

Batch-PDF-Verarbeitung in C#: Automatisieren Sie Dokumenten-Workflows in großem Umfang
Die Batch-PDF-Verarbeitung in C# mit IronPDF ermöglicht .NET-Entwicklern die Automatisierung von Dokumenten-Workflows in großem Umfang - von der parallelen HTML-zu-PDF-Konvertierung und dem Zusammenführen/Splitten von Massen bis hin zu asynchronen PDF-Pipelines mit integrierter Fehlerbehandlung, Wiederholungslogik und Checkpointing. IronPDFs threadsichere Chromium-Engine und das auf IDisposable basierende Speichermanagement machen es speziell für die PDF-Automatisierung mit hohem Durchsatz entwickelt, egal ob Sie es lokal, in Azure Functions , AWS Lambda oder Kubernetes ausführen.
TL;DR: Schnellstartanleitung
Dieses Tutorial behandelt die skalierbare PDF-Automatisierung in C# - von der parallelen Konvertierung und Massenoperationen bis hin zur Cloud-Bereitstellung und belastbaren Pipeline-Mustern.
- Für wen ist das?: .NET-Entwickler und -Architekten, die für dokumentenlastige Arbeitsabläufe verantwortlich sind - Projekte zur Dokumentenmigration, zur täglichen Berichterstellung, zur Überprüfung der Einhaltung von Vorschriften oder zur Digitalisierung von Archiven, bei denen eine sequenzielle Verarbeitung nicht möglich ist.
- Was Sie entwickeln werden: Parallele HTML-zu-PDF-Konvertierung mit
Parallel.ForEach, Batch-Merge- und Split-Operationen, asynchrone Pipelines mitSemaphoreSlimzur Steuerung der Parallelität, Fehlerbehandlung mit Skip-on-Failure- und Retry-Logik, Checkpoint-/Resume-Muster zur Wiederherstellung nach Abstürzen sowie Cloud-Bereitstellungskonfigurationen für Azure Functions, AWS Lambda und Kubernetes. - Wo es läuft: .NET 6+, .NET Framework 4.6.2+, .NET Standard 2.0. Das gesamte Rendering erfolgt über die eingebettete Chromium-Engine von IronPDF - keine Headless-Browser-Abhängigkeiten oder externe Dienste erforderlich.
- Wann ist dieser Ansatz zu verwenden: Wenn Sie mehr PDFs verarbeiten müssen, als die sequenzielle Ausführung zulässt - Dokumentenmigration in großem Umfang, geplante Batch-Aufträge mit engen Zeitfenstern oder mandantenfähige Plattformen mit variablen Dokumentenlasten.
- Warum das technisch wichtig ist: IronPDFs
ChromePdfRendererist threadsicher und zustandslos pro Rendervorgang, was bedeutet, dass mehrere Threads sicher eine einzelne Renderer-Instanz gemeinsam nutzen können. In Kombination mit der Task Parallel Library von .NET undIDisposableaufPdfDocumenterhalten Sie ein vorhersehbares Speicherverhalten und eine CPU-Auslastung ohne Race Conditions oder Speicherlecks.
Stapelkonvertierung eines ganzen Verzeichnisses von HTML-Dateien in PDF mit nur wenigen Codezeilen:
-
Installieren Sie IronPDF mit NuGet Package Manager
PM > Install-Package IronPdf -
Kopieren Sie diesen Codeausschnitt und führen Sie ihn aus.
using IronPdf; using System.IO; using System.Threading.Tasks; var renderer = new ChromePdfRenderer(); var htmlFiles = Directory.GetFiles("input/", "*.html"); Parallel.ForEach(htmlFiles, htmlFile => { var pdf = renderer.RenderHtmlFileAsPdf(htmlFile); pdf.SaveAs($"output/{Path.GetFileNameWithoutExtension(htmlFile)}.pdf"); }); -
Bereitstellen zum Testen in Ihrer Live-Umgebung
Beginnen Sie noch heute, IronPDF in Ihrem Projekt zu verwenden, mit einer kostenlosen Testversion

Nachdem Sie IronPDF gekauft oder sich für eine 30-tägige Testversion angemeldet haben, fügen Sie Ihren Lizenzschlüssel am Anfang Ihrer Anwendung hinzu.
IronPdf.License.LicenseKey = "KEY";IronPdf.License.LicenseKey = "KEY";Imports IronPdf
IronPdf.License.LicenseKey = "KEY"Nutzen Sie IronPDF heute kostenlos in Ihrem Projekt.
Inhaltsverzeichnis
- Verständnis des Problems
- Grundlage
- Kerngeschäft
- Resilienz
- Leistung
- Einsatz
- Alles zusammenfügen
Wenn Sie Tausende von PDFs zu verarbeiten haben
Die Stapelverarbeitung von PDF-Dateien ist keine Nischenanforderung - sie ist ein Routinebestandteil der Dokumentenverwaltung in Unternehmen. Die Szenarien, die dies erfordern, kommen in allen Branchen vor und haben eines gemeinsam: Es ist keine Option, die Dinge einzeln zu erledigen.
Dokumentenmigrationsprojekte sind einer der häufigsten Auslöser. Wenn ein Unternehmen von einem Dokumentenverwaltungssystem auf ein anderes umsteigt, müssen Tausende (manchmal Millionen) von Dokumenten konvertiert, neu formatiert oder mit neuen Tags versehen werden. Ein Versicherungsunternehmen, das von einem alten Schadensystem migriert, muss möglicherweise 500.000 TIFF-basierte Schadensdokumente in durchsuchbare PDFs konvertieren. Eine Anwaltskanzlei, die auf eine neue Fallverwaltungsplattform umsteigt, muss möglicherweise verstreute Korrespondenz in einheitliche Falldateien zusammenführen. Es handelt sich um einmalige Aufträge, die jedoch einen enormen Umfang haben und keine Fehler verzeihen.
Tägliche Berichtserstellung ist die stationäre Version desselben Problems. Finanzinstitute, die Tagesabschlussberichte für Tausende von Kunden erstellen, Logistikunternehmen, die Versandmanifeste für jeden ausgehenden Container generieren, Gesundheitssysteme, die täglich Zusammenfassungen für Patienten in Hunderten von Abteilungen erstellen - sie alle erzeugen PDF-Ausgaben in einem Umfang, bei dem eine sequenzielle Verarbeitung akzeptable Zeitfenster sprengen würde. Wenn 10.000 Berichte bis 6 Uhr morgens fertig sein müssen und die Daten erst um Mitternacht fertig sind, haben Sie keine sechs Stunden Zeit, um einen nach dem anderen zu rendern.
Digitalisierung von Archiven befindet sich an der Schnittstelle zwischen Migration und Compliance. Regierungsbehörden, Universitäten und Unternehmen mit jahrzehntelangen Papierunterlagen müssen ihre Dokumente digitalisieren und in standardkonformen Formaten (in der Regel PDF/A) archivieren. Das Volumen ist überwältigend - allein die NARA erhält Millionen von Seiten an Bundesunterlagen zur dauerhaften Aufbewahrung - und der Prozess muss so zuverlässig sein, dass man Jahre später keine Lücken entdeckt.
Die Einhaltung von Vorschriften ist oft der dringendste Anlass. Wenn bei einer Prüfung festgestellt wird, dass Ihr Dokumentenarchiv einer neu eingeführten Norm nicht entspricht - z. B. dass Ihre gespeicherten Rechnungen nicht den PDF/A-3-Vorschriften für die elektronische Rechnungsstellung entsprechen oder dass Ihre medizinischen Unterlagen nicht mit den in Abschnitt 508 geforderten Kennzeichnungen für die Barrierefreiheit versehen sind -, müssen Sie Ihr gesamtes vorhandenes Archiv nach der neuen Norm bearbeiten. Der Druck ist hoch, der Zeitplan eng und der Umfang ist das, was Ihr Archiv zufällig enthält.
In jedem dieser Szenarien ist die Kernherausforderung dieselbe: Wie kann man eine große Anzahl von PDF-Operationen zuverlässig und effizient verarbeiten, ohne dass der Speicher knapp wird oder halbfertige Arbeit zurückbleibt, wenn etwas schiefgeht?
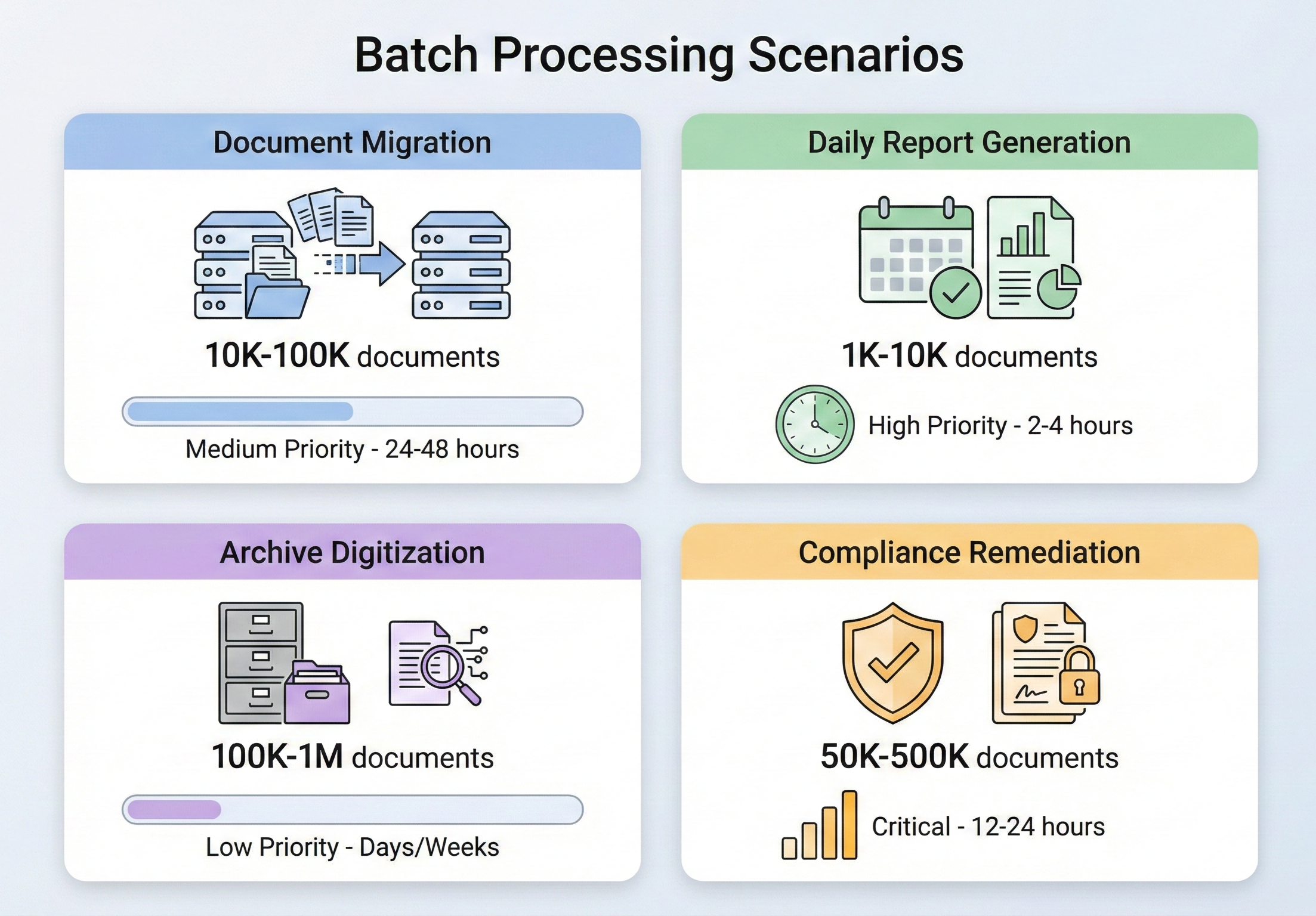
IronPDF Stapelverarbeitungsarchitektur
Bevor Sie sich mit den einzelnen Vorgängen befassen, sollten Sie verstehen, wie IronPDF für die Verarbeitung gleichzeitiger Arbeitslasten ausgelegt ist und welche architektonischen Entscheidungen Sie treffen sollten, wenn Sie eine Batch-Pipeline darauf aufbauen.
Installation von IronPDF
Installieren Sie IronPDF über NuGet:
Install-Package IronPdfInstall-Package IronPdfOder verwenden Sie die .NET CLI:
dotnet add package IronPdfdotnet add package IronPdfIronPDF unterstützt .NET Framework 4.6.2+, .NET Core, .NET 5 bis .NET 10, und .NET Standard 2.0. Es läuft auf Windows, Linux, macOS und Docker-Containern und eignet sich damit sowohl für Batch-Jobs vor Ort als auch für die Cloud-native Bereitstellung.
Für die Stapelverarbeitung in der Produktion legen Sie Ihren Lizenzschlüssel mit License.LicenseKey beim Start der Anwendung fest, bevor mit den PDF-Operationen begonnen wird. Dadurch wird sichergestellt, dass jeder Rendering-Aufruf über alle Threads hinweg Zugriff auf den vollen Funktionsumfang ohne Wasserzeichen pro Datei hat.
Gleichzeitigkeitskontrolle und Thread-Sicherheit
Die Chromium-basierte Rendering-Engine von IronPDF ist thread-sicher. Sie können mehrere ChromePdfRenderer-Instanzen über mehrere Threads hinweg erstellen oder eine einzelne Instanz gemeinsam nutzen – IronPDF kümmert sich um die interne Synchronisierung. Die offizielle Empfehlung für die Stapelverarbeitung ist die Verwendung der in .NET integrierten Funktion Parallel.ForEach, die die Arbeit automatisch auf alle verfügbaren CPU-Kerne verteilt.
Allerdings bedeutet "threadsicher" nicht "unbegrenzt viele Threads verwenden". Jeder gleichzeitige PDF-Rendering-Vorgang verbraucht Speicher (die Chromium-Engine benötigt Arbeitsspeicher für DOM-Parsing, CSS-Layout und Bildrasterisierung), und das Starten zu vieler paralleler Operationen auf einem speicherbeschränkten System wird die Leistung beeinträchtigen oder zu Fehlern führen. Das richtige Maß an Gleichzeitigkeit hängt von Ihrer Hardware ab: Ein Server mit 16 Kernen und 64 GB RAM kann bequem 8-12 gleichzeitige Rendervorgänge bewältigen; Eine VM mit 4 Kernen und 8 GB RAM könnte auf 2–4 beschränkt sein. Dies lässt sich mit ParallelOptions.MaxDegreeOfParallelism steuern – stellen Sie den Wert zunächst auf etwa die Hälfte Ihrer verfügbaren CPU-Kerne ein und passen Sie ihn dann je nach beobachteter Speicherauslastung an.
