

How to Extract Embedded Text and Images from PDFs
Extracting embedded text and images involves retrieving textual content and graphical elements within the document. This process allows users to access and repurpose the content for editing, searching, or converting text to other formats and saving images for reuse or analysis.
To extract text and images from a PDF, use IronPdf. The extracted image can be saved to the disk or converted to another image format and embedded in the newly rendered document.
How to Extract Embedded Text and Images from PDFs
Install with NuGet
Install-Package IronPdf

Extract Text Example
Text extraction can be performed on both newly rendered and existing PDF documents. Use the ExtractAllText method to extract the embedded text from the document. The method will return a string containing all the text in the given PDF. Pages are separated by four consecutive Environment.NewLinesPages. Let's use a sample PDF that I have rendered from the Wikipedia website.
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-text.csusing IronPdf;
using System.IO;
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract text
string text = pdf.ExtractAllText();
// Export the extracted text to a text file
File.WriteAllText("extractedText.txt", text);Imports IronPdf
Imports System.IO
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract text
Private text As String = pdf.ExtractAllText()
' Export the extracted text to a text file
File.WriteAllText("extractedText.txt", text)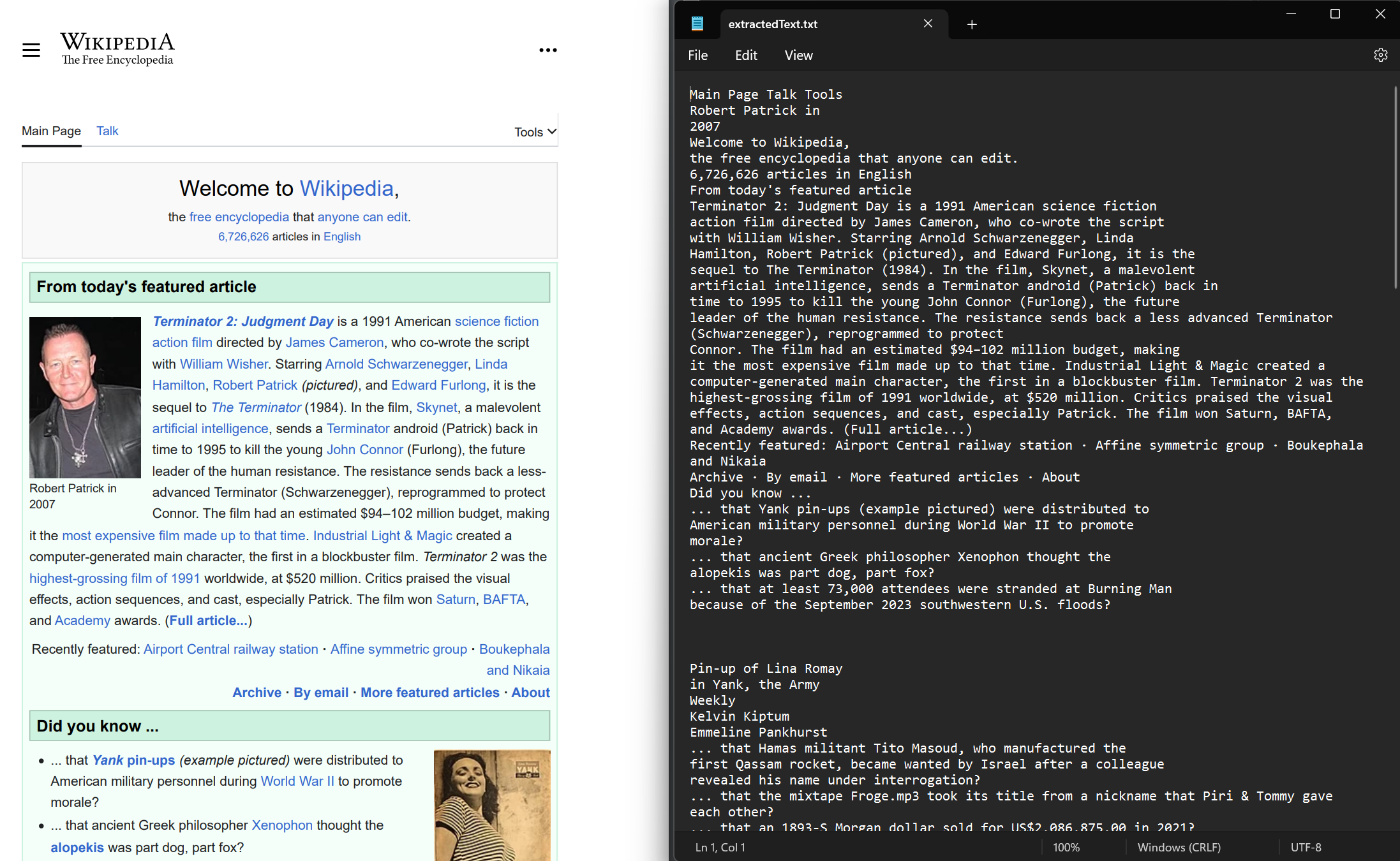
Extract Text by Line and Character
Within each PDF page, it is possible to retrieve the coordinates of text lines and characters. First, select a page from the PDF and access the Lines and Characters property. The coordinates are laid out as Top, Right, Bottom, and Left values, representing the position of the text.
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-text-by-line-character.csusing IronPdf;
using System.IO;
using System.Linq;
// Open PDF from file
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract text by lines
var lines = pdf.Pages[0].Lines;
// Extract text by characters
var characters = pdf.Pages[0].Characters;
File.WriteAllLines("lines.txt", lines.Select(l => $"at Y={l.Bottom:F2}: {l.Contents}"));Imports IronPdf
Imports System.IO
Imports System.Linq
' Open PDF from file
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract text by lines
Private lines = pdf.Pages(0).Lines
