

C# AI 驱动的 PDF编辑 与处理:使用 IronPDF 总结、提取和分析文档
IronPDF的C# AI 驱动 PDF 处理功能让.NET开发人员能够总结文档、提取结构化数据,并直接在现有的 PDF 工作流程之上构建问答系统——它使用基于Microsoft Semantic Kernel构建的 IronPdf.Extensions.AI 包与Azure OpenAI和OpenAI模型无缝连接。 无论您是在构建法律发现工具、财务分析管道,还是在构建文档智能平台,IronPDF 都能处理 PDF 提取和上下文准备工作,让您专注于人工智能逻辑。
TL;DR:快速入门指南
本教程介绍如何在 C# .NET 中将 IronPDF 连接到人工智能服务,以进行文档汇总、数据提取和智能查询。
- 适用对象:构建文档智能应用程序(法律发现系统、财务分析工具、合规审查平台或任何需要从大量 PDF 文档中提取意义的应用程序)的 .NET 开发人员。
- 您将构建的内容:单文档摘要、使用自定义模式的结构化 JSON 数据提取、文档内容的问题解答、长文档的 RAG 管道以及跨文档库的批量人工智能处理工作流。
- 运行环境:任何具有 Azure OpenAI 或 OpenAI API 密钥的 .NET 6+ 环境。 人工智能扩展与 Microsoft Semantic Kernel 集成,可自动处理上下文窗口管理、分块和协调。
- 何时使用此方法:当您的应用程序需要处理文本提取以外的 PDF 文件时(如理解合同义务、总结研究论文、将财务表格提取为结构化数据,或大规模回答用户有关文档内容的问题)。
- 在技术上为何重要:原始文本提取会丢失文档结构--表格崩溃、多列布局中断、语义关系消失。 IronPDF 通过保留结构和管理标记限制来为人工智能消费准备文档,因此模型会收到干净、有条理的输入。
用几行代码概括 PDF:
购买或注册 IronPDF 30 天试用版后,请在应用程序的开头添加许可证密钥。
IronPdf.License.LicenseKey = "KEY";IronPdf.License.LicenseKey = "KEY";Imports IronPdf
IronPdf.License.LicenseKey = "KEY"目录
AI + PDF 的机遇
为什么 PDF 是最大的未开发数据源
PDF 是现代企业中最大的结构化商业知识库之一。专业文档--合同、财务报表、合规报告、法律简报和研究论文--主要以 PDF 格式存储。 这些文件包含重要的商业情报:定义义务和责任的合同条款、推动投资决策的财务指标、确保合规的监管要求以及指导战略的研究成果。
然而,传统的 PDF 处理方法受到严重限制。 基本的文本提取工具可以从页面中提取原始字符,但它们会丢失关键的上下文:表格结构会坍塌成杂乱无章的文本,多栏布局会变得毫无意义,章节之间的语义关系也会消失。
人工智能能够理解上下文和结构,这是一个突破。 现代法律硕士不仅能看到文字,还能理解文档的组织结构,识别合同条款或财务表格等模式,甚至能从复杂的布局中提取含义。 与早期型号相比,GPT-5 的统一推理系统及其实时路由器和 Claude Sonnet 4.5 的增强代理功能都表现出明显降低的幻觉率,使其成为专业文档分析的可靠工具。
法律硕士如何理解文档结构
大型语言模型为 PDF 分析带来了复杂的自然语言处理能力。 GPT-5 的混合架构具有多个子模型(主模型、迷你模型、思维模型、纳米模型)和一个实时路由器,该路由器可根据任务复杂程度动态选择最佳变体--简单的问题可路由到速度更快的模型,而复杂的推理任务可使用完整的模型。
Claude Opus 4.6 尤其擅长长时间运行的代理任务,其代理团队可直接协调分段作业,100 万标记的上下文窗口可处理整个文档库,无需分块。
这种对上下文的理解使 LLM 能够完成需要真正理解的任务。 在分析合同时,法学硕士不仅能识别包含 "终止 "一词的条款,还能理解允许终止的具体条件、涉及的通知要求以及由此产生的责任。 实现这一功能的技术基础是为现代 LLM 提供动力的转换器架构,GPT-5 的上下文窗口可支持多达 272,000 个输入令牌,而 Claude Sonnet 4.5 的 200K 令牌窗口可提供全面的文档覆盖。
IronPDF 的内置 AI 集成
安装 IronPDF 和 AI 扩展
开始使用人工智能驱动的 PDF 处理需要 IronPDF 核心库、人工智能扩展包和 Microsoft Semantic Kernel 依赖项。
使用 NuGet 软件包管理器安装 IronPdf:
PM > Install-Package IronPdf
PM > Install-Package IronPdf.Extensions.AI
PM > Install-Package Microsoft.SemanticKernel
PM > Install-Package Microsoft.SemanticKernel.Plugins.MemoryPM > Install-Package IronPdf
PM > Install-Package IronPdf.Extensions.AI
PM > Install-Package Microsoft.SemanticKernel
PM > Install-Package Microsoft.SemanticKernel.Plugins.Memory这些软件包可共同提供完整的解决方案。 IronPdf 处理所有与 PDF 相关的操作--文本提取、页面渲染、格式转换,而人工智能扩展则通过 Microsoft Semantic Kernel 管理与语言模型的集成。
<NoWarn>$(NoWarn);SKEXP0001;SKEXP0010;SKEXP0050</NoWarn> 添加到您的 .csproj 属性组中,以抑制编译器警告。配置您的 OpenAI/Azure API 密钥
在利用人工智能功能之前,您需要配置访问人工智能服务提供商的权限。 IronPDF 的人工智能扩展支持 OpenAI 和 Azure OpenAI。 Azure OpenAI 通常是企业应用程序的首选,因为它提供了增强的安全功能、合规认证以及在特定地理区域内保存数据的能力。
要配置 Azure OpenAI,您需要从 Azure 门户获取用于聊天和嵌入模型的 Azure 端点 URL、API 密钥和部署名称。
初始化人工智能引擎
IronPDF 的人工智能扩展在引擎盖下使用 Microsoft Semantic Kernel。 在使用任何人工智能功能之前,您必须使用 Azure OpenAI 凭据初始化内核,并为文档处理配置内存存储。
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/configure-azure-credentials.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
// Initialize IronPDF AI with Azure OpenAI credentials
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel with Azure OpenAI
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
// Create memory store for document embeddings
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
// Initialize IronPDF AI
IronDocumentAI.Initialize(kernel, memory);
Console.WriteLine("IronPDF AI initialized successfully with Azure OpenAI");Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
' Initialize IronPDF AI with Azure OpenAI credentials
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel with Azure OpenAI
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
' Create memory store for document embeddings
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
' Initialize IronPDF AI
IronDocumentAI.Initialize(kernel, memory)
Console.WriteLine("IronPDF AI initialized successfully with Azure OpenAI")初始化创建了两个关键组件:
- 内核:通过 Azure OpenAI 处理聊天完成和文本嵌入生成
- 内存:存储文档嵌入,用于语义搜索和检索操作
使用 IronDocumentAI.Initialize() 初始化后,您就可以在整个应用程序中使用 AI 功能。 对于生产应用程序,强烈建议将凭证存储在环境变量或 Azure Key Vault 中。
IronPDF 如何为人工智能语境准备 PDF 文件
人工智能驱动的 PDF 处理中最具挑战性的一个方面是准备文档供语言模型使用。 虽然 GPT-5 支持多达 272,000 个输入标记,Claude Opus 4.6 现在也提供了 1M 标记上下文窗口,但一份法律合同或财务报告仍然很容易超过旧型号的限制。
IronPDF 的人工智能扩展通过智能文档准备处理这种复杂性。 当您调用人工智能方法时,IronPDF 会首先从 PDF 中提取文本,同时保留结构信息--识别段落、保留表格结构并保持各部分之间的关系。
对于超出上下文限制的文档,IronPDF 会在语义断点(文档结构中的自然分区,如节首、分页符或段落边界)处实施策略性分块。
文档摘要
单个文档摘要
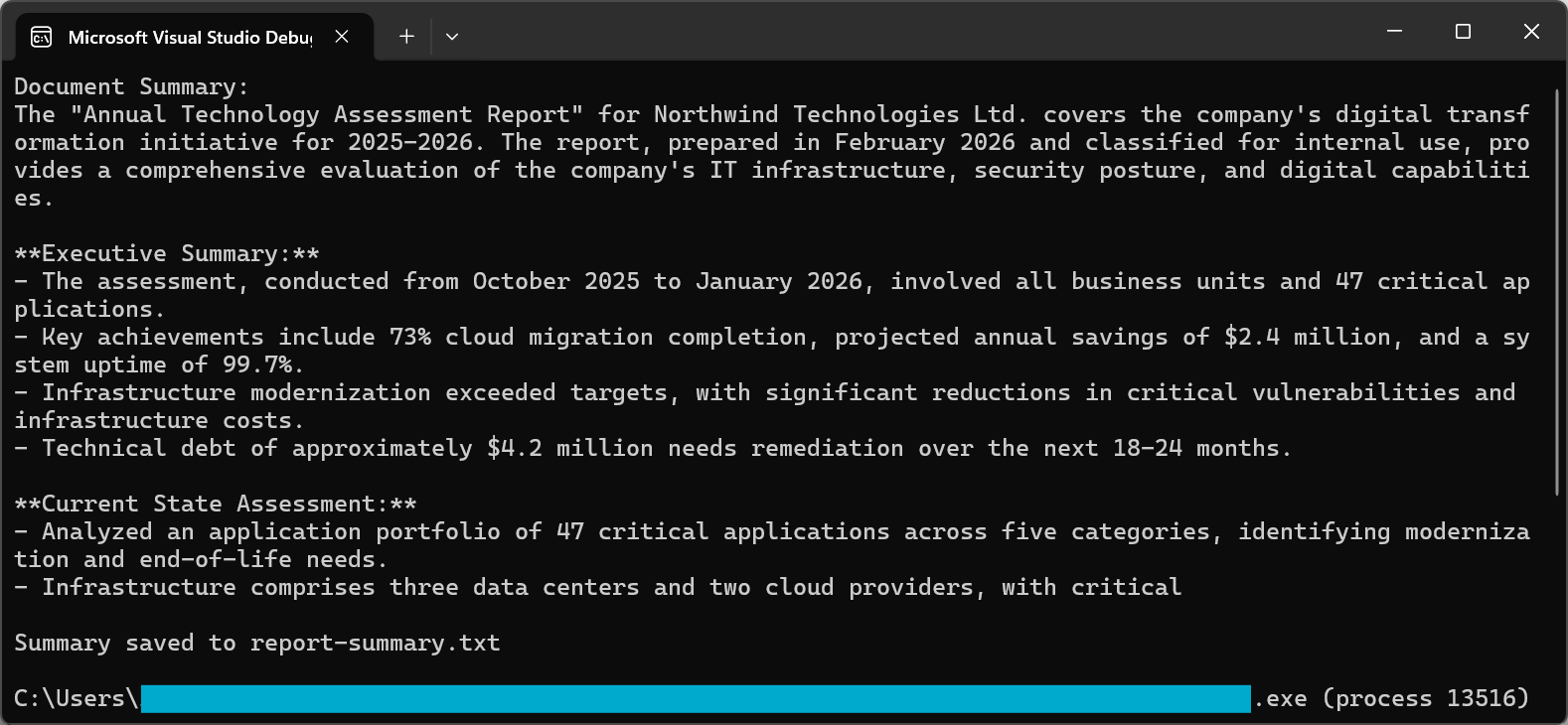
文档摘要将冗长的文档浓缩为易于消化的见解,从而带来直接价值。 Summarize 方法处理整个工作流程:提取文本、准备供 AI 使用、向语言模型请求摘要以及保存结果。
输入
该代码使用 PdfDocument.FromFile() 加载 PDF,并调用 pdf.Summarize() 生成简洁的摘要,然后将结果保存到文本文件中。
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/single-document-summary.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
// Summarize a PDF document using IronPDF AI
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
// Load and summarize PDF
var pdf = PdfDocument.FromFile("sample-report.pdf");
string summary = await pdf.Summarize();
Console.WriteLine("Document Summary:");
Console.WriteLine(summary);
File.WriteAllText("report-summary.txt", summary);
Console.WriteLine("\nSummary saved to report-summary.txt");Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
' Summarize a PDF document using IronPDF AI
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
' Load and summarize PDF
Dim pdf = PdfDocument.FromFile("sample-report.pdf")
Dim summary As String = Await pdf.Summarize()
Console.WriteLine("Document Summary:")
Console.WriteLine(summary)
File.WriteAllText("report-summary.txt", summary)
Console.WriteLine(vbCrLf & "Summary saved to report-summary.txt")控制台输出
总结过程使用了复杂的提示,以确保高质量的结果。 2026 年的 GPT-5 和 Claude Sonnet 4.5 均大幅改进了指令跟踪功能,确保摘要在捕捉基本信息的同时保持简洁和可读性。
有关文档摘要技术和高级选项的更详细解释,请参阅我们的 how-to guide 。
多文档合成
现实世界中的许多场景都需要综合多个文档中的信息。 法律团队可能需要确定合同组合中的共同条款,财务分析师可能希望比较各季度报告中的指标。
多文档合成的方法包括对每份文档进行单独处理以提取关键信息,然后汇总这些见解进行最终合成。
此示例遍历多个 PDF,对每个 PDF 调用 pdf.Summarize(),然后使用 pdf.Query() 和组合摘要生成统一的综合结果。
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/multi-document-synthesis.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
// Synthesize insights across multiple related documents (e.g., quarterly reports into annual summary)
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
// Define documents to synthesize
string[] documentPaths = {
"Q1-report.pdf",
"Q2-report.pdf",
"Q3-report.pdf",
"Q4-report.pdf"
};
var documentSummaries = new List<string>();
// Summarize each document
foreach (string path in documentPaths)
{
var pdf = PdfDocument.FromFile(path);
string summary = await pdf.Summarize();