Speichermanagement im großen Maßstab
Die Speicherverwaltung ist das wichtigste Thema bei der Stapelverarbeitung von PDF-Dateien. Jedes PdfDocument-Objekt speichert den gesamten Binärinhalt einer PDF-Datei im Speicher. Werden diese Objekte nicht freigegeben, wächst der Speicherbedarf linear mit der Anzahl der verarbeiteten Dateien.
Die entscheidende Regel: Verwenden Sie immer using Anweisungen oder rufen Sie Dispose() explizit auf PdfDocument Objekten auf. IronPDFs PdfDocument implementiert IDisposable, und das Versäumnis, den Speicher freizugeben, ist die häufigste Ursache für Speicherprobleme in Batch-Szenarien. Bei jeder Iteration Ihrer Verarbeitungsschleife sollte ein PdfDocument-Objekt erstellt, seine Arbeit erledigt und es anschließend wieder freigegeben werden – akkumulieren Sie niemals PdfDocument-Objekte in einer Liste oder Sammlung, es sei denn, Sie haben einen bestimmten Grund dafür und genügend Speicherplatz, um dies zu handhaben.
Über die Entsorgung hinaus sollten Sie diese Speicherverwaltungsstrategien für große Stapel berücksichtigen:
Bearbeiten Sie die Übersetzung häppchenweise, anstatt alles auf einmal zu laden. Wenn Sie 50.000 Dateien verarbeiten müssen, sollten Sie sie nicht alle in einer Liste aufzählen und dann iterieren, sondern sie in Stapeln von 100 oder 500 Dateien verarbeiten, damit der Garbage Collector zwischen den Stapeln Speicher zurückgewinnen kann.
Force garbage collection between chunks für extrem große Batches. Im Allgemeinen sollte man die Speicherverwaltung dem Garbage Collector überlassen, aber die Stapelverarbeitung ist einer der seltenen Fälle, in denen der Aufruf von GC.Collect() zwischen den Chunk-Grenzen verhindern kann, dass sich Speicherdruck aufbaut.
Überwachen Sie die Speichernutzung mithilfe von GC.GetTotalMemory() oder Metriken auf Prozessebene. Wenn die Speichernutzung einen Schwellenwert überschreitet (z. B. 80 % des verfügbaren Arbeitsspeichers), halten Sie die Verarbeitung an, damit der GC den Rückstand aufholen kann.
Fortschrittsberichte und Protokollierung
Wenn ein Stapelverarbeitungsauftrag mehrere Stunden dauert, ist ein Überblick über den Fortschritt nicht nur optional, sondern unerlässlich. Zumindest sollten Sie den Beginn und die Fertigstellung jeder Datei protokollieren, die Anzahl der Erfolge/Misserfolge verfolgen und eine geschätzte Restzeit angeben. Verwenden Sie Interlocked.Increment für threadsichere Zähler bei der Ausführung paralleler Operationen und protokollieren Sie in regelmäßigen Abständen (alle 50 oder 100 Dateien) anstatt bei jeder einzelnen Datei, um eine Überflutung Ihrer Ausgabe zu vermeiden. Verfolgen Sie die verstrichene Zeit mit System.Diagnostics.Stopwatch und berechnen Sie eine laufende Datei-pro-Sekunde-Rate, um eine aussagekräftige voraussichtliche Ankunftszeit zu erhalten.
Bei Produktions-Batch-Aufträgen sollte der Fortschritt in einen dauerhaften Speicher (Datenbank, Datei oder Nachrichtenwarteschlange) geschrieben werden, damit Überwachungs-Dashboards den Status in Echtzeit anzeigen können, ohne dass eine direkte Verbindung zum Batch-Prozess erforderlich ist.
Gängige Batch-Operationen
Nachdem die architektonische Grundlage geschaffen wurde, wollen wir nun die gängigsten Batch-Operationen und ihre IronPDF-Implementierungen durchgehen.
Batch-Konvertierung von HTML in PDF
Die Konvertierung von HTML in PDF ist die häufigste Stapelverarbeitung. Ob Sie Rechnungen aus Vorlagen generieren, eine Bibliothek mit HTML-Dokumentation in PDF konvertieren oder dynamische Berichte aus einer Webanwendung rendern, das Muster ist dasselbe: Iterieren Sie Ihre Eingaben, rendern Sie jede einzelne und speichern Sie die Ausgabe.
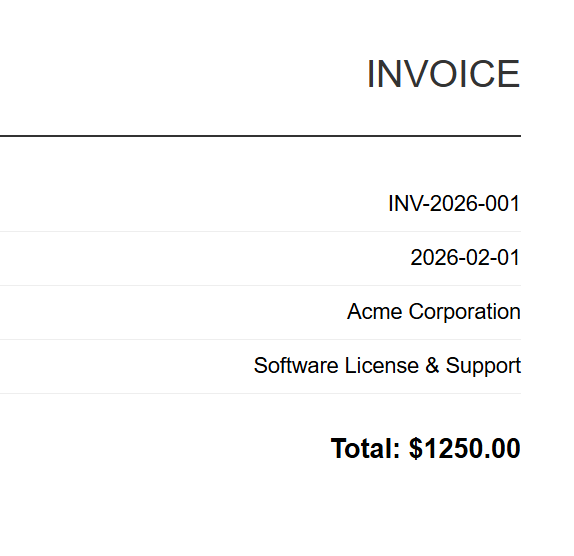
Eingabe (5 HTML-Dateien)
INV-2026-001
INV-2026-002
INV-2026-003
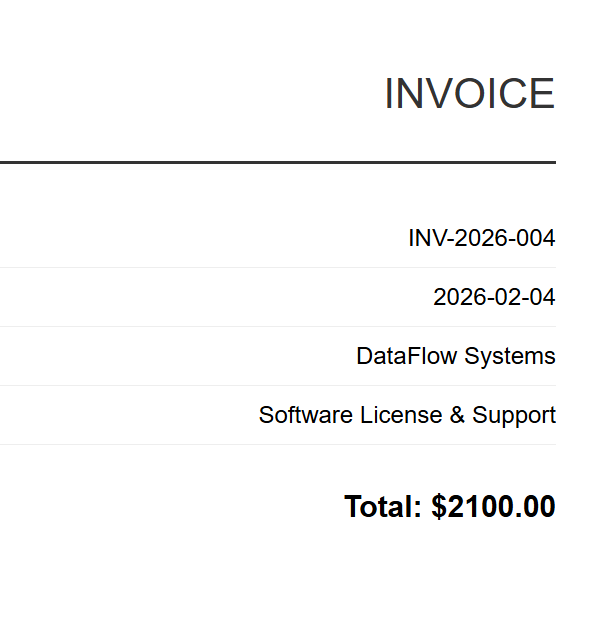
INV-2026-004
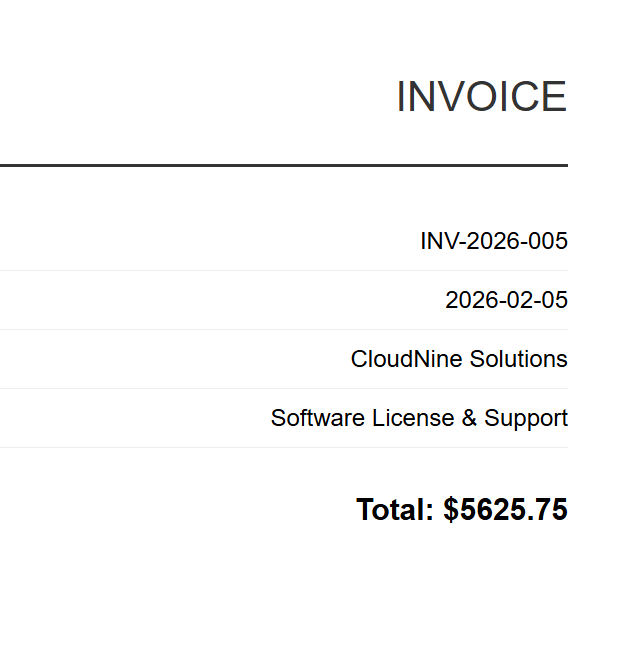
INV-2026-005
Die Implementierung verwendet ChromePdfRenderer mit Parallel.ForEach, um alle HTML-Dateien gleichzeitig zu verarbeiten, wobei die Parallelität durch MaxDegreeOfParallelism gesteuert wird, um Durchsatz und Speicherverbrauch in Einklang zu bringen. Jede Datei wird mit RenderHtmlFileAsPdf gerendert und im Ausgabeverzeichnis gespeichert, wobei der Fortschritt über threadsichere Interlocked Zähler verfolgt wird.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-html-to-pdf.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
using System.Threading;
// Configure paths
string inputFolder = "input/";
string outputFolder = "output/";
Directory.CreateDirectory(outputFolder);
string[] htmlFiles = Directory.GetFiles(inputFolder, "*.html");
Console.WriteLine($"Found {htmlFiles.Length} HTML files to convert");
// Create renderer instance (thread-safe, can be shared)
var renderer = new ChromePdfRenderer();
// Track progress
int processed = 0;
int failed = 0;
// Process in parallel with controlled concurrency
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(htmlFiles, options, htmlFile =>
{
try
{
string fileName = Path.GetFileNameWithoutExtension(htmlFile);
string outputPath = Path.Combine(outputFolder, $"{fileName}.pdf");
using var pdf = renderer.RenderHtmlFileAsPdf(htmlFile);
pdf.SaveAs(outputPath);
Interlocked.Increment(ref processed);
Console.WriteLine($"[OK] {fileName}.pdf");
}
catch (Exception ex)
{
Interlocked.Increment(ref failed);
Console.WriteLine($"[ERROR] {Path.GetFileName(htmlFile)}: {ex.Message}");
}
});
Console.WriteLine($"\nComplete: {processed} succeeded, {failed} failed");Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading.Tasks
Imports System.Threading
' Configure paths
Dim inputFolder As String = "input/"
Dim outputFolder As String = "output/"
Directory.CreateDirectory(outputFolder)
Dim htmlFiles As String() = Directory.GetFiles(inputFolder, "*.html")
Console.WriteLine($"Found {htmlFiles.Length} HTML files to convert")
' Create renderer instance (thread-safe, can be shared)
Dim renderer As New ChromePdfRenderer()
' Track progress
Dim processed As Integer = 0
Dim failed As Integer = 0
' Process in parallel with controlled concurrency
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(htmlFiles, options, Sub(htmlFile)
Try
Dim fileName As String = Path.GetFileNameWithoutExtension(htmlFile)
Dim outputPath As String = Path.Combine(outputFolder, $"{fileName}.pdf")
Using pdf = renderer.RenderHtmlFileAsPdf(htmlFile)
pdf.SaveAs(outputPath)
End Using
Interlocked.Increment(processed)
Console.WriteLine($"[OK] {fileName}.pdf")
Catch ex As Exception
Interlocked.Increment(failed)
Console.WriteLine($"[ERROR] {Path.GetFileName(htmlFile)}: {ex.Message}")
End Try
End Sub)
Console.WriteLine($"\nComplete: {processed} succeeded, {failed} failed")Ausgabe
Jede HTML-Rechnung wird in eine entsprechende PDF-Datei umgewandelt. Oben sehen Sie INV-2026-001.pdf - eine von 5 Batch-Ausgaben.
Bei der Generierung von Vorlagen (z. B. Rechnungen, Berichte) werden die Daten in der Regel vor dem Rendern in eine HTML-Vorlage eingefügt. Die Vorgehensweise ist einfach: Laden Sie Ihre HTML-Vorlage einmal, verwenden Sie string.Replace, um die Daten pro Datensatz (Kundenname, Summen, Datum) einzufügen, und übergeben Sie das befüllte HTML an RenderHtmlAsPdf innerhalb Ihrer parallelen Schleife. IronPDF bietet außerdem RenderHtmlAsPdfAsync für Szenarien, in denen Sie async/await anstelle von Parallel.ForEach verwenden möchten – wir werden asynchrone Muster in einem späteren Abschnitt ausführlich behandeln.
Stapel-PDF-Zusammenführung
Das Zusammenführen von PDF-Gruppen zu kombinierten Dokumenten ist in juristischen (Zusammenführen von Fallakten), finanziellen (Zusammenführen von Monatsauszügen zu Quartalsberichten) und Verlags-Workflows üblich.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-merge.csusing IronPdf;
using System;
using System.IO;
using System.Linq;
using System.Collections.Generic;
string inputFolder = "documents/";
string outputFolder = "merged/";
Directory.CreateDirectory(outputFolder);
// Group PDFs by prefix (e.g., "invoice-2026-01-*.pdf" -> one merged file)
var pdfFiles = Directory.GetFiles(inputFolder, "*.pdf");
var groups = pdfFiles
.GroupBy(f => Path.GetFileName(f).Split('-').Take(3).Aggregate((a, b) => $"{a}-{b}"))
.Where(g => g.Count() > 1);
Console.WriteLine($"Found {groups.Count()} groups to merge");
foreach (var group in groups)
{
string groupName = group.Key;
var filesToMerge = group.OrderBy(f => f).ToList();
Console.WriteLine($"Merging {filesToMerge.Count} files into {groupName}.pdf");
try
{
// Load all PDFs for this group
var pdfDocs = new List<PdfDocument>();
foreach (string filePath in filesToMerge)
{
pdfDocs.Add(PdfDocument.FromFile(filePath));
}
// Merge all documents
using var merged = PdfDocument.Merge(pdfDocs);
merged.SaveAs(Path.Combine(outputFolder, $"{groupName}-merged.pdf"));
// Dispose source documents
foreach (var doc in pdfDocs)
{
doc.Dispose();
}
Console.WriteLine($" [OK] Created {groupName}-merged.pdf ({merged.PageCount} pages)");
}
catch (Exception ex)
{
Console.WriteLine($" [ERROR] {groupName}: {ex.Message}");
}
}
Console.WriteLine("\nMerge complete");Imports IronPdf
Imports System
Imports System.IO
Imports System.Linq
Imports System.Collections.Generic
Module Program
Sub Main()
Dim inputFolder As String = "documents/"
Dim outputFolder As String = "merged/"
Directory.CreateDirectory(outputFolder)
' Group PDFs by prefix (e.g., "invoice-2026-01-*.pdf" -> one merged file)
Dim pdfFiles = Directory.GetFiles(inputFolder, "*.pdf")
Dim groups = pdfFiles _
.GroupBy(Function(f) Path.GetFileName(f).Split("-"c).Take(3).Aggregate(Function(a, b) $"{a}-{b}")) _
.Where(Function(g) g.Count() > 1)
Console.WriteLine($"Found {groups.Count()} groups to merge")
For Each group In groups
Dim groupName As String = group.Key
Dim filesToMerge = group.OrderBy(Function(f) f).ToList()
Console.WriteLine($"Merging {filesToMerge.Count} files into {groupName}.pdf")
Try
' Load all PDFs for this group
Dim pdfDocs As New List(Of PdfDocument)()
For Each filePath As String In filesToMerge
pdfDocs.Add(PdfDocument.FromFile(filePath))
Next
' Merge all documents
Using merged = PdfDocument.Merge(pdfDocs)
merged.SaveAs(Path.Combine(outputFolder, $"{groupName}-merged.pdf"))
End Using
' Dispose source documents
For Each doc In pdfDocs
doc.Dispose()
Next
Console.WriteLine($" [OK] Created {groupName}-merged.pdf ({merged.PageCount} pages)")
Catch ex As Exception
Console.WriteLine($" [ERROR] {groupName}: {ex.Message}")
End Try
Next
Console.WriteLine(vbCrLf & "Merge complete")
End Sub
End ModuleBeim Zusammenführen einer großen Anzahl von Dateien ist auf den Speicherverbrauch zu achten: Die Methode PdfDocument.Merge lädt alle Quelldokumente gleichzeitig in den Speicher. Wenn Sie Hunderte von großen PDF-Dateien zusammenführen, sollten Sie eine schrittweise Zusammenführung in Erwägung ziehen - kombinieren Sie Gruppen von 10-20 Dateien zu Zwischendokumenten und führen Sie dann die Zwischendokumente zusammen.
