

Procesamiento de PDF por lotes en C#: Automatice los flujos de trabajo de documentos a escala
el procesamiento de PDF por lotes en C# con IronPDF permite a los desarrolladores .NET automatizar flujos de trabajo de documentos a escala, desde la conversión paralela de HTML a PDF y la fusión y división masivas hasta procesos de PDF asíncronos con gestión de errores, lógica de reintento y puntos de comprobación integrados. El motor Chromium seguro para subprocesos de IronPDF y la administración de memoria basada en IDisposable lo hacen especialmente diseñado para la automatización de PDF de alto rendimiento , ya sea que se ejecute localmente, en Azure Functions , AWS Lambda o Kubernetes .
TL;DR: Guía de inicio rápido
Este tutorial cubre la automatización escalable de PDF en C#, desde la conversión paralela y las operaciones masivas hasta la implementación en la nube y los patrones de canalización resistentes.
- A quién va dirigido: Desarrolladores y arquitectos .NET responsables de flujos de trabajo con gran cantidad de documentos: proyectos de migración de documentos, canales de generación de informes diarios, barridos de corrección de cumplimiento o esfuerzos de digitalización de archivos en los que el procesamiento secuencial no es factible.
- Lo que construirás: Conversión paralela de HTML a PDF con
Parallel.ForEach, operaciones de combinación y división por lotes, canalizaciones asincrónicas conSemaphoreSlimpara control de simultaneidad, manejo de errores con lógica de reintento y omisión en caso de falla, patrones de punto de control/reanudación para recuperación de fallas y configuraciones de implementación en la nube para Azure Functions, AWS Lambda y Kubernetes. - Dónde funciona: .NET 6+, .NET Framework 4.6.2+, .NET Standard 2.0. Todo el renderizado utiliza el motor Chromium integrado de IronPDF: no se requieren dependencias de navegadores headless ni servicios externos.
- Cuándo utilizar este enfoque: Cuando necesite procesar más PDF de los que permite la ejecución secuencial: migración de documentos a escala, trabajos por lotes programados con ventanas de tiempo ajustadas o plataformas multiusuario con cargas de documentos variables.
- Por qué es importante desde el punto de vista técnico:
ChromePdfRendererde IronPDF es seguro para subprocesos y sin estado por renderizado, lo que significa que varios subprocesos pueden compartir de forma segura una única instancia de renderizado. Combinado con la biblioteca de tareas paralelas de .NET yIDisposableenPdfDocument, obtiene un comportamiento de memoria predecible y saturación de CPU sin condiciones de carrera ni pérdidas de memoria.
Convierta por lotes un directorio entero de archivos HTML a PDF con sólo unas pocas líneas de código:
-
Instala IronPDF con el Administrador de Paquetes NuGet
PM > Install-Package IronPdf -
Copie y ejecute este fragmento de código.
using IronPdf; using System.IO; using System.Threading.Tasks; var renderer = new ChromePdfRenderer(); var htmlFiles = Directory.GetFiles("input/", "*.html"); Parallel.ForEach(htmlFiles, htmlFile => { var pdf = renderer.RenderHtmlFileAsPdf(htmlFile); pdf.SaveAs($"output/{Path.GetFileNameWithoutExtension(htmlFile)}.pdf"); }); -
Despliegue para probar en su entorno real
Comienza a usar IronPDF en tu proyecto hoy mismo con una prueba gratuita

Una vez que haya adquirido IronPDF o se haya suscrito a una versión de prueba de 30 días, añada su clave de licencia al inicio de su solicitud.
IronPdf.License.LicenseKey = "KEY";IronPdf.License.LicenseKey = "KEY";Imports IronPdf
IronPdf.License.LicenseKey = "KEY"Comience a usar IronPDF en su proyecto hoy con una prueba gratuita.
Tabla de contenido
- Comprensión del problema
- Fundamentos
- Operaciones básicas
- Resiliencia
- Realización
- Despliegue
- Ponerlo todo junto
Cuando tiene que procesar miles de archivos PDF
El procesamiento de PDF por lotes no es un requisito de nicho, sino una parte rutinaria de la gestión de documentos empresariales. Las situaciones que lo exigen se dan en todos los sectores y comparten un rasgo común: hacer las cosas de una en una no es una opción.
Los proyectos de migración de documentos son uno de los desencadenantes más comunes. Cuando una organización pasa de un sistema de gestión documental a otro, es necesario convertir, reformatear o reetiquetar miles (a veces millones) de documentos. Una compañía de seguros que migra de un sistema de reclamaciones heredado puede necesitar convertir 500.000 documentos de reclamaciones basados en TIFF a PDF con capacidad de búsqueda. Un bufete de abogados que se muda a una nueva plataforma de gestión de casos puede necesitar fusionar correspondencia dispersa en archivos de casos unificados. Se trata de trabajos puntuales, pero de gran envergadura y que no perdonan los errores.
Generación de informes diarios es la versión en estado estacionario del mismo problema. Las instituciones financieras que producen informes de cartera al final del día para miles de clientes, las empresas de logística que generan manifiestos de embarque para cada contenedor saliente, los sistemas sanitarios que crean resúmenes diarios de pacientes en cientos de departamentos... todos ellos generan documentos PDF a una escala en la que el procesamiento secuencial sobrepasaría las ventanas de tiempo aceptables. Cuando 10.000 informes deben estar listos a las 6 de la mañana y los datos no son definitivos hasta medianoche, no se dispone de seis horas para traducirlos uno por uno.
La digitalización de archivos se encuentra en la intersección de la migración y el cumplimiento de normativas. Agencias gubernamentales, universidades y empresas con décadas de registros en papel se enfrentan a la obligación de digitalizar y archivar documentos en formatos conformes con los estándares (normalmente PDF/A). Los volúmenes son asombrosos -solo NARA recibe millones de páginas de registros federales para su conservación permanente- y el proceso debe ser lo suficientemente fiable como para no descubrir lagunas años después.
Cumplimiento de normativas suele ser el desencadenante más urgente. Cuando una auditoría revela que su archivo de documentos no cumple una norma de reciente aplicación -por ejemplo, sus facturas almacenadas no cumplen la normativa PDF/A-3 de facturación electrónica, o sus historiales médicos carecen del etiquetado de accesibilidad exigido por la Sección 508-, necesita procesar todo su archivo existente conforme a la nueva norma. La presión es alta, el plazo ajustado y el volumen es el que contenga tu archivo.
En cada uno de estos escenarios, el reto principal es el mismo: ¿cómo procesar un gran número de operaciones PDF de forma fiable, eficiente y sin quedarse sin memoria o sin dejar el trabajo a medias cuando algo va mal?
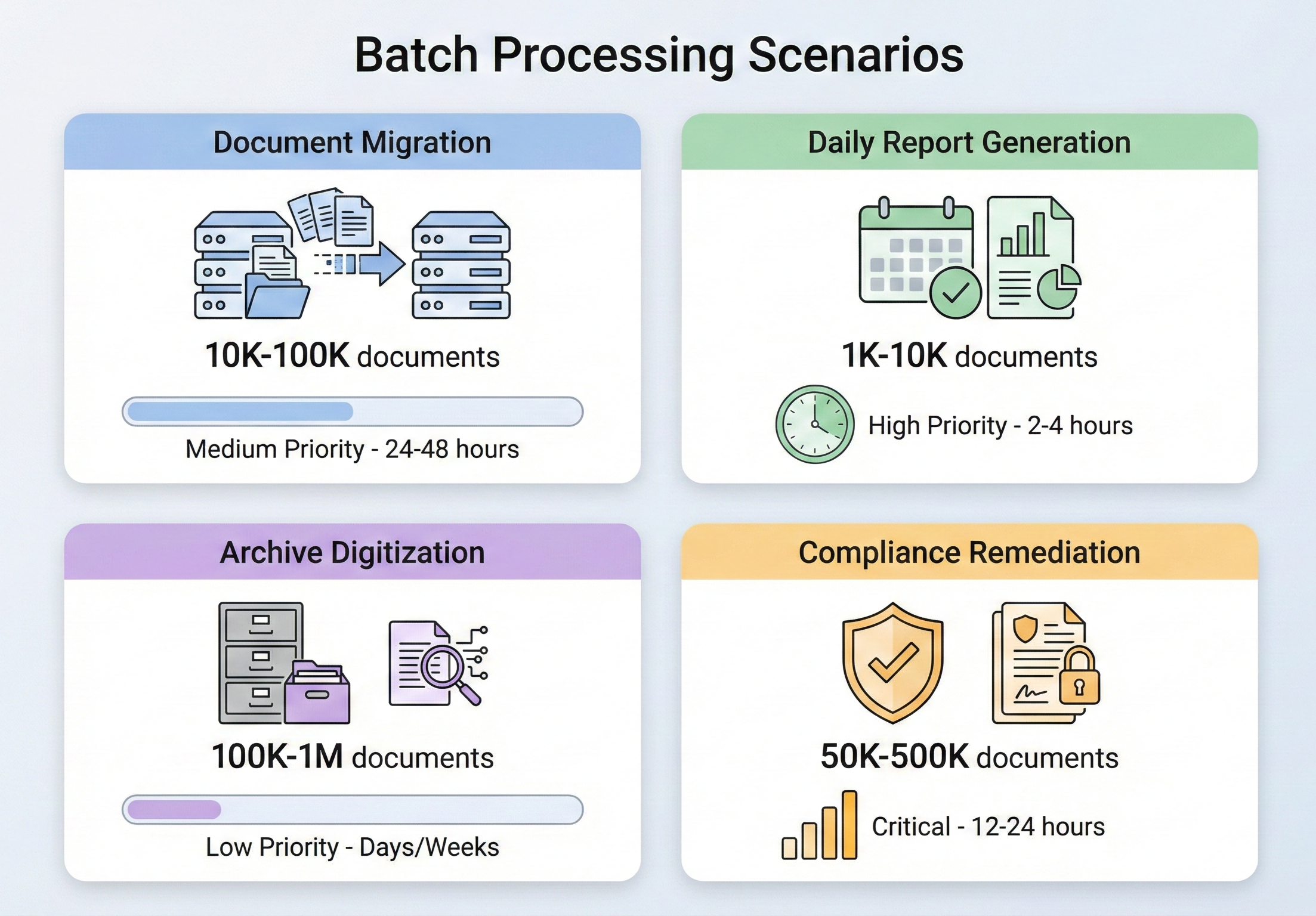
Arquitectura de procesamiento por lotes de IronPDF
Antes de sumergirse en operaciones específicas, es importante entender cómo IronPDF está diseñado para manejar cargas de trabajo concurrentes y qué decisiones arquitectónicas debe tomar al construir una canalización por lotes sobre él.
Instalación de IronPDF
Instale IronPDF a través de NuGet:
Install-Package IronPdfInstall-Package IronPdfO utilizando la CLI de .NET:
dotnet add package IronPdfdotnet add package IronPdfIronPDF es compatible con .NET Framework 4.6.2+, .NET Core, .NET 5 hasta .NET 10, y .NET Standard 2.0. Se ejecuta en Windows, Linux, macOS y contenedores Docker, por lo que es adecuado tanto para trabajos por lotes locales como para la implementación nativa en la nube.
Para el procesamiento por lotes de producción, configure su clave de licencia con License.LicenseKey al iniciar la aplicación antes de que comience cualquier operación de PDF. Esto garantiza que todas las llamadas de renderización en todos los subprocesos tengan acceso al conjunto completo de funciones sin marcas de agua por archivo.
Control de concurrencia y seguridad de subprocesos
El motor de renderizado basado en Chromium de IronPDF es seguro para hilos. Puede crear múltiples instancias de ChromePdfRenderer en varios subprocesos o compartir una sola instancia: IronPDF maneja la sincronización interna. La recomendación oficial para el procesamiento por lotes es utilizar el Parallel.ForEach integrado de .NET, que distribuye el trabajo entre todos los núcleos de CPU disponibles de forma automática.
Dicho esto, "seguro para subprocesos" no significa "utilizar subprocesos ilimitados". Cada operación simultánea de renderizado de PDF consume memoria (el motor de Chromium necesita espacio de trabajo para el análisis del DOM, el diseño de CSS y la rasterización de imágenes), y ejecutar demasiadas operaciones paralelas en un sistema con memoria limitada reducirá el rendimiento o provocará un error. El nivel adecuado de concurrencia depende del hardware: un servidor de 16 núcleos con 64 GB de RAM puede manejar cómodamente entre 8 y 12 renderizaciones simultáneas; Una máquina virtual de 4 núcleos con 8 GB podría estar limitada a 2 o 4. Controle esto con ParallelOptions.MaxDegreeOfParallelism: configúrelo en aproximadamente la mitad de los núcleos de CPU disponibles como punto de partida y luego ajústelo según la presión de memoria observada.
Gestión de memoria a escala
La gestión de la memoria es la preocupación más importante en el procesamiento de PDF por lotes. Cada objeto PdfDocument contiene el contenido binario completo de un PDF en la memoria, y si no se eliminan estos objetos, la memoria crecerá linealmente con la cantidad de archivos procesados.
La regla crítica: utilice siempre declaraciones using o llame explícitamente a Dispose() en objetos PdfDocument. PdfDocument de IronPDF implementa IDisposable, y no poder eliminarlo es la causa más común de problemas de memoria en escenarios de procesamiento por lotes. Cada iteración de su bucle de procesamiento debe crear un PdfDocument, hacer su trabajo y desecharlo; nunca acumule objetos PdfDocument en una lista o colección a menos que tenga una razón específica y suficiente memoria para manejarlo.