' Extract text by characters
Private characters = pdf.Pages(0).Characters
File.WriteAllLines("lines.txt", lines.Select(Function(l) $"at Y={l.Bottom:F2}: {l.Contents}"))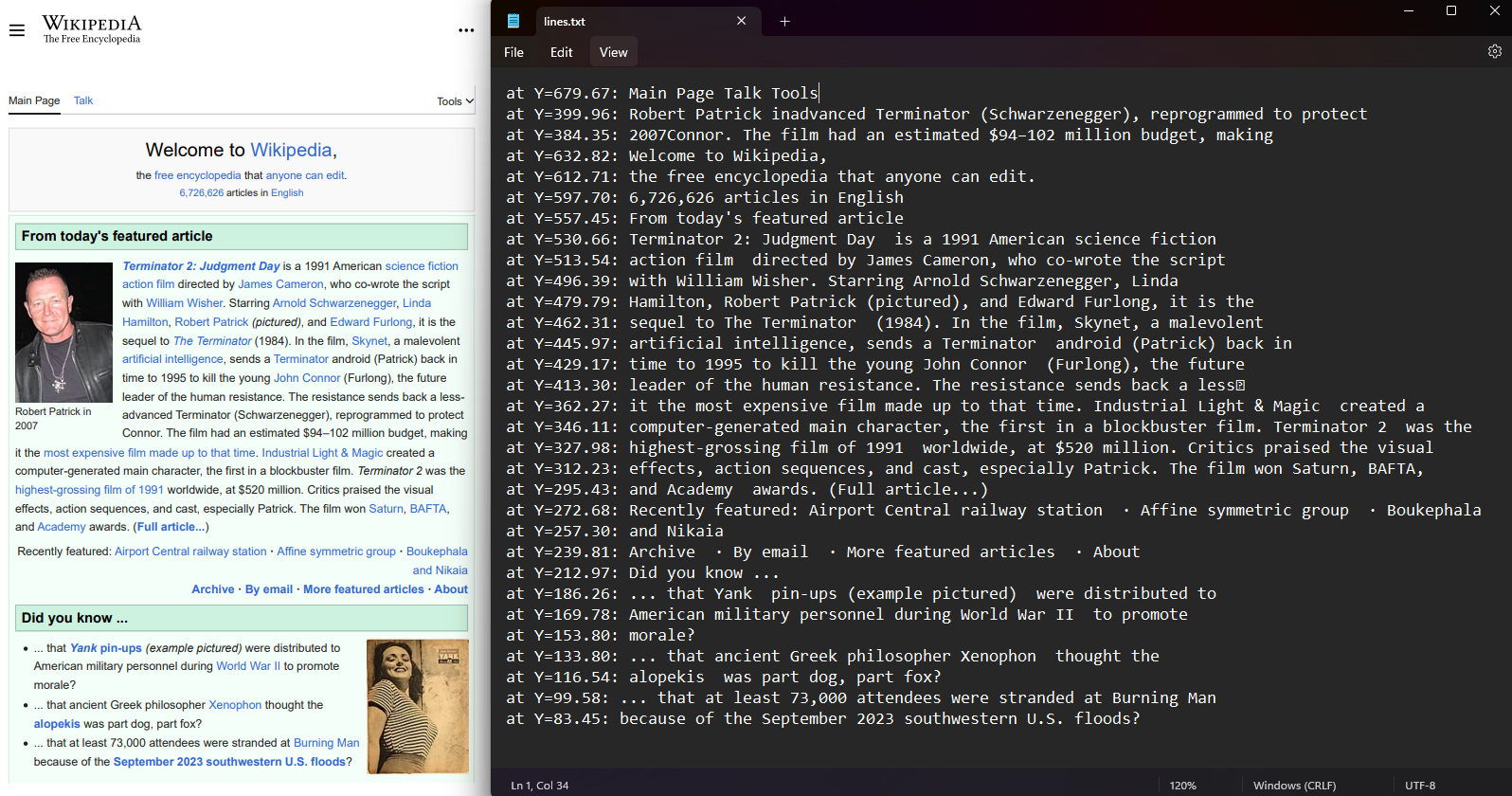
Extract Images Example
Use the ExtractAllImages method to extract all images embedded in the document. The method will return the images as a list of AnyBitmap objects. Using the same document from our previous example, we extracted the images and exported them to the 'images' folder.
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-image.csusing IronPdf;
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract images
var images = pdf.ExtractAllImages();
for(int i = 0; i < images.Count; i++)
{
// Export the extracted images
images[i].SaveAs($"images/image{i}.png");
}Imports IronPdf
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract images
Private images = pdf.ExtractAllImages()
For i As Integer = 0 To images.Count - 1
' Export the extracted images
images(i).SaveAs($"images/image{i}.png")
Next i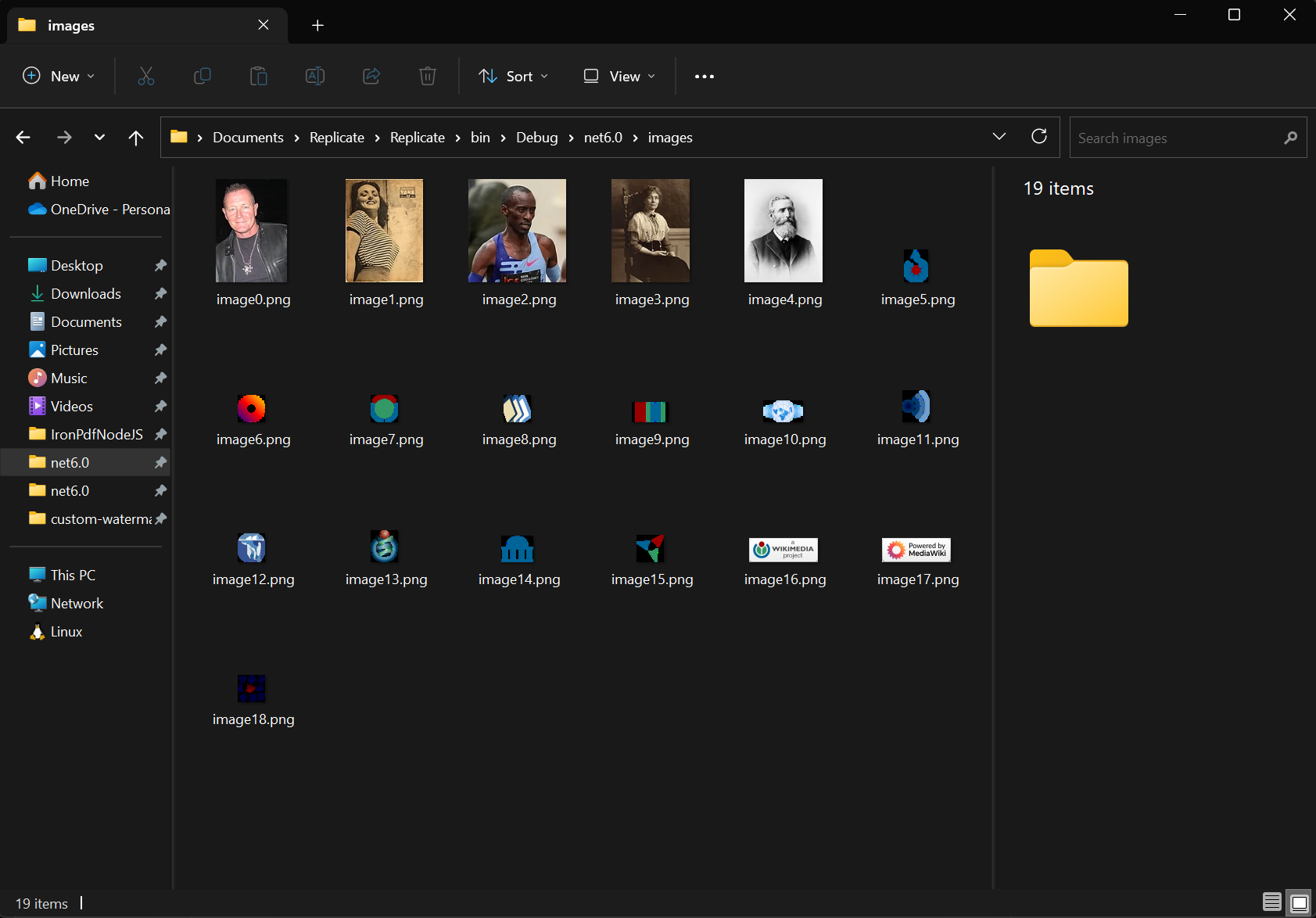