documentSummaries.Add($"=== {Path.GetFileName(path)} ===\n{summary}");
Console.WriteLine($"Processed: {path}");
}
// Combine and synthesize across all documents
string combinedSummaries = string.Join("\n\n", documentSummaries);
var synthesisDoc = PdfDocument.FromFile(documentPaths[0]);
string synthesisQuery = @"Based on the quarterly summaries below, provide an annual synthesis:
ll trends across quarters
chievements and challenges
over-year patterns
s:
inedSummaries;
string synthesis = await synthesisDoc.Query(synthesisQuery);
Console.WriteLine("\n=== Annual Synthesis ===");
Console.WriteLine(synthesis);
File.WriteAllText("annual-synthesis.txt", synthesis);Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.IO
' Synthesize insights across multiple related documents (e.g., quarterly reports into annual summary)
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
' Define documents to synthesize
Dim documentPaths As String() = {
"Q1-report.pdf",
"Q2-report.pdf",
"Q3-report.pdf",
"Q4-report.pdf"
}
Dim documentSummaries = New List(Of String)()
' Summarize each document
For Each path As String In documentPaths
Dim pdf = PdfDocument.FromFile(path)
Dim summary As String = Await pdf.Summarize()
documentSummaries.Add($"=== {Path.GetFileName(path)} ==={vbCrLf}{summary}")
Console.WriteLine($"Processed: {path}")
Next
' Combine and synthesize across all documents
Dim combinedSummaries As String = String.Join(vbCrLf & vbCrLf, documentSummaries)
Dim synthesisDoc = PdfDocument.FromFile(documentPaths(0))
Dim synthesisQuery As String = "Based on the quarterly summaries below, provide an annual synthesis:" & vbCrLf &
"Overall trends across quarters" & vbCrLf &
"Key achievements and challenges" & vbCrLf &
"Year-over-year patterns" & vbCrLf & vbCrLf &
combinedSummaries
Dim synthesis As String = Await synthesisDoc.Query(synthesisQuery)
Console.WriteLine(vbCrLf & "=== Annual Synthesis ===")
Console.WriteLine(synthesis)
File.WriteAllText("annual-synthesis.txt", synthesis)这种模式可以有效地扩展到大型文档集。 通过并行处理文档和管理中间结果,您可以分析成百上千份文档,同时保持合成的连贯性。
生成执行摘要
执行摘要需要采用与标准摘要不同的方法。 执行摘要不是简单地浓缩内容,而是必须确定最关键的业务信息,突出关键决策或建议,并以适合领导审阅的格式介绍研究结果。
该代码使用 pdf.Query(),以结构化的提示要求以业务语言进行关键决策、重要发现、财务影响和风险评估。
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/executive-summary.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
// Generate executive summary from strategic documents for C-suite leadership
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
var pdf = PdfDocument.FromFile("strategic-plan.pdf");
string executiveQuery = @"Create an executive summary for C-suite leadership. Include:
cisions Required:**
ny decisions needing executive approval
al Findings:**
5 most important findings (bullet points)
ial Impact:**
e/cost implications if mentioned
ssessment:**
riority risks identified
ended Actions:**
ate next steps
er 500 words. Use business language appropriate for board presentation.";
string executiveSummary = await pdf.Query(executiveQuery);
File.WriteAllText("executive-summary.txt", executiveSummary);
Console.WriteLine("Executive summary saved to executive-summary.txt");Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
' Generate executive summary from strategic documents for C-suite leadership
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
Dim pdf = PdfDocument.FromFile("strategic-plan.pdf")
Dim executiveQuery As String = "Create an executive summary for C-suite leadership. Include:
cisions Required:**
ny decisions needing executive approval
al Findings:**
5 most important findings (bullet points)
ial Impact:**
e/cost implications if mentioned
ssessment:**
riority risks identified
ended Actions:**
ate next steps
er 500 words. Use business language appropriate for board presentation."
Dim executiveSummary As String = Await pdf.Query(executiveQuery)
File.WriteAllText("executive-summary.txt", executiveSummary)
Console.WriteLine("Executive summary saved to executive-summary.txt")由此产生的执行摘要优先考虑可操作的信息,而不是全面的覆盖范围,准确提供决策者所需的信息,而不是过多的细节。
智能数据提取
将结构化数据提取为 JSON.
人工智能驱动的 PDF 处理最强大的应用之一是从非结构化文档中提取结构化数据。 2026 年结构化提取成功的关键是使用具有结构化输出模式的 JSON 模式。 GPT-5 引入了改进的结构化输出,而 Claude Sonnet 4.5 则为可靠的数据提取提供了增强的工具协调功能。
输入
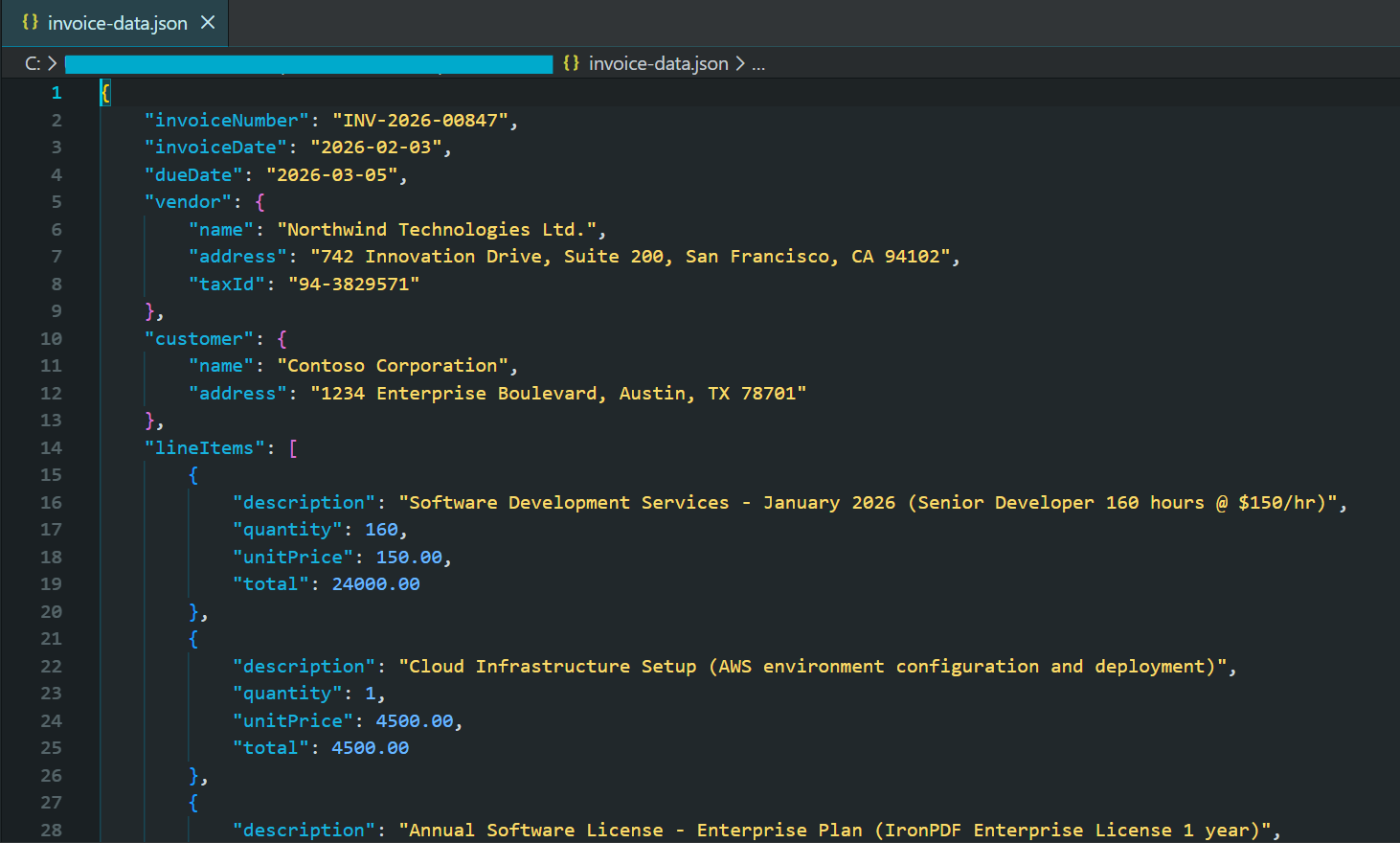
该代码使用 JSON 模式提示调用 pdf.Query(),然后使用 JsonSerializer.Deserialize() 解析和验证提取的发票数据。
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/extract-invoice-json.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System.Text.Json;
// Extract structured invoice data as JSON from PDF
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
var pdf = PdfDocument.FromFile("sample-invoice.pdf");
// Define JSON schema for extraction
string extractionQuery = @"Extract invoice data and return as JSON with this exact structure:
voiceNumber"": ""string"",
voiceDate"": ""YYYY-MM-DD"",
eDate"": ""YYYY-MM-DD"",
ndor"": {
""name"": ""string"",
""address"": ""string"",
""taxId"": ""string or null""
stomer"": {
""name"": ""string"",
""address"": ""string""
neItems"": [
{
""description"": ""string"",
""quantity"": number,
""unitPrice"": number,
""total"": number
}
btotal"": number,
xRate"": number,
xAmount"": number,
tal"": number,
rrency"": ""string""
NLY valid JSON, no additional text.";
string jsonResponse = await pdf.Query(extractionQuery);
// Parse and save JSON
try
{
var invoiceData = JsonSerializer.Deserialize<JsonElement>(jsonResponse);
string formattedJson = JsonSerializer.Serialize(invoiceData, new JsonSerializerOptions { WriteIndented = true });
Console.WriteLine("Extracted Invoice Data:");
Console.WriteLine(formattedJson);
File.WriteAllText("invoice-data.json", formattedJson);
}
catch (JsonException)
{
Console.WriteLine("Unable to parse JSON response");
File.WriteAllText("invoice-raw-response.txt", jsonResponse);
}Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.Text.Json
' Extract structured invoice data as JSON from PDF
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
Dim pdf = PdfDocument.FromFile("sample-invoice.pdf")
' Define JSON schema for extraction
Dim extractionQuery As String = "Extract invoice data and return as JSON with this exact structure:
voiceNumber"": ""string"",
voiceDate"": ""YYYY-MM-DD"",
eDate"": ""YYYY-MM-DD"",
ndor"": {
""name"": ""string"",
""address"": ""string"",
""taxId"": ""string or null""
stomer"": {
""name"": ""string"",
""address"": ""string""
neItems"": [
{
""description"": ""string"",
""quantity"": number,
""unitPrice"": number,
""total"": number
}
btotal"": number,
xRate"": number,
xAmount"": number,
tal"": number,
rrency"": ""string""
NLY valid JSON, no additional text."