Además de la eliminación, considere estas estrategias de gestión de memoria para grandes lotes:
Procesa en trozos en lugar de cargar todo a la vez. Si necesita procesar 50.000 archivos, no los enumere todos en una lista y luego itere: procéselos en lotes de 100 o 500, permitiendo que el recolector de basura recupere memoria entre trozos.
Forzar la recolección de basura entre chunks para lotes extremadamente grandes. Si bien generalmente debe dejar que el GC se administre a sí mismo, el procesamiento por lotes es uno de los raros escenarios en los que llamar a GC.Collect() entre los límites de los fragmentos puede evitar que se acumule presión en la memoria.
Supervise el consumo de memoria utilizando GC.GetTotalMemory() o métricas a nivel de proceso. Si el uso de memoria supera un umbral (por ejemplo, el 80% de la RAM disponible), detenga el procesamiento para permitir que la GC se ponga al día.
Informes de progreso y registro
Cuando un trabajo por lotes tarda horas en completarse, la visibilidad de su progreso no es opcional, sino esencial. Como mínimo, debe registrar el inicio y la finalización de cada archivo, realizar un seguimiento del recuento de éxitos y fracasos y proporcionar una estimación del tiempo restante. Utilice Interlocked.Increment para contadores seguros para subprocesos cuando ejecute operaciones paralelas y registre a intervalos regulares (cada 50 o 100 archivos) en lugar de en cada archivo individual para evitar inundar su salida. Realice un seguimiento del tiempo transcurrido con System.Diagnostics.Stopwatch y calcule una tasa de archivos por segundo para obtener un tiempo estimado de llegada (ETA) significativo.
Para los trabajos por lotes de producción, considere la posibilidad de escribir el progreso en un almacén persistente (base de datos, archivo o cola de mensajes) para que los paneles de control puedan mostrar el estado en tiempo real sin conectarse directamente al proceso por lotes.
Operaciones por lotes comunes
Una vez establecida la base arquitectónica, repasemos las operaciones por lotes más comunes y sus implementaciones en IronPDF.
Conversión de HTML a PDF por lotes
La conversión de HTML a PDF es la operación por lotes más común. Ya se trate de generar facturas a partir de plantillas, convertir una biblioteca de documentación HTML a PDF o generar informes dinámicos desde una aplicación web, el patrón es el mismo: iterar sobre las entradas, generar cada una de ellas y guardar el resultado.
Entrada (5 archivos HTML)
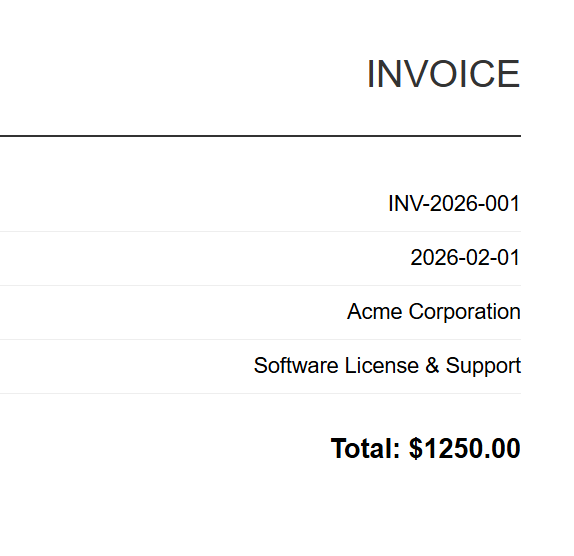
INV-2026-001
INV-2026-002
INV-2026-003
INV-2026-004
INV-2026-005
La implementación utiliza ChromePdfRenderer con Parallel.ForEach para procesar todos los archivos HTML simultáneamente, controlando el paralelismo a través de MaxDegreeOfParallelism para equilibrar el rendimiento frente al consumo de memoria. Cada archivo se procesa con RenderHtmlFileAsPdf y se guarda en el directorio de salida, con seguimiento del progreso mediante contadores Interlocked seguros para subprocesos.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-html-to-pdf.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
using System.Threading;
// Configure paths
string inputFolder = "input/";
string outputFolder = "output/";
Directory.CreateDirectory(outputFolder);
string[] htmlFiles = Directory.GetFiles(inputFolder, "*.html");
Console.WriteLine($"Found {htmlFiles.Length} HTML files to convert");
// Create renderer instance (thread-safe, can be shared)
var renderer = new ChromePdfRenderer();
// Track progress
int processed = 0;
int failed = 0;
// Process in parallel with controlled concurrency
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(htmlFiles, options, htmlFile =>
{
try
{
string fileName = Path.GetFileNameWithoutExtension(htmlFile);
string outputPath = Path.Combine(outputFolder, $"{fileName}.pdf");
using var pdf = renderer.RenderHtmlFileAsPdf(htmlFile);
pdf.SaveAs(outputPath);
Interlocked.Increment(ref processed);
Console.WriteLine($"[OK] {fileName}.pdf");
}
catch (Exception ex)
{
Interlocked.Increment(ref failed);
Console.WriteLine($"[ERROR] {Path.GetFileName(htmlFile)}: {ex.Message}");
}
});
Console.WriteLine($"\nComplete: {processed} succeeded, {failed} failed");Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading.Tasks
Imports System.Threading
' Configure paths
Dim inputFolder As String = "input/"
Dim outputFolder As String = "output/"
Directory.CreateDirectory(outputFolder)
Dim htmlFiles As String() = Directory.GetFiles(inputFolder, "*.html")
Console.WriteLine($"Found {htmlFiles.Length} HTML files to convert")
' Create renderer instance (thread-safe, can be shared)
Dim renderer As New ChromePdfRenderer()
' Track progress
Dim processed As Integer = 0
Dim failed As Integer = 0
' Process in parallel with controlled concurrency
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(htmlFiles, options, Sub(htmlFile)
Try
Dim fileName As String = Path.GetFileNameWithoutExtension(htmlFile)
Dim outputPath As String = Path.Combine(outputFolder, $"{fileName}.pdf")
Using pdf = renderer.RenderHtmlFileAsPdf(htmlFile)
pdf.SaveAs(outputPath)
End Using
Interlocked.Increment(processed)
Console.WriteLine($"[OK] {fileName}.pdf")
Catch ex As Exception
Interlocked.Increment(failed)
Console.WriteLine($"[ERROR] {Path.GetFileName(htmlFile)}: {ex.Message}")
End Try
End Sub)
Console.WriteLine($"\nComplete: {processed} succeeded, {failed} failed")Resultado
Cada factura HTML se convierte en su correspondiente PDF. Arriba se muestra INV-2026-001.pdf, uno de los 5 resultados por lotes.
En el caso de la generación basada en plantillas (por ejemplo, facturas, informes), lo normal es combinar los datos en una plantilla HTML antes de la renderización. El enfoque es sencillo: cargue su plantilla HTML una vez, use string.Replace para inyectar datos por registro (nombre del cliente, totales, fechas) y pase el HTML generado a RenderHtmlAsPdf dentro de su bucle paralelo. IronPDF también proporciona RenderHtmlAsPdfAsync para escenarios donde desee usar async/await en lugar de Parallel.ForEach. Abordaremos los patrones asíncronos en detalle en una sección posterior.
Fusión de PDF por lotes
La fusión de grupos de PDF en documentos combinados es común en los flujos de trabajo jurídicos (fusión de documentos de expedientes), financieros (combinación de extractos mensuales en informes trimestrales) y editoriales.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-merge.csusing IronPdf;
using System;
using System.IO;
using System.Linq;
using System.Collections.Generic;
string inputFolder = "documents/";
string outputFolder = "merged/";
Directory.CreateDirectory(outputFolder);
// Group PDFs by prefix (e.g., "invoice-2026-01-*.pdf" -> one merged file)
var pdfFiles = Directory.GetFiles(inputFolder, "*.pdf");
var groups = pdfFiles
.GroupBy(f => Path.GetFileName(f).Split('-').Take(3).Aggregate((a, b) => $"{a}-{b}"))
.Where(g => g.Count() > 1);
Console.WriteLine($"Found {groups.Count()} groups to merge");
foreach (var group in groups)
{
string groupName = group.Key;
var filesToMerge = group.OrderBy(f => f).ToList();
Console.WriteLine($"Merging {filesToMerge.Count} files into {groupName}.pdf");
try
{
// Load all PDFs for this group
var pdfDocs = new List<PdfDocument>();
foreach (string filePath in filesToMerge)
{
pdfDocs.Add(PdfDocument.FromFile(filePath));
}
// Merge all documents
using var merged = PdfDocument.Merge(pdfDocs);
merged.SaveAs(Path.Combine(outputFolder, $"{groupName}-merged.pdf"));
// Dispose source documents
foreach (var doc in pdfDocs)
{
doc.Dispose();
}
Console.WriteLine($" [OK] Created {groupName}-merged.pdf ({merged.PageCount} pages)");
}
catch (Exception ex)
{
Console.WriteLine($" [ERROR] {groupName}: {ex.Message}");
}
}
Console.WriteLine("\nMerge complete");Imports IronPdf
Imports System
Imports System.IO
Imports System.Linq
Imports System.Collections.Generic
Module Program
Sub Main()
Dim inputFolder As String = "documents/"
Dim outputFolder As String = "merged/"
Directory.CreateDirectory(outputFolder)
' Group PDFs by prefix (e.g., "invoice-2026-01-*.pdf" -> one merged file)
Dim pdfFiles = Directory.GetFiles(inputFolder, "*.pdf")
Dim groups = pdfFiles _
.GroupBy(Function(f) Path.GetFileName(f).Split("-"c).Take(3).Aggregate(Function(a, b) $"{a}-{b}")) _
.Where(Function(g) g.Count() > 1)
Console.WriteLine($"Found {groups.Count()} groups to merge")
For Each group In groups
Dim groupName As String = group.Key
Dim filesToMerge = group.OrderBy(Function(f) f).ToList()
Console.WriteLine($"Merging {filesToMerge.Count} files into {groupName}.pdf")
Try
' Load all PDFs for this group
Dim pdfDocs As New List(Of PdfDocument)()
For Each filePath As String In filesToMerge
pdfDocs.Add(PdfDocument.FromFile(filePath))
Next
' Merge all documents
Using merged = PdfDocument.Merge(pdfDocs)
merged.SaveAs(Path.Combine(outputFolder, $"{groupName}-merged.pdf"))
End Using
' Dispose source documents
For Each doc In pdfDocs
doc.Dispose()
Next
Console.WriteLine($" [OK] Created {groupName}-merged.pdf ({merged.PageCount} pages)")
Catch ex As Exception
Console.WriteLine($" [ERROR] {groupName}: {ex.Message}")
End Try
Next
Console.WriteLine(vbCrLf & "Merge complete")
End Sub
End ModulePara fusionar grandes cantidades de archivos, tenga en cuenta la memoria: el método PdfDocument.Merge carga todos los documentos fuente en la memoria simultáneamente. Si va a fusionar cientos de PDF de gran tamaño, considere la posibilidad de hacerlo por etapas: combine grupos de 10 a 20 archivos en documentos intermedios y, a continuación, fusione los intermedios.
Dividir PDF por lotes
Dividir PDF de varias páginas en páginas individuales (o intervalos de páginas) es la operación inversa a la fusión. Común en el procesamiento de la sala de correo, donde un lote escaneado de documentos debe separarse en registros individuales, y en flujos de trabajo de impresión donde los documentos compuestos deben separarse.
Entrada
El código a continuación demuestra cómo extraer páginas individuales usando CopyPage en un bucle paralelo, creando archivos PDF separados para cada página. Una función auxiliar alternativa SplitByRange muestra cómo extraer rangos de páginas en lugar de páginas individuales, lo que resulta útil para dividir documentos grandes en segmentos más pequeños.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-split.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
string inputFolder = "multipage/";
string outputFolder = "split/";
Directory.CreateDirectory(outputFolder);
string[] pdfFiles = Directory.GetFiles(inputFolder, "*.pdf");
Console.WriteLine($"Found {pdfFiles.Length} PDFs to split");
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(pdfFiles, options, pdfFile =>
{
string baseName = Path.GetFileNameWithoutExtension(pdfFile);
try
{
using var pdf = PdfDocument.FromFile(pdfFile);
int pageCount = pdf.PageCount;
Console.WriteLine($"Splitting {baseName}.pdf ({pageCount} pages)");
// Extract each page as a separate PDF
for (int i = 0; i < pageCount; i++)
{
using var singlePage = pdf.CopyPage(i);
string outputPath = Path.Combine(outputFolder, $"{baseName}-page-{i + 1:D3}.pdf");
singlePage.SaveAs(outputPath);
}
Console.WriteLine($" [OK] Created {pageCount} files from {baseName}.pdf");
}
catch (Exception ex)
{
Console.WriteLine($" [ERROR] {baseName}: {ex.Message}");
}
});
// Alternative: Extract page ranges instead of individual pages
void SplitByRange(string inputFile, string outputFolder, int pagesPerChunk)
{
using var pdf = PdfDocument.FromFile(inputFile);
string baseName = Path.GetFileNameWithoutExtension(inputFile);
int totalPages = pdf.PageCount;
int chunkNumber = 1;
for (int startPage = 0; startPage < totalPages; startPage += pagesPerChunk)
{
int endPage = Math.Min(startPage + pagesPerChunk - 1, totalPages - 1);
using var chunk = pdf.CopyPages(startPage, endPage);
chunk.SaveAs(Path.Combine(outputFolder, $"{baseName}-chunk-{chunkNumber:D3}.pdf"));
chunkNumber++;
}
}
Console.WriteLine("\nSplit complete");Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading.Tasks
Module Program
Sub Main()
Dim inputFolder As String = "multipage/"
Dim outputFolder As String = "split/"
Directory.CreateDirectory(outputFolder)
Dim pdfFiles As String() = Directory.GetFiles(inputFolder, "*.pdf")
Console.WriteLine($"Found {pdfFiles.Length} PDFs to split")
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(pdfFiles, options, Sub(pdfFile)
Dim baseName As String = Path.GetFileNameWithoutExtension(pdfFile)
Try
Using pdf = PdfDocument.FromFile(pdfFile)
Dim pageCount As Integer = pdf.PageCount
Console.WriteLine($"Splitting {baseName}.pdf ({pageCount} pages)")
' Extract each page as a separate PDF
For i As Integer = 0 To pageCount - 1
Using singlePage = pdf.CopyPage(i)
Dim outputPath As String = Path.Combine(outputFolder, $"{baseName}-page-{i + 1:D3}.pdf")
singlePage.SaveAs(outputPath)
End Using
Next
Console.WriteLine($" [OK] Created {pageCount} files from {baseName}.pdf")
End Using
Catch ex As Exception
Console.WriteLine($" [ERROR] {baseName}: {ex.Message}")
End Try
End Sub)
' Alternative: Extract page ranges instead of individual pages
Sub SplitByRange(inputFile As String, outputFolder As String, pagesPerChunk As Integer)
Using pdf = PdfDocument.FromFile(inputFile)
Dim baseName As String = Path.GetFileNameWithoutExtension(inputFile)
Dim totalPages As Integer = pdf.PageCount
Dim chunkNumber As Integer = 1
For startPage As Integer = 0 To totalPages - 1 Step pagesPerChunk
Dim endPage As Integer = Math.Min(startPage + pagesPerChunk - 1, totalPages - 1)
Using chunk = pdf.CopyPages(startPage, endPage)
chunk.SaveAs(Path.Combine(outputFolder, $"{baseName}-chunk-{chunkNumber:D3}.pdf"))
chunkNumber += 1
End Using
Next
End Using
End Sub
Console.WriteLine(vbCrLf & "Split complete")
End Sub
End ModuleResultado
Página 2 extraída como PDF independiente (annual-report-page-2.pdf)
Los métodos CopyPage y CopyPages de IronPDF crean nuevos objetos PdfDocument que contienen las páginas especificadas. Recuerde eliminar tanto el documento fuente como cada documento de página extraído después de guardarlo.
