


C# PDF Parser
Parse PDF files in C# using IronPDF's ExtractAllText method to extract text from entire documents or specific pages. This approach provides simple, efficient PDF text extraction for .NET applications with just a few lines of code.
IronPDF makes PDF parsing straightforward in C# applications. This tutorial demonstrates how to use IronPDF, a comprehensive C# library for PDF generation and manipulation, to parse PDFs in just a few steps.
Quickstart: Efficient PDF Parsing with IronPDF
Start parsing PDFs in C# using IronPDF with minimal code. This example shows how to extract all text from a PDF file while maintaining its original formatting. IronPDF's ExtractAllText method enables seamless PDF parsing integration into .NET applications. Follow these steps for straightforward setup and execution.
-
Install IronPDF with NuGet Package Manager
PM > Install-Package IronPdf -
Copy and run this code snippet.
var text = IronPdf.FromFile("sample.pdf").ExtractAllText(); -
Deploy to test on your live environment
Start using IronPDF in your project today with a free trial

Minimal Workflow (5 steps)
- Download C# PDF parser library
- Install in your Visual Studio
- Use the
ExtractAllTextmethod to extract every single line of text - Extract all text from a single page with the
ExtractTextFromPagemethod - View parsed PDF content
How Do I Parse PDF Files in C#?
Parsing PDF files is simple with IronPDF. The code below uses the ExtractAllText method to extract every line of text from the entire PDF document. The comparison shows extracted PDF content alongside its output. The library also supports extracting text and images from specific sections of PDF documents.
:path=/static-assets/pdf/content-code-examples/how-to/csharp-parse-pdf-parse-pdf.csusing IronPdf;
// Select the desired PDF File
PdfDocument pdf = PdfDocument.FromFile("sample.pdf");
// Extract all text from an pdf
string allText = pdf.ExtractAllText();
// Extract all text from page 1
string page1Text = pdf.ExtractTextFromPage(0);Imports IronPdf
' Select the desired PDF File
Private pdf As PdfDocument = PdfDocument.FromFile("sample.pdf")
' Extract all text from an pdf
Private allText As String = pdf.ExtractAllText()
' Extract all text from page 1
Private page1Text As String = pdf.ExtractTextFromPage(0)IronPDF simplifies PDF parsing across various scenarios. Whether working with HTML to PDF conversions, extracting content from existing documents, or implementing advanced PDF features, the library provides comprehensive support.
IronPDF offers seamless integration with Windows applications and supports deployment on Linux and macOS platforms. The library also supports Azure deployment for cloud-based solutions.
Advanced Text Extraction Examples
Here are additional ways to parse PDF content using IronPDF:
:path=/static-assets/pdf/content-code-examples/how-to/csharp-parse-pdf-3.csusing IronPdf;
// Parse PDF from URL
var pdfFromUrl = PdfDocument.FromUrl("https://example.com/document.pdf");
string urlPdfText = pdfFromUrl.ExtractAllText();
// Parse password-protected PDFs
var protectedPdf = PdfDocument.FromFile("protected.pdf", "password123");
string protectedText = protectedPdf.ExtractAllText();
// Extract text from specific page range
var largePdf = PdfDocument.FromFile("large-document.pdf");
for (int i = 5; i < 10; i++)
{
string pageText = largePdf.ExtractTextFromPage(i);
Console.WriteLine($"Page {i + 1}: {pageText.Substring(0, 100)}...");
}
Imports IronPdf
' Parse PDF from URL
Dim pdfFromUrl = PdfDocument.FromUrl("https://example.com/document.pdf")
Dim urlPdfText As String = pdfFromUrl.ExtractAllText()
' Parse password-protected PDFs
Dim protectedPdf = PdfDocument.FromFile("protected.pdf", "password123")
Dim protectedText As String = protectedPdf.ExtractAllText()
' Extract text from specific page range
Dim largePdf = PdfDocument.FromFile("large-document.pdf")
For i As Integer = 5 To 9
Dim pageText As String = largePdf.ExtractTextFromPage(i)
Console.WriteLine($"Page {i + 1}: {pageText.Substring(0, 100)}...")
NextThese examples demonstrate IronPDF's flexibility when handling different PDF sources and scenarios. For complex parsing needs, explore PDF DOM object access to work with structured content.