Dim jsonResponse As String = Await pdf.QueryAsync(extractionQuery)
' Parse and save JSON
Try
Dim invoiceData = JsonSerializer.Deserialize(Of JsonElement)(jsonResponse)
Dim formattedJson As String = JsonSerializer.Serialize(invoiceData, New JsonSerializerOptions With {.WriteIndented = True})
Console.WriteLine("Extracted Invoice Data:")
Console.WriteLine(formattedJson)
File.WriteAllText("invoice-data.json", formattedJson)
Catch ex As JsonException
Console.WriteLine("Unable to parse JSON response")
File.WriteAllText("invoice-raw-response.txt", jsonResponse)
End Try生成的 JSON 文件的部分截图
2026 年的现代人工智能模型支持结构化输出模式,可保证符合所提供模式的有效 JSON 响应。 这样就不需要对畸形响应进行复杂的错误处理。
合同条款识别
法律合同包含一些特别重要的特定类型条款:终止条款、责任限制、赔偿要求、知识产权转让和保密义务。 人工智能驱动的条款识别可自动进行分析,同时保持高准确性。
本示例使用 pdf.Query() 和以条款为中心的 JSON 模式来提取合同类型、参与方、关键日期以及具有风险级别的单个条款。
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/contract-clause-analysis.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System.Text.Json;
// Analyze contract clauses and identify key terms, risks, and critical dates
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
var pdf = PdfDocument.FromFile("contract.pdf");
// Define JSON schema for contract analysis
string clauseQuery = @"Analyze this contract and identify key clauses. Return JSON:
ntractType"": ""string"",
rties"": [""string""],
fectiveDate"": ""string"",
auses"": [
{
""type"": ""Termination|Liability|Indemnification|Confidentiality|IP|Payment|Warranty|Other"",
""title"": ""string"",
""summary"": ""string"",
""riskLevel"": ""Low|Medium|High"",
""keyTerms"": [""string""]
}
iticalDates"": [
{
""description"": ""string"",
""date"": ""string""
}
erallRiskAssessment"": ""Low|Medium|High"",
commendations"": [""string""]
: termination rights, liability caps, indemnification, IP ownership, confidentiality, payment terms.
NLY valid JSON.";
string analysisJson = await pdf.Query(clauseQuery);
try
{
var analysis = JsonSerializer.Deserialize<JsonElement>(analysisJson);
string formatted = JsonSerializer.Serialize(analysis, new JsonSerializerOptions { WriteIndented = true });
Console.WriteLine("Contract Clause Analysis:");
Console.WriteLine(formatted);
File.WriteAllText("contract-analysis.json", formatted);
// Display high-risk clauses
Console.WriteLine("\n=== High Risk Clauses ===");
foreach (var clause in analysis.GetProperty("clauses").EnumerateArray())
{
if (clause.GetProperty("riskLevel").GetString() == "High")
{
Console.WriteLine($"- {clause.GetProperty("type")}: {clause.GetProperty("summary")}");
}
}
}
catch (JsonException)
{
Console.WriteLine("Unable to parse contract analysis");
File.WriteAllText("contract-analysis-raw.txt", analysisJson);
}Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.Text.Json
' Analyze contract clauses and identify key terms, risks, and critical dates
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
Dim pdf = PdfDocument.FromFile("contract.pdf")
' Define JSON schema for contract analysis
Dim clauseQuery As String = "Analyze this contract and identify key clauses. Return JSON:
ntractType"": ""string"",
rties"": [""string""],
fectiveDate"": ""string"",
auses"": [
{
""type"": ""Termination|Liability|Indemnification|Confidentiality|IP|Payment|Warranty|Other"",
""title"": ""string"",
""summary"": ""string"",
""riskLevel"": ""Low|Medium|High"",
""keyTerms"": [""string""]
}
iticalDates"": [
{
""description"": ""string"",
""date"": ""string""
}
erallRiskAssessment"": ""Low|Medium|High"",
commendations"": [""string""]
: termination rights, liability caps, indemnification, IP ownership, confidentiality, payment terms.
NLY valid JSON."
Dim analysisJson As String = Await pdf.Query(clauseQuery)
Try
Dim analysis = JsonSerializer.Deserialize(Of JsonElement)(analysisJson)
Dim formatted As String = JsonSerializer.Serialize(analysis, New JsonSerializerOptions With {.WriteIndented = True})
Console.WriteLine("Contract Clause Analysis:")
Console.WriteLine(formatted)
File.WriteAllText("contract-analysis.json", formatted)
' Display high-risk clauses
Console.WriteLine(vbCrLf & "=== High Risk Clauses ===")
For Each clause In analysis.GetProperty("clauses").EnumerateArray()
If clause.GetProperty("riskLevel").GetString() = "High" Then
Console.WriteLine($"- {clause.GetProperty("type")}: {clause.GetProperty("summary")}")
End If
Next
Catch ex As JsonException
Console.WriteLine("Unable to parse contract analysis")
File.WriteAllText("contract-analysis-raw.txt", analysisJson)
End Try该功能将合同审核从一个连续的人工流程转变为一个自动化、可扩展的工作流程。 法律团队可以在数百份合同中快速识别高风险条款。
金融数据解析
财务文件包含重要的量化数据,并嵌入复杂的叙述和表格中。 人工智能驱动的解析技术在财务文件方面表现出色,因为它能够理解上下文--区分历史结果和前瞻性预测,识别数字是以千为单位还是以百万为单位,并理解不同指标之间的关系。
该代码使用 pdf.Query() 和财务 JSON 模式,将损益表数据、资产负债表指标和前瞻性指引提取为结构化输出。
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/financial-data-extraction.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System.Text.Json;
// Extract financial metrics from annual reports and earnings documents
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
var pdf = PdfDocument.FromFile("annual-report.pdf");
// Define JSON schema for financial extraction (numbers in millions)
string financialQuery = @"Extract financial metrics from this document. Return JSON:
portPeriod"": ""string"",
mpany"": ""string"",
rrency"": ""string"",
comeStatement"": {
""revenue"": number,
""costOfRevenue"": number,
""grossProfit"": number,
""operatingExpenses"": number,
""operatingIncome"": number,
""netIncome"": number,
""eps"": number
lanceSheet"": {
""totalAssets"": number,
""totalLiabilities"": number,
""shareholdersEquity"": number,
""cash"": number,
""totalDebt"": number
yMetrics"": {
""revenueGrowthYoY"": ""string"",
""grossMargin"": ""string"",
""operatingMargin"": ""string"",
""netMargin"": ""string"",
""debtToEquity"": number
idance"": {
""nextQuarterRevenue"": ""string"",
""fullYearRevenue"": ""string"",
""notes"": ""string""
for unavailable data. Numbers in millions unless stated.
NLY valid JSON.";
string financialJson = await pdf.Query(financialQuery);
try
{
var financials = JsonSerializer.Deserialize<JsonElement>(financialJson);
string formatted = JsonSerializer.Serialize(financials, new JsonSerializerOptions { WriteIndented = true });
Console.WriteLine("Extracted Financial Data:");
Console.WriteLine(formatted);
File.WriteAllText("financial-data.json", formatted);
}
catch (JsonException)
{
Console.WriteLine("Unable to parse financial data");
File.WriteAllText("financial-raw.txt", financialJson);
}Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.Text.Json
' Extract financial metrics from annual reports and earnings documents
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
Dim pdf = PdfDocument.FromFile("annual-report.pdf")
' Define JSON schema for financial extraction (numbers in millions)
Dim financialQuery As String = "Extract financial metrics from this document. Return JSON:
portPeriod"": ""string"",
mpany"": ""string"",
rrency"": ""string"",
comeStatement"": {
""revenue"": number,
""costOfRevenue"": number,
""grossProfit"": number,
""operatingExpenses"": number,
""operatingIncome"": number,
""netIncome"": number,
""eps"": number
lanceSheet"": {
""totalAssets"": number,
""totalLiabilities"": number,
""shareholdersEquity"": number,
""cash"": number,
""totalDebt"": number
yMetrics"": {
""revenueGrowthYoY"": ""string"",
""grossMargin"": ""string"",
""operatingMargin"": ""string"",
""netMargin"": ""string"",
""debtToEquity"": number
idance"": {
""nextQuarterRevenue"": ""string"",
""fullYearRevenue"": ""string"",
""notes"": ""string""
for unavailable data. Numbers in millions unless stated.
NLY valid JSON."
Dim financialJson As String = Await pdf.Query(financialQuery)
Try
Dim financials = JsonSerializer.Deserialize(Of JsonElement)(financialJson)
Dim formatted As String = JsonSerializer.Serialize(financials, New JsonSerializerOptions With {.WriteIndented = True})
Console.WriteLine("Extracted Financial Data:")
Console.WriteLine(formatted)
File.WriteAllText("financial-data.json", formatted)
Catch ex As JsonException
Console.WriteLine("Unable to parse financial data")
File.WriteAllText("financial-raw.txt", financialJson)
End Try提取的结构化数据可直接输入财务模型、时间序列数据库或分析平台,从而实现跨报告期的指标自动跟踪。
自定义提取提示
许多组织都有基于其特定领域、文件格式或业务流程的独特提取要求。 IronPdf 的人工智能集成完全支持自定义提取提示,允许您准确定义应该提取哪些信息以及信息的结构。
本示例演示了 pdf.Query() 的研究型模式提取方法、关键发现及其置信度以及学术论文的局限性。
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/custom-research-extraction.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System.Text.Json;
// Extract structured research metadata from academic papers
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
var pdf = PdfDocument.FromFile("research-paper.pdf");
// Define JSON schema for research paper extraction
string researchQuery = @"Extract structured information from this research paper. Return JSON:
tle"": ""string"",
thors"": [""string""],
stitution"": ""string"",
blicationDate"": ""string"",
stract"": ""string"",
searchQuestion"": ""string"",
thodology"": {
""type"": ""Quantitative|Qualitative|Mixed Methods"",
""approach"": ""string"",
""sampleSize"": ""string"",
""dataCollection"": ""string""
yFindings"": [
{
""finding"": ""string"",
""significance"": ""string"",
""confidence"": ""High|Medium|Low""
}
mitations"": [""string""],
tureWork"": [""string""],
ywords"": [""string""]
extracting verifiable claims and noting uncertainty.
NLY valid JSON.";
string extractionResult = await pdf.Query(researchQuery);
try
{
var research = JsonSerializer.Deserialize<JsonElement>(extractionResult);
string formatted = JsonSerializer.Serialize(research, new JsonSerializerOptions { WriteIndented = true });
Console.WriteLine("Research Paper Extraction:");
Console.WriteLine(formatted);
File.WriteAllText("research-extraction.json", formatted);
// Display key findings with confidence levels
Console.WriteLine("\n=== Key Findings ===");
foreach (var finding in research.GetProperty("keyFindings").EnumerateArray())
{
string confidence = finding.GetProperty("confidence").GetString() ?? "Unknown";
Console.WriteLine($"[{confidence}] {finding.GetProperty("finding")}");
}
}
catch (JsonException)
{
Console.WriteLine("Unable to parse research extraction");
File.WriteAllText("research-raw.txt", extractionResult);
}Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.Text.Json
' Extract structured research metadata from academic papers
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
Dim pdf = PdfDocument.FromFile("research-paper.pdf")
' Define JSON schema for research paper extraction
Dim researchQuery As String = "Extract structured information from this research paper. Return JSON:
tle"": ""string"",
thors"": [""string""],
stitution"": ""string"",
blicationDate"": ""string"",
stract"": ""string"",
searchQuestion"": ""string"",
thodology"": {
""type"": ""Quantitative|Qualitative|Mixed Methods"",
""approach"": ""string"",
""sampleSize"": ""string"",
""dataCollection"": ""string""
yFindings"": [
{
""finding"": ""string"",
""significance"": ""string"",
""confidence"": ""High|Medium|Low""
}
mitations"": [""string""],
tureWork"": [""string""],
ywords"": [""string""]
extracting verifiable claims and noting uncertainty.
NLY valid JSON."
