

Traitement des PDF par l'IA en C# : Résumer, extraire et analyser des documents avec IronPDF
Le traitement PDF alimenté par l'IA en C# avec IronPDF permet aux développeurs .NET de résumer des documents , d'extraire des données structurées et de construire des systèmes de questions-réponses directement sur les flux de travail PDF existants — en utilisant le package IronPdf.Extensions.AI construit sur Microsoft Semantic Kernel pour se connecter de manière transparente avec Azure OpenAI et les modèles OpenAI . Que vous construisiez des outils de découverte juridique, des pipelines d'analyse financière ou des plateformes d'intelligence documentaire, IronPDF prend en charge l'extraction des PDF et la préparation du contexte afin que vous puissiez vous concentrer sur la logique de l'IA.
TL;DR : Guide de démarrage rapide
Ce tutoriel explique comment connecter IronPDF à des services d'IA pour la synthèse de documents, l'extraction de données et l'interrogation intelligente en C# .NET.
- À qui s'adresse ce document: Les développeurs .NET qui créent des applications d'intelligence documentaire - systèmes de divulgation juridique, outils d'analyse financière, plateformes d'examen de la conformité, ou toute application qui doit extraire du sens à partir de grands volumes de documents PDF.
- Ce que vous allez construire: Résumé d'un seul document, extraction de données JSON structurées avec des schémas personnalisés, réponse aux questions sur le contenu des documents, pipelines RAG pour les documents longs, et flux de traitement AI par lots à travers les bibliothèques de documents.
- Où ça marche: Tout environnement .NET 6+ avec une clé Azure OpenAI ou OpenAI API. L'extension AI s'intègre à Microsoft Semantic Kernel et gère automatiquement la gestion des fenêtres contextuelles, le découpage et l'orchestration.
- Quand utiliser cette approche: Lorsque votre application doit traiter des PDF au-delà de l'extraction de texte - comprendre les obligations contractuelles, résumer des articles de recherche, extraire des tableaux financiers en tant que données structurées, ou répondre aux questions des utilisateurs sur le contenu des documents à l'échelle.
- Pourquoi c'est important techniquement: L'extraction de texte brut perd la structure du document - les tableaux s'effondrent, les mises en page multi-colonnes se brisent et les relations sémantiques disparaissent. IronPDF prépare les documents pour la consommation de l'IA en préservant la structure et en gérant les limites de jetons, afin que le modèle reçoive des données d'entrée propres et bien organisées.
Résumez un PDF en quelques lignes de code :
-
Installez IronPDF avec le Gestionnaire de Packages NuGet
PM > Install-Package IronPdf -
Copiez et exécutez cet extrait de code.
await IronPdf.AI.PdfAIEngine.Summarize("contract.pdf", "summary.txt", azureEndpoint, azureApiKey); -
Déployez pour tester sur votre environnement de production.
Commencez à utiliser IronPDF dans votre projet dès aujourd'hui avec un essai gratuit

Après avoir acheté ou vous être inscrit à une version d'essai de 30 jours d'IronPDF, ajoutez votre clé de licence au début de votre application.
IronPdf.License.LicenseKey = "KEY";IronPdf.License.LicenseKey = "KEY";Imports IronPdf
IronPdf.License.LicenseKey = "KEY"Table des matières
- L'opportunité AI + PDF
- Intégration IA intégrée d'IronPDF
- Résumé du document
- Extraction intelligente de données
- Question-Réponse sur les documents
- Traitement par lots de l'IA
- Cas d'utilisation dans le monde réel
- Dépannage et assistance technique
L'opportunité AI + PDF
Pourquoi les PDF sont la plus grande source de données inexploitée
Les PDF représentent l'un des plus grands réservoirs de connaissances professionnelles structurées dans l'entreprise moderne. Les documents professionnels - contrats, états financiers, rapports de conformité, mémoires juridiques et documents de recherche - sont principalement stockés au format PDF. Ces documents contiennent des informations commerciales essentielles : des termes contractuels qui définissent les obligations et les responsabilités, des mesures financières qui orientent les décisions d'investissement, des exigences réglementaires qui garantissent la conformité et des résultats de recherche qui orientent la stratégie.
Pourtant, les approches traditionnelles du traitement des PDF ont été sévèrement limitées. Les outils d'extraction de texte de base peuvent extraire des caractères bruts d'une page, mais ils perdent un contexte crucial : les structures de tableau s'effondrent en texte mélangé, les mises en page en plusieurs colonnes deviennent absurdes et les relations sémantiques entre les sections disparaissent.
L'avancée provient de la capacité de l'IA à comprendre le contexte et la structure. Les linguistes modernes ne se contentent pas de voir les mots : ils comprennent l'organisation des documents, reconnaissent les schémas tels que les clauses contractuelles ou les tableaux financiers, et peuvent extraire le sens même à partir de mises en page complexes. Le système de raisonnement unifié de GPT-5 avec son routeur en temps réel et les capacités agentiques améliorées de Claude Sonnet 4.5 démontrent tous deux des taux d'hallucination considérablement réduits par rapport aux modèles précédents, ce qui les rend fiables pour l'analyse de documents professionnels.
Comment les LLM comprennent la structure des documents
Les grands modèles de langage apportent des capacités sophistiquées de traitement du langage naturel à l'analyse des PDF. L'architecture hybride de GPT-5 comprend plusieurs sous-modèles (principal, mini, réflexion, nano) avec un routeur en temps réel qui sélectionne dynamiquement la variante optimale en fonction de la complexité de la tâche : les questions simples passent par des modèles plus rapides tandis que les tâches de raisonnement complexes font appel au modèle complet.
Claude Opus 4.6 excelle particulièrement dans les tâches agentiques de longue durée, avec des équipes d'agents qui se coordonnent directement sur des tâches segmentées et une fenêtre contextuelle de 1 million de mots-clés qui peut traiter des bibliothèques de documents entières sans découpage.
Comment les modèles d'IA analysent la structure des documents PDF et identifient leurs éléments ?
Cette compréhension du contexte permet aux LLM d'effectuer des tâches qui nécessitent une véritable compréhension. Lors de l'analyse d'un contrat, un gestionnaire du droit du travail peut non seulement identifier les clauses contenant le mot "résiliation", mais aussi comprendre les conditions spécifiques dans lesquelles la résiliation est autorisée, les exigences en matière de préavis et les responsabilités qui en découlent. La base technique permettant cette capacité est l'architecture de transformateur qui alimente les LLM modernes, avec la fenêtre de contexte de GPT-5 supportant jusqu'à 272 000 jetons d'entrée et la fenêtre de jeton de 200 000 de Claude Sonnet 4.5 fournissant une couverture complète du document.
Intégration de l'IA dans IronPDF
Installation d'IronPDF et des extensions AI
Pour commencer avec le traitement PDF alimenté par l'IA, il faut disposer de la bibliothèque de base IronPDF, du package d'extensions AI et des dépendances Microsoft Semantic Kernel.
Installez IronPDF à l'aide du Package Manager NuGet :
PM > Install-Package IronPdf
PM > Install-Package IronPdf.Extensions.AI
PM > Install-Package Microsoft.SemanticKernel
PM > Install-Package Microsoft.SemanticKernel.Plugins.MemoryPM > Install-Package IronPdf
PM > Install-Package IronPdf.Extensions.AI
PM > Install-Package Microsoft.SemanticKernel
PM > Install-Package Microsoft.SemanticKernel.Plugins.MemoryCes progiciels fonctionnent ensemble pour fournir une solution complète. IronPDF prend en charge toutes les opérations liées au PDF - extraction de texte, rendu des pages, conversion de format - tandis que l'extension AI gère l'intégration avec les modèles de langage via Microsoft Semantic Kernel.
Les packages du noyau sémantique incluent des API expérimentales. Ajoutez CODE-37 à votre PropertyGroup .csproj pour supprimer les avertissements du compilateur.
Configuration de votre clé API OpenAI/Azure
Avant de pouvoir exploiter les fonctionnalités de l'IA, vous devez configurer l'accès à un fournisseur de services d'IA. L'extension AI d'IronPDF prend en charge à la fois OpenAI et Azure OpenAI. Azure OpenAI est souvent préféré pour les applications d'entreprise parce qu'il offre des fonctions de sécurité améliorées, des certifications de conformité et la possibilité de conserver les données dans des régions géographiques spécifiques.
Pour configurer Azure OpenAI, vous aurez besoin de l'URL de votre point de terminaison Azure, de la clé API et des noms de déploiement pour les modèles de chat et d'intégration à partir du portail Azure.
Initialisation du moteur d'IA
L'extension AI d'IronPDF utilise le noyau sémantique de Microsoft sous le capot. Avant d'utiliser les fonctions d'IA, vous devez initialiser le noyau avec vos identifiants Azure OpenAI et configurer la mémoire pour le traitement des documents.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/configure-azure-credentials.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
// Initialize IronPDF AI with Azure OpenAI credentials
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel with Azure OpenAI
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
// Create memory store for document embeddings
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
// Initialize IronPDF AI
IronDocumentAI.Initialize(kernel, memory);
Console.WriteLine("IronPDF AI initialized successfully with Azure OpenAI");Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
' Initialize IronPDF AI with Azure OpenAI credentials
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel with Azure OpenAI
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
' Create memory store for document embeddings
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
' Initialize IronPDF AI
IronDocumentAI.Initialize(kernel, memory)
Console.WriteLine("IronPDF AI initialized successfully with Azure OpenAI")L'initialisation crée deux composants clés :
- Kernel: Gère les complétions de chat et la génération d'intégration de texte via Azure OpenAI
- Mémoire: Stocke les enchâssements de documents pour les opérations de recherche sémantique et d'extraction
Une fois initialisé avec IronDocumentAI.Initialize(), vous pouvez utiliser les fonctionnalités d'IA dans toute votre application. Pour les applications de production, il est fortement recommandé de stocker les informations d'identification dans des variables d'environnement ou dans Azure Key Vault.
Comment IronPDF prépare les PDF pour le contexte de l'IA
L'un des aspects les plus délicats du traitement des PDF par l'IA est la préparation des documents en vue de leur consommation par les modèles linguistiques. Bien que GPT-5 prenne en charge jusqu'à 272 000 jetons d'entrée et que Claude Opus 4.6 offre désormais une fenêtre contextuelle de 1 million de jetons, un simple contrat juridique ou un rapport financier peut encore facilement dépasser les limites des anciens modèles.
L'extension AI d'IronPDF gère cette complexité par le biais d'une préparation intelligente des documents. Lorsque vous appelez une méthode AI, IronPdf extrait d'abord le texte du PDF tout en préservant les informations structurelles : identification des paragraphes, préservation des structures de tableaux et maintien des relations entre les sections.
Pour les documents qui dépassent les limites du contexte, IronPDF met en œuvre un découpage stratégique aux points de rupture sémantique, c'est-à-dire aux divisions naturelles de la structure du document, comme les en-têtes de section, les sauts de page ou les limites de paragraphe.
Synthèse de documents
Sommaires de documents individuels
Le résumé de documents apporte une valeur immédiate en condensant de longs documents en informations digestes. La méthode Summarize gère l'ensemble du flux de travail : extraction du texte, préparation de celui-ci pour la consommation par l'IA, demande d'un résumé au modèle de langage et enregistrement des résultats.
Entrée
Le code charge un PDF en utilisant PdfDocument.FromFile() et appelle pdf.Summarize() pour générer un résumé concis, puis enregistre le résultat dans un fichier texte.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/single-document-summary.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
// Summarize a PDF document using IronPDF AI
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
// Load and summarize PDF
var pdf = PdfDocument.FromFile("sample-report.pdf");
string summary = await pdf.Summarize();
Console.WriteLine("Document Summary:");
Console.WriteLine(summary);
File.WriteAllText("report-summary.txt", summary);
Console.WriteLine("\nSummary saved to report-summary.txt");Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
' Summarize a PDF document using IronPDF AI
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
' Load and summarize PDF
Dim pdf = PdfDocument.FromFile("sample-report.pdf")
Dim summary As String = Await pdf.Summarize()
Console.WriteLine("Document Summary:")
Console.WriteLine(summary)
File.WriteAllText("report-summary.txt", summary)
Console.WriteLine(vbCrLf & "Summary saved to report-summary.txt")Sortie Console
Le processus de résumé utilise des messages-guides sophistiqués pour garantir des résultats de haute qualité. Le GPT-5 et Claude Sonnet 4.5 en 2026 présentent tous deux des capacités de suivi d'instructions considérablement améliorées, garantissant que les résumés capturent les informations essentielles tout en restant concis et lisibles.