PDF-Stapelaufteilung
Das Aufteilen mehrseitiger PDFs in einzelne Seiten (oder Seitenbereiche) ist das Gegenteil des Zusammenführens. Üblich in der Postbearbeitung, wo ein gescannter Dokumentenstapel in einzelne Datensätze zerlegt werden muss, und in Druck-Workflows, wo zusammengesetzte Dokumente zerlegt werden müssen.
Eingabe
Der unten stehende Code demonstriert das Extrahieren einzelner Seiten mithilfe von CopyPage in einer parallelen Schleife, wodurch für jede Seite separate PDF-Dateien erstellt werden. Eine alternative SplitByRange Hilfsfunktion zeigt, wie man Seitenbereiche anstatt einzelner Seiten extrahiert, was nützlich ist, um große Dokumente in kleinere Segmente zu unterteilen.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-split.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
string inputFolder = "multipage/";
string outputFolder = "split/";
Directory.CreateDirectory(outputFolder);
string[] pdfFiles = Directory.GetFiles(inputFolder, "*.pdf");
Console.WriteLine($"Found {pdfFiles.Length} PDFs to split");
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(pdfFiles, options, pdfFile =>
{
string baseName = Path.GetFileNameWithoutExtension(pdfFile);
try
{
using var pdf = PdfDocument.FromFile(pdfFile);
int pageCount = pdf.PageCount;
Console.WriteLine($"Splitting {baseName}.pdf ({pageCount} pages)");
// Extract each page as a separate PDF
for (int i = 0; i < pageCount; i++)
{
using var singlePage = pdf.CopyPage(i);
string outputPath = Path.Combine(outputFolder, $"{baseName}-page-{i + 1:D3}.pdf");
singlePage.SaveAs(outputPath);
}
Console.WriteLine($" [OK] Created {pageCount} files from {baseName}.pdf");
}
catch (Exception ex)
{
Console.WriteLine($" [ERROR] {baseName}: {ex.Message}");
}
});
// Alternative: Extract page ranges instead of individual pages
void SplitByRange(string inputFile, string outputFolder, int pagesPerChunk)
{
using var pdf = PdfDocument.FromFile(inputFile);
string baseName = Path.GetFileNameWithoutExtension(inputFile);
int totalPages = pdf.PageCount;
int chunkNumber = 1;
for (int startPage = 0; startPage < totalPages; startPage += pagesPerChunk)
{
int endPage = Math.Min(startPage + pagesPerChunk - 1, totalPages - 1);
using var chunk = pdf.CopyPages(startPage, endPage);
chunk.SaveAs(Path.Combine(outputFolder, $"{baseName}-chunk-{chunkNumber:D3}.pdf"));
chunkNumber++;
}
}
Console.WriteLine("\nSplit complete");Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading.Tasks
Module Program
Sub Main()
Dim inputFolder As String = "multipage/"
Dim outputFolder As String = "split/"
Directory.CreateDirectory(outputFolder)
Dim pdfFiles As String() = Directory.GetFiles(inputFolder, "*.pdf")
Console.WriteLine($"Found {pdfFiles.Length} PDFs to split")
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(pdfFiles, options, Sub(pdfFile)
Dim baseName As String = Path.GetFileNameWithoutExtension(pdfFile)
Try
Using pdf = PdfDocument.FromFile(pdfFile)
Dim pageCount As Integer = pdf.PageCount
Console.WriteLine($"Splitting {baseName}.pdf ({pageCount} pages)")
' Extract each page as a separate PDF
For i As Integer = 0 To pageCount - 1
Using singlePage = pdf.CopyPage(i)
Dim outputPath As String = Path.Combine(outputFolder, $"{baseName}-page-{i + 1:D3}.pdf")
singlePage.SaveAs(outputPath)
End Using
Next
Console.WriteLine($" [OK] Created {pageCount} files from {baseName}.pdf")
End Using
Catch ex As Exception
Console.WriteLine($" [ERROR] {baseName}: {ex.Message}")
End Try
End Sub)
' Alternative: Extract page ranges instead of individual pages
Sub SplitByRange(inputFile As String, outputFolder As String, pagesPerChunk As Integer)
Using pdf = PdfDocument.FromFile(inputFile)
Dim baseName As String = Path.GetFileNameWithoutExtension(inputFile)
Dim totalPages As Integer = pdf.PageCount
Dim chunkNumber As Integer = 1
For startPage As Integer = 0 To totalPages - 1 Step pagesPerChunk
Dim endPage As Integer = Math.Min(startPage + pagesPerChunk - 1, totalPages - 1)
Using chunk = pdf.CopyPages(startPage, endPage)
chunk.SaveAs(Path.Combine(outputFolder, $"{baseName}-chunk-{chunkNumber:D3}.pdf"))
chunkNumber += 1
End Using
Next
End Using
End Sub
Console.WriteLine(vbCrLf & "Split complete")
End Sub
End ModuleAusgabe
Seite 2 als eigenständiges PDF extrahiert (annual-report-page-2.pdf)
Die Methoden CopyPage und CopyPages von IronPDF erstellen neue PdfDocument Objekte, die die angegebenen Seiten enthalten. Denken Sie daran, sowohl das Quelldokument als auch jede extrahierte Seite nach dem Speichern zu entsorgen.
Batch-Komprimierung
Wenn Speicherkosten eine Rolle spielen oder wenn Sie PDFs über Verbindungen mit begrenzter Bandbreite übertragen müssen, kann die Stapelkomprimierung Ihren Archivierungsbedarf drastisch reduzieren. IronPDF bietet zwei Komprimierungsansätze: CompressImages zur Reduzierung der Bildqualität/Bildgröße und CompressStructTree zur Entfernung struktureller Metadaten. Die neuere CompressAndSaveAs API (eingeführt in Version 2025.12) bietet eine überlegene Komprimierung durch die Kombination mehrerer Optimierungstechniken.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-compression.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
using System.Threading;
string inputFolder = "originals/";
string outputFolder = "compressed/";
Directory.CreateDirectory(outputFolder);
string[] pdfFiles = Directory.GetFiles(inputFolder, "*.pdf");
Console.WriteLine($"Found {pdfFiles.Length} PDFs to compress");
long totalOriginalSize = 0;
long totalCompressedSize = 0;
int processed = 0;
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(pdfFiles, options, pdfFile =>
{
string fileName = Path.GetFileName(pdfFile);
string outputPath = Path.Combine(outputFolder, fileName);
try
{
long originalSize = new FileInfo(pdfFile).Length;
Interlocked.Add(ref totalOriginalSize, originalSize);
using var pdf = PdfDocument.FromFile(pdfFile);
// Apply compression with JPEG quality setting (0-100, lower = more compression)
pdf.CompressAndSaveAs(outputPath, 60);
long compressedSize = new FileInfo(outputPath).Length;
Interlocked.Add(ref totalCompressedSize, compressedSize);
Interlocked.Increment(ref processed);
double reduction = (1 - (double)compressedSize / originalSize) * 100;
Console.WriteLine($"[OK] {fileName}: {originalSize / 1024}KB → {compressedSize / 1024}KB ({reduction:F1}% reduction)");
}
catch (Exception ex)
{
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
});
double totalReduction = (1 - (double)totalCompressedSize / totalOriginalSize) * 100;
Console.WriteLine($"\nCompression complete:");
Console.WriteLine($" Files processed: {processed}");
Console.WriteLine($" Total original: {totalOriginalSize / 1024 / 1024}MB");
Console.WriteLine($" Total compressed: {totalCompressedSize / 1024 / 1024}MB");
Console.WriteLine($" Overall reduction: {totalReduction:F1}%");Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading.Tasks
Imports System.Threading
Module Program
Sub Main()
Dim inputFolder As String = "originals/"
Dim outputFolder As String = "compressed/"
Directory.CreateDirectory(outputFolder)
Dim pdfFiles As String() = Directory.GetFiles(inputFolder, "*.pdf")
Console.WriteLine($"Found {pdfFiles.Length} PDFs to compress")
Dim totalOriginalSize As Long = 0
Dim totalCompressedSize As Long = 0
Dim processed As Integer = 0
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(pdfFiles, options, Sub(pdfFile)
Dim fileName As String = Path.GetFileName(pdfFile)
Dim outputPath As String = Path.Combine(outputFolder, fileName)
Try
Dim originalSize As Long = New FileInfo(pdfFile).Length
Interlocked.Add(totalOriginalSize, originalSize)
Using pdf = PdfDocument.FromFile(pdfFile)
' Apply compression with JPEG quality setting (0-100, lower = more compression)
pdf.CompressAndSaveAs(outputPath, 60)
End Using
Dim compressedSize As Long = New FileInfo(outputPath).Length
Interlocked.Add(totalCompressedSize, compressedSize)
Interlocked.Increment(processed)
Dim reduction As Double = (1 - CDbl(compressedSize) / originalSize) * 100
Console.WriteLine($"[OK] {fileName}: {originalSize \ 1024}KB → {compressedSize \ 1024}KB ({reduction:F1}% reduction)")
Catch ex As Exception
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End Sub)
Dim totalReduction As Double = (1 - CDbl(totalCompressedSize) / totalOriginalSize) * 100
Console.WriteLine(vbCrLf & "Compression complete:")
Console.WriteLine($" Files processed: {processed}")
Console.WriteLine($" Total original: {totalOriginalSize \ 1024 \ 1024}MB")
Console.WriteLine($" Total compressed: {totalCompressedSize \ 1024 \ 1024}MB")
Console.WriteLine($" Overall reduction: {totalReduction:F1}%")
End Sub
End ModuleEin paar Dinge zur Komprimierung sollten beachtet werden: JPEG-Qualitätseinstellungen unter 60 führen bei den meisten Bildern zu sichtbaren Artefakten. Die Option ShrinkImage kann in einigen Konfigurationen zu Verzerrungen führen – testen Sie dies mit repräsentativen Stichproben, bevor Sie einen kompletten Batch ausführen. Das Entfernen des Strukturbaums (CompressStructTree) wirkt sich auf die Textauswahl und die Suche in den komprimierten PDFs aus. Verwenden Sie diese Funktion daher nur, wenn diese Funktionen nicht benötigt werden.
Batch-Formatkonvertierung (PDF/A, PDF/UA)
Die Konvertierung eines bestehenden Archivs in ein standardkonformes Format - PDF/A für die Langzeitarchivierung oder PDF/UA für die Barrierefreiheit - ist eine der hochwertigsten Batch-Operationen. IronPDF unterstützt alle PDF/A-Versionen (einschließlich PDF/A-4, hinzugefügt in Version 2025.11) und PDF/UA-Konformität (einschließlich PDF/UA-2, hinzugefügt in Version 2025.12).
Eingabe
Das Beispiel lädt jede PDF-Datei mit PdfDocument.FromFile und konvertiert sie dann mit SaveAsPdfA und dem Parameter PdfAVersions.PdfA3b in PDF/A-3b. Eine alternative ConvertToPdfUA Funktion demonstriert die Konvertierung zur Barrierefreiheitskonformität unter Verwendung von SaveAsPdfUA, allerdings benötigt PDF/UA Quelldokumente mit korrekter struktureller Kennzeichnung.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-format-conversion.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
using System.Threading;
string inputFolder = "originals/";
string outputFolder = "pdfa-archive/";
Directory.CreateDirectory(outputFolder);
string[] pdfFiles = Directory.GetFiles(inputFolder, "*.pdf");
Console.WriteLine($"Found {pdfFiles.Length} PDFs to convert to PDF/A-3b");
int converted = 0;
int failed = 0;
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(pdfFiles, options, pdfFile =>
{
string fileName = Path.GetFileName(pdfFile);
string outputPath = Path.Combine(outputFolder, fileName);
try
{
using var pdf = PdfDocument.FromFile(pdfFile);
// Convert to PDF/A-3b for long-term archival
pdf.SaveAsPdfA(outputPath, PdfAVersions.PdfA3b);
Interlocked.Increment(ref converted);
Console.WriteLine($"[OK] {fileName} → PDF/A-3b");
}
catch (Exception ex)
{
Interlocked.Increment(ref failed);
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
});
Console.WriteLine($"\nConversion complete: {converted} succeeded, {failed} failed");
// Alternative: Convert to PDF/UA for accessibility compliance
void ConvertToPdfUA(string inputFolder, string outputFolder)
{
Directory.CreateDirectory(outputFolder);
string[] files = Directory.GetFiles(inputFolder, "*.pdf");
Parallel.ForEach(files, pdfFile =>
{
string fileName = Path.GetFileName(pdfFile);
try
{
using var pdf = PdfDocument.FromFile(pdfFile);
// PDF/UA requires proper tagging - ensure source is well-structured
pdf.SaveAsPdfUA(Path.Combine(outputFolder, fileName));
Console.WriteLine($"[OK] {fileName} → PDF/UA");
}
catch (Exception ex)
{
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
});
}Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading.Tasks
Imports System.Threading
Module Program
Sub Main()
Dim inputFolder As String = "originals/"
Dim outputFolder As String = "pdfa-archive/"
Directory.CreateDirectory(outputFolder)
Dim pdfFiles As String() = Directory.GetFiles(inputFolder, "*.pdf")
Console.WriteLine($"Found {pdfFiles.Length} PDFs to convert to PDF/A-3b")
Dim converted As Integer = 0
Dim failed As Integer = 0
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(pdfFiles, options, Sub(pdfFile)
Dim fileName As String = Path.GetFileName(pdfFile)
Dim outputPath As String = Path.Combine(outputFolder, fileName)
Try
Using pdf = PdfDocument.FromFile(pdfFile)
' Convert to PDF/A-3b for long-term archival
pdf.SaveAsPdfA(outputPath, PdfAVersions.PdfA3b)
Interlocked.Increment(converted)
Console.WriteLine($"[OK] {fileName} → PDF/A-3b")
End Using
Catch ex As Exception
Interlocked.Increment(failed)
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End Sub)
Console.WriteLine($"{vbCrLf}Conversion complete: {converted} succeeded, {failed} failed")
End Sub
' Alternative: Convert to PDF/UA for accessibility compliance
Sub ConvertToPdfUA(inputFolder As String, outputFolder As String)
Directory.CreateDirectory(outputFolder)
Dim files As String() = Directory.GetFiles(inputFolder, "*.pdf")
Parallel.ForEach(files, Sub(pdfFile)
Dim fileName As String = Path.GetFileName(pdfFile)
Try
Using pdf = PdfDocument.FromFile(pdfFile)
' PDF/UA requires proper tagging - ensure source is well-structured
pdf.SaveAsPdfUA(Path.Combine(outputFolder, fileName))
Console.WriteLine($"[OK] {fileName} → PDF/UA")
End Using
Catch ex As Exception
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End Sub)
End Sub
End ModuleAusgabe
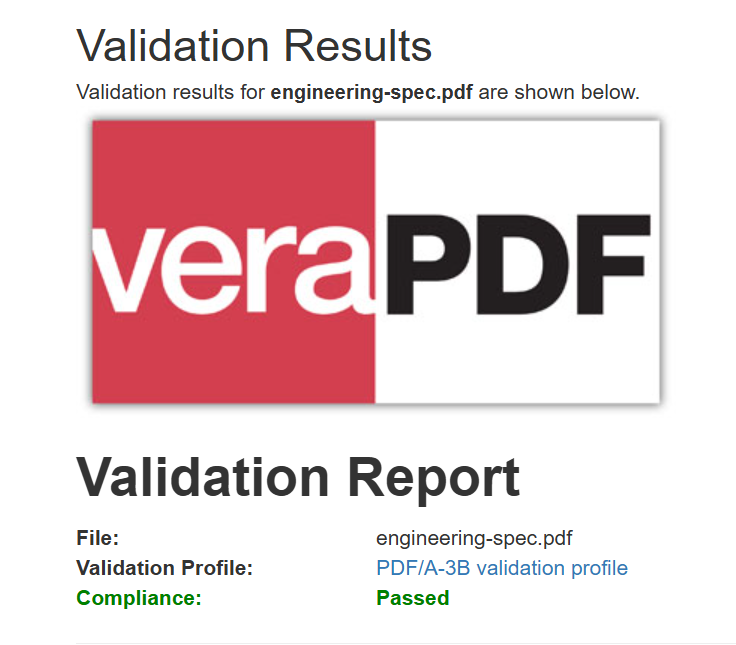
Die PDF-Ausgabe ist Byte für Byte identisch, enthält aber nun PDF/A-3b-konforme Metadaten für Archivierungssysteme.