Dim extractionResult As String = Await pdf.Query(researchQuery)
Try
Dim research = JsonSerializer.Deserialize(Of JsonElement)(extractionResult)
Dim formatted As String = JsonSerializer.Serialize(research, New JsonSerializerOptions With {.WriteIndented = True})
Console.WriteLine("Research Paper Extraction:")
Console.WriteLine(formatted)
File.WriteAllText("research-extraction.json", formatted)
' Display key findings with confidence levels
Console.WriteLine(vbCrLf & "=== Key Findings ===")
For Each finding In research.GetProperty("keyFindings").EnumerateArray()
Dim confidence As String = finding.GetProperty("confidence").GetString() OrElse "Unknown"
Console.WriteLine($"[{confidence}] {finding.GetProperty("finding")}")
Next
Catch ex As JsonException
Console.WriteLine("Unable to parse research extraction")
File.WriteAllText("research-raw.txt", extractionResult)
End Try自定义提示将人工智能驱动的提取从通用工具转变为针对您的特定需求量身定制的专业解决方案。
文档问答
构建 PDF 问答系统
问题解答系统使用户能够与 PDF 文档进行对话式交互,用自然语言提出问题并获得准确的上下文答案。 基本模式包括从 PDF 中提取文本,在提示中将文本与用户的问题相结合,然后请求人工智能给出答案。
输入
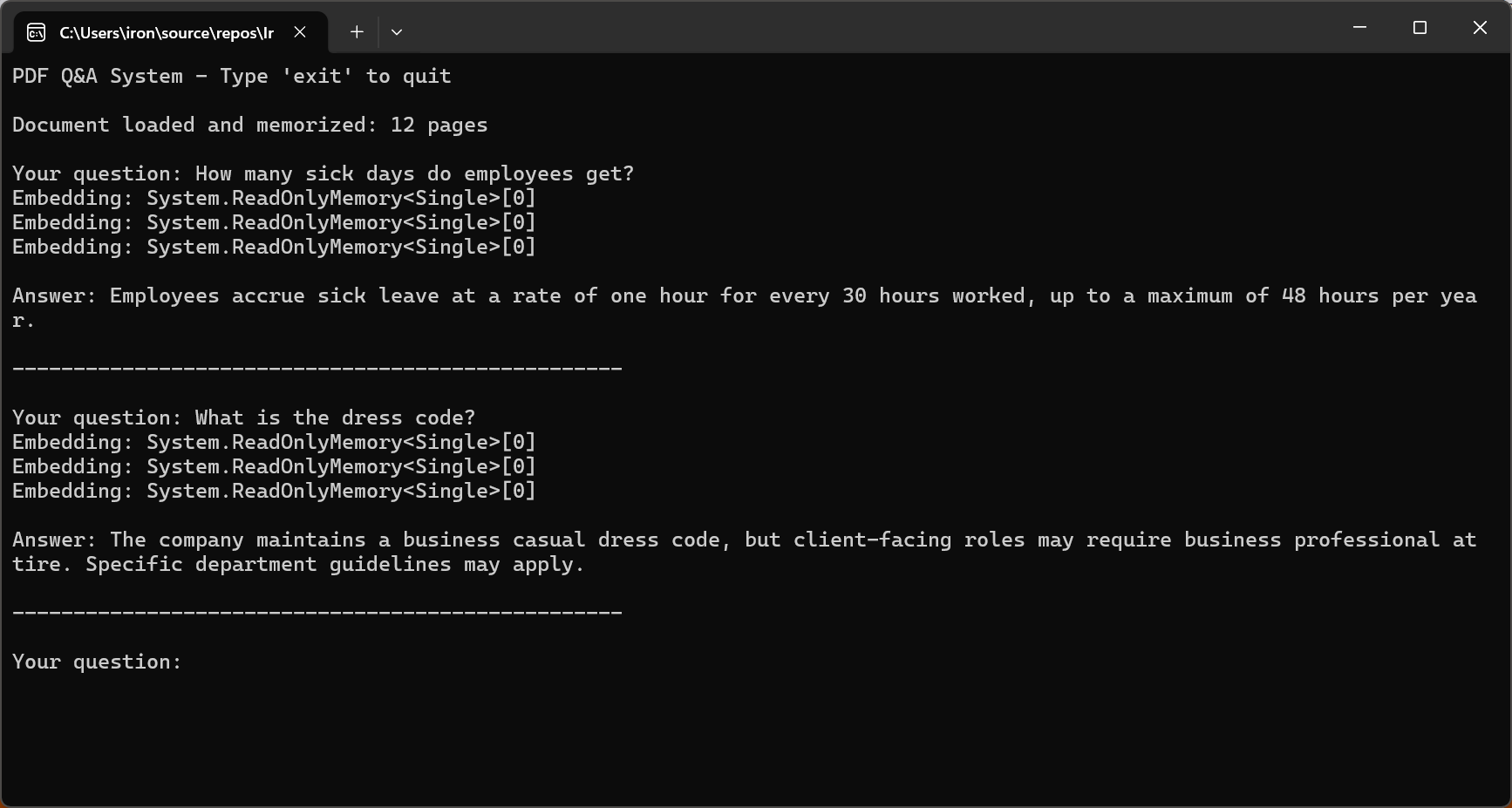
该代码调用 pdf.Memorize() 对文档进行语义搜索索引,然后使用 pdf.Query() 进入交互式循环来回答用户问题。
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/pdf-question-answering.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
// Interactive Q&A system for querying PDF documents
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
var pdf = PdfDocument.FromFile("sample-legal-document.pdf");
// Memorize document to enable persistent querying
await pdf.Memorize();
Console.WriteLine("PDF Q&A System - Type 'exit' to quit\n");
Console.WriteLine($"Document loaded and memorized: {pdf.PageCount} pages\n");
// Interactive Q&A loop
while (true)
{
Console.Write("Your question: ");
string? question = Console.ReadLine();
if (string.IsNullOrWhiteSpace(question) || question.ToLower() == "exit")
break;
string answer = await pdf.Query(question);
Console.WriteLine($"\nAnswer: {answer}\n");
Console.WriteLine(new string('-', 50) + "\n");
}
Console.WriteLine("Q&A session ended.");Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
' Interactive Q&A system for querying PDF documents
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
Dim pdf = PdfDocument.FromFile("sample-legal-document.pdf")
' Memorize document to enable persistent querying
Await pdf.Memorize()
Console.WriteLine("PDF Q&A System - Type 'exit' to quit" & vbCrLf)
Console.WriteLine($"Document loaded and memorized: {pdf.PageCount} pages" & vbCrLf)
' Interactive Q&A loop
While True
Console.Write("Your question: ")
Dim question As String = Console.ReadLine()
If String.IsNullOrWhiteSpace(question) OrElse question.ToLower() = "exit" Then
Exit While
End If
Dim answer As String = Await pdf.Query(question)
Console.WriteLine($"{vbCrLf}Answer: {answer}{vbCrLf}")
Console.WriteLine(New String("-"c, 50) & vbCrLf)
End While
Console.WriteLine("Q&A session ended.")控制台输出
2026 年有效问答的关键在于限制人工智能仅根据文档内容进行回答。 GPT-5 的 "安全完成 "训练方法和 Claude Sonnet 4.5 改进的对齐方式大大降低了幻听率。
为上下文窗口对长文档进行分块
现实世界中的大多数文档都超出了 AI 上下文窗口的范围。 有效的分块策略对于处理这些文档至关重要。 分块是指将文档分成足够小的片段,以适应上下文窗口,同时保持语义的连贯性。
此代码遍历 pdf.Pages,创建 DocumentChunk 对象,并配置 maxChunkTokens 和 overlapTokens 以实现上下文连续性。
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/semantic-document-chunking.csusing IronPdf;
// Split long documents into overlapping chunks for RAG systems
var pdf = PdfDocument.FromFile("long-document.pdf");
// Chunking configuration
int maxChunkTokens = 4000; // Leave room for prompts and responses
int overlapTokens = 200; // Overlap for context continuity
int approxCharsPerToken = 4; // Rough estimate for tokenization
int maxChunkChars = maxChunkTokens * approxCharsPerToken;
int overlapChars = overlapTokens * approxCharsPerToken;
var chunks = new List<DocumentChunk>();
var currentChunk = new System.Text.StringBuilder();
int chunkStartPage = 1;
int currentPage = 1;
for (int i = 0; i < pdf.PageCount; i++)
{
string pageText = pdf.Pages[i].Text;
currentPage = i + 1;
if (currentChunk.Length + pageText.Length > maxChunkChars && currentChunk.Length > 0)
{
chunks.Add(new DocumentChunk
{
Text = currentChunk.ToString(),
StartPage = chunkStartPage,
EndPage = currentPage - 1,
ChunkIndex = chunks.Count
});
// Create overlap with previous chunk for continuity
string overlap = currentChunk.Length > overlapChars
? currentChunk.ToString().Substring(currentChunk.Length - overlapChars)
: currentChunk.ToString();
currentChunk.Clear();
currentChunk.Append(overlap);
chunkStartPage = currentPage - 1;
}
currentChunk.AppendLine($"\n--- Page {currentPage} ---\n");
currentChunk.Append(pageText);
}
if (currentChunk.Length > 0)
{
chunks.Add(new DocumentChunk
{
Text = currentChunk.ToString(),
StartPage = chunkStartPage,
EndPage = currentPage,
ChunkIndex = chunks.Count
});
}
Console.WriteLine($"Document chunked into {chunks.Count} segments");
foreach (var chunk in chunks)
{
Console.WriteLine($" Chunk {chunk.ChunkIndex + 1}: Pages {chunk.StartPage}-{chunk.EndPage} ({chunk.Text.Length} chars)");
}
// Save chunk metadata for RAG indexing
File.WriteAllText("chunks-metadata.json", System.Text.Json.JsonSerializer.Serialize(
chunks.Select(c => new { c.ChunkIndex, c.StartPage, c.EndPage, Length = c.Text.Length }),
new System.Text.Json.JsonSerializerOptions { WriteIndented = true }
));
ic class DocumentChunk
public string Text { get; set; } = "";
public int StartPage { get; set; }
public int EndPage { get; set; }
public int ChunkIndex { get; set; }Imports IronPdf
Imports System.IO
Imports System.Text
Imports System.Text.Json
' Split long documents into overlapping chunks for RAG systems
Dim pdf = PdfDocument.FromFile("long-document.pdf")
' Chunking configuration
Dim maxChunkTokens As Integer = 4000 ' Leave room for prompts and responses
Dim overlapTokens As Integer = 200 ' Overlap for context continuity
Dim approxCharsPerToken As Integer = 4 ' Rough estimate for tokenization
Dim maxChunkChars As Integer = maxChunkTokens * approxCharsPerToken
Dim overlapChars As Integer = overlapTokens * approxCharsPerToken
Dim chunks As New List(Of DocumentChunk)()
Dim currentChunk As New StringBuilder()
Dim chunkStartPage As Integer = 1
Dim currentPage As Integer = 1
For i As Integer = 0 To pdf.PageCount - 1
Dim pageText As String = pdf.Pages(i).Text
currentPage = i + 1
If currentChunk.Length + pageText.Length > maxChunkChars AndAlso currentChunk.Length > 0 Then
chunks.Add(New DocumentChunk With {
.Text = currentChunk.ToString(),
.StartPage = chunkStartPage,
.EndPage = currentPage - 1,
.ChunkIndex = chunks.Count
})
' Create overlap with previous chunk for continuity
Dim overlap As String = If(currentChunk.Length > overlapChars,
currentChunk.ToString().Substring(currentChunk.Length - overlapChars),
currentChunk.ToString())
currentChunk.Clear()
currentChunk.Append(overlap)
chunkStartPage = currentPage - 1
End If
currentChunk.AppendLine(vbCrLf & "--- Page " & currentPage & " ---" & vbCrLf)
currentChunk.Append(pageText)
Next
If currentChunk.Length > 0 Then
chunks.Add(New DocumentChunk With {
.Text = currentChunk.ToString(),
.StartPage = chunkStartPage,
.EndPage = currentPage,
.ChunkIndex = chunks.Count
})
End If
Console.WriteLine($"Document chunked into {chunks.Count} segments")
For Each chunk In chunks
Console.WriteLine($" Chunk {chunk.ChunkIndex + 1}: Pages {chunk.StartPage}-{chunk.EndPage} ({chunk.Text.Length} chars)")
Next
' Save chunk metadata for RAG indexing
File.WriteAllText("chunks-metadata.json", JsonSerializer.Serialize(
chunks.Select(Function(c) New With {.ChunkIndex = c.ChunkIndex, .StartPage = c.StartPage, .EndPage = c.EndPage, .Length = c.Text.Length}),
New JsonSerializerOptions With {.WriteIndented = True}
))
Public Class DocumentChunk
Public Property Text As String = ""
Public Property StartPage As Integer
Public Property EndPage As Integer
Public Property ChunkIndex As Integer
End Class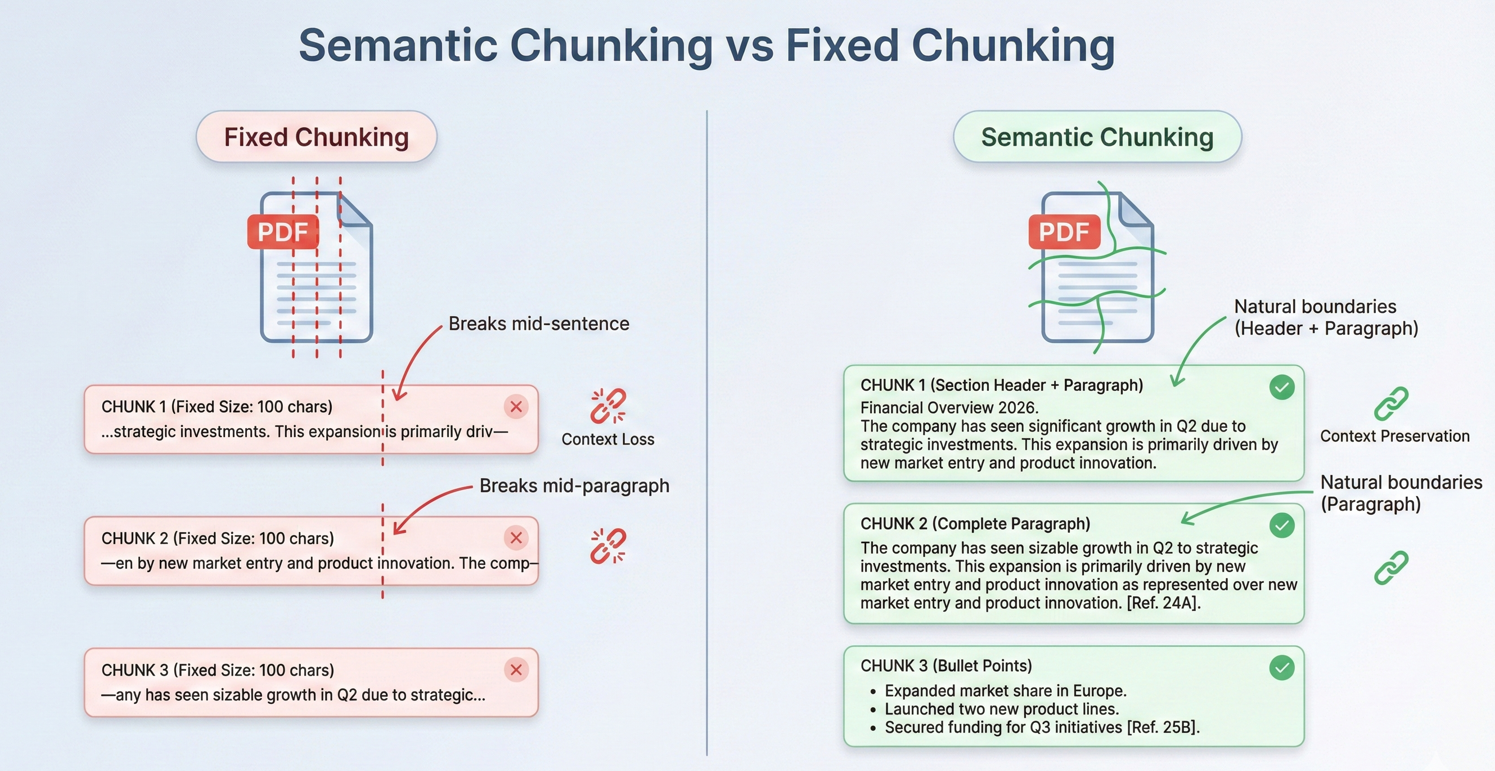
重叠的语块提供了跨边界的连续性,即使相关信息跨越语块边界,也能确保人工智能有足够的上下文。
RAG(检索-增强生成)模式
检索-增强生成是 2026 年人工智能驱动的文档分析的一种强大模式。RAG 系统不是将整个文档提供给人工智能,而是首先检索特定查询的相关部分,然后将这些部分作为生成答案的上下文。
RAG 工作流程有三个主要阶段:文档准备(分块和创建嵌入)、检索(搜索相关块)和生成(使用检索到的块作为人工智能响应的上下文)。
该代码通过对每个 PDF 调用 pdf.Memorize() 来建立多个 PDF 的索引,然后使用 pdf.Query() 从合并的文档内存中检索答案。
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/rag-system-implementation.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
// Retrieval-Augmented Generation (RAG) system for querying across multiple indexed documents
