")
Next
End Subこれらの例では、Webアプリケーションやバッチ処理シナリオへのPDF解析の組み込みを示しています。 高度な実装については、複数のPDFを処理する際のパフォーマンスを向上させるasyncとマルチスレッドテクニックを探求してください。
次に何ができるのかを見てみましょうか? こちらのチュートリアルページをご覧ください: PDFの編集
よくある質問
C# で PDF フ ァ イ ルか ら すべてのテ キ ス ト を抽出す る 方法は?
IronPDFのExtractAllTextメソッドを使ってPDFファイルからすべてのテキストを抽出することができます。IronPdf.FromFile("sample.pdf")でPDFを読み込み、ExtractAllText()を呼び出すだけで、元の書式を維持したまますべてのテキスト内容を取り出すことができます。
.NETでPDFを解析する最も簡単な方法は何ですか?
最もシンプルな方法はIronPDFを使い、たった1行のコードを書くことです: var text = IronPdf.FromFile("sample.pdf").ExtractAllText().var text = IronPdf.FromFile("sample.pdf").ExtractAllText(). このメソッドはPDF文書全体からすべての行のテキストを抽出します。
PDFの特定のページからテキストを抽出できますか?
はい、IronPDFは個々のページからテキストを抽出するExtractTextFromPageメソッドを提供しています。これにより、一度にすべてのコンテンツを抽出するのではなく、PDFドキュメントの特定のセクションをターゲットにすることができます。
パスワードで保護されたPDFをC#で解析するには?
IronPDFはパスワードで保護されたPDFの解析をサポートしています。PdfDocument.FromFile("protected.pdf", "password123")を使用して保護されたドキュメントを読み込み、ExtractAllText()を呼び出してテキスト内容を抽出します。
ローカルファイルではなくURLからPDFを解析できますか?
はい、IronPDFはPdfDocument.FromUrl("https://example.com/document.pdf")を使ってURLから直接PDFを解析することができます。URLからPDFをロードした後、ExtractAllText()を使用してテキストコンテンツを抽出します。
PDFパーサーはどのようなプラットフォームをサポートしていますか?
IronPDFはWindowsアプリケーション、Linux、macOS、Azureクラウドデプロイメントを含む複数のプラットフォームでPDF解析をサポートし、.NETアプリケーションに包括的なクロスプラットフォーム互換性を提供します。
PDFパーサーは、抽出時にテキストの書式を維持しますか?
はい、IronPDFのExtractAllTextメソッドは抽出時にPDFコンテンツの元の書式を維持し、解析されたテキストがソースドキュメントの構造とレイアウトを保持することを保証します。
PDFからテキストと画像の両方を抽出できますか?
IronPDFはPDFドキュメントからテキストと画像の両方を抽出することをサポートしています。テキスト抽出のためのExtractAllTextメソッドに加えて、ライブラリはPDF文書の特定のセクションから画像を抽出するための追加機能を提供します。


まだスクロールしていますか?
すぐに証拠が欲しいですか? PM > Install-Package IronPdf
サンプルを実行するHTML が PDF に変換されるのを確認します。