Die Formatkonvertierung ist besonders wichtig für Projekte zur Einhaltung von Vorschriften, bei denen ein Unternehmen feststellt, dass sein vorhandenes Archiv nicht den gesetzlichen Standards entspricht. Das Batch-Muster ist einfach, aber der Validierungsschritt ist entscheidend - überprüfen Sie immer, ob jede konvertierte Datei tatsächlich die Konformitätsprüfungen besteht, bevor Sie sie als vollständig betrachten. Auf die Validierung gehen wir im Abschnitt über die Widerstandsfähigkeit im Detail ein.
Aufbau stabiler Batch-Pipelines
Eine Batch-Pipeline, die bei 100 Dateien perfekt funktioniert und bei Datei Nr. 4.327 von 50.000 abstürzt, ist nicht sinnvoll. Resilienz - die Fähigkeit, Fehler anständig zu behandeln, vorübergehende Ausfälle zu wiederholen und nach Abstürzen fortzufahren - ist das, was eine produktionsreife Pipeline von einem Prototyp trennt.
Fehlerbehandlung und Skip-on-Failure
Das grundlegendste Ausfallsicherheitsmuster ist "Skip-on-Failure": Wenn eine einzelne Datei nicht verarbeitet werden kann, wird der Fehler protokolliert und mit der nächsten Datei fortgesetzt, anstatt den gesamten Stapel abzubrechen. Das klingt selbstverständlich, aber überraschenderweise übersieht man es leicht, wenn man Parallel.ForEach verwendet – eine unbehandelte Ausnahme in einer beliebigen parallelen Aufgabe wird als AggregateException weitergegeben und beendet die Schleife.
Das folgende Beispiel demonstriert sowohl Skip-on-Failure- als auch Retry-Logik – indem jede Datei in einen try-catch-Block für eine elegante Fehlerbehandlung eingeschlossen wird, mit einer inneren Retry-Schleife, die exponentielles Backoff für vorübergehende Ausnahmen wie IOException und OutOfMemoryException verwendet:
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-error-handling-retry.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
using System.Threading;
using System.Collections.Concurrent;
string inputFolder = "input/";
string outputFolder = "output/";
string errorLogPath = "error-log.txt";
Directory.CreateDirectory(outputFolder);
string[] htmlFiles = Directory.GetFiles(inputFolder, "*.html");
var renderer = new ChromePdfRenderer();
var errorLog = new ConcurrentBag<string>();
int processed = 0;
int failed = 0;
int retried = 0;
const int maxRetries = 3;
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(htmlFiles, options, htmlFile =>
{
string fileName = Path.GetFileNameWithoutExtension(htmlFile);
string outputPath = Path.Combine(outputFolder, $"{fileName}.pdf");
int attempt = 0;
bool success = false;
while (attempt < maxRetries && !success)
{
attempt++;
try
{
using var pdf = renderer.RenderHtmlFileAsPdf(htmlFile);
pdf.SaveAs(outputPath);
success = true;
Interlocked.Increment(ref processed);
if (attempt > 1)
{
Interlocked.Increment(ref retried);
Console.WriteLine($"[OK] {fileName}.pdf (succeeded on attempt {attempt})");
}
else
{
Console.WriteLine($"[OK] {fileName}.pdf");
}
}
catch (Exception ex) when (IsTransientException(ex) && attempt < maxRetries)
{
// Transient error - wait and retry with exponential backoff
int delayMs = (int)Math.Pow(2, attempt) * 500;
Console.WriteLine($"[RETRY] {fileName}: {ex.Message} (attempt {attempt}, waiting {delayMs}ms)");
Thread.Sleep(delayMs);
}
catch (Exception ex)
{
// Non-transient error or max retries exceeded
Interlocked.Increment(ref failed);
string errorMessage = $"{DateTime.Now:yyyy-MM-dd HH:mm:ss} | {fileName} | {ex.GetType().Name} | {ex.Message}";
errorLog.Add(errorMessage);
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
}
});
// Write error log
if (errorLog.Count > 0)
{
File.WriteAllLines(errorLogPath, errorLog);
}
Console.WriteLine($"\nBatch complete:");
Console.WriteLine($" Processed: {processed}");
Console.WriteLine($" Failed: {failed}");
Console.WriteLine($" Retried: {retried}");
if (failed > 0)
{
Console.WriteLine($" Error log: {errorLogPath}");
}
// Helper to identify transient exceptions worth retrying
bool IsTransientException(Exception ex)
{
return ex is IOException ||
ex is OutOfMemoryException ||
ex.Message.Contains("timeout", StringComparison.OrdinalIgnoreCase) ||
ex.Message.Contains("locked", StringComparison.OrdinalIgnoreCase);
}Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading
Imports System.Collections.Concurrent
Module Program
Sub Main()
Dim inputFolder As String = "input/"
Dim outputFolder As String = "output/"
Dim errorLogPath As String = "error-log.txt"
Directory.CreateDirectory(outputFolder)
Dim htmlFiles As String() = Directory.GetFiles(inputFolder, "*.html")
Dim renderer As New ChromePdfRenderer()
Dim errorLog As New ConcurrentBag(Of String)()
Dim processed As Integer = 0
Dim failed As Integer = 0
Dim retried As Integer = 0
Const maxRetries As Integer = 3
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(htmlFiles, options, Sub(htmlFile)
Dim fileName As String = Path.GetFileNameWithoutExtension(htmlFile)
Dim outputPath As String = Path.Combine(outputFolder, $"{fileName}.pdf")
Dim attempt As Integer = 0
Dim success As Boolean = False
While attempt < maxRetries AndAlso Not success
attempt += 1
Try
Using pdf = renderer.RenderHtmlFileAsPdf(htmlFile)
pdf.SaveAs(outputPath)
success = True
Interlocked.Increment(processed)
If attempt > 1 Then
Interlocked.Increment(retried)
Console.WriteLine($"[OK] {fileName}.pdf (succeeded on attempt {attempt})")
Else
Console.WriteLine($"[OK] {fileName}.pdf")
End If
End Using
Catch ex As Exception When IsTransientException(ex) AndAlso attempt < maxRetries
' Transient error - wait and retry with exponential backoff
Dim delayMs As Integer = CInt(Math.Pow(2, attempt)) * 500
Console.WriteLine($"[RETRY] {fileName}: {ex.Message} (attempt {attempt}, waiting {delayMs}ms)")
Thread.Sleep(delayMs)
Catch ex As Exception
' Non-transient error or max retries exceeded
Interlocked.Increment(failed)
Dim errorMessage As String = $"{DateTime.Now:yyyy-MM-dd HH:mm:ss} | {fileName} | {ex.GetType().Name} | {ex.Message}"
errorLog.Add(errorMessage)
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End While
End Sub)
' Write error log
If errorLog.Count > 0 Then
File.WriteAllLines(errorLogPath, errorLog)
End If
Console.WriteLine($"{vbCrLf}Batch complete:")
Console.WriteLine($" Processed: {processed}")
Console.WriteLine($" Failed: {failed}")
Console.WriteLine($" Retried: {retried}")
If failed > 0 Then
Console.WriteLine($" Error log: {errorLogPath}")
End If
End Sub
' Helper to identify transient exceptions worth retrying
Function IsTransientException(ex As Exception) As Boolean
Return TypeOf ex Is IOException OrElse
TypeOf ex Is OutOfMemoryException OrElse
ex.Message.Contains("timeout", StringComparison.OrdinalIgnoreCase) OrElse
ex.Message.Contains("locked", StringComparison.OrdinalIgnoreCase)
End Function
End ModuleÜberprüfen Sie nach Abschluss des Stapels das Fehlerprotokoll, um zu verstehen, welche Dateien fehlgeschlagen sind und warum. Häufige Fehlerursachen sind beschädigte Quelldateien, passwortgeschützte PDFs, nicht unterstützte Funktionen im Quellinhalt und Speicherplatzmangel bei sehr großen Dokumenten.
Wiederholungslogik für vorübergehende Fehler
Einige Fehler sind vorübergehend - sie werden erfolgreich sein, wenn Sie es erneut versuchen. Dazu gehören Konkurrenz im Dateisystem (ein anderer Prozess hat die Datei gesperrt), temporärer Speicherdruck (der GC hat noch nicht aufgeholt) und Netzwerk-Timeouts beim Laden externer Ressourcen in HTML-Inhalten. Das obige Codebeispiel behandelt diese mit exponentiellem Backoff - es beginnt mit einer kurzen Verzögerung und verdoppelt diese bei jedem Wiederholungsversuch, wobei eine maximale Anzahl von Wiederholungsversuchen (normalerweise 3) erreicht wird.
Der Schlüssel ist die Unterscheidung zwischen wiederholbaren und nicht wiederholbaren Fehlern. Bei einer Fehlermeldung IOException (Datei gesperrt) oder OutOfMemoryException (vorübergehender Druck) lohnt sich ein erneuter Versuch. Ein ArgumentException (ungültige Eingabe) oder ein konsistenter Darstellungsfehler ist nicht hilfreich – ein erneuter Versuch hilft nicht und Sie verschwenden Zeit und Ressourcen.
Checkpointing für Wiederaufnahme nach Absturz
Wenn ein Batch-Job 50.000 Dateien über mehrere Stunden hinweg verarbeitet, sollte ein Absturz bei Datei Nr. 35.000 nicht bedeuten, dass man wieder von vorne anfangen muss. Checkpointing - die Aufzeichnung, welche Dateien erfolgreich verarbeitet wurden - ermöglicht es Ihnen, dort fortzufahren, wo Sie aufgehört haben.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-checkpointing.csusing IronPdf;
using System;
using System.IO;
using System.Linq;
using System.Threading.Tasks;
using System.Threading;
using System.Collections.Generic;
string inputFolder = "input/";
string outputFolder = "output/";
string checkpointPath = "checkpoint.txt";
string errorLogPath = "errors.txt";
Directory.CreateDirectory(outputFolder);
// Load checkpoint - files already processed successfully
var completedFiles = new HashSet<string>();
if (File.Exists(checkpointPath))
{
completedFiles = new HashSet<string>(File.ReadAllLines(checkpointPath));
Console.WriteLine($"Resuming from checkpoint: {completedFiles.Count} files already processed");
}
// Get files to process (excluding already completed)
string[] allFiles = Directory.GetFiles(inputFolder, "*.html");
string[] filesToProcess = allFiles
.Where(f => !completedFiles.Contains(Path.GetFileName(f)))
.ToArray();
Console.WriteLine($"Files to process: {filesToProcess.Length} (skipping {completedFiles.Count} already done)");
var renderer = new ChromePdfRenderer();
var checkpointLock = new object();
int processed = 0;
int failed = 0;
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(filesToProcess, options, htmlFile =>
{
string fileName = Path.GetFileName(htmlFile);
string baseName = Path.GetFileNameWithoutExtension(htmlFile);
string outputPath = Path.Combine(outputFolder, $"{baseName}.pdf");
try
{
using var pdf = renderer.RenderHtmlFileAsPdf(htmlFile);
pdf.SaveAs(outputPath);
// Record success in checkpoint (thread-safe)
lock (checkpointLock)
{
File.AppendAllText(checkpointPath, fileName + Environment.NewLine);
}
Interlocked.Increment(ref processed);
Console.WriteLine($"[OK] {baseName}.pdf");
}
catch (Exception ex)
{
Interlocked.Increment(ref failed);
// Log error for review
lock (checkpointLock)
{
File.AppendAllText(errorLogPath,
$"{DateTime.Now:yyyy-MM-dd HH:mm:ss} | {fileName} | {ex.Message}{Environment.NewLine}");
}
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
});
Console.WriteLine($"\nBatch complete:");
Console.WriteLine($" Newly processed: {processed}");
Console.WriteLine($" Failed: {failed}");
Console.WriteLine($" Total completed: {completedFiles.Count + processed}");
Console.WriteLine($" Checkpoint saved to: {checkpointPath}");Imports IronPdf
Imports System
Imports System.IO
Imports System.Linq
Imports System.Threading.Tasks
Imports System.Threading
Imports System.Collections.Generic
Module Program
Sub Main()
Dim inputFolder As String = "input/"
Dim outputFolder As String = "output/"
Dim checkpointPath As String = "checkpoint.txt"
Dim errorLogPath As String = "errors.txt"
Directory.CreateDirectory(outputFolder)
' Load checkpoint - files already processed successfully
Dim completedFiles As New HashSet(Of String)()
If File.Exists(checkpointPath) Then
completedFiles = New HashSet(Of String)(File.ReadAllLines(checkpointPath))
Console.WriteLine($"Resuming from checkpoint: {completedFiles.Count} files already processed")
End If
' Get files to process (excluding already completed)
Dim allFiles As String() = Directory.GetFiles(inputFolder, "*.html")
Dim filesToProcess As String() = allFiles _
.Where(Function(f) Not completedFiles.Contains(Path.GetFileName(f))) _
.ToArray()
Console.WriteLine($"Files to process: {filesToProcess.Length} (skipping {completedFiles.Count} already done)")
Dim renderer As New ChromePdfRenderer()
Dim checkpointLock As New Object()
Dim processed As Integer = 0
Dim failed As Integer = 0
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(filesToProcess, options, Sub(htmlFile)
Dim fileName As String = Path.GetFileName(htmlFile)
Dim baseName As String = Path.GetFileNameWithoutExtension(htmlFile)
Dim outputPath As String = Path.Combine(outputFolder, $"{baseName}.pdf")
Try
Using pdf = renderer.RenderHtmlFileAsPdf(htmlFile)
pdf.SaveAs(outputPath)
End Using
' Record success in checkpoint (thread-safe)
SyncLock checkpointLock
File.AppendAllText(checkpointPath, fileName & Environment.NewLine)
End SyncLock
Interlocked.Increment(processed)
Console.WriteLine($"[OK] {baseName}.pdf")
Catch ex As Exception
Interlocked.Increment(failed)
' Log error for review
SyncLock checkpointLock
File.AppendAllText(errorLogPath,
$"{DateTime.Now:yyyy-MM-dd HH:mm:ss} | {fileName} | {ex.Message}{Environment.NewLine}")
End SyncLock
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End Sub)
Console.WriteLine(vbCrLf & "Batch complete:")
Console.WriteLine($" Newly processed: {processed}")
Console.WriteLine($" Failed: {failed}")
Console.WriteLine($" Total completed: {completedFiles.Count + processed}")
Console.WriteLine($" Checkpoint saved to: {checkpointPath}")
End Sub
End ModuleDie Checkpoint-Datei dient als dauerhafte Aufzeichnung der abgeschlossenen Arbeit. Wenn die Pipeline startet, liest sie die Prüfpunktdatei und überspringt alle Dateien, die bereits erfolgreich verarbeitet wurden. Wenn die Verarbeitung einer Datei abgeschlossen ist, wird ihr Pfad an die Prüfpunktdatei angehängt. Dieser Ansatz ist einfach, dateibasiert und erfordert keine externen Abhängigkeiten.