Pour une explication plus détaillée des techniques de résumé de documents et des options avancées, veuillez consulter notre guide pratique.
Synthèse multi-documents
De nombreux scénarios du monde réel nécessitent de synthétiser les informations contenues dans plusieurs documents. Une équipe juridique pourrait avoir besoin d'identifier des clauses communes dans un portefeuille de contrats, ou un analyste financier pourrait vouloir comparer des mesures dans des rapports trimestriels.
L'approche de la synthèse multi-documents consiste à traiter chaque document individuellement pour en extraire les informations clés, puis à agréger ces informations pour la synthèse finale.
Cet exemple parcourt plusieurs PDF, appelant pdf.Summarize() sur chacun, puis utilise pdf.Query() avec les résumés combinés pour générer une synthèse unifiée.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/multi-document-synthesis.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
// Synthesize insights across multiple related documents (e.g., quarterly reports into annual summary)
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
// Define documents to synthesize
string[] documentPaths = {
"Q1-report.pdf",
"Q2-report.pdf",
"Q3-report.pdf",
"Q4-report.pdf"
};
var documentSummaries = new List<string>();
// Summarize each document
foreach (string path in documentPaths)
{
var pdf = PdfDocument.FromFile(path);
string summary = await pdf.Summarize();
documentSummaries.Add($"=== {Path.GetFileName(path)} ===\n{summary}");
Console.WriteLine($"Processed: {path}");
}
// Combine and synthesize across all documents
string combinedSummaries = string.Join("\n\n", documentSummaries);
var synthesisDoc = PdfDocument.FromFile(documentPaths[0]);
string synthesisQuery = @"Based on the quarterly summaries below, provide an annual synthesis:
ll trends across quarters
chievements and challenges
over-year patterns
s:
inedSummaries;
string synthesis = await synthesisDoc.Query(synthesisQuery);
Console.WriteLine("\n=== Annual Synthesis ===");
Console.WriteLine(synthesis);
File.WriteAllText("annual-synthesis.txt", synthesis);Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.IO
' Synthesize insights across multiple related documents (e.g., quarterly reports into annual summary)
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
' Define documents to synthesize
Dim documentPaths As String() = {
"Q1-report.pdf",
"Q2-report.pdf",
"Q3-report.pdf",
"Q4-report.pdf"
}
Dim documentSummaries = New List(Of String)()
' Summarize each document
For Each path As String In documentPaths
Dim pdf = PdfDocument.FromFile(path)
Dim summary As String = Await pdf.Summarize()
documentSummaries.Add($"=== {Path.GetFileName(path)} ==={vbCrLf}{summary}")
Console.WriteLine($"Processed: {path}")
Next
' Combine and synthesize across all documents
Dim combinedSummaries As String = String.Join(vbCrLf & vbCrLf, documentSummaries)
Dim synthesisDoc = PdfDocument.FromFile(documentPaths(0))
Dim synthesisQuery As String = "Based on the quarterly summaries below, provide an annual synthesis:" & vbCrLf &
"Overall trends across quarters" & vbCrLf &
"Key achievements and challenges" & vbCrLf &
"Year-over-year patterns" & vbCrLf & vbCrLf &
combinedSummaries
Dim synthesis As String = Await synthesisDoc.Query(synthesisQuery)
Console.WriteLine(vbCrLf & "=== Annual Synthesis ===")
Console.WriteLine(synthesis)
File.WriteAllText("annual-synthesis.txt", synthesis)Ce modèle s'adapte efficacement à de grands ensembles de documents. En traitant les documents en parallèle et en gérant les résultats intermédiaires, vous pouvez analyser des centaines ou des milliers de documents tout en conservant une synthèse cohérente.
Génération d'un résumé exécutif
Les résumés exécutifs requièrent une approche différente de celle d'un résumé standard. Plutôt que de simplement condenser le contenu, un résumé doit identifier les informations les plus critiques pour l'entreprise, mettre en évidence les décisions ou recommandations clés et présenter les résultats dans un format adapté à l'examen par les dirigeants.
Le code utilise pdf.Query() avec une invite structurée demandant des décisions clés, des conclusions critiques, l'impact financier et une évaluation des risques dans un langage commercial.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/executive-summary.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
// Generate executive summary from strategic documents for C-suite leadership
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
var pdf = PdfDocument.FromFile("strategic-plan.pdf");
string executiveQuery = @"Create an executive summary for C-suite leadership. Include:
cisions Required:**
ny decisions needing executive approval
al Findings:**
5 most important findings (bullet points)
ial Impact:**
e/cost implications if mentioned
ssessment:**
riority risks identified
ended Actions:**
ate next steps
er 500 words. Use business language appropriate for board presentation.";
string executiveSummary = await pdf.Query(executiveQuery);
File.WriteAllText("executive-summary.txt", executiveSummary);
Console.WriteLine("Executive summary saved to executive-summary.txt");Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
' Generate executive summary from strategic documents for C-suite leadership
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
Dim pdf = PdfDocument.FromFile("strategic-plan.pdf")
Dim executiveQuery As String = "Create an executive summary for C-suite leadership. Include:
cisions Required:**
ny decisions needing executive approval
al Findings:**
5 most important findings (bullet points)
ial Impact:**
e/cost implications if mentioned
ssessment:**
riority risks identified
ended Actions:**
ate next steps
er 500 words. Use business language appropriate for board presentation."
Dim executiveSummary As String = Await pdf.Query(executiveQuery)
File.WriteAllText("executive-summary.txt", executiveSummary)
Console.WriteLine("Executive summary saved to executive-summary.txt")Le résumé qui en résulte donne la priorité aux informations exploitables plutôt qu'à une couverture exhaustive, en fournissant exactement ce dont les décideurs ont besoin sans les surcharger de détails.
Extraction intelligente de données
Extraire des données structurées vers JSON
L'une des applications les plus puissantes du traitement des PDF par l'IA est l'extraction de données structurées à partir de documents non structurés. La clé d'une extraction structurée réussie en 2026 est l'utilisation de schémas JSON avec des modes de sortie structurés. GPT-5 introduit des sorties structurées améliorées, tandis que Claude Sonnet 4.5 offre une orchestration d'outils améliorée pour une extraction de données fiable.
Entrée
Le code appelle pdf.Query() avec une invite de schéma JSON, puis utilise JsonSerializer.Deserialize() pour analyser et valider les données de facture extraites.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/extract-invoice-json.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System.Text.Json;
// Extract structured invoice data as JSON from PDF
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
var pdf = PdfDocument.FromFile("sample-invoice.pdf");
// Define JSON schema for extraction
string extractionQuery = @"Extract invoice data and return as JSON with this exact structure:
voiceNumber"": ""string"",
voiceDate"": ""YYYY-MM-DD"",
eDate"": ""YYYY-MM-DD"",
ndor"": {
""name"": ""string"",
""address"": ""string"",
""taxId"": ""string or null""
stomer"": {
""name"": ""string"",
""address"": ""string""
neItems"": [
{
""description"": ""string"",
""quantity"": number,
""unitPrice"": number,
""total"": number
}
btotal"": number,
xRate"": number,
xAmount"": number,
tal"": number,
rrency"": ""string""
NLY valid JSON, no additional text.";
string jsonResponse = await pdf.Query(extractionQuery);
// Parse and save JSON
try
{
var invoiceData = JsonSerializer.Deserialize<JsonElement>(jsonResponse);
string formattedJson = JsonSerializer.Serialize(invoiceData, new JsonSerializerOptions { WriteIndented = true });
Console.WriteLine("Extracted Invoice Data:");
Console.WriteLine(formattedJson);
File.WriteAllText("invoice-data.json", formattedJson);
}
catch (JsonException)
{
Console.WriteLine("Unable to parse JSON response");
File.WriteAllText("invoice-raw-response.txt", jsonResponse);
}Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.Text.Json
' Extract structured invoice data as JSON from PDF
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
Dim pdf = PdfDocument.FromFile("sample-invoice.pdf")
' Define JSON schema for extraction
Dim extractionQuery As String = "Extract invoice data and return as JSON with this exact structure:
voiceNumber"": ""string"",
voiceDate"": ""YYYY-MM-DD"",
eDate"": ""YYYY-MM-DD"",
ndor"": {
""name"": ""string"",
""address"": ""string"",
""taxId"": ""string or null""
stomer"": {
""name"": ""string"",
""address"": ""string""
neItems"": [
{
""description"": ""string"",
""quantity"": number,
""unitPrice"": number,
""total"": number
}
btotal"": number,
xRate"": number,
xAmount"": number,
tal"": number,
rrency"": ""string""
NLY valid JSON, no additional text."
Dim jsonResponse As String = Await pdf.QueryAsync(extractionQuery)
' Parse and save JSON
Try
Dim invoiceData = JsonSerializer.Deserialize(Of JsonElement)(jsonResponse)
Dim formattedJson As String = JsonSerializer.Serialize(invoiceData, New JsonSerializerOptions With {.WriteIndented = True})
Console.WriteLine("Extracted Invoice Data:")
Console.WriteLine(formattedJson)
File.WriteAllText("invoice-data.json", formattedJson)
Catch ex As JsonException
Console.WriteLine("Unable to parse JSON response")
File.WriteAllText("invoice-raw-response.txt", jsonResponse)
End TryCapture d'écran partielle du fichier JSON généré
Les modèles d'IA modernes de 2026 prennent en charge des modes de sortie structurés qui garantissent des réponses JSON valides conformes aux schémas fournis. Cela élimine la nécessité d'une gestion complexe des erreurs liées à des réponses mal formées.
Identification des clauses contractuelles
Les contrats juridiques contiennent des types de clauses spécifiques qui revêtent une importance particulière : les clauses de résiliation, les limitations de responsabilité, les exigences d'indemnisation, les cessions de propriété intellectuelle et les obligations de confidentialité. L'identification des clauses par l'IA permet d'automatiser cette analyse tout en conservant une grande précision.
Cet exemple utilise pdf.Query() avec un schéma JSON axé sur les clauses pour extraire le type de contrat, les parties, les dates critiques et les clauses individuelles avec les niveaux de risque.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/contract-clause-analysis.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System.Text.Json;
// Analyze contract clauses and identify key terms, risks, and critical dates
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
var pdf = PdfDocument.FromFile("contract.pdf");
// Define JSON schema for contract analysis
string clauseQuery = @"Analyze this contract and identify key clauses. Return JSON:
ntractType"": ""string"",
rties"": [""string""],
fectiveDate"": ""string"",
auses"": [
{
""type"": ""Termination|Liability|Indemnification|Confidentiality|IP|Payment|Warranty|Other"",
""title"": ""string"",
""summary"": ""string"",
""riskLevel"": ""Low|Medium|High"",
""keyTerms"": [""string""]
}
iticalDates"": [
{
""description"": ""string"",
""date"": ""string""
}
erallRiskAssessment"": ""Low|Medium|High"",
commendations"": [""string""]
: termination rights, liability caps, indemnification, IP ownership, confidentiality, payment terms.
NLY valid JSON.";
string analysisJson = await pdf.Query(clauseQuery);
try
{
var analysis = JsonSerializer.Deserialize<JsonElement>(analysisJson);
string formatted = JsonSerializer.Serialize(analysis, new JsonSerializerOptions { WriteIndented = true });
Console.WriteLine("Contract Clause Analysis:");
Console.WriteLine(formatted);
File.WriteAllText("contract-analysis.json", formatted);
// Display high-risk clauses
Console.WriteLine("\n=== High Risk Clauses ===");
foreach (var clause in analysis.GetProperty("clauses").EnumerateArray())
{
if (clause.GetProperty("riskLevel").GetString() == "High")
{
Console.WriteLine($"- {clause.GetProperty("type")}: {clause.GetProperty("summary")}");
}
}
}
catch (JsonException)
{
Console.WriteLine("Unable to parse contract analysis");
File.WriteAllText("contract-analysis-raw.txt", analysisJson);
}Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.Text.Json
' Analyze contract clauses and identify key terms, risks, and critical dates
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
Dim pdf = PdfDocument.FromFile("contract.pdf")
' Define JSON schema for contract analysis
Dim clauseQuery As String = "Analyze this contract and identify key clauses. Return JSON:
ntractType"": ""string"",
rties"": [""string""],
fectiveDate"": ""string"",
auses"": [
{
""type"": ""Termination|Liability|Indemnification|Confidentiality|IP|Payment|Warranty|Other"",
""title"": ""string"",
""summary"": ""string"",
""riskLevel"": ""Low|Medium|High"",
""keyTerms"": [""string""]
}
iticalDates"": [
{
""description"": ""string"",
""date"": ""string""
}
erallRiskAssessment"": ""Low|Medium|High"",
commendations"": [""string""]
: termination rights, liability caps, indemnification, IP ownership, confidentiality, payment terms.
