

Dostępność PDF w C#: Tworzenie, konwersja i walidacja dokumentów PDF/UA
Legislacja dotycząca dostępności nie jest już kwestią przyszłości dla deweloperów .NET. Jest tutaj, terminy są realne, a kary są egzekwowalne. Zgodność PDF/UA C#, generowanie dostępnych PDF .NET, zgodność Sekcja 508 PDF C# oraz zgodność WCAG PDF C# stały się teraz rutynowymi wymaganiami dla każdej zespołu budującego przepływy dokumentów związane z rządem, opieką zdrowotną, edukacją, usługami prawnymi lub finansowymi. IronPDF zapewnia silnik PDF z etykietami, metody SaveAsPdfUA i RenderHtmlAsPdfUA, możliwości konwersji wsadowej oraz wsparcie dla środowiska .NET na różnych platformach, aby Twoje wyjściowe pliki PDF były zgodne ze standardamiPDF/UA-1i PDF/UA-2, niezależnie czy konwertujesz archiwa dziedziczone czy generujesz dostępne dokumenty z HTML w czasie rzeczywistym.
TL;DR: Przewodnik Quickstart
Ten tutorial obejmuje dostępność PDF/UA w C# z kontekstu regulacyjnego przez implementację, walidację i naprawę na dużą skalę.
- Do kogo to jest skierowane: Deweloperzy .NET, architekci i liderzy ds. zgodności odpowiedzialni za dostępność dokumentów w aplikacjach, które tworzą, konwertują lub dystrybuują pliki PDF. To obejmuje kontrahentów rządowych przygotowujących się do audytów Sekcji 508, zespoły SaaS budujące dostępne ścieżki raportowania i architektów przedsiębiorstw planujących projekty naprawcze dokumentów przeciwko terminom ADA Tytuł II.
- Co zbudujesz: KonwersjaPDF/UA-1iPDF/UA-2z istniejących plików PDF z
SaveAsPdfUA, generowanie dostępnych HTML do PDF zRenderHtmlAsPdfUA, konwersja w pamięci zConvertToPdfUA, wsadowe ścieżki naprawcze z przetwarzaniem równoległym i obsługą błędów oraz przepływy walidacji za pomocą veraPDF i Protokołu Matterhorn. - Gdzie działa: .NET 6+, .NET Framework 4.6.2+, .NETStandardowy2.0. Windows, Linux, macOS, Docker, Azure i AWS. Wszystkie renderingi używają osadzonego silnika Chromium IronPDF bez zewnętrznych zależności przeglądarki.
- Kiedy używać tego podejścia: Gdy pliki PDF muszą spełniać standardy dostępności narzucone przez Sekcję 508, ADA Tytuł II (terminy: kwiecień 2026/2027), UE Ustawa o dostępności (czerwiec 2025) lub polityki organizacyjne WCAG 2.1 Poziom AA.
- Dlaczego to ważne technicznie: Silnik renderowania Chromium w IronPDF zachowuje semantyczną strukturę HTML przez konwersję, tworząc etykietowane pliki PDF, gdzie nagłówki, listy, tabele i tekst alternatywny bezpośrednio mapują się na elementy struktury PDF. Połączone z jedną metodą
SaveAsPdfUAkonwersji dla istniejących plików, otrzymujesz zarówno ścieżkę generacji, jak i naprawy bez ręcznej manipulacji etykietami.
Konwersja istniejącego pliku PDF do formatu PDF/UA w dwóch liniach:
-
Install IronPDF with NuGet Package Manager
PM > Install-Package IronPdf -
Skopiuj i uruchom ten fragment kodu.
using IronPdf; PdfDocument pdf = PdfDocument.FromFile("quarterly-report.pdf"); // Convert and save asPDF/UA-1compliant pdf.SaveAsPdfUA("quarterly-report-accessible.pdf"); -
Wdrożenie do testowania w środowisku produkcyjnym
Rozpocznij używanie IronPDF w swoim projekcie już dziś z darmową wersją próbną

Po zakupie lub zapisaniu się na 30-dniowy okres próbny IronPDF, dodaj swój klucz licencyjny na początku aplikacji.
IronPdf.License.LicenseKey = "KEY";IronPdf.License.LicenseKey = "KEY";Imports IronPdf
IronPdf.License.LicenseKey = "KEY"Rozpocznij używanie IronPDF w swoim projekcie już dziś dzięki darmowej wersji próbnej.
Spis treści
- Zrozumienie Standardu
- Generowanie z HTML
- Wersjonowanie
- Walidacja
- Remediacja na dużą skalę
- Praktyczne zastosowania
Czym jest PDF/UA i dlaczego jest teraz obowiązkowy?
Dostępność plików PDF była kiedyś czymś, czym zespoły zajmowały się dopiero w końcu. Najlepsza praktyka, a nie sztywny wymóg. To się zmieniło. Wiele nakładających się na siebie przepisów z twardymi terminami sprawia, że jest to obecnie obowiązek prawny dla wielu kategorii organizacji, a konsekwencje nieprzestrzegania przepisów sięgają od ustaleń audytowych po postępowania sądowe.
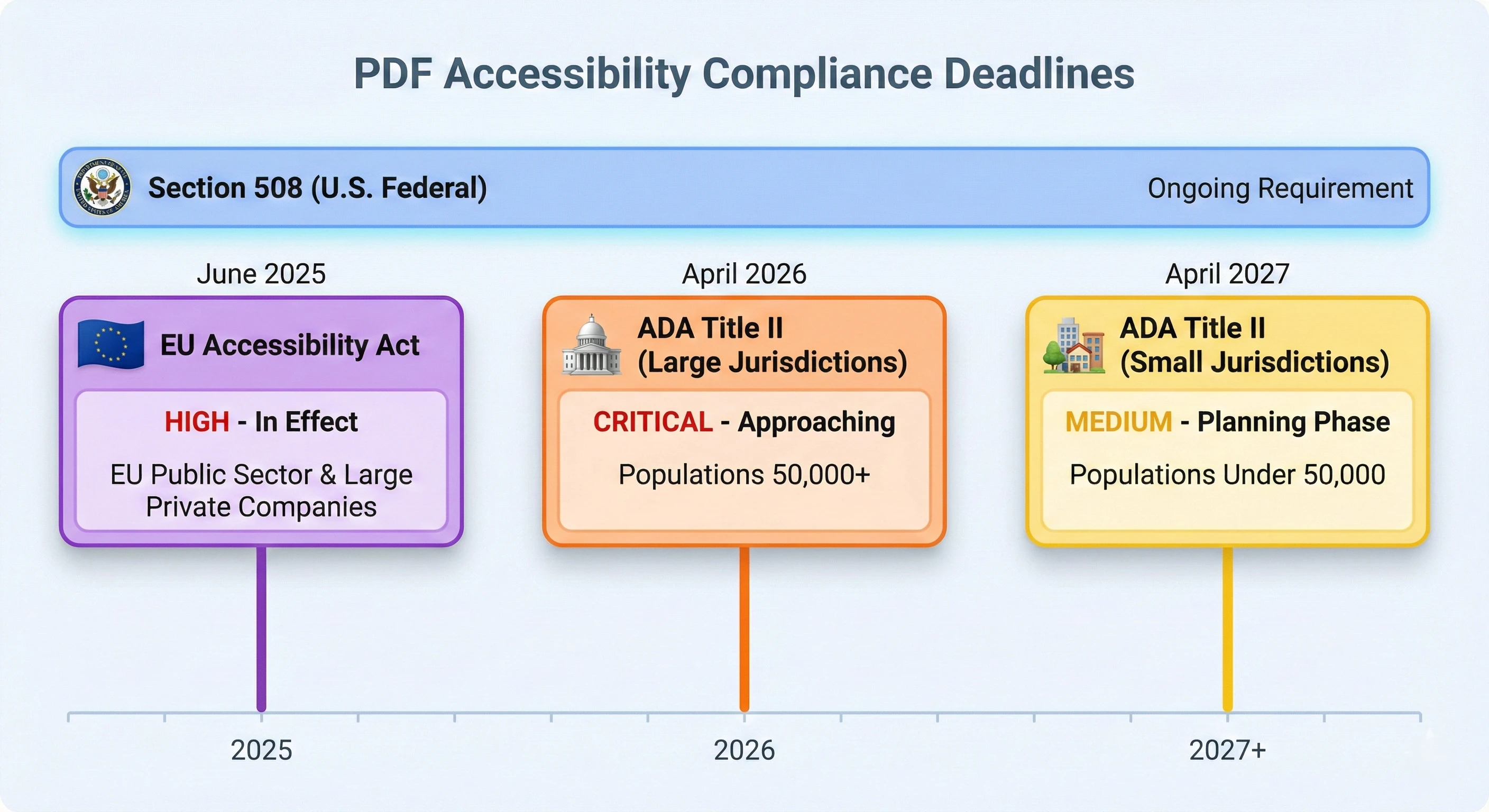
Punkt zwrotny w kwestiach prawnych
Trzy zmiany regulacyjne sprawiły, że zgodność z PDF/UA stała się pilna.
Nie są to ryzyka teoretyczne. Liczba pozwów dotyczących dostępności rośnie z roku na rok, a sądy konsekwentnie orzekają, że dokumenty cyfrowe wchodzą w zakres przepisów dotyczących dyskryminacji osób niepełnosprawnych. Organizacje, które traktują dostępność jako problem przyszłości, coraz częściej muszą odpowiadać na skargi, wyniki audytów i spory sądowe dotyczące dokumentów wygenerowanych przez ich oprogramowanie miesiące lub lata temu.