Für anspruchsvollere Szenarien sollten Sie eine Datenbanktabelle oder einen verteilten Cache (wie Redis) als Checkpoint-Speicher verwenden, insbesondere wenn mehrere Worker parallel auf verschiedenen Rechnern Dateien verarbeiten.
Prüfung vor und nach der Bearbeitung
Die Validierung ist das Kernstück einer belastbaren Pipeline. Die Validierung vor der Verarbeitung fängt problematische Eingaben ab, bevor sie Verarbeitungszeit verschwenden; die Validierung nach der Verarbeitung stellt sicher, dass die Ausgabe Ihren Qualitäts- und Compliance-Anforderungen entspricht.
Eingabe
Diese Implementierung umschließt die Verarbeitungsschleife mit den Hilfsfunktionen PreValidate und PostValidate. Bei der Vorabprüfung werden Dateigröße, Inhaltstyp und grundlegende HTML-Struktur vor der Verarbeitung überprüft. Bei der Nachvalidierung wird überprüft, ob die ausgegebene PDF-Datei eine gültige Seitenzahl und eine angemessene Dateigröße aufweist. Validierte Dateien werden in einen separaten Ordner verschoben, während fehlerhafte Dateien zur manuellen Überprüfung in einen Ablehnungsordner geleitet werden.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-validation.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
using System.Threading;
using System.Collections.Concurrent;
string inputFolder = "input/";
string outputFolder = "output/";
string validatedFolder = "validated/";
string rejectedFolder = "rejected/";
Directory.CreateDirectory(outputFolder);
Directory.CreateDirectory(validatedFolder);
Directory.CreateDirectory(rejectedFolder);
string[] inputFiles = Directory.GetFiles(inputFolder, "*.html");
var renderer = new ChromePdfRenderer();
int preValidationFailed = 0;
int processingFailed = 0;
int postValidationFailed = 0;
int succeeded = 0;
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(inputFiles, options, inputFile =>
{
string fileName = Path.GetFileNameWithoutExtension(inputFile);
string outputPath = Path.Combine(outputFolder, $"{fileName}.pdf");
// Pre-validation: Check input file
if (!PreValidate(inputFile))
{
Interlocked.Increment(ref preValidationFailed);
Console.WriteLine($"[SKIP] {fileName}: Failed pre-validation");
return;
}
try
{
// Process
using var pdf = renderer.RenderHtmlFileAsPdf(inputFile);
pdf.SaveAs(outputPath);
// Post-validation: Check output file
if (PostValidate(outputPath))
{
// Move to validated folder
string validatedPath = Path.Combine(validatedFolder, $"{fileName}.pdf");
File.Move(outputPath, validatedPath, overwrite: true);
Interlocked.Increment(ref succeeded);
Console.WriteLine($"[OK] {fileName}.pdf (validated)");
}
else
{
// Move to rejected folder for manual review
string rejectedPath = Path.Combine(rejectedFolder, $"{fileName}.pdf");
File.Move(outputPath, rejectedPath, overwrite: true);
Interlocked.Increment(ref postValidationFailed);
Console.WriteLine($"[REJECT] {fileName}.pdf: Failed post-validation");
}
}
catch (Exception ex)
{
Interlocked.Increment(ref processingFailed);
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
});
Console.WriteLine($"\nValidation summary:");
Console.WriteLine($" Succeeded: {succeeded}");
Console.WriteLine($" Pre-validation failed: {preValidationFailed}");
Console.WriteLine($" Processing failed: {processingFailed}");
Console.WriteLine($" Post-validation failed: {postValidationFailed}");
// Pre-validation: Quick checks on input file
bool PreValidate(string filePath)
{
try
{
var fileInfo = new FileInfo(filePath);
// Check file exists and is readable
if (!fileInfo.Exists) return false;
// Check file is not empty
if (fileInfo.Length == 0) return false;
// Check file is not too large (e.g., 50MB limit)
if (fileInfo.Length > 50 * 1024 * 1024) return false;
// Quick content check - must be valid HTML
string content = File.ReadAllText(filePath);
if (string.IsNullOrWhiteSpace(content)) return false;
if (!content.Contains("<html", StringComparison.OrdinalIgnoreCase) &&
!content.Contains("<!DOCTYPE", StringComparison.OrdinalIgnoreCase))
{
return false;
}
return true;
}
catch
{
return false;
}
}
// Post-validation: Verify output PDF meets requirements
bool PostValidate(string pdfPath)
{
try
{
using var pdf = PdfDocument.FromFile(pdfPath);
// Check PDF has at least one page
if (pdf.PageCount < 1) return false;
// Check file size is reasonable (not just header, not corrupted)
var fileInfo = new FileInfo(pdfPath);
if (fileInfo.Length < 1024) return false;
return true;
}
catch
{
return false;
}
}Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading.Tasks
Imports System.Threading
Imports System.Collections.Concurrent
Module Program
Sub Main()
Dim inputFolder As String = "input/"
Dim outputFolder As String = "output/"
Dim validatedFolder As String = "validated/"
Dim rejectedFolder As String = "rejected/"
Directory.CreateDirectory(outputFolder)
Directory.CreateDirectory(validatedFolder)
Directory.CreateDirectory(rejectedFolder)
Dim inputFiles As String() = Directory.GetFiles(inputFolder, "*.html")
Dim renderer As New ChromePdfRenderer()
Dim preValidationFailed As Integer = 0
Dim processingFailed As Integer = 0
Dim postValidationFailed As Integer = 0
Dim succeeded As Integer = 0
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(inputFiles, options, Sub(inputFile)
Dim fileName As String = Path.GetFileNameWithoutExtension(inputFile)
Dim outputPath As String = Path.Combine(outputFolder, $"{fileName}.pdf")
' Pre-validation: Check input file
If Not PreValidate(inputFile) Then
Interlocked.Increment(preValidationFailed)
Console.WriteLine($"[SKIP] {fileName}: Failed pre-validation")
Return
End If
Try
' Process
Using pdf = renderer.RenderHtmlFileAsPdf(inputFile)
pdf.SaveAs(outputPath)
' Post-validation: Check output file
If PostValidate(outputPath) Then
' Move to validated folder
Dim validatedPath As String = Path.Combine(validatedFolder, $"{fileName}.pdf")
File.Move(outputPath, validatedPath, overwrite:=True)
Interlocked.Increment(succeeded)
Console.WriteLine($"[OK] {fileName}.pdf (validated)")
Else
' Move to rejected folder for manual review
Dim rejectedPath As String = Path.Combine(rejectedFolder, $"{fileName}.pdf")
File.Move(outputPath, rejectedPath, overwrite:=True)
Interlocked.Increment(postValidationFailed)
Console.WriteLine($"[REJECT] {fileName}.pdf: Failed post-validation")
End If
End Using
Catch ex As Exception
Interlocked.Increment(processingFailed)
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End Sub)
Console.WriteLine(vbCrLf & "Validation summary:")
Console.WriteLine($" Succeeded: {succeeded}")
Console.WriteLine($" Pre-validation failed: {preValidationFailed}")
Console.WriteLine($" Processing failed: {processingFailed}")
Console.WriteLine($" Post-validation failed: {postValidationFailed}")
End Sub
' Pre-validation: Quick checks on input file
Function PreValidate(filePath As String) As Boolean
Try
Dim fileInfo As New FileInfo(filePath)
' Check file exists and is readable
If Not fileInfo.Exists Then Return False
' Check file is not empty
If fileInfo.Length = 0 Then Return False
' Check file is not too large (e.g., 50MB limit)
If fileInfo.Length > 50 * 1024 * 1024 Then Return False
' Quick content check - must be valid HTML
Dim content As String = File.ReadAllText(filePath)
If String.IsNullOrWhiteSpace(content) Then Return False
If Not content.Contains("<html", StringComparison.OrdinalIgnoreCase) AndAlso
Not content.Contains("<!DOCTYPE", StringComparison.OrdinalIgnoreCase) Then
Return False
End If
Return True
Catch
Return False
End Try
End Function
' Post-validation: Verify output PDF meets requirements
Function PostValidate(pdfPath As String) As Boolean
Try
Using pdf = PdfDocument.FromFile(pdfPath)
' Check PDF has at least one page
If pdf.PageCount < 1 Then Return False
' Check file size is reasonable (not just header, not corrupted)
Dim fileInfo As New FileInfo(pdfPath)
If fileInfo.Length < 1024 Then Return False
Return True
End Using
Catch
Return False
End Try
End Function
End ModuleAusgabe
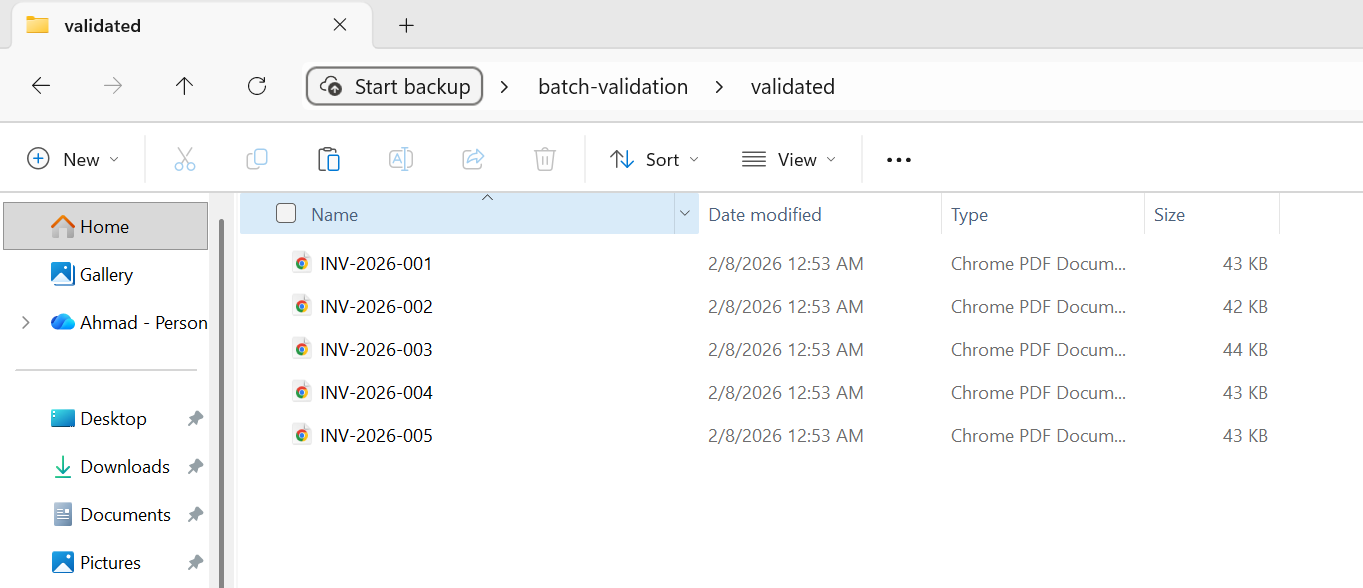
Alle 5 Dateien haben die Validierung bestanden und wurden in den validierten Ordner verschoben.
Die Vorverarbeitungsvalidierung sollte schnell sein - Sie prüfen auf offensichtlich fehlerhafte Eingaben und führen keine vollständige Verarbeitung durch. Die Validierung nach der Bearbeitung kann gründlicher sein, insbesondere bei Konvertierungen, bei denen die Ausgabe bestimmte Standards erfüllen muss (PDF/A, PDF/UA). Jede Datei, die die Nachbearbeitungsprüfung nicht besteht, sollte nicht stillschweigend akzeptiert, sondern zur manuellen Überprüfung gekennzeichnet werden.
Asynchrone und parallele Verarbeitungsmuster
IronPDF unterstützt sowohl Parallel.ForEach (threadbasierte Parallelverarbeitung) als auch async/await (asynchrone Ein-/Ausgabe). Der Schlüssel zur Maximierung des Durchsatzes liegt darin, zu verstehen, wann man welche Tools einsetzt und wie man sie effektiv kombiniert.