Compresión por lotes
Cuando los costes de almacenamiento son importantes o cuando es necesario transmitir archivos PDF a través de conexiones con limitaciones de ancho de banda, la compresión por lotes puede reducir drásticamente la huella de archivo. IronPDF ofrece dos enfoques de compresión: CompressImages para reducir la calidad/tamaño de la imagen, y CompressStructTree para eliminar metadatos estructurales. La nueva API CompressAndSaveAs (introducida en la versión 2025.12) proporciona una compresión superior al combinar múltiples técnicas de optimización.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-compression.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
using System.Threading;
string inputFolder = "originals/";
string outputFolder = "compressed/";
Directory.CreateDirectory(outputFolder);
string[] pdfFiles = Directory.GetFiles(inputFolder, "*.pdf");
Console.WriteLine($"Found {pdfFiles.Length} PDFs to compress");
long totalOriginalSize = 0;
long totalCompressedSize = 0;
int processed = 0;
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(pdfFiles, options, pdfFile =>
{
string fileName = Path.GetFileName(pdfFile);
string outputPath = Path.Combine(outputFolder, fileName);
try
{
long originalSize = new FileInfo(pdfFile).Length;
Interlocked.Add(ref totalOriginalSize, originalSize);
using var pdf = PdfDocument.FromFile(pdfFile);
// Apply compression with JPEG quality setting (0-100, lower = more compression)
pdf.CompressAndSaveAs(outputPath, 60);
long compressedSize = new FileInfo(outputPath).Length;
Interlocked.Add(ref totalCompressedSize, compressedSize);
Interlocked.Increment(ref processed);
double reduction = (1 - (double)compressedSize / originalSize) * 100;
Console.WriteLine($"[OK] {fileName}: {originalSize / 1024}KB → {compressedSize / 1024}KB ({reduction:F1}% reduction)");
}
catch (Exception ex)
{
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
});
double totalReduction = (1 - (double)totalCompressedSize / totalOriginalSize) * 100;
Console.WriteLine($"\nCompression complete:");
Console.WriteLine($" Files processed: {processed}");
Console.WriteLine($" Total original: {totalOriginalSize / 1024 / 1024}MB");
Console.WriteLine($" Total compressed: {totalCompressedSize / 1024 / 1024}MB");
Console.WriteLine($" Overall reduction: {totalReduction:F1}%");Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading.Tasks
Imports System.Threading
Module Program
Sub Main()
Dim inputFolder As String = "originals/"
Dim outputFolder As String = "compressed/"
Directory.CreateDirectory(outputFolder)
Dim pdfFiles As String() = Directory.GetFiles(inputFolder, "*.pdf")
Console.WriteLine($"Found {pdfFiles.Length} PDFs to compress")
Dim totalOriginalSize As Long = 0
Dim totalCompressedSize As Long = 0
Dim processed As Integer = 0
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(pdfFiles, options, Sub(pdfFile)
Dim fileName As String = Path.GetFileName(pdfFile)
Dim outputPath As String = Path.Combine(outputFolder, fileName)
Try
Dim originalSize As Long = New FileInfo(pdfFile).Length
Interlocked.Add(totalOriginalSize, originalSize)
Using pdf = PdfDocument.FromFile(pdfFile)
' Apply compression with JPEG quality setting (0-100, lower = more compression)
pdf.CompressAndSaveAs(outputPath, 60)
End Using
Dim compressedSize As Long = New FileInfo(outputPath).Length
Interlocked.Add(totalCompressedSize, compressedSize)
Interlocked.Increment(processed)
Dim reduction As Double = (1 - CDbl(compressedSize) / originalSize) * 100
Console.WriteLine($"[OK] {fileName}: {originalSize \ 1024}KB → {compressedSize \ 1024}KB ({reduction:F1}% reduction)")
Catch ex As Exception
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End Sub)
Dim totalReduction As Double = (1 - CDbl(totalCompressedSize) / totalOriginalSize) * 100
Console.WriteLine(vbCrLf & "Compression complete:")
Console.WriteLine($" Files processed: {processed}")
Console.WriteLine($" Total original: {totalOriginalSize \ 1024 \ 1024}MB")
Console.WriteLine($" Total compressed: {totalCompressedSize \ 1024 \ 1024}MB")
Console.WriteLine($" Overall reduction: {totalReduction:F1}%")
End Sub
End ModuleAlgunas cosas a tener en cuenta sobre la compresión: Los ajustes de calidad JPEG por debajo de 60 producirán artefactos visibles en la mayoría de las imágenes. La opción ShrinkImage puede causar distorsión en algunas configuraciones: pruebe con muestras representativas antes de ejecutar un lote completo. Además, eliminar el árbol de estructura (CompressStructTree) afectará la selección de texto y la búsqueda en los PDF comprimidos, así que úselo solo cuando esas capacidades no sean necesarias.
Conversión de formatos por lotes (PDF/A, PDF/UA)
Convertir un archivo existente a un formato que cumpla los estándares - PDF/A para archivado a largo plazo o PDF/UA para accesibilidad - es una de las operaciones por lotes de mayor valor. IronPDF es compatible con todas las versiones de PDF/A (incluida PDF/A-4, añadida en la versión 2025.11) y PDF/UA (incluida PDF/UA-2, añadida en la versión 2025.12).
Entrada
El ejemplo carga cada PDF con PdfDocument.FromFile y luego lo convierte a PDF/A-3b usando SaveAsPdfA con el parámetro PdfAVersions.PdfA3b. Una función alternativa ConvertToPdfUA demuestra la conversión de cumplimiento de accesibilidad usando SaveAsPdfUA, aunque PDF/UA requiere documentos fuente con etiquetado estructural adecuado.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-format-conversion.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
using System.Threading;
string inputFolder = "originals/";
string outputFolder = "pdfa-archive/";
Directory.CreateDirectory(outputFolder);
string[] pdfFiles = Directory.GetFiles(inputFolder, "*.pdf");
Console.WriteLine($"Found {pdfFiles.Length} PDFs to convert to PDF/A-3b");
int converted = 0;
int failed = 0;
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(pdfFiles, options, pdfFile =>
{
string fileName = Path.GetFileName(pdfFile);
string outputPath = Path.Combine(outputFolder, fileName);
try
{
using var pdf = PdfDocument.FromFile(pdfFile);
// Convert to PDF/A-3b for long-term archival
pdf.SaveAsPdfA(outputPath, PdfAVersions.PdfA3b);
Interlocked.Increment(ref converted);
Console.WriteLine($"[OK] {fileName} → PDF/A-3b");
}
catch (Exception ex)
{
Interlocked.Increment(ref failed);
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
});
Console.WriteLine($"\nConversion complete: {converted} succeeded, {failed} failed");
// Alternative: Convert to PDF/UA for accessibility compliance
void ConvertToPdfUA(string inputFolder, string outputFolder)
{
Directory.CreateDirectory(outputFolder);
string[] files = Directory.GetFiles(inputFolder, "*.pdf");
Parallel.ForEach(files, pdfFile =>
{
string fileName = Path.GetFileName(pdfFile);
try
{
using var pdf = PdfDocument.FromFile(pdfFile);
// PDF/UA requires proper tagging - ensure source is well-structured
pdf.SaveAsPdfUA(Path.Combine(outputFolder, fileName));
Console.WriteLine($"[OK] {fileName} → PDF/UA");
}
catch (Exception ex)
{
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
});
}Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading.Tasks
Imports System.Threading
Module Program
Sub Main()
Dim inputFolder As String = "originals/"
Dim outputFolder As String = "pdfa-archive/"
Directory.CreateDirectory(outputFolder)
Dim pdfFiles As String() = Directory.GetFiles(inputFolder, "*.pdf")
Console.WriteLine($"Found {pdfFiles.Length} PDFs to convert to PDF/A-3b")
Dim converted As Integer = 0
Dim failed As Integer = 0
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(pdfFiles, options, Sub(pdfFile)
Dim fileName As String = Path.GetFileName(pdfFile)
Dim outputPath As String = Path.Combine(outputFolder, fileName)
Try
Using pdf = PdfDocument.FromFile(pdfFile)
' Convert to PDF/A-3b for long-term archival
pdf.SaveAsPdfA(outputPath, PdfAVersions.PdfA3b)
Interlocked.Increment(converted)
Console.WriteLine($"[OK] {fileName} → PDF/A-3b")
End Using
Catch ex As Exception
Interlocked.Increment(failed)
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End Sub)
Console.WriteLine($"{vbCrLf}Conversion complete: {converted} succeeded, {failed} failed")
End Sub
' Alternative: Convert to PDF/UA for accessibility compliance
Sub ConvertToPdfUA(inputFolder As String, outputFolder As String)
Directory.CreateDirectory(outputFolder)
Dim files As String() = Directory.GetFiles(inputFolder, "*.pdf")
Parallel.ForEach(files, Sub(pdfFile)
Dim fileName As String = Path.GetFileName(pdfFile)
Try
Using pdf = PdfDocument.FromFile(pdfFile)
' PDF/UA requires proper tagging - ensure source is well-structured
pdf.SaveAsPdfUA(Path.Combine(outputFolder, fileName))
Console.WriteLine($"[OK] {fileName} → PDF/UA")
End Using
Catch ex As Exception
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End Sub)
End Sub
End ModuleResultado
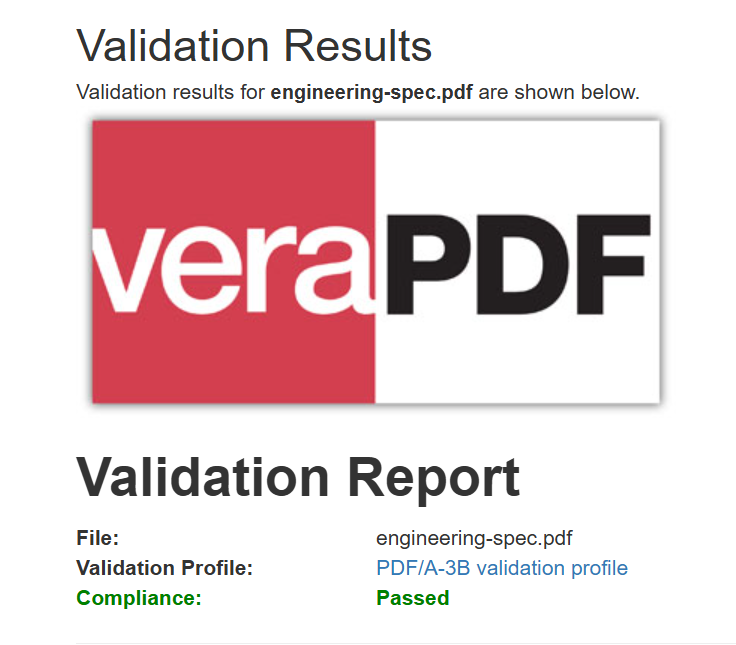
El PDF resultante es idéntico en apariencia byte a byte, pero ahora lleva metadatos de conformidad PDF/A-3b para sistemas de archivo.
La conversión de formatos es especialmente importante para los proyectos de corrección de la conformidad, en los que una organización descubre que su archivo existente no cumple una norma reglamentaria. El patrón por lotes es sencillo, pero el paso de validación es fundamental: comprueba siempre que cada archivo convertido supera realmente las comprobaciones de conformidad antes de considerarlo completo. La validación se trata en detalle en la sección de resiliencia.