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
// Index all documents in folder
string[] documentPaths = Directory.GetFiles("documents/", "*.pdf");
Console.WriteLine($"Indexing {documentPaths.Length} documents...\n");
// Memorize each document (creates embeddings for retrieval)
foreach (string path in documentPaths)
{
var pdf = PdfDocument.FromFile(path);
await pdf.Memorize();
Console.WriteLine($"Indexed: {Path.GetFileName(path)} ({pdf.PageCount} pages)");
}
Console.WriteLine("\n=== RAG System Ready ===\n");
// Query across all indexed documents
string query = "What are the key compliance requirements for data retention?";
Console.WriteLine($"Query: {query}\n");
var searchPdf = PdfDocument.FromFile(documentPaths[0]);
string answer = await searchPdf.Query(query);
Console.WriteLine($"Answer: {answer}");
// Interactive query loop
Console.WriteLine("\n--- Enter questions (type 'exit' to quit) ---\n");
while (true)
{
Console.Write("Question: ");
string? userQuery = Console.ReadLine();
if (string.IsNullOrWhiteSpace(userQuery) || userQuery.ToLower() == "exit")
break;
string response = await searchPdf.Query(userQuery);
Console.WriteLine($"\nAnswer: {response}\n");
}Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.IO
' Retrieval-Augmented Generation (RAG) system for querying across multiple indexed documents
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
' Index all documents in folder
Dim documentPaths As String() = Directory.GetFiles("documents/", "*.pdf")
Console.WriteLine($"Indexing {documentPaths.Length} documents..." & vbCrLf)
' Memorize each document (creates embeddings for retrieval)
For Each path As String In documentPaths
Dim pdf = PdfDocument.FromFile(path)
Await pdf.Memorize()
Console.WriteLine($"Indexed: {Path.GetFileName(path)} ({pdf.PageCount} pages)")
Next
Console.WriteLine(vbCrLf & "=== RAG System Ready ===" & vbCrLf)
' Query across all indexed documents
Dim query As String = "What are the key compliance requirements for data retention?"
Console.WriteLine($"Query: {query}" & vbCrLf)
Dim searchPdf = PdfDocument.FromFile(documentPaths(0))
Dim answer As String = Await searchPdf.Query(query)
Console.WriteLine($"Answer: {answer}")
' Interactive query loop
Console.WriteLine(vbCrLf & "--- Enter questions (type 'exit' to quit) ---" & vbCrLf)
While True
Console.Write("Question: ")
Dim userQuery As String = Console.ReadLine()
If String.IsNullOrWhiteSpace(userQuery) OrElse userQuery.ToLower() = "exit" Then
Exit While
End If
Dim response As String = Await searchPdf.Query(userQuery)
Console.WriteLine(vbCrLf & $"Answer: {response}" & vbCrLf)
End WhileRAG 系统擅长处理大型文档库--法律案例数据库、技术文档库和研究档案库。 通过只检索相关部分,他们在保持响应质量的同时,还能有效地扩展到无限的文档大小。
从 PDF 页面引用来源
对于专业应用,人工智能答案必须是可验证的。 引用方法包括在分块和检索过程中维护有关分块来源的元数据。 每个语块不仅存储文本内容,还存储其源页码、章节标题和在文档中的位置。
输入
该代码使用 pdf.Query() 进行引用说明,然后使用正则表达式调用 ExtractCitedPages() 来解析页面引用,并使用 pdf.Pages[pageNum - 1].Text 来验证来源。
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/answer-with-citations.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System.Text.RegularExpressions;
// Answer questions with page citations and source verification
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
var pdf = PdfDocument.FromFile("sample-legal-document.pdf");
await pdf.Memorize();
string question = "What are the termination conditions in this agreement?";
// Request citations in query
string citationQuery = $@"{question}
T: Include specific page citations in your answer using the format (Page X) or (Pages X-Y).
e information that appears in the document.";
string answerWithCitations = await pdf.Query(citationQuery);
Console.WriteLine("Question: " + question);
Console.WriteLine("\nAnswer with Citations:");
Console.WriteLine(answerWithCitations);
// Extract cited page numbers using regex
var citedPages = ExtractCitedPages(answerWithCitations);
Console.WriteLine($"\nCited pages: {string.Join(", ", citedPages)}");
// Verify citations with page excerpts
Console.WriteLine("\n=== Source Verification ===");
foreach (int pageNum in citedPages.Take(3))
{
if (pageNum <= pdf.PageCount && pageNum > 0)
{
string pageText = pdf.Pages[pageNum - 1].Text;
string excerpt = pageText.Length > 200 ? pageText.Substring(0, 200) + "..." : pageText;
Console.WriteLine($"\nPage {pageNum} excerpt:\n{excerpt}");
}
}
// Extract page numbers from citation format (Page X) or (Pages X-Y)
List<int> ExtractCitedPages(string text)
{
var pages = new HashSet<int>();
var matches = Regex.Matches(text, @"\(Pages?\s*(\d+)(?:\s*-\s*(\d+))?\)", RegexOptions.IgnoreCase);
foreach (Match match in matches)
{
int startPage = int.Parse(match.Groups[1].Value);
pages.Add(startPage);
if (match.Groups[2].Success)
{
int endPage = int.Parse(match.Groups[2].Value);
for (int p = startPage; p <= endPage; p++)
pages.Add(p);
}
}
return pages.OrderBy(p => p).ToList();
}Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.Text.RegularExpressions
' Answer questions with page citations and source verification
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
Dim pdf = PdfDocument.FromFile("sample-legal-document.pdf")
Await pdf.Memorize()
Dim question As String = "What are the termination conditions in this agreement?"
' Request citations in query
Dim citationQuery As String = $"{question}
T: Include specific page citations in your answer using the format (Page X) or (Pages X-Y).
e information that appears in the document."
Dim answerWithCitations As String = Await pdf.Query(citationQuery)
Console.WriteLine("Question: " & question)
Console.WriteLine(vbCrLf & "Answer with Citations:")
Console.WriteLine(answerWithCitations)
' Extract cited page numbers using regex
Dim citedPages = ExtractCitedPages(answerWithCitations)
Console.WriteLine(vbCrLf & "Cited pages: " & String.Join(", ", citedPages))
' Verify citations with page excerpts
Console.WriteLine(vbCrLf & "=== Source Verification ===")
For Each pageNum As Integer In citedPages.Take(3)
If pageNum <= pdf.PageCount AndAlso pageNum > 0 Then
Dim pageText As String = pdf.Pages(pageNum - 1).Text
Dim excerpt As String = If(pageText.Length > 200, pageText.Substring(0, 200) & "...", pageText)
Console.WriteLine(vbCrLf & "Page " & pageNum & " excerpt:" & vbCrLf & excerpt)
End If
Next
' Extract page numbers from citation format (Page X) or (Pages X-Y)
Function ExtractCitedPages(ByVal text As String) As List(Of Integer)
Dim pages = New HashSet(Of Integer)()
Dim matches = Regex.Matches(text, "\((Pages?)\s*(\d+)(?:\s*-\s*(\d+))?\)", RegexOptions.IgnoreCase)
For Each match As Match In matches
Dim startPage As Integer = Integer.Parse(match.Groups(2).Value)
pages.Add(startPage)
If match.Groups(3).Success Then
Dim endPage As Integer = Integer.Parse(match.Groups(3).Value)
For p As Integer = startPage To endPage
pages.Add(p)
Next
End If
Next
Return pages.OrderBy(Function(p) p).ToList()
End Function控制台输出
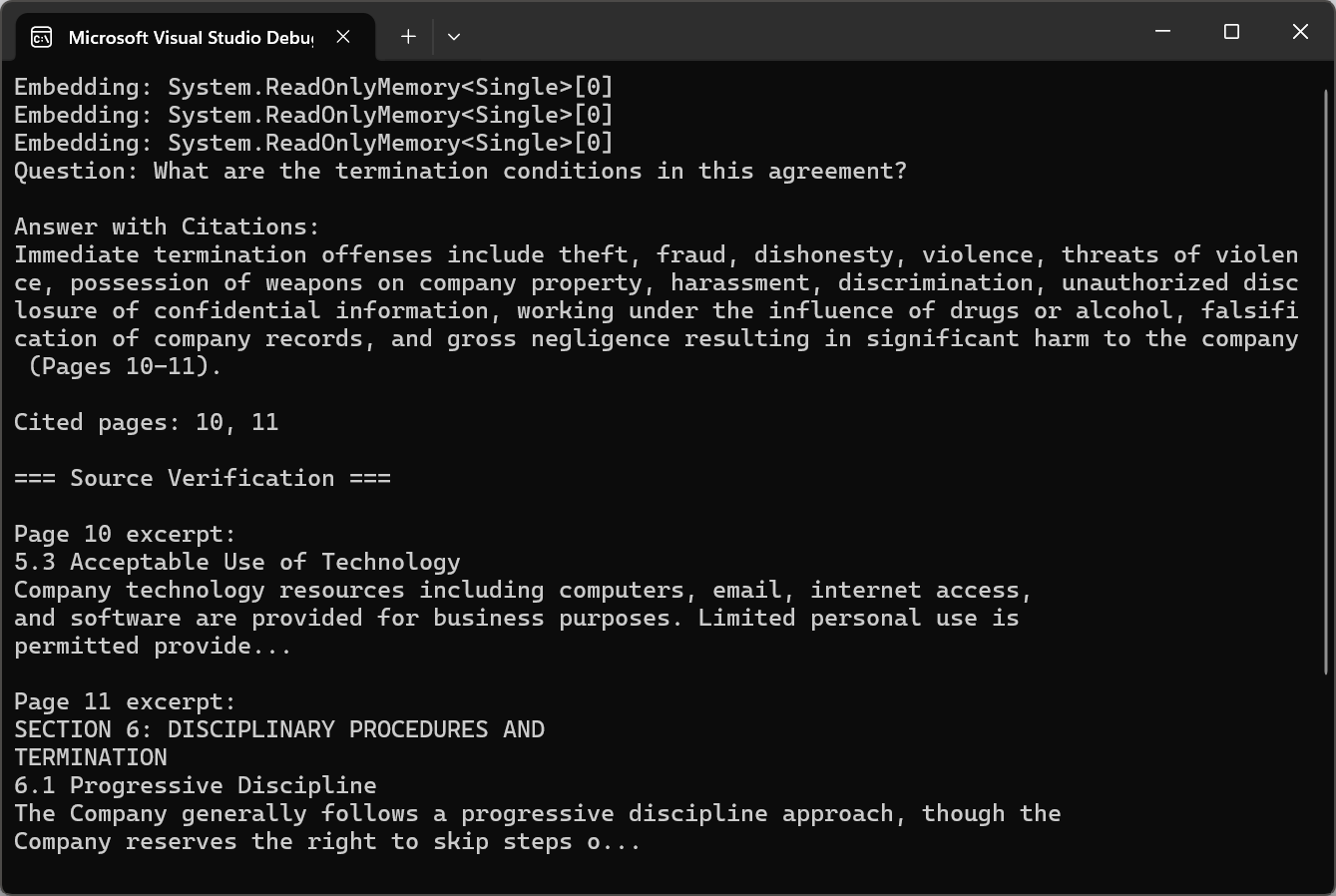
引用将人工智能生成的答案从不透明性输出转化为透明、可验证的信息。 用户可以查看源材料来验证答案,并建立对人工智能辅助分析的信心。
批量人工智能处理
大规模处理文档库
企业文档处理通常涉及数千或数百万个 PDF。 可扩展批处理的基础是并行化。 IronPDF 是线程安全的,允许不受干扰地并发处理 PDF。
此代码使用 SemaphoreSlim 和可配置的 maxConcurrency 并行处理 PDF,对每个 PDF 调用 pdf.Summarize(),同时跟踪结果为 ConcurrentBag。
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/batch-document-processing.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System;
using System.Collections.Concurrent;
using System.Text;
// Process multiple documents in parallel with rate limiting
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
// Configure parallel processing with rate limiting
int maxConcurrency = 3;
string inputFolder = "documents/";
string outputFolder = "summaries/";
Directory.CreateDirectory(outputFolder);
string[] pdfFiles = Directory.GetFiles(inputFolder, "*.pdf");
Console.WriteLine($"Processing {pdfFiles.Length} documents...\n");
var results = new ConcurrentBag<ProcessingResult>();
var semaphore = new SemaphoreSlim(maxConcurrency);
var tasks = pdfFiles.Select(async filePath =>
{
await semaphore.WaitAsync();
var result = new ProcessingResult { FilePath = filePath };
try
{
var stopwatch = System.Diagnostics.Stopwatch.StartNew();
var pdf = PdfDocument.FromFile(filePath);
string summary = await pdf.Summarize();
string outputPath = Path.Combine(outputFolder,
Path.GetFileNameWithoutExtension(filePath) + "-summary.txt");
await File.WriteAllTextAsync(outputPath, summary);
stopwatch.Stop();
result.Success = true;
result.ProcessingTime = stopwatch.Elapsed;