Integration der parallelen Aufgabenbibliothek
Parallel.ForEach ist der einfachste und effektivste Ansatz für CPU-intensive Stapelverarbeitungen. Die Rendering-Engine von IronPDF ist CPU-intensiv (HTML-Parsing, CSS-Layout, Bildrasterisierung), und Parallel.ForEach verteilt diese Arbeit automatisch auf alle verfügbaren Kerne.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-tpl.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
using System.Threading;
using System.Diagnostics;
string inputFolder = "input/";
string outputFolder = "output/";
Directory.CreateDirectory(outputFolder);
string[] htmlFiles = Directory.GetFiles(inputFolder, "*.html");
var renderer = new ChromePdfRenderer();
Console.WriteLine($"Processing {htmlFiles.Length} files with {Environment.ProcessorCount} CPU cores");
int processed = 0;
var stopwatch = Stopwatch.StartNew();
// Configure parallelism based on system resources
// Rule of thumb: ProcessorCount / 2 for memory-intensive operations
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Math.Max(1, Environment.ProcessorCount / 2)
};
Console.WriteLine($"Max parallelism: {options.MaxDegreeOfParallelism}");
// Use Parallel.ForEach for CPU-bound batch operations
Parallel.ForEach(htmlFiles, options, htmlFile =>
{
string fileName = Path.GetFileNameWithoutExtension(htmlFile);
string outputPath = Path.Combine(outputFolder, $"{fileName}.pdf");
try
{
// Render HTML to PDF
using var pdf = renderer.RenderHtmlFileAsPdf(htmlFile);
pdf.SaveAs(outputPath);
int current = Interlocked.Increment(ref processed);
// Progress reporting every 10 files
if (current % 10 == 0)
{
double elapsed = stopwatch.Elapsed.TotalSeconds;
double rate = current / elapsed;
double remaining = (htmlFiles.Length - current) / rate;
Console.WriteLine($"Progress: {current}/{htmlFiles.Length} ({rate:F1} files/sec, ~{remaining:F0}s remaining)");
}
}
catch (Exception ex)
{
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
});
stopwatch.Stop();
double totalRate = processed / stopwatch.Elapsed.TotalSeconds;
Console.WriteLine($"\nComplete:");
Console.WriteLine($" Files processed: {processed}/{htmlFiles.Length}");
Console.WriteLine($" Total time: {stopwatch.Elapsed.TotalSeconds:F1}s");
Console.WriteLine($" Average rate: {totalRate:F1} files/sec");
Console.WriteLine($" Time per file: {stopwatch.Elapsed.TotalMilliseconds / processed:F0}ms");
// Memory monitoring helper (call between chunks for large batches)
void CheckMemoryPressure()
{
const long memoryThreshold = 4L * 1024 * 1024 * 1024; // 4 GB
long currentMemory = GC.GetTotalMemory(forceFullCollection: false);
if (currentMemory > memoryThreshold)
{
Console.WriteLine($"Memory pressure detected ({currentMemory / 1024 / 1024}MB), forcing GC...");
GC.Collect();
GC.WaitForPendingFinalizers();
GC.Collect();
}
}Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading.Tasks
Imports System.Threading
Imports System.Diagnostics
Module Program
Sub Main()
Dim inputFolder As String = "input/"
Dim outputFolder As String = "output/"
Directory.CreateDirectory(outputFolder)
Dim htmlFiles As String() = Directory.GetFiles(inputFolder, "*.html")
Dim renderer As New ChromePdfRenderer()
Console.WriteLine($"Processing {htmlFiles.Length} files with {Environment.ProcessorCount} CPU cores")
Dim processed As Integer = 0
Dim stopwatch As Stopwatch = Stopwatch.StartNew()
' Configure parallelism based on system resources
' Rule of thumb: ProcessorCount / 2 for memory-intensive operations
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Math.Max(1, Environment.ProcessorCount \ 2)
}
Console.WriteLine($"Max parallelism: {options.MaxDegreeOfParallelism}")
' Use Parallel.ForEach for CPU-bound batch operations
Parallel.ForEach(htmlFiles, options, Sub(htmlFile)
Dim fileName As String = Path.GetFileNameWithoutExtension(htmlFile)
Dim outputPath As String = Path.Combine(outputFolder, $"{fileName}.pdf")
Try
' Render HTML to PDF
Using pdf = renderer.RenderHtmlFileAsPdf(htmlFile)
pdf.SaveAs(outputPath)
End Using
Dim current As Integer = Interlocked.Increment(processed)
' Progress reporting every 10 files
If current Mod 10 = 0 Then
Dim elapsed As Double = stopwatch.Elapsed.TotalSeconds
Dim rate As Double = current / elapsed
Dim remaining As Double = (htmlFiles.Length - current) / rate
Console.WriteLine($"Progress: {current}/{htmlFiles.Length} ({rate:F1} files/sec, ~{remaining:F0}s remaining)")
End If
Catch ex As Exception
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End Sub)
stopwatch.Stop()
Dim totalRate As Double = processed / stopwatch.Elapsed.TotalSeconds
Console.WriteLine(vbCrLf & "Complete:")
Console.WriteLine($" Files processed: {processed}/{htmlFiles.Length}")
Console.WriteLine($" Total time: {stopwatch.Elapsed.TotalSeconds:F1}s")
Console.WriteLine($" Average rate: {totalRate:F1} files/sec")
Console.WriteLine($" Time per file: {stopwatch.Elapsed.TotalMilliseconds / processed:F0}ms")
' Memory monitoring helper (call between chunks for large batches)
CheckMemoryPressure()
End Sub
Sub CheckMemoryPressure()
Const memoryThreshold As Long = 4L * 1024 * 1024 * 1024 ' 4 GB
Dim currentMemory As Long = GC.GetTotalMemory(forceFullCollection:=False)
If currentMemory > memoryThreshold Then
Console.WriteLine($"Memory pressure detected ({currentMemory \ 1024 \ 1024}MB), forcing GC...")
GC.Collect()
GC.WaitForPendingFinalizers()
GC.Collect()
End If
End Sub
End ModuleDie Option MaxDegreeOfParallelism ist entscheidend. Ohne diese Option versucht die TPL, alle verfügbaren Kerne zu nutzen, was zu einer Überlastung des Speichers führen kann, wenn jedes Rendering ressourcenintensiv ist. Legen Sie diesen Wert auf der Grundlage des verfügbaren Arbeitsspeichers Ihres Systems geteilt durch den typischen Speicherverbrauch pro Render fest (in der Regel 100-300 MB pro gleichzeitigem Render für komplexes HTML).
Kontrolle der Gleichzeitigkeit (SemaphoreSlim)
Wenn Sie eine feinere Kontrolle über die Parallelität benötigen, als Parallel.ForEach bietet – zum Beispiel beim Mischen von asynchroner E/A mit CPU-gebundenem Rendering –, bietet Ihnen SemaphoreSlim eine explizite Kontrolle darüber, wie viele Operationen gleichzeitig ausgeführt werden. Das Muster ist einfach: Erstellen Sie ein SemaphoreSlim mit der gewünschten Parallelitätsgrenze (z. B. 4 gleichzeitige Renderings), rufen Sie WaitAsync vor jedem Rendering auf und Release in einem finally-Block danach. Starten Sie dann alle Aufgaben mit Task.WhenAll.
Dieses Muster ist besonders nützlich, wenn Ihre Pipeline sowohl E/A-gebundene Schritte (Lesen von Dateien aus dem Blob-Speicher, Schreiben von Ergebnissen in eine Datenbank) als auch CPU-gebundene Schritte (Rendern von PDFs) umfasst. Der Semaphor begrenzt die CPU-gebundene Rendering-Gleichzeitigkeit, während die E/A-gebundenen Schritte ohne Drosselung ablaufen können.
Best Practices für Async/Await
IronPDF bietet asynchrone Varianten seiner Rendering-Methoden an, darunter RenderHtmlAsPdfAsync, RenderUrlAsPdfAsync und RenderHtmlFileAsPdfAsync. Sie sind ideal für Webanwendungen (bei denen das Blockieren des Anfrage-Threads inakzeptabel ist) und für Pipelines, die PDF-Rendering mit asynchronen E/A-Operationen kombinieren.
Einige wichtige asynchrone Best Practices für die Stapelverarbeitung:
Verwenden Sie nicht Task.Run, um synchrone IronPDF Methoden zu umschließen – verwenden Sie stattdessen die nativen asynchronen Varianten. Das Einkapseln synchroner Methoden in Task.Run verschwendet einen Thread-Pool-Thread und verursacht zusätzlichen Aufwand ohne jeglichen Nutzen.
Verwenden Sie .Result oder .Wait() nicht bei asynchronen Aufgaben – dies blockiert den aufrufenden Thread und kann zu Deadlocks in UI- oder ASP.NET Kontexten führen. Verwenden Sie immer await.
Fassen Sie Ihre Task.WhenAll-Aufrufe zusammen, anstatt alle Aufgaben gleichzeitig abzuwarten. Wenn Sie 10.000 Aufgaben haben und Task.WhenAll gleichzeitig auf alle diese Aufgaben anwenden, starten Sie 10.000 parallele Operationen. Verwenden Sie stattdessen .Chunk(10) oder einen ähnlichen Ansatz, um sie in Gruppen zu verarbeiten und jede Gruppe nacheinander abzuwarten.
Speichererschöpfung vermeiden
Die Erschöpfung des Speichers ist die häufigste Fehlerart bei der Stapelverarbeitung von PDF-Dateien. Der defensive Ansatz besteht darin, die Speichernutzung mit GC.GetTotalMemory() vor jedem Rendern zu überwachen und eine Sammlung auszulösen, wenn der Verbrauch einen Schwellenwert überschreitet (z. B. 4 GB oder 80 % des verfügbaren RAM). Rufen Sie GC.Collect(), gefolgt von GC.WaitForPendingFinalizers() und einem zweiten GC.Collect() auf, um so viel Speicher wie möglich freizugeben, bevor Sie fortfahren. Dies fügt eine kurze Pause hinzu, verhindert aber die katastrophale Alternative, dass ein OutOfMemoryException Ihren gesamten Batch bei Datei Nr. 30.000 zum Absturz bringt.
Kombiniert man dies mit der Drosselung MaxDegreeOfParallelism aus dem TPL-Abschnitt und dem Entsorgungsmuster using aus dem Abschnitt zur Speicherverwaltung, erhält man einen dreischichtigen Schutz gegen Speicherprobleme: Begrenzung der Parallelität, aggressive Entsorgung und Überwachung mit einem Sicherheitsventil.
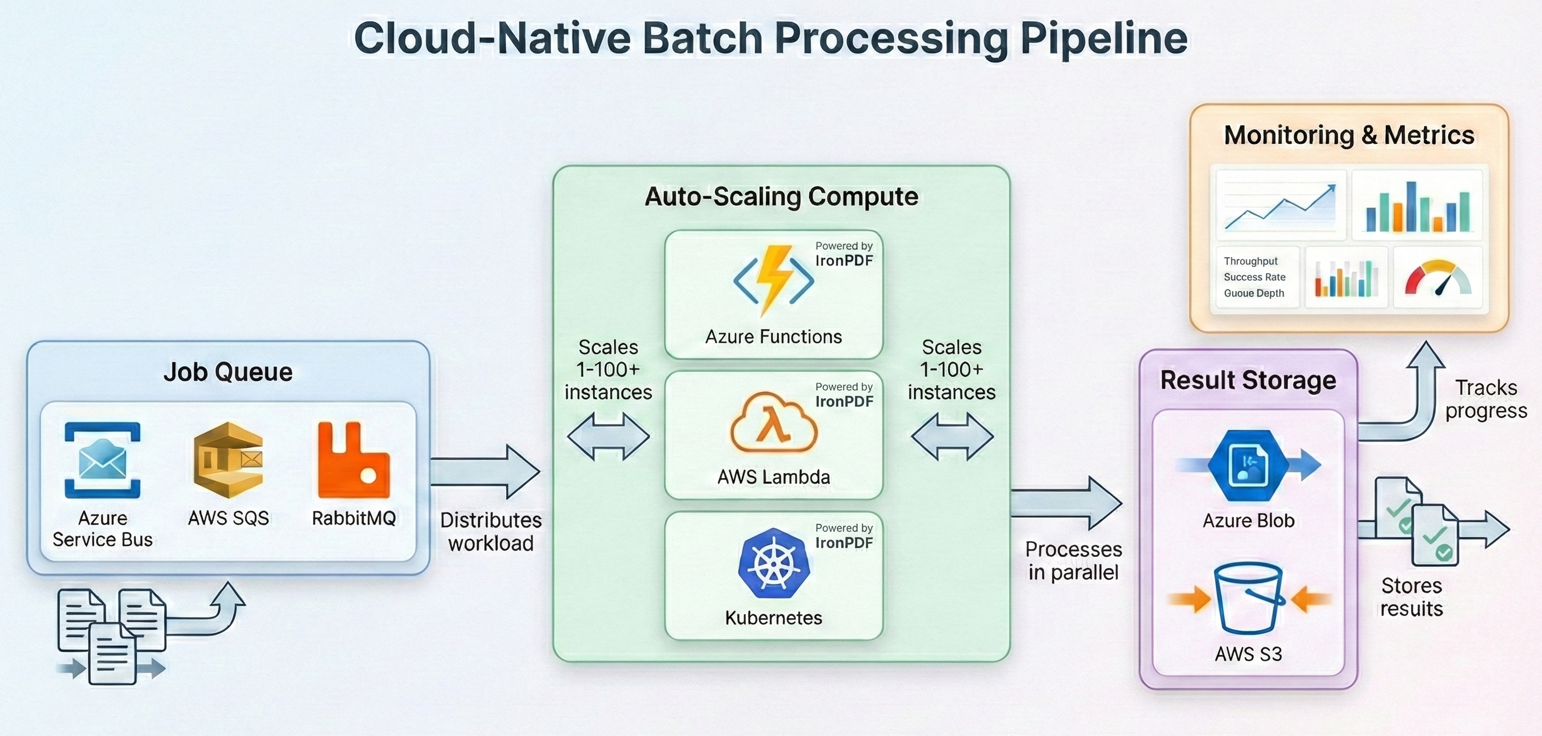
Cloud-Bereitstellung für Batch-Aufträge
Die moderne Batch-Verarbeitung wird zunehmend in der Cloud ausgeführt, wo Sie die Rechenressourcen entsprechend den Arbeitsanforderungen skalieren können und nur für das zahlen, was Sie nutzen. IronPDF läuft auf allen wichtigen Cloud-Plattformen - hier erfahren Sie, wie Sie Batch-Pipelines für jede Plattform erstellen.