Sekcja 508 ustawy o rehabilitacji wymaga od Stanów Zjednoczonych agencje federalne i ich kontrahenci od lat tworzą dostępne technologie informatyczne. Dokumenty PDF są wyraźnie uwzględnione. Jeśli oprogramowanie generuje dokumenty wykorzystywane przez agencję federalną lub w jej imieniu, dokumenty te muszą być dostępne. Departament Sprawiedliwości bada skargi i podejmuje działania egzekucyjne wobec organizacji, które nie przestrzegają przepisów.
Tytuł II ustawy ADA rozszerza obowiązki w zakresie dostępności na władze stanowe i lokalne. Ostateczna regulacja Departamentu Sprawiedliwości (DOJ), opublikowana w 2024 r., wyznaczyła terminy dostosowania się do przepisów na kwiecień 2026 r. dla podmiotów zatrudniających 50 000 lub więcej osób oraz na kwiecień 2027 r. dla mniejszych podmiotów. Zakres jest szeroki: każdy plik PDF opublikowany na stronie rządowej, rozesłany e-mailem lub wygenerowany przez aplikację dla obywateli musi spełniać wymagania WCAG 2.1 poziom AA. Są to porządki obrad, dokumenty budżetowe, wnioski o pozwolenia, akta sądowe, mapy zagospodarowania przestrzennego i protokoły posiedzeń rady, a także wiele innych rodzajów dokumentów.
Europejska ustawa o dostępności (EAA) weszła w życie w czerwcu 2025 r. i wymaga, aby produkty i usługi sprzedawane w UE spełniały wymogi dotyczące dostępności. W przypadku firm programistycznych obsługujących klientów z UE dokumenty generowane przez aplikacje muszą być dostępne. Nie ogranicza się to do sektora rządowego; Dotyczy to produktów i usług sektora prywatnego z szerokiego zakresu kategorii.
Czego faktycznie wymaga PDF/UA
PDF/UA (ISO 14289) określa wymagania techniczne, które plik PDF musi spełniać, aby technologie wspomagające mogły go niezawodnie przetwarzać. Dokument zgodny z wytycznymi musi zawierać:
Kompletna struktura etykiet. Każdy element znaczącej treści musi być reprezentowany w logicznym drzewie struktury za pomocą standardowych etykiet PDF: <h1> przez <h6> dla nagłówków, <p> dla akapitów, <Table> dla tabel danych, <Figure> dla obrazów i <l> dla list. Treści o charakterze czysto dekoracyjnym muszą być oznaczone jako artefakty, aby czytniki ekranu je pomijały.
Prawidłowa kolejność czytania. Drzewo tagów musi odzwierciedlać logiczną kolejność, w jakiej należy czytać treść, a nie wizualną kolejność, w jakiej pojawia się ona na stronie. W przypadku układów wielokolumnowych lub dokumentów z paskami bocznymi to rozróżnienie ma duże znaczenie.
Tekst alternatywny dla treści nie-tekstowej. Każdy obraz, wykres i diagram przekazujący informacje musi mieć załączony tekst alternatywny do swojego tagu <Figure>. Obrazy dekoracyjne należy oznaczyć jako artefakty.
Prawidłowe metadane. Dokument musi zawierać deklarację języka naturalnego (np. "en" dla języka angielskiego), mieć sensowny tytuł oraz zawierać identyfikator PDF/UA w metadanych XMP.
Czcionki osadzone z mapowaniami Unicode. Wszystkie czcionki muszą być osadzone, a mapowania znaków Unicode (ToUnicode CMap) muszą być obecne, aby tekst mógł być pobierany i odczytywany na głos w sposób dokładny.
PDF/UA a WCAG: jak te dwa standardy współdziałają
Programiści często pytają, czy powinni kierować swoje działania na zgodność z PDF/UA czy WCAG. Odpowiedź brzmi: oba, ponieważ działają one na różnych warstwach.
WCAG (Web Content Accessibility Guidelines) określa zasady dostępności i kryteria sukcesu dla treści internetowych. Jest to standard, do którego odwołują się sekcja 508, tytuł II ustawy ADA oraz EAA. WCAG określa, jakie cechy powinny posiadać treści dostępne: powinny być dostrzegalne, obsługiwane, zrozumiałe i solidne.
PDF/UA wyjaśnia, jak osiągnąć te cele w pliku PDF. Jest to standard technicznej implementacji. Plik PDF zgodny ze standardem PDF/UA spełni kryteria sukcesu WCAG dotyczące treści dokumentów. Te dwa standardy się uzupełniają, a nie konkurują ze sobą. W praktyce, jeśli proces tworzenia dokumentów generuje pliki PDF z tagami, o dobrej strukturze, które przechodzą walidację PDF/UA, istnieje również duże prawdopodobieństwo zgodności z WCAG.
Wymóg retroaktywny
Jedna rzecz, która zaskakuje organizacje: przepisy te nie dotyczą wyłącznie nowych dokumentów. Konieczne może być również poprawienie istniejących plików PDF opublikowanych na stronach internetowych lub rozpowszechnianych za pośrednictwem aplikacji. Tytuł II ustawy ADA wymaga, aby treści internetowe (w tym pliki PDF) publikowane przez władze stanowe i lokalne spełniały wymagania WCAG 2.1 poziomu AA. Nie ma ogólnego wyłączenia dla dokumentów starszego typu.
To sprawia, że narzędzia do konwersji programowej są niezbędne. Ręczne poprawianie tysięcy plików PDF nie jest praktyczne. W dalszej części tego samouczka omówimy wzorce naprawy zbiorczej.
Jakie są różnice między wersjami PDF/UA?
PDF/UA-1 (ISO 14289-1, oparty na PDF 1.7)
PDF/UA-1 został opublikowany w 2012 roku i pozostaje najczęściej stosowaną wersją standardu. Opiera się na specyfikacji PDF 1.7 i definiuje kompleksowy zestaw wymagań dotyczących struktury tagowanego pliku PDF, metadanych, czcionek oraz zgodności z technologiami wspomagającymi. Większość narzędzi do walidacji, w tym veraPDF i narzędzie do sprawdzania dostępności w programie Adobe Acrobat, obsługuje standardPDF/UA-1jako główny cel.
Jeśli rozpoczynasz nowy projekt dotyczący dostępności i potrzebujesz szerokiej kompatybilności z istniejącymi narzędziami i procesami,PDF/UA-1jest bezpiecznym wyborem domyślnym. Spełnia wymagania sekcji 508, tytułu II ustawy ADA oraz unijnej ustawy o dostępności.
PDF/UA-2(ISO 14289-2:2024, oparty na PDF 2.0)
PDF/UA-2 został opublikowany w 2024 roku i stanowi znaczącą aktualizację. Oparty na specyfikacji PDF 2.0 (ISO 32000-2:2020), wprowadza ulepszoną obsługę nowoczesnych funkcji PDF, w tym adnotacji, pól formularzy, treści multimedialnych i złożonych struktur dokumentów.PDF/UA-2zapewnia również lepszą zgodność z ewoluującymi standardami dostępności stron internetowych.
IronPDF obsługuje obie wersje. Podczas eksportu można określić, który z nich ma być docelowy, co pokażemy w przykładach kodu poniżej.
WTPDF (Well-Tagged PDF) i jego znaczenie
Możesz natknąć się na odniesienia do WTPDF, co oznacza Well-Tagged PDF. Opublikowany przez PDF Association, WTPDF to zbiór wytycznych technicznych wyjaśniających, jak tworzyć poprawnie otagowane pliki PDF. Nie jest to odrębny standard, a raczej praktyczny dodatek doPDF/UA-2i PDF 2.0. WTPDF zawiera szczegółowe zasady dotyczące użycia tagów, mapowania elementów struktury oraz oznaczania treści, wykraczające poza to, co definiuje sama specyfikacja PDF/UA. Potraktuj to jako przewodnik wdrożeniowy, który stanowi uzupełnienie formalnego standardu.
Którą wersję należy wybrać?
| PDF/UA-1 | PDF/UA-2 | |
|---|---|---|
| Opublikowano | 2012 | 2024 |
| Specyfikacja podstawowa | PDF 1.7 (ISO 32000-1) | PDF 2.0 (ISO 32000-2) |
| Zakres regulacyjny | Sekcja 508, tytuł II ustawy ADA, unijna ustawa o dostępności | Zgodność z przyszłymi wersjami przy zachowaniu tych samych zasad |
| Narzędzia do walidacji | veraPDF, Adobe Acrobat Pro, PAC 2024 | veraPDF (rosnące wsparcie) |
| Semantyka pól formularza | Standardowy | Ulepszone (bogatsze metadane dotyczące dostępności) |
| Najlepsze dla | Większość dzisiejszych projektów | Nowe systemy wymagające funkcji PDF 2.0 |
W przypadku większości dzisiejszych projektów właściwym wyborem jest PDF/UA-1. Charakteryzuje się on najszerszą obsługą narzędzi, najbardziej dojrzałym ekosystemem walidacji oraz spełnia wszystkie aktualne wymogi regulacyjne. Wybierz PDF/UA-2, jeśli potrzebujesz konkretnie funkcji PDF 2.0, takich jak ulepszona semantyka pól formularzy, ulepszona obsługa adnotacji lub kompatybilność z nowymi standardami.
IronPDF domyślnie obsługuje standard PDF/UA-1 i umożliwia łatwe przejście na PDF/UA-2, gdy tylko będziesz gotowy.
Jak tworzyć pliki PDF z HTML, które są dostępne dla osób niepełnosprawnych?