result.OutputPath = outputPath;
Console.WriteLine($"[OK] {Path.GetFileName(filePath)} ({stopwatch.ElapsedMilliseconds}ms)");
}
catch (Exception ex)
{
result.Success = false;
result.ErrorMessage = ex.Message;
Console.WriteLine($"[ERROR] {Path.GetFileName(filePath)}: {ex.Message}");
}
finally
{
semaphore.Release();
results.Add(result);
}
}).ToArray();
await Task.WhenAll(tasks);
// Generate processing report
var successful = results.Where(r => r.Success).ToList();
var failed = results.Where(r => !r.Success).ToList();
var report = new StringBuilder();
report.AppendLine("=== Batch Processing Report ===");
report.AppendLine($"Successful: {successful.Count}");
report.AppendLine($"Failed: {failed.Count}");
if (successful.Any())
{
var avgTime = TimeSpan.FromMilliseconds(successful.Average(r => r.ProcessingTime.TotalMilliseconds));
report.AppendLine($"Average processing time: {avgTime.TotalSeconds:F1}s");
}
if (failed.Any())
{
report.AppendLine("\nFailed documents:");
foreach (var fail in failed)
report.AppendLine($" - {Path.GetFileName(fail.FilePath)}: {fail.ErrorMessage}");
}
string reportText = report.ToString();
Console.WriteLine($"\n{reportText}");
File.WriteAllText(Path.Combine(outputFolder, "processing-report.txt"), reportText);
s ProcessingResult
public string FilePath { get; set; } = "";
public bool Success { get; set; }
public TimeSpan ProcessingTime { get; set; }
public string OutputPath { get; set; } = "";
public string ErrorMessage { get; set; } = "";Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System
Imports System.Collections.Concurrent
Imports System.Text
Imports System.IO
Imports System.Linq
Imports System.Threading
Imports System.Threading.Tasks
' Process multiple documents in parallel with rate limiting
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
' Configure parallel processing with rate limiting
Dim maxConcurrency As Integer = 3
Dim inputFolder As String = "documents/"
Dim outputFolder As String = "summaries/"
Directory.CreateDirectory(outputFolder)
Dim pdfFiles As String() = Directory.GetFiles(inputFolder, "*.pdf")
Console.WriteLine($"Processing {pdfFiles.Length} documents...{vbCrLf}")
Dim results = New ConcurrentBag(Of ProcessingResult)()
Dim semaphore = New SemaphoreSlim(maxConcurrency)
Dim tasks = pdfFiles.Select(Async Function(filePath)
Await semaphore.WaitAsync()
Dim result = New ProcessingResult With {.FilePath = filePath}
Try
Dim stopwatch = System.Diagnostics.Stopwatch.StartNew()
Dim pdf = PdfDocument.FromFile(filePath)
Dim summary As String = Await pdf.Summarize()
Dim outputPath = Path.Combine(outputFolder, Path.GetFileNameWithoutExtension(filePath) & "-summary.txt")
Await File.WriteAllTextAsync(outputPath, summary)
stopwatch.Stop()
result.Success = True
result.ProcessingTime = stopwatch.Elapsed
result.OutputPath = outputPath
Console.WriteLine($"[OK] {Path.GetFileName(filePath)} ({stopwatch.ElapsedMilliseconds}ms)")
Catch ex As Exception
result.Success = False
result.ErrorMessage = ex.Message
Console.WriteLine($"[ERROR] {Path.GetFileName(filePath)}: {ex.Message}")
Finally
semaphore.Release()
results.Add(result)
End Try
End Function).ToArray()
Await Task.WhenAll(tasks)
' Generate processing report
Dim successful = results.Where(Function(r) r.Success).ToList()
Dim failed = results.Where(Function(r) Not r.Success).ToList()
Dim report = New StringBuilder()
report.AppendLine("=== Batch Processing Report ===")
report.AppendLine($"Successful: {successful.Count}")
report.AppendLine($"Failed: {failed.Count}")
If successful.Any() Then
Dim avgTime = TimeSpan.FromMilliseconds(successful.Average(Function(r) r.ProcessingTime.TotalMilliseconds))
report.AppendLine($"Average processing time: {avgTime.TotalSeconds:F1}s")
End If
If failed.Any() Then
report.AppendLine($"{vbCrLf}Failed documents:")
For Each fail In failed
report.AppendLine($" - {Path.GetFileName(fail.FilePath)}: {fail.ErrorMessage}")
Next
End If
Dim reportText As String = report.ToString()
Console.WriteLine($"{vbCrLf}{reportText}")
File.WriteAllText(Path.Combine(outputFolder, "processing-report.txt"), reportText)
Public Class ProcessingResult
Public Property FilePath As String = ""
Public Property Success As Boolean
Public Property ProcessingTime As TimeSpan
Public Property OutputPath As String = ""
Public Property ErrorMessage As String = ""
End Class强大的错误处理能力对于大规模翻译至关重要。 生产系统采用指数式回退重试逻辑、失败文档的单独错误日志记录以及可恢复处理。
成本管理和令牌使用
人工智能应用程序接口费用通常按令牌收取。 2026 年,GPT-5 的价格为每百万输入代币 1.25 美元,每百万输出代币 10 美元,而 Claude Sonnet 4.5 的价格为每百万输入代币 3 美元,每百万输出代币 15 美元。 主要的成本优化策略是尽量减少不必要的标记使用。
OpenAI 的批量 API 提供 50% 的令牌费用折扣,以换取更长的处理时间(最长 24 小时)。 对于隔夜处理或定期分析,批处理可节省大量成本。
该代码使用 pdf.ExtractAllText() 提取文本,创建 JSONL 批量请求,通过 HttpClient 上传到 OpenAI 文件端点,并提交到批量 API。
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/batch-api-processing.csusing IronPdf;
using System.Text.Json;
using System.Net.Http.Headers;
// Use OpenAI Batch API for 50% cost savings on large-scale document processing
string openAiApiKey = "your-openai-api-key";
string inputFolder = "documents/";
// Prepare batch requests in JSONL format
var batchRequests = new List<string>();
string[] pdfFiles = Directory.GetFiles(inputFolder, "*.pdf");
Console.WriteLine($"Preparing batch for {pdfFiles.Length} documents...\n");
foreach (string filePath in pdfFiles)
{
var pdf = PdfDocument.FromFile(filePath);
string pdfText = pdf.ExtractAllText();
// Truncate to stay within batch API limits
if (pdfText.Length > 100000)
pdfText = pdfText.Substring(0, 100000) + "\n[Truncated...]";
var request = new
{
custom_id = Path.GetFileNameWithoutExtension(filePath),
method = "POST",
url = "/v1/chat/completions",
body = new
{
model = "gpt-4o",
messages = new[]
{
new { role = "system", content = "Summarize the following document concisely." },
new { role = "user", content = pdfText }
},
max_tokens = 1000
}
};
batchRequests.Add(JsonSerializer.Serialize(request));
}
// Create JSONL file
string batchFilePath = "batch-requests.jsonl";
File.WriteAllLines(batchFilePath, batchRequests);
Console.WriteLine($"Created batch file with {batchRequests.Count} requests");
// Upload file to OpenAI
using var httpClient = new HttpClient();
httpClient.DefaultRequestHeaders.Authorization = new AuthenticationHeaderValue("Bearer", openAiApiKey);
using var fileContent = new MultipartFormDataContent();
fileContent.Add(new ByteArrayContent(File.ReadAllBytes(batchFilePath)), "file", "batch-requests.jsonl");
fileContent.Add(new StringContent("batch"), "purpose");
var uploadResponse = await httpClient.PostAsync("https://api.openai.com/v1/files", fileContent);
var uploadResult = JsonSerializer.Deserialize<JsonElement>(await uploadResponse.Content.ReadAsStringAsync());
string fileId = uploadResult.GetProperty("id").GetString()!;
Console.WriteLine($"Uploaded file: {fileId}");
// Create batch job (24-hour completion window for 50% discount)
var batchJobRequest = new
{
input_file_id = fileId,
endpoint = "/v1/chat/completions",
completion_window = "24h"
};
var batchResponse = await httpClient.PostAsync(
"https://api.openai.com/v1/batches",
new StringContent(JsonSerializer.Serialize(batchJobRequest), System.Text.Encoding.UTF8, "application/json")
);
var batchResult = JsonSerializer.Deserialize<JsonElement>(await batchResponse.Content.ReadAsStringAsync());
string batchId = batchResult.GetProperty("id").GetString()!;
Console.WriteLine($"\nBatch job created: {batchId}");
Console.WriteLine("Job will complete within 24 hours");
Console.WriteLine($"Check status: GET https://api.openai.com/v1/batches/{batchId}");
File.WriteAllText("batch-job-id.txt", batchId);
Console.WriteLine("\nBatch ID saved to batch-job-id.txt");Imports IronPdf
Imports System.Text.Json
Imports System.Net.Http.Headers
' Use OpenAI Batch API for 50% cost savings on large-scale document processing
Dim openAiApiKey As String = "your-openai-api-key"
Dim inputFolder As String = "documents/"
' Prepare batch requests in JSONL format
Dim batchRequests As New List(Of String)()
Dim pdfFiles As String() = Directory.GetFiles(inputFolder, "*.pdf")
Console.WriteLine($"Preparing batch for {pdfFiles.Length} documents..." & vbCrLf)
For Each filePath As String In pdfFiles
Dim pdf = PdfDocument.FromFile(filePath)
Dim pdfText As String = pdf.ExtractAllText()
' Truncate to stay within batch API limits
If pdfText.Length > 100000 Then
pdfText = pdfText.Substring(0, 100000) & vbCrLf & "[Truncated...]"