NLY valid JSON."
Dim analysisJson As String = Await pdf.Query(clauseQuery)
Try
Dim analysis = JsonSerializer.Deserialize(Of JsonElement)(analysisJson)
Dim formatted As String = JsonSerializer.Serialize(analysis, New JsonSerializerOptions With {.WriteIndented = True})
Console.WriteLine("Contract Clause Analysis:")
Console.WriteLine(formatted)
File.WriteAllText("contract-analysis.json", formatted)
' Display high-risk clauses
Console.WriteLine(vbCrLf & "=== High Risk Clauses ===")
For Each clause In analysis.GetProperty("clauses").EnumerateArray()
If clause.GetProperty("riskLevel").GetString() = "High" Then
Console.WriteLine($"- {clause.GetProperty("type")}: {clause.GetProperty("summary")}")
End If
Next
Catch ex As JsonException
Console.WriteLine("Unable to parse contract analysis")
File.WriteAllText("contract-analysis-raw.txt", analysisJson)
End TryCette capacité transforme l'examen des contrats d'un processus séquentiel et manuel en un flux de travail automatisé et évolutif. Les équipes juridiques peuvent rapidement identifier les dispositions à haut risque dans des centaines de contrats.
Analyse de données financières
Les documents financiers contiennent des données quantitatives essentielles intégrées dans des récits et des tableaux complexes. L'analyse syntaxique alimentée par l'IA excelle dans les documents financiers parce qu'elle comprend le contexte : elle fait la distinction entre les résultats historiques et les projections, elle détermine si les chiffres sont exprimés en milliers ou en millions, et elle comprend les relations entre les différentes mesures.
Le code utilise pdf.Query() avec un schéma JSON financier pour extraire les données du compte de résultat, les indicateurs du bilan et les prévisions dans une sortie structurée.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/financial-data-extraction.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System.Text.Json;
// Extract financial metrics from annual reports and earnings documents
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
var pdf = PdfDocument.FromFile("annual-report.pdf");
// Define JSON schema for financial extraction (numbers in millions)
string financialQuery = @"Extract financial metrics from this document. Return JSON:
portPeriod"": ""string"",
mpany"": ""string"",
rrency"": ""string"",
comeStatement"": {
""revenue"": number,
""costOfRevenue"": number,
""grossProfit"": number,
""operatingExpenses"": number,
""operatingIncome"": number,
""netIncome"": number,
""eps"": number
lanceSheet"": {
""totalAssets"": number,
""totalLiabilities"": number,
""shareholdersEquity"": number,
""cash"": number,
""totalDebt"": number
yMetrics"": {
""revenueGrowthYoY"": ""string"",
""grossMargin"": ""string"",
""operatingMargin"": ""string"",
""netMargin"": ""string"",
""debtToEquity"": number
idance"": {
""nextQuarterRevenue"": ""string"",
""fullYearRevenue"": ""string"",
""notes"": ""string""
for unavailable data. Numbers in millions unless stated.
NLY valid JSON.";
string financialJson = await pdf.Query(financialQuery);
try
{
var financials = JsonSerializer.Deserialize<JsonElement>(financialJson);
string formatted = JsonSerializer.Serialize(financials, new JsonSerializerOptions { WriteIndented = true });
Console.WriteLine("Extracted Financial Data:");
Console.WriteLine(formatted);
File.WriteAllText("financial-data.json", formatted);
}
catch (JsonException)
{
Console.WriteLine("Unable to parse financial data");
File.WriteAllText("financial-raw.txt", financialJson);
}Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.Text.Json
' Extract financial metrics from annual reports and earnings documents
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
Dim pdf = PdfDocument.FromFile("annual-report.pdf")
' Define JSON schema for financial extraction (numbers in millions)
Dim financialQuery As String = "Extract financial metrics from this document. Return JSON:
portPeriod"": ""string"",
mpany"": ""string"",
rrency"": ""string"",
comeStatement"": {
""revenue"": number,
""costOfRevenue"": number,
""grossProfit"": number,
""operatingExpenses"": number,
""operatingIncome"": number,
""netIncome"": number,
""eps"": number
lanceSheet"": {
""totalAssets"": number,
""totalLiabilities"": number,
""shareholdersEquity"": number,
""cash"": number,
""totalDebt"": number
yMetrics"": {
""revenueGrowthYoY"": ""string"",
""grossMargin"": ""string"",
""operatingMargin"": ""string"",
""netMargin"": ""string"",
""debtToEquity"": number
idance"": {
""nextQuarterRevenue"": ""string"",
""fullYearRevenue"": ""string"",
""notes"": ""string""
for unavailable data. Numbers in millions unless stated.
NLY valid JSON."
Dim financialJson As String = Await pdf.Query(financialQuery)
Try
Dim financials = JsonSerializer.Deserialize(Of JsonElement)(financialJson)
Dim formatted As String = JsonSerializer.Serialize(financials, New JsonSerializerOptions With {.WriteIndented = True})
Console.WriteLine("Extracted Financial Data:")
Console.WriteLine(formatted)
File.WriteAllText("financial-data.json", formatted)
Catch ex As JsonException
Console.WriteLine("Unable to parse financial data")
File.WriteAllText("financial-raw.txt", financialJson)
End TryLes données structurées extraites peuvent alimenter directement des modèles financiers, des bases de données de séries chronologiques ou des plateformes d'analyse, ce qui permet un suivi automatisé des mesures sur l'ensemble des périodes de reporting.
Instructions d'extraction personnalisées
De nombreuses organisations ont des exigences uniques en matière d'extraction en fonction de leur domaine spécifique, des formats de documents ou des processus d'entreprise. L'intégration de l'IA d'IronPDF prend entièrement en charge les invites d'extraction personnalisées, ce qui vous permet de définir exactement quelles informations doivent être extraites et comment elles doivent être structurées.
Cet exemple illustre pdf.Query() avec une méthodologie d'extraction de schémas axée sur la recherche, les principaux résultats avec niveaux de confiance et les limites des articles universitaires.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/custom-research-extraction.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System.Text.Json;
// Extract structured research metadata from academic papers
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
var pdf = PdfDocument.FromFile("research-paper.pdf");
// Define JSON schema for research paper extraction
string researchQuery = @"Extract structured information from this research paper. Return JSON:
tle"": ""string"",
thors"": [""string""],
stitution"": ""string"",
blicationDate"": ""string"",
stract"": ""string"",
searchQuestion"": ""string"",
thodology"": {
""type"": ""Quantitative|Qualitative|Mixed Methods"",
""approach"": ""string"",
""sampleSize"": ""string"",
""dataCollection"": ""string""
yFindings"": [
{
""finding"": ""string"",
""significance"": ""string"",
""confidence"": ""High|Medium|Low""
}
mitations"": [""string""],
tureWork"": [""string""],
ywords"": [""string""]
extracting verifiable claims and noting uncertainty.
NLY valid JSON.";
string extractionResult = await pdf.Query(researchQuery);
try
{
var research = JsonSerializer.Deserialize<JsonElement>(extractionResult);
string formatted = JsonSerializer.Serialize(research, new JsonSerializerOptions { WriteIndented = true });
Console.WriteLine("Research Paper Extraction:");
Console.WriteLine(formatted);
File.WriteAllText("research-extraction.json", formatted);
// Display key findings with confidence levels
Console.WriteLine("\n=== Key Findings ===");
foreach (var finding in research.GetProperty("keyFindings").EnumerateArray())
{
string confidence = finding.GetProperty("confidence").GetString() ?? "Unknown";
Console.WriteLine($"[{confidence}] {finding.GetProperty("finding")}");
}
}
catch (JsonException)
{
Console.WriteLine("Unable to parse research extraction");
File.WriteAllText("research-raw.txt", extractionResult);
}Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.Text.Json
' Extract structured research metadata from academic papers
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
Dim pdf = PdfDocument.FromFile("research-paper.pdf")
' Define JSON schema for research paper extraction
Dim researchQuery As String = "Extract structured information from this research paper. Return JSON:
tle"": ""string"",
thors"": [""string""],
stitution"": ""string"",
blicationDate"": ""string"",
stract"": ""string"",
searchQuestion"": ""string"",
thodology"": {
""type"": ""Quantitative|Qualitative|Mixed Methods"",
""approach"": ""string"",
""sampleSize"": ""string"",
""dataCollection"": ""string""
yFindings"": [
{
""finding"": ""string"",
""significance"": ""string"",
""confidence"": ""High|Medium|Low""
}
mitations"": [""string""],
tureWork"": [""string""],
ywords"": [""string""]
extracting verifiable claims and noting uncertainty.
NLY valid JSON."
Dim extractionResult As String = Await pdf.Query(researchQuery)
Try
Dim research = JsonSerializer.Deserialize(Of JsonElement)(extractionResult)
Dim formatted As String = JsonSerializer.Serialize(research, New JsonSerializerOptions With {.WriteIndented = True})
Console.WriteLine("Research Paper Extraction:")
Console.WriteLine(formatted)
File.WriteAllText("research-extraction.json", formatted)
' Display key findings with confidence levels
Console.WriteLine(vbCrLf & "=== Key Findings ===")
For Each finding In research.GetProperty("keyFindings").EnumerateArray()
Dim confidence As String = finding.GetProperty("confidence").GetString() OrElse "Unknown"
Console.WriteLine($"[{confidence}] {finding.GetProperty("finding")}")
Next
Catch ex As JsonException
Console.WriteLine("Unable to parse research extraction")
File.WriteAllText("research-raw.txt", extractionResult)
End TryLes messages-guides personnalisés transforment l'extraction assistée par IA d'un outil générique en une solution spécialisée adaptée à vos besoins spécifiques.
Réponse aux questions sur les documents
Construction d'un système de questions-réponses en PDF
Les systèmes de réponse aux questions permettent aux utilisateurs d'interagir avec les documents PDF de manière conversationnelle, en posant des questions en langage naturel et en recevant des réponses précises et contextuelles. Le modèle de base consiste à extraire le texte du PDF, à le combiner avec la question de l'utilisateur dans une invite et à demander une réponse à l'IA.
Entrée
Le code appelle pdf.Memorize() pour indexer le document pour la recherche sémantique, puis entre dans une boucle interactive utilisant pdf.Query() pour répondre aux questions de l'utilisateur.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/pdf-question-answering.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
// Interactive Q&A system for querying PDF documents
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
var pdf = PdfDocument.FromFile("sample-legal-document.pdf");
// Memorize document to enable persistent querying
await pdf.Memorize();
Console.WriteLine("PDF Q&A System - Type 'exit' to quit\n");
Console.WriteLine($"Document loaded and memorized: {pdf.PageCount} pages\n");
// Interactive Q&A loop
while (true)
{
Console.Write("Your question: ");
string? question = Console.ReadLine();
if (string.IsNullOrWhiteSpace(question) || question.ToLower() == "exit")
break;
string answer = await pdf.Query(question);
Console.WriteLine($"\nAnswer: {answer}\n");
Console.WriteLine(new string('-', 50) + "\n");
}
Console.WriteLine("Q&A session ended.");Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
' Interactive Q&A system for querying PDF documents
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
Dim pdf = PdfDocument.FromFile("sample-legal-document.pdf")
' Memorize document to enable persistent querying
Await pdf.Memorize()
Console.WriteLine("PDF Q&A System - Type 'exit' to quit" & vbCrLf)
Console.WriteLine($"Document loaded and memorized: {pdf.PageCount} pages" & vbCrLf)
' Interactive Q&A loop
While True
Console.Write("Your question: ")
Dim question As String = Console.ReadLine()
If String.IsNullOrWhiteSpace(question) OrElse question.ToLower() = "exit" Then
Exit While
End If
Dim answer As String = Await pdf.Query(question)
Console.WriteLine($"{vbCrLf}Answer: {answer}{vbCrLf}")
Console.WriteLine(New String("-"c, 50) & vbCrLf)
End While
Console.WriteLine("Q&A session ended.")Sortie Console
La clé de l'efficacité des questions-réponses en 2026 est de contraindre l'IA à répondre en se basant uniquement sur le contenu du document. La méthode d'entraînement "safe completions" de GPT-5 et l'alignement amélioré de Claude Sonnet 4.5 réduisent considérablement les taux d'hallucination.