Handling Different PDF Types
IronPDF excels at parsing various PDF types:
:path=/static-assets/pdf/content-code-examples/how-to/csharp-parse-pdf-4.csusing IronPdf;
using System.Text.RegularExpressions;
// Parse scanned PDFs with OCR (requires IronOcr)
var scannedPdf = PdfDocument.FromFile("scanned-document.pdf");
string ocrText = scannedPdf.ExtractAllText();
// Parse PDFs with forms
var formPdf = PdfDocument.FromFile("form.pdf");
string formText = formPdf.ExtractAllText();
// Extract and filter specific content
string invoiceText = pdf.ExtractAllText();
var invoiceNumber = Regex.Match(invoiceText, @"Invoice #: (\d+)").Groups[1].Value;
var totalAmount = Regex.Match(invoiceText, @"Total: \$([0-9,]+\.\d{2})").Groups[1].Value;
Imports IronPdf
Imports System.Text.RegularExpressions
' Parse scanned PDFs with OCR (requires IronOcr)
Dim scannedPdf = PdfDocument.FromFile("scanned-document.pdf")
Dim ocrText As String = scannedPdf.ExtractAllText()
' Parse PDFs with forms
Dim formPdf = PdfDocument.FromFile("form.pdf")
Dim formText As String = formPdf.ExtractAllText()
' Extract and filter specific content
Dim invoiceText As String = pdf.ExtractAllText()
Dim invoiceNumber = Regex.Match(invoiceText, "Invoice #: (\d+)").Groups(1).Value
Dim totalAmount = Regex.Match(invoiceText, "Total: \$([0-9,]+\.\d{2})").Groups(1).ValueHow Do I View the Parsed PDF Content?
A C# Form displays the parsed PDF content from the code execution above. This output provides the exact text from a PDF for document processing needs.
~ PDF ~
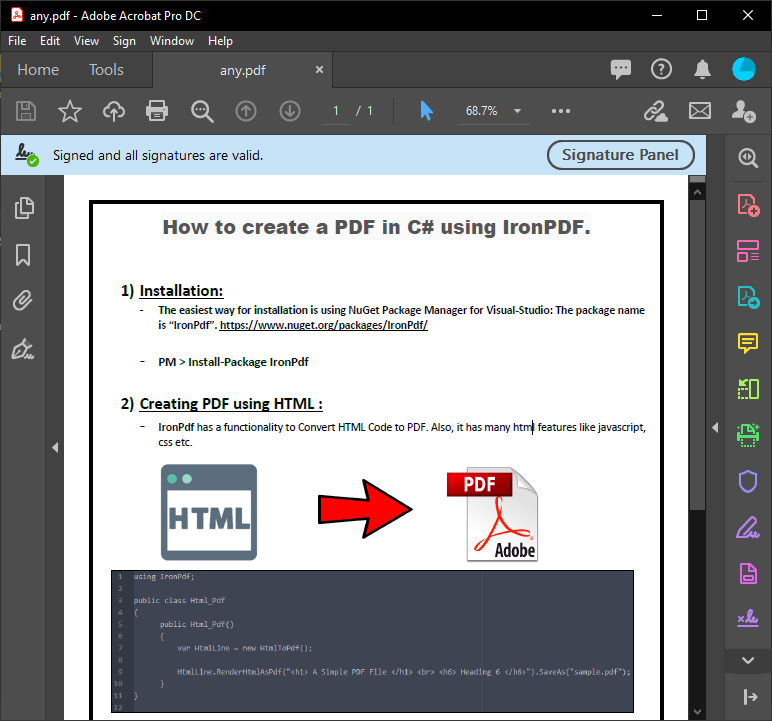
~ C# Form ~
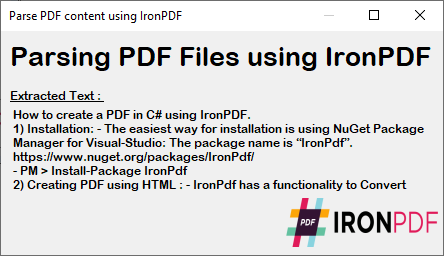
The extracted text maintains the original formatting and structure from the PDF, making it ideal for data processing, content analysis, or migration tasks. Process this text further by finding and replacing specific content or exporting it to other formats.