Jeśli aplikacja generuje pliki PDF na podstawie treści HTML (raporty, faktury, wyciągi, korespondencja), istnieje możliwość wbudowania funkcji dostępności od samego początku, zamiast wprowadzać poprawki po fakcie. Metoda RenderHtmlAsPdfUA IronPDF renderuje HTML bezpośrednio do wyjścia zgodnego z PDF/UA, a jakość wyniku zależy w dużej mierze od jakości wejściowego HTML.
Pisanie kodu HTML dostosowanego do potrzeb osób niepełnosprawnych
Dostępny kod HTML przekłada się naturalnie na dostępną strukturę pliku PDF z tagami. Oto najważniejsze zasady:
Używaj semantycznych elementów HTML. Strukturyzuj swoją treść z <h1> do <h6> dla nagłówków, <p> dla akapitów, <ul> i <ol> dla list, <table> z <thead>, <tbody> i <th> dla tabel danych oraz <nav>, <main>, <article> i <section> dla struktury strony.
Dostarczaj tekst alternatywny dla każdego znaczącego obrazu. Użyj atrybutu alt na wszystkich tagach <img>. Dla obrazów dekoracyjnych użyj pustego alt="" aby zasygnalizować, że obraz powinien być traktowany jako artefakt.
Zachowaj logiczną hierarchię nagłówków. Zacznij od pojedynczego <h1> i nie pomijaj poziomów. Dokument przechodzący od <h1> do <h3> spowoduje uszkodzone drzewo nagłówków w wyjściu PDF.
Etykietuj pola formularza. Jeśli HTML zawiera elementy formularza, należy połączyć każde wejście z elementem <label> używając atrybutu for.
Ustaw język dokumentu. Dołącz atrybut lang w swoim elemencie <html> (np. <html lang="en">).
Renderowanie HTML do PDF/UA z RenderHtmlAsPdfUA
Oto kompletny przykład renderowania dostępnego dokumentu HTML bezpośrednio do formatu PDF/UA:
Renderuje ciąg HTML zawierający nagłówki semantyczne, tabelę danych, listę uporządkowaną oraz obraz z tekstem alternatywnym bezpośrednio do dokumentu zgodnego ze standardem PDF/UA.
:path=/static-assets/pdf/content-code-examples/tutorials/pdf-accessibility-csharp-pdfua-tutorial/pdfua-render-html.csusing IronPdf;
ChromePdfRenderer renderer = new ChromePdfRenderer();
string accessibleHtml = @"
<!DOCTYPE html>
<html lang='en'>
<head>
<meta charset='UTF-8'>
<title>Quarterly Accessibility Report</title>
<style>
body {
font-family: Arial, sans-serif;
line-height: 1.6;
color: #333;
max-width: 800px;
margin: 0 auto;
padding: 20px;
}
h1 {
color: #1a1a1a;
border-bottom: 2px solid #0066cc;
padding-bottom: 8px;
}
h2 {
color: #2a2a2a;
margin-top: 24px;
}
table {
border-collapse: collapse;
width: 100%;
margin: 16px 0;
}
th, td {
border: 1px solid #ccc;
padding: 10px;
text-align: left;
}
th {
background-color: #f0f0f0;
font-weight: bold;
}
.summary {
background-color: #f9f9f9;
padding: 16px;
border-left: 4px solid #0066cc;
margin: 16px 0;
}
</style>
</head>
<body>
<h1>Q3 2025 Accessibility Compliance Report</h1>
<div class='summary'>
<p>This report summarizes the accessibility remediation progress
for all public-facing PDF documents across the organization.</p>
</div>
<h2>Document Inventory</h2>
<p>The following table shows the current status of document
remediation by department.</p>
<table>
<thead>
<tr>
<th scope='col'>Department</th>
<th scope='col'>Total Documents</th>
<th scope='col'>Compliant</th>
<th scope='col'>Pending</th>
</tr>
</thead>
<tbody>
<tr>
<td>Legal</td>
<td>1,247</td>
<td>892</td>
<td>355</td>
</tr>
<tr>
<td>Finance</td>
<td>3,891</td>
<td>3,102</td>
<td>789</td>
</tr>
<tr>
<td>Human Resources</td>
<td>567</td>
<td>401</td>
<td>166</td>
</tr>
</tbody>
</table>
<h2>Key Findings</h2>
<p>Three areas require immediate attention before the
April 2026 deadline:</p>
<ol>
<li>Legacy court filing templates lack heading
structure entirely.</li>
<li>Financial statement PDFs generated before 2023
have no tagged content.</li>
<li>HR onboarding packets contain scanned images
without OCR text layers.</li>
</ol>
<h2>Remediation Timeline</h2>
<p>The project team recommends prioritizing public-facing
documents first, followed by internal documents accessed by
more than 50 employees.</p>
<img src='timeline-chart.png'
alt='Gantt chart showing remediation phases: Phase 1
covers public documents from October through December
2025, Phase 2 covers internal documents from January
through March 2026.' />
</body>
</html>";
// Render directly to PDF/UA-compliant output
PdfDocument pdf = renderer.RenderHtmlAsPdfUA(accessibleHtml);
// Set document metadata (required by PDF/UA)
pdf.MetaData.Title = "Q3 2025 Accessibility Compliance Report";
pdf.MetaData.Author = "Compliance Department";
pdf.SaveAs("accessibility-report-pdfua.pdf");
Imports IronPdf
Dim renderer As New ChromePdfRenderer()
Dim accessibleHtml As String = "
<!DOCTYPE html>
<html lang='en'>
<head>
<meta charset='UTF-8'>
<title>Quarterly Accessibility Report</title>
<style>
body {
font-family: Arial, sans-serif;
line-height: 1.6;
color: #333;
max-width: 800px;
margin: 0 auto;
padding: 20px;
}
h1 {
color: #1a1a1a;
border-bottom: 2px solid #0066cc;
padding-bottom: 8px;
}
h2 {
color: #2a2a2a;
margin-top: 24px;
}
table {
border-collapse: collapse;
width: 100%;
margin: 16px 0;
}
th, td {
border: 1px solid #ccc;
padding: 10px;
text-align: left;
}
th {
background-color: #f0f0f0;
font-weight: bold;
}
.summary {
background-color: #f9f9f9;
padding: 16px;
border-left: 4px solid #0066cc;
margin: 16px 0;
}
</style>
</head>
<body>
<h1>Q3 2025 Accessibility Compliance Report</h1>
<div class='summary'>
<p>This report summarizes the accessibility remediation progress
for all public-facing PDF documents across the organization.</p>
</div>
<h2>Document Inventory</h2>
<p>The following table shows the current status of document
remediation by department.</p>
<table>
<thead>
<tr>
<th scope='col'>Department</th>
<th scope='col'>Total Documents</th>
<th scope='col'>Compliant</th>
<th scope='col'>Pending</th>
</tr>
</thead>
<tbody>
<tr>
<td>Legal</td>
<td>1,247</td>
<td>892</td>
<td>355</td>
</tr>
<tr>
<td>Finance</td>
<td>3,891</td>
<td>3,102</td>
<td>789</td>
</tr>
<tr>
<td>Human Resources</td>
<td>567</td>
<td>401</td>
<td>166</td>
</tr>
</tbody>
</table>
<h2>Key Findings</h2>
<p>Three areas require immediate attention before the
April 2026 deadline:</p>
<ol>
<li>Legacy court filing templates lack heading
structure entirely.</li>
<li>Financial statement PDFs generated before 2023
have no tagged content.</li>
<li>HR onboarding packets contain scanned images
without OCR text layers.</li>
</ol>
<h2>Remediation Timeline</h2>
<p>The project team recommends prioritizing public-facing
documents first, followed by internal documents accessed by
more than 50 employees.</p>
<img src='timeline-chart.png'
alt='Gantt chart showing remediation phases: Phase 1
covers public documents from October through December
2025, Phase 2 covers internal documents from January
through March 2026.' />
</body>
</html>"
' Render directly to PDF/UA-compliant output
Dim pdf As PdfDocument = renderer.RenderHtmlAsPdfUA(accessibleHtml)
' Set document metadata (required by PDF/UA)
pdf.MetaData.Title = "Q3 2025 Accessibility Compliance Report"
pdf.MetaData.Author = "Compliance Department"
pdf.SaveAs("accessibility-report-pdfua.pdf")Wynik
Jak widać, semantyczne elementy HTML (nagłówki, tabela danych z nagłówkami kolumn, lista uporządkowana i obraz z tekstem alternatywnym) są zachowane jako odpowiednie tagi struktury PDF/UA w wygenerowanym pliku wyjściowym.
Zachowanie struktury poprzez konwersję
IronPDF wykorzystuje wbudowany silnik renderujący Chromium, tę samą technologię, która zasila przeglądarki Google Chrome i Microsoft Edge. Ma to znaczenie dla dostępności, ponieważ Chromium już rozumie semantykę HTML. Kiedy IronPDF renderuje kod HTML do formatu PDF/UA, mapuje elementy HTML na ich odpowiedniki w tagach PDF:
<h1> przez <h6> stają się <h1> przez <h6> tagami nagłówkowymi. <p> staje się <p> tagami akapitowymi. <table>, <tr>, <th> i <td> stają się <Table>, <tr>, <th> i <td> elementami strukturalnymi. <ul> i <ol> stają się <l> (Lista) z dziećmi <li> (Element listy). <img> z tekstem alternatywnym staje się <Figure> z wpisem /Alt.