Découpage de longs documents pour les fenêtres contextuelles
La plupart des documents du monde réel dépassent les fenêtres contextuelles de l'IA. Des stratégies de découpage efficaces sont essentielles pour le traitement de ces documents. Le découpage consiste à diviser les documents en segments suffisamment petits pour tenir dans des fenêtres contextuelles tout en préservant la cohérence sémantique.
Ce code itère sur pdf.Pages, créant des objets DocumentChunk avec des maxChunkTokens et overlapTokens configurables pour la continuité du contexte.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/semantic-document-chunking.csusing IronPdf;
// Split long documents into overlapping chunks for RAG systems
var pdf = PdfDocument.FromFile("long-document.pdf");
// Chunking configuration
int maxChunkTokens = 4000; // Leave room for prompts and responses
int overlapTokens = 200; // Overlap for context continuity
int approxCharsPerToken = 4; // Rough estimate for tokenization
int maxChunkChars = maxChunkTokens * approxCharsPerToken;
int overlapChars = overlapTokens * approxCharsPerToken;
var chunks = new List<DocumentChunk>();
var currentChunk = new System.Text.StringBuilder();
int chunkStartPage = 1;
int currentPage = 1;
for (int i = 0; i < pdf.PageCount; i++)
{
string pageText = pdf.Pages[i].Text;
currentPage = i + 1;
if (currentChunk.Length + pageText.Length > maxChunkChars && currentChunk.Length > 0)
{
chunks.Add(new DocumentChunk
{
Text = currentChunk.ToString(),
StartPage = chunkStartPage,
EndPage = currentPage - 1,
ChunkIndex = chunks.Count
});
// Create overlap with previous chunk for continuity
string overlap = currentChunk.Length > overlapChars
? currentChunk.ToString().Substring(currentChunk.Length - overlapChars)
: currentChunk.ToString();
currentChunk.Clear();
currentChunk.Append(overlap);
chunkStartPage = currentPage - 1;
}
currentChunk.AppendLine($"\n--- Page {currentPage} ---\n");
currentChunk.Append(pageText);
}
if (currentChunk.Length > 0)
{
chunks.Add(new DocumentChunk
{
Text = currentChunk.ToString(),
StartPage = chunkStartPage,
EndPage = currentPage,
ChunkIndex = chunks.Count
});
}
Console.WriteLine($"Document chunked into {chunks.Count} segments");
foreach (var chunk in chunks)
{
Console.WriteLine($" Chunk {chunk.ChunkIndex + 1}: Pages {chunk.StartPage}-{chunk.EndPage} ({chunk.Text.Length} chars)");
}
// Save chunk metadata for RAG indexing
File.WriteAllText("chunks-metadata.json", System.Text.Json.JsonSerializer.Serialize(
chunks.Select(c => new { c.ChunkIndex, c.StartPage, c.EndPage, Length = c.Text.Length }),
new System.Text.Json.JsonSerializerOptions { WriteIndented = true }
));
ic class DocumentChunk
public string Text { get; set; } = "";
public int StartPage { get; set; }
public int EndPage { get; set; }
public int ChunkIndex { get; set; }Imports IronPdf
Imports System.IO
Imports System.Text
Imports System.Text.Json
' Split long documents into overlapping chunks for RAG systems
Dim pdf = PdfDocument.FromFile("long-document.pdf")
' Chunking configuration
Dim maxChunkTokens As Integer = 4000 ' Leave room for prompts and responses
Dim overlapTokens As Integer = 200 ' Overlap for context continuity
Dim approxCharsPerToken As Integer = 4 ' Rough estimate for tokenization
Dim maxChunkChars As Integer = maxChunkTokens * approxCharsPerToken
Dim overlapChars As Integer = overlapTokens * approxCharsPerToken
Dim chunks As New List(Of DocumentChunk)()
Dim currentChunk As New StringBuilder()
Dim chunkStartPage As Integer = 1
Dim currentPage As Integer = 1
For i As Integer = 0 To pdf.PageCount - 1
Dim pageText As String = pdf.Pages(i).Text
currentPage = i + 1
If currentChunk.Length + pageText.Length > maxChunkChars AndAlso currentChunk.Length > 0 Then
chunks.Add(New DocumentChunk With {
.Text = currentChunk.ToString(),
.StartPage = chunkStartPage,
.EndPage = currentPage - 1,
.ChunkIndex = chunks.Count
})
' Create overlap with previous chunk for continuity
Dim overlap As String = If(currentChunk.Length > overlapChars,
currentChunk.ToString().Substring(currentChunk.Length - overlapChars),
currentChunk.ToString())
currentChunk.Clear()
currentChunk.Append(overlap)
chunkStartPage = currentPage - 1
End If
currentChunk.AppendLine(vbCrLf & "--- Page " & currentPage & " ---" & vbCrLf)
currentChunk.Append(pageText)
Next
If currentChunk.Length > 0 Then
chunks.Add(New DocumentChunk With {
.Text = currentChunk.ToString(),
.StartPage = chunkStartPage,
.EndPage = currentPage,
.ChunkIndex = chunks.Count
})
End If
Console.WriteLine($"Document chunked into {chunks.Count} segments")
For Each chunk In chunks
Console.WriteLine($" Chunk {chunk.ChunkIndex + 1}: Pages {chunk.StartPage}-{chunk.EndPage} ({chunk.Text.Length} chars)")
Next
' Save chunk metadata for RAG indexing
File.WriteAllText("chunks-metadata.json", JsonSerializer.Serialize(
chunks.Select(Function(c) New With {.ChunkIndex = c.ChunkIndex, .StartPage = c.StartPage, .EndPage = c.EndPage, .Length = c.Text.Length}),
New JsonSerializerOptions With {.WriteIndented = True}
))
Public Class DocumentChunk
Public Property Text As String = ""
Public Property StartPage As Integer
Public Property EndPage As Integer
Public Property ChunkIndex As Integer
End Class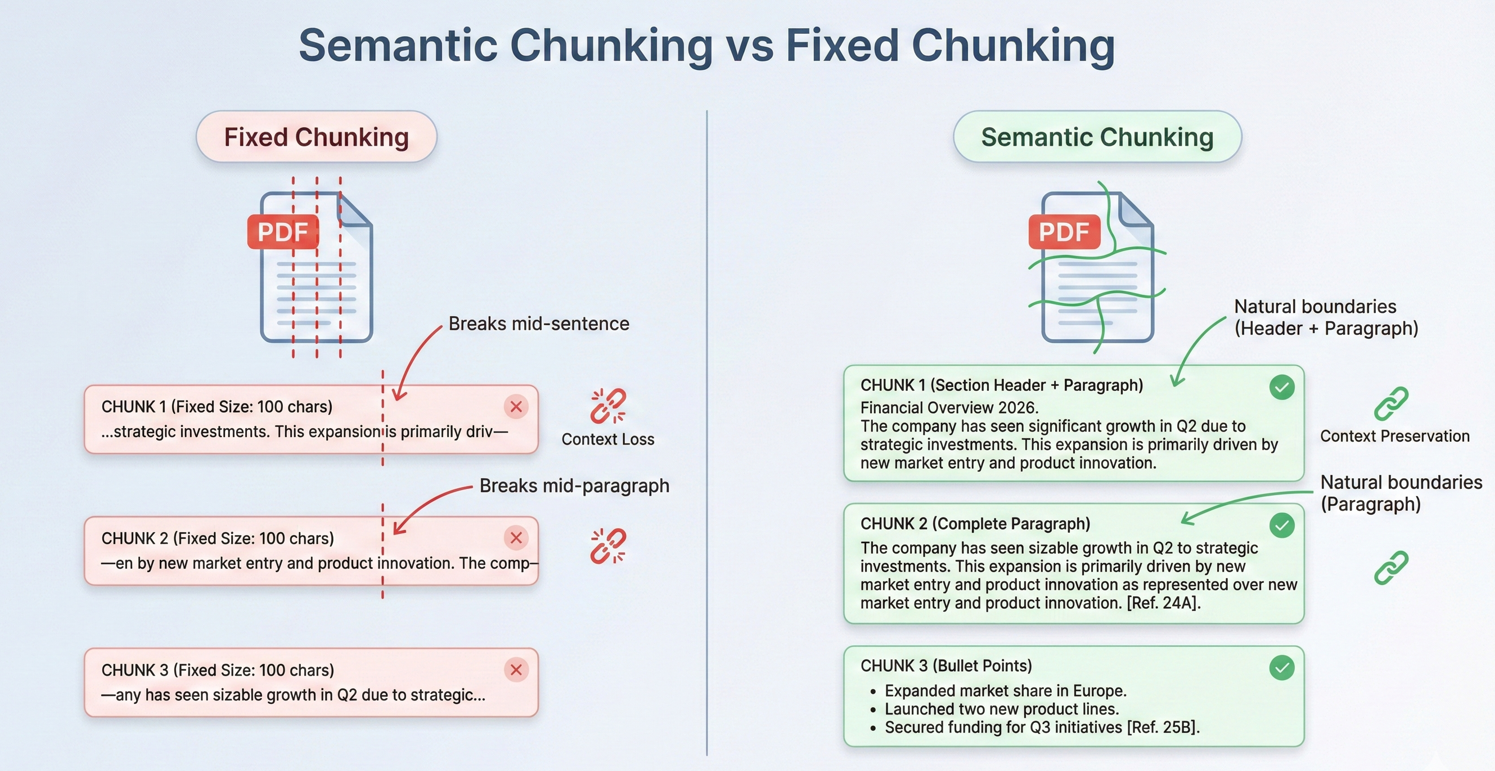
Les morceaux qui se chevauchent assurent une continuité au-delà des frontières, garantissant que l'IA dispose d'un contexte suffisant même lorsque les informations pertinentes s'étendent au-delà des limites des morceaux.
Modèles RAG (génération augmentée par récupération)
La génération assistée par récupération représente un modèle puissant pour l'analyse de documents alimentée par l'IA en 2026. Plutôt que d'alimenter l'IA avec des documents entiers, les systèmes RAG ne récupèrent d'abord que les parties pertinentes pour une requête donnée, puis utilisent ces parties comme contexte pour générer des réponses.
Le flux de travail RAG comporte trois phases principales : la préparation du document (découpage et création d'enchâssements), la récupération (recherche de morceaux pertinents) et la génération (utilisation des morceaux récupérés comme contexte pour les réponses de l'IA).
Le code indexe plusieurs PDF en appelant pdf.Memorize() sur chacun, puis utilise pdf.Query() pour récupérer les réponses de la mémoire de document combinée.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/rag-system-implementation.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
// Retrieval-Augmented Generation (RAG) system for querying across multiple indexed documents
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
// Index all documents in folder
string[] documentPaths = Directory.GetFiles("documents/", "*.pdf");
Console.WriteLine($"Indexing {documentPaths.Length} documents...\n");
// Memorize each document (creates embeddings for retrieval)
foreach (string path in documentPaths)
{
var pdf = PdfDocument.FromFile(path);
await pdf.Memorize();
Console.WriteLine($"Indexed: {Path.GetFileName(path)} ({pdf.PageCount} pages)");
}
Console.WriteLine("\n=== RAG System Ready ===\n");
// Query across all indexed documents
string query = "What are the key compliance requirements for data retention?";
Console.WriteLine($"Query: {query}\n");
var searchPdf = PdfDocument.FromFile(documentPaths[0]);
string answer = await searchPdf.Query(query);
Console.WriteLine($"Answer: {answer}");
// Interactive query loop
Console.WriteLine("\n--- Enter questions (type 'exit' to quit) ---\n");
while (true)
{
Console.Write("Question: ");
string? userQuery = Console.ReadLine();
if (string.IsNullOrWhiteSpace(userQuery) || userQuery.ToLower() == "exit")
break;
string response = await searchPdf.Query(userQuery);
Console.WriteLine($"\nAnswer: {response}\n");
}Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.IO
' Retrieval-Augmented Generation (RAG) system for querying across multiple indexed documents
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
' Index all documents in folder
Dim documentPaths As String() = Directory.GetFiles("documents/", "*.pdf")
Console.WriteLine($"Indexing {documentPaths.Length} documents..." & vbCrLf)
' Memorize each document (creates embeddings for retrieval)
For Each path As String In documentPaths
Dim pdf = PdfDocument.FromFile(path)
Await pdf.Memorize()
Console.WriteLine($"Indexed: {Path.GetFileName(path)} ({pdf.PageCount} pages)")
Next
Console.WriteLine(vbCrLf & "=== RAG System Ready ===" & vbCrLf)
' Query across all indexed documents
Dim query As String = "What are the key compliance requirements for data retention?"