Construcción de procesos por lotes resistentes
Un proceso por lotes que funciona perfectamente con 100 archivos y se bloquea con el archivo 4.327 de 50.000 no es útil. La resiliencia, es decir, la capacidad de gestionar errores con elegancia, reintentar fallos transitorios y reanudar la actividad después de un fallo, es lo que diferencia un canal de producción de un prototipo.
Manejo de errores y omisión en caso de fallo
El patrón de resiliencia más básico es el skip-on-failure: si falla el procesamiento de un único archivo, se registra el error y se continúa con el siguiente archivo en lugar de abortar todo el lote. Esto suena obvio, pero es sorprendentemente fácil pasarlo por alto cuando se usa Parallel.ForEach: una excepción no controlada en cualquier tarea paralela se propagará como un AggregateException y terminará el bucle.
El siguiente ejemplo demuestra la lógica de reintento y omisión en caso de error en conjunto: envolviendo cada archivo en un try-catch para un manejo elegante de errores, con un bucle de reintento interno que utiliza un retroceso exponencial para excepciones transitorias como IOException y OutOfMemoryException:
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-error-handling-retry.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
using System.Threading;
using System.Collections.Concurrent;
string inputFolder = "input/";
string outputFolder = "output/";
string errorLogPath = "error-log.txt";
Directory.CreateDirectory(outputFolder);
string[] htmlFiles = Directory.GetFiles(inputFolder, "*.html");
var renderer = new ChromePdfRenderer();
var errorLog = new ConcurrentBag<string>();
int processed = 0;
int failed = 0;
int retried = 0;
const int maxRetries = 3;
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(htmlFiles, options, htmlFile =>
{
string fileName = Path.GetFileNameWithoutExtension(htmlFile);
string outputPath = Path.Combine(outputFolder, $"{fileName}.pdf");
int attempt = 0;
bool success = false;
while (attempt < maxRetries && !success)
{
attempt++;
try
{
using var pdf = renderer.RenderHtmlFileAsPdf(htmlFile);
pdf.SaveAs(outputPath);
success = true;
Interlocked.Increment(ref processed);
if (attempt > 1)
{
Interlocked.Increment(ref retried);
Console.WriteLine($"[OK] {fileName}.pdf (succeeded on attempt {attempt})");
}
else
{
Console.WriteLine($"[OK] {fileName}.pdf");
}
}
catch (Exception ex) when (IsTransientException(ex) && attempt < maxRetries)
{
// Transient error - wait and retry with exponential backoff
int delayMs = (int)Math.Pow(2, attempt) * 500;
Console.WriteLine($"[RETRY] {fileName}: {ex.Message} (attempt {attempt}, waiting {delayMs}ms)");
Thread.Sleep(delayMs);
}
catch (Exception ex)
{
// Non-transient error or max retries exceeded
Interlocked.Increment(ref failed);
string errorMessage = $"{DateTime.Now:yyyy-MM-dd HH:mm:ss} | {fileName} | {ex.GetType().Name} | {ex.Message}";
errorLog.Add(errorMessage);
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
}
});
// Write error log
if (errorLog.Count > 0)
{
File.WriteAllLines(errorLogPath, errorLog);
}
Console.WriteLine($"\nBatch complete:");
Console.WriteLine($" Processed: {processed}");
Console.WriteLine($" Failed: {failed}");
Console.WriteLine($" Retried: {retried}");
if (failed > 0)
{
Console.WriteLine($" Error log: {errorLogPath}");
}
// Helper to identify transient exceptions worth retrying
bool IsTransientException(Exception ex)
{
return ex is IOException ||
ex is OutOfMemoryException ||
ex.Message.Contains("timeout", StringComparison.OrdinalIgnoreCase) ||
ex.Message.Contains("locked", StringComparison.OrdinalIgnoreCase);
}Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading
Imports System.Collections.Concurrent
Module Program
Sub Main()
Dim inputFolder As String = "input/"
Dim outputFolder As String = "output/"
Dim errorLogPath As String = "error-log.txt"
Directory.CreateDirectory(outputFolder)
Dim htmlFiles As String() = Directory.GetFiles(inputFolder, "*.html")
Dim renderer As New ChromePdfRenderer()
Dim errorLog As New ConcurrentBag(Of String)()
Dim processed As Integer = 0
Dim failed As Integer = 0
Dim retried As Integer = 0
Const maxRetries As Integer = 3
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(htmlFiles, options, Sub(htmlFile)
Dim fileName As String = Path.GetFileNameWithoutExtension(htmlFile)
Dim outputPath As String = Path.Combine(outputFolder, $"{fileName}.pdf")
Dim attempt As Integer = 0
Dim success As Boolean = False
While attempt < maxRetries AndAlso Not success
attempt += 1
Try
Using pdf = renderer.RenderHtmlFileAsPdf(htmlFile)
pdf.SaveAs(outputPath)
success = True
Interlocked.Increment(processed)
If attempt > 1 Then
Interlocked.Increment(retried)
Console.WriteLine($"[OK] {fileName}.pdf (succeeded on attempt {attempt})")
Else
Console.WriteLine($"[OK] {fileName}.pdf")
End If
End Using
Catch ex As Exception When IsTransientException(ex) AndAlso attempt < maxRetries
' Transient error - wait and retry with exponential backoff
Dim delayMs As Integer = CInt(Math.Pow(2, attempt)) * 500
Console.WriteLine($"[RETRY] {fileName}: {ex.Message} (attempt {attempt}, waiting {delayMs}ms)")
Thread.Sleep(delayMs)
Catch ex As Exception
' Non-transient error or max retries exceeded
Interlocked.Increment(failed)
Dim errorMessage As String = $"{DateTime.Now:yyyy-MM-dd HH:mm:ss} | {fileName} | {ex.GetType().Name} | {ex.Message}"
errorLog.Add(errorMessage)
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End While
End Sub)
' Write error log
If errorLog.Count > 0 Then
File.WriteAllLines(errorLogPath, errorLog)
End If
Console.WriteLine($"{vbCrLf}Batch complete:")
Console.WriteLine($" Processed: {processed}")
Console.WriteLine($" Failed: {failed}")
Console.WriteLine($" Retried: {retried}")
If failed > 0 Then
Console.WriteLine($" Error log: {errorLogPath}")
End If
End Sub
' Helper to identify transient exceptions worth retrying
Function IsTransientException(ex As Exception) As Boolean
Return TypeOf ex Is IOException OrElse
TypeOf ex Is OutOfMemoryException OrElse
ex.Message.Contains("timeout", StringComparison.OrdinalIgnoreCase) OrElse
ex.Message.Contains("locked", StringComparison.OrdinalIgnoreCase)
End Function
End ModuleUna vez completado el lote, revise el registro de errores para saber qué archivos fallaron y por qué. Entre las causas de fallo más comunes se encuentran los archivos fuente dañados, los PDF protegidos con contraseña, las funciones no compatibles en el contenido fuente y las condiciones de memoria insuficiente en documentos muy grandes.
Lógica de respuesta para fallos transitorios
Algunos fallos son pasajeros - tendrán éxito si lo intentas de nuevo. Por ejemplo, la contención del sistema de archivos (otro proceso tiene el archivo bloqueado), la presión de la memoria temporal (la GC aún no se ha puesto al día) y los tiempos de espera de la red al cargar recursos externos en contenido HTML. El ejemplo de código anterior gestiona estos reintentos con un retardo exponencial: empieza con un retardo corto y lo duplica en cada intento de reintento, hasta un número máximo de reintentos (normalmente 3).
La clave está en distinguir entre fallos reintentables y no reintentables. Vale la pena volver a intentar un IOException (archivo bloqueado) o un OutOfMemoryException (presión temporal). Un ArgumentException (entrada no válida) o un error de representación constante no lo es; volver a intentarlo no ayudará y perderá tiempo y recursos.
Checkpointing para reanudar después de un fallo
Cuando un trabajo por lotes procesa 50.000 archivos a lo largo de varias horas, un fallo en el archivo 35.000 no debería significar volver a empezar desde el principio. Los puntos de comprobación, es decir, el registro de los archivos que se han procesado correctamente, permiten reanudar el proceso desde el punto en que se dejó.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-checkpointing.csusing IronPdf;
using System;
using System.IO;
using System.Linq;
using System.Threading.Tasks;
using System.Threading;
using System.Collections.Generic;
string inputFolder = "input/";
string outputFolder = "output/";
string checkpointPath = "checkpoint.txt";
string errorLogPath = "errors.txt";
Directory.CreateDirectory(outputFolder);
// Load checkpoint - files already processed successfully
var completedFiles = new HashSet<string>();
if (File.Exists(checkpointPath))
{
completedFiles = new HashSet<string>(File.ReadAllLines(checkpointPath));
Console.WriteLine($"Resuming from checkpoint: {completedFiles.Count} files already processed");
}
// Get files to process (excluding already completed)
string[] allFiles = Directory.GetFiles(inputFolder, "*.html");
string[] filesToProcess = allFiles
.Where(f => !completedFiles.Contains(Path.GetFileName(f)))
.ToArray();
Console.WriteLine($"Files to process: {filesToProcess.Length} (skipping {completedFiles.Count} already done)");
var renderer = new ChromePdfRenderer();
var checkpointLock = new object();
int processed = 0;
int failed = 0;
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(filesToProcess, options, htmlFile =>
{
string fileName = Path.GetFileName(htmlFile);
string baseName = Path.GetFileNameWithoutExtension(htmlFile);
string outputPath = Path.Combine(outputFolder, $"{baseName}.pdf");
try
{
using var pdf = renderer.RenderHtmlFileAsPdf(htmlFile);
pdf.SaveAs(outputPath);
// Record success in checkpoint (thread-safe)
lock (checkpointLock)
{
File.AppendAllText(checkpointPath, fileName + Environment.NewLine);
}
Interlocked.Increment(ref processed);
Console.WriteLine($"[OK] {baseName}.pdf");
}
catch (Exception ex)
{
Interlocked.Increment(ref failed);
// Log error for review
lock (checkpointLock)
{
File.AppendAllText(errorLogPath,
$"{DateTime.Now:yyyy-MM-dd HH:mm:ss} | {fileName} | {ex.Message}{Environment.NewLine}");
}
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
});
Console.WriteLine($"\nBatch complete:");
Console.WriteLine($" Newly processed: {processed}");
Console.WriteLine($" Failed: {failed}");
Console.WriteLine($" Total completed: {completedFiles.Count + processed}");
Console.WriteLine($" Checkpoint saved to: {checkpointPath}");Imports IronPdf
Imports System
Imports System.IO
Imports System.Linq
Imports System.Threading.Tasks
Imports System.Threading
Imports System.Collections.Generic
Module Program
Sub Main()
Dim inputFolder As String = "input/"
Dim outputFolder As String = "output/"
Dim checkpointPath As String = "checkpoint.txt"
Dim errorLogPath As String = "errors.txt"
Directory.CreateDirectory(outputFolder)
' Load checkpoint - files already processed successfully
Dim completedFiles As New HashSet(Of String)()
If File.Exists(checkpointPath) Then
completedFiles = New HashSet(Of String)(File.ReadAllLines(checkpointPath))
Console.WriteLine($"Resuming from checkpoint: {completedFiles.Count} files already processed")
End If
' Get files to process (excluding already completed)
Dim allFiles As String() = Directory.GetFiles(inputFolder, "*.html")
Dim filesToProcess As String() = allFiles _
.Where(Function(f) Not completedFiles.Contains(Path.GetFileName(f))) _
.ToArray()
Console.WriteLine($"Files to process: {filesToProcess.Length} (skipping {completedFiles.Count} already done)")
Dim renderer As New ChromePdfRenderer()
Dim checkpointLock As New Object()
Dim processed As Integer = 0
Dim failed As Integer = 0
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(filesToProcess, options, Sub(htmlFile)
Dim fileName As String = Path.GetFileName(htmlFile)
Dim baseName As String = Path.GetFileNameWithoutExtension(htmlFile)
Dim outputPath As String = Path.Combine(outputFolder, $"{baseName}.pdf")
Try
Using pdf = renderer.RenderHtmlFileAsPdf(htmlFile)
pdf.SaveAs(outputPath)
End Using
' Record success in checkpoint (thread-safe)
SyncLock checkpointLock
File.AppendAllText(checkpointPath, fileName & Environment.NewLine)
End SyncLock
Interlocked.Increment(processed)
Console.WriteLine($"[OK] {baseName}.pdf")
Catch ex As Exception
Interlocked.Increment(failed)
' Log error for review
SyncLock checkpointLock
File.AppendAllText(errorLogPath,
$"{DateTime.Now:yyyy-MM-dd HH:mm:ss} | {fileName} | {ex.Message}{Environment.NewLine}")
End SyncLock
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End Sub)
Console.WriteLine(vbCrLf & "Batch complete:")
Console.WriteLine($" Newly processed: {processed}")
Console.WriteLine($" Failed: {failed}")
Console.WriteLine($" Total completed: {completedFiles.Count + processed}")
Console.WriteLine($" Checkpoint saved to: {checkpointPath}")
End Sub
End ModuleEl archivo de control actúa como registro permanente del trabajo realizado. Cuando se inicia el proceso, lee el archivo de control y omite los archivos que ya se han procesado correctamente. Cuando un archivo termina de procesarse, su ruta se añade al archivo de punto de control. Este método es sencillo, se basa en archivos y no requiere dependencias externas.
Para situaciones más sofisticadas, considere la posibilidad de utilizar una tabla de base de datos o una caché distribuida (como Redis) como almacén de puntos de control, especialmente si varios trabajadores procesan archivos en paralelo en diferentes máquinas.