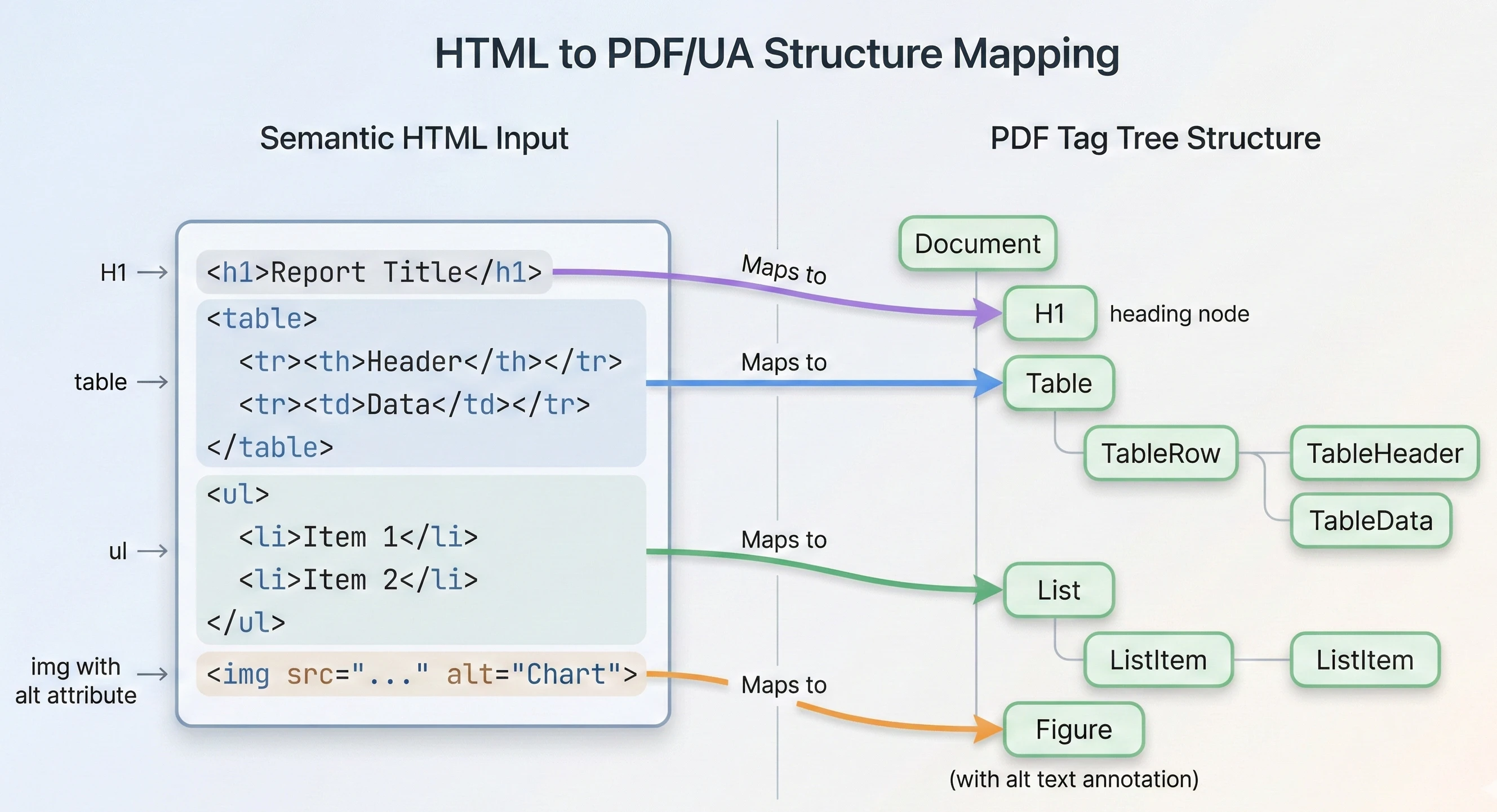
Mapowanie to odbywa się automatycznie. Nie ma potrzeby ręcznego tworzenia drzewa tagów PDF ani pisania kodu elementów struktury.
Typowe wzorce HTML, które ograniczają dostępność
Nawet programiści, którzy zazwyczaj piszą czysty kod HTML, czasami używają wzorców, które generują niedostępne pliki PDF. Zwróć uwagę na następujące kwestie:
Używanie <div> do wszystkiego. Dokument zbudowany w całości z nieformatowanych elementów <div> tworzy płaskie, niestrukturalne drzewo tagów. Czytniki ekranu nie mogą poruszać się po nim w sposób sensowny. Zamiast tego użyj elementów semantycznych.
Symulowanie tabel za pomocą siatek CSS lub flexbox. Dane prezentowane w wizualnym układzie siatki za pomocą CSS, ale nie faktycznych elementów <table>, nie spowodują utworzenia odpowiednich tagów tabeli w PDF. Jeśli treść to dane tabelaryczne, użyj prawdziwego <table>.
Pomijanie poziomów nagłówków. Przeskok od <h1> do <h3> tworzy lukę w hierarchii nagłówków, którą narzędzia do sprawdzania dostępności oznaczą jako błąd.
Obrazy bez tekstu alternatywnego. Każdy tag <img> bez atrybutu alt utworzy tag <Figure> bez tekstu alternatywnego, co jest bezpośrednim naruszeniem PDF/UA.
Tekst osadzony w obrazach. Jeśli kod HTML zawiera tekst renderowany jako obraz (zrzuty ekranu tabel, wykresy rastrowe), treść ta jest niewidoczna dla czytników ekranu. W miarę możliwości należy używać prawdziwego tekstu HTML i podać wyczerpujący tekst alternatywny dla pozostałych obrazów.
Jak wybrać międzyPDF/UA-1a PDF/UA-2?
Wynik domyślny (PDF/UA-1)
Domyślnie IronPDF generuje pliki w formacie PDF/UA-1. O ile nie ma konkretnego powodu, aby wybierać PDF/UA-2, należy pozostać przy ustawieniu domyślnym.
:path=/static-assets/pdf/content-code-examples/tutorials/pdf-accessibility-csharp-pdfua-tutorial/pdfua-default-output.csusing IronPdf;
PdfDocument pdf = PdfDocument.FromFile("standard-report.pdf");
// Default: saves as PDF/UA-1
pdf.SaveAsPdfUA("accessible-report.pdf");
Imports IronPdf
Dim pdf As PdfDocument = PdfDocument.FromFile("standard-report.pdf")
' Default: saves as PDF/UA-1
pdf.SaveAsPdfUA("accessible-report.pdf")Wynik
Ten sam raport jest teraz zgodny ze standardem PDF/UA-1, posiada kompletną strukturę tagów oraz identyfikator ISO 14289-1 osadzony w metadanych XMP.
Eksportowanie jakoPDF/UA-2z parametrem wersji
Jeśli potrzebujesz formatu PDF/UA-2, określ parametr wersji:
:path=/static-assets/pdf/content-code-examples/tutorials/pdf-accessibility-csharp-pdfua-tutorial/pdfua-export-pdfua2.csusing IronPdf;
PdfDocument pdf = PdfDocument.FromFile("modern-form.pdf");
// Export as PDF/UA-2 (based on PDF 2.0)
pdf.SaveAsPdfUA("accessible-form-ua2.pdf", PdfUAVersions.PdfUA2);
Imports IronPdf
Dim pdf As PdfDocument = PdfDocument.FromFile("modern-form.pdf")
' Export as PDF/UA-2 (based on PDF 2.0)
pdf.SaveAsPdfUA("accessible-form-ua2.pdf", PdfUAVersions.PdfUA2)Wynik
Formularz wyeksportowany jako PDF/UA-2, wykorzystujący wewnętrzną strukturę PDF 2.0 z bogatszymi metadanymi dostępności dla pól formularza.
Można również konwertować w pamięci i zapisywać osobno:
:path=/static-assets/pdf/content-code-examples/tutorials/pdf-accessibility-csharp-pdfua-tutorial/pdfua-in-memory-pdfua2.csusing IronPdf;
PdfDocument pdf = PdfDocument.FromFile("complex-document.pdf");
// Convert to PDF/UA-2 in memory
pdf.ConvertToPdfUA(PdfUAVersions.PdfUA2);
// Perform additional modifications
pdf.MetaData.Title = "Complex Document - Accessible Version";
// Save the converted document
pdf.SaveAs("complex-document-accessible.pdf");
Imports IronPdf
Dim pdf As PdfDocument = PdfDocument.FromFile("complex-document.pdf")
' Convert to PDF/UA-2 in memory
pdf.ConvertToPdfUA(PdfUAVersions.PdfUA2)
' Perform additional modifications
pdf.MetaData.Title = "Complex Document - Accessible Version"
' Save the converted document
pdf.SaveAs("complex-document-accessible.pdf")Wynik
Dokument przekonwertowany w pamięci i zapisany jako PDF/UA-2. Uwaga: PDF/UA-2 wykorzystuje wewnętrznie format PDF 2.0. Przed zmianą należy upewnić się, że narzędzia końcowe obsługują format PDF 2.0.
Kiedy stosować PDF/UA-2
Warto rozważyć użycie standardu PDF/UA-2, jeśli dokumenty wykorzystują funkcje PDF 2.0, których standard PDF/UA-1 nie jest w stanie w pełni obsłużyć. Obejmuje to zwiększoną dostępność pól formularzy dzięki bogatszym informacjom semantycznym, ulepszoną obsługę adnotacji w zakresie komentarzy, znaczników i procesów recenzowania, lepszą obsługę treści multimedialnych osadzonych w plikach PDF oraz kompatybilność z nowymi standardami dostępności opartymi na PDF 2.0.
W przypadku większości dzisiejszych projektów związanych z zapewnieniem zgodności standardPDF/UA-1w zupełności wystarcza.PDF/UA-2to przyszłościowy wybór dla nowych systemów, które nie będą musiały przetwarzać wyników w starszych narzędziach.
Jak sprawdzić zgodność z PDF/UA?