Console.WriteLine($"Query: {query}" & vbCrLf)
Dim searchPdf = PdfDocument.FromFile(documentPaths(0))
Dim answer As String = Await searchPdf.Query(query)
Console.WriteLine($"Answer: {answer}")
' Interactive query loop
Console.WriteLine(vbCrLf & "--- Enter questions (type 'exit' to quit) ---" & vbCrLf)
While True
Console.Write("Question: ")
Dim userQuery As String = Console.ReadLine()
If String.IsNullOrWhiteSpace(userQuery) OrElse userQuery.ToLower() = "exit" Then
Exit While
End If
Dim response As String = Await searchPdf.Query(userQuery)
Console.WriteLine(vbCrLf & $"Answer: {response}" & vbCrLf)
End WhileLes systèmes RAG excellent dans le traitement de grandes collections de documents - bases de données d'affaires juridiques, bibliothèques de documentation technique, archives de recherche. En ne récupérant que les parties pertinentes, ils maintiennent la qualité de la réponse tout en s'adaptant à des tailles de document effectivement illimitées.
Citer des sources à partir de pages PDF
Pour les applications professionnelles, les réponses de l'IA doivent être vérifiables. L'approche de la citation implique le maintien de métadonnées sur les origines des morceaux pendant le découpage et la récupération. Chaque morceau stocke non seulement le contenu textuel, mais aussi les numéros de page source, les en-têtes de section et la position dans le document.
Entrée
Le code utilise pdf.Query() avec des instructions de citation, puis appelle ExtractCitedPages() avec des expressions régulières pour analyser les références de page et vérifier les sources en utilisant pdf.Pages[pageNum - 1].Text.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/answer-with-citations.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System.Text.RegularExpressions;
// Answer questions with page citations and source verification
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
var pdf = PdfDocument.FromFile("sample-legal-document.pdf");
await pdf.Memorize();
string question = "What are the termination conditions in this agreement?";
// Request citations in query
string citationQuery = $@"{question}
T: Include specific page citations in your answer using the format (Page X) or (Pages X-Y).
e information that appears in the document.";
string answerWithCitations = await pdf.Query(citationQuery);
Console.WriteLine("Question: " + question);
Console.WriteLine("\nAnswer with Citations:");
Console.WriteLine(answerWithCitations);
// Extract cited page numbers using regex
var citedPages = ExtractCitedPages(answerWithCitations);
Console.WriteLine($"\nCited pages: {string.Join(", ", citedPages)}");
// Verify citations with page excerpts
Console.WriteLine("\n=== Source Verification ===");
foreach (int pageNum in citedPages.Take(3))
{
if (pageNum <= pdf.PageCount && pageNum > 0)
{
string pageText = pdf.Pages[pageNum - 1].Text;
string excerpt = pageText.Length > 200 ? pageText.Substring(0, 200) + "..." : pageText;
Console.WriteLine($"\nPage {pageNum} excerpt:\n{excerpt}");
}
}
// Extract page numbers from citation format (Page X) or (Pages X-Y)
List<int> ExtractCitedPages(string text)
{
var pages = new HashSet<int>();
var matches = Regex.Matches(text, @"\(Pages?\s*(\d+)(?:\s*-\s*(\d+))?\)", RegexOptions.IgnoreCase);
foreach (Match match in matches)
{
int startPage = int.Parse(match.Groups[1].Value);
pages.Add(startPage);
if (match.Groups[2].Success)
{
int endPage = int.Parse(match.Groups[2].Value);
for (int p = startPage; p <= endPage; p++)
pages.Add(p);
}
}
return pages.OrderBy(p => p).ToList();
}Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.Text.RegularExpressions
' Answer questions with page citations and source verification
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
Dim pdf = PdfDocument.FromFile("sample-legal-document.pdf")
Await pdf.Memorize()
Dim question As String = "What are the termination conditions in this agreement?"
' Request citations in query
Dim citationQuery As String = $"{question}
T: Include specific page citations in your answer using the format (Page X) or (Pages X-Y).
e information that appears in the document."
Dim answerWithCitations As String = Await pdf.Query(citationQuery)
Console.WriteLine("Question: " & question)
Console.WriteLine(vbCrLf & "Answer with Citations:")
Console.WriteLine(answerWithCitations)
' Extract cited page numbers using regex
Dim citedPages = ExtractCitedPages(answerWithCitations)
Console.WriteLine(vbCrLf & "Cited pages: " & String.Join(", ", citedPages))
' Verify citations with page excerpts
Console.WriteLine(vbCrLf & "=== Source Verification ===")
For Each pageNum As Integer In citedPages.Take(3)
If pageNum <= pdf.PageCount AndAlso pageNum > 0 Then
Dim pageText As String = pdf.Pages(pageNum - 1).Text
Dim excerpt As String = If(pageText.Length > 200, pageText.Substring(0, 200) & "...", pageText)
Console.WriteLine(vbCrLf & "Page " & pageNum & " excerpt:" & vbCrLf & excerpt)
End If
Next
' Extract page numbers from citation format (Page X) or (Pages X-Y)
Function ExtractCitedPages(ByVal text As String) As List(Of Integer)
Dim pages = New HashSet(Of Integer)()
Dim matches = Regex.Matches(text, "\((Pages?)\s*(\d+)(?:\s*-\s*(\d+))?\)", RegexOptions.IgnoreCase)
For Each match As Match In matches
Dim startPage As Integer = Integer.Parse(match.Groups(2).Value)
pages.Add(startPage)
If match.Groups(3).Success Then
Dim endPage As Integer = Integer.Parse(match.Groups(3).Value)
For p As Integer = startPage To endPage
pages.Add(p)
Next
End If
Next
Return pages.OrderBy(Function(p) p).ToList()
End FunctionSortie Console
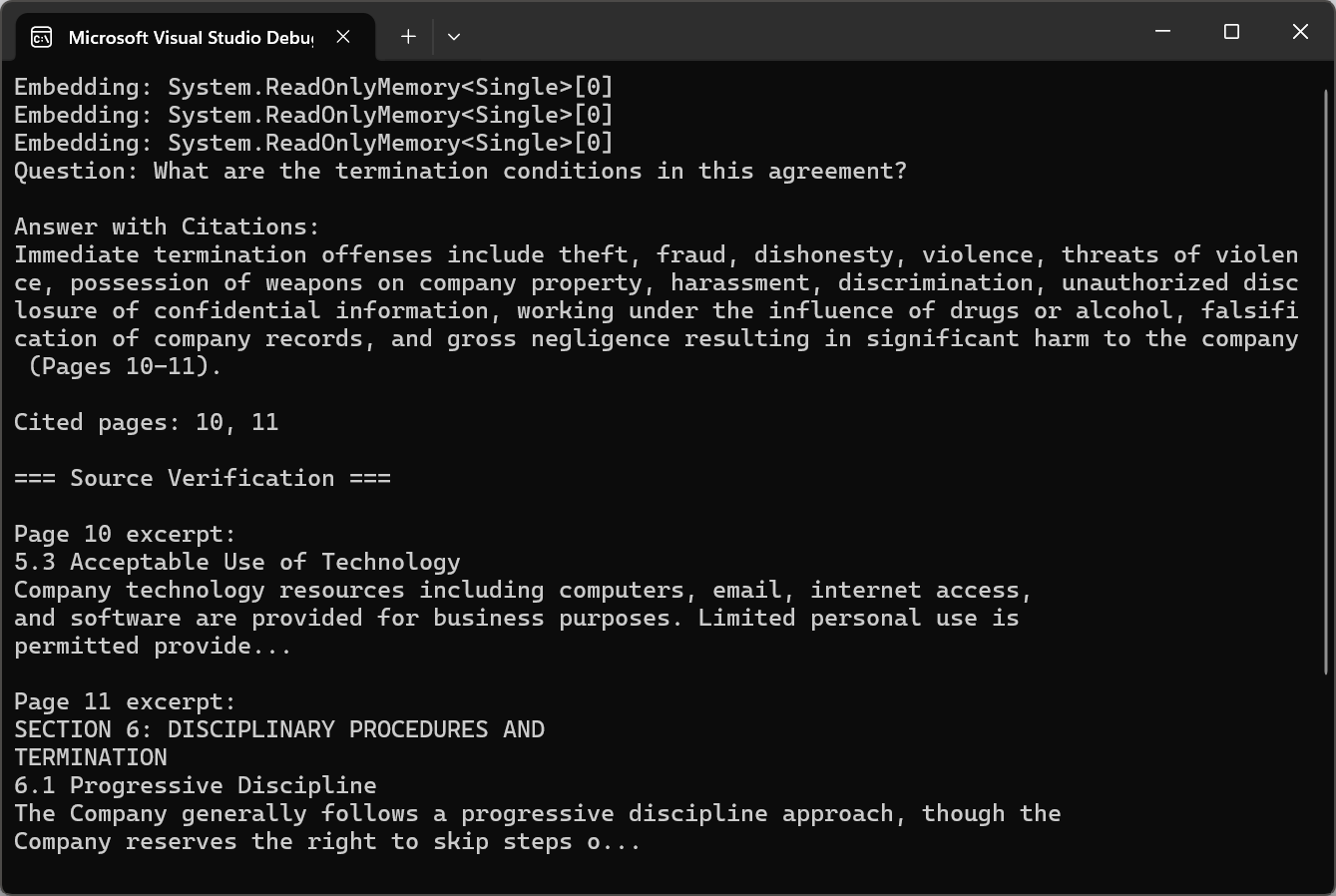
Les citations transforment les réponses générées par l'IA en informations transparentes et vérifiables. Les utilisateurs peuvent consulter le matériel source pour valider les réponses et renforcer leur confiance dans l'analyse assistée par l'IA.
Traitement par lots de l'IA
Traiter des bibliothèques de documents à grande échelle
Le traitement des documents d'entreprise implique souvent des milliers ou des millions de PDF. La parallélisation est à la base du traitement par lots évolutif. IronPdf est à l'abri des threads, ce qui permet un traitement simultané des PDF sans interférence.