Validación antes y después del procesamiento
La validación es la parte final de un proceso resistente. La validación previa al procesamiento detecta las entradas problemáticas antes de que pierdan tiempo de procesamiento; la validación posterior al procesamiento garantiza que el resultado cumpla sus requisitos de calidad y conformidad.
Entrada
Esta implementación envuelve el bucle de procesamiento con las funciones auxiliares PreValidate y PostValidate. La validación previa comprueba el tamaño del archivo, el tipo de contenido y la estructura HTML básica antes de procesarlo. La posvalidación verifica que el PDF de salida tenga un número de páginas válido y un tamaño de archivo razonable, moviendo los archivos validados a una carpeta separada y enviando los fallos a una carpeta de rechazo para su revisión manual.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-validation.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
using System.Threading;
using System.Collections.Concurrent;
string inputFolder = "input/";
string outputFolder = "output/";
string validatedFolder = "validated/";
string rejectedFolder = "rejected/";
Directory.CreateDirectory(outputFolder);
Directory.CreateDirectory(validatedFolder);
Directory.CreateDirectory(rejectedFolder);
string[] inputFiles = Directory.GetFiles(inputFolder, "*.html");
var renderer = new ChromePdfRenderer();
int preValidationFailed = 0;
int processingFailed = 0;
int postValidationFailed = 0;
int succeeded = 0;
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Environment.ProcessorCount / 2
};
Parallel.ForEach(inputFiles, options, inputFile =>
{
string fileName = Path.GetFileNameWithoutExtension(inputFile);
string outputPath = Path.Combine(outputFolder, $"{fileName}.pdf");
// Pre-validation: Check input file
if (!PreValidate(inputFile))
{
Interlocked.Increment(ref preValidationFailed);
Console.WriteLine($"[SKIP] {fileName}: Failed pre-validation");
return;
}
try
{
// Process
using var pdf = renderer.RenderHtmlFileAsPdf(inputFile);
pdf.SaveAs(outputPath);
// Post-validation: Check output file
if (PostValidate(outputPath))
{
// Move to validated folder
string validatedPath = Path.Combine(validatedFolder, $"{fileName}.pdf");
File.Move(outputPath, validatedPath, overwrite: true);
Interlocked.Increment(ref succeeded);
Console.WriteLine($"[OK] {fileName}.pdf (validated)");
}
else
{
// Move to rejected folder for manual review
string rejectedPath = Path.Combine(rejectedFolder, $"{fileName}.pdf");
File.Move(outputPath, rejectedPath, overwrite: true);
Interlocked.Increment(ref postValidationFailed);
Console.WriteLine($"[REJECT] {fileName}.pdf: Failed post-validation");
}
}
catch (Exception ex)
{
Interlocked.Increment(ref processingFailed);
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
});
Console.WriteLine($"\nValidation summary:");
Console.WriteLine($" Succeeded: {succeeded}");
Console.WriteLine($" Pre-validation failed: {preValidationFailed}");
Console.WriteLine($" Processing failed: {processingFailed}");
Console.WriteLine($" Post-validation failed: {postValidationFailed}");
// Pre-validation: Quick checks on input file
bool PreValidate(string filePath)
{
try
{
var fileInfo = new FileInfo(filePath);
// Check file exists and is readable
if (!fileInfo.Exists) return false;
// Check file is not empty
if (fileInfo.Length == 0) return false;
// Check file is not too large (e.g., 50MB limit)
if (fileInfo.Length > 50 * 1024 * 1024) return false;
// Quick content check - must be valid HTML
string content = File.ReadAllText(filePath);
if (string.IsNullOrWhiteSpace(content)) return false;
if (!content.Contains("<html", StringComparison.OrdinalIgnoreCase) &&
!content.Contains("<!DOCTYPE", StringComparison.OrdinalIgnoreCase))
{
return false;
}
return true;
}
catch
{
return false;
}
}
// Post-validation: Verify output PDF meets requirements
bool PostValidate(string pdfPath)
{
try
{
using var pdf = PdfDocument.FromFile(pdfPath);
// Check PDF has at least one page
if (pdf.PageCount < 1) return false;
// Check file size is reasonable (not just header, not corrupted)
var fileInfo = new FileInfo(pdfPath);
if (fileInfo.Length < 1024) return false;
return true;
}
catch
{
return false;
}
}Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading.Tasks
Imports System.Threading
Imports System.Collections.Concurrent
Module Program
Sub Main()
Dim inputFolder As String = "input/"
Dim outputFolder As String = "output/"
Dim validatedFolder As String = "validated/"
Dim rejectedFolder As String = "rejected/"
Directory.CreateDirectory(outputFolder)
Directory.CreateDirectory(validatedFolder)
Directory.CreateDirectory(rejectedFolder)
Dim inputFiles As String() = Directory.GetFiles(inputFolder, "*.html")
Dim renderer As New ChromePdfRenderer()
Dim preValidationFailed As Integer = 0
Dim processingFailed As Integer = 0
Dim postValidationFailed As Integer = 0
Dim succeeded As Integer = 0
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Environment.ProcessorCount \ 2
}
Parallel.ForEach(inputFiles, options, Sub(inputFile)
Dim fileName As String = Path.GetFileNameWithoutExtension(inputFile)
Dim outputPath As String = Path.Combine(outputFolder, $"{fileName}.pdf")
' Pre-validation: Check input file
If Not PreValidate(inputFile) Then
Interlocked.Increment(preValidationFailed)
Console.WriteLine($"[SKIP] {fileName}: Failed pre-validation")
Return
End If
Try
' Process
Using pdf = renderer.RenderHtmlFileAsPdf(inputFile)
pdf.SaveAs(outputPath)
' Post-validation: Check output file
If PostValidate(outputPath) Then
' Move to validated folder
Dim validatedPath As String = Path.Combine(validatedFolder, $"{fileName}.pdf")
File.Move(outputPath, validatedPath, overwrite:=True)
Interlocked.Increment(succeeded)
Console.WriteLine($"[OK] {fileName}.pdf (validated)")
Else
' Move to rejected folder for manual review
Dim rejectedPath As String = Path.Combine(rejectedFolder, $"{fileName}.pdf")
File.Move(outputPath, rejectedPath, overwrite:=True)
Interlocked.Increment(postValidationFailed)
Console.WriteLine($"[REJECT] {fileName}.pdf: Failed post-validation")
End If
End Using
Catch ex As Exception
Interlocked.Increment(processingFailed)
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End Sub)
Console.WriteLine(vbCrLf & "Validation summary:")
Console.WriteLine($" Succeeded: {succeeded}")
Console.WriteLine($" Pre-validation failed: {preValidationFailed}")
Console.WriteLine($" Processing failed: {processingFailed}")
Console.WriteLine($" Post-validation failed: {postValidationFailed}")
End Sub
' Pre-validation: Quick checks on input file
Function PreValidate(filePath As String) As Boolean
Try
Dim fileInfo As New FileInfo(filePath)
' Check file exists and is readable
If Not fileInfo.Exists Then Return False
' Check file is not empty
If fileInfo.Length = 0 Then Return False
' Check file is not too large (e.g., 50MB limit)
If fileInfo.Length > 50 * 1024 * 1024 Then Return False
' Quick content check - must be valid HTML
Dim content As String = File.ReadAllText(filePath)
If String.IsNullOrWhiteSpace(content) Then Return False
If Not content.Contains("<html", StringComparison.OrdinalIgnoreCase) AndAlso
Not content.Contains("<!DOCTYPE", StringComparison.OrdinalIgnoreCase) Then
Return False
End If
Return True
Catch
Return False
End Try
End Function
' Post-validation: Verify output PDF meets requirements
Function PostValidate(pdfPath As String) As Boolean
Try
Using pdf = PdfDocument.FromFile(pdfPath)
' Check PDF has at least one page
If pdf.PageCount < 1 Then Return False
' Check file size is reasonable (not just header, not corrupted)
Dim fileInfo As New FileInfo(pdfPath)
If fileInfo.Length < 1024 Then Return False
Return True
End Using
Catch
Return False
End Try
End Function
End ModuleResultado
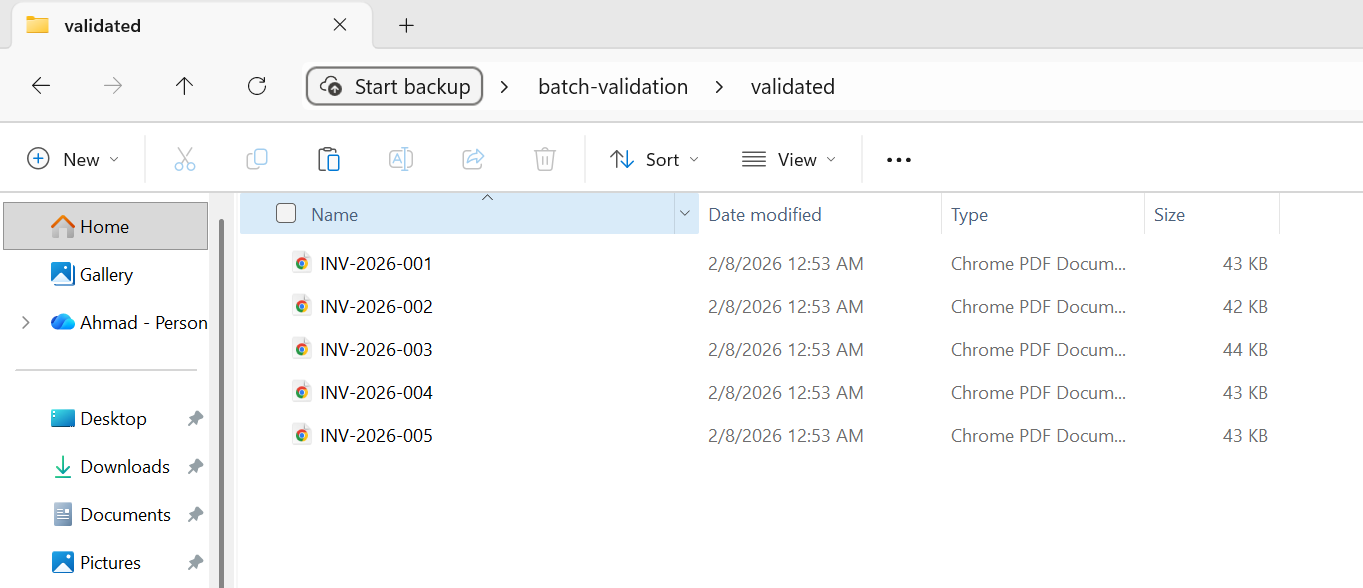
Los 5 archivos pasaron la validación y se trasladaron a la carpeta validada.
La validación previa al procesamiento debe ser rápida: se trata de comprobar si hay entradas obviamente defectuosas, no de realizar un procesamiento completo. La validación posterior al procesamiento puede ser más exhaustiva, especialmente en el caso de las conversiones de conformidad, en las que el resultado debe cumplir normas específicas (PDF/A, PDF/UA). Cualquier archivo que no supere la validación posterior al procesamiento deberá marcarse para su revisión manual en lugar de aceptarse de forma silenciosa.
Patrones de procesamiento asíncrono y paralelo
IronPDF admite tanto Parallel.ForEach (paralelismo basado en subprocesos) como async/await (E/S asincrónica). Entender cuándo utilizar cada una de ellas -y cómo combinarlas de forma eficaz- es clave para maximizar el rendimiento.
Integración de bibliotecas de tareas paralelas
Parallel.ForEach es el enfoque más simple y efectivo para operaciones por lotes limitadas por CPU. El motor de renderizado de IronPDF consume muchos recursos de la CPU (análisis de HTML, diseño de CSS, rasterización de imágenes) y Parallel.ForEach distribuye automáticamente este trabajo entre todos los núcleos disponibles.