Funktionen mit dauerhaften Funktionen sichern
Azure Durable Functions bieten eine integrierte Orchestrierung für Fan-Out/Fan-In-Muster und eignen sich daher hervorragend für die Stapelverarbeitung von PDF-Dateien. Die Orchestrator-Funktion verteilt die Arbeit auf mehrere Instanzen von Aktivitätsfunktionen, die jeweils eine Teilmenge von Dateien verarbeiten. Ihr Orchestrator ruft CallActivityAsync in einer Fan-Out-Schleife auf, jede Aktivitätsfunktion instanziiert ein ChromePdfRenderer, verarbeitet ihren Dateiblock, und der Orchestrator sammelt die Ergebnisse.
Wichtige Überlegungen zu Azure Functions: Der Standard-Verbrauchsplan hat ein 5-Minuten-Timeout pro Funktionsaufruf und begrenzten Speicher. Verwenden Sie für die Stapelverarbeitung den Premium- oder Dedicated-Plan, der längere Timeouts und mehr Speicher unterstützt. IronPDF erfordert die volle .NET-Laufzeit (nicht gekürzt). Stellen Sie also sicher, dass Ihre Funktionsanwendung for .NET 8+ mit dem entsprechenden Laufzeitkennzeichen konfiguriert ist.
AWS Lambda mit Step-Funktionen
AWS Step Functions bieten eine ähnliche Orchestrierungsfunktion wie Azure Durable Functions. Jeder Schritt im Zustandsautomaten ruft eine Lambda-Funktion auf, die ein Paket von Dateien verarbeitet. Ihr Lambda-Handler empfängt einen Batch von S3-Objektschlüsseln, lädt jedes PDF mit PdfDocument.FromFile, wendet Ihre Verarbeitungspipeline an (Komprimierung, Formatkonvertierung usw.) und schreibt die Ergebnisse zurück in einen S3-Ausgabe-Bucket.
AWS Lambda hat eine maximale Ausführungszeit von 15 Minuten und begrenzten Speicherplatz (standardmäßig 512 MB, konfigurierbar bis zu 10 GB). Für große Batch-Aufträge verwenden Sie Step Functions, um die Arbeitslast zu unterteilen und jedes Chunk in einem separaten Lambda-Aufruf zu verarbeiten. Speichern Sie die Zwischenergebnisse in S3 statt in einem lokalen Speicher.
Kubernetes-Jobplanung
Für Unternehmen, die eigene Kubernetes-Cluster betreiben, lässt sich die PDF-Batch-Verarbeitung gut mit Kubernetes Jobs und CronJobs abbilden. Jeder Pod führt einen Batch Worker aus, der Dateien aus einer Warteschlange (Azure Service Bus, RabbitMQ oder SQS) abruft, sie mit IronPDF verarbeitet und die Ergebnisse in den Objektspeicher schreibt. Die Worker-Schleife folgt dem gleichen Muster wie in früheren Abschnitten beschrieben: eine Nachricht aus der Warteschlange nehmen, ChromePdfRenderer.RenderHtmlAsPdf() oder PdfDocument.FromFile() verwenden, um das Dokument zu verarbeiten, das Ergebnis hochladen und die Nachricht bestätigen. Umschließen Sie die Verarbeitung mit demselben try-catch und der Wiederholungslogik aus den Resilienz-Mustern, und verwenden Sie SemaphoreSlim, um die Gleichzeitigkeit pro Pod zu steuern.
IronPDF bietet offizielle Docker-Unterstützung und läuft auf Linux-Containern. Verwenden Sie das NuGet Paket IronPdf zusammen mit den entsprechenden nativen Laufzeitpaketen für das Betriebssystem Ihres Containers (z. B. IronPdf.Linux für Linux-basierte Images). Definieren Sie für Kubernetes Ressourcenanforderungen und -grenzen, die den Speicheranforderungen von IronPDF entsprechen (in der Regel 512 MB-2 GB pro Pod, je nach Gleichzeitigkeit). Horizontal Pod Autoscaler kann Worker auf der Grundlage der Warteschlangentiefe skalieren, und das Checkpointing-Muster stellt sicher, dass keine Arbeit verloren geht, wenn Pods verdrängt werden.
Strategien zur Kostenoptimierung
Die Stapelverarbeitung in der Cloud kann teuer werden, wenn man nicht auf die Ressourcenzuweisung achtet. Hier sind die Strategien, die die größte Wirkung haben:
Richtig dimensionierte Rechenleistung. PDF-Rendering ist CPU- und speicherintensiv, nicht GPU-intensiv. Verwenden Sie rechenoptimierte Instanzen (C-Series auf Azure, C-Type auf AWS) und keine Allzweck- oder speicheroptimierten Instanzen. Sie erhalten ein besseres Preis-zu-Render-Verhältnis.
Verwenden Sie Spot/Preemptible Instances für Batch-Workloads, die Unterbrechungen tolerieren können. Die Batch-PDF-Verarbeitung ist von Natur aus wiederaufnehmbar (dank Checkpointing), was sie zu einem idealen Kandidaten für Spot-Preise macht, die in der Regel 60-90 % Rabatt gegenüber On-Demand bieten.
Bearbeiten Sie außerhalb der Hauptgeschäftszeiten, wenn es Ihr Zeitplan erlaubt. Viele Cloud-Anbieter bieten niedrigere Preise oder eine höhere Verfügbarkeit in der Nacht und am Wochenende.
Frühzeitig komprimieren, einmal speichern. Führen Sie die Komprimierung als Teil Ihrer Verarbeitungspipeline und nicht als separaten Schritt aus. Die Speicherung komprimierter PDFs von Anfang an reduziert die laufenden Speicherkosten für die gesamte Lebensdauer des Archivs.
Tier your storage. Verarbeitete PDFs, auf die häufig zugegriffen wird, sollten im Hot Storage abgelegt werden; archivierte PDFs, auf die nur selten zugegriffen wird, sollten auf Cool- oder Archivebenen (Azure Cool/Archive, AWS S3 Glacier) verschoben werden. Allein dadurch können die Speicherkosten um 50-80 % gesenkt werden.
Real-World Pipeline Beispiel
Lassen Sie uns alles mit einer vollständigen, produktionsreifen Batch-Pipeline verbinden, die den gesamten Workflow demonstriert: Ingest → Validieren → Verarbeiten → Archivieren → Berichten.
Dieses Beispiel verarbeitet ein Verzeichnis von HTML-Rechnungsvorlagen, rendert sie in PDF, komprimiert die Ausgabe, konvertiert sie zur Archivierung in PDF/A-3b, validiert das Ergebnis und erstellt am Ende einen zusammenfassenden Bericht.
Verwenden Sie dieselben 5 HTML-Rechnungen aus dem obigen Batch-Konvertierungsbeispiel...
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-full-pipeline.csusing IronPdf;
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Threading.Tasks;
using System.Threading;
using System.Collections.Concurrent;
using System.Diagnostics;
using System.Text.Json;
// Configuration
var config = new PipelineConfig
{
InputFolder = "input/",
OutputFolder = "output/",
ArchiveFolder = "archive/",
ErrorFolder = "errors/",
CheckpointPath = "pipeline-checkpoint.json",
ReportPath = "pipeline-report.json",
MaxConcurrency = Math.Max(1, Environment.ProcessorCount / 2),
MaxRetries = 3,
JpegQuality = 70
};
// Initialize folders
Directory.CreateDirectory(config.OutputFolder);
Directory.CreateDirectory(config.ArchiveFolder);
Directory.CreateDirectory(config.ErrorFolder);
// Load checkpoint for resume capability
var checkpoint = LoadCheckpoint(config.CheckpointPath);
var results = new ConcurrentBag<ProcessingResult>();
var stopwatch = Stopwatch.StartNew();
// Get files to process
string[] allFiles = Directory.GetFiles(config.InputFolder, "*.html");
string[] filesToProcess = allFiles
.Where(f => !checkpoint.CompletedFiles.Contains(Path.GetFileName(f)))
.ToArray();
Console.WriteLine($"Pipeline starting:");
Console.WriteLine($" Total files: {allFiles.Length}");
Console.WriteLine($" Already processed: {checkpoint.CompletedFiles.Count}");
Console.WriteLine($" To process: {filesToProcess.Length}");
Console.WriteLine($" Concurrency: {config.MaxConcurrency}");
var renderer = new ChromePdfRenderer();
var checkpointLock = new object();
var options = new ParallelOptions
{
MaxDegreeOfParallelism = config.MaxConcurrency
};
Parallel.ForEach(filesToProcess, options, inputFile =>
{
var result = new ProcessingResult
{
FileName = Path.GetFileName(inputFile),
StartTime = DateTime.UtcNow
};
try
{
// Stage: Pre-validation
if (!ValidateInput(inputFile))
{
result.Status = "PreValidationFailed";
result.Error = "Input file failed validation";
results.Add(result);
return;
}
string baseName = Path.GetFileNameWithoutExtension(inputFile);
string tempPath = Path.Combine(config.OutputFolder, $"{baseName}.pdf");
string archivePath = Path.Combine(config.ArchiveFolder, $"{baseName}.pdf");
// Stage: Process with retry
PdfDocument pdf = null;
int attempt = 0;
bool success = false;
while (attempt < config.MaxRetries && !success)
{
attempt++;
try
{
pdf = renderer.RenderHtmlFileAsPdf(inputFile);
success = true;
}
catch (Exception ex) when (IsTransient(ex) && attempt < config.MaxRetries)
{
Thread.Sleep((int)Math.Pow(2, attempt) * 500);
}
}
if (!success || pdf == null)
{
result.Status = "ProcessingFailed";
result.Error = "Max retries exceeded";
results.Add(result);
return;
}
using (pdf)
{
// Stage: Compress and convert to PDF/A-3b for archival
pdf.SaveAsPdfA(tempPath, PdfAVersions.PdfA3b);
}
// Stage: Post-validation
if (!ValidateOutput(tempPath))
{
File.Move(tempPath, Path.Combine(config.ErrorFolder, $"{baseName}.pdf"), overwrite: true);
result.Status = "PostValidationFailed";
result.Error = "Output file failed validation";
results.Add(result);
return;
}
// Stage: Archive
File.Move(tempPath, archivePath, overwrite: true);
// Update checkpoint
lock (checkpointLock)
{
checkpoint.CompletedFiles.Add(result.FileName);
SaveCheckpoint(config.CheckpointPath, checkpoint);
}
result.Status = "Success";
result.OutputSize = new FileInfo(archivePath).Length;
result.EndTime = DateTime.UtcNow;
results.Add(result);
Console.WriteLine($"[OK] {baseName}.pdf ({result.OutputSize / 1024}KB)");
}
catch (Exception ex)
{
result.Status = "Error";
result.Error = ex.Message;
result.EndTime = DateTime.UtcNow;
results.Add(result);
Console.WriteLine($"[ERROR] {result.FileName}: {ex.Message}");
}
});
stopwatch.Stop();
// Generate report
var report = new PipelineReport
{
TotalFiles = allFiles.Length,
ProcessedThisRun = results.Count,
Succeeded = results.Count(r => r.Status == "Success"),
PreValidationFailed = results.Count(r => r.Status == "PreValidationFailed"),
ProcessingFailed = results.Count(r => r.Status == "ProcessingFailed"),
PostValidationFailed = results.Count(r => r.Status == "PostValidationFailed"),
Errors = results.Count(r => r.Status == "Error"),
TotalDuration = stopwatch.Elapsed,
AverageFileTime = results.Any() ? TimeSpan.FromMilliseconds(stopwatch.Elapsed.TotalMilliseconds / results.Count) : TimeSpan.Zero
};
string reportJson = JsonSerializer.Serialize(report, new JsonSerializerOptions { WriteIndented = true });
File.WriteAllText(config.ReportPath, reportJson);
Console.WriteLine($"\n=== Pipeline Complete ===");
Console.WriteLine($"Succeeded: {report.Succeeded}");
Console.WriteLine($"Failed: {report.PreValidationFailed + report.ProcessingFailed + report.PostValidationFailed + report.Errors}");
Console.WriteLine($"Duration: {report.TotalDuration.TotalMinutes:F1} minutes");
Console.WriteLine($"Report: {config.ReportPath}");
// Helper methods
bool ValidateInput(string path)
{
try
{
var info = new FileInfo(path);
if (!info.Exists || info.Length == 0 || info.Length > 50 * 1024 * 1024) return false;
string content = File.ReadAllText(path);
return content.Contains("<html", StringComparison.OrdinalIgnoreCase) ||
content.Contains("<!DOCTYPE", StringComparison.OrdinalIgnoreCase);
}
catch { return false; }
}
bool ValidateOutput(string path)
{
try
{
using var pdf = PdfDocument.FromFile(path);
return pdf.PageCount > 0 && new FileInfo(path).Length > 1024;
}
catch { return false; }
}
bool IsTransient(Exception ex) =>
ex is IOException || ex is OutOfMemoryException ||
ex.Message.Contains("timeout", StringComparison.OrdinalIgnoreCase);
Checkpoint LoadCheckpoint(string path)
{
if (File.Exists(path))
{
string json = File.ReadAllText(path);
return JsonSerializer.Deserialize<Checkpoint>(json) ?? new Checkpoint();
}
return new Checkpoint();
}
void SaveCheckpoint(string path, Checkpoint cp) =>
File.WriteAllText(path, JsonSerializer.Serialize(cp));
ata classes
s PipelineConfig
public string InputFolder { get; set; } = "";
public string OutputFolder { get; set; } = "";
public string ArchiveFolder { get; set; } = "";
public string ErrorFolder { get; set; } = "";
public string CheckpointPath { get; set; } = "";
public string ReportPath { get; set; } = "";
public int MaxConcurrency { get; set; }
public int MaxRetries { get; set; }
public int JpegQuality { get; set; }
s Checkpoint
public HashSet<string> CompletedFiles { get; set; } = new();
s ProcessingResult
public string FileName { get; set; } = "";
public string Status { get; set; } = "";
public string Error { get; set; } = "";
public long OutputSize { get; set; }
public DateTime StartTime { get; set; }
public DateTime EndTime { get; set; }
s PipelineReport
public int TotalFiles { get; set; }
public int ProcessedThisRun { get; set; }
public int Succeeded { get; set; }
public int PreValidationFailed { get; set; }
public int ProcessingFailed { get; set; }
public int PostValidationFailed { get; set; }
public int Errors { get; set; }
public TimeSpan TotalDuration { get; set; }
public TimeSpan AverageFileTime { get; set; }Imports IronPdf
Imports System
Imports System.Collections.Generic
Imports System.IO
Imports System.Linq
Imports System.Threading.Tasks
Imports System.Threading
Imports System.Collections.Concurrent
Imports System.Diagnostics
Imports System.Text.Json
' Configuration
Dim config As New PipelineConfig With {
.InputFolder = "input/",
.OutputFolder = "output/",
.ArchiveFolder = "archive/",
.ErrorFolder = "errors/",
.CheckpointPath = "pipeline-checkpoint.json",
.ReportPath = "pipeline-report.json",
.MaxConcurrency = Math.Max(1, Environment.ProcessorCount \ 2),
.MaxRetries = 3,
.JpegQuality = 70
}
' Initialize folders
Directory.CreateDirectory(config.OutputFolder)
Directory.CreateDirectory(config.ArchiveFolder)
Directory.CreateDirectory(config.ErrorFolder)
' Load checkpoint for resume capability
Dim checkpoint As Checkpoint = LoadCheckpoint(config.CheckpointPath)
Dim results As New ConcurrentBag(Of ProcessingResult)()
Dim stopwatch As Stopwatch = Stopwatch.StartNew()
' Get files to process
Dim allFiles As String() = Directory.GetFiles(config.InputFolder, "*.html")
Dim filesToProcess As String() = allFiles.