Ce code utilise SemaphoreSlim avec maxConcurrency configurable pour traiter les PDF en parallèle, en appelant pdf.Summarize() sur chacun tout en suivant les résultats dans un ConcurrentBag.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/batch-document-processing.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System;
using System.Collections.Concurrent;
using System.Text;
// Process multiple documents in parallel with rate limiting
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
// Configure parallel processing with rate limiting
int maxConcurrency = 3;
string inputFolder = "documents/";
string outputFolder = "summaries/";
Directory.CreateDirectory(outputFolder);
string[] pdfFiles = Directory.GetFiles(inputFolder, "*.pdf");
Console.WriteLine($"Processing {pdfFiles.Length} documents...\n");
var results = new ConcurrentBag<ProcessingResult>();
var semaphore = new SemaphoreSlim(maxConcurrency);
var tasks = pdfFiles.Select(async filePath =>
{
await semaphore.WaitAsync();
var result = new ProcessingResult { FilePath = filePath };
try
{
var stopwatch = System.Diagnostics.Stopwatch.StartNew();
var pdf = PdfDocument.FromFile(filePath);
string summary = await pdf.Summarize();
string outputPath = Path.Combine(outputFolder,
Path.GetFileNameWithoutExtension(filePath) + "-summary.txt");
await File.WriteAllTextAsync(outputPath, summary);
stopwatch.Stop();
result.Success = true;
result.ProcessingTime = stopwatch.Elapsed;
result.OutputPath = outputPath;
Console.WriteLine($"[OK] {Path.GetFileName(filePath)} ({stopwatch.ElapsedMilliseconds}ms)");
}
catch (Exception ex)
{
result.Success = false;
result.ErrorMessage = ex.Message;
Console.WriteLine($"[ERROR] {Path.GetFileName(filePath)}: {ex.Message}");
}
finally
{
semaphore.Release();
results.Add(result);
}
}).ToArray();
await Task.WhenAll(tasks);
// Generate processing report
var successful = results.Where(r => r.Success).ToList();
var failed = results.Where(r => !r.Success).ToList();
var report = new StringBuilder();
report.AppendLine("=== Batch Processing Report ===");
report.AppendLine($"Successful: {successful.Count}");
report.AppendLine($"Failed: {failed.Count}");
if (successful.Any())
{
var avgTime = TimeSpan.FromMilliseconds(successful.Average(r => r.ProcessingTime.TotalMilliseconds));
report.AppendLine($"Average processing time: {avgTime.TotalSeconds:F1}s");
}
if (failed.Any())
{
report.AppendLine("\nFailed documents:");
foreach (var fail in failed)
report.AppendLine($" - {Path.GetFileName(fail.FilePath)}: {fail.ErrorMessage}");
}
string reportText = report.ToString();
Console.WriteLine($"\n{reportText}");
File.WriteAllText(Path.Combine(outputFolder, "processing-report.txt"), reportText);
s ProcessingResult
public string FilePath { get; set; } = "";
public bool Success { get; set; }
public TimeSpan ProcessingTime { get; set; }
public string OutputPath { get; set; } = "";
public string ErrorMessage { get; set; } = "";Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System
Imports System.Collections.Concurrent
Imports System.Text
Imports System.IO
Imports System.Linq
Imports System.Threading
Imports System.Threading.Tasks
' Process multiple documents in parallel with rate limiting
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
' Configure parallel processing with rate limiting
Dim maxConcurrency As Integer = 3
Dim inputFolder As String = "documents/"
Dim outputFolder As String = "summaries/"
Directory.CreateDirectory(outputFolder)
Dim pdfFiles As String() = Directory.GetFiles(inputFolder, "*.pdf")
Console.WriteLine($"Processing {pdfFiles.Length} documents...{vbCrLf}")
Dim results = New ConcurrentBag(Of ProcessingResult)()
Dim semaphore = New SemaphoreSlim(maxConcurrency)
Dim tasks = pdfFiles.Select(Async Function(filePath)
Await semaphore.WaitAsync()
Dim result = New ProcessingResult With {.FilePath = filePath}
Try
Dim stopwatch = System.Diagnostics.Stopwatch.StartNew()
Dim pdf = PdfDocument.FromFile(filePath)
Dim summary As String = Await pdf.Summarize()
Dim outputPath = Path.Combine(outputFolder, Path.GetFileNameWithoutExtension(filePath) & "-summary.txt")
Await File.WriteAllTextAsync(outputPath, summary)
stopwatch.Stop()
result.Success = True
result.ProcessingTime = stopwatch.Elapsed
result.OutputPath = outputPath
Console.WriteLine($"[OK] {Path.GetFileName(filePath)} ({stopwatch.ElapsedMilliseconds}ms)")
Catch ex As Exception
result.Success = False
result.ErrorMessage = ex.Message
Console.WriteLine($"[ERROR] {Path.GetFileName(filePath)}: {ex.Message}")
Finally
semaphore.Release()
results.Add(result)
End Try
End Function).ToArray()
Await Task.WhenAll(tasks)
' Generate processing report
Dim successful = results.Where(Function(r) r.Success).ToList()
Dim failed = results.Where(Function(r) Not r.Success).ToList()
Dim report = New StringBuilder()
report.AppendLine("=== Batch Processing Report ===")
report.AppendLine($"Successful: {successful.Count}")
report.AppendLine($"Failed: {failed.Count}")
If successful.Any() Then
Dim avgTime = TimeSpan.FromMilliseconds(successful.Average(Function(r) r.ProcessingTime.TotalMilliseconds))
report.AppendLine($"Average processing time: {avgTime.TotalSeconds:F1}s")
End If
If failed.Any() Then
report.AppendLine($"{vbCrLf}Failed documents:")
For Each fail In failed
report.AppendLine($" - {Path.GetFileName(fail.FilePath)}: {fail.ErrorMessage}")
Next
End If
Dim reportText As String = report.ToString()
Console.WriteLine($"{vbCrLf}{reportText}")
File.WriteAllText(Path.Combine(outputFolder, "processing-report.txt"), reportText)
Public Class ProcessingResult
Public Property FilePath As String = ""
Public Property Success As Boolean
Public Property ProcessingTime As TimeSpan
Public Property OutputPath As String = ""
Public Property ErrorMessage As String = ""
End ClassUne gestion robuste des erreurs est essentielle à l'échelle. Les systèmes de production mettent en œuvre une logique de réessai avec un backoff exponentiel, une journalisation distincte des erreurs pour les documents qui échouent et un traitement qui peut être repris.
Gestion des coûts et utilisation des jetons
Les coûts de l'API AI sont généralement facturés par jeton. En 2026, le prix du GPT-5 est de 1,25 $ par million de jetons d'entrée et de 10 $ par million de jetons de sortie, tandis que le prix du Claude Sonnet 4.5 est de 3 $ par million de jetons d'entrée et de 15 $ par million de jetons de sortie. La principale stratégie d'optimisation des coûts consiste à minimiser l'utilisation inutile de jetons.
L'API Batch d'OpenAI offre des réductions de 50 % sur le coût des jetons en échange de délais de traitement plus longs (jusqu'à 24 heures). Pour le traitement de nuit ou l'analyse périodique, le traitement par lots permet de réaliser des économies substantielles.
Le code extrait le texte à l'aide de pdf.ExtractAllText(), crée des requêtes par lots JSONL, télécharge via HttpClient vers le point de terminaison des fichiers OpenAI et soumet à l'API par lots.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/batch-api-processing.csusing IronPdf;
using System.Text.Json;
using System.Net.Http.Headers;
// Use OpenAI Batch API for 50% cost savings on large-scale document processing
string openAiApiKey = "your-openai-api-key";
string inputFolder = "documents/";
// Prepare batch requests in JSONL format
var batchRequests = new List<string>();
string[] pdfFiles = Directory.GetFiles(inputFolder, "*.pdf");
Console.WriteLine($"Preparing batch for {pdfFiles.Length} documents...\n");
foreach (string filePath in pdfFiles)
{
var pdf = PdfDocument.FromFile(filePath);
string pdfText = pdf.ExtractAllText();
// Truncate to stay within batch API limits
if (pdfText.Length > 100000)
pdfText = pdfText.Substring(0, 100000) + "\n[Truncated...]";
var request = new
{
custom_id = Path.GetFileNameWithoutExtension(filePath),
method = "POST",
url = "/v1/chat/completions",
body = new
{
model = "gpt-4o",
messages = new[]
{
new { role = "system", content = "Summarize the following document concisely." },
new { role = "user", content = pdfText }
},
max_tokens = 1000
}
};
batchRequests.Add(JsonSerializer.Serialize(request));
}
// Create JSONL file
string batchFilePath = "batch-requests.jsonl";
File.WriteAllLines(batchFilePath, batchRequests);
Console.WriteLine($"Created batch file with {batchRequests.Count} requests");
// Upload file to OpenAI
using var httpClient = new HttpClient();
httpClient.DefaultRequestHeaders.Authorization = new AuthenticationHeaderValue("Bearer", openAiApiKey);
using var fileContent = new MultipartFormDataContent();
fileContent.Add(new ByteArrayContent(File.ReadAllBytes(batchFilePath)), "file", "batch-requests.jsonl");
fileContent.Add(new StringContent("batch"), "purpose");
var uploadResponse = await httpClient.PostAsync("https://api.openai.com/v1/files", fileContent);
var uploadResult = JsonSerializer.Deserialize<JsonElement>(await uploadResponse.Content.ReadAsStringAsync());
string fileId = uploadResult.GetProperty("id").GetString()!;
Console.WriteLine($"Uploaded file: {fileId}");
// Create batch job (24-hour completion window for 50% discount)
var batchJobRequest = new
{
input_file_id = fileId,
endpoint = "/v1/chat/completions",
completion_window = "24h"
};
var batchResponse = await httpClient.PostAsync(
"https://api.openai.com/v1/batches",
new StringContent(JsonSerializer.Serialize(batchJobRequest), System.Text.Encoding.UTF8, "application/json")
);
var batchResult = JsonSerializer.Deserialize<JsonElement>(await batchResponse.Content.ReadAsStringAsync());
string batchId = batchResult.GetProperty("id").GetString()!;
Console.WriteLine($"\nBatch job created: {batchId}");
Console.WriteLine("Job will complete within 24 hours");
Console.WriteLine($"Check status: GET https://api.openai.com/v1/batches/{batchId}");
File.WriteAllText("batch-job-id.txt", batchId);
Console.WriteLine("\nBatch ID saved to batch-job-id.txt");Imports IronPdf
Imports System.Text.Json
Imports System.Net.Http.Headers
' Use OpenAI Batch API for 50% cost savings on large-scale document processing
Dim openAiApiKey As String = "your-openai-api-key"
Dim inputFolder As String = "documents/"
' Prepare batch requests in JSONL format
Dim batchRequests As New List(Of String)()
Dim pdfFiles As String() = Directory.GetFiles(inputFolder, "*.pdf")
Console.WriteLine($"Preparing batch for {pdfFiles.Length} documents..." & vbCrLf)
For Each filePath As String In pdfFiles
Dim pdf = PdfDocument.FromFile(filePath)
Dim pdfText As String = pdf.ExtractAllText()
' Truncate to stay within batch API limits
If pdfText.Length > 100000 Then
pdfText = pdfText.Substring(0, 100000) & vbCrLf & "[Truncated...]"
End If
Dim request = New With {
.custom_id = Path.GetFileNameWithoutExtension(filePath),
.method = "POST",
.url = "/v1/chat/completions",
.body = New With {
.model = "gpt-4o",
.messages = New Object() {
New With {.role = "system", .content = "Summarize the following document concisely."},
New With {.role = "user", .content = pdfText}
},
.max_tokens = 1000
}
}
batchRequests.Add(JsonSerializer.Serialize(request))
Next
' Create JSONL file
Dim batchFilePath As String = "batch-requests.jsonl"
File.WriteAllLines(batchFilePath, batchRequests)
Console.WriteLine($"Created batch file with {batchRequests.Count} requests")
' Upload file to OpenAI
Using httpClient As New HttpClient()
httpClient.DefaultRequestHeaders.Authorization = New AuthenticationHeaderValue("Bearer", openAiApiKey)
Using fileContent As New MultipartFormDataContent()
fileContent.Add(New ByteArrayContent(File.ReadAllBytes(batchFilePath)), "file", "batch-requests.jsonl")
fileContent.Add(New StringContent("batch"), "purpose")
Dim uploadResponse = Await httpClient.PostAsync("https://api.openai.com/v1/files", fileContent)
Dim uploadResult = JsonSerializer.Deserialize(Of JsonElement)(Await uploadResponse.Content.ReadAsStringAsync())
Dim fileId As String = uploadResult.GetProperty("id").GetString()
Console.WriteLine($"Uploaded file: {fileId}")
' Create batch job (24-hour completion window for 50% discount)
Dim batchJobRequest = New With {
.input_file_id = fileId,
.endpoint = "/v1/chat/completions",
.completion_window = "24h"
}
Dim batchResponse = Await httpClient.PostAsync(
"https://api.openai.com/v1/batches",
New StringContent(JsonSerializer.Serialize(batchJobRequest), System.Text.Encoding.UTF8, "application/json")
)
Dim batchResult = JsonSerializer.Deserialize(Of JsonElement)(Await batchResponse.Content.ReadAsStringAsync())
Dim batchId As String = batchResult.GetProperty("id").GetString()
Console.WriteLine(vbCrLf & $"Batch job created: {batchId}")
Console.WriteLine("Job will complete within 24 hours")
Console.WriteLine($"Check status: GET https://api.openai.com/v1/batches/{batchId}")
File.WriteAllText("batch-job-id.txt", batchId)
Console.WriteLine(vbCrLf & "Batch ID saved to batch-job-id.txt")
End Using
End UsingIl est essentiel de contrôler l'utilisation des jetons dans la production. De nombreuses organisations découvrent que 80 % de leurs documents peuvent être traités avec des modèles plus petits et moins chers, réservant les modèles coûteux aux cas complexes.