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-tpl.csusing IronPdf;
using System;
using System.IO;
using System.Threading.Tasks;
using System.Threading;
using System.Diagnostics;
string inputFolder = "input/";
string outputFolder = "output/";
Directory.CreateDirectory(outputFolder);
string[] htmlFiles = Directory.GetFiles(inputFolder, "*.html");
var renderer = new ChromePdfRenderer();
Console.WriteLine($"Processing {htmlFiles.Length} files with {Environment.ProcessorCount} CPU cores");
int processed = 0;
var stopwatch = Stopwatch.StartNew();
// Configure parallelism based on system resources
// Rule of thumb: ProcessorCount / 2 for memory-intensive operations
var options = new ParallelOptions
{
MaxDegreeOfParallelism = Math.Max(1, Environment.ProcessorCount / 2)
};
Console.WriteLine($"Max parallelism: {options.MaxDegreeOfParallelism}");
// Use Parallel.ForEach for CPU-bound batch operations
Parallel.ForEach(htmlFiles, options, htmlFile =>
{
string fileName = Path.GetFileNameWithoutExtension(htmlFile);
string outputPath = Path.Combine(outputFolder, $"{fileName}.pdf");
try
{
// Render HTML to PDF
using var pdf = renderer.RenderHtmlFileAsPdf(htmlFile);
pdf.SaveAs(outputPath);
int current = Interlocked.Increment(ref processed);
// Progress reporting every 10 files
if (current % 10 == 0)
{
double elapsed = stopwatch.Elapsed.TotalSeconds;
double rate = current / elapsed;
double remaining = (htmlFiles.Length - current) / rate;
Console.WriteLine($"Progress: {current}/{htmlFiles.Length} ({rate:F1} files/sec, ~{remaining:F0}s remaining)");
}
}
catch (Exception ex)
{
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}");
}
});
stopwatch.Stop();
double totalRate = processed / stopwatch.Elapsed.TotalSeconds;
Console.WriteLine($"\nComplete:");
Console.WriteLine($" Files processed: {processed}/{htmlFiles.Length}");
Console.WriteLine($" Total time: {stopwatch.Elapsed.TotalSeconds:F1}s");
Console.WriteLine($" Average rate: {totalRate:F1} files/sec");
Console.WriteLine($" Time per file: {stopwatch.Elapsed.TotalMilliseconds / processed:F0}ms");
// Memory monitoring helper (call between chunks for large batches)
void CheckMemoryPressure()
{
const long memoryThreshold = 4L * 1024 * 1024 * 1024; // 4 GB
long currentMemory = GC.GetTotalMemory(forceFullCollection: false);
if (currentMemory > memoryThreshold)
{
Console.WriteLine($"Memory pressure detected ({currentMemory / 1024 / 1024}MB), forcing GC...");
GC.Collect();
GC.WaitForPendingFinalizers();
GC.Collect();
}
}Imports IronPdf
Imports System
Imports System.IO
Imports System.Threading.Tasks
Imports System.Threading
Imports System.Diagnostics
Module Program
Sub Main()
Dim inputFolder As String = "input/"
Dim outputFolder As String = "output/"
Directory.CreateDirectory(outputFolder)
Dim htmlFiles As String() = Directory.GetFiles(inputFolder, "*.html")
Dim renderer As New ChromePdfRenderer()
Console.WriteLine($"Processing {htmlFiles.Length} files with {Environment.ProcessorCount} CPU cores")
Dim processed As Integer = 0
Dim stopwatch As Stopwatch = Stopwatch.StartNew()
' Configure parallelism based on system resources
' Rule of thumb: ProcessorCount / 2 for memory-intensive operations
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = Math.Max(1, Environment.ProcessorCount \ 2)
}
Console.WriteLine($"Max parallelism: {options.MaxDegreeOfParallelism}")
' Use Parallel.ForEach for CPU-bound batch operations
Parallel.ForEach(htmlFiles, options, Sub(htmlFile)
Dim fileName As String = Path.GetFileNameWithoutExtension(htmlFile)
Dim outputPath As String = Path.Combine(outputFolder, $"{fileName}.pdf")
Try
' Render HTML to PDF
Using pdf = renderer.RenderHtmlFileAsPdf(htmlFile)
pdf.SaveAs(outputPath)
End Using
Dim current As Integer = Interlocked.Increment(processed)
' Progress reporting every 10 files
If current Mod 10 = 0 Then
Dim elapsed As Double = stopwatch.Elapsed.TotalSeconds
Dim rate As Double = current / elapsed
Dim remaining As Double = (htmlFiles.Length - current) / rate
Console.WriteLine($"Progress: {current}/{htmlFiles.Length} ({rate:F1} files/sec, ~{remaining:F0}s remaining)")
End If
Catch ex As Exception
Console.WriteLine($"[ERROR] {fileName}: {ex.Message}")
End Try
End Sub)
stopwatch.Stop()
Dim totalRate As Double = processed / stopwatch.Elapsed.TotalSeconds
Console.WriteLine(vbCrLf & "Complete:")
Console.WriteLine($" Files processed: {processed}/{htmlFiles.Length}")
Console.WriteLine($" Total time: {stopwatch.Elapsed.TotalSeconds:F1}s")
Console.WriteLine($" Average rate: {totalRate:F1} files/sec")
Console.WriteLine($" Time per file: {stopwatch.Elapsed.TotalMilliseconds / processed:F0}ms")
' Memory monitoring helper (call between chunks for large batches)
CheckMemoryPressure()
End Sub
Sub CheckMemoryPressure()
Const memoryThreshold As Long = 4L * 1024 * 1024 * 1024 ' 4 GB
Dim currentMemory As Long = GC.GetTotalMemory(forceFullCollection:=False)
If currentMemory > memoryThreshold Then
Console.WriteLine($"Memory pressure detected ({currentMemory \ 1024 \ 1024}MB), forcing GC...")
GC.Collect()
GC.WaitForPendingFinalizers()
GC.Collect()
End If
End Sub
End ModuleLa opción MaxDegreeOfParallelism es crítica. Sin ella, el TPL intentará utilizar todos los núcleos disponibles, lo que puede saturar la memoria si cada renderización consume muchos recursos. Ajústalo en función de la RAM disponible en tu sistema dividida por el consumo típico de memoria por renderizado (normalmente 100-300 MB por renderizado concurrente para HTML complejo).
Control de la concurrencia (SemaphoreSlim)
Cuando necesita un control más preciso sobre la concurrencia que el que proporciona Parallel.ForEach (por ejemplo, al mezclar E/S asincrónica con renderizado limitado por CPU), SemaphoreSlim le brinda control explícito sobre cuántas operaciones se ejecutan simultáneamente. El patrón es sencillo: crea un SemaphoreSlim con el límite de concurrencia deseado (por ejemplo, 4 renderizaciones simultáneas), llama a WaitAsync antes de cada renderización y a Release en un bloque finally después. Luego inicie todas las tareas con Task.WhenAll.
Este patrón es especialmente útil cuando el proceso incluye tanto pasos de E/S (lectura de archivos de almacenamiento blob, escritura de resultados en una base de datos) como pasos de CPU (renderización de PDF). El semáforo limita la concurrencia de renderizado vinculada a la CPU al tiempo que permite que los pasos vinculados a la E/S avancen sin estrangulamiento.
Mejores prácticas de Async/Await
IronPDF ofrece variantes asincrónicas de sus métodos de renderizado, incluidos RenderHtmlAsPdfAsync, RenderUrlAsPdfAsync y RenderHtmlFileAsPdfAsync. Son ideales para aplicaciones web (donde el bloqueo del hilo de solicitud es inaceptable) y para pipelines que mezclan el renderizado de PDF con operaciones de E/S asíncronas.
Algunas prácticas recomendadas importantes de async para el procesamiento por lotes:
No utilice Task.Run para encapsular métodos IronPDF sincrónicos ; utilice en su lugar las variantes asincrónicas nativas. Envolver métodos sincrónicos en Task.Run desperdicia un hilo del grupo de subprocesos y agrega sobrecarga sin ningún beneficio.
No utilice .Result o .Wait() en tareas asincrónicas : esto bloquea el hilo que realiza la llamada y puede causar bloqueos en los contextos de UI o ASP.NET . Utilice siempre await.
Agrupe sus llamadas Task.WhenAll en lugar de esperar todas las tareas a la vez. Si tiene 10 000 tareas y llama a Task.WhenAll en todas ellas simultáneamente, iniciará 10 000 operaciones simultáneas. En su lugar, utilice .Chunk(10) o un enfoque similar para procesarlos en grupos, esperando cada grupo secuencialmente.
Evitar el agotamiento de memoria
El agotamiento de la memoria es el modo de fallo más común en el procesamiento de PDF por lotes. El enfoque defensivo es monitorear el uso de memoria con GC.GetTotalMemory() antes de cada renderizado y activar una recopilación cuando el consumo cruza un umbral (por ejemplo, 4 GB o el 80 % de la RAM disponible). Llame a GC.Collect() seguido de GC.WaitForPendingFinalizers() y un segundo GC.Collect() para recuperar la mayor cantidad de memoria posible antes de continuar. Esto agrega una pequeña pausa pero evita la alternativa catastrófica de un OutOfMemoryException que haga colapsar todo el lote en el archivo n.° 30 000.
Combine esto con la limitación MaxDegreeOfParallelism de la sección TPL y el patrón de eliminación using de la sección de administración de memoria, y tendrá una defensa de tres capas contra problemas de memoria: limitar la concurrencia, eliminar agresivamente y monitorear con una válvula de seguridad.
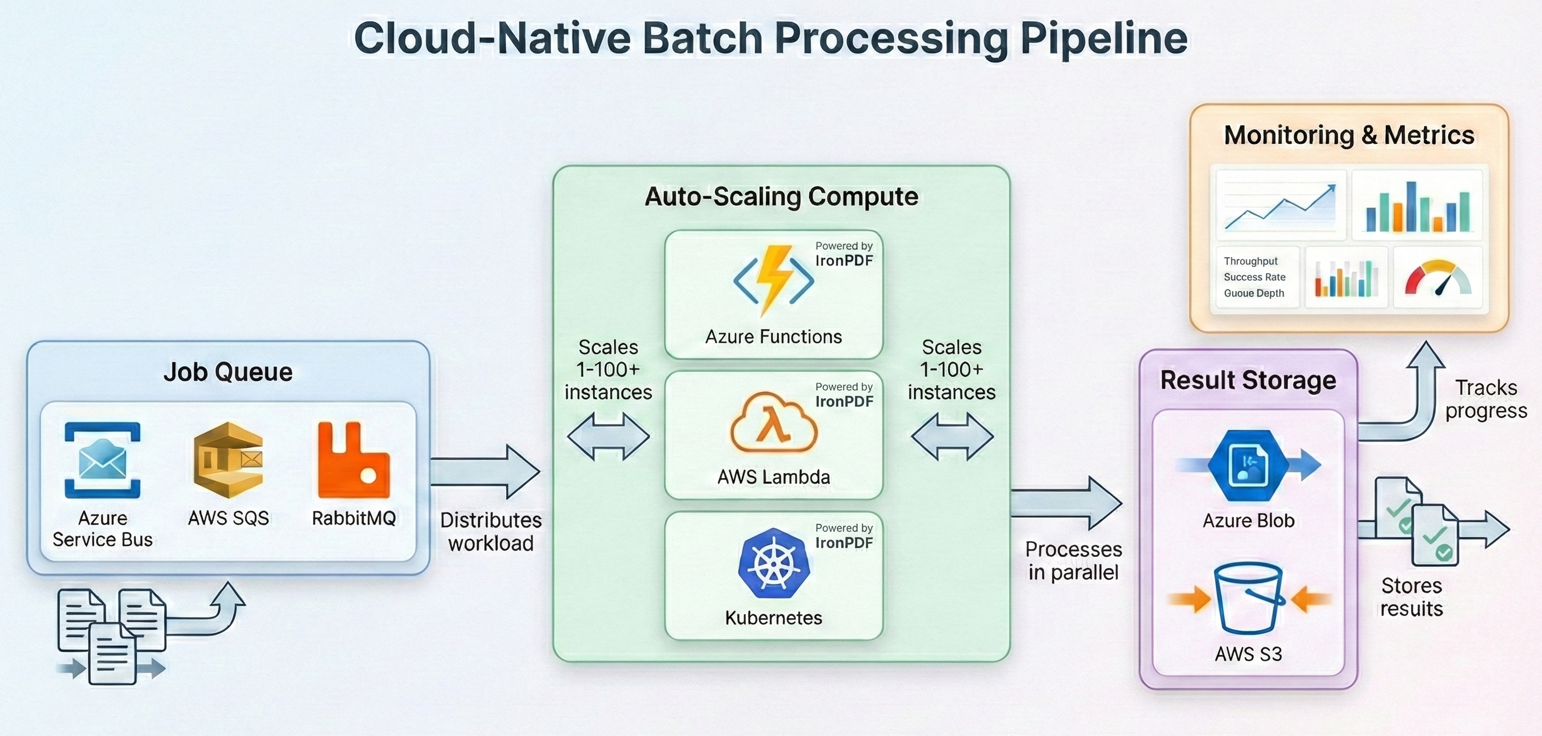
Despliegue en la nube para trabajos por lotes
El procesamiento por lotes moderno se ejecuta cada vez más en la nube, donde se pueden escalar los recursos informáticos para adaptarse a las demandas de carga de trabajo y pagar sólo por lo que se utiliza. IronPDF se ejecuta en las principales plataformas en la nube. A continuación se explica cómo diseñar procesos por lotes para cada una de ellas.
Azure Functions con Funciones Duraderas
Azure Durable Functions proporciona una orquestación integrada para patrones fan-out/fan-in, lo que las convierte en una opción natural para el procesamiento de PDF por lotes. La función orquestadora distribuye el trabajo entre varias instancias de funciones de actividad, cada una de las cuales procesa un subconjunto de archivos. Su orquestador llama a CallActivityAsync en un bucle de distribución, cada función de actividad instancia un ChromePdfRenderer, procesa su fragmento de archivos y el orquestador recopila los resultados.
Consideraciones clave para Azure Functions: el plan de consumo predeterminado tiene un tiempo de espera de 5 minutos por invocación de función y memoria limitada. Para el procesamiento por lotes, utilice el plan Premium o Dedicado, que admite tiempos de espera más largos y más memoria. IronPDF requiere el tiempo de ejecución completo de .NET (no recortado), así que asegúrese de que su aplicación funcional está configurada for .NET 8+ con el identificador de tiempo de ejecución adecuado.
AWS Lambda con funciones escalonadas
AWS Step Functions ofrece una capacidad de orquestación similar a Azure Durable Functions. Cada paso de la máquina de estados invoca una función Lambda que procesa un fragmento de archivos. Su controlador Lambda recibe un lote de claves de objetos S3, carga cada PDF con PdfDocument.FromFile, aplica su canal de procesamiento (compresión, conversión de formato, etc.) y escribe los resultados en un depósito S3 de salida.
AWS Lambda tiene un tiempo de ejecución máximo de 15 minutos y un almacenamiento /tmp limitado (512 MB por defecto, configurable hasta 10 GB). Para trabajos por lotes de gran tamaño, utilice Step Functions para dividir la carga de trabajo en partes y procesar cada parte en una invocación Lambda independiente. Almacenar los resultados intermedios en S3 en lugar de almacenamiento local.