End If
Dim request = New With {
.custom_id = Path.GetFileNameWithoutExtension(filePath),
.method = "POST",
.url = "/v1/chat/completions",
.body = New With {
.model = "gpt-4o",
.messages = New Object() {
New With {.role = "system", .content = "Summarize the following document concisely."},
New With {.role = "user", .content = pdfText}
},
.max_tokens = 1000
}
}
batchRequests.Add(JsonSerializer.Serialize(request))
Next
' Create JSONL file
Dim batchFilePath As String = "batch-requests.jsonl"
File.WriteAllLines(batchFilePath, batchRequests)
Console.WriteLine($"Created batch file with {batchRequests.Count} requests")
' Upload file to OpenAI
Using httpClient As New HttpClient()
httpClient.DefaultRequestHeaders.Authorization = New AuthenticationHeaderValue("Bearer", openAiApiKey)
Using fileContent As New MultipartFormDataContent()
fileContent.Add(New ByteArrayContent(File.ReadAllBytes(batchFilePath)), "file", "batch-requests.jsonl")
fileContent.Add(New StringContent("batch"), "purpose")
Dim uploadResponse = Await httpClient.PostAsync("https://api.openai.com/v1/files", fileContent)
Dim uploadResult = JsonSerializer.Deserialize(Of JsonElement)(Await uploadResponse.Content.ReadAsStringAsync())
Dim fileId As String = uploadResult.GetProperty("id").GetString()
Console.WriteLine($"Uploaded file: {fileId}")
' Create batch job (24-hour completion window for 50% discount)
Dim batchJobRequest = New With {
.input_file_id = fileId,
.endpoint = "/v1/chat/completions",
.completion_window = "24h"
}
Dim batchResponse = Await httpClient.PostAsync(
"https://api.openai.com/v1/batches",
New StringContent(JsonSerializer.Serialize(batchJobRequest), System.Text.Encoding.UTF8, "application/json")
)
Dim batchResult = JsonSerializer.Deserialize(Of JsonElement)(Await batchResponse.Content.ReadAsStringAsync())
Dim batchId As String = batchResult.GetProperty("id").GetString()
Console.WriteLine(vbCrLf & $"Batch job created: {batchId}")
Console.WriteLine("Job will complete within 24 hours")
Console.WriteLine($"Check status: GET https://api.openai.com/v1/batches/{batchId}")
File.WriteAllText("batch-job-id.txt", batchId)
Console.WriteLine(vbCrLf & "Batch ID saved to batch-job-id.txt")
End Using
End Using必须监控生产中的令牌使用情况。 许多组织发现,他们 80% 的文档都可以用较小、较便宜的模型来处理,只有在复杂情况下才使用昂贵的模型。
缓存和增量处理
对于增量更新的文档集,智能缓存和增量处理策略可显著降低成本。 文档级缓存可将结果与源 PDF 的哈希值一起存储,从而避免对未更改的文档进行不必要的重新处理。
DocumentCacheManager 类使用 ComputeFileHash() 和 SHA256 来检测更改,并将结果存储在带有 CacheEntry 时间戳的 LastAccessed 对象中。
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/incremental-caching.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System;
using System.Collections.Generic;
using System.Security.Cryptography;
using System.Text.Json;
// Cache AI processing results using file hashes to avoid reprocessing unchanged documents
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
// Configure caching
string cacheFolder = "ai-cache/";
string documentsFolder = "documents/";
Directory.CreateDirectory(cacheFolder);
var cacheManager = new DocumentCacheManager(cacheFolder);
// Process documents with caching
string[] pdfFiles = Directory.GetFiles(documentsFolder, "*.pdf");
int cached = 0, processed = 0;
foreach (string filePath in pdfFiles)
{
string fileName = Path.GetFileName(filePath);
string fileHash = cacheManager.ComputeFileHash(filePath);
var cachedResult = cacheManager.GetCachedResult(fileName, fileHash);
if (cachedResult != null)
{
Console.WriteLine($"[CACHE HIT] {fileName}");
cached++;
continue;
}
Console.WriteLine($"[PROCESSING] {fileName}");
var pdf = PdfDocument.FromFile(filePath);
string summary = await pdf.Summarize();
cacheManager.CacheResult(fileName, fileHash, summary);
processed++;
}
Console.WriteLine($"\nProcessing complete: {cached} cached, {processed} newly processed");
Console.WriteLine($"Cost savings: {(cached * 100.0 / Math.Max(1, cached + processed)):F1}% served from cache");
ash-based cache manager with JSON index
s DocumentCacheManager
private readonly string _cacheFolder;
private readonly string _indexPath;
private Dictionary<string, CacheEntry> _index;
public DocumentCacheManager(string cacheFolder)
{
_cacheFolder = cacheFolder;
_indexPath = Path.Combine(cacheFolder, "cache-index.json");
_index = LoadIndex();
}
private Dictionary<string, CacheEntry> LoadIndex()
{
if (File.Exists(_indexPath))
{
string json = File.ReadAllText(_indexPath);
return JsonSerializer.Deserialize<Dictionary<string, CacheEntry>>(json) ?? new();
}
return new Dictionary<string, CacheEntry>();
}
private void SaveIndex()
{
string json = JsonSerializer.Serialize(_index, new JsonSerializerOptions { WriteIndented = true });
File.WriteAllText(_indexPath, json);
}
// SHA256 hash to detect file changes
public string ComputeFileHash(string filePath)
{
using var sha256 = SHA256.Create();
using var stream = File.OpenRead(filePath);
byte[] hash = sha256.ComputeHash(stream);
return Convert.ToHexString(hash);
}
public string? GetCachedResult(string fileName, string currentHash)
{
if (_index.TryGetValue(fileName, out var entry))
{
if (entry.FileHash == currentHash && File.Exists(entry.CachePath))
{
entry.LastAccessed = DateTime.UtcNow;
SaveIndex();
return File.ReadAllText(entry.CachePath);
}
}
return null;
}
public void CacheResult(string fileName, string fileHash, string result)
{
string cachePath = Path.Combine(_cacheFolder, $"{Path.GetFileNameWithoutExtension(fileName)}-{fileHash[..8]}.txt");
File.WriteAllText(cachePath, result);
_index[fileName] = new CacheEntry
{
FileHash = fileHash,
CachePath = cachePath,
CreatedAt = DateTime.UtcNow,
LastAccessed = DateTime.UtcNow
};
SaveIndex();
}
s CacheEntry
public string FileHash { get; set; } = "";
public string CachePath { get; set; } = "";
public DateTime CreatedAt { get; set; }
public DateTime LastAccessed { get; set; }Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System
Imports System.Collections.Generic
Imports System.Security.Cryptography
Imports System.Text.Json
' Cache AI processing results using file hashes to avoid reprocessing unchanged documents
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
' Configure caching
Dim cacheFolder As String = "ai-cache/"
Dim documentsFolder As String = "documents/"
Directory.CreateDirectory(cacheFolder)
Dim cacheManager = New DocumentCacheManager(cacheFolder)
' Process documents with caching
Dim pdfFiles As String() = Directory.GetFiles(documentsFolder, "*.pdf")
Dim cached As Integer = 0, processed As Integer = 0
For Each filePath As String In pdfFiles
Dim fileName As String = Path.GetFileName(filePath)
Dim fileHash As String = cacheManager.ComputeFileHash(filePath)
Dim cachedResult As String = cacheManager.GetCachedResult(fileName, fileHash)
If cachedResult IsNot Nothing Then
Console.WriteLine($"[CACHE HIT] {fileName}")
cached += 1
Continue For
End If
Console.WriteLine($"[PROCESSING] {fileName}")
Dim pdf = PdfDocument.FromFile(filePath)
Dim summary As String = Await pdf.Summarize()
cacheManager.CacheResult(fileName, fileHash, summary)
processed += 1
Next
Console.WriteLine(vbCrLf & $"Processing complete: {cached} cached, {processed} newly processed")
Console.WriteLine($"Cost savings: {(cached * 100.0 / Math.Max(1, cached + processed)):F1}% served from cache")
' Hash-based cache manager with JSON index
Public Class DocumentCacheManager
Private ReadOnly _cacheFolder As String
Private ReadOnly _indexPath As String
Private _index As Dictionary(Of String, CacheEntry)
Public Sub New(cacheFolder As String)
_cacheFolder = cacheFolder
_indexPath = Path.Combine(cacheFolder, "cache-index.json")
_index = LoadIndex()
End Sub
Private Function LoadIndex() As Dictionary(Of String, CacheEntry)
If File.Exists(_indexPath) Then
Dim json As String = File.ReadAllText(_indexPath)
Return JsonSerializer.Deserialize(Of Dictionary(Of String, CacheEntry))(json) OrElse New Dictionary(Of String, CacheEntry)()
End If
Return New Dictionary(Of String, CacheEntry)()
End Function
Private Sub SaveIndex()
Dim json As String = JsonSerializer.Serialize(_index, New JsonSerializerOptions With {.WriteIndented = True})
File.WriteAllText(_indexPath, json)
End Sub
' SHA256 hash to detect file changes
Public Function ComputeFileHash(filePath As String) As String
Using sha256 = SHA256.Create()
Using stream = File.OpenRead(filePath)
Dim hash As Byte() = sha256.ComputeHash(stream)
Return Convert.ToHexString(hash)
End Using
End Using
End Function
Public Function GetCachedResult(fileName As String, currentHash As String) As String
If _index.TryGetValue(fileName, entry) Then
If entry.FileHash = currentHash AndAlso File.Exists(entry.CachePath) Then
entry.LastAccessed = DateTime.UtcNow
SaveIndex()
Return File.ReadAllText(entry.CachePath)
End If
End If
Return Nothing
End Function
Public Sub CacheResult(fileName As String, fileHash As String, result As String)
Dim cachePath As String = Path.Combine(_cacheFolder, $"{Path.GetFileNameWithoutExtension(fileName)}-{fileHash.Substring(0, 8)}.txt")
File.WriteAllText(cachePath, result)
_index(fileName) = New CacheEntry With {
.FileHash = fileHash,
.CachePath = cachePath,
.CreatedAt = DateTime.UtcNow,
.LastAccessed = DateTime.UtcNow
}
SaveIndex()
End Sub
End Class
Public Class CacheEntry
Public Property FileHash As String = ""
Public Property CachePath As String = ""
Public Property CreatedAt As DateTime
Public Property LastAccessed As DateTime
End ClassGPT-5 和 Claude Sonnet 4.5 in 2026 还具有自动提示缓存功能,可将重复模式的有效令牌消耗量减少 50-90%--这对于大规模运营而言是一项重大的成本节约。
真实的使用案例
法律发现和合同分析
法律取证传统上需要大量初级律师手动审阅成千上万页的文件。 人工智能驱动的发现转变了这一流程,能够快速识别相关文件、自动审查特权并提取关键证据事实。
IronPdf 的人工智能集成实现了复杂的法律工作流程:特权检测、相关性评分、问题识别和关键日期提取。 律师事务所报告称,发现审查时间缩短了 70-80%,使他们能够以较小的团队处理较大的案件。
2026 年,随着 GPT-5 和 Claude Sonnet 4.5 的准确性提高和幻听率降低,法律专业人士可以信赖人工智能辅助分析,做出越来越关键的决策。
财务报告分析
金融分析师花费大量时间从收益报告、美国证券交易委员会文件和分析师演示文稿中提取数据。 人工智能驱动的金融文档处理可自动完成提取工作,使分析人员能够专注于解释而非数据收集。
本示例处理多个 10-K 文件,使用 pdf.Query() 和 CompanyFinancials JSON 模式提取和比较各公司的收入、利润率和风险因素。
:path=/static-assets/pdf/content-code-examples/tutorials/ai-powered-pdf-processing-csharp/financial-sector-analysis.csusing IronPdf;
using IronPdf.AI;
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Memory;
using Microsoft.SemanticKernel.Connectors.OpenAI;
using System.Collections.Generic;
using System.Text.Json;
using System.Text;
// Compare financial metrics across multiple company filings for sector analysis
// Azure OpenAI configuration
string azureEndpoint = "https://your-resource.openai.azure.com/";
string apiKey = "your-azure-api-key";
string chatDeployment = "gpt-4o";
string embeddingDeployment = "text-embedding-ada-002";
// Initialize Semantic Kernel
var kernel = Kernel.CreateBuilder()
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey)
.Build();
var memory = new MemoryBuilder()
.WithMemoryStore(new VolatileMemoryStore())
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey)
.Build();
IronDocumentAI.Initialize(kernel, memory);
// Analyze company filings
string[] companyFilings = {
"filings/company-a-10k.pdf",
"filings/company-b-10k.pdf",
"filings/company-c-10k.pdf"
};
var sectorData = new List<CompanyFinancials>();
foreach (string filing in companyFilings)
{
Console.WriteLine($"Analyzing: {Path.GetFileName(filing)}");
var pdf = PdfDocument.FromFile(filing);
// Define JSON schema for 10-K extraction (numbers in millions USD)
string extractionQuery = @"Extract key financial metrics from this 10-K filing. Return JSON:
mpanyName"": ""string"",
scalYear"": ""string"",
venue"": number,
venueGrowth"": number,
ossMargin"": number,
eratingMargin"": number,
tIncome"": number,
s"": number,
talDebt"": number,
shPosition"": number,
ployeeCount"": number,
yRisks"": [""string""],
idance"": ""string""
in millions USD. Growth/margins as percentages.