Mise en cache et traitement incrémental
Pour les collections de documents qui sont mises à jour de manière incrémentielle, des stratégies intelligentes de mise en cache et de traitement incrémentiel réduisent considérablement les coûts. La mise en cache au niveau du document stocke les résultats avec un hachage du PDF source, évitant ainsi le retraitement inutile de documents inchangés.
La classe DocumentCacheManager utilise ComputeFileHash() avec SHA256 pour détecter les changements, stockant les résultats dans des objets CacheEntry avec des horodatages LastAccessed.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/incremental-caching.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System;
using System.Collections.Generic;
using System.Security.Cryptography;
using System.Text.Json;
// Cache AI processing results using file hashes to avoid reprocessing unchanged documents
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
// Configure caching
string cacheFolder = "ai-cache/";
string documentsFolder = "documents/";
Directory.CreateDirectory(cacheFolder);
var cacheManager = new DocumentCacheManager(cacheFolder);
// Process documents with caching
string[] pdfFiles = Directory.GetFiles(documentsFolder, "*.pdf");
int cached = 0, processed = 0;
foreach (string filePath in pdfFiles)
{
string fileName = Path.GetFileName(filePath);
string fileHash = cacheManager.ComputeFileHash(filePath);
var cachedResult = cacheManager.GetCachedResult(fileName, fileHash);
if (cachedResult != null)
{
Console.WriteLine($"[CACHE HIT] {fileName}");
cached++;
continue;
}
Console.WriteLine($"[PROCESSING] {fileName}");
var pdf = PdfDocument.FromFile(filePath);
string summary = await pdf.Summarize();
cacheManager.CacheResult(fileName, fileHash, summary);
processed++;
}
Console.WriteLine($"\nProcessing complete: {cached} cached, {processed} newly processed");
Console.WriteLine($"Cost savings: {(cached * 100.0 / Math.Max(1, cached + processed)):F1}% served from cache");
ash-based cache manager with JSON index
s DocumentCacheManager
private readonly string _cacheFolder;
private readonly string _indexPath;
private Dictionary<string, CacheEntry> _index;
public DocumentCacheManager(string cacheFolder)
{
_cacheFolder = cacheFolder;
_indexPath = Path.Combine(cacheFolder, "cache-index.json");
_index = LoadIndex();
}
private Dictionary<string, CacheEntry> LoadIndex()
{
if (File.Exists(_indexPath))
{
string json = File.ReadAllText(_indexPath);
return JsonSerializer.Deserialize<Dictionary<string, CacheEntry>>(json) ?? new();
}
return new Dictionary<string, CacheEntry>();
}
private void SaveIndex()
{
string json = JsonSerializer.Serialize(_index, new JsonSerializerOptions { WriteIndented = true });
File.WriteAllText(_indexPath, json);
}
// SHA256 hash to detect file changes
public string ComputeFileHash(string filePath)
{
using var sha256 = SHA256.Create();
using var stream = File.OpenRead(filePath);
byte[] hash = sha256.ComputeHash(stream);
return Convert.ToHexString(hash);
}
public string? GetCachedResult(string fileName, string currentHash)
{
if (_index.TryGetValue(fileName, out var entry))
{
if (entry.FileHash == currentHash && File.Exists(entry.CachePath))
{
entry.LastAccessed = DateTime.UtcNow;
SaveIndex();
return File.ReadAllText(entry.CachePath);
}
}
return null;
}
public void CacheResult(string fileName, string fileHash, string result)
{
string cachePath = Path.Combine(_cacheFolder, $"{Path.GetFileNameWithoutExtension(fileName)}-{fileHash[..8]}.txt");
File.WriteAllText(cachePath, result);
_index[fileName] = new CacheEntry
{
FileHash = fileHash,
CachePath = cachePath,
CreatedAt = DateTime.UtcNow,
LastAccessed = DateTime.UtcNow
};
SaveIndex();
}
s CacheEntry
public string FileHash { get; set; } = "";
public string CachePath { get; set; } = "";
public DateTime CreatedAt { get; set; }
public DateTime LastAccessed { get; set; }Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System
Imports System.Collections.Generic
Imports System.Security.Cryptography
Imports System.Text.Json
' Cache AI processing results using file hashes to avoid reprocessing unchanged documents
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
' Configure caching
Dim cacheFolder As String = "ai-cache/"
Dim documentsFolder As String = "documents/"
Directory.CreateDirectory(cacheFolder)
Dim cacheManager = New DocumentCacheManager(cacheFolder)
' Process documents with caching
Dim pdfFiles As String() = Directory.GetFiles(documentsFolder, "*.pdf")
Dim cached As Integer = 0, processed As Integer = 0
For Each filePath As String In pdfFiles
Dim fileName As String = Path.GetFileName(filePath)
Dim fileHash As String = cacheManager.ComputeFileHash(filePath)
Dim cachedResult As String = cacheManager.GetCachedResult(fileName, fileHash)
If cachedResult IsNot Nothing Then
Console.WriteLine($"[CACHE HIT] {fileName}")
cached += 1
Continue For
End If
Console.WriteLine($"[PROCESSING] {fileName}")
Dim pdf = PdfDocument.FromFile(filePath)
Dim summary As String = Await pdf.Summarize()
cacheManager.CacheResult(fileName, fileHash, summary)
processed += 1
Next
Console.WriteLine(vbCrLf & $"Processing complete: {cached} cached, {processed} newly processed")
Console.WriteLine($"Cost savings: {(cached * 100.0 / Math.Max(1, cached + processed)):F1}% served from cache")
' Hash-based cache manager with JSON index
Public Class DocumentCacheManager
Private ReadOnly _cacheFolder As String
Private ReadOnly _indexPath As String
Private _index As Dictionary(Of String, CacheEntry)
Public Sub New(cacheFolder As String)
_cacheFolder = cacheFolder
_indexPath = Path.Combine(cacheFolder, "cache-index.json")
_index = LoadIndex()
End Sub
Private Function LoadIndex() As Dictionary(Of String, CacheEntry)
If File.Exists(_indexPath) Then
Dim json As String = File.ReadAllText(_indexPath)
Return JsonSerializer.Deserialize(Of Dictionary(Of String, CacheEntry))(json) OrElse New Dictionary(Of String, CacheEntry)()
End If
Return New Dictionary(Of String, CacheEntry)()
End Function
Private Sub SaveIndex()
Dim json As String = JsonSerializer.Serialize(_index, New JsonSerializerOptions With {.WriteIndented = True})
File.WriteAllText(_indexPath, json)
End Sub
' SHA256 hash to detect file changes
Public Function ComputeFileHash(filePath As String) As String
Using sha256 = SHA256.Create()
Using stream = File.OpenRead(filePath)
Dim hash As Byte() = sha256.ComputeHash(stream)
Return Convert.ToHexString(hash)
End Using
End Using
End Function
Public Function GetCachedResult(fileName As String, currentHash As String) As String
If _index.TryGetValue(fileName, entry) Then
If entry.FileHash = currentHash AndAlso File.Exists(entry.CachePath) Then
entry.LastAccessed = DateTime.UtcNow
SaveIndex()
Return File.ReadAllText(entry.CachePath)
End If
End If
Return Nothing
End Function
Public Sub CacheResult(fileName As String, fileHash As String, result As String)
Dim cachePath As String = Path.Combine(_cacheFolder, $"{Path.GetFileNameWithoutExtension(fileName)}-{fileHash.Substring(0, 8)}.txt")
File.WriteAllText(cachePath, result)
_index(fileName) = New CacheEntry With {
.FileHash = fileHash,
.CachePath = cachePath,
.CreatedAt = DateTime.UtcNow,
.LastAccessed = DateTime.UtcNow
}
SaveIndex()
End Sub
End Class
Public Class CacheEntry
Public Property FileHash As String = ""
Public Property CachePath As String = ""
Public Property CreatedAt As DateTime
Public Property LastAccessed As DateTime
End ClassGPT-5 et Claude Sonnet 4.5 en 2026 sont également dotés d'une fonction de mise en cache automatique des invites qui peut réduire la consommation effective de jetons de 50 à 90 % pour les motifs répétés, ce qui représente une économie importante pour les opérations à grande échelle.
Cas d'Utilisation du Monde Réel
Découverte juridique et analyse de contrats
Traditionnellement, la découverte juridique nécessitait des armées d'avocats débutants qui examinaient manuellement des centaines de milliers de pages. La découverte assistée par l'IA transforme ce processus, en permettant l'identification rapide des documents pertinents, l'examen automatique des privilèges et l'extraction de faits probants clés.
L'intégration de l'IA d'IronPDF permet de mettre en place des flux de travail juridiques sophistiqués : détection des privilèges, notation de la pertinence, identification des problèmes et extraction des dates clés. Les cabinets d'avocats déclarent avoir réduit les délais d'examen des documents de 70 à 80 %, ce qui leur permet de traiter des affaires plus importantes avec des équipes plus réduites.
Grâce à l'amélioration de la précision de GPT-5 et de Claude Sonnet 4.5 et à la réduction des taux d'hallucination en 2026, les Professional juridiques peuvent faire confiance à l'analyse assistée par l'IA pour des décisions de plus en plus critiques.
Analyse d'un rapport financier
Les analystes financiers passent énormément de temps à extraire des données des rapports sur les bénéfices, des documents déposés auprès de la SEC et des présentations d'analystes. Le traitement des documents financiers par l'IA automatise cette extraction, ce qui permet aux analystes de se concentrer sur l'interprétation plutôt que sur la collecte de données.
Cet exemple traite plusieurs déclarations 10-K, en utilisant pdf.Query() avec un schéma JSON CompanyFinancials pour extraire et comparer les revenus, les marges et les facteurs de risque entre les entreprises.
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/financial-sector-analysis.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System.Collections.Generic;
using System.Text.Json;
using System.Text;
// Compare financial metrics across multiple company filings for sector analysis
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
// Analyze company filings
string[] companyFilings = {
"filings/company-a-10k.pdf",
"filings/company-b-10k.pdf",
"filings/company-c-10k.pdf"
};
var sectorData = new List<CompanyFinancials>();
foreach (string filing in companyFilings)
{
Console.WriteLine($"Analyzing: {Path.GetFileName(filing)}");
var pdf = PdfDocument.FromFile(filing);
// Define JSON schema for 10-K extraction (numbers in millions USD)
string extractionQuery = @"Extract key financial metrics from this 10-K filing. Return JSON:
mpanyName"": ""string"",
scalYear"": ""string"",
venue"": number,
venueGrowth"": number,
ossMargin"": number,
eratingMargin"": number,
tIncome"": number,
s"": number,
talDebt"": number,
shPosition"": number,
ployeeCount"": number,
yRisks"": [""string""],
idance"": ""string""
in millions USD. Growth/margins as percentages.