Stworzenie dokumentu PDF/UA to tylko połowa zadania. Należy sprawdzić, czy wynik rzeczywiście spełnia standard. Walidacja pozwala wykryć problemy, które łatwo przeoczyć podczas tworzenia oprogramowania, i dostarcza udokumentowanych dowodów potrzebnych do audytów zgodności.
Weryfikacja za pomocą veraPDF
veraPDF to bezpłatne narzędzie typu open source z interfejsem wiersza poleceń i GUI, służące do sprawdzania plików PDF pod kątem zgodności ze standardami PDF/UA i PDF/A. Przekaż skonwertowany plik i profil ua1, aby go sprawdzić:
Wejscie
Dokument PDF/UA wygenerowany przez IronPDF, gotowy do walidacji. To jest wyjście z SaveAsPdfUA.
verapdf --profile ua1 output-quarterly-report-accessible.pdfverapdf --profile ua1 output-quarterly-report-accessible.pdfWynik
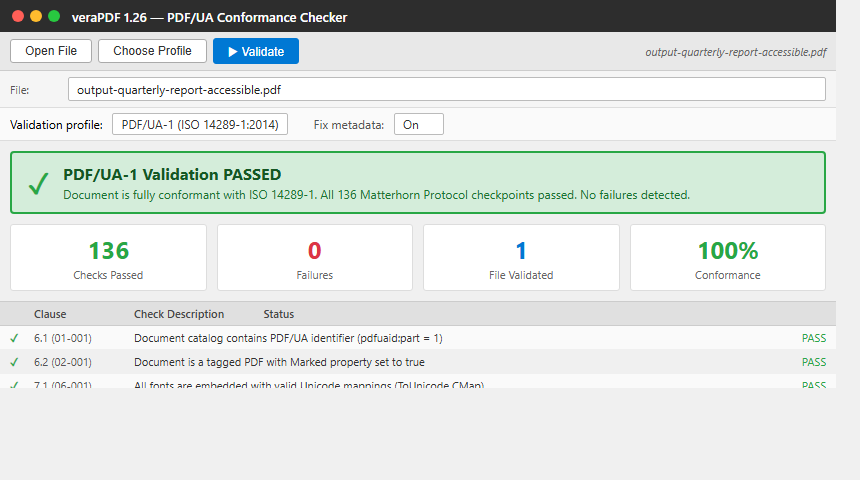
136 pomyślnie przejrzanych testów, 0 błędów. Wynik generowany przez IronPDF jest w pełni zgodny z normą ISO 14289-1. Raport HTML zawiera listę wszystkich punktów kontrolnych protokołu Matterhorn wraz z wynikami. Zintegruj CLI z potokiem CI/CD, aby wykrywać regresje, zanim trafią do środowiska produkcyjnego.
Zrozumienie protokołu Matterhorn
Protokół Matterhorn to zestaw warunków testowych opublikowany przez PDF Association, który dokładnie określa, jak sprawdzić zgodność pliku PDF z normą PDF/UA-1. Organizuje kontrole w 31 punktach kontrolnych obejmujących 136 konkretnych warunków awarii. Każdy warunek niepowodzenia odpowiada klauzuli w specyfikacji PDF/UA-1.
Na przykład punkt kontrolny 01 dotyczy tego, czy katalog dokumentów zawiera wymagany identyfikator PDF/UA. Punkt kontrolny 06 dotyczy tego, czy wszystkie czcionki są osadzone z prawidłowymi mapowaniami Unicode. Punkt kontrolny 13 dotyczy tego, czy grafiki mają odpowiedni tekst alternatywny.
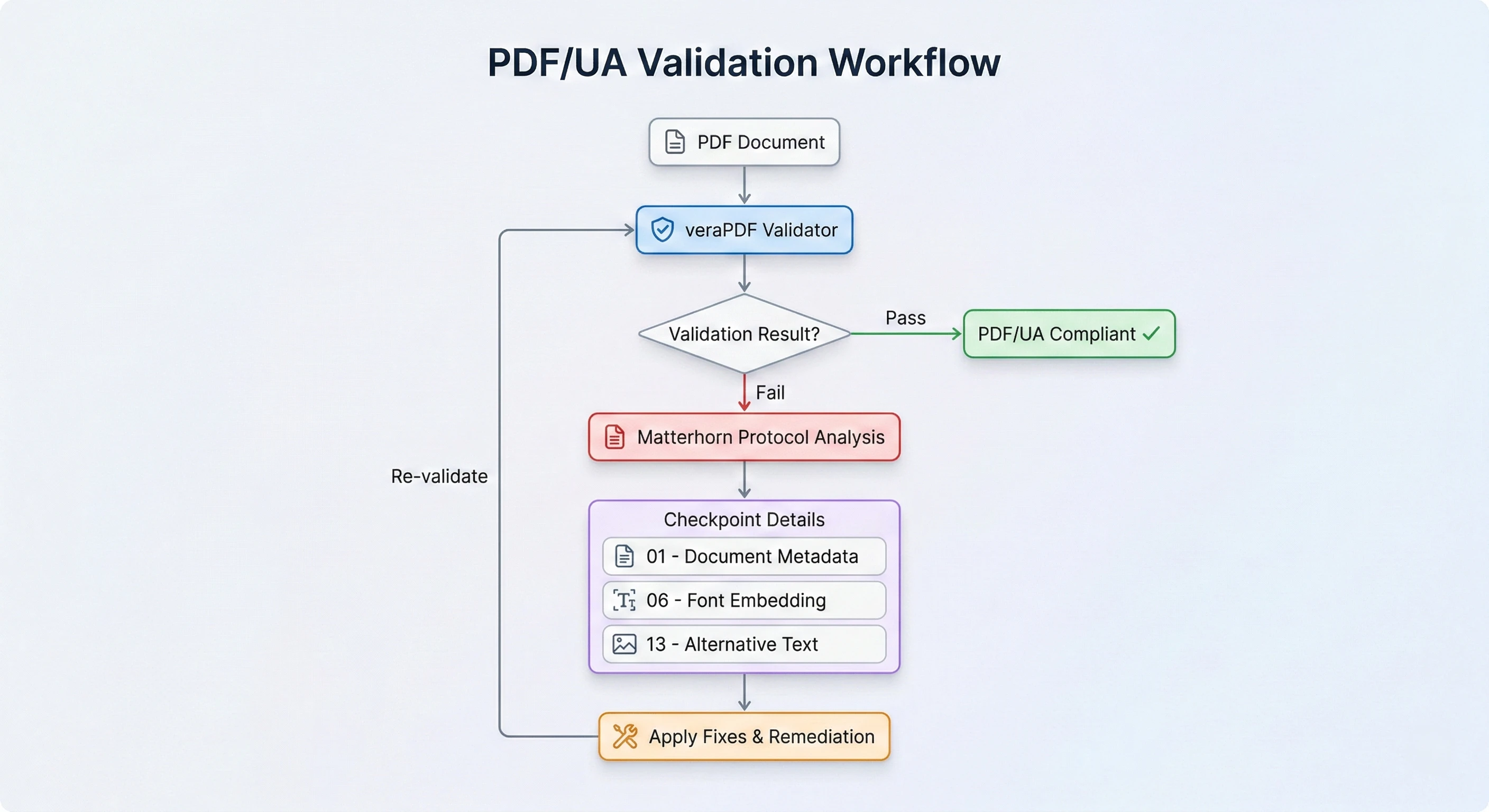
Zrozumienie protokołu Matterhorn pomaga w interpretacji wyników walidacji i ustalaniu priorytetów poprawek. Nie wszystkie warunki awarii mają taką samą wagę. Brakujący tytuł dokumentu to sprawa, którą można załatwić w pięć minut. Dokument całkowicie pozbawiony tagów wymaga pełnej konwersji.
Typowe błędy w zakresie zgodności i sposoby ich naprawiania
Oto kwestie, które najczęściej pojawiają się podczas sprawdzania poprawności plików PDF/UA:
Brak tytułu dokumentu. Metadane dokumentu muszą zawierać wpis "Title", a słownik ViewerPreferences musi określać, że w pasku tytułu okna powinien być wyświetlany tytuł (a nie nazwa pliku). Napraw to, ustawiając metadane przed zapisaniem:
:path=/static-assets/pdf/content-code-examples/tutorials/pdf-accessibility-csharp-pdfua-tutorial/pdfua-fix-document-title.csusing IronPdf;
PdfDocument pdf = PdfDocument.FromFile("input.pdf");
// Set the required document title
pdf.MetaData.Title = "Annual Budget Report - FY2025";
pdf.SaveAsPdfUA("budget-report-accessible.pdf");
Imports IronPdf
Dim pdf As PdfDocument = PdfDocument.FromFile("input.pdf")
' Set the required document title
pdf.MetaData.Title = "Annual Budget Report - FY2025"
pdf.SaveAsPdfUA("budget-report-accessible.pdf")Wynik
Wynik przechodzi teraz kontrolę tytułu dokumentu, a tytuł jest wyświetlany w pasku tytułu okna przeglądarki PDF zamiast nazwy pliku.
Brak tekstu alternatywnego przy ilustracjach. Każdy obraz, który przekazuje znaczenie, musi mieć tekst alternatywny. Dodaj to do źródłowego kodu HTML przed renderowaniem lub popraw bezpośrednio źródłowy plik PDF.
Nieprawidłowa hierarchia nagłówków. Dokument z pominiętymi lub nieuporządkowanymi poziomami nagłówków nie przejdzie walidacji. Przed konwersją popraw strukturę nagłówków w tekście źródłowym.