Programación de trabajos de Kubernetes
Para las organizaciones que ejecutan sus propios clústeres Kubernetes, el procesamiento de PDF por lotes se adapta bien a Kubernetes Jobs y CronJobs. Cada pod ejecuta un trabajador por lotes que extrae archivos de una cola (Azure Service Bus, RabbitMQ o SQS), los procesa con IronPDF y escribe los resultados en el almacenamiento de objetos. El bucle de trabajo sigue el mismo patrón tratado en secciones anteriores: sacar un mensaje de la cola, usar ChromePdfRenderer.RenderHtmlAsPdf() o PdfDocument.FromFile() para procesar el documento, cargar el resultado y reconocer el mensaje. Envuelva el procesamiento en el mismo try-catch con la lógica de reintento de los patrones de resiliencia y use SemaphoreSlim para controlar la concurrencia por pod.
IronPDF es compatible con Docker y se ejecuta en contenedores Linux. Utilice el paquete NuGet IronPdf con los paquetes de ejecución nativos adecuados para el sistema operativo de su contenedor (por ejemplo, IronPdf.Linux para imágenes basadas en Linux). Para Kubernetes, defina solicitudes y límites de recursos que coincidan con los requisitos de memoria de IronPDF (normalmente 512 MB-2 GB por pod en función de la concurrencia). Horizontal Pod Autoscaler puede escalar los trabajadores en función de la profundidad de la cola, y el patrón de checkpointing garantiza que no se pierda ningún trabajo si se desalojan los pods.
Estrategias de optimización de costes
El procesamiento por lotes en la nube puede resultar caro si no se tiene en cuenta la asignación de recursos. Estas son las estrategias que tienen mayor impacto:
Dimensiona correctamente tu computación. El renderizado de PDF es intensivo en CPU y memoria, no en GPU. Utilice instancias optimizadas para computación (serie C en Azure, tipo C en AWS) en lugar de instancias de uso general u optimizadas para memoria. Obtendrá una mejor relación precio-rendimiento.
Utilizar instancias puntuales/prefabricadas para cargas de trabajo por lotes que puedan tolerar interrupciones. El procesamiento de PDF por lotes es inherentemente reanudable (gracias a los puntos de control), lo que lo convierte en un candidato ideal para la fijación de precios al contado, que suele ofrecer descuentos del 60-90% con respecto a los servicios bajo demanda.
Procese durante las horas de menor actividad si su calendario lo permite. Muchos proveedores de servicios en la nube ofrecen precios más bajos o mayor disponibilidad puntual durante las noches y los fines de semana.
Comprima antes, almacene una vez. Ejecute la compresión como parte de su canal de procesamiento en lugar de como un paso separado. Almacenar los PDF comprimidos desde el principio reduce los costes de almacenamiento durante toda la vida útil del archivo.
Equipar su almacenamiento Los PDF procesados a los que se accede con frecuencia deben ir en almacenamiento en caliente; los PDF archivados a los que se accede con poca frecuencia deben trasladarse a niveles fríos o de archivo (Azure Cool/Archive, AWS S3 Glacier). Esto por sí solo puede reducir los costes de almacenamiento en un 50-80%.
Ejemplo de canalización en el mundo real
Vamos a atar todo junto con una tubería por lotes completa, de grado de producción que demuestra el flujo de trabajo completo: Ingest → Validate → Process → Archive → Report.
Este ejemplo procesa un directorio de plantillas de facturas HTML, las convierte a PDF, comprime el resultado, lo convierte a PDF/A-3b para cumplir los requisitos de archivado, valida el resultado y produce un informe resumido al final.
Utilizando las mismas 5 facturas HTML del ejemplo de conversión por lotes anterior...
:path=/static-assets/pdf/content-code-examples/tutorials/batch-pdf-processing-csharp/batch-processing-full-pipeline.csusing IronPdf;
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Threading.Tasks;
using System.Threading;
using System.Collections.Concurrent;
using System.Diagnostics;
using System.Text.Json;
// Configuration
var config = new PipelineConfig
{
InputFolder = "input/",
OutputFolder = "output/",
ArchiveFolder = "archive/",
ErrorFolder = "errors/",
CheckpointPath = "pipeline-checkpoint.json",
ReportPath = "pipeline-report.json",
MaxConcurrency = Math.Max(1, Environment.ProcessorCount / 2),
MaxRetries = 3,
JpegQuality = 70
};
// Initialize folders
Directory.CreateDirectory(config.OutputFolder);
Directory.CreateDirectory(config.ArchiveFolder);
Directory.CreateDirectory(config.ErrorFolder);
// Load checkpoint for resume capability
var checkpoint = LoadCheckpoint(config.CheckpointPath);
var results = new ConcurrentBag<ProcessingResult>();
var stopwatch = Stopwatch.StartNew();
// Get files to process
string[] allFiles = Directory.GetFiles(config.InputFolder, "*.html");
string[] filesToProcess = allFiles
.Where(f => !checkpoint.CompletedFiles.Contains(Path.GetFileName(f)))
.ToArray();
Console.WriteLine($"Pipeline starting:");
Console.WriteLine($" Total files: {allFiles.Length}");
Console.WriteLine($" Already processed: {checkpoint.CompletedFiles.Count}");
Console.WriteLine($" To process: {filesToProcess.Length}");
Console.WriteLine($" Concurrency: {config.MaxConcurrency}");
var renderer = new ChromePdfRenderer();
var checkpointLock = new object();
var options = new ParallelOptions
{
MaxDegreeOfParallelism = config.MaxConcurrency
};
Parallel.ForEach(filesToProcess, options, inputFile =>
{
var result = new ProcessingResult
{
FileName = Path.GetFileName(inputFile),
StartTime = DateTime.UtcNow
};
try
{
// Stage: Pre-validation
if (!ValidateInput(inputFile))
{
result.Status = "PreValidationFailed";
result.Error = "Input file failed validation";
results.Add(result);
return;
}
string baseName = Path.GetFileNameWithoutExtension(inputFile);
string tempPath = Path.Combine(config.OutputFolder, $"{baseName}.pdf");
string archivePath = Path.Combine(config.ArchiveFolder, $"{baseName}.pdf");
// Stage: Process with retry
PdfDocument pdf = null;
int attempt = 0;
bool success = false;
while (attempt < config.MaxRetries && !success)
{
attempt++;
try
{
pdf = renderer.RenderHtmlFileAsPdf(inputFile);
success = true;
}
catch (Exception ex) when (IsTransient(ex) && attempt < config.MaxRetries)
{
Thread.Sleep((int)Math.Pow(2, attempt) * 500);
}
}
if (!success || pdf == null)
{
result.Status = "ProcessingFailed";
result.Error = "Max retries exceeded";
results.Add(result);
return;
}
using (pdf)
{
// Stage: Compress and convert to PDF/A-3b for archival
pdf.SaveAsPdfA(tempPath, PdfAVersions.PdfA3b);
}
// Stage: Post-validation
if (!ValidateOutput(tempPath))
{
File.Move(tempPath, Path.Combine(config.ErrorFolder, $"{baseName}.pdf"), overwrite: true);
result.Status = "PostValidationFailed";
result.Error = "Output file failed validation";
results.Add(result);
return;
}
// Stage: Archive
File.Move(tempPath, archivePath, overwrite: true);
// Update checkpoint
lock (checkpointLock)
{
checkpoint.CompletedFiles.Add(result.FileName);
SaveCheckpoint(config.CheckpointPath, checkpoint);
}
result.Status = "Success";
result.OutputSize = new FileInfo(archivePath).Length;
result.EndTime = DateTime.UtcNow;
results.Add(result);
Console.WriteLine($"[OK] {baseName}.pdf ({result.OutputSize / 1024}KB)");
}
catch (Exception ex)
{
result.Status = "Error";
result.Error = ex.Message;
result.EndTime = DateTime.UtcNow;
results.Add(result);
Console.WriteLine($"[ERROR] {result.FileName}: {ex.Message}");
}
});
stopwatch.Stop();
// Generate report
var report = new PipelineReport
{
TotalFiles = allFiles.Length,
ProcessedThisRun = results.Count,
Succeeded = results.Count(r => r.Status == "Success"),
PreValidationFailed = results.Count(r => r.Status == "PreValidationFailed"),
ProcessingFailed = results.Count(r => r.Status == "ProcessingFailed"),
PostValidationFailed = results.Count(r => r.Status == "PostValidationFailed"),
Errors = results.Count(r => r.Status == "Error"),
TotalDuration = stopwatch.Elapsed,
AverageFileTime = results.Any() ? TimeSpan.FromMilliseconds(stopwatch.Elapsed.TotalMilliseconds / results.Count) : TimeSpan.Zero
};
string reportJson = JsonSerializer.Serialize(report, new JsonSerializerOptions { WriteIndented = true });
File.WriteAllText(config.ReportPath, reportJson);
Console.WriteLine($"\n=== Pipeline Complete ===");
Console.WriteLine($"Succeeded: {report.Succeeded}");
Console.WriteLine($"Failed: {report.PreValidationFailed + report.ProcessingFailed + report.PostValidationFailed + report.Errors}");
Console.WriteLine($"Duration: {report.TotalDuration.TotalMinutes:F1} minutes");
Console.WriteLine($"Report: {config.ReportPath}");
// Helper methods
bool ValidateInput(string path)
{
try
{
var info = new FileInfo(path);
if (!info.Exists || info.Length == 0 || info.Length > 50 * 1024 * 1024) return false;
string content = File.ReadAllText(path);
return content.Contains("<html", StringComparison.OrdinalIgnoreCase) ||
content.Contains("<!DOCTYPE", StringComparison.OrdinalIgnoreCase);
}
catch { return false; }
}
bool ValidateOutput(string path)
{
try
{
using var pdf = PdfDocument.FromFile(path);
return pdf.PageCount > 0 && new FileInfo(path).Length > 1024;
}
catch { return false; }
}
bool IsTransient(Exception ex) =>
ex is IOException || ex is OutOfMemoryException ||
ex.Message.Contains("timeout", StringComparison.OrdinalIgnoreCase);
Checkpoint LoadCheckpoint(string path)
{
if (File.Exists(path))
{
string json = File.ReadAllText(path);
return JsonSerializer.Deserialize<Checkpoint>(json) ?? new Checkpoint();
}
return new Checkpoint();
}
void SaveCheckpoint(string path, Checkpoint cp) =>
File.WriteAllText(path, JsonSerializer.Serialize(cp));
ata classes
s PipelineConfig
public string InputFolder { get; set; } = "";
public string OutputFolder { get; set; } = "";
public string ArchiveFolder { get; set; } = "";
public string ErrorFolder { get; set; } = "";
public string CheckpointPath { get; set; } = "";
public string ReportPath { get; set; } = "";
public int MaxConcurrency { get; set; }
public int MaxRetries { get; set; }
public int JpegQuality { get; set; }
s Checkpoint
public HashSet<string> CompletedFiles { get; set; } = new();
s ProcessingResult
public string FileName { get; set; } = "";
public string Status { get; set; } = "";
public string Error { get; set; } = "";
public long OutputSize { get; set; }
public DateTime StartTime { get; set; }
public DateTime EndTime { get; set; }
s PipelineReport
public int TotalFiles { get; set; }
public int ProcessedThisRun { get; set; }
public int Succeeded { get; set; }
public int PreValidationFailed { get; set; }
public int ProcessingFailed { get; set; }
public int PostValidationFailed { get; set; }
public int Errors { get; set; }
public TimeSpan TotalDuration { get; set; }
public TimeSpan AverageFileTime { get; set; }Imports IronPdf
Imports System
Imports System.Collections.Generic
Imports System.IO
Imports System.Linq
Imports System.Threading.Tasks
Imports System.Threading
Imports System.Collections.Concurrent
Imports System.Diagnostics
Imports System.Text.Json
' Configuration
Dim config As New PipelineConfig With {
.InputFolder = "input/",
.OutputFolder = "output/",
.ArchiveFolder = "archive/",
.ErrorFolder = "errors/",
.CheckpointPath = "pipeline-checkpoint.json",
.ReportPath = "pipeline-report.json",
.MaxConcurrency = Math.Max(1, Environment.ProcessorCount \ 2),
.MaxRetries = 3,
.JpegQuality = 70
}
' Initialize folders
Directory.CreateDirectory(config.OutputFolder)
Directory.CreateDirectory(config.ArchiveFolder)
Directory.CreateDirectory(config.ErrorFolder)
' Load checkpoint for resume capability
Dim checkpoint As Checkpoint = LoadCheckpoint(config.CheckpointPath)
Dim results As New ConcurrentBag(Of ProcessingResult)()
Dim stopwatch As Stopwatch = Stopwatch.StartNew()
' Get files to process
Dim allFiles As String() = Directory.GetFiles(config.InputFolder, "*.html")
Dim filesToProcess As String() = allFiles.
Where(Function(f) Not checkpoint.CompletedFiles.Contains(Path.GetFileName(f))).