NLY valid JSON.";
string result = await pdf.Query(extractionQuery);
try
{
var financials = JsonSerializer.Deserialize<CompanyFinancials>(result);
if (financials != null)
sectorData.Add(financials);
}
catch
{
Console.WriteLine($" Warning: Could not parse financials for {filing}");
}
}
// Generate sector comparison report
var report = new StringBuilder();
report.AppendLine("=== Sector Analysis Report ===\n");
report.AppendLine("Revenue Comparison (millions USD):");
foreach (var company in sectorData.OrderByDescending(c => c.Revenue))
report.AppendLine($" {company.CompanyName}: ${company.Revenue:N0} ({company.RevenueGrowth:+0.0;-0.0}% YoY)");
report.AppendLine("\nProfitability Margins:");
foreach (var company in sectorData.OrderByDescending(c => c.OperatingMargin))
report.AppendLine($" {company.CompanyName}: {company.GrossMargin:F1}% gross, {company.OperatingMargin:F1}% operating");
report.AppendLine("\nFinancial Health (Debt vs Cash):");
foreach (var company in sectorData)
{
double netDebt = company.TotalDebt - company.CashPosition;
string status = netDebt < 0 ? "Net Cash" : "Net Debt";
report.AppendLine($" {company.CompanyName}: {status} ${Math.Abs(netDebt):N0}M");
}
string reportText = report.ToString();
Console.WriteLine($"\n{reportText}");
File.WriteAllText("sector-analysis-report.txt", reportText);
// Save full JSON data
string outputJson = JsonSerializer.Serialize(sectorData, new JsonSerializerOptions { WriteIndented = true });
File.WriteAllText("sector-analysis.json", outputJson);
Console.WriteLine("Analysis saved to sector-analysis.json and sector-analysis-report.txt");
s CompanyFinancials
public string CompanyName { get; set; } = "";
public string FiscalYear { get; set; } = "";
public double Revenue { get; set; }
public double RevenueGrowth { get; set; }
public double GrossMargin { get; set; }
public double OperatingMargin { get; set; }
public double NetIncome { get; set; }
public double Eps { get; set; }
public double TotalDebt { get; set; }
public double CashPosition { get; set; }
public int EmployeeCount { get; set; }
public List<string> KeyRisks { get; set; } = new();
public string Guidance { get; set; } = "";Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.Collections.Generic
Imports System.Text.Json
Imports System.Text
Imports System.IO
' Compare financial metrics across multiple company filings for sector analysis
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
' Analyze company filings
Dim companyFilings As String() = {
"filings/company-a-10k.pdf",
"filings/company-b-10k.pdf",
"filings/company-c-10k.pdf"
}
Dim sectorData = New List(Of CompanyFinancials)()
For Each filing As String In companyFilings
Console.WriteLine($"Analyzing: {Path.GetFileName(filing)}")
Dim pdf = PdfDocument.FromFile(filing)
' Define JSON schema for 10-K extraction (numbers in millions USD)
Dim extractionQuery As String = "Extract key financial metrics from this 10-K filing. Return JSON:
mpanyName"": ""string"",
scalYear"": ""string"",
venue"": number,
venueGrowth"": number,
ossMargin"": number,
eratingMargin"": number,
tIncome"": number,
s"": number,
talDebt"": number,
shPosition"": number,
ployeeCount"": number,
yRisks"": [""string""],
idance"": ""string""
in millions USD. Growth/margins as percentages.
NLY valid JSON."
Dim result As String = Await pdf.Query(extractionQuery)
Try
Dim financials = JsonSerializer.Deserialize(Of CompanyFinancials)(result)
If financials IsNot Nothing Then
sectorData.Add(financials)
End If
Catch
Console.WriteLine($" Warning: Could not parse financials for {filing}")
End Try
Next
' Generate sector comparison report
Dim report = New StringBuilder()
report.AppendLine("=== Sector Analysis Report ===" & vbCrLf)
report.AppendLine("Revenue Comparison (millions USD):")
For Each company In sectorData.OrderByDescending(Function(c) c.Revenue)
report.AppendLine($" {company.CompanyName}: ${company.Revenue:N0} ({company.RevenueGrowth:+0.0;-0.0}% YoY)")
Next
report.AppendLine(vbCrLf & "Profitability Margins:")
For Each company In sectorData.OrderByDescending(Function(c) c.OperatingMargin)
report.AppendLine($" {company.CompanyName}: {company.GrossMargin:F1}% gross, {company.OperatingMargin:F1}% operating")
Next
report.AppendLine(vbCrLf & "Financial Health (Debt vs Cash):")
For Each company In sectorData
Dim netDebt As Double = company.TotalDebt - company.CashPosition
Dim status As String = If(netDebt < 0, "Net Cash", "Net Debt")
report.AppendLine($" {company.CompanyName}: {status} ${Math.Abs(netDebt):N0}M")
Next
Dim reportText As String = report.ToString()
Console.WriteLine(vbCrLf & reportText)
File.WriteAllText("sector-analysis-report.txt", reportText)
' Save full JSON data
Dim outputJson As String = JsonSerializer.Serialize(sectorData, New JsonSerializerOptions With {.WriteIndented = True})
File.WriteAllText("sector-analysis.json", outputJson)
Console.WriteLine("Analysis saved to sector-analysis.json and sector-analysis-report.txt")
Public Class CompanyFinancials
Public Property CompanyName As String = ""
Public Property FiscalYear As String = ""
Public Property Revenue As Double
Public Property RevenueGrowth As Double
Public Property GrossMargin As Double
Public Property OperatingMargin As Double
Public Property NetIncome As Double
Public Property Eps As Double
Public Property TotalDebt As Double
Public Property CashPosition As Double
Public Property EmployeeCount As Integer
Public Property KeyRisks As List(Of String) = New List(Of String)()
Public Property Guidance As String = ""
End ClassLes sociétés d'investissement utilisent l'analyse alimentée par l'IA pour traiter des milliers de documents chaque jour, ce qui permet aux analystes de surveiller une couverture plus large du marché et de réagir plus rapidement aux opportunités émergentes.
Résumé d'un document de recherche
La recherche universitaire génère des millions d'articles par an. La synthèse assistée par l'IA aide les chercheurs à évaluer rapidement la pertinence des articles, à comprendre les principales conclusions et à identifier les articles qui méritent d'être lus en détail. Un résumé de recherche efficace doit identifier la question de recherche, expliquer la méthodologie, résumer les principaux résultats avec les mises en garde appropriées et placer les résultats dans leur contexte.
Les institutions de recherche utilisent le résumé d'IA pour maintenir les bases de connaissances institutionnelles, en traitant automatiquement les nouvelles publications. Avec le raisonnement scientifique amélioré de GPT-5 et les capacités analytiques améliorées de Claude Sonnet 4.5 en 2026, le résumé académique atteint de nouveaux niveaux de précision.
Traitement des documents gouvernementaux
Les agences gouvernementales produisent des collections massives de documents - réglementations, commentaires publics, déclarations d'impact sur l'environnement, dossiers judiciaires, rapports d'audit. Le traitement des documents alimenté par l'IA rend les informations gouvernementales exploitables grâce à l'analyse de la conformité réglementaire, à l'évaluation de l'impact environnemental et au suivi législatif.
L'analyse des commentaires du public présente des défis uniques : les propositions réglementaires majeures peuvent recevoir des centaines de milliers de commentaires. Les systèmes d'IA peuvent classer les commentaires par sujet, identifier les thèmes communs, détecter les campagnes coordonnées et extraire les arguments de fond justifiant une réponse de l'agence.
La génération 2026 de modèles d'IA apporte des capacités sans précédent au traitement des documents gouvernementaux, favorisant la transparence démocratique et l'élaboration de politiques éclairées.
Dépannage et assistance technique
Solutions rapides aux erreurs courantes
- Lenteur du premier rendu? Normal. Chrome s'initialise en 2–3 s, puis accélère.
- <Utilisez au moins Azure B1 ou des ressources équivalentes.
- Les ressources manquantes? Définissez les chemins d'accès de base ou intégrez-les en tant que base64.
- <Ajouter RenderDelay pour l'exécution de JavaScript.
- Problèmes de mémoire? Mettez à jour la dernière version d'IronPDF pour corriger les performances.
- Form field issues? Assurer des noms uniques et mettre à jour la dernière version.
Obtenez de l'aide des ingénieurs qui ont développé IronPDF, 24/7
IronPDF offre une assistance technique 24 heures sur 24 et 7 jours sur 7. Vous avez des problèmes avec la conversion de HTML en PDF ou l'intégration de l'IA ? Contactez nous :
- Guide complet de dépannage
- Stratégies d'optimisation des performances
- Demandes d'assistance technique
- Liste de contrôle de dépannage rapide
Prochaines étapes
Maintenant que vous comprenez le traitement PDF alimenté par l'IA, la prochaine étape consiste à explorer les capacités plus larges d'IronPDF. Le guide d'intégration de l'OpenAI offre une couverture plus approfondie des modèles de résumé, d'interrogation et de mémorisation, tandis que le tutoriel d'extraction de texte et d'image montre comment prétraiter les PDF avant l'analyse de l'IA. Pour les flux de travail d'assemblage de documents, apprenez à fusionner et diviser des PDF pour le traitement par lots.
Lorsque vous êtes prêt à aller au-delà des fonctionnalités d'IronPDF, le tutoriel complet d'édition de PDF couvre les filigranes, les en-têtes, les pieds de page, les formulaires et les annotations. Pour d'autres approches d'intégration de l'IA, le tutoriel C# de ChatGPT présente différents modèles. Le déploiement en production est abordé dans le guide de déploiement Azure pour les WebApps et les fonctions, et le tutoriel de création de PDF C# couvre la génération de PDF à partir de HTML, d'URL et de contenu brut.
Prêt à démarrer ? Démarrez votre essai gratuit de 30 jours pour tester en production sans filigrane, avec une licence flexible qui évolue avec votre équipe. Pour toute question concernant l'intégration de l'IA ou toute autre fonctionnalité d'IronPDF, notre équipe d'assistance technique est à votre disposition.
Questions Fréquemment Posées
Quels sont les avantages de l'utilisation de l'IA pour le traitement des PDF en C# ?
Le traitement PDF alimenté par l'IA en C# permet des fonctionnalités avancées telles que le résumé de documents, l'extraction de données vers JSON et la construction de systèmes de questions-réponses. Il améliore l'efficacité et la précision dans le traitement de grands volumes de documents.
Comment IronPDF intègre-t-il l'IA pour résumer les documents ?
IronPDF intègre l'IA en s'appuyant sur des modèles tels que GPT-5 et Claude, qui peuvent analyser et résumer des documents, facilitant ainsi la déduction d'idées et la compréhension rapide de textes volumineux.
Quel est le rôle des motifs RAG dans le traitement des PDF par l'IA ?
Les modèles RAG (Retrieve and Generate) sont utilisés dans le traitement des PDF par l'IA pour améliorer la qualité de la recherche et de la génération d'informations, ce qui permet une analyse des documents plus précise et plus pertinente sur le plan contextuel.
Comment les données structurées peuvent-elles être extraites des PDF à l'aide d'IronPDF ?
IronPDF permet d'extraire des données structurées à partir de PDF dans des formats tels que JSON, ce qui facilite l'intégration et l'analyse transparentes des données dans différentes applications et systèmes.
IronPDF peut-il gérer de grandes bibliothèques de documents grâce à l'IA ?
Oui, IronPDF peut traiter efficacement de grandes bibliothèques de documents en utilisant des modèles d'IA pour automatiser des tâches telles que le résumé et l'extraction de données, ce qui évolue bien avec les intégrations OpenAI et Azure OpenAI.
Quels sont les modèles d'IA pris en charge par IronPDF pour le traitement des PDF ?
IronPDF prend en charge des modèles d'IA avancés tels que GPT-5 et Claude, qui sont utilisés pour des tâches telles que le résumé de documents et la construction de systèmes de questions-réponses, améliorant ainsi les capacités de traitement globales.
Comment IronPDF facilite-t-il la mise en place de systèmes de questions-réponses ?
IronPDF aide à construire des systèmes de questions-réponses en traitant et en analysant les documents pour en extraire les informations pertinentes, qui peuvent ensuite être utilisées pour générer des réponses précises aux requêtes des utilisateurs.
Quels sont les principaux cas d'utilisation du traitement des PDF par l'IA en C# ?
Les principaux cas d'utilisation comprennent le résumé de documents, l'extraction de données structurées, le développement de systèmes de questions-réponses et le traitement de tâches de traitement de documents à grande échelle à l'aide d'intégrations d'IA comme OpenAI.
Est-il possible d'utiliser IronPDF avec Azure OpenAI pour le traitement des documents ?
Oui, IronPDF peut être intégré à Azure OpenAI pour améliorer les tâches de traitement des documents, en fournissant des solutions évolutives pour résumer, extraire et analyser les documents PDF.
Comment IronPDF améliore-t-il l'analyse des documents grâce à l'IA ?
IronPDF améliore l'analyse des documents en utilisant des modèles d'IA pour automatiser et améliorer des tâches telles que le résumé, l'extraction de données et la recherche d'informations, ce qui permet un traitement plus efficace et plus précis des documents.


Vous faites encore défiler ?
Vous voulez une preuve rapidement ? PM > Install-Package IronPdf
exécuter un échantillon Regardez votre code HTML se transformer en PDF.