Czcionki nie są osadzone lub brakuje mapowań Unicode. Zazwyczaj dzieje się tak w przypadku starszych plików PDF, które wykorzystują niestandardowe kodowanie czcionek. IronPDF obsługuje osadzanie czcionek podczas konwersji, ale bardzo stare lub uszkodzone pliki źródłowe mogą wymagać szczególnej uwagi.
Wymagania dotyczące czcionek, przestrzeni kolorów i metadanych
PDF/UA ma określone wymagania dotyczące prezentacji wizualnej, które są sprawdzane przez narzędzia automatyczne. Wszystkie czcionki muszą być osadzone z prawidłowymi mapowaniami ToUnicode. Tekst musi być możliwy do wyodrębnienia jako znaki Unicode. Przestrzenie kolorów muszą być niezależne od urządzenia lub posiadać powiązany profil ICC. Pola formularzy muszą mieć odpowiednie etykiety i opisy.
IronPDF automatycznie uwzględnia wymagania dotyczące osadzania czcionek, przestrzeni kolorów i struktury podczas konwersji. Język i metadane można łatwo ustawić w kodzie, jak pokazano w przykładach w tym samouczku.
Ręczne kontrole, których automatyzacja nie jest w stanie wykryć
Niektóre aspekty dostępności wymagają weryfikacji przez człowieka. Automatyczne narzędzia sprawdzające mogą poinformować, że obraz ma tekst alternatywny, ale nie są w stanie ocenić, czy ten tekst jest rzeczywiście przydatny. Mogą oni potwierdzić, że nagłówki istnieją, ale nie są w stanie zweryfikować, czy tekst nagłówka dokładnie opisuje następującą po nim treść.
Wprowadź etap ręcznej weryfikacji do swojego procesu pracy w przypadku dokumentów o wysokim priorytecie. Zwróć uwagę na to, czy tekst alternatywny dokładnie opisuje zawartość obrazu, czy kolejność czytania ma sens logiczny przy linearnym odbiorze, czy tekst linku jest opisowy (a nie tylko "kliknij tutaj") oraz czy deklaracja języka odpowiada rzeczywistej zawartości dokumentu.
Dodatkowe narzędzia do walidacji
veraPDF jest standardem w zakresie automatycznego sprawdzania zgodności z PDF/UA, ale oprócz niego przydatne mogą być również inne narzędzia:
Program Adobe Acrobat Pro zawiera narzędzie do sprawdzania dostępności, dostępne w menu Narzędzia > Dostępność > Pełna kontrola. Jest to przydatne do szybkiej wizualnej kontroli podczas tworzenia oprogramowania i generuje raport czytelny dla człowieka. Zakres jest mniej kompleksowy niż w przypadku veraPDF dla PDF/UA-1, ale jest szeroko dostępny w większości zespołów.
PAC 2024 (PDF Accessibility Checker, bezpłatny dla systemu Windows) od PDF Association oferuje wizualną kontrolę drzewa tagów oraz sprawdzanie zgodności z PDF/UA i WCAG. Jest to szczególnie przydatne do sprawdzania kolejności czytania i struktury nagłówków wizualnie, a nie za pomocą raportu tekstowego.
Program Acrobat Reader umożliwia otwarcie panelu Tagów bezpośrednio w menu Widok > Pokaż/Ukryj > Panele nawigacyjne > Tagi. Nie jest to narzędzie do walidacji, ale umożliwia szybką wizualną kontrolę drzewa struktury bez konieczności korzystania z programu Acrobat Pro.
Najbardziej niezawodnym podejściem jest połączenie veraPDF do automatycznych kontroli CI/CD z ręczną weryfikacją w programie Acrobat lub PAC w przypadku dokumentów o wysokim priorytecie.
Jak naprawiać niezgodne pliki PDF na dużą skalę?
W przypadku organizacji posiadających duże biblioteki dokumentów konwersja poszczególnych plików nie jest praktyczna. Gdy audyt wykaże, że archiwum nie spełnia standardów dostępności lub gdy zbliża się termin, a do przetworzenia są tysiące dokumentów, potrzebne jest programowe podejście, które pozwoli obsłużyć dużą ilość danych przy minimalnej interwencji ręcznej.
Konwersja zbiorcza bibliotek dokumentów do formatu PDF/UA
IronPDF jest bezpieczny dla wątków, co oznacza, że można przetwarzać wiele dokumentów równolegle. Oto implementacja konwersji wsadowej na poziomie produkcyjnym z kontrolą współbieżności, obsługą błędów i raportowaniem postępu:
:path=/static-assets/pdf/content-code-examples/tutorials/pdf-accessibility-csharp-pdfua-tutorial/pdfua-batch-conversion.csusing IronPdf;
using System;
using System.Collections.Concurrent;
using System.IO;
using System.Linq;
using System.Threading;
using System.Threading.Tasks;
public class PdfUaBatchConverter
{
private readonly SemaphoreSlim _semaphore;
private readonly ConcurrentBag<string> _failures;
private int _processed;
public PdfUaBatchConverter(int maxConcurrency = 4)
{
_semaphore = new SemaphoreSlim(maxConcurrency);
_failures = new ConcurrentBag<string>();
_processed = 0;
}
public async Task ConvertDirectoryAsync(
string inputDirectory,
string outputDirectory,
NaturalLanguages language = NaturalLanguages.English)
{
Directory.CreateDirectory(outputDirectory);
string[] pdfFiles = Directory.GetFiles(inputDirectory, "*.pdf");
int totalFiles = pdfFiles.Length;
Console.WriteLine($"Starting PDF/UA conversion: {totalFiles} files");
Console.WriteLine($"Concurrency: {_semaphore.CurrentCount} parallel operations");
Console.WriteLine($"Language: {language}");
Console.WriteLine(new string('-', 50));
var stopwatch = System.Diagnostics.Stopwatch.StartNew();
var tasks = pdfFiles.Select(async inputPath =>
{
await _semaphore.WaitAsync();
try
{
string fileName = Path.GetFileName(inputPath);
string outputPath = Path.Combine(outputDirectory, fileName);
using (PdfDocument pdf = PdfDocument.FromFile(inputPath))
{
pdf.SaveAsPdfUA(outputPath, NaturalLanguage: language);
}
int count = Interlocked.Increment(ref _processed);
// Log progress every 10 files
if (count % 10 == 0 || count == totalFiles)
{
double rate = count / stopwatch.Elapsed.TotalSeconds;
Console.WriteLine(
$" [{count}/{totalFiles}] " +
$"{rate:F1} files/sec");
}
}
catch (Exception ex)
{
_failures.Add(
$"{Path.GetFileName(inputPath)}: {ex.Message}");
Interlocked.Increment(ref _processed);
}
finally
{
_semaphore.Release();
}
});
await Task.WhenAll(tasks);
stopwatch.Stop();
// Summary report
Console.WriteLine(new string('-', 50));
Console.WriteLine($"Completed in {stopwatch.Elapsed.TotalSeconds:F1}s");
Console.WriteLine(
$"Succeeded: {totalFiles - _failures.Count} " +
$"Failed: {_failures.Count}");
if (_failures.Any())
{
Console.WriteLine("\nFailed files:");
foreach (string failure in _failures)
Console.WriteLine($" - {failure}");
// Write failures to log file for later review
File.WriteAllLines(
Path.Combine(outputDirectory, "_failures.log"),
_failures);
}
}
}
// Usage
var converter = new PdfUaBatchConverter(
maxConcurrency: Environment.ProcessorCount);
await converter.ConvertDirectoryAsync(
inputDirectory: @"C:\Documents\Legacy",
outputDirectory: @"C:\Documents\Accessible",
language: NaturalLanguages.English
);
Imports IronPdf
Imports System
Imports System.Collections.Concurrent
Imports System.IO
Imports System.Linq
Imports System.Threading
Imports System.Threading.Tasks
Public Class PdfUaBatchConverter
Private ReadOnly _semaphore As SemaphoreSlim
Private ReadOnly _failures As ConcurrentBag(Of String)
Private _processed As Integer
Public Sub New(Optional maxConcurrency As Integer = 4)
_semaphore = New SemaphoreSlim(maxConcurrency)
_failures = New ConcurrentBag(Of String)()
_processed = 0
End Sub
Public Async Function ConvertDirectoryAsync(inputDirectory As String, outputDirectory As String, Optional language As NaturalLanguages = NaturalLanguages.English) As Task
Directory.CreateDirectory(outputDirectory)
Dim pdfFiles As String() = Directory.GetFiles(inputDirectory, "*.pdf")
Dim totalFiles As Integer = pdfFiles.Length
Console.WriteLine($"Starting PDF/UA conversion: {totalFiles} files")
Console.WriteLine($"Concurrency: {_semaphore.CurrentCount} parallel operations")
Console.WriteLine($"Language: {language}")
Console.WriteLine(New String("-"c, 50))
Dim stopwatch = System.Diagnostics.Stopwatch.StartNew()
Dim tasks = pdfFiles.Select(Async Function(inputPath)
Await _semaphore.WaitAsync()
Try
Dim fileName As String = Path.GetFileName(inputPath)
Dim outputPath As String = Path.Combine(outputDirectory, fileName)
Using pdf As PdfDocument = PdfDocument.FromFile(inputPath)
pdf.SaveAsPdfUA(outputPath, NaturalLanguage:=language)
End Using
Dim count As Integer = Interlocked.Increment(_processed)
' Log progress every 10 files
If count Mod 10 = 0 OrElse count = totalFiles Then
Dim rate As Double = count / stopwatch.Elapsed.TotalSeconds
Console.WriteLine($" [{count}/{totalFiles}] {rate:F1} files/sec")
End If
Catch ex As Exception
_failures.Add($"{Path.GetFileName(inputPath)}: {ex.Message}")
Interlocked.Increment(_processed)
Finally
_semaphore.Release()
End Try
End Function)
Await Task.WhenAll(tasks)
stopwatch.Stop()
' Summary report
Console.WriteLine(New String("-"c, 50))
Console.WriteLine($"Completed in {stopwatch.Elapsed.TotalSeconds:F1}s")
Console.WriteLine($"Succeeded: {totalFiles - _failures.Count} Failed: {_failures.Count}")
If _failures.Any() Then
Console.WriteLine(vbCrLf & "Failed files:")
For Each failure As String In _failures
Console.WriteLine($" - {failure}")
Next
' Write failures to log file for later review
File.WriteAllLines(Path.Combine(outputDirectory, "_failures.log"), _failures)
End If
End Function
End Class
' Usage
Dim converter As New PdfUaBatchConverter(maxConcurrency:=Environment.ProcessorCount)
Await converter.ConvertDirectoryAsync(inputDirectory:="C:\Documents\Legacy", outputDirectory:="C:\Documents\Accessible", language:=NaturalLanguages.English)Wynik
WyjściePDF/UA-1dla jednego przetworzonego pliku. Wzór korzysta z SemaphoreSlim do kontroli współbieżności, przechwytywania błędów dla każdego pliku, usuwania na bazie using aby zapobiec wyciekom pamięci oraz bieżącej stawki plików na sekundę.