Where(Function(f) Not checkpoint.CompletedFiles.Contains(Path.GetFileName(f))).
ToArray()
Console.WriteLine("Pipeline starting:")
Console.WriteLine($" Total files: {allFiles.Length}")
Console.WriteLine($" Already processed: {checkpoint.CompletedFiles.Count}")
Console.WriteLine($" To process: {filesToProcess.Length}")
Console.WriteLine($" Concurrency: {config.MaxConcurrency}")
Dim renderer As New ChromePdfRenderer()
Dim checkpointLock As New Object()
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = config.MaxConcurrency
}
Parallel.ForEach(filesToProcess, options, Sub(inputFile)
Dim result As New ProcessingResult With {
.FileName = Path.GetFileName(inputFile),
.StartTime = DateTime.UtcNow
}
Try
' Stage: Pre-validation
If Not ValidateInput(inputFile) Then
result.Status = "PreValidationFailed"
result.Error = "Input file failed validation"
results.Add(result)
Return
End If
Dim baseName As String = Path.GetFileNameWithoutExtension(inputFile)
Dim tempPath As String = Path.Combine(config.OutputFolder, $"{baseName}.pdf")
Dim archivePath As String = Path.Combine(config.ArchiveFolder, $"{baseName}.pdf")
' Stage: Process with retry
Dim pdf As PdfDocument = Nothing
Dim attempt As Integer = 0
Dim success As Boolean = False
While attempt < config.MaxRetries AndAlso Not success
attempt += 1
Try
pdf = renderer.RenderHtmlFileAsPdf(inputFile)
success = True
Catch ex As Exception When IsTransient(ex) AndAlso attempt < config.MaxRetries
Thread.Sleep(CInt(Math.Pow(2, attempt)) * 500)
End Try
End While
If Not success OrElse pdf Is Nothing Then
result.Status = "ProcessingFailed"
result.Error = "Max retries exceeded"
results.Add(result)
Return
End If
Using pdf
' Stage: Compress and convert to PDF/A-3b for archival
pdf.SaveAsPdfA(tempPath, PdfAVersions.PdfA3b)
End Using
' Stage: Post-validation
If Not ValidateOutput(tempPath) Then
File.Move(tempPath, Path.Combine(config.ErrorFolder, $"{baseName}.pdf"), overwrite:=True)
result.Status = "PostValidationFailed"
result.Error = "Output file failed validation"
results.Add(result)
Return
End If
' Stage: Archive
File.Move(tempPath, archivePath, overwrite:=True)
' Update checkpoint
SyncLock checkpointLock
checkpoint.CompletedFiles.Add(result.FileName)
SaveCheckpoint(config.CheckpointPath, checkpoint)
End SyncLock
result.Status = "Success"
result.OutputSize = New FileInfo(archivePath).Length
result.EndTime = DateTime.UtcNow
results.Add(result)
Console.WriteLine($"[OK] {baseName}.pdf ({result.OutputSize \ 1024}KB)")
Catch ex As Exception
result.Status = "Error"
result.Error = ex.Message
result.EndTime = DateTime.UtcNow
results.Add(result)
Console.WriteLine($"[ERROR] {result.FileName}: {ex.Message}")
End Try
End Sub)
stopwatch.Stop()
' Generate report
Dim report As New PipelineReport With {
.TotalFiles = allFiles.Length,
.ProcessedThisRun = results.Count,
.Succeeded = results.Count(Function(r) r.Status = "Success"),
.PreValidationFailed = results.Count(Function(r) r.Status = "PreValidationFailed"),
.ProcessingFailed = results.Count(Function(r) r.Status = "ProcessingFailed"),
.PostValidationFailed = results.Count(Function(r) r.Status = "PostValidationFailed"),
.Errors = results.Count(Function(r) r.Status = "Error"),
.TotalDuration = stopwatch.Elapsed,
.AverageFileTime = If(results.Any(), TimeSpan.FromMilliseconds(stopwatch.Elapsed.TotalMilliseconds / results.Count), TimeSpan.Zero)
}
Dim reportJson As String = JsonSerializer.Serialize(report, New JsonSerializerOptions With {.WriteIndented = True})
File.WriteAllText(config.ReportPath, reportJson)
Console.WriteLine(vbCrLf & "=== Pipeline Complete ===")
Console.WriteLine($"Succeeded: {report.Succeeded}")
Console.WriteLine($"Failed: {report.PreValidationFailed + report.ProcessingFailed + report.PostValidationFailed + report.Errors}")
Console.WriteLine($"Duration: {report.TotalDuration.TotalMinutes:F1} minutes")
Console.WriteLine($"Report: {config.ReportPath}")
' Helper methods
Function ValidateInput(path As String) As Boolean
Try
Dim info As New FileInfo(path)
If Not info.Exists OrElse info.Length = 0 OrElse info.Length > 50 * 1024 * 1024 Then Return False
Dim content As String = File.ReadAllText(path)
Return content.Contains("<html", StringComparison.OrdinalIgnoreCase) OrElse
content.Contains("<!DOCTYPE", StringComparison.OrdinalIgnoreCase)
Catch
Return False
End Try
End Function
Function ValidateOutput(path As String) As Boolean
Try
Using pdf = PdfDocument.FromFile(path)
Return pdf.PageCount > 0 AndAlso New FileInfo(path).Length > 1024
End Using
Catch
Return False
End Try
End Function
Function IsTransient(ex As Exception) As Boolean
Return TypeOf ex Is IOException OrElse TypeOf ex Is OutOfMemoryException OrElse
ex.Message.Contains("timeout", StringComparison.OrdinalIgnoreCase)
End Function
Function LoadCheckpoint(path As String) As Checkpoint
If File.Exists(path) Then
Dim json As String = File.ReadAllText(path)
Return JsonSerializer.Deserialize(Of Checkpoint)(json) OrElse New Checkpoint()
End If
Return New Checkpoint()
End Function
Sub SaveCheckpoint(path As String, cp As Checkpoint)
File.WriteAllText(path, JsonSerializer.Serialize(cp))
End Sub
' Data classes
Class PipelineConfig
Public Property InputFolder As String = ""
Public Property OutputFolder As String = ""
Public Property ArchiveFolder As String = ""
Public Property ErrorFolder As String = ""
Public Property CheckpointPath As String = ""
Public Property ReportPath As String = ""
Public Property MaxConcurrency As Integer
Public Property MaxRetries As Integer
Public Property JpegQuality As Integer
End Class
Class Checkpoint
Public Property CompletedFiles As HashSet(Of String) = New HashSet(Of String)()
End Class
Class ProcessingResult
Public Property FileName As String = ""
Public Property Status As String = ""
Public Property Error As String = ""
Public Property OutputSize As Long
Public Property StartTime As DateTime
Public Property EndTime As DateTime
End Class
Class PipelineReport
Public Property TotalFiles As Integer
Public Property ProcessedThisRun As Integer
Public Property Succeeded As Integer
Public Property PreValidationFailed As Integer
Public Property ProcessingFailed As Integer
Public Property PostValidationFailed As Integer
Public Property Errors As Integer
Public Property TotalDuration As TimeSpan
Public Property AverageFileTime As TimeSpan
End ClassAusgabe
Pipeline-Bericht mit den Ergebnissen der Stapelverarbeitung.
Diese Pipeline umfasst alle Muster, die wir in diesem Tutorial behandelt haben: parallele Verarbeitung mit kontrollierter Gleichzeitigkeit, Fehlerbehandlung pro Datei mit Skip-on-Failure, Wiederholungslogik für vorübergehende Fehler, Checkpointing für die Wiederaufnahme nach einem Absturz, Validierung vor und nach der Verarbeitung, Speicherverwaltung mit expliziter Entsorgung und umfassende Protokollierung mit einem abschließenden Bericht.
Die Ausgabe dieser Pipeline ist ein Verzeichnis mit komprimierten, PDF/A-3b-konformen Archivdateien, eine Prüfpunktdatei für die Fortsetzungsfähigkeit, ein Fehlerprotokoll für Dateien, die nicht verarbeitet werden konnten, und ein zusammenfassender Bericht mit Verarbeitungsstatistiken. Dies ist das Muster, das Sie für jede ernsthafte Stapelverarbeitung von PDF-Dateien benötigen.
Nächste Schritte
Bei der PDF-Stapelverarbeitung in großem Maßstab geht es nicht nur um den Aufruf einer Rendering-Methode in einer Schleife. Sie erfordert eine durchdachte Architektur in Bezug auf Gleichzeitigkeit, Speicherverwaltung, Fehlerbehandlung und Bereitstellung - und die richtige Bibliothek, damit das alles funktioniert. IronPDF bietet eine thread-sichere Rendering-Engine, eine asynchrone API-Oberfläche, Komprimierungstools und Formatkonvertierungsfunktionen, die die Grundlage für jede .NET-Batch-PDF-Pipeline bilden.
Ganz gleich, ob Sie einen nächtlichen Berichtsgenerator erstellen, der vor Sonnenaufgang Tausende von PDFs produziert, ein älteres Dokumentenarchiv auf PDF/A-Konformität migrieren oder einen Cloud-nativen Verarbeitungsdienst auf Kubernetes einrichten, die Muster in diesem Tutorial bieten Ihnen ein bewährtes Framework, auf dem Sie aufbauen können. Parallele Verarbeitung mit kontrollierter Gleichzeitigkeit hält den Durchsatz hoch. Skip-on-Failure- und Retry-Logik halten die Pipeline am Laufen, wenn einzelne Dateien Probleme verursachen. Checkpointing stellt sicher, dass Sie nie den Fortschritt verlieren. Und mit Cloud-Bereitstellungsmustern können Sie die Rechenleistung an Ihre Arbeitslast anpassen.
Bereit, loszulegen? Laden Sie IronPDF herunter und probieren Sie es mit einer kostenlosen Testversion aus - dieselbe Bibliothek beherrscht alles, vom Rendering einzelner Dateien bis hin zu Batch-Pipelines mit Hunderttausenden von Dateien. Wenn Sie Fragen zur Skalierung, Bereitstellung oder Architektur für Ihren speziellen Anwendungsfall haben, wenden Sie sich an unser technisches Support-Team - wir haben Teams beim Aufbau von Batch-Pipelines in jeder Größenordnung unterstützt und helfen Ihnen gerne dabei, es richtig zu machen.
Häufig gestellte Fragen
Was ist Stapelverarbeitung von PDF-Dateien in C#?
Batch-PDF-Verarbeitung in C# bezieht sich auf die automatisierte Verarbeitung zahlreicher PDF-Dokumente gleichzeitig unter Verwendung der Programmiersprache C#. Diese Methode ist ideal für die Automatisierung von Dokumenten-Workflows in großem Umfang.
Wie kann IronPDF bei der Stapelverarbeitung von PDF-Dateien helfen?
IronPDF bietet robuste Werkzeuge und Bibliotheken, die die Stapelverarbeitung von PDF-Dateien in C# rationalisieren. IronPDF unterstützt die parallele Verarbeitung von Tausenden von PDFs gleichzeitig und ermöglicht so eine effiziente Handhabung.
Was sind die Vorteile der Parallelverarbeitung mit IronPDF?
Die Parallelverarbeitung mit IronPDF ermöglicht eine schnellere und effizientere Stapelverarbeitung von PDF-Dateien. Dieser Ansatz maximiert die Ressourcennutzung und reduziert die Verarbeitungszeit erheblich.
Kann IronPDF auf Cloud-Plattformen für die Stapelverarbeitung eingesetzt werden?
Ja, IronPDF kann auf Cloud-Plattformen wie Azure Functions, AWS Lambda und Kubernetes eingesetzt werden und ermöglicht eine skalierbare und flexible Stapelverarbeitung von PDF-Dateien.
Wie geht IronPDF mit Fehlern bei der Stapelverarbeitung von PDF-Dateien um?
IronPDF enthält Funktionen zur Fehlerbehandlung und Wiederholungslogik, die die Zuverlässigkeit bei der Stapelverarbeitung von PDF-Dateien gewährleisten. Diese Funktionen helfen bei der Verwaltung und Behebung von Fehlern ohne manuelles Eingreifen.
Welche Rolle spielt die Wiederholungslogik bei der PDF-Verarbeitung mit IronPDF?
Die Wiederholungslogik in IronPDF stellt sicher, dass vorübergehende Probleme den Workflow der Stapelverarbeitung nicht unterbrechen. Wenn ein Fehler auftritt, kann IronPDF automatisch versuchen, das fehlerhafte Dokument erneut zu verarbeiten.
Warum ist C# eine geeignete Sprache für die Stapelverarbeitung von PDF-Dateien?
C# ist eine leistungsstarke Programmiersprache mit umfangreichen Bibliotheken und Frameworks, die sich ideal für die Stapelverarbeitung von PDF-Dateien eignet. Sie lässt sich nahtlos in IronPDF integrieren und ermöglicht eine effiziente Automatisierung von Dokumenten.
Wie gewährleistet IronPDF die Sicherheit von PDF-Dokumenten während der Verarbeitung?
IronPDF unterstützt den sicheren Umgang mit PDF-Dokumenten, indem es Verschlüsselungs- und Kennwortschutzfunktionen bereitstellt, die gewährleisten, dass verarbeitete Dokumente vertraulich und sicher bleiben.
Welche Anwendungsfälle gibt es für die Stapelverarbeitung von PDF-Dateien in Unternehmen?
Unternehmen nutzen die Stapelverarbeitung von PDF-Dateien für Aufgaben wie die Massengenerierung von Rechnungen, die Digitalisierung von Dokumenten und die Verteilung von Berichten in großem Umfang. IronPDF erleichtert diese Anwendungsfälle durch die Automatisierung und Rationalisierung von Dokumenten-Workflows.
Kann IronPDF verschiedene PDF-Formate und -Versionen verarbeiten?
Ja, IronPDF ist so konzipiert, dass es verschiedene PDF-Formate und -Versionen verarbeiten kann, wodurch Kompatibilität und Flexibilität bei der Stapelverarbeitung gewährleistet sind.


Scrollst du immer noch?
Sie brauchen schnell einen Beweis? PM > Install-Package IronPdf
Führen Sie eine Probe aus Sehen Sie zu, wie Ihr HTML-Code in eine PDF-Datei umgewandelt wird.