ToArray()
Console.WriteLine("Pipeline starting:")
Console.WriteLine($" Total files: {allFiles.Length}")
Console.WriteLine($" Already processed: {checkpoint.CompletedFiles.Count}")
Console.WriteLine($" To process: {filesToProcess.Length}")
Console.WriteLine($" Concurrency: {config.MaxConcurrency}")
Dim renderer As New ChromePdfRenderer()
Dim checkpointLock As New Object()
Dim options As New ParallelOptions With {
.MaxDegreeOfParallelism = config.MaxConcurrency
}
Parallel.ForEach(filesToProcess, options, Sub(inputFile)
Dim result As New ProcessingResult With {
.FileName = Path.GetFileName(inputFile),
.StartTime = DateTime.UtcNow
}
Try
' Stage: Pre-validation
If Not ValidateInput(inputFile) Then
result.Status = "PreValidationFailed"
result.Error = "Input file failed validation"
results.Add(result)
Return
End If
Dim baseName As String = Path.GetFileNameWithoutExtension(inputFile)
Dim tempPath As String = Path.Combine(config.OutputFolder, $"{baseName}.pdf")
Dim archivePath As String = Path.Combine(config.ArchiveFolder, $"{baseName}.pdf")
' Stage: Process with retry
Dim pdf As PdfDocument = Nothing
Dim attempt As Integer = 0
Dim success As Boolean = False
While attempt < config.MaxRetries AndAlso Not success
attempt += 1
Try
pdf = renderer.RenderHtmlFileAsPdf(inputFile)
success = True
Catch ex As Exception When IsTransient(ex) AndAlso attempt < config.MaxRetries
Thread.Sleep(CInt(Math.Pow(2, attempt)) * 500)
End Try
End While
If Not success OrElse pdf Is Nothing Then
result.Status = "ProcessingFailed"
result.Error = "Max retries exceeded"
results.Add(result)
Return
End If
Using pdf
' Stage: Compress and convert to PDF/A-3b for archival
pdf.SaveAsPdfA(tempPath, PdfAVersions.PdfA3b)
End Using
' Stage: Post-validation
If Not ValidateOutput(tempPath) Then
File.Move(tempPath, Path.Combine(config.ErrorFolder, $"{baseName}.pdf"), overwrite:=True)
result.Status = "PostValidationFailed"
result.Error = "Output file failed validation"
results.Add(result)
Return
End If
' Stage: Archive
File.Move(tempPath, archivePath, overwrite:=True)
' Update checkpoint
SyncLock checkpointLock
checkpoint.CompletedFiles.Add(result.FileName)
SaveCheckpoint(config.CheckpointPath, checkpoint)
End SyncLock
result.Status = "Success"
result.OutputSize = New FileInfo(archivePath).Length
result.EndTime = DateTime.UtcNow
results.Add(result)
Console.WriteLine($"[OK] {baseName}.pdf ({result.OutputSize \ 1024}KB)")
Catch ex As Exception
result.Status = "Error"
result.Error = ex.Message
result.EndTime = DateTime.UtcNow
results.Add(result)
Console.WriteLine($"[ERROR] {result.FileName}: {ex.Message}")
End Try
End Sub)
stopwatch.Stop()
' Generate report
Dim report As New PipelineReport With {
.TotalFiles = allFiles.Length,
.ProcessedThisRun = results.Count,
.Succeeded = results.Count(Function(r) r.Status = "Success"),
.PreValidationFailed = results.Count(Function(r) r.Status = "PreValidationFailed"),
.ProcessingFailed = results.Count(Function(r) r.Status = "ProcessingFailed"),
.PostValidationFailed = results.Count(Function(r) r.Status = "PostValidationFailed"),
.Errors = results.Count(Function(r) r.Status = "Error"),
.TotalDuration = stopwatch.Elapsed,
.AverageFileTime = If(results.Any(), TimeSpan.FromMilliseconds(stopwatch.Elapsed.TotalMilliseconds / results.Count), TimeSpan.Zero)
}
Dim reportJson As String = JsonSerializer.Serialize(report, New JsonSerializerOptions With {.WriteIndented = True})
File.WriteAllText(config.ReportPath, reportJson)
Console.WriteLine(vbCrLf & "=== Pipeline Complete ===")
Console.WriteLine($"Succeeded: {report.Succeeded}")
Console.WriteLine($"Failed: {report.PreValidationFailed + report.ProcessingFailed + report.PostValidationFailed + report.Errors}")
Console.WriteLine($"Duration: {report.TotalDuration.TotalMinutes:F1} minutes")
Console.WriteLine($"Report: {config.ReportPath}")
' Helper methods
Function ValidateInput(path As String) As Boolean
Try
Dim info As New FileInfo(path)
If Not info.Exists OrElse info.Length = 0 OrElse info.Length > 50 * 1024 * 1024 Then Return False
Dim content As String = File.ReadAllText(path)
Return content.Contains("<html", StringComparison.OrdinalIgnoreCase) OrElse
content.Contains("<!DOCTYPE", StringComparison.OrdinalIgnoreCase)
Catch
Return False
End Try
End Function
Function ValidateOutput(path As String) As Boolean
Try
Using pdf = PdfDocument.FromFile(path)
Return pdf.PageCount > 0 AndAlso New FileInfo(path).Length > 1024
End Using
Catch
Return False
End Try
End Function
Function IsTransient(ex As Exception) As Boolean
Return TypeOf ex Is IOException OrElse TypeOf ex Is OutOfMemoryException OrElse
ex.Message.Contains("timeout", StringComparison.OrdinalIgnoreCase)
End Function
Function LoadCheckpoint(path As String) As Checkpoint
If File.Exists(path) Then
Dim json As String = File.ReadAllText(path)
Return JsonSerializer.Deserialize(Of Checkpoint)(json) OrElse New Checkpoint()
End If
Return New Checkpoint()
End Function
Sub SaveCheckpoint(path As String, cp As Checkpoint)
File.WriteAllText(path, JsonSerializer.Serialize(cp))
End Sub
' Data classes
Class PipelineConfig
Public Property InputFolder As String = ""
Public Property OutputFolder As String = ""
Public Property ArchiveFolder As String = ""
Public Property ErrorFolder As String = ""
Public Property CheckpointPath As String = ""
Public Property ReportPath As String = ""
Public Property MaxConcurrency As Integer
Public Property MaxRetries As Integer
Public Property JpegQuality As Integer
End Class
Class Checkpoint
Public Property CompletedFiles As HashSet(Of String) = New HashSet(Of String)()
End Class
Class ProcessingResult
Public Property FileName As String = ""
Public Property Status As String = ""
Public Property Error As String = ""
Public Property OutputSize As Long
Public Property StartTime As DateTime
Public Property EndTime As DateTime
End Class
Class PipelineReport
Public Property TotalFiles As Integer
Public Property ProcessedThisRun As Integer
Public Property Succeeded As Integer
Public Property PreValidationFailed As Integer
Public Property ProcessingFailed As Integer
Public Property PostValidationFailed As Integer
Public Property Errors As Integer
Public Property TotalDuration As TimeSpan
Public Property AverageFileTime As TimeSpan
End ClassResultado
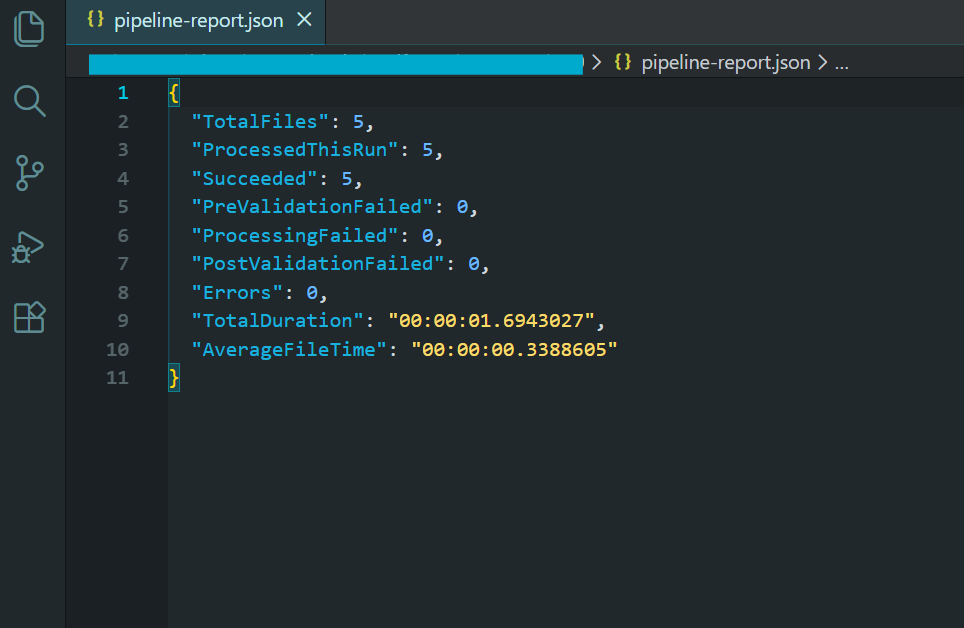
Informe de canalización que muestra los resultados del procesamiento por lotes.
Este pipeline incorpora todos los patrones que hemos tratado en este tutorial: procesamiento paralelo con concurrencia controlada, gestión de errores por archivo con skip-on-failure, lógica de reintento para errores transitorios, checkpointing para reanudar después de un fallo, validación previa y posterior al procesamiento, gestión de memoria con eliminación explícita y registro completo con un informe de resumen final.
El resultado de este proceso es un directorio de archivos comprimidos compatibles con PDF/A-3b, un archivo de control para reanudar el proceso, un registro de errores para los archivos que no se han podido procesar y un informe resumido con estadísticas de procesamiento. Este es el patrón que desea para cualquier carga de trabajo seria de procesamiento de PDF por lotes.
Próximos pasos
El procesamiento de PDF por lotes a escala no consiste únicamente en llamar a un método de renderización en un bucle. Requiere una arquitectura bien pensada en torno a la concurrencia, la gestión de memoria, la gestión de errores y la implementación, así como la biblioteca adecuada para que todo funcione. IronPDF proporciona el motor de renderizado a prueba de hilos, la superficie API asíncrona, herramientas de compresión y capacidades de conversión de formato que forman la base de cualquier canalización de PDF por lotes .NET.
Tanto si está creando un generador de informes nocturno que produce miles de PDF antes del amanecer, como si está migrando un archivo de documentos heredado a cumplimiento de PDF/A, o poniendo en marcha un servicio de procesamiento nativo en la nube en Kubernetes, los patrones de este tutorial le ofrecen un marco probado sobre el que construir. El procesamiento paralelo con concurrencia controlada mantiene un alto rendimiento. La lógica de omisión en caso de fallo y de reintento mantiene el proceso en marcha cuando algunos archivos causan problemas. Los puntos de control garantizan que nunca se pierda el progreso. Además, los patrones de despliegue en la nube permiten escalar la computación para adaptarla a la carga de trabajo.
¿Listo para empezar a construir? Descargue IronPDF y pruébelo con una versión de prueba gratuita: la misma biblioteca se encarga de todo, desde el renderizado de un solo archivo hasta los procesos por lotes de cientos de miles de archivos. Si tiene alguna pregunta sobre el escalado, el despliegue o la arquitectura para su caso de uso específico, póngase en contacto con nuestro equipo de soporte de ingeniería: hemos ayudado a equipos a crear procesos por lotes a todas las escalas y estaremos encantados de ayudarle a hacerlo bien.
Preguntas Frecuentes
¿Qué es el procesamiento de PDF por lotes en C#?
El procesamiento de PDF por lotes en C# se refiere al manejo automatizado de numerosos documentos PDF simultáneamente, utilizando el lenguaje de programación C#. Este método es ideal para automatizar flujos de trabajo de documentos a escala.
¿Cómo puede IronPDF ayudar en el procesamiento de PDF por lotes?
IronPDF proporciona sólidas herramientas y bibliotecas que agilizan el procesamiento de PDF por lotes en C#. Es compatible con el procesamiento en paralelo, lo que permite la gestión eficaz de miles de archivos PDF simultáneamente.
¿Cuáles son las ventajas de utilizar el procesamiento paralelo con IronPDF?
El procesamiento paralelo con IronPDF permite un procesamiento por lotes de PDF más rápido y eficaz. Este enfoque maximiza la utilización de recursos y reduce significativamente el tiempo de procesamiento.
¿Se puede implementar IronPDF en plataformas en la nube para el procesamiento por lotes?
Sí, IronPDF se puede implementar en plataformas en la nube como Azure Functions, AWS Lambda y Kubernetes, lo que permite un procesamiento de PDF por lotes escalable y flexible.
¿Cómo gestiona IronPDF los errores durante el procesamiento de PDF por lotes?
IronPDF incluye funciones de gestión de errores y lógica de reintento que garantizan la fiabilidad durante el procesamiento de PDF por lotes. Estas funciones ayudan a gestionar y rectificar errores sin intervención manual.
¿Cuál es la función de la lógica de reintento en el procesamiento de PDF con IronPDF?
La lógica de reintento de IronPDF garantiza que los problemas temporales no interrumpan el flujo de trabajo de procesamiento por lotes. Si se produce un error, IronPDF puede intentar automáticamente volver a procesar el documento que ha fallado.
¿Por qué C# es un lenguaje adecuado para el procesamiento de PDF por lotes?
C# es un potente lenguaje de programación con amplias bibliotecas y marcos de trabajo que lo hacen ideal para el procesamiento de PDF por lotes. Se integra perfectamente con IronPDF para una automatización eficaz de los documentos.
¿Cómo garantiza IronPDF la seguridad de los documentos PDF durante su procesamiento?
IronPDF es compatible con el manejo seguro de documentos PDF mediante funciones de cifrado y protección por contraseña, lo que garantiza la confidencialidad y seguridad de los documentos procesados.
¿Cuáles son algunos de los casos de uso del procesamiento de PDF por lotes en las empresas?
Las empresas utilizan el procesamiento de PDF por lotes para tareas como la generación masiva de facturas, la digitalización de documentos y la distribución de informes a gran escala. IronPDF facilita estos casos de uso automatizando y agilizando los flujos de trabajo de documentos.
¿Puede IronPDF manejar diferentes formatos y versiones de PDF?
Sí, IronPDF está diseñado para manejar varios formatos y versiones de PDF, lo que garantiza la compatibilidad y la flexibilidad en las tareas de procesamiento por lotes.


¿Aún desplazándote?
¿Quieres una prueba rápida? PM > Install-Package IronPdf
ejecutar una muestra Mira cómo tu HTML se convierte en PDF.