Osiągnięcie 80–90% automatycznej konwersji dostępności
Pozostałe 10–20% pracy związanej z dostosowaniem wymaga ludzkiej oceny: sensowny tekst alternatywny dla złożonych obrazów, korekty kolejności czytania w przypadku nietypowych układów oraz semantyczne przypisanie nagłówków do dokumentów, które w oryginale nie miały odpowiedniej struktury. Po zakończeniu automatycznego przetwarzania należy zaplanować ręczną weryfikację dokumentów o najwyższym priorytecie.
Priorytetyzacja działań naprawczych
Nie wszystkie dokumenty wiążą się z takim samym ryzykiem braku zgodności. Skoncentruj swoje działania naprawcze w sposób strategiczny:
Najpierw dokumenty przeznaczone dla odbiorców zewnętrznych. Najwyższy priorytet mają wszystkie materiały publikowane na Państwa stronie internetowej, przekazywane klientom lub składane do agencji rządowych. Są to dokumenty, które najczęściej powodują skargi lub audyty.
Dokumenty wewnętrzne, do których często sięga się w drugiej kolejności. Materiały szkoleniowe, podręczniki dotyczące zasad i formularze kadrowe, z których wielu pracowników korzysta regularnie, powinny zostać niezwłocznie poprawione.
Dokumenty archiwalne i o małym natężeniu ruchu są na końcu. Starsze dokumenty, do których dostęp jest minimalny, mogą być naprawiane na bieżąco lub konwertowane na żądanie, gdy ktoś o to poprosi.
Takie podejście pozwala wykazać postępy w zakresie zgodności w przypadku najbardziej widocznych dokumentów, jednocześnie stopniowo przetwarzając pozostałą część archiwum.
Łączenie PDF/UA z procesami scalania, podpisywania i metadanych
W procesach produkcyjnych konwersja do formatu PDF/UA rzadko odbywa się w izolacji. Często trzeba to połączyć z innymi operacjami na dokumentach. IronPDF obsługuje łączenie tych funkcji w łańcuch:
Wejscie
Dwa dokumenty źródłowe: strona tytułowa i raport finansowy, każdy z nich przekonwertowany do formatu PDF/UA i połączony w jeden plik dostępny dla osób niepełnosprawnych.
:path=/static-assets/pdf/content-code-examples/tutorials/pdf-accessibility-csharp-pdfua-tutorial/pdfua-merge-metadata.csusing IronPdf;
// Load and convert to PDF/UA in memory
PdfDocument report = PdfDocument.FromFile("financial-report.pdf");
report.ConvertToPdfUA();
// Set comprehensive metadata
report.MetaData.Title = "Annual Financial Report 2025";
report.MetaData.Author = "Finance Department";
report.MetaData.Subject = "Year-end financial summary and analysis";
// Merge with a cover page (also converted to PDF/UA)
PdfDocument coverPage = PdfDocument.FromFile("cover-page.pdf");
coverPage.ConvertToPdfUA();
PdfDocument finalDocument = PdfDocument.Merge(coverPage, report);
// Save the combined, accessible document
finalDocument.SaveAs("annual-report-final-accessible.pdf");
// Dispose of intermediate documents
report.Dispose();
coverPage.Dispose();
Imports IronPdf
' Load and convert to PDF/UA in memory
Dim report As PdfDocument = PdfDocument.FromFile("financial-report.pdf")
report.ConvertToPdfUA()
' Set comprehensive metadata
report.MetaData.Title = "Annual Financial Report 2025"
report.MetaData.Author = "Finance Department"
report.MetaData.Subject = "Year-end financial summary and analysis"
' Merge with a cover page (also converted to PDF/UA)
Dim coverPage As PdfDocument = PdfDocument.FromFile("cover-page.pdf")
coverPage.ConvertToPdfUA()
Dim finalDocument As PdfDocument = PdfDocument.Merge(coverPage, report)
' Save the combined, accessible document
finalDocument.SaveAs("annual-report-final-accessible.pdf")
' Dispose of intermediate documents
report.Dispose()
coverPage.Dispose()Wynik
Jak widać, dwa dokumenty źródłowe zostały połączone w jeden plik zgodny ze standardem PDF/UA (strona tytułowa, a następnie sprawozdanie finansowe) z podpisem cyfrowym i kompleksowymi metadanymi.
Konwersja do formatu PDF/UA jest również kompatybilna z podpisami cyfrowymi, ochroną hasłem oraz formatowaniem archiwalnym PDF/A.
Jakie są rzeczywiste przykłady zastosowań zgodności z PDF/UA?
Wymagania dotyczące dostępności plików PDF pojawiają się w każdym sektorze, a konkretne wyzwania różnią się w zależności od branży.
Najbardziej konkretne terminy dotyczą agencji rządowych. Władze stanowe i lokalne podlegające przepisom tytułu II ustawy ADA przetwarzają dziesiątki tysięcy starszych dokumentów (porządki obrad, wnioski o pozwolenia, mapy zagospodarowania przestrzennego i inne) przed terminami wyznaczonymi na kwiecień 2026 r. i kwiecień 2027 r. Omówione wcześniej wzorce naprawy partii mają tutaj bezpośrednie zastosowanie.
Organizacje prawne generują ogromne ilości plików PDF: dokumenty procesowe, pisma procesowe, akta spraw, umowy i materiały dowodowe. W przypadku dokumentów składanych elektronicznie lub udostępnianych osobom z niepełnosprawnościami obowiązują wymogi dotyczące dostępności. Wbudowanie konwersji do formatu PDF/UA w etapie wyjściowym systemu zarządzania dokumentami zapewnia zgodność z normami niezależnie od sposobu tworzenia treści.
Instytucje szkolnictwa wyższego tworzą materiały dydaktyczne, programy nauczania, prace badawcze, formularze administracyjne i raporty instytucjonalne. Zgodnie z sekcją 508 (dla instytucji otrzymujących fundusze federalne) oraz tytułem II ustawy ADA (dla instytucji publicznych) dokumenty te muszą być dostępne. Szczególnie przydatny jest tutaj proces konwersji HTML do PDF/UA, ponieważ wiele treści akademickich pochodzi z internetu lub jest generowanych na podstawie szablonów.
Organizacje opieki zdrowotnej tworzą zestawienia dla pacjentów, wyjaśnienia dotyczące ubezpieczenia, wyniki badań i materiały edukacyjne, które muszą być dostępne zgodnie z sekcją 508 i różnymi przepisami stanowymi. Dokumenty te często zawierają dane tabelaryczne i wykresy, dlatego szczególnie ważne jest prawidłowe oznaczanie tabel i tekst alternatywny obrazów.
Firmy świadczące usługi finansowe generują wyciągi z kont, dokumenty informacyjne, zgłoszenia regulacyjne i raporty. Wiele z nich musi być dostępnych w momencie dystrybucji do klientów lub złożenia w agencjach rządowych. Duża objętość sprawia, że niezbędne jest przetwarzanie wsadowe.
Jak osiągnąć zgodność zarówno z PDF/UA, jak i PDF/A?
Kiedy potrzebujesz zarówno archiwizacji, jak i dostępności
PDF/A to standard archiwizacji, który gwarantuje, że dokumenty pozostaną widoczne i możliwe do odtworzenia przez długi czas. PDF/UA to standard dostępności. Niektóre organizacje potrzebują zarówno dokumentów, które są trwale zachowane, jak i dostępnych. Jest to powszechne w przypadku dokumentacji rządowej, archiwizacji prawnej oraz dokumentacji medycznej.
Poziom zgodności PDF/A-3a wymaga w szczególności zarówno zgodności archiwalnej, jak i pełnej dostępności (litera "a" oznacza "dostępny"). Jeśli uzyskasz format PDF/A-3a, skutecznie spełnisz zarówno wymagania PDF/A, jak i PDF/UA.