Integrating PDF Parsing into Your Applications
IronPDF's parsing capabilities integrate into various application types:
// ASP.NET Core example
public IActionResult ParseUploadedPdf(IFormFile pdfFile)
{
using var stream = pdfFile.OpenReadStream();
var pdf = PdfDocument.FromStream(stream);
var extractedText = pdf.ExtractAllText();
// Process or store the extracted text
return Json(new {
success = true,
textLength = extractedText.Length,
preview = extractedText.Substring(0, Math.Min(500, extractedText.Length))
});
}
// Console application example
static void BatchParsePdfs(string folderPath)
{
var pdfFiles = Directory.GetFiles(folderPath, "*.pdf");
foreach (var file in pdfFiles)
{
var pdf = PdfDocument.FromFile(file);
var text = pdf.ExtractAllText();
// Save extracted text
var textFile = Path.ChangeExtension(file, ".txt");
File.WriteAllText(textFile, text);
Console.WriteLine($"Parsed: {Path.GetFileName(file)} - {text.Length} characters");
}
}// ASP.NET Core example
public IActionResult ParseUploadedPdf(IFormFile pdfFile)
{
using var stream = pdfFile.OpenReadStream();
var pdf = PdfDocument.FromStream(stream);
var extractedText = pdf.ExtractAllText();
// Process or store the extracted text
return Json(new {
success = true,
textLength = extractedText.Length,
preview = extractedText.Substring(0, Math.Min(500, extractedText.Length))
});
}
// Console application example
static void BatchParsePdfs(string folderPath)
{
var pdfFiles = Directory.GetFiles(folderPath, "*.pdf");
foreach (var file in pdfFiles)
{
var pdf = PdfDocument.FromFile(file);
var text = pdf.ExtractAllText();
// Save extracted text
var textFile = Path.ChangeExtension(file, ".txt");
File.WriteAllText(textFile, text);
Console.WriteLine($"Parsed: {Path.GetFileName(file)} - {text.Length} characters");
}
}Imports Microsoft.AspNetCore.Mvc
Imports System.IO
' ASP.NET Core example
Public Function ParseUploadedPdf(pdfFile As IFormFile) As IActionResult
Using stream = pdfFile.OpenReadStream()
Dim pdf = PdfDocument.FromStream(stream)
Dim extractedText = pdf.ExtractAllText()
' Process or store the extracted text
Return Json(New With {
.success = True,
.textLength = extractedText.Length,
.preview = extractedText.Substring(0, Math.Min(500, extractedText.Length))
})
End Using
End Function
' Console application example
Private Shared Sub BatchParsePdfs(folderPath As String)
Dim pdfFiles = Directory.GetFiles(folderPath, "*.pdf")
For Each file In pdfFiles
Dim pdf = PdfDocument.FromFile(file)
Dim text = pdf.ExtractAllText()
' Save extracted text
Dim textFile = Path.ChangeExtension(file, ".txt")
File.WriteAllText(textFile, text)
Console.WriteLine($"Parsed: {Path.GetFileName(file)} - {text.Length} characters")
Next
End SubThese examples show PDF parsing incorporation into web applications and batch processing scenarios. For advanced implementations, explore async and multithreading techniques to improve performance when processing multiple PDFs.
Ready to see what else you can do? Check out our tutorial page here: Edit PDFs
Frequently Asked Questions
How do I extract all text from a PDF file in C#?
You can extract all text from a PDF file using IronPDF's ExtractAllText method. Simply load your PDF with IronPdf.FromFile("sample.pdf") and call ExtractAllText() to retrieve all text content while maintaining the original formatting.
What's the simplest way to parse a PDF in .NET?
The simplest way is using IronPDF with just one line of code: var text = IronPdf.FromFile("sample.pdf").ExtractAllText(). This method extracts every line of text from the entire PDF document with minimal setup required.
Can I extract text from a specific page of a PDF?
Yes, IronPDF provides the ExtractTextFromPage method to extract text from individual pages. This allows you to target specific sections of your PDF document rather than extracting all content at once.
How do I parse password-protected PDFs in C#?
IronPDF supports parsing password-protected PDFs. Use PdfDocument.FromFile("protected.pdf", "password123") to load the protected document, then call ExtractAllText() to extract the text content.
Can I parse PDFs from URLs instead of local files?
Yes, IronPDF can parse PDFs directly from URLs using PdfDocument.FromUrl("https://example.com/document.pdf"). After loading the PDF from the URL, use ExtractAllText() to extract the text content.
What platforms does the PDF parser support?
IronPDF supports PDF parsing across multiple platforms including Windows applications, Linux, macOS, and Azure cloud deployments, providing comprehensive cross-platform compatibility for your .NET applications.
Does the PDF parser maintain text formatting during extraction?
Yes, IronPDF's ExtractAllText method maintains the original formatting of the PDF content during extraction, ensuring that the parsed text retains its structure and layout from the source document.
Can I extract both text and images from PDFs?
IronPDF supports extracting both text and images from PDF documents. Beyond the ExtractAllText method for text extraction, the library provides additional functionality for extracting images from specific sections of PDF documents.


Still Scrolling?
Want proof fast? PM > Install-Package IronPdf
run a sample watch your HTML become a PDF.










