

C# Read PDF Walkthrough

Today, we'll walk through a simple method for reading PDF content and extracting text in its original format. This can be done for entire documents or specific pages, all within your C# project.



Get started with IronPDF
Start using IronPDF in your project today with a free trial.
How to Read PDF Files in C#
- Download IronPDF C# Library for PDF Reading and Writing
- Install with IronPDF via NuGet to test the Library
- Read PDF files, extract content, and even extract high quality and original images
- Use a C# Form to show you the perfect output of reading the PDF content
- View your PDF output
Read PDF File in C#
Using this C# library, we can read PDF files, extract content, and even extract high-quality and original images. See the examples below for the many ways we can use different functions to achieve our PDF reading needs in a .NET environment.
:path=/static-assets/pdf/content-code-examples/how-to/csharp-read-pdf-read-pdf.csusing IronPdf;
using IronSoftware.Drawing;
using System.Collections.Generic;
// Select the desired PDF File
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract all text from an pdf
string allText = pdf.ExtractAllText();
// Get all Images
IEnumerable<AnyBitmap> AllImages = pdf.ExtractAllImages();
// Else combine above both functionality using PageCount
for (var index = 0; index < pdf.PageCount; index++)
{
string Text = pdf.ExtractTextFromPage(index);
IEnumerable<AnyBitmap> Images = pdf.ExtractImagesFromPage(index);
}Imports IronPdf
Imports IronSoftware.Drawing
Imports System.Collections.Generic
' Select the desired PDF File
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract all text from an pdf
Private allText As String = pdf.ExtractAllText()
' Get all Images
Private AllImages As IEnumerable(Of AnyBitmap) = pdf.ExtractAllImages()
' Else combine above both functionality using PageCount
For index = 0 To pdf.PageCount - 1
Dim Text As String = pdf.ExtractTextFromPage(index)
Dim Images As IEnumerable(Of AnyBitmap) = pdf.ExtractImagesFromPage(index)
Next indexOutput
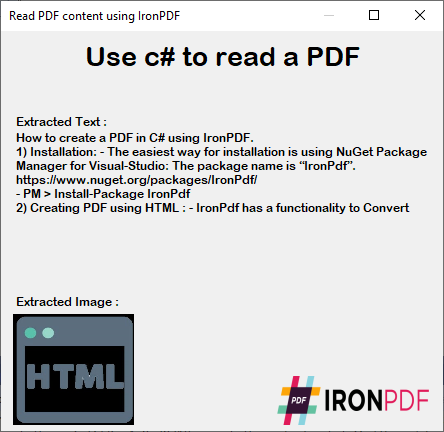
We have used a C# Form to show you the perfect output of reading the PDF content. With this approach, it's all about simplicity and using as little code as possible to achieve your project needs.
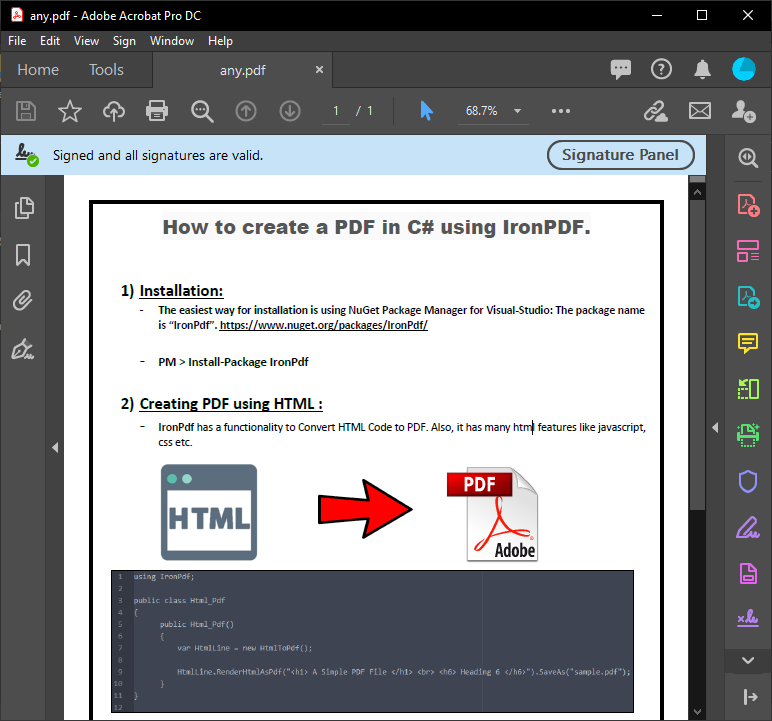
~ PDF ~
~ C# Form ~
Library Quick Access

Library Documentation
Documentation for the IronPDF library is available in the handy API Reference for you to explore and share.
IronPDF API Reference DocumentationFrequently Asked Questions
What is IronPDF?
IronPDF is a C# library that allows developers to read, edit, and create PDF files within their C# projects.
How do I install IronPDF?
You can install IronPDF via NuGet by downloading it from the NuGet website or using the NuGet package manager in your development environment.
How can I extract text from a PDF using IronPDF?
You can extract text from a PDF by loading the document in IronPDF and using the 'ExtractAllText' method to retrieve the content.
Can IronPDF extract images from PDF files?
Yes, IronPDF can extract high-quality and original images from PDF files.
Is there documentation available for IronPDF?
Yes, the IronPDF library has comprehensive documentation available in the API Reference, which can be accessed online.
What are the basic steps to read a PDF file using IronPDF in C#?
To read a PDF file using IronPDF, download and install the library via NuGet, load the PDF document, and use the ExtractAllText method to read the content.
Can I use IronPDF to display PDF content in a C# Form?
Yes, IronPDF can be used in conjunction with a C# Form to display PDF content, ensuring that the output is presented perfectly.
Is IronPDF suitable for .NET projects?
IronPDF is designed for use within .NET projects, providing a seamless integration for PDF reading and manipulation.
Are there example codes available for using IronPDF?
Yes, there are example codes available that demonstrate how to use IronPDF for reading and extracting text from PDF files in a C# environment.
Where can I view the PDF output when using IronPDF?
The PDF output can be viewed directly in your C# application or through the console, depending on how you implement IronPDF in your project.