In addition to the ExtractAllImages method shown above, the user can use the ExtractAllBitmaps and ExtractAllRawImages methods to extract image information from the document. While the ExtractAllBitmaps method will return a List of AnyBitmap, like the code example, the ExtractAllRawImages method extracts all images from a PDF document and returns them as raw data in the form of Byte Arrays (byte[]).
Extract Text and Images on Specific Pages
Both text and image extraction can be performed on single or multiple specified pages. Use the ExtractTextFromPage and ExtractTextFromPages methods to extract text from a single page or multiple pages, respectively. For extracting images, use the ExtractImagesFromPage and ExtractImagesFromPages methods.
:path=/static-assets/pdf/content-code-examples/how-to/extract-text-and-images-extract-text-single-multiple.csusing IronPdf;
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract text from page 1
string textFromPage1 = pdf.ExtractTextFromPage(0);
int[] pages = new[] { 0, 2 };
// Extract text from pages 1 & 3
string textFromPage1_3 = pdf.ExtractTextFromPages(pages);Imports IronPdf
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract text from page 1
Private textFromPage1 As String = pdf.ExtractTextFromPage(0)
Private pages() As Integer = { 0, 2 }
' Extract text from pages 1 & 3
Private textFromPage1_3 As String = pdf.ExtractTextFromPages(pages)