NLY valid JSON.";
string result = await pdf.Query(extractionQuery);
try
{
var financials = JsonSerializer.Deserialize<CompanyFinancials>(result);
if (financials != null)
sectorData.Add(financials);
}
catch
{
Console.WriteLine($" Warning: Could not parse financials for {filing}");
}
}
// Generate sector comparison report
var report = new StringBuilder();
report.AppendLine("=== Sector Analysis Report ===\n");
report.AppendLine("Revenue Comparison (millions USD):");
foreach (var company in sectorData.OrderByDescending(c => c.Revenue))
report.AppendLine($" {company.CompanyName}: ${company.Revenue:N0} ({company.RevenueGrowth:+0.0;-0.0}% YoY)");
report.AppendLine("\nProfitability Margins:");
foreach (var company in sectorData.OrderByDescending(c => c.OperatingMargin))
report.AppendLine($" {company.CompanyName}: {company.GrossMargin:F1}% gross, {company.OperatingMargin:F1}% operating");
report.AppendLine("\nFinancial Health (Debt vs Cash):");
foreach (var company in sectorData)
{
double netDebt = company.TotalDebt - company.CashPosition;
string status = netDebt < 0 ? "Net Cash" : "Net Debt";
report.AppendLine($" {company.CompanyName}: {status} ${Math.Abs(netDebt):N0}M");
}
string reportText = report.ToString();
Console.WriteLine($"\n{reportText}");
File.WriteAllText("sector-analysis-report.txt", reportText);
// Save full JSON data
string outputJson = JsonSerializer.Serialize(sectorData, new JsonSerializerOptions { WriteIndented = true });
File.WriteAllText("sector-analysis.json", outputJson);
Console.WriteLine("Analysis saved to sector-analysis.json and sector-analysis-report.txt");
s CompanyFinancials
public string CompanyName { get; set; } = "";
public string FiscalYear { get; set; } = "";
public double Revenue { get; set; }
public double RevenueGrowth { get; set; }
public double GrossMargin { get; set; }
public double OperatingMargin { get; set; }
public double NetIncome { get; set; }
public double Eps { get; set; }
public double TotalDebt { get; set; }
public double CashPosition { get; set; }
public int EmployeeCount { get; set; }
public List<string> KeyRisks { get; set; } = new();
public string Guidance { get; set; } = "";Imports IronPdf
Imports IronPdf.AI
Imports Microsoft.SemanticKernel
Imports Microsoft.SemanticKernel.Memory
Imports Microsoft.SemanticKernel.Connectors.OpenAI
Imports System.Collections.Generic
Imports System.Text.Json
Imports System.Text
Imports System.IO
' Compare financial metrics across multiple company filings for sector analysis
' Azure OpenAI configuration
Dim azureEndpoint As String = "https://your-resource.openai.azure.com/"
Dim apiKey As String = "your-azure-api-key"
Dim chatDeployment As String = "gpt-4o"
Dim embeddingDeployment As String = "text-embedding-ada-002"
' Initialize Semantic Kernel
Dim kernel = Kernel.CreateBuilder() _
.AddAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.AddAzureOpenAIChatCompletion(chatDeployment, azureEndpoint, apiKey) _
.Build()
Dim memory = New MemoryBuilder() _
.WithMemoryStore(New VolatileMemoryStore()) _
.WithAzureOpenAITextEmbeddingGeneration(embeddingDeployment, azureEndpoint, apiKey) _
.Build()
IronDocumentAI.Initialize(kernel, memory)
' Analyze company filings
Dim companyFilings As String() = {
"filings/company-a-10k.pdf",
"filings/company-b-10k.pdf",
"filings/company-c-10k.pdf"
}
Dim sectorData = New List(Of CompanyFinancials)()
For Each filing As String In companyFilings
Console.WriteLine($"Analyzing: {Path.GetFileName(filing)}")
Dim pdf = PdfDocument.FromFile(filing)
' Define JSON schema for 10-K extraction (numbers in millions USD)
Dim extractionQuery As String = "Extract key financial metrics from this 10-K filing. Return JSON:
mpanyName"": ""string"",
scalYear"": ""string"",
venue"": number,
venueGrowth"": number,
ossMargin"": number,
eratingMargin"": number,
tIncome"": number,
s"": number,
talDebt"": number,
shPosition"": number,
ployeeCount"": number,
yRisks"": [""string""],
idance"": ""string""
in millions USD. Growth/margins as percentages.
NLY valid JSON."
Dim result As String = Await pdf.Query(extractionQuery)
Try
Dim financials = JsonSerializer.Deserialize(Of CompanyFinancials)(result)
If financials IsNot Nothing Then
sectorData.Add(financials)
End If
Catch
Console.WriteLine($" Warning: Could not parse financials for {filing}")
End Try
Next
' Generate sector comparison report
Dim report = New StringBuilder()
report.AppendLine("=== Sector Analysis Report ===" & vbCrLf)
report.AppendLine("Revenue Comparison (millions USD):")
For Each company In sectorData.OrderByDescending(Function(c) c.Revenue)
report.AppendLine($" {company.CompanyName}: ${company.Revenue:N0} ({company.RevenueGrowth:+0.0;-0.0}% YoY)")
Next
report.AppendLine(vbCrLf & "Profitability Margins:")
For Each company In sectorData.OrderByDescending(Function(c) c.OperatingMargin)
report.AppendLine($" {company.CompanyName}: {company.GrossMargin:F1}% gross, {company.OperatingMargin:F1}% operating")
Next
report.AppendLine(vbCrLf & "Financial Health (Debt vs Cash):")
For Each company In sectorData
Dim netDebt As Double = company.TotalDebt - company.CashPosition
Dim status As String = If(netDebt < 0, "Net Cash", "Net Debt")
report.AppendLine($" {company.CompanyName}: {status} ${Math.Abs(netDebt):N0}M")
Next
Dim reportText As String = report.ToString()
Console.WriteLine(vbCrLf & reportText)
File.WriteAllText("sector-analysis-report.txt", reportText)
' Save full JSON data
Dim outputJson As String = JsonSerializer.Serialize(sectorData, New JsonSerializerOptions With {.WriteIndented = True})
File.WriteAllText("sector-analysis.json", outputJson)
Console.WriteLine("Analysis saved to sector-analysis.json and sector-analysis-report.txt")
Public Class CompanyFinancials
Public Property CompanyName As String = ""
Public Property FiscalYear As String = ""
Public Property Revenue As Double
Public Property RevenueGrowth As Double
Public Property GrossMargin As Double
Public Property OperatingMargin As Double
Public Property NetIncome As Double
Public Property Eps As Double
Public Property TotalDebt As Double
Public Property CashPosition As Double
Public Property EmployeeCount As Integer
Public Property KeyRisks As List(Of String) = New List(Of String)()
Public Property Guidance As String = ""
End Class投资公司使用人工智能分析技术每天处理成千上万份文件,使分析师能够监控更广泛的市场覆盖范围,更快地应对新出现的机遇。
研究论文摘要
学术研究每年产生数百万篇论文。 由人工智能驱动的摘要可帮助研究人员快速评估论文相关性、了解关键研究结果并确定需要详细阅读的论文。 有效的研究总结必须明确研究问题、解释研究方法、总结主要发现并提出适当的注意事项,并将结果置于上下文中。
研究机构使用人工智能摘要维护机构知识库,自动处理新出版物。 2026 年,随着 GPT-5 科学推理能力的提高和 Claude Sonnet 4.5 分析能力的增强,学术总结的准确性将达到新的水平。
政府文件处理
政府机构制作大量文件集--法规、公众意见、环境影响报告、法庭文件、审计报告。 人工智能驱动的文档处理通过合规性分析、环境影响评估和立法跟踪,使政府信息具有可操作性。
公众意见分析带来了独特的挑战--重大监管提案可能会收到成千上万条意见。 人工智能系统可以按主题对评论进行分类,识别共同的主题,检测协调的活动,并提取值得机构回应的实质性论点。
2026 代人工智能模型为政府文件处理带来了前所未有的能力,支持民主透明和知情决策。
故障排除和技术支持
快速解决常见错误
- 首次呈现速度慢?正常。 Chrome 在 2–3 秒内初始化,然后加速。
- 云问题? 至少使用 Azure B1 或同等资源。
- 缺少资产?设置基本路径或嵌入为 base64。
- 缺少元素?为 JavaScript 的执行添加 RenderDelay。
- 内存问题?更新到最新的 IronPDF 版本以修复性能问题。
- 表格字段问题?确保名称唯一并更新到最新版本。
从 IronPDF 的工程师团队获得帮助,全天候提供服务
IronPdf 提供全天候工程师支持。 在将 HTML 转换为 PDF 或集成 AI 时遇到困难? 请联系我们:
下一步
现在您已经了解了人工智能驱动的 PDF 处理,下一步就是探索 IronPDF 更广泛的功能。 OpenAI集成指南对摘要、查询和记忆模式进行了更深入的介绍,而文本和图像提取教程则展示了如何在人工智能分析之前对PDF进行预处理。 对于文档装配工作流程,请学习如何合并和拆分 PDF 文件以进行批处理。
当您准备扩展 IronPDF 功能之外的功能时,完整的 PDF 编辑教程涵盖了水印、页眉、页脚、表单和注释。 关于其他人工智能集成方法,ChatGPT C# 教程 演示了不同的模式。 Azure 部署指南涉及 WebApps 和函数的生产部署,C# PDF 创建教程涉及从 HTML、URL 和原始内容生成 PDF。
准备好开始了吗? 开始 30 天免费试用,在无水印的情况下进行生产测试,灵活的 License 可根据团队规模进行扩展。 有关 IronPdf 集成或任何 IronPdf 功能的问题,我们的工程支持团队可提供帮助。
常见问题解答
在 C# 中使用人工智能进行 PDF 处理有哪些好处?
C# 中人工智能驱动的 PDF 处理可以实现文档摘要、数据提取到 JSON 以及构建问答系统等高级功能。它提高了处理大量文件的效率和准确性。
IronPDF 如何集成人工智能来总结文档?
IronPDF 通过利用 GPT-5 和 Claude 等模型集成了人工智能,这些模型可以对文档进行分析和总结,从而更容易获得洞察力并快速理解大量文本。
RAG 模式在人工智能驱动的 PDF 处理中的作用是什么?
RAG(检索和生成)模式用于人工智能驱动的 PDF 处理,以提高信息检索和生成的质量,从而实现更准确、更贴近上下文的文档分析。
如何使用 IronPDF 从 PDF 中提取结构化数据?
IronPDF 可以将 PDF 中的结构化数据提取为 JSON 等格式,促进不同应用程序和系统间的无缝数据集成和分析。
IronPDF 能否用人工智能处理大型文档库?
是的,IronPDF 可以通过使用人工智能模型来自动执行摘要和数据提取等任务,从而高效处理大型文档库,这与 OpenAI 和 Azure OpenAI 集成具有良好的扩展性。
IronPDF 在处理 PDF 时支持哪些人工智能模型?
IronPDF 支持 GPT-5 和 Claude 等高级人工智能模型,用于文档摘要和问答系统构建等任务,增强了整体处理能力。
IronPDF 如何促进问答系统的构建?
IronPDF 通过处理和分析文档来提取相关信息,然后用于生成对用户询问的准确回复,从而协助构建问答系统。
C# 人工智能驱动的 PDF 处理的主要用例是什么?
主要用例包括文档摘要、结构化数据提取、问答系统开发,以及使用 OpenAI 等人工智能集成处理大规模文档处理任务。
是否可以将 IronPDF 与 Azure OpenAI 一起用于文档处理?
是的,IronPDF 可以与 Azure OpenAI 集成,以增强文档处理任务,为汇总、提取和分析 PDF 文档提供可扩展的解决方案。
IronPDF 如何利用人工智能改进文档分析?
IronPDF 通过利用人工智能模型来自动执行和增强摘要、数据提取和信息检索等任务,从而提高文档分析的效率和准确性。


还在滚动吗?
想快速获得证据? PM > Install-Package IronPdf
运行示例看着你的HTML代码变成PDF文件。