IronPDF obsługuje oba standardy:
:path=/static-assets/pdf/content-code-examples/tutorials/pdf-accessibility-csharp-pdfua-tutorial/pdfua-dual-compliance.csusing IronPdf;
PdfDocument pdf = PdfDocument.FromFile("government-record.pdf");
// Convert to PDF/UA for accessibility
pdf.ConvertToPdfUA();
// Set required metadata
pdf.MetaData.Title = "Public Hearing Minutes - January 2025";
pdf.MetaData.Author = "City Clerk's Office";
// Convert to PDF/A for archival compliance
pdf.SaveAsPdfA("government-record-archive.pdf");
Imports IronPdf
Dim pdf As PdfDocument = PdfDocument.FromFile("government-record.pdf")
' Convert to PDF/UA for accessibility
pdf.ConvertToPdfUA()
' Set required metadata
pdf.MetaData.Title = "Public Hearing Minutes - January 2025"
pdf.MetaData.Author = "City Clerk's Office"
' Convert to PDF/A for archival compliance
pdf.SaveAsPdfA("government-record-archive.pdf")Wynik
Dokument zapisano w formacie PDF/A-3a, czyli na poziomie zgodności, który spełnia jednocześnie wymagania dotyczące archiwizacji (PDF/A) i dostępności (PDF/UA).
Łączenie PDF/UA z podpisami cyfrowymi
Dokumenty dostępne, które wymagają również uwierzytelnienia, mogą łączyć konwersję do formatu PDF/UA z podpisami cyfrowymi. Najpierw zastosuj konwersję do formatu PDF/UA, a następnie podpisz dokument:
:path=/static-assets/pdf/content-code-examples/tutorials/pdf-accessibility-csharp-pdfua-tutorial/pdfua-digital-signature.csusing IronPdf;
using IronPdf.Signing;
PdfDocument pdf = PdfDocument.FromFile("contract.pdf");
pdf.ConvertToPdfUA();
pdf.MetaData.Title = "Service Agreement - Executed Copy";
// Apply a digital signature to the accessible document
var signature = new PdfSignature("certificate.pfx", "password");
pdf.Sign(signature);
pdf.SaveAs("contract-accessible-signed.pdf");
Imports IronPdf
Imports IronPdf.Signing
Dim pdf As PdfDocument = PdfDocument.FromFile("contract.pdf")
pdf.ConvertToPdfUA()
pdf.MetaData.Title = "Service Agreement - Executed Copy"
' Apply a digital signature to the accessible document
Dim signature As New PdfSignature("certificate.pfx", "password")
pdf.Sign(signature)
pdf.SaveAs("contract-accessible-signed.pdf")Dokumenty dostosowane do przyszłych standardów
Standardy dostępności wciąż się zmieniają. WCAG 2.2 został opublikowany w 2023 r., a prace nad WCAG 3.0 są w toku.PDF/UA-2jest bardziej zgodny z nowoczesnymi standardami internetowymi niż PDF/UA-1. Wprowadzając zgodność z PDF/UA do procesów tworzenia dokumentów już teraz, tworzysz fundament, który można aktualizować wraz z ewolucją standardów, zamiast zmagać się później z koniecznością całkowitej modernizacji.
Inwestycja w infrastrukturę dokumentów dostępnych dla wszystkich przynosi korzyści wykraczające poza samą zgodność z przepisami. Prawidłowo otagowane pliki PDF są łatwiejsze do wyszukiwania, lepiej wyświetlają się na urządzeniach mobilnych, zapewniają lepsze wyniki ekstrakcji tekstu i działają bardziej niezawodnie w różnych przeglądarkach PDF i na różnych platformach. Dostępność to nie tylko wymóg prawny. To lepsza inżynieria.
Kolejne kroki
Zgodność z PDF/UA to nie tylko zaznaczenie jednego pola wyboru. Obejmuje to zrozumienie przepisów, prawidłowe tworzenie kodu HTML, konwersję programową, automatyczną walidację oraz skalowalne naprawianie istniejących archiwów. Istnieją jednak narzędzia i wzorce, które ułatwiają zarządzanie tymi zadaniami, nawet w przypadku organizacji posiadających duże biblioteki dokumentów i mających napięte terminy. IronPDF zapewnia silnik PDF z etykietami, metody SaveAsPdfUA i RenderHtmlAsPdfUA, możliwości przetwarzania wsadowego oraz wsparcie dla różnych platform .NET, co stanowi fundament każdej dostępnej ścieżki PDF .NET. Niezależnie czy potrzebujesz zgodności Sekcja 508 PDF C# dla rządowego kontraktu, zgodności WCAG PDF C# dla platformy raportowej w przedsiębiorstwie, czy konwersji PDF/UA C# dla projektu naprawy dokumentów z trudnym terminem, wzorce w tym tutorialu dają Ci sprawdzoną ramę do budowy.
Rozpocznij od jednoplikowej konwersji, aby zrozumieć, co produkuje SaveAsPdfUA. Sprawdź poprawność tłumaczenia za pomocą veraPDF i protokołu Matterhorn. Buduj dostępne szablony HTML używające semantycznych elementów i odpowiedniej hierarchii nagłówków. Następnie skaluje się w górę za pomocą wsadowej ścieżki konwersji dla swojego istniejącego archiwum. Połącz PDF/UA z zgodnością archiwizacyjną PDF/A, podpisami cyfrowymi, zarządzaniem metadanymi i kompresją PDF, aby zbudować przepływy dokumentów spełniające wszystkie wymagania Twojej organizacji.
Dla głębszej referencji, przewodnik po PDF/UA IronPDF szczegółowo omawia powierzchnię API, a tutorial dotyczący archiwizacji PDF/A przeprowadza przez pełen przepływ zgodności archiwizacyjnej, jeśli potrzebujesz obu standardów jednocześnie.
Czy jesteś gotowy do rozpoczęcia budowy? Pobierz IronPDF i wypróbuj z bezpłatną wersją próbną. Ta sama biblioteka obsługuje wszystko, od jednoplikowej konwersji dostępności po ścieżki naprawcze w skali dla przedsiębiorstw. Jeśli masz pytania dotyczące implementacji, strategii zgodności lub architektury dla swojego specyficznego przypadku użycia, skontaktuj się z naszym zespołem wsparcia inżynieryjnego. Pomogliśmy zespołom każdej skali poprawnie uporządkować dostępność dokumentów i z przyjemnością pomożemy Ci zrobić to samo.
Często Zadawane Pytania
What is PDF/UA and why is it important?
PDF/UA (Universal Accessibility) to norma ISO dotycząca dokumentów PDF dostępnych dla osób niepełnosprawnych, zapewniająca im dostęp do treści PDF i możliwość interakcji z nimi. Ma ona kluczowe znaczenie dla zgodności z przepisami dotyczącymi dostępności, takimi jak sekcja 508 i unijna ustawa o dostępności.
Jak mogę przekonwertować istniejące pliki PDF do formatu PDF/UA przy użyciu języka C#?
Możesz konwertować istniejące pliki PDF do formatu PDF/UA w języku C# za pomocą metody SaveAsPdfUA biblioteki IronPDF, która zapewnia zgodność dokumentów ze standardami dostępności poprzez osadzenie niezbędnych tagów i struktur.
Jakie narzędzia oferuje IronPDF do renderowania HTML do formatu PDF/UA zgodnego z zasadami dostępności?
IronPDF oferuje metodę RenderHtmlAsPdfUA, która pozwala programistom konwertować treści HTML na pliki PDF z tagami zgodne ze standardami dostępności PDF/UA.
Czy IronPDF może obsłużyć projekty naprawy plików PDF/UA na dużą skalę?
Tak, IronPDF obsługuje zbiorczą korektę dużych archiwów dokumentów poprzez równoległe potoki przetwarzania, co sprawia, że jest wydajny w obsłudze rozległych projektów korekty PDF/UA.
Jak sprawdzić zgodność z PDF/UA za pomocą IronPDF?
IronPDF integruje się z veraPDF, narzędziem pomagającym w walidacji zgodności PDF/UA z protokołem Matterhorn, zapewniając, że dokumenty spełniają standardy dostępności.
Jakie typowe problemy związane z zgodnością z PDF/UA może pomóc rozwiązać IronPDF?
IronPDF może pomóc w naprawieniu typowych problemów związanych z zgodnością, takich jak brakujące tytuły dokumentów, brakujące osadzone czcionki i uszkodzone hierarchie nagłówków w dokumentach PDF/UA.
Czy IronPDF jest kompatybilny z różnymi środowiskami .NET?
Tak, IronPDF jest kompatybilny z .NET 6+, .NET Framework 4.6.2+ oraz .NET Standard 2.0 i obsługuje wdrożenie na systemach Windows, Linux, macOS, Docker, Azure i AWS.
W jaki sposób można łączyć dokumenty PDF/UA z podpisami cyfrowymi przy użyciu IronPDF?
IronPDF pozwala łączyć dokumenty zgodne ze standardem PDF/UA z podpisami cyfrowymi w celu zwiększenia bezpieczeństwa dokumentów i zapewnienia zgodności z przepisami.
Jakie znaczenie mają terminy określone w tytule II ustawy ADA na kwiecień 2026 i 2027 roku?
Terminy te wyznaczają moment, w którym niektóre aplikacje przeznaczone dla użytkowników muszą spełniać zaktualizowane standardy dostępności zgodnie z tytułem II ustawy ADA, co sprawia, że narzędzia takie jak IronPDF są niezbędne dla programistów, aby zapewnić zgodność ich plików PDF z tymi wymaganiami.
Czy IronPDF może pomóc w obsłudze metadanych w dokumentach PDF/UA?
Tak, IronPDF obsługuje integrację procesów związanych z metadanymi w dokumentach PDF/UA, co jest niezbędne do zachowania dostępności i zgodności z przepisami.


Wciąż przewijasz?
Czy chcesz szybko dowodu? PM > Install-Package IronPdf
Uruchom przykład i zobacz, jak Twój kod HTML zamienia się w plik PDF.










